Retrieval-Augmented Generation for Knowledge-Intensive NLP Tasks
基于检索增强的生成技术面向知识密集型自然语言处理任务

摘要
大规模预训练语言模型已被证实能够在其参数中存储事实性知识,并在微调下游自然语言处理任务时取得最先进的性能。然而,这些模型在访问和精确操控知识方面仍存在局限,因此在知识密集型任务上,其表现仍落后于针对特定任务设计的架构。此外,为其决策提供溯源依据以及更新其世界知识,仍是待解决的研究难题。虽已有研究提出通过可微分访问机制连接显式非参数化记忆的预训练模型来克服这一问题,但迄今为止相关探索仅局限于抽取式下游任务。本文研究了一种适用于检索增强生成模型的通用微调方法------该模型将预训练的参数化记忆与非参数化记忆相结合以实现语言生成。我们提出了RAG模型,其中参数化记忆部分采用预训练的序列到序列模型,非参数化记忆部分则是维基百科的稠密向量索引,通过预训练的神经检索器进行访问。我们比较了两种RAG架构:一种在整个生成序列中固定使用同一组检索段落,另一种允许每个标记生成时使用不同的检索段落。我们在多种知识密集型自然语言处理任务上对模型进行微调与评估,并在三个开放域问答任务上取得了最先进的成果,其表现超越了参数化序列到序列模型及针对特定任务设计的检索-抽取架构。在语言生成任务中,我们发现RAG模型比最先进的纯参数化序列到序列基线模型能够产生更具针对性、多样性和事实准确性的语言。
1.引言
预训练神经语言模型已被证明能从数据中学习大量深层次知识47。它们无需访问外部记忆即可实现这一点,其参数化的隐式知识库本身就具备这种能力51, 52。尽管这一进展令人振奋,但此类模型确实存在缺陷:难以扩展或修正其记忆,无法直观解释其预测依据,且可能产生"幻觉"38。结合参数化记忆与非参数化(即基于检索的)记忆的混合模型20, 26, 48能够部分解决这些问题,因为知识可以直接被修改和扩展,且被调用的知识可供检查与解释。REALM20与ORQA31作为近期提出的两个模型,将掩码语言模型8与可微分检索器相结合,已展现出显著效果。但以往研究仅探索了开放领域的抽取式问答。本文将为"自然语言处理的支柱"------序列到序列模型(seq2seq)引入参数化与非参数化记忆相混合的机制。
我们通过一种通用微调方法,为预训练的参数化记忆生成模型赋予非参数化记忆能力,该方法称为检索增强生成(RAG)。我们构建的RAG模型以预训练的序列到序列变换器作为参数化记忆,并以维基百科的稠密向量索引作为非参数化记忆,该索引通过预训练的神经检索器进行访问。我们将这些组件整合至一个端到端训练的概率模型中(见图1)。检索器(稠密段落检索器26,下文简称DPR)根据输入提供潜在文档,随后序列到序列模型(BART32)基于这些潜在文档及输入生成输出。我们通过Top-K近似对潜在文档进行边缘化处理,可按每条输出(假设同一文档负责所有词元)或按每个词元(不同文档负责不同词元)进行计算。与T551或BART类似,RAG可在任何序列到序列任务上进行微调,在此过程中生成器与检索器被联合学习。
已有大量先前研究提出通过非参数化内存增强系统架构的方案,这些架构需针对特定任务从头训练,例如记忆网络64, 55、堆栈增强网络25以及记忆层30。与之相反,我们探索了一种参数化与非参数化内存组件均已通过预训练、并预载海量知识的设置。关键在于,通过使用预训练的访问机制,系统无需额外训练即具备知识访问能力。
我们的研究结果凸显了将参数化与非参数化记忆与生成过程相结合在知识密集型任务中的优势------这类任务若不具备外部知识源,人类几乎无法完成。我们的RAG模型在开放版自然问答集29、网络问答集3和精选Trec数据集2上取得了领先水平的结果,并在TriviaQA24数据集上显著超越了近期采用专门预训练目标的方法。尽管这些任务本质为抽取式任务,我们发现无约束生成模型的表现优于以往的抽取式方法。在知识密集型生成任务中,我们在MS-MARCO1和Jeopardy问题生成数据集上进行了实验,结果表明相较于BART基线模型,我们的模型能生成更具事实准确性、更具体且更多样化的回答。对于FEVER56事实核查任务,我们的结果与当前采用强检索监督机制的流水线模型相比差距仅为4.3%。最后,我们证明可通过替换非参数化记忆模块来更新模型知识,从而适应动态变化的世界信息。
2.方法
我们研究了RAG(检索增强生成)模型,该模型利用输入序列x检索文本文档z,并将其作为生成目标序列y时的附加上下文。如图1所示,我们的模型利用两个组件:(i)一个参数为ηηη的检索器pη(z∣x)p_η(z|x)pη(z∣x),它根据查询x返回文本段落的(前K项截断)分布;(ii)一个参数为θ的生成器pθ(yi∣x,z,y1:i−1)p_θ(y_i|x, z, y_{1:i−1})pθ(yi∣x,z,y1:i−1)模型通过基于前i-1个词元y1:i−1y_{1:i-1}y1:i−1的上下文、原始输入x以及检索到的段落zzz来生成当前词元。
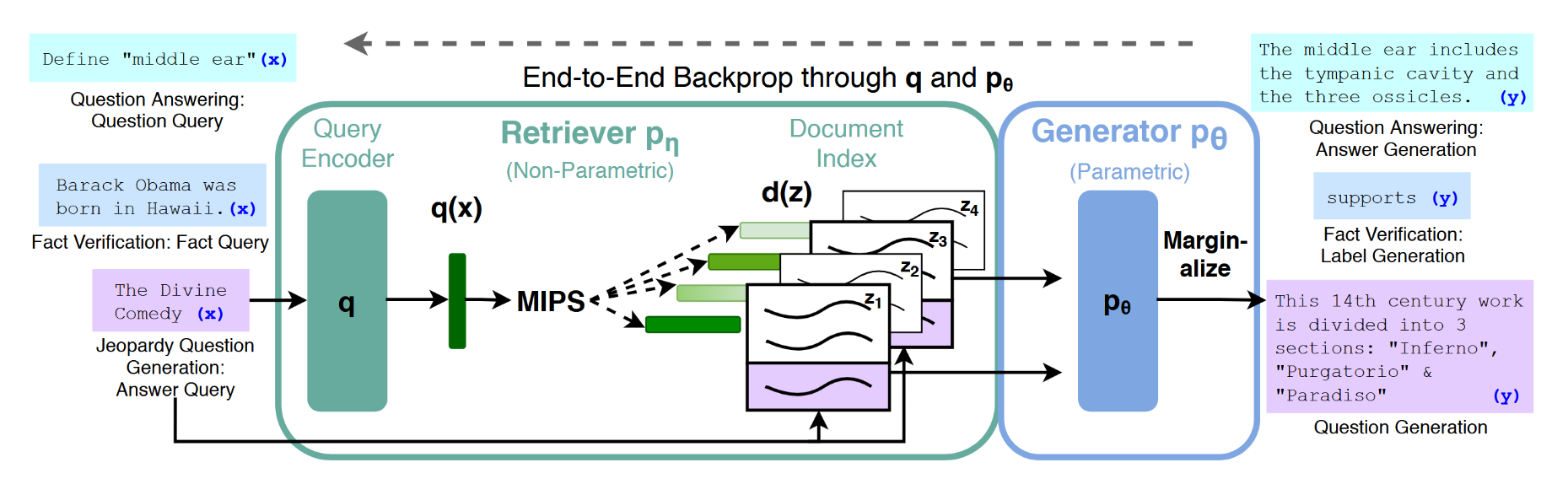
图1:方法概览。我们将预训练的检索器(查询编码器+文档索引)与预训练的序列到序列模型(生成器)相结合,并进行端到端的微调。对于查询x,我们使用最大内积搜索(MIPS)来查找前K个文档ziz_izi。对于最终预测y,我们将z视为潜在变量,并对基于不同文档的序列到序列预测结果进行边际化处理。
为端到端地训练检索器与生成器,我们将检索到的文档视为隐变量。我们提出了两种模型,通过不同方式对隐文档进行边缘化处理以生成文本分布。在第一种方法RAG-Sequence中,模型使用同一文档预测每个目标词元;第二种方法RAG-Token则允许基于不同文档预测每个目标词元。下文将正式介绍这两种模型,随后说明pηp_ηpη与pθp_θpθ组件,以及训练和解码流程。
2.1 模型
RAG序列模型
RAG-Sequence模型使用同一份检索文档来生成完整序列。从技术上讲,它将检索到的文档视为单一潜变量,通过Top-K近似进行边际化处理以获得seq2seq概率p(y∣x)p(y|x)p(y∣x)。具体而言,模型首先利用检索器获取前K篇文档,随后生成器针对每篇文档分别计算输出序列概率,最终对这些概率进行边际化整合。
pRAG-Sequence(y∣x)≈∑z∈top−k(p(⋅∣x))pη(z∣x)pθ(y∣x,z)=∑z∈top−k(p(⋅∣x))pη(z∣x)∏iNpθ(yi∣x,z,y1:i−1)\begin{aligned}p_\text{RAG-Sequence}(y|x)&\approx\sum_{z\in\mathrm{top-}k(p(\cdot|x))}p_\eta(z|x)p_\theta(y|x,z)&=\sum_{z\in\mathrm{top-}k(p(\cdot|x))}p_\eta(z|x)\prod_i^Np_\theta(y_i|x,z,y_{1:i-1})\end{aligned}pRAG-Sequence(y∣x)≈z∈top−k(p(⋅∣x))∑pη(z∣x)pθ(y∣x,z)=z∈top−k(p(⋅∣x))∑pη(z∣x)i∏Npθ(yi∣x,z,y1:i−1)
