本文详细介绍了TI舱内毫米波雷达芯片的评估流程和SDK应用开发方法。在评估流程部分,主要介绍了评估板程序下载步骤、雷达参数配置方法、舱内传感应用场景(入侵检测、儿童检测、安全带提醒)的演示流程;在SDK应用开发方法部分,涵盖多核启动流程、存储分配和核间通信机制,同时进行了典型的工作流程解析,重点描述了从点云生成得到分类处理的完整信号链。
文章为开发者提供了从硬件评估到功能实现的完整技术参考。用户可以在此基础上搭建自己的应用逻辑,包括根据车身信号实现三种不同模式的实时切换,以及最终识别结果的信号输出,硬件看门狗等等产品化的开发。
目录
芯片方案评估
程序下载
Ti的雷达芯片都会有对应的评估板,我们可以先拿到它的评估板,如下图所示。

我们通过USB线将评估板与电脑相连接,然后在<MMWAVE_SDK6_INSTALL_DIR>\tools\visualizer\visualizer.exe目录下找到可视化的评估工具。
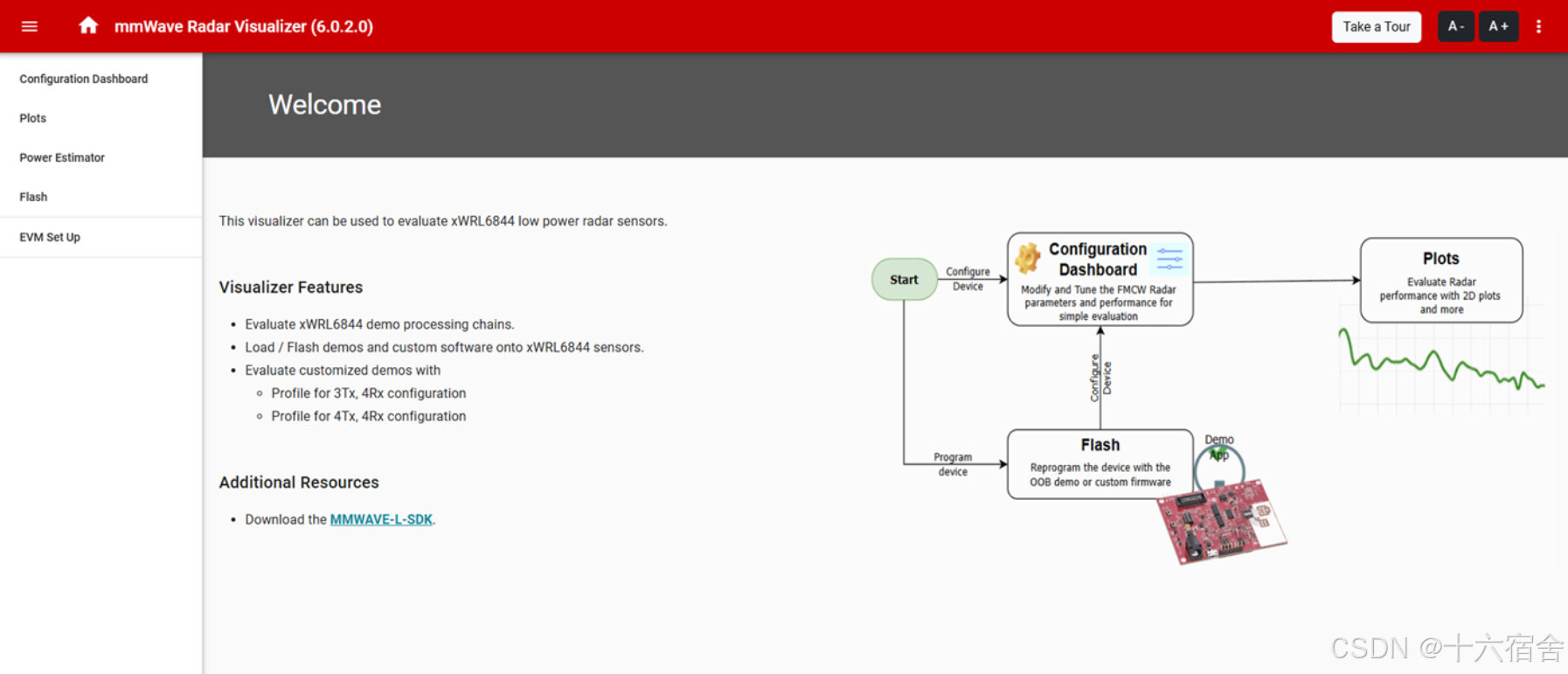
下一步我们将在可视化工具中打开"Flash"选项卡,并选择评估板的COM端口(系统应能自动识别该端口)。
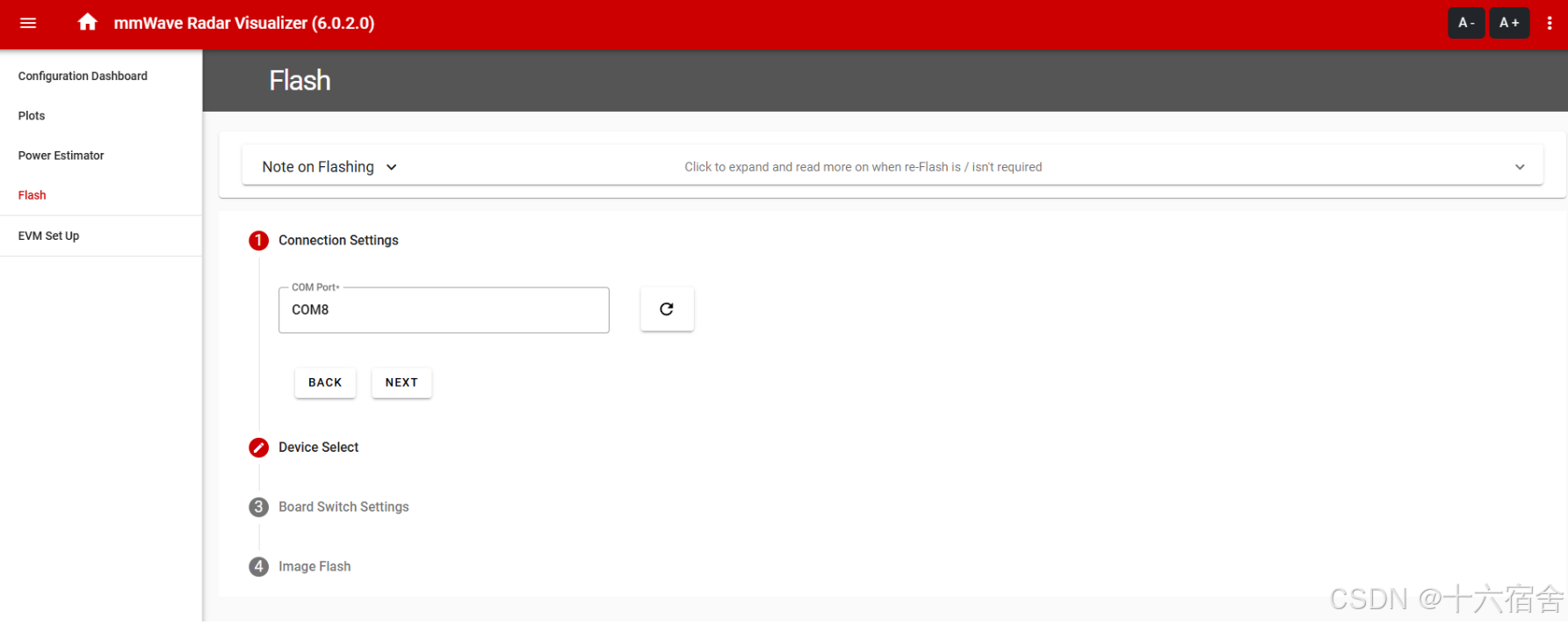
若无法识别,请在设备管理器中查找名为 "XDS110 Class Application/User UART" 的COM 端口,然后在图形用户界面中选择此喘口。
然后,在可视化界面选择对应的芯片类型(一般为自动识别)。
下一步通过拨码开关,将板卡配置成Flashing Mode。
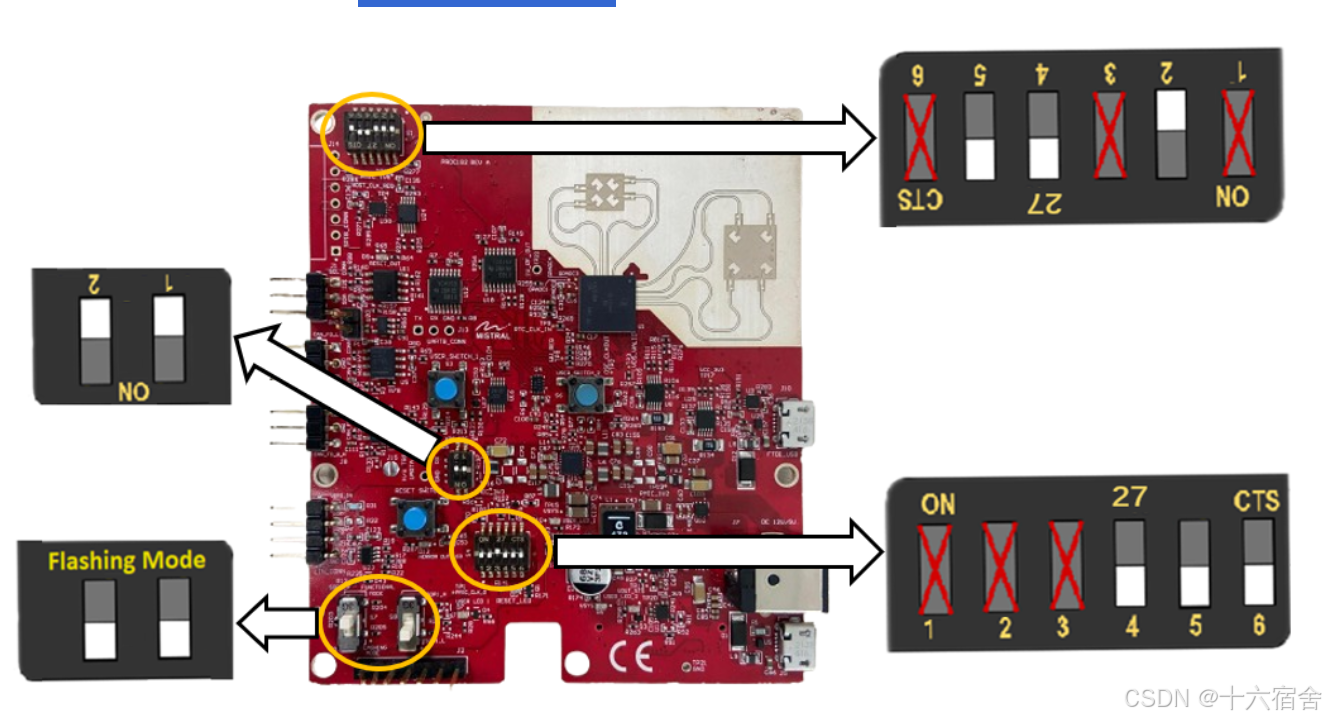
然后选择摁下重启按钮(绿色圆圈标记),板卡重启之后以此模式工作。

最后,选择需要下载的二进制固件文件,这里我们选择demo_in_cabin_sensing_6844_system.release.appimage。
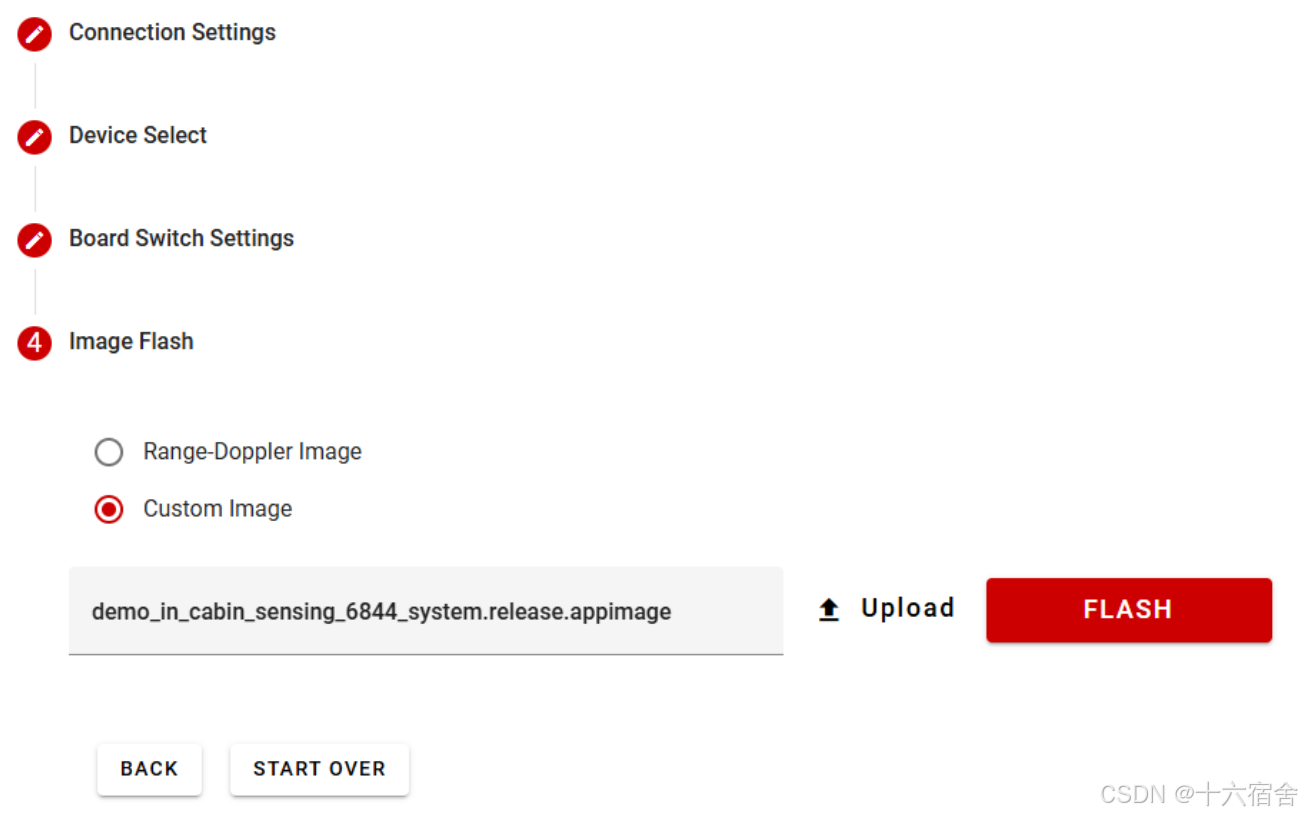
至此,程序已经下载完毕。
Chirp配置
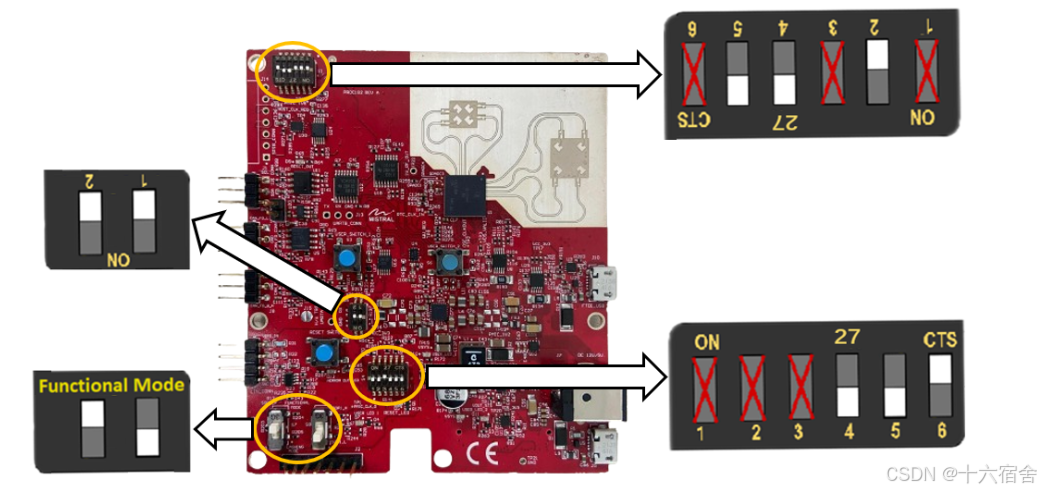
在可视化的评估工具中点击"Configuration Dashboard"。将弹出一个提示窗口,指示您将设备切换至功能模式。通过将开关设置为可视化的评估工具中显示的方式,将设备置于功能模式。然后,摁下重启键,板卡重启,进入功能模式。
在配置界面中,选择对应的整个信号处理链路的配置,包括Chirp,AD,Cfar,aoa等配置信息,用户可以根据自己的实际需要,进行调整从而进行针对性的测试。最后, 点击"Send Selected Config"发送配置。
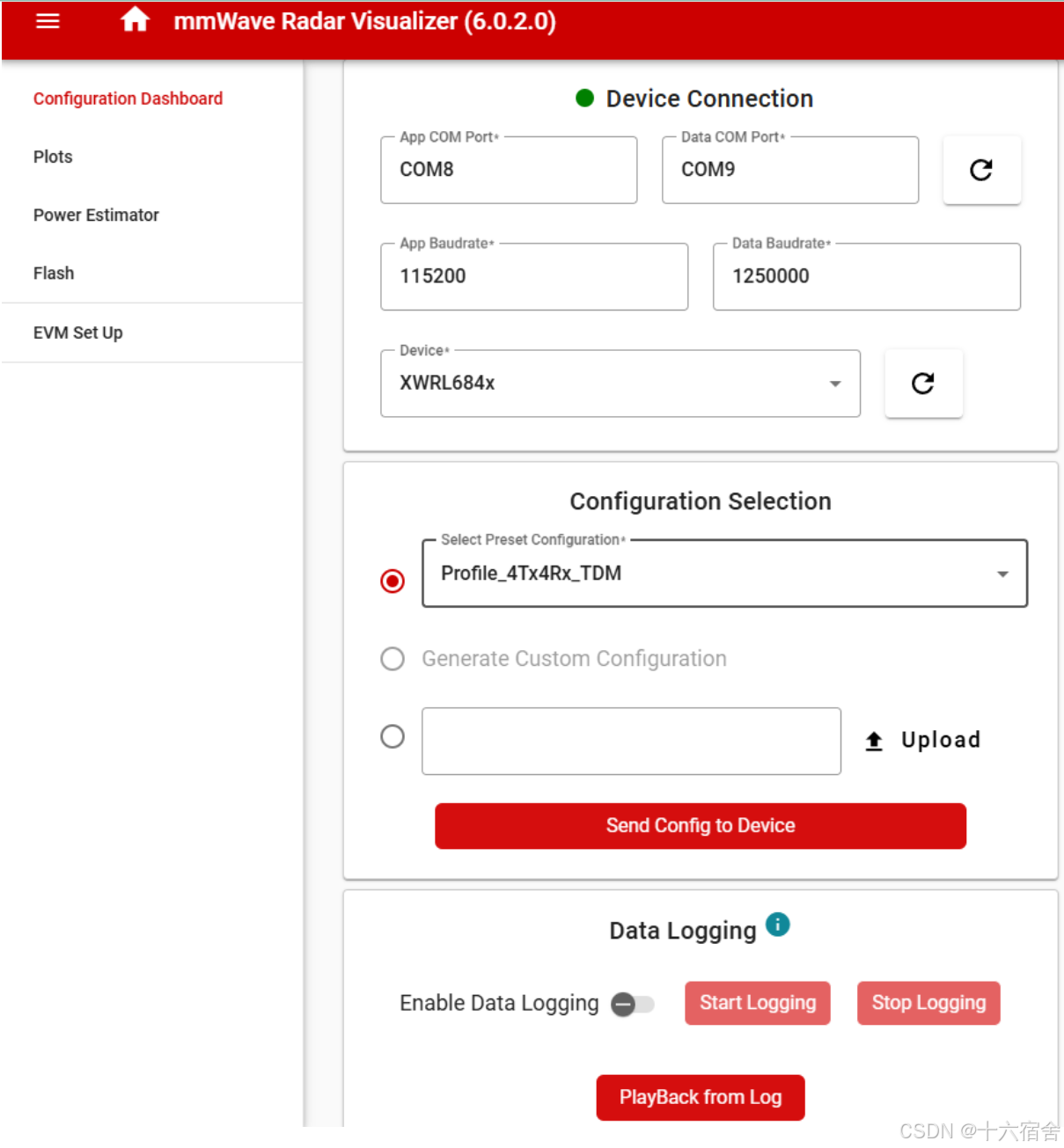
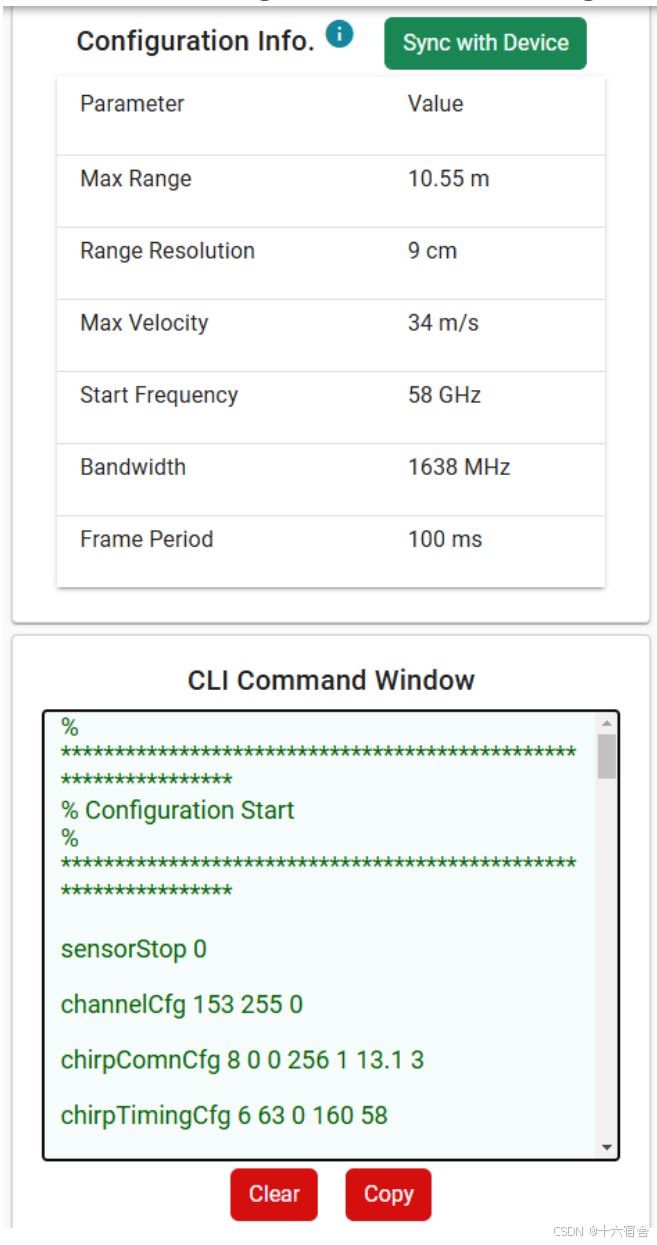
