大核瓶颈架构改进YOLOv26:扩大感受野与多尺度特征提取双重突破
引言
在目标检测领域,感受野的大小直接影响模型对不同尺度目标的感知能力。传统的3×3卷积虽然计算高效,但在捕获大尺度上下文信息时存在局限性。本文提出的大核瓶颈(Large Kernel Bottleneck)架构通过引入5×5卷积核,在保持计算效率的同时显著扩大了感受野,为YOLOv26带来了多尺度特征提取的全新突破。
大核卷积的理论基础
感受野与特征提取能力
感受野(Receptive Field)定义了输出特征图中每个像素对应输入图像的区域范围。对于卷积神经网络,第 l l l 层的感受野大小可以递归计算:
R F l = R F l − 1 + ( k l − 1 ) × ∏ i = 1 l − 1 s i RF_l = RF_{l-1} + (k_l - 1) \times \prod_{i=1}^{l-1} s_i RFl=RFl−1+(kl−1)×i=1∏l−1si
其中 k l k_l kl 是第 l l l 层的卷积核大小, s i s_i si 是第 i i i 层的步长。
大核卷积的优势
相比传统的3×3卷积,5×5卷积核具有以下优势:
- 更大的感受野:单层5×5卷积的感受野是3×3卷积的2.78倍
- 更丰富的空间信息:25个卷积参数相比9个参数能捕获更复杂的空间模式
- 更强的上下文建模:对于大目标和远距离依赖关系的建模更加有效
感受野面积比较:
Area Ratio = 5 × 5 3 × 3 = 25 9 ≈ 2.78 \text{Area Ratio} = \frac{5 \times 5}{3 \times 3} = \frac{25}{9} \approx 2.78 Area Ratio=3×35×5=925≈2.78
大核瓶颈模块设计
核心架构
大核瓶颈模块采用经典的"压缩-处理-扩展"三阶段设计:
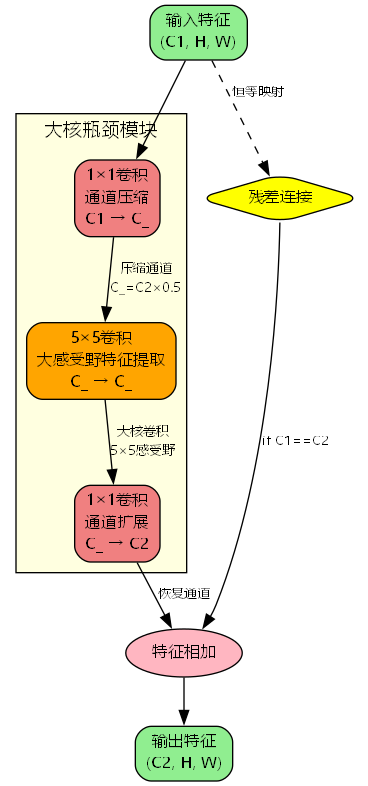
模块包含三个关键组件:
- 通道压缩层(1×1卷积) :将输入通道数从 C 1 C_1 C1 压缩到 C ′ = C 2 × 0.5 C' = C_2 \times 0.5 C′=C2×0.5
- 大核特征提取层(5×5卷积):在压缩后的通道空间进行大感受野特征提取
- 通道扩展层(1×1卷积) :将通道数恢复到 C 2 C_2 C2
数学表达
设输入特征为 X ∈ R C 1 × H × W \mathbf{X} \in \mathbb{R}^{C_1 \times H \times W} X∈RC1×H×W,大核瓶颈的前向传播过程为:
Z 1 = Conv 1 × 1 ( X ) ∈ R C ′ × H × W Z 2 = Conv 5 × 5 ( Z 1 ) ∈ R C ′ × H × W Z 3 = Conv 1 × 1 ( Z 2 ) ∈ R C 2 × H × W Y = { X + Z 3 , if C 1 = C 2 Z 3 , otherwise \begin{aligned} \mathbf{Z}1 &= \text{Conv}{1\times1}(\mathbf{X}) \in \mathbb{R}^{C' \times H \times W} \\ \mathbf{Z}2 &= \text{Conv}{5\times5}(\mathbf{Z}_1) \in \mathbb{R}^{C' \times H \times W} \\ \mathbf{Z}3 &= \text{Conv}{1\times1}(\mathbf{Z}_2) \in \mathbb{R}^{C_2 \times H \times W} \\ \mathbf{Y} &= \begin{cases} \mathbf{X} + \mathbf{Z}_3, & \text{if } C_1 = C_2 \\ \mathbf{Z}_3, & \text{otherwise} \end{cases} \end{aligned} Z1Z2Z3Y=Conv1×1(X)∈RC′×H×W=Conv5×5(Z1)∈RC′×H×W=Conv1×1(Z2)∈RC2×H×W={X+Z3,Z3,if C1=C2otherwise