RAG-词元模型
在RAG-Token模型中,我们可以为每个目标标记抽取不同的潜在文档并进行相应边缘化处理。这使得生成器在生成答案时能够从多份文档中选择内容。具体而言,首先通过检索器获取前K份文档,接着生成器针对每份文档分别生成下一个输出标记的概率分布,经边缘化处理后,再对后续输出标记重复该过程。其形式化定义如下:
pRAG−Token(y∣x)≈∏iN∑z∈top−k(p(⋅∣x))pη(z∣x)pθ(yi∣x,zi,y1:i−1)\begin{aligned}p_{\mathrm{RAG-Token}}(y|x)&\approx\prod_i^N\sum_{z\in\mathrm{top-}k(p(\cdot|x))}p_\eta(z|x)p_\theta(y_i|x,z_i,y_{1:i-1})\end{aligned}pRAG−Token(y∣x)≈i∏Nz∈top−k(p(⋅∣x))∑pη(z∣x)pθ(yi∣x,zi,y1:i−1)
最后我们指出,通过将目标类别视为长度为1的目标序列,RAG可应用于序列分类任务,此时RAG-Sequence和RAG-Token是等价的。
2.2 检索器:密集段落检索器
检索组件pη(z∣x)p_η(z|x)pη(z∣x)基于DPR26。DPR采用双编码器架构:
pη(z∣x)∝exp(d(z)⊤q(x))d(z)=BERTd(z),q(x)=BERTq(x)\begin{aligned}p_\eta(z|x)&\propto\exp\left(\mathbf{d}(z)^\top\mathbf{q}(x)\right)&&\mathbf{d}(z)&=\mathbf{B}\mathrm{ERT}_d(z),&\mathbf{q}(x)&=\mathrm{BERT}_q(x)\end{aligned}pη(z∣x)∝exp(d(z)⊤q(x))d(z)=BERTd(z),q(x)=BERTq(x)
其中 d(z)d(z)d(z) 是由 BERTBASE 文档编码器 8 生成的文档稠密表示,q(x)q(x)q(x) 是由同样基于 BERTBASE 的查询编码器生成的查询表示。计算 top−k(pη(⋅∣x))top-k(p_η(·|x))top−k(pη(⋅∣x)),即获取先验概率 pη(z∣x)p_η(z|x)pη(z∣x) 最高的 k 个文档 z 的列表,是一个最大内积搜索问题,可以在亚线性时间内近似求解 23。我们使用 DPR 的预训练双编码器来初始化检索器并构建文档索引。该检索器经过训练,用于检索包含 TriviaQA 24 和 Natural Questions 29 问题答案的文档。我们将此文档索引称为非参数记忆。
2.3 生成器:BART
生成器组件 pθ(yi∣x,z,y1:i−1)p_θ(y_i|x, z, y_{1:i-1})pθ(yi∣x,z,y1:i−1) 可采用任何编码器-解码器架构进行建模。我们使用BART-large模型32,这是一个拥有4亿参数的预训练序列到序列变换器58。在使用BART生成时,为将输入x与检索内容z结合,我们仅对二者进行拼接。BART通过去噪目标函数及多种不同的噪声函数进行预训练,已在多种生成任务上取得了最先进的结果,并超越了规模相当的T5模型32。此后,我们将BART生成器的参数θθθ称为参数化记忆。
2.4 训练
我们联合训练检索器与生成器组件,过程中未对应当检索何种文档施加任何直接监督。给定包含输入/输出对 (xj,yj)(x_j, y_j)(xj,yj) 的微调训练语料库,我们通过带有Adam优化器28的随机梯度下降法,最小化每个目标的负边际对数似然 Σjlogp(yj∣xj)Σ_j log p(y_j | x_j)Σjlogp(yj∣xj)。在训练期间更新文档编码器BERTdBERT_dBERTd成本高昂,因为这需要像REALM在预训练阶段所做的那样20定期更新文档索引。我们发现这一步骤对于实现强劲性能并非必要,因此保持文档编码器(及其索引)固定,仅对查询编码器BERTqBERT_qBERTq和BART生成器进行微调。
2.5 解码
在测试阶段,RAG-Sequence和RAG-Token需要采用不同的方法来近似求解 argmaxyp(y∣x)arg max_y p(y|x)argmaxyp(y∣x)。
RAG-Token模型可被视为一个标准的自回归序列到序列生成器,其转移概率为:pθ′(yi∣x,y1:i−1)=∑z∈top−k(p(⋅∣x))pη(zi∣x)pθ(yi∣x,z,y1:i−1)p'θ(y_i|x, y{1:i-1}) = \sum_{z∈top-k(p(·|x))} p_η(z_i|x)p_θ(y_i|x, z, y_{1:i-1})pθ′(yi∣x,y1:i−1)=∑z∈top−k(p(⋅∣x))pη(zi∣x)pθ(yi∣x,z,y1:i−1)。为进行解码,我们可以将 pθ′(yi∣x,y1:i−1)p'θ(y_i|x, y{1:i-1})pθ′(yi∣x,y1:i−1) 代入标准束搜索解码器。
RAG序列模型
对于RAG序列模型,其似然函数p(y∣x)p(y|x)p(y∣x)无法分解为传统的逐标记似然形式,因此无法通过单次束搜索求解。我们改为对每个文档z独立执行束搜索,并利用pθ(yi∣x,y1:i−1)p_θ(y_i|x, y_{1:i-1})pθ(yi∣x,y1:i−1)对每个假设进行评分,从而生成假设集合Y。该集合中的部分假设可能未出现在所有文档的搜索束中。为估计某一假设y的概率,我们需要对未在束中出现该假设的每个文档z执行额外的前向计算,将生成器概率与pη(z∣x)p_η(z|x)pη(z∣x)相乘,最后跨文档束求和得到边缘概率。此解码流程称为"彻底解码"。
对于较长输出序列,|Y|可能变得很大,导致需要大量前向计算。为提高解码效率,我们可引入进一步近似:若假设y未在输入x和文档ziz_izi的束搜索中生成,则令pθ(y∣x,zi)⇡0p_θ(y|x, z_i) ⇡ 0pθ(y∣x,zi)⇡0。该近似避免了生成候选集Y后执行额外前向计算的需求。此解码流程称为"快速解码"。
3.实验
我们在多种知识密集型任务中对RAG进行了实验。所有实验均采用单一的维基百科数据转储作为非参数化知识源。遵循Lee等人31和Karpukhin等人26的方法,我们使用2018年12月的版本。每篇维基百科文章被分割为互不重叠的100词文本块,共计生成2100万份文档。我们使用文档编码器计算每份文档的嵌入向量,并借助FAISS23构建了单一的最大内积搜索索引,该索引采用分层可导航小世界近似方法37以实现快速检索。在训练过程中,我们为每个查询检索前k篇相关文档。训练阶段我们考虑k值在{5,10}\{5, 10\}{5,10}之间,并通过开发集数据确定测试阶段的k值。接下来将详细阐述每项任务的实验设置。
3.1 开放域问答