您可以在"Device Configuration Input"标签页中看到发送的配置转化的指标。
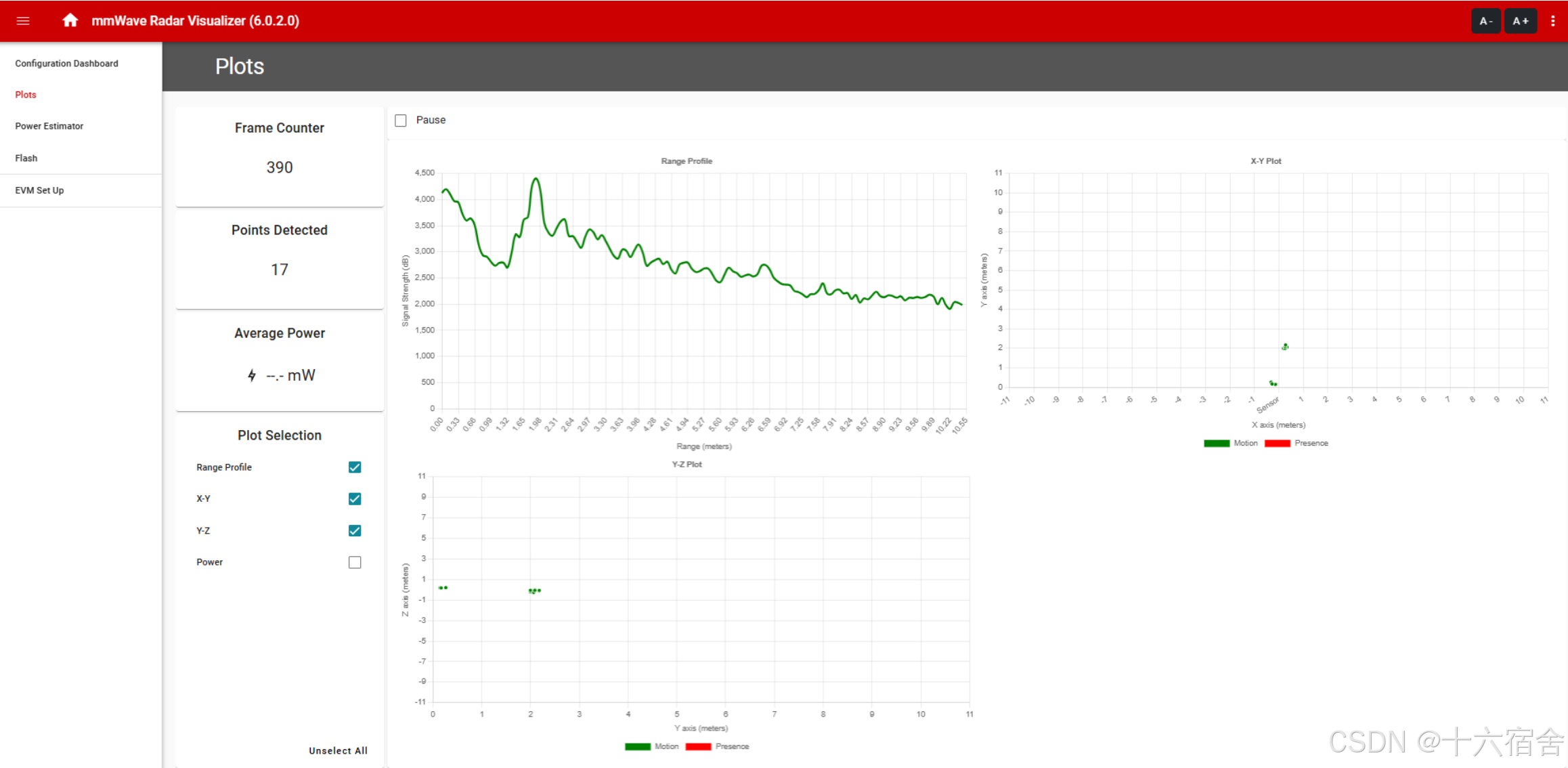
您可以通过打开"Plots"标签页,可以看原始的一维数据以及2维热图。
使用场景演示
下面的示例演示了使用TI车载雷达芯片用于车内传感应用的情况,包括入侵检测(ID)、儿童存在检测(CPD)以及安全带提醒(SBR)。CPD和SBR将共享相同的信号处理链以实现点云生成,所以他们的配置文件是一样的。所有三个应用(即ID、CPD和SBR)都将使用相同的演示二进制文件和演示上位机。可以加载不同的配置文件,以支持这三个不同应用。
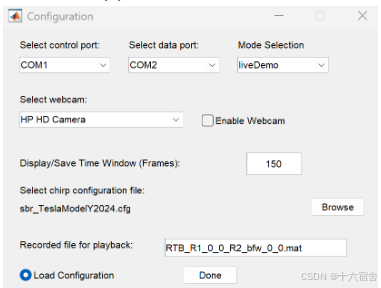
请注意,此示例是EVM板在顶前控制台安装方式下进行测试和调优的。为实现最佳性能,针对其他天线设计以及不同安装位置还需进行优化工作。下面我们来介绍安全带提醒功能的演示的快速开始介绍。首先,我们在<Radar_Toolbox>\tools\visualizers\LowPower_Incabin_GUI\src\目录下点开occupancy_demo_gui_AWRL6844.exe,然后选择对应的配置文件即可。
下图是一个演示实例,可以看到雷达正确识别了三个座位上的乘客,并且没有将水误识别成人。
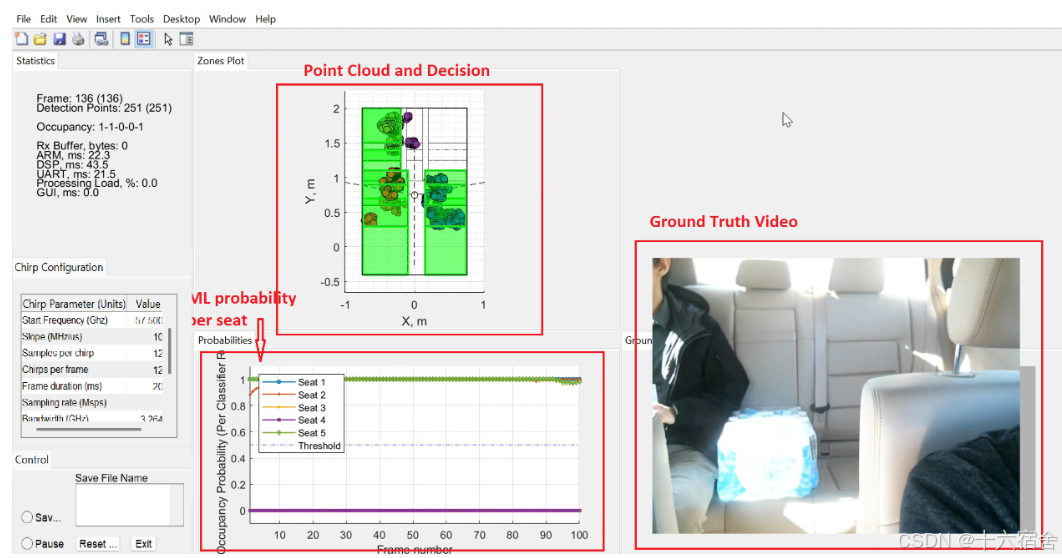
点云的图是3D的,可以旋转观察每个位置的3D点云情况。
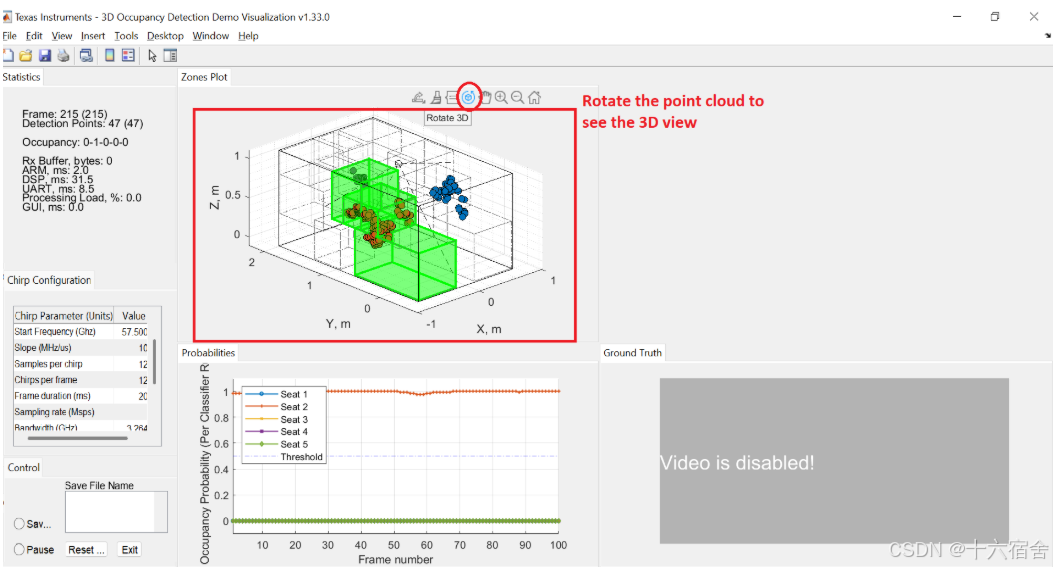
要想实际的演示效果能有达到预期,我们之前还需要进行一些准备工作。首先,我们需要将点云数据从传感器坐标系转换到车辆坐标系中。我们可以通过CLI配置的sensorPosition来配置传感器的安装位置,从而完成坐标的切换。

还需要按照当天的天线进行配置。
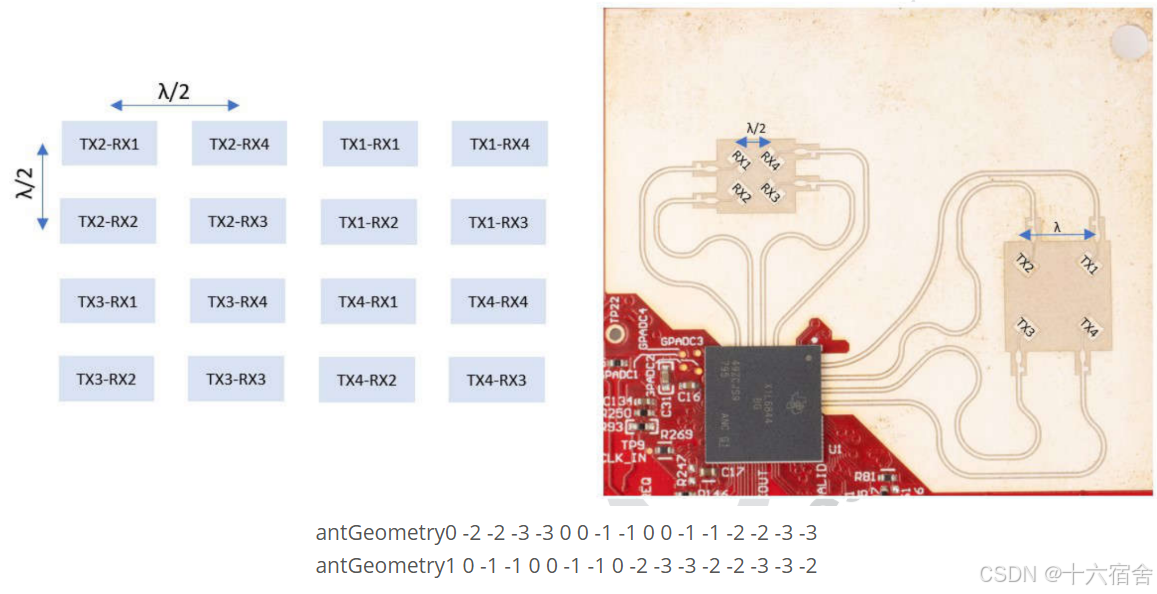
为了获得最佳的探测性能,用户应运行Out of Box Demo Range Bias以及Rx Channel Gain/Phase Measurement进行幅相校准,以获取准确的校准数值,下图为每人的校准数据。
bash
compRangeBiasAndRxChanPhase 0 1 0 1 0 1 0 1 0 -1 0 -1 0 -1 0 -1 0 1 0 1 0 1 0 1 0 -1 0 -1 0 -1 0 -1 0 (This is the default command)最后,还需要对Zone的进行定义,每一个Zone有三个Cuboid组成,Cuboid 1代表的是头和胸部区域,Cuboid 2代表的是臀部区域,Cuboid 3代表的是腿和脚区域。
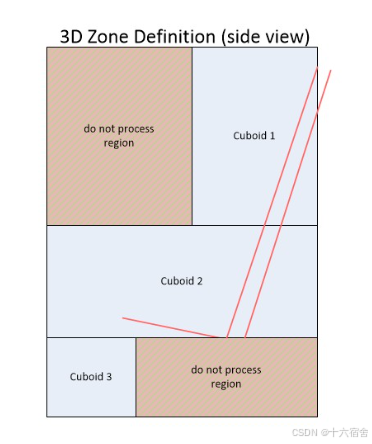