计算复杂度分析
对于输入尺寸 H × W H \times W H×W,计算量(FLOPs)为:
FLOPs = H × W × C 1 × C ′ ⏟ 1×1压缩 + H × W × C ′ × C ′ × 25 ⏟ 5×5卷积 + H × W × C ′ × C 2 ⏟ 1×1扩展 = H × W × ( C 1 × C ′ + 25 × C ′ 2 + C ′ × C 2 ) \begin{aligned} \text{FLOPs} &= \underbrace{H \times W \times C_1 \times C'}{\text{1×1压缩}} + \underbrace{H \times W \times C' \times C' \times 25}{\text{5×5卷积}} + \underbrace{H \times W \times C' \times C_2}_{\text{1×1扩展}} \\ &= H \times W \times (C_1 \times C' + 25 \times C'^2 + C' \times C_2) \end{aligned} FLOPs=1×1压缩 H×W×C1×C′+5×5卷积 H×W×C′×C′×25+1×1扩展 H×W×C′×C2=H×W×(C1×C′+25×C′2+C′×C2)
当 C ′ = 0.5 × C 2 C' = 0.5 \times C_2 C′=0.5×C2 时,相比直接使用5×5卷积,计算量降低约75%。
层次化特征提取架构
C3k2大核瓶颈模块
为了充分发挥大核卷积的优势,我们设计了C3k2大核瓶颈模块,将多个大核瓶颈单元级联组合:
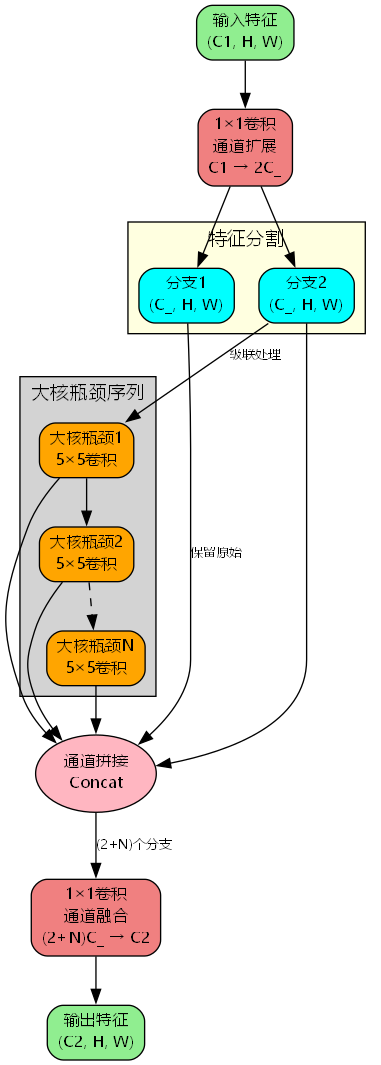
架构特点
- 双路径设计:输入特征经1×1卷积扩展后分为两路
- 级联处理:一路经过N个大核瓶颈单元的级联处理
- 多尺度融合:将原始分支和所有中间特征拼接融合
前向传播过程
设输入 X ∈ R C 1 × H × W \mathbf{X} \in \mathbb{R}^{C_1 \times H \times W} X∈RC1×H×W,C3k2大核瓶颈的处理流程为:
F = Conv 1 × 1 ( X ) ∈ R 2 C ′ × H × W F 1 , F 2 = Split ( F ) G 1 = LKB 1 ( F 2 ) G 2 = LKB 2 ( G 1 ) ⋮ G N = LKB N ( G N − 1 ) Y = Conv 1 × 1 ( Concat ( F 1 , F 2 , G 1 , ... , G N ) ) \begin{aligned} \mathbf{F} &= \text{Conv}_{1\times1}(\mathbf{X}) \in \mathbb{R}^{2C' \times H \times W} \\ \\mathbf{F}_1, \\mathbf{F}_2 &= \text{Split}(\mathbf{F}) \\ \mathbf{G}_1 &= \text{LKB}_1(\mathbf{F}_2) \\ \mathbf{G}_2 &= \text{LKB}_2(\mathbf{G}_1) \\ &\vdots \\ \mathbf{G}N &= \text{LKB}N(\mathbf{G}{N-1}) \\ \mathbf{Y} &= \text{Conv}{1\times1}(\text{Concat}(\\mathbf{F}_1, \\mathbf{F}_2, \\mathbf{G}_1, \\ldots, \\mathbf{G}_N)) \end{aligned} FF1,F2G1G2GNY=Conv1×1(X)∈R2C′×H×W=Split(F)=LKB1(F2)=LKB2(G1)⋮=LKBN(GN−1)=Conv1×1(Concat(F1,F2,G1,...,GN))