开放域问答是知识密集型任务的重要现实应用与常见测试平台20。我们将问题与答案视为输入-输出文本对(x, y),通过直接最小化答案的负对数似然来训练RAG模型。我们将RAG与流行的抽取式问答范式5,7,31,26进行比较,后者主要依赖非参数化知识,从检索文档中抽取答案片段。同时,我们也与"闭卷问答"方法52进行对比,该方法虽与RAG同属生成式问答,但完全依赖参数化知识而不利用检索机制。我们选用四个主流开放域问答数据集:自然问题集29、TriviaQA24、WebQuestions3以及CuratedTrec2。鉴于CT与WQ数据规模较小,我们遵循DPR26的方法,使用NQ训练的RAG模型初始化CT和WQ模型。采用与先前研究31,26相同的训练/验证/测试划分,并报告精确匹配得分。在TQA评估中,为与T552对比,我们同时在其维基测试集上进行了评测。
3.2 抽象性问答
RAG模型能够超越简单的抽取式问答,通过自由形式的抽象文本生成来回答问题。为了在知识密集型场景中测试RAG的自然语言生成能力,我们采用MSMARCO NLG任务v2.143。该任务包含问题、每个问题对应的十条通过搜索引擎检索的黄金段落,以及基于检索段落标注的完整句子答案。我们不使用提供的段落,仅使用问题和答案,从而将MSMARCO视为开放域抽象问答任务进行处理。MSMARCO中部分问题若不借助黄金段落则无法生成与参考答案匹配的回答,例如"加利福尼亚州火山的天气如何?",因此不使用黄金段落时性能会有所下降。我们还注意到,部分MSMARCO问题仅依靠维基百科无法解答。在这种情况下,RAG可以依赖其参数化知识生成合理的回应。
3.3 危局问题生成
为评估RAG在非问答场景下的生成能力,我们研究开放域问题生成。与采用标准开放域问答任务中通常简短的问题不同,我们提出了更具挑战性的任务------生成《危险边缘》式问题。该节目采用独特形式,要求根据关于某实体的线索猜测该实体。例如,"世界杯"是问题"1986年墨西哥成为首个两次主办这项国际体育赛事的国家"的答案。由于《危险边缘》问题均为精确的事实性陈述,以其答案实体为条件生成此类问题,构成了一个具有挑战性的知识密集型生成任务。
我们采用SearchQA10的数据划分方式,训练集10万例、开发集1.4万例、测试集2.7万例。由于这是一项新任务,我们训练了一个BART模型作为基线对比。参照67的方法,我们使用基于SQuAD调优的Q-BLEU-1指标42进行评估。Q-BLEU是BLEU的变体,对实体匹配赋予更高权重,在问题生成任务中比传统指标具有更高的人工评判相关性。我们还进行了两项人工评估:一项评估生成内容的事实性,另一项评估特异性。我们将事实性定义为陈述能否被可信外部来源佐证,特异性则定义为输入与输出间的高度相互依赖性33。遵循最佳实践,我们采用成对比较评估法34。评估人员会看到一个答案及两个生成问题(分别来自BART和RAG模型),随后从四个选项中选择其一:问题A更优、问题B更优、两者皆佳或两者均不佳。
3.4 事实核查
FEVER 56 任务要求判断一个自然语言陈述是否被维基百科支持或反驳,或是否存在信息不足而无法判定。该任务需要从维基百科中检索与陈述相关的证据,然后基于这些证据进行推理,以分类该陈述在仅依据维基百科的情况下是真实、虚假还是无法验证的。FEVER 是一个检索问题与一项具有挑战性的蕴含推理任务的结合。它也为探索 RAG 模型处理分类任务而非生成任务的能力提供了合适的测试平台。我们将 FEVER 的类别标签(支持、反驳或信息不足)映射为单一的输出令牌,并直接使用陈述-类别对进行训练。关键的是,与大多数其他处理 FEVER 的方法不同,我们不使用对检索证据的监督。在许多现实应用中,检索监督信号并不可用,而不需要此类监督的模型将适用于更广泛的任务。我们探索了两种变体:标准的三分类任务(支持/反驳/信息不足)以及 Thorne 和 Vlachos 57 中研究的二分类任务(支持/反驳)。在两种情况下,我们均报告标签准确率。
4.结论
4.1 开放域问答
表1展示了RAG与前沿模型的对比结果。在所有四项开放域问答任务中,RAG均取得了新的最优性能(仅在TQA的T5可比划分中表现如此)。RAG结合了"闭卷式"(仅参数化)方法的生成灵活性以及"开卷式"检索方法的性能优势。与REALM和T5+SSM不同,RAG无需昂贵且专用的"显著跨度掩码"预训练即可获得强劲结果20。值得注意的是,RAG的检索器通过DPR检索器初始化,后者使用了Natural Questions和TriviaQA数据集的检索监督进行训练。与采用基于BERT的"交叉编码器"进行文档重排序并搭配抽取式阅读器的DPR问答系统相比,RAG表现出明显优势。RAG证明,要实现最优性能,既不需要重排序模块,也不需要抽取式阅读器。
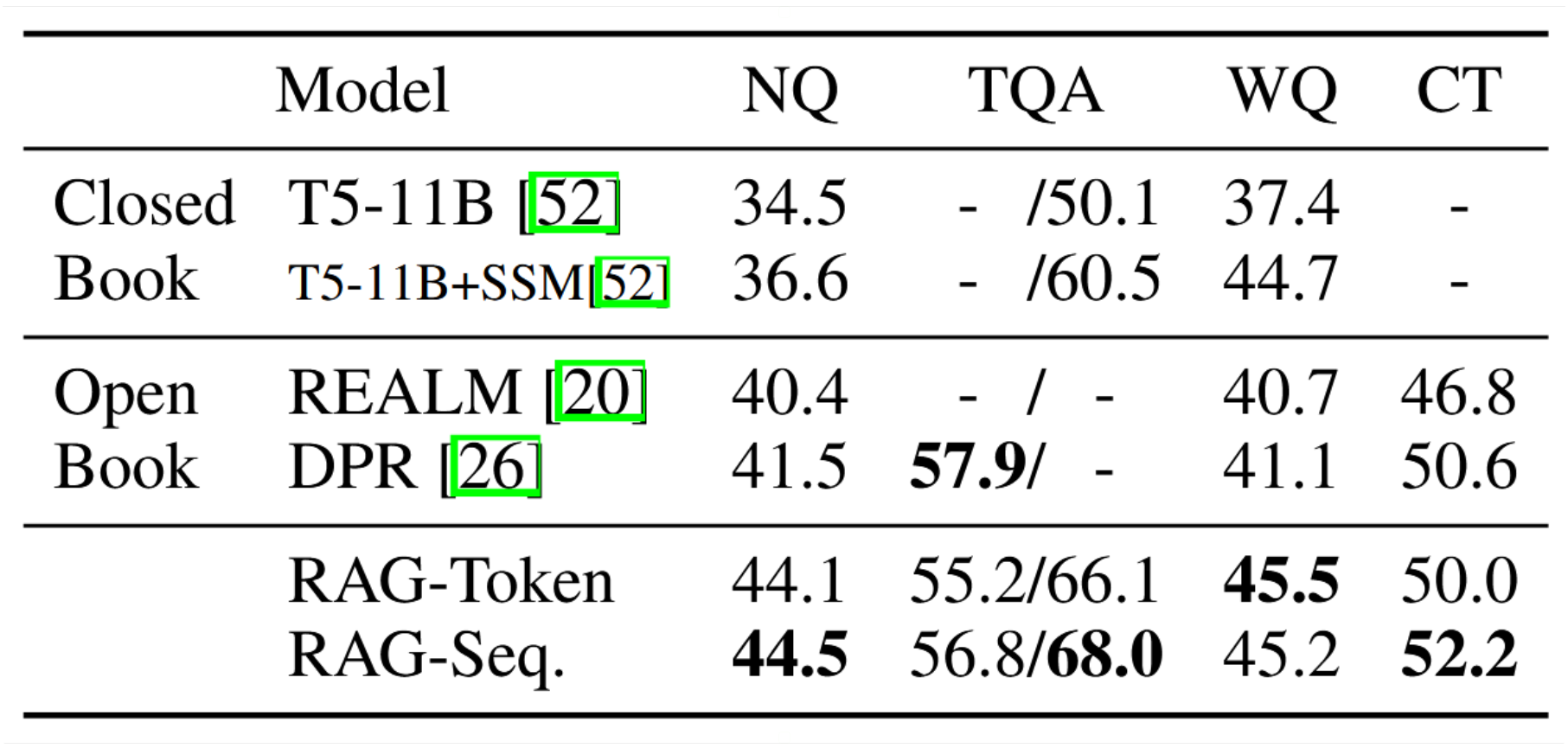
表1:开放域问答测试得分。关于TQA数据,左栏使用标准开放域问答测试集,右栏使用TQA-Wiki测试集。详见附录D。
即便可以提取答案,生成答案仍有若干优势。即使文档仅包含答案线索而非逐字对应的答案,仍能为生成正确答案提供支持,这是标准抽取式方法无法实现的。通过更有效的文档边缘化处理。此外,即使正确答案未出现在任何检索到的文档中,RAG仍能生成正确答案,在NQ数据集上此类情况达到了11.8%的准确率,而抽取式模型在此类情况下的准确率为0%。
4.2 抽象式问答
如表2所示,在Open MS-MARCO NLG任务上,RAG-Sequence模型在Bleu分数和Rouge-L分数上均领先BART模型2.6分。RAG方法达到了与最先进模型相当的性能,这一结果令人印象深刻,因为:(i)那些最先进模型在生成参考答案时可以访问包含特定信息的黄金段落,(ii)许多问题在没有黄金段落的情况下无法回答,且(iii)并非所有问题都能仅从维基百科中获取答案。表3展示了我们模型生成的一些答案。从质量上看,我们发现RAG模型比BART模型产生的幻觉更少,生成的文本在事实上更准确。后文我们还将表明,RAG生成的文本比BART生成的文本具有更高的多样性(参见第4.5节)。
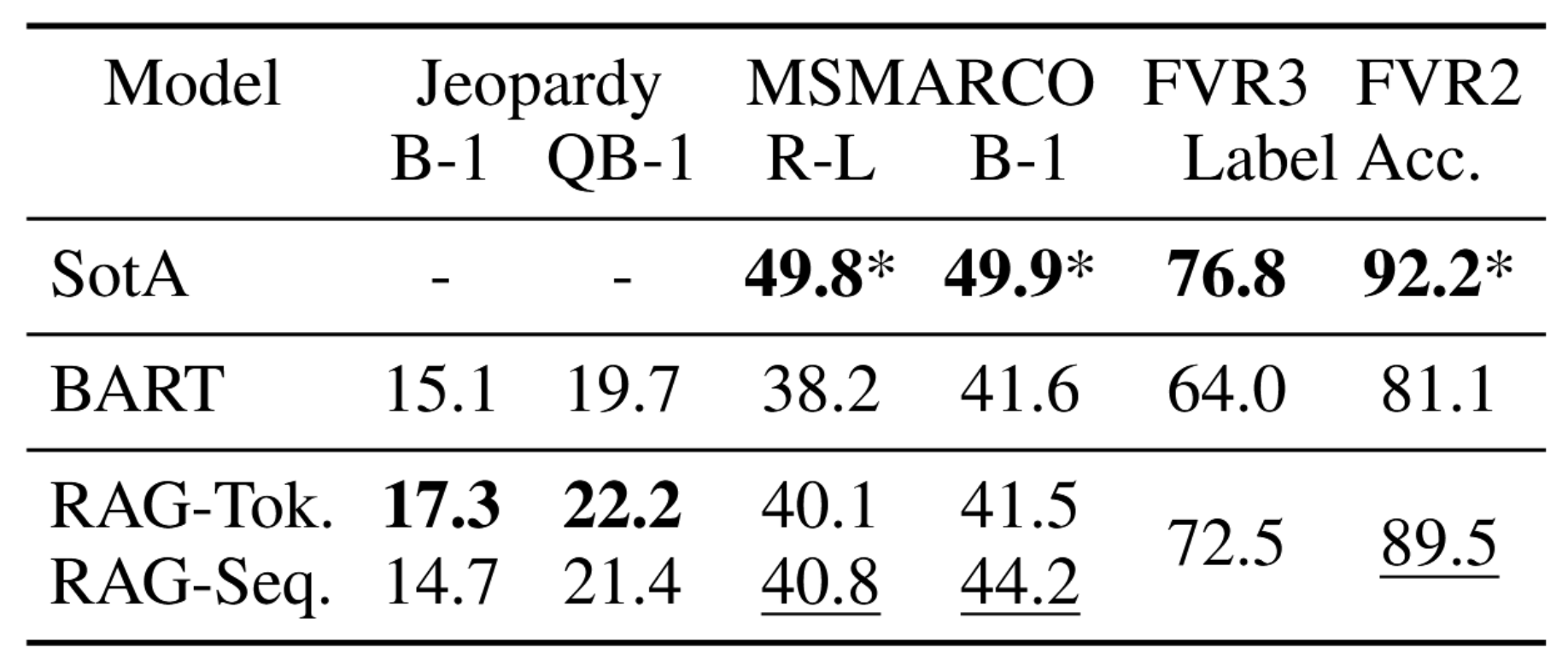
表2:生成与分类测试分数。MS-MARCO SotA为4,FEVER-3为68,FEVER-2为57 *使用黄金上下文/证据。最佳非黄金访问模型已用下划线标出。
4.3 危机问答生成
表2显示,在Jeopardy问答生成任务中,RAG-Token模型表现优于RAG-Sequence模型,且两种模型在Q-BLEU-1指标上均超越BART模型。表4展示了基于BART与RAG-Token模型生成的452对文本的人类评估结果。评估者指出,仅在7.1%的情况下BART比RAG更具事实准确性,而在42.7%的情况下RAG更具事实准确性,另有17%的情况下两者均具事实准确性,这清晰证明了RAG在此任务上优于先进的生成模型。评估者还发现RAG生成的文本在特异性方面显著更优。表3展示了各模型的典型生成样例。

表3:生成任务示例。RAG模型生成的回答更具体且事实准确性更高。"?"表示事实错误的回答,*表示部分正确的回答。