下面是示例的配置。
cpp
% zone 0 (driver) cuboids
cuboidDef <zoneInd> <coboidInd> <xMIn> <xMax> <yMin> <yMax> <zMin> <zMax>
cuboidDef 0 0 0.15 0.75 0.6 1.1 0.5 1.1
cuboidDef 0 1 0.15 0.75 0.3 0.9 0.5 0.85
cuboidDef 0 2 0.15 0.75 -0.4 0.7 -0.1 0.5
% zone 1 (front passenger) cuboids
cuboidDef 1 0 -0.75 -0.15 0.6 1.1 0.5 1.1
cuboidDef 1 1 -0.75 -0.15 0.3 0.9 0.5 0.85
cuboidDef 1 2 -0.75 -0.15 -0.4 0.7 -0.1 0.5
% zone 2 (2nd row driver side) cuboids
cuboidDef 2 0 0.28 0.75 1.5 2.0 0.8 1.1
cuboidDef 2 1 0.28 0.75 1.25 2.0 0.3 0.8
cuboidDef 2 2 0.28 0.75 0.95 1.4 -0.1 0.4
% zone 3 (2nd row middle) cuboids
cuboidDef 3 0 -0.2 0.2 1.5 2.0 0.8 1.1
cuboidDef 3 1 -0.2 0.2 1.4 2.0 0.35 0.8
cuboidDef 3 2 -0.2 0.2 1.25 1.4 0 0.4
% zone 4 (2nd row passenger side) cuboids
cuboidDef 4 0 -0.75 -0.28 1.5 2.0 0.8 1.1
cuboidDef 4 1 -0.75 -0.28 1.25 2.0 0.3 0.8
cuboidDef 4 2 -0.75 -0.28 0.95 1.4 -0.1 0.4入侵检测和儿童检测,这里就赘述了,大致流程都是一致的,儿童检测和上述的介绍基本一致,入侵检测在导入的配置文件以及显示界面略有不同。
SDK开发介绍
MMWAVE-L-SDK包含用于开发基于RTOS和非RTOS的ARM R5F CPU及相关外设应用的示例、库和工具。该SDK还包含用于与这些ARM R5F应用程序进行接口开发的示例。
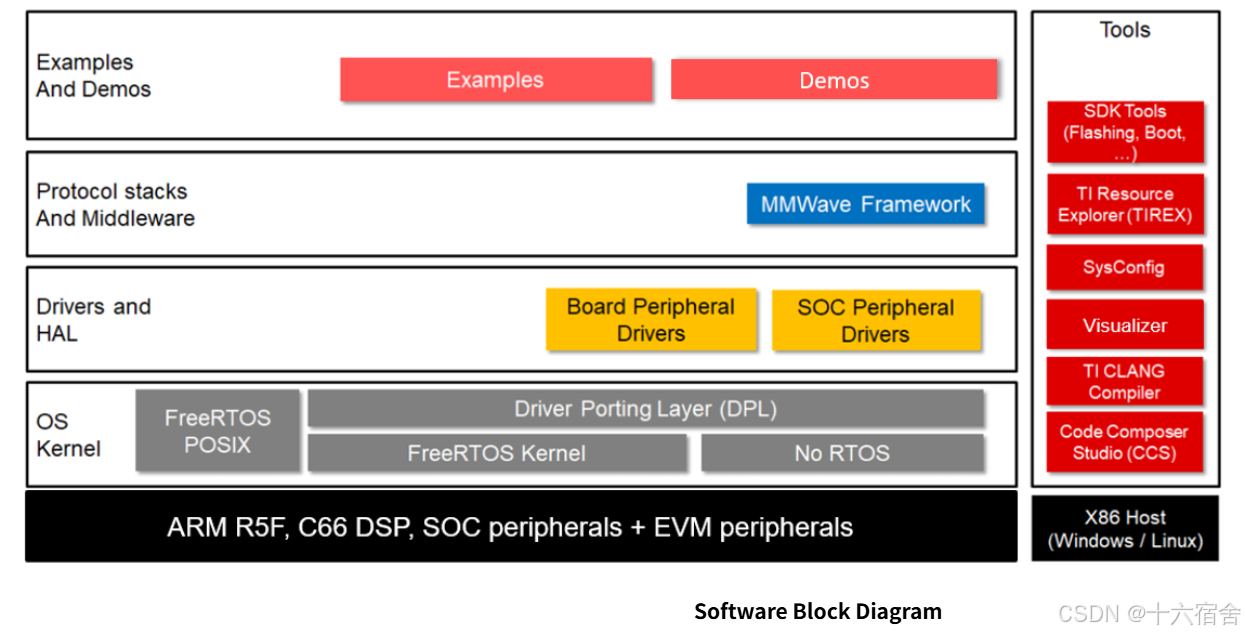
芯片启动流程
AWRL6844 的启动是一个从硬件引脚锁定模式开始,由 ROM 加载程序,再到主控核心运行应用程序,最后协同各处理核心并初始化射频硬件的完整流程,其核心是根据启动模式选择(SOP)加载并执行用户应用程序。主要包含一下几个关键步骤:
-
电与模式锁定:芯片上电或复位后,首先锁定系统配置模式(SOP),决定后续的启动行为。