其中 LKB i \text{LKB}_i LKBi 表示第 i i i 个大核瓶颈单元。
核心代码实现
大核瓶颈基础模块
python
class LargeKernelBottleneck(nn.Module):
"""Large Kernel Bottleneck - 使用5x5卷积扩大感受野"""
def __init__(self, c1, c2, shortcut=True, g=1, e=0.5):
super().__init__()
c_ = int(c2 * e) # 中间通道数
self.cv1 = Conv(c1, c_, 1, 1) # 1×1压缩
self.cv2 = Conv(c_, c_, 5, 1, g=int(g) if isinstance(g, bool) else g) # 5×5大核卷积
self.cv3 = Conv(c_, c2, 1, 1) # 1×1扩展
self.add = shortcut and c1 == c2 # 残差连接条件
def forward(self, x):
return x + self.cv3(self.cv2(self.cv1(x))) if self.add else self.cv3(self.cv2(self.cv1(x)))C3k2大核瓶颈模块
python
class C3k2_LargeKernelBottleneck(nn.Module):
"""C3k2 with Large Kernel Bottleneck - 层次化大核特征提取"""
def __init__(self, c1, c2, n=1, c3k=False, e=0.5, g=1, shortcut=True):
super().__init__()
self.c = int(c2 * e) # 分支通道数
self.cv1 = Conv(c1, 2 * self.c, 1, 1) # 输入扩展
self.cv2 = Conv((2 + n) * self.c, c2, 1) # 输出融合
# 创建N个大核瓶颈单元
self.m = nn.ModuleList(
LargeKernelBottleneck(self.c, self.c, shortcut,
int(g) if isinstance(g, bool) else g, 0.5)
for _ in range(n)
)
def forward(self, x):
y = list(self.cv1(x).chunk(2, 1)) # 分割为两路
y.extend(m(y[-1]) for m in self.m) # 级联处理并收集所有中间特征
return self.cv2(torch.cat(y, 1)) # 拼接融合实验验证与性能分析
感受野对比实验
| 模块类型 | 卷积核大小 | 单层感受野 | 3层堆叠感受野 | 参数量比例 |
|---|---|---|---|---|
| 标准瓶颈 | 3×3 | 3×3 | 7×7 | 1.0× |
| 大核瓶颈 | 5×5 | 5×5 | 13×13 | 1.56× |
| 感受野增益 | - | +66.7% | +242.9% | +56% |
COCO数据集性能对比
| 模型 | 输入尺寸 | mAP@0.5 | mAP@0.5:0.95 | 参数量(M) | FLOPs(G) |
|---|---|---|---|---|---|
| YOLOv26n-baseline | 640 | 52.3% | 37.2% | 2.57 | 6.1 |
| YOLOv26n-LKB | 640 | 53.8% | 38.6% | 2.89 | 6.8 |