"危险边缘"类问答通常包含两条独立信息,此时RAG-Token模型可能表现最佳,因其能融合多篇文档内容生成回答。图2展示了一个示例:当生成"太阳"时,提及《太阳照常升起》的文档2后验概率显著升高;而生成《永别了,武器》时文档1主导后验分布。有趣的是,当每本书名的首个词符生成后,文档后验分布趋于平缓。这表明生成器无需依赖特定文档即可补全书名,即模型的参数化知识足以完成标题补全。我们通过BART纯基线模型的实验验证该假设:输入部分解码序列"The Sun"时,BART会补全为"《太阳照常升起》是该书作者的作品",表明该标题已存储于BART参数中。类似地,输入"《太阳照常升起》是该书作者的作品《A"时,BART将补全为"《太阳照常升起》是该书作者的作品《永别了,武器》"。此例揭示了参数化与非参数化记忆的协同机制------非参数化组件引导生成过程,从而激活参数化记忆中存储的特定知识。

图2:输入"海明威"时,采用5篇检索文档进行Jeopardy生成的每个输出标记的RAG-Token文档后验概率p(zi∣x,yi,y−i)p(z_i|x, y_i, y_{-i})p(zi∣x,yi,y−i)。生成《永别了,武器》时文档1的后验概率较高,生成《太阳照常升起》时文档2的后验概率较高。
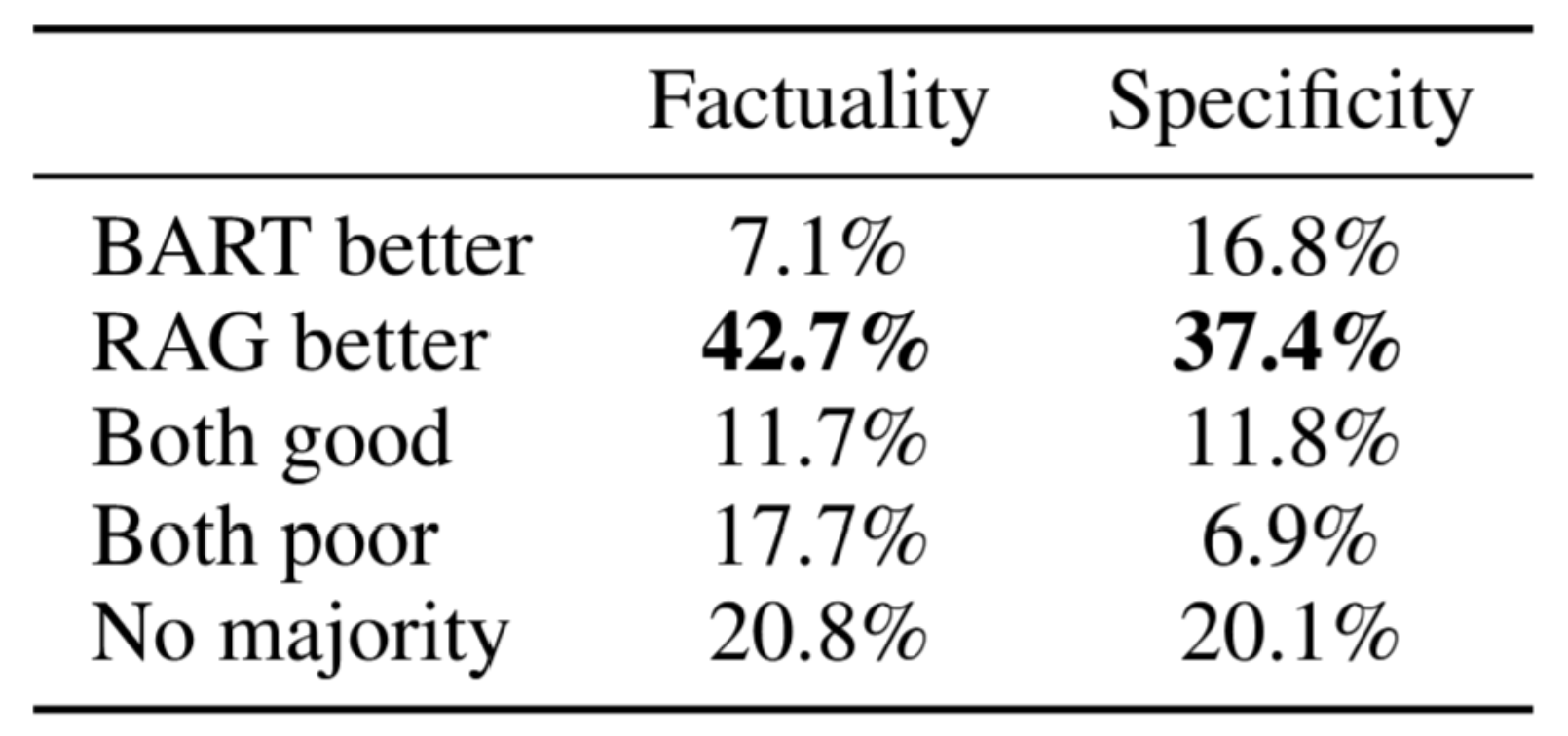
表4:针对《危险边缘》问题生成任务的人工评估结果。
4.4 事实核查
表2展示了我们在FEVER数据集上的实验结果。对于三分类任务,RAG模型的性能与最先进模型的差距在4.3%以内,而这些先进模型是具备特定领域架构、经过大量工程实现的复杂流水线系统,且需要使用中间检索监督进行训练,而RAG则无需此类监督。
在二分类任务中,我们与Thorne和Vlachos57的研究进行对比,他们的方法是基于给定的标准证据句子,训练RoBERTa35模型将主张分类为真实或虚假。尽管RAG模型仅接收主张文本并自行检索证据,但其准确率与该模型的差距在2.7%以内。我们还分析了RAG检索到的文档是否与FEVER数据集中标注的标准证据文档一致。我们计算了RAG检索的前k个文档与标准证据标注之间在文章标题上的重叠率。研究发现,在71%的情况下,被检索出的首篇文档来源于标准文章;而在90%的情况下,标准文章会出现在检索结果的前10篇文章中。
4.5 附加结果
生成多样性
第4.3节表明,在《危险边缘》问题生成任务中,RAG模型比BART模型更具事实准确性和具体性。借鉴近期关于促进解码多样性的研究33, 59, 39,我们还通过计算不同模型生成文本中独特n-gram与总n-gram的比例来考察生成多样性。表5显示,RAG-Sequence的生成结果比RAG-Token更多样,且两者在无需任何多样性促进解码技术的情况下,其多样性均显著高于BART模型。
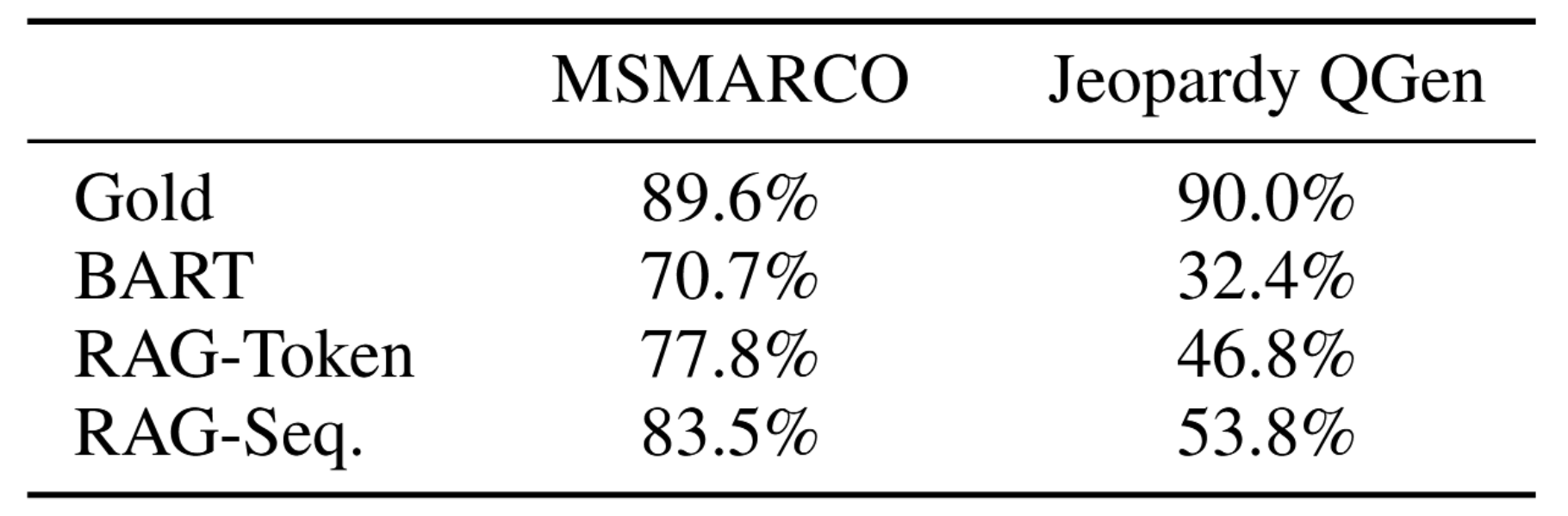
表5:生成任务中不同三元组与总三元组之比。
检索消融实验
RAG的关键特性在于学习为任务检索相关信息。为评估检索机制的有效性,我们在训练期间冻结检索器进行消融实验。如表6所示,学习式检索在所有任务上均提升了结果。我们将RAG的密集检索器与基于词重叠的BM25检索器53进行对比:在此设置中,我们用固定的BM25系统替换RAG的检索器,并在计算p(z∣x)p(z|x)p(z∣x)时使用BM25检索分数作为逻辑值。表6展示了结果。对于FEVER任务,BM25表现最佳,这可能是因为FEVER声明高度以实体为中心,因此非常适合基于词重叠的检索。而可微分检索在所有其他任务上改进了结果,尤其在开放域问答任务中效果提升显著,这在该任务中至关重要。
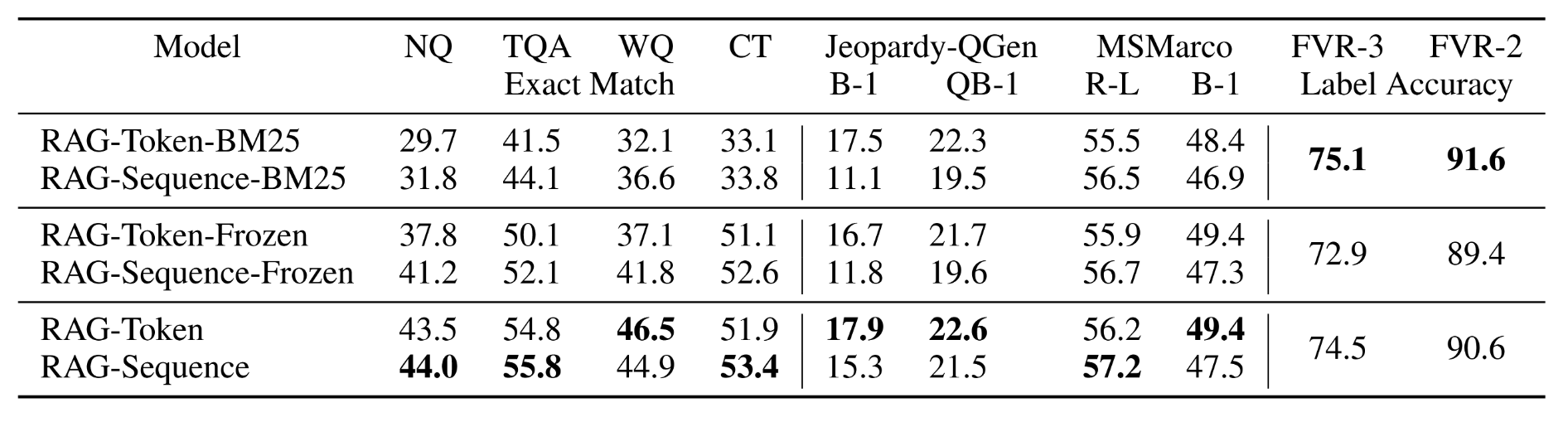
表6:开发集消融实验结果。由于FEVER属于分类任务,两种RAG模型效果等同。
索引热交换
非参数化记忆模型(如RAG)的优势在于,测试期间可轻松更新知识。而纯参数化模型(如T5或BART)需要随着世界变化进行额外训练才能更新其行为。为验证这一点,我们使用2016年12月的DrQA5维基百科数据构建索引,并将基于此索引的RAG输出与我们主要结果中较新的索引(2018年12月)进行比较。我们整理了在这两个日期之间发生变动的82位世界领导人名单,并采用"{职位}是谁?"的提问模板(例如"秘鲁总统是谁?")。
检索更多文档的影响
模型训练时使用5篇或10篇检索到的潜在文档,我们未观察到两者在性能上存在显著差异。在测试阶段,我们可灵活调整检索文档的数量,这会影响模型性能与运行时间。图3(左)显示,对于RAG-Sequence模型,测试时检索更多文档能持续提升开放域问答效果;而RAG-Token模型的性能在检索10篇文档时达到峰值。图3(右)表明,增加检索文档数量会提升RAG-Token模型的Rouge-L分数,但会降低Bleu-1分数,而这一趋势在RAG-Sequence模型中较不明显。
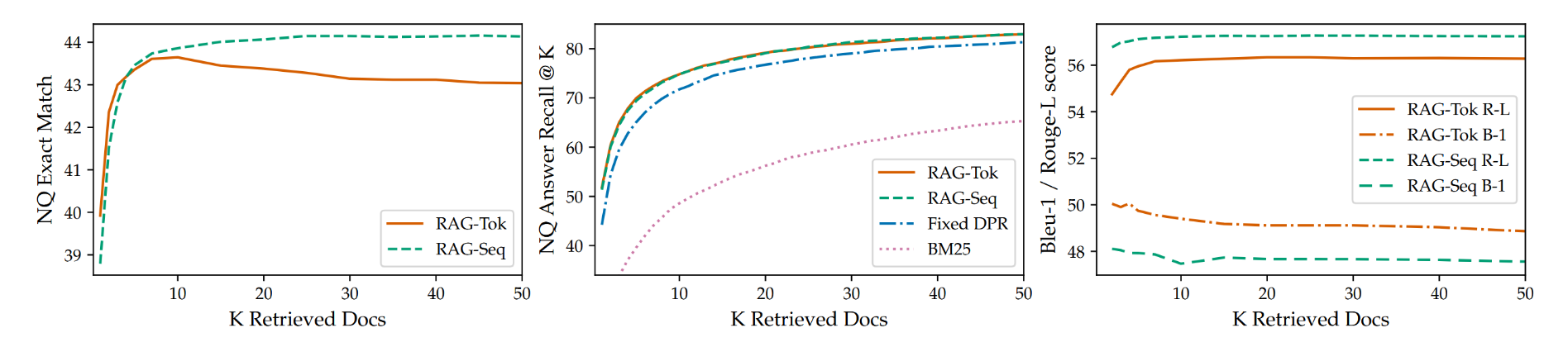
图3:左侧:随检索文档数量增加的NQ性能表现。居中:NQ中的检索召回性能表现。右侧:随检索文档数量增加的MS-MARCO Bleu-1与Rouge-L分数。
5.相关工作
单任务检索
先前研究已表明,当单独考量时,检索机制能在多种自然语言处理任务中提升性能。此类任务包括开放域问答[5, 29]、事实核查[56]、事实补全[48]、长形式问答[12]、维基百科文章生成[36]、对话系统[41, 65, 9, 13]、机器翻译[17]以及语言建模[19, 27]。我们的工作统一了以往将检索融入单一任务的成功经验,证明基于检索的单一架构能够在多项任务中实现强劲性能。
自然语言处理的通用架构
先前关于通用自然语言处理架构的研究表明,在不使用检索机制的情况下已取得显著成功。研究表明,经过微调后,单个预训练语言模型能够在GLUE基准测试中的多种分类任务上实现强劲性能60, 6149, 8。随后GPT-250证明了单个从左到右的预训练语言模型可在判别性与生成性任务中均取得优异表现。为进一步提升性能,BART32与T551, 52提出了采用双向注意力机制的单一预训练编码器-解码器模型,在判别性与生成性任务上实现了更强性能。本研究旨在通过训练检索模块来增强预训练生成语言模型,从而以单一统一架构拓展潜在任务的应用空间。
习得检索
在信息检索领域,学习检索文档已有大量研究,近期工作多采用与我们相似的预训练神经语言模型44, 26。部分研究通过检索优化模块来辅助特定下游任务(如问答),其方法包括使用搜索46、强化学习6, 63, 62或与我们工作类似的隐变量方法31, 20。这些成功案例借助不同的检索架构与优化技术,在单一任务上实现了优异性能;而我们的研究表明,单一的检索架构可通过微调在多种任务上均取得强劲表现。
基于记忆的架构
我们的文档索引可被视为供神经网络关注的大型外部记忆库,其机制类似于记忆网络64, 55。同期研究14学习检索输入中每个实体的训练后嵌入表示,而非如本研究直接检索原始文本。其他研究通过关注事实嵌入向量9, 13来提升对话模型生成事实性文本的能力,更有与本研究思路相近者直接对检索文本进行关注15。我们记忆机制的核心特征在于其由原始文本构成,而非分布式表示,这使其具备双重优势:(一) 具备人类可读性,为模型提供了一种可解释形式;(二) 具备人类可写性,允许我们通过编辑文档索引实现模型记忆的动态更新。
检索-编辑方法