-
ROM Bootloader 执行:片上的 ROM 引导程序开始运行,根据 SOP 模式从指定的外设(如 Flash、UART)加载初始程序。
-
应用程序加载与核心启动:RBL 会从外部连接的闪存(如 QSPI Flash)中,读取一个预先准备好的整体应用镜像文件 (appimage)。这个文件是一个"大包",里面包含了将要运行在芯片上所有核心(如 DSP、R5F 主控核、前端控制器 FECSS 等)的二进制程序代码。RBL 会解析这个整体应用镜像,识别出属于不同核心的部分。完成加载后,RBL会释放核心的复位状态,让其开始从加载好的程序入口点执行代码。
-
应用初始化与运行:AWRL6844 是一个多核异构处理器,包含 Cortex-R5F(主控)、C66x DSP(信号处理) 和 Cortex-M3(前端控制) 等核心。用户应用程序启动后,完成雷达硬件初始化、配置并开始工作。
-
初始化 SDK 和底层驱动 :调用
mmWaveLink等API初始化雷达硬件抽象层。 -
射频前端 (RF) 上电与校准:应用程序会控制射频前端上电,并执行一系列的校准流程,如锁相环 (APLL) 校准、发射功率 (Tx) 校准、接收增益 (Rx) 校准等,以确保雷达性能。这些校准数据会从存储中恢复或在启动时重新测量。
-
配置工作参数 :根据用户配置(如
cfg文件),设置雷达的发射波形(chirp)、帧结构、信号处理链参数等。 -
启动传感器 :完成所有配置后,调用
Sensor_start命令,雷达开始发射并接收信号,进入正常工作状态。
雷达工作流程
针对SBR的应用,为增强对近乎静态目标(如车辆内静止的人)的检测性能,Demo采用多帧技术来生成距离-角度热图,而非使用单一帧。通过使用多帧滑动窗口技术,可实现不同时间粒度的检测。该窗口内的帧数可通过CLI命令sigProcChainCommonCfg(默认设置为4)进行配置。
此示例的高级流程描述如下:
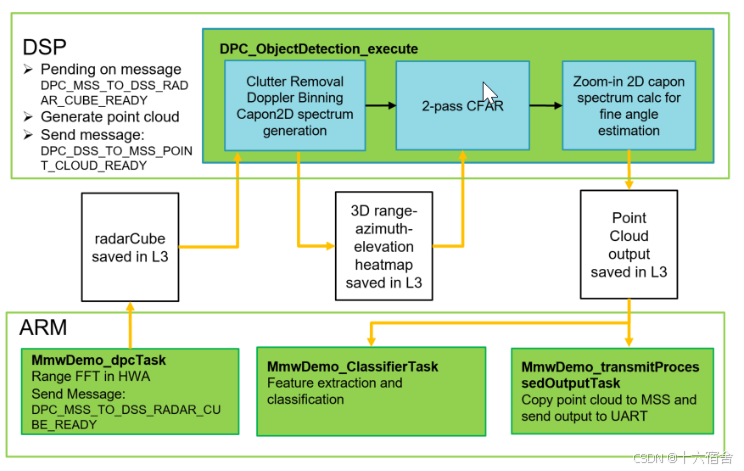
- 本Demo使用了大多数毫米波雷达演示中使用的标准距离处理方法,并由HWA(硬件加速器)控制以生成雷达立方体。
- 帧中的每个chirp 的距离处理完成后,雷达立方体即准备就绪。ARM核心将发送IPC(核间通信)消息DPC_MSS_TO_DSS_RADAR_ CUBE_READY.
- DSP核心接收到IPC消息之后, DSP核心将调用"DPC_ObjectDetetion_execute" 函数以启动点云检测的帧间处理流程。点云生成过程包含3个步骤:
- 使用Capon波束成形算法在粗角度网格上生成3D距离-方位-仰角热图。
- 在距离和角度方向上均应用2-pass CFAR。
- 对于每个检测到的峰值,将计算放大方位角-俯仰角谱以获得精确的角度估计。
- 点云生成完成后,DSP核心将发送IPC消DPC_DSS_TO_MSS_POINT_CLOUD_READY。