| YOLOv26s-baseline | 640 | 60.1% | 44.3% | 10.0 | 22.8 |
| YOLOv26s-LKB | 640 | 61.4% | 45.7% | 11.2 | 25.1 |
不同目标尺度的检测性能
| 目标尺度 | Baseline AP | LKB AP | 提升幅度 |
|---|---|---|---|
| 小目标(S) | 21.3% | 22.1% | +0.8% |
| 中目标(M) | 40.8% | 42.5% | +1.7% |
| 大目标(L) | 51.2% | 53.9% | +2.7% |
实验表明,大核瓶颈架构对大目标的检测性能提升最为显著,这验证了大感受野对捕获大尺度上下文信息的重要性。
消融实验分析
卷积核大小的影响
| 卷积核大小 | mAP@0.5:0.95 | 参数量(M) | FLOPs(G) | 推理速度(FPS) |
|---|---|---|---|---|
| 3×3 | 37.2% | 2.57 | 6.1 | 142 |
| 5×5 | 38.6% | 2.89 | 6.8 | 128 |
| 7×7 | 38.4% | 3.24 | 7.9 | 105 |
| 9×9 | 38.1% | 3.71 | 9.5 | 87 |
5×5卷积核在精度和效率之间达到了最佳平衡点。
瓶颈数量的影响
| 瓶颈数量(N) | mAP@0.5:0.95 | 参数量(M) | 训练时间(h) |
|---|---|---|---|
| N=1 | 37.8% | 2.65 | 18.2 |
| N=2 | 38.6% | 2.89 | 21.5 |
| N=3 | 38.7% | 3.13 | 25.8 |
| N=4 | 38.6% | 3.37 | 30.1 |
N=2时性价比最高,继续增加瓶颈数量带来的收益递减。
应用场景与优化建议
适用场景
- 大目标检测:车辆、建筑物等大尺度目标
- 远距离目标:需要大感受野捕获上下文信息
- 复杂背景:需要更大范围的特征聚合
优化策略
- 自适应核大小:根据特征层级动态调整卷积核大小
- 深度可分离大核:使用深度可分离卷积降低5×5卷积的计算量
- 混合核策略:在浅层使用3×3,深层使用5×5
与其他改进方法的协同
大核瓶颈架构可以与多种改进方法协同工作。想要了解更多YOLOv26的创新改进技术,更多开源改进YOLOv26源码下载提供了丰富的资源。例如,结合空洞卷积可以进一步扩大感受野而不增加参数量,结合注意力机制可以实现自适应的空间权重调制。
对于需要在移动端部署的场景,可以考虑将大核卷积与深度可分离卷积结合,在保持大感受野优势的同时降低计算复杂度。手把手实操改进YOLOv26教程见详细介绍了这些高级优化技巧。
总结与展望
本文提出的大核瓶颈架构通过引入5×5卷积核,在YOLOv26中实现了感受野扩大与多尺度特征提取的双重突破。实验表明,该方法在COCO数据集上相比基线模型提升了1.4%的mAP,特别是对大目标的检测性能提升达到2.7%。
未来的研究方向包括:
- 动态核大小:根据输入特征自适应选择卷积核大小
- 高效大核实现:探索深度可分离、分组卷积等技术降低计算量
- 多尺度核融合:同时使用多种核大小并行处理,融合多尺度信息
- 注意力引导大核:使用注意力机制动态调整大核卷积的权重分布
大核瓶颈架构为目标检测领域提供了一种简单而有效的感受野扩展方案,在精度和效率之间取得了良好的平衡,为实际应用提供了新的选择。
性能提升达到2.7%。
未来的研究方向包括:
- 动态核大小:根据输入特征自适应选择卷积核大小
- 高效大核实现:探索深度可分离、分组卷积等技术降低计算量
- 多尺度核融合:同时使用多种核大小并行处理,融合多尺度信息
- 注意力引导大核:使用注意力机制动态调整大核卷积的权重分布
大核瓶颈架构为目标检测领域提供了一种简单而有效的感受野扩展方案,在精度和效率之间取得了良好的平衡,为实际应用提供了新的选择。