我们的方法在某种程度上与检索-编辑式方法具有相似性,后者会为给定输入检索一个相似的训练输入-输出对,然后通过编辑生成最终输出。这类方法已在机器翻译18, 22和语义解析21等多个领域被证明是成功的。但我们的方法也存在若干不同之处:我们并不强调对单个检索项进行轻微编辑,而是注重聚合多个检索内容的信息,同时学习潜在检索机制,并且检索的是证据文档而非相关的训练对。尽管如此,检索增强生成技术在这些场景中可能仍表现良好,有望成为未来有价值的研究方向。
6.讨论
在本研究中,我们提出了能够访问参数化与非参数化记忆的混合生成模型。实验表明,我们的RAG模
,展现了其在多种自然语言处理任务中广泛应用的潜力。
相较于先前的研究,本工作提供了若干积极的社会效益:其更牢固地根植于真实事实性知识(此处以维基百科为例),使得生成结果的"幻觉"更少、事实性更强,并提供了更强的可控性与可解释性。检索增强生成技术可应用于多种直接惠及社会的场景,例如通过为其配备医学知识库并在此领域进行开放域问答,或帮助人们提升工作效率。
然而,这些优势也伴随着潜在风险:维基百科或任何外部知识源,可能永远无法达到完全客观且毫无偏见。由于检索增强生成技术可作为语言模型使用,尽管程度可能较轻,但仍需关注类似GPT-250所面临的问题,包括可能被用于生成新闻或社交媒体上的滥用内容、虚假或误导性信息;冒用他人身份;或自动化生产垃圾邮件/钓鱼内容54。未来数十年间,先进语言模型也可能导致多种工作岗位的自动化16。为缓解这些风险,可采用人工智能系统来对抗误导性内容及自动化垃圾邮件/钓鱼行为。
6.引用文献
- 1 Payal Bajaj, Daniel Campos, Nick Craswell, Li Deng, Jianfeng Gao, Xiaodong Liu, Rangan Majumder, Andrew McNamara, Bhaskar Mitra, Tri Nguyen, Mir Rosenberg, Xia Song, Alina Stoica, Saurabh Tiwary, and Tong Wang. MS MARCO: A Human Generated MAchine Reading COmprehension Dataset. arXiv:1611.09268 cs, November 2016. URL http: //arxiv.org/abs/1611.09268. arXiv: 1611.09268.
- 2 Petr Baudiš and Jan Šedivy. Modeling of the question answering task in the yodaqa system. In International Conference of the Cross-Language Evaluation Forum for European Languages, pages 222--228. Springer, 2015. URL https://link.springer.com/chapter/10.1007% 2F978-3-319-24027-5_20.
- 3 Jonathan Berant, Andrew Chou, Roy Frostig, and Percy Liang. Semantic Parsing on Freebase from Question-Answer Pairs. In Proceedings of the 2013 Conference on Empirical Methods in Natural Language Processing, pages 1533--1544, Seattle, Washington, USA, October 2013. Association for Computational Linguistics. URL http://www.aclweb.org/anthology/ D13-1160.
- 4 Bin Bi, Chenliang Li, Chen Wu, Ming Yan, and Wei Wang. Palm: Pre-training an autoencoding&autoregressive language model for context-conditioned generation. ArXiv, abs/2004.07159, 2020. URL https://arxiv.org/abs/2004.07159.
- 5 Danqi Chen, Adam Fisch, Jason Weston, and Antoine Bordes. Reading Wikipedia to Answer Open-Domain Questions. In Proceedings of the 55th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 1870--1879, Vancouver, Canada, July 2017. Association for Computational Linguistics. doi: 10.18653/v1/P17-1171. URL https://www.aclweb.org/anthology/P17-1171.
- 6 Eunsol Choi, Daniel Hewlett, Jakob Uszkoreit, Illia Polosukhin, Alexandre Lacoste, and Jonathan Berant. Coarse-to-fine question answering for long documents. In Proceedings of the 55th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 209--220, Vancouver, Canada, July 2017. Association for Computational Linguistics. doi: 10.18653/v1/P17-1020. URL https://www.aclweb.org/anthology/P17-1020.
- 7 Christopher Clark and Matt Gardner. Simple and Effective Multi-Paragraph Reading Comprehension. arXiv:1710.10723 cs, October 2017. URL http://arxiv.org/abs/1710.10723. arXiv: 1710.10723.
- 8 Jacob Devlin, Ming-Wei Chang, Kenton Lee, and Kristina Toutanova. BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding. In Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pages 4171--4186, Minneapolis, Minnesota, June 2019. Association for Computational Linguistics. doi: 10.18653/v1/N19-1423. URL https://www.aclweb.org/anthology/N19-1423.