- 接收到此IPC消息后,ARM核心将发布一个信号量classifierTaskSemHandle。
- MmwDemo_ClassifierTask在接收到classifierTaskSemHandle信号量后进行特征提取与分类,并在完成时发布信号量tlvsemHandle。
- 当接收到信号量tlvSemHandle后,MmwDemo_transmitProcessedoutputTask通过UART输出点云、特征和分类信息。
以下是点云后的数据处理的框图。
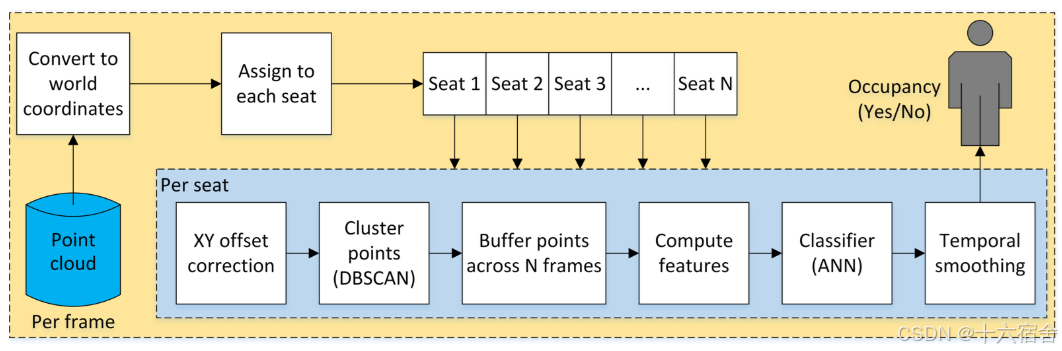
点云首先被转换到世界(车辆)坐标系中,并分配到不同的座椅区域。每个区域内的点将在 XY 平面上进行归一化处理,以便对所有座椅区域训练同一个分类器。可以对点进行聚类以滤除孤立点(可选的)。来自聚类的点会在一个滑动窗口内跨N帧(在 SBR 模式下 N = 20)进行缓冲。之后,生成特征并通过基于人工神经网络(ANN)的分类器运行。最终,目标代码输出软决策,即座椅被占用的概率。在可视化工具中,经过时间平滑后,会给出最终的硬决策。SBR 占用状态分类器使用了 7 个特征,包括累积点的总数,以及 x 值、y 值、z 值的均方根和标准差(std)。
存储分配
Ti的雷达芯片往往具有三个部分,分别是Front-End Controller Sub-System(FECSS),它是前端控制子系统,我们无法对这部分进行编程,它会根据我们的配置来完成前端的射频前端的初始化等工作;DSP Sub-System (DSS)是DSP子系统,它主要完成距离维度FFT数据到点云的转化;Application Sub-System(APPSS)应用子系统,ARM核心,主要完成片内外设的初始化以及后续的数据处理以及转发和模式切换等工作。针对每个核心,Ti芯片又分配多级的存储。如下表所示:
| 子系统 | 内存类型/位置 | 容量 | 主要用途与说明 |
|---|---|---|---|
| DSP 子系统 (DSPSS) | L1(Cache) | 64KB | 分为L1P(程序)和L1D(数据),高速缓存,直接映射 |
| L2 | 384KB | C66x DSP 核心的专用高性能内存,用于存放关键代码和数据。 | |
| L3 | 512KB | AWRL6844 特有,作为 DSP 子系统内部的大容量本地内存。 | |
| L3 | 896KB | 这部分内存(总1408KB中的一部分)可以与应用子系统或前端子系统共享。 | |
| 应用子系统 (APPSS) | TCM | 768KB | Cortex-R5F 主控核心的专用紧耦合内存,具有确定的访问延迟。 |
| L3 | 896KB | 与DSP共享 | |
| 前端控制子系统 (FECSS) | 内存 | 128KB | 用于控制雷达前端(射频、ADC等)的专用内存。 |