- 9 Emily Dinan, Stephen Roller, Kurt Shuster, Angela Fan, Michael Auli, and Jason Weston. Wizard of wikipedia: Knowledge-powered conversational agents. In International Conference on Learning Representations, 2019. URL https://openreview.net/forum?id=r1l73iRqKm.
- 10 Matthew Dunn, Levent Sagun, Mike Higgins, V. Ugur Guney, Volkan Cirik, and Kyunghyun Cho. SearchQA: A New Q&A Dataset Augmented with Context from a Search Engine. arXiv:1704.05179 cs, April 2017. URL http://arxiv.org/abs/1704.05179. arXiv: 1704.05179.
- 11 Angela Fan, Mike Lewis, and Yann Dauphin. Hierarchical neural story generation. In Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 889--898, Melbourne, Australia, July 2018. Association for Computational Linguistics. doi: 10.18653/v1/P18-1082. URL https://www.aclweb.org/anthology/ P18-1082.
- 12 Angela Fan, Yacine Jernite, Ethan Perez, David Grangier, Jason Weston, and Michael Auli. ELI5: Long form question answering. In Proceedings of the 57th Annual Meeting of the Association for Computational Linguistics, pages 3558--3567, Florence, Italy, July 2019. Association for Computational Linguistics. doi: 10.18653/v1/P19-1346. URL https://www.aclweb.org/ anthology/P19-1346.
- 13 Angela Fan, Claire Gardent, Chloe Braud, and Antoine Bordes. Augmenting transformers with KNN-based composite memory, 2020. URL https://openreview.net/forum?id= H1gx1CNKPH.
- 14 Thibault Févry, Livio Baldini Soares, Nicholas FitzGerald, Eunsol Choi, and Tom Kwiatkowski. Entities as experts: Sparse memory access with entity supervision. ArXiv, abs/2004.07202, 2020. URL https://arxiv.org/abs/2004.07202.
- 15 Marjan Ghazvininejad, Chris Brockett, Ming-Wei Chang, Bill Dolan, Jianfeng Gao, Wen tau Yih, and Michel Galley. A knowledge-grounded neural conversation model. In AAAI Conference on Artificial Intelligence, 2018. URL https://www.aaai.org/ocs/index.php/ AAAI/AAAI18/paper/view/16710.
- 16 Katja Grace, John Salvatier, Allan Dafoe, Baobao Zhang, and Owain Evans. When will AI exceed human performance? evidence from AI experts. CoRR, abs/1705.08807, 2017. URL http://arxiv.org/abs/1705.08807.
- 17 Jiatao Gu, Yong Wang, Kyunghyun Cho, and Victor O.K. Li. Search engine guided neural machine translation. In AAAI Conference on Artificial Intelligence, 2018. URL https: //www.aaai.org/ocs/index.php/AAAI/AAAI18/paper/view/17282.
- 18 Jiatao Gu, Yong Wang, Kyunghyun Cho, and Victor O.K. Li. Search engine guided neural machine translation. In 32nd AAAI Conference on Artificial Intelligence, AAAI 2018, 32nd AAAI Conference on Artificial Intelligence, AAAI 2018, pages 5133--5140. AAAI press, 2018. 32nd AAAI Conference on Artificial Intelligence, AAAI 2018 ; Conference date: 02-02-2018 Through 07-02-2018.
- 19 Kelvin Guu, Tatsunori B. Hashimoto, Yonatan Oren, and Percy Liang. Generating sentences by editing prototypes. Transactions of the Association for Computational Linguistics, 6:437--450, 2018. doi: 10.1162/tacl_a_00030. URL https://www.aclweb.org/anthology/Q18-1031.
- 20 Kelvin Guu, Kenton Lee, Zora Tung, Panupong Pasupat, and Ming-Wei Chang. REALM: Retrieval-augmented language model pre-training. ArXiv, abs/2002.08909, 2020. URL https: //arxiv.org/abs/2002.08909.
- 21 Tatsunori B Hashimoto, Kelvin Guu, Yonatan Oren, and Percy S Liang. A retrieve-and-edit framework for predicting structured outputs. In S. Bengio, H. Wallach, H. Larochelle, K. Grauman, N. Cesa-Bianchi, and R. Garnett, editors, Advances in Neural Information Processing Systems 31, pages 1005210062. Curran Associates, Inc., 2018. URL http://papers.nips.cc/paper/ 8209-a-retrieve-and-edit-framework-for-predicting-structured-outputs. pdf.
- 22 Nabil Hossain, Marjan Ghazvininejad, and Luke Zettlemoyer. Simple and effective retrieveedit-rerank text generation. In Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics, pages 2532--2538, Online, July 2020. Association for Computational Linguistics. doi: 10.18653/v1/2020.acl-main.228. URL https://www.aclweb.org/ anthology/2020.acl-main.228.
- 23 Jeff Johnson, Matthijs Douze, and Hervé Jégou. Billion-scale similarity search with gpus. arXiv preprint arXiv:1702.08734, 2017. URL https://arxiv.org/abs/1702.08734.
- 24 Mandar Joshi, Eunsol Choi, Daniel Weld, and Luke Zettlemoyer. TriviaQA: A Large Scale Distantly Supervised Challenge Dataset for Reading Comprehension. In Proceedings of the 55th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 1601--1611, Vancouver, Canada, July 2017. Association for Computational Linguistics. doi: 10.18653/v1/P17-1147. URL https://www.aclweb.org/anthology/P17-1147.
- 25 Armand Joulin and Tomas Mikolov. Inferring algorithmic patterns with stackaugmented recurrent nets. In Proceedings of the 28th International Conference on Neural Information Processing Systems - Volume 1, NIPS'15, page 190--198, Cambridge, MA, USA, 2015. MIT Press. URL https://papers.nips.cc/paper/ 5857-inferring-algorithmic-patterns-with-stack-augmented-recurrent-nets.
- 26 Vladimir Karpukhin, Barlas Oguz, Sewon Min, Ledell Wu, Sergey Edunov, Danqi Chen, and Wen-tau Yih. Dense passage retrieval for open-domain question answering. arXiv preprint arXiv:2004.04906, 2020. URL https://arxiv.org/abs/2004.04906.
- 27 Urvashi Khandelwal, Omer Levy, Dan Jurafsky, Luke Zettlemoyer, and Mike Lewis. Generalization through memorization: Nearest neighbor language models. In International Conference on Learning Representations, 2020. URL https://openreview.net/forum?id=HklBjCEKvH.
- 28 Diederik P. Kingma and Jimmy Ba. Adam: A method for stochastic optimization. In Yoshua Bengio and Yann LeCun, editors, 3rd International Conference on Learning Representations, ICLR 2015, San Diego, CA, USA, May 7-9, 2015, Conference Track Proceedings, 2015. URL http://arxiv.org/abs/1412.6980.
- 29 Tom Kwiatkowski, Jennimaria Palomaki, Olivia Redfield, Michael Collins, Ankur Parikh, Chris Alberti, Danielle Epstein, Illia Polosukhin, Matthew Kelcey, Jacob Devlin, Kenton Lee, Kristina N. Toutanova, Llion Jones, Ming-Wei Chang, Andrew Dai, Jakob Uszkoreit, Quoc Le, and Slav Petrov. Natural Questions: a Benchmark for Question Answering Research. Transactions of the Association of Computational Linguistics, 2019. URL https://tomkwiat.users.x20web.corp.google.com/papers/ natural-questions/main-1455-kwiatkowski.pdf.
- 30 Guillaume Lample, Alexandre Sablayrolles, Marc' Aurelio Ranzato, Ludovic Denoyer, and Herve Jegou. Large memory layers with product keys. In H. Wallach, H. Larochelle, A. Beygelzimer, F. d' Alché-Buc, E. Fox, and R. Garnett, editors, Advances in Neural Information Processing Systems 32, pages 8548--8559. Curran Associates, Inc., 2019. URL http: //papers.nips.cc/paper/9061-large-memory-layers-with-product-keys.pdf.
- 31 Kenton Lee, Ming-Wei Chang, and Kristina Toutanova. Latent retrieval for weakly supervised open domain question answering. In Proceedings of the 57th Annual Meeting of the Association for Computational Linguistics, pages 6086--6096, Florence, Italy, July 2019. Association for Computational Linguistics. doi: 10.18653/v1/P19-1612. URL https://www.aclweb.org/ anthology/P19-1612.
- 32 Mike Lewis, Yinhan Liu, Naman Goyal, Marjan Ghazvininejad, Abdelrahman Mohamed, Omer Levy, Veselin Stoyanov, and Luke Zettlemoyer. BART: Denoising sequence-to-sequence pre-training for natural language generation, translation, and comprehension. arXiv preprint arXiv:1910.13461, 2019. URL https://arxiv.org/abs/1910.13461.
- 33 Jiwei Li, Michel Galley, Chris Brockett, Jianfeng Gao, and Bill Dolan. A diversity-promoting objective function for neural conversation models. In Proceedings of the 2016 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, pages 110--119, San Diego, California, June 2016. Association for Computational Linguistics. doi: 10.18653/v1/N16-1014. URL https://www.aclweb.org/anthology/ N16-1014.
- 34 Margaret Li, Jason Weston, and Stephen Roller. Acute-eval: Improved dialogue evaluation with optimized questions and multi-turn comparisons. ArXiv, abs/1909.03087, 2019. URL https://arxiv.org/abs/1909.03087.
- 35 Hairong Liu, Mingbo Ma, Liang Huang, Hao Xiong, and Zhongjun He. Robust neural machine translation with joint textual and phonetic embedding. In Proceedings of the 57th Annual Meeting of the Association for Computational Linguistics, pages 3044--3049, Florence, Italy, July 2019. Association for Computational Linguistics. doi: 10.18653/v1/P19-1291. URL https://www.aclweb.org/anthology/P19-1291.
- 36 Peter J. Liu*, Mohammad Saleh*, Etienne Pot, Ben Goodrich, Ryan Sepassi, Lukasz Kaiser, and Noam Shazeer. Generating wikipedia by summarizing long sequences. In International Conference on Learning Representations, 2018. URL https://openreview.net/forum? id=Hyg0vbWC-.
- 37 Yury A. Malkov and D. A. Yashunin. Efficient and robust approximate nearest neighbor search using hierarchical navigable small world graphs. IEEE Transactions on Pattern Analysis and Machine Intelligence, 42:824--836, 2016. URL https://arxiv.org/abs/1603.09320. 38 Gary Marcus. The next decade in ai: four steps towards robust artificial intelligence. arXiv preprint arXiv:2002.06177, 2020. URL https://arxiv.org/abs/2002.06177. 39 Luca Massarelli, Fabio Petroni, Aleksandra Piktus, Myle Ott, Tim Rocktäschel, Vassilis Plachouras, Fabrizio Silvestri, and Sebastian Riedel. How decoding strategies affect the verifiability of generated text. arXiv preprint arXiv:1911.03587, 2019. URL https: //arxiv.org/abs/1911.03587.
- 40 Paulius Micikevicius, Sharan Narang, Jonah Alben, Gregory Diamos, Erich Elsen, David Garcia, Boris Ginsburg, Michael Houston, Oleksii Kuchaiev, Ganesh Venkatesh, and Hao Wu. Mixed precision training. In ICLR, 2018. URL https://openreview.net/forum?id=r1gs9JgRZ.
- 41 Nikita Moghe, Siddhartha Arora, Suman Banerjee, and Mitesh M. Khapra. Towards exploiting background knowledge for building conversation systems. In Proceedings of the 2018 Conference on Empirical Methods in Natural Language Processing, pages 2322--2332, Brussels, Belgium, October-November 2018. Association for Computational Linguistics. doi: 10.18653/v1/D18-1255. URL https://www.aclweb.org/anthology/D18-1255.
- 42 Preksha Nema and Mitesh M. Khapra. Towards a better metric for evaluating question generation systems. In Proceedings of the 2018 Conference on Empirical Methods in Natural Language Processing, pages 3950--3959, Brussels, Belgium, October-November 2018. Association for Computational Linguistics. doi: 10.18653/v1/D18-1429. URL https://www.aclweb.org/ anthology/D18-1429.
- 43 Tri Nguyen, Mir Rosenberg, Xia Song, Jianfeng Gao, Saurabh Tiwary, Rangan Majumder, and Li Deng. MS MARCO: A human generated machine reading comprehension dataset. In Tarek Richard Besold, Antoine Bordes, Artur S. d'Avila Garcez, and Greg Wayne, editors, Proceedings of the Workshop on Cognitive Computation: Integrating neural and symbolic approaches 2016 co-located with the 30th Annual Conference on Neural Information Processing Systems (NIPS 2016), Barcelona, Spain, December 9, 2016, volume 1773 of CEUR Workshop Proceedings. CEUR-WS.org, 2016. URL http://ceur-ws.org/Vol-1773/CoCoNIPS_ 2016_paper9.pdf.