在DSP与ARM的两个子系统对应的工程中,Linker.cmd用于定义工程中代码和数据在内存中的layout,而memory_hex.cmd则定义他们在片外Flash的layout,前者可以理解为"运行布局",后者可以理解为"烧录布局",在CCS生成这个Appimage的过程中,每个核心的工程首先根据Linker.cmd生成.out文件,我们可以直接用这个文件进行在线调试,然后会根据memory_hex.cmd生成hex文件,最后system则会将两个核心生成的hex进行打包,生成Appimage。
核间通信
因为Ti的雷达芯片大部分情况都是多核异构的,一个核心常常用于应用数据处理(如DSP核心),另一个核心则用于实时控制(ARM核心)。Ti芯片采用的是一种Message机制,它作为一种基于共享内存以及硬件中断的软件组件提供给用户。下面是一个简单的实例,当然,您可以参照Demo中的基于以下实例封装好的API。
首先,我们需要包含以下头文件。
cpp
#include <stdio.h>
#include <drivers/ipc_notify.h>
#include <kernel/dpl/DebugP.h>下面是必要的初始化操作。
cpp
int32_t status;
IpcNotify_Params notifyParams;
/* initialize parameters to default */
IpcNotify_Params_init(¬ifyParams);
/* specify the core on which this API is called */
notifyParams.selfCoreId = CSL_CORE_ID_R5FSS0_0;
/* list the cores that will do IPC Notify with this core
* Make sure to NOT list `self` core in the list below
*/
notifyParams.numCores = 1;
notifyParams.coreIdList[0] = CSL_CORE_ID_C66SS0;
status = IpcNotify_init(¬ifyParams);
DebugP_assert(status==SystemP_SUCCESS);下面是注册一个句柄用来接受Message。
cpp
int32_t status;
/* client ID to register against, make sure messages are sent to this client ID */
uint16_t clientId = 4;
/* create a local queue to hold the message */
MyQueue_create(&gMyLocalQ);
/* register a handler to receive messages */
status = IpcNotify_registerClient(clientId, MyMsg_handler, &gMyLocalQ);
DebugP_assert(status==SystemP_SUCCESS);下面是MSS核心向DSS发送Message的实现。
cpp
/* send `msgValue` to `clientId` of core CSL_CORE_ID_C66SS0 */
int32_t status;
/* client ID for which this message is intended,
* make sure a handler is registered for this client ID
*/
uint16_t clientId = 4;
/* message value to send, make sure the
* registered handler handles this message
*/
uint64_t msgValue = 0x08765432;
/* no error checks done inside IpcNotify_sendMsg(), so doing here just to show the constraints */
DebugP_assert(msgValue < IPC_NOTIFY_MSG_VALUE_MAX);
DebugP_assert(clientId < IPC_NOTIFY_CLIENT_ID_MAX);
/* wait until msg is put into internal HW/SW FIFO */
status = IpcNotify_sendMsg(CSL_CORE_ID_C66SS0, clientId, msgValue, 1);
DebugP_assert(status==SystemP_SUCCESS);最后是DSS核心接收到Message的处理函数(注意这里是中断上下文,尽可能简短),以及实际处理的Task实现。
cpp
/* NOTE: local queue implementation not shown, this is a standard FIFO like SW queue,
* which is thread and interrupt safe and can block until there is a element to dequeue
*/
/* local Q to hold received messages */
MyQueue_Obj gMyLocalQ;
void MyMsg_handler(uint32_t remoteCoreId, uint16_t localClientId, uint64_t msgValue, void *args)
{
MyQueue_Obj *myLocalQ = (MyQueue_Obj*)args;
/* message received from remote core `remoteCoreId`, for client ID `localClientId` on this core */
/* instead of handling the messages in callback which is called within ISR, queue this into a larger SW queue.
* Handle to the SW queue is passed via args in this example.
* SW queue could be one per remote core, one per client ID or a common Q for all remote cores and so on.
* Passing queue handle as argument allows the handler to remain
* common across multiple remote cores and client ID's
*/
MyQueue_put(myLocalQ, msgValue);
/* NOTE: THis is a sample handler, actually application can have different design based on its
* specific requirements
*/
}
/* Message handler task */
void MyTask_main(void *args)
{
while(1)
{
uint64_t msgValue;
/* block until there is a element to dequeue from this Q */
MyQueue_wait(&gMyLocalQ, &msgValue);
if(msgValue == 0x08765432)
{
/* handle message value.
* typically message value will be a command to execute
* OR
* it will point (offset or index within a known shared memory base address or array)
* to command and parameters to execute
*/
}
}
}十六宿舍 原创作品,转载必须标注原文链接。
©2023 Yang Li. All rights reserved.
欢迎关注 『十六宿舍』,大家喜欢的话,给个 👍 ,更多关于嵌入式相关技术的内容持续更新中。