- 44 Rodrigo Nogueira and Kyunghyun Cho. Passage re-ranking with BERT. arXiv preprint arXiv:1901.04085, 2019. URL https://arxiv.org/abs/1901.04085.
- 45 Myle Ott, Sergey Edunov, Alexei Baevski, Angela Fan, Sam Gross, Nathan Ng, David Grangier, and Michael Auli. fairseq: A fast, extensible toolkit for sequence modeling. In Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics (Demonstrations), pages 48--53, Minneapolis, Minnesota, June 2019. Association for Computational Linguistics. doi: 10.18653/v1/N19-4009. URL https://www.aclweb. org/anthology/N19-4009.
- 46 Ethan Perez, Siddharth Karamcheti, Rob Fergus, Jason Weston, Douwe Kiela, and Kyunghyun Cho. Finding generalizable evidence by learning to convince q&a models. In Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing (EMNLP-IJCNLP), pages 2402--2411, Hong Kong, China, November 2019. Association for Computational Linguistics. doi: 10.18653/v1/D19-1244. URL https://www.aclweb.org/anthology/D19-1244.
- 47 Fabio Petroni, Tim Rocktäschel, Sebastian Riedel, Patrick Lewis, Anton Bakhtin, Yuxiang Wu, and Alexander Miller. Language models as knowledge bases? In Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing (EMNLP-IJCNLP), pages 2463--2473, Hong Kong, China, November 2019. Association for Computational Linguistics. doi: 10.18653/v1/ D19-1250. URL https://www.aclweb.org/anthology/D19-1250.
- 48 Fabio Petroni, Patrick Lewis, Aleksandra Piktus, Tim Rocktäschel, Yuxiang Wu, Alexander H. Miller, and Sebastian Riedel. How context affects language models' factual predictions. In Automated Knowledge Base Construction, 2020. URL https://openreview.net/forum? id=025X0zPfn.
- 49 Alec Radford, Karthik Narasimhan, Tim Salimans, and Ilya Sutskever. Improving Language Understanding by Generative Pre-Training, 2018. URL https://s3-us-west-2.amazonaws.com/openai-assets/research-covers/ language-unsupervised/language_understanding_paper.pdf.
- 50 Alec Radford, Jeff Wu, Rewon Child, David Luan, Dario Amodei, and Ilya Sutskever. Language models are unsupervised multitask learners, 2019. URL https://d4mucfpksywv.cloudfront.net/better-language-models/language_ models_are_unsupervised_multitask_learners.pdf.
- 51 Colin Raffel, Noam Shazeer, Adam Roberts, Katherine Lee, Sharan Narang, Michael Matena, Yanqi Zhou, Wei Li, and Peter J. Liu. Exploring the limits of transfer learning with a unified text-to-text transformer. arXiv e-prints, 2019. URL https://arxiv.org/abs/1910.10683.
- 52 Adam Roberts, Colin Raffel, and Noam Shazeer. How much knowledge can you pack into the parameters of a language model? arXiv e-prints, 2020. URL https://arxiv.org/abs/ 2002.08910.
- 53 Stephen Robertson and Hugo Zaragoza. The probabilistic relevance framework: Bm25 and beyond. Found. Trends Inf. Retr., 3(4):333--389, April 2009. ISSN 1554-0669. doi: 10.1561/ 1500000019. URL https://doi.org/10.1561/1500000019.
- 54 Irene Solaiman, Miles Brundage, Jack Clark, Amanda Askell, Ariel Herbert-Voss, Jeff Wu, Alec Radford, and Jian-Bing Wang. Release strategies and the social impacts of language models. ArXiv, abs/1908.09203, 2019.
- 55 Sainbayar Sukhbaatar, Arthur Szlam, Jason Weston, and Rob Fergus. End-to-end memory networks. In C. Cortes, N. D. Lawrence, D. D. Lee, M. Sugiyama, and R. Garnett, editors, Advances in Neural Information Processing Systems 28, pages 2440--2448. Curran Associates, Inc., 2015. URL http://papers.nips.cc/paper/5846-end-to-end-memory-networks.pdf.
- 56 James Thorne, Andreas Vlachos, Christos Christodoulopoulos, and Arpit Mittal. FEVER: a large-scale dataset for fact extraction and VERification. In Proceedings of the 2018 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long Papers), pages 809--819, New Orleans, Louisiana, June 2018. Association for Computational Linguistics. doi: 10.18653/v1/N18-1074. URL https://www.aclweb.org/anthology/N18-1074.
- 57 James H. Thorne and Andreas Vlachos. Avoiding catastrophic forgetting in mitigating model biases in sentence-pair classification with elastic weight consolidation. ArXiv, abs/2004.14366, 2020. URL https://arxiv.org/abs/2004.14366.
- 58 Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszkoreit, Llion Jones, Aidan N Gomez, Ł ukasz Kaiser, and Illia Polosukhin. Attention is all you need. In I. Guyon, U. V. Luxburg, S. Bengio, H. Wallach, R. Fergus, S. Vishwanathan, and R. Garnett, editors, Advances in Neural Information Processing Systems 30, pages 5998--6008. Curran Associates, Inc., 2017. URL http://papers.nips.cc/paper/7181-attention-is-all-you-need.pdf.
- 59 Ashwin Vijayakumar, Michael Cogswell, Ramprasaath Selvaraju, Qing Sun, Stefan Lee, David Crandall, and Dhruv Batra. Diverse beam search for improved description of complex scenes. AAAI Conference on Artificial Intelligence, 2018. URL https://www.aaai.org/ocs/index. php/AAAI/AAAI18/paper/view/17329.
- 60 Alex Wang, Amanpreet Singh, Julian Michael, Felix Hill, Omer Levy, and Samuel Bowman. GLUE: A multi-task benchmark and analysis platform for natural language understanding. In Proceedings of the 2018 EMNLP Workshop BlackboxNLP: Analyzing and Interpreting Neural Networks for NLP, pages 353--355, Brussels, Belgium, November 2018. Association for Computational Linguistics. doi: 10.18653/v1/W18-5446. URL https://www.aclweb.org/ anthology/W18-5446.
- 61 Alex Wang, Yada Pruksachatkun, Nikita Nangia, Amanpreet Singh, Julian Michael, Felix Hill, Omer Levy, and Samuel Bowman. SuperGLUE: A Stickier Benchmark for GeneralPurpose Language Understanding Systems. In H. Wallach, H. Larochelle, A. Beygelzimer, F. d\textquotesingle Alché-Buc, E. Fox, and R. Garnett, editors, Advances in Neural Information Processing Systems 32, pages 3261--3275. Curran Associates, Inc., 2019. URL https:// arxiv.org/abs/1905.00537.
- 62 Shuohang Wang, Mo Yu, Xiaoxiao Guo, Zhiguo Wang, Tim Klinger, Wei Zhang, Shiyu Chang, Gerry Tesauro, Bowen Zhou, and Jing Jiang. R3: Reinforced ranker-reader for open-domain question answering. In Sheila A. McIlraith and Kilian Q. Weinberger, editors, Proceedings of the Thirty-Second AAAI Conference on Artificial Intelligence, (AAAI-18), the 30th innovative Applications of Artificial Intelligence (IAAI-18), and the 8th AAAI Symposium on Educational Advances in Artificial Intelligence (EAAI-18), New Orleans, Louisiana, USA, February 2-7, 2018, pages 5981--5988. AAAI Press, 2018. URL https://www.aaai.org/ocs/index. php/AAAI/AAAI18/paper/view/16712.
- 63 Shuohang Wang, Mo Yu, Jing Jiang, Wei Zhang, Xiaoxiao Guo, Shiyu Chang, Zhiguo Wang, Tim Klinger, Gerald Tesauro, and Murray Campbell. Evidence aggregation for answer reranking in open-domain question answering. In ICLR, 2018. URL https://openreview. net/forum?id=rJl3yM-Ab.
- 64 Jason Weston, Sumit Chopra, and Antoine Bordes. Memory networks. In Yoshua Bengio and Yann LeCun, editors, 3rd International Conference on Learning Representations, ICLR 2015, San Diego, CA, USA, May 7-9, 2015, Conference Track Proceedings, 2015. URL http://arxiv.org/abs/1410.3916.
- 65 Jason Weston, Emily Dinan, and Alexander Miller. Retrieve and refine: Improved sequence generation models for dialogue. In Proceedings of the 2018 EMNLP Workshop SCAI: The 2nd International Workshop on Search-Oriented Conversational AI, pages 87--92, Brussels, Belgium, October 2018. Association for Computational Linguistics. doi: 10.18653/v1/W18-5713. URL https://www.aclweb.org/anthology/W18-5713.
- 66 Thomas Wolf, Lysandre Debut, Victor Sanh, Julien Chaumond, Clement Delangue, Anthony Moi, Pierric Cistac, Tim Rault, Rémi Louf, Morgan Funtowicz, Joe Davison, Sam Shleifer, Patrick von Platen, Clara Ma, Yacine Jernite, Julien Plu, Canwen Xu, Teven Le Scao, Sylvain Gugger, Mariama Drame, Quentin Lhoest, and Alexander M. Rush. Huggingface's transformers: State-of-the-art natural language processing. ArXiv, abs/1910.03771, 2019.
- 67 Shiyue Zhang and Mohit Bansal. Addressing semantic drift in question generation for semisupervised question answering. In Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing (EMNLP-IJCNLP), pages 2495--2509, Hong Kong, China, November 2019. Association for Computational Linguistics. doi: 10.18653/v1/D19-1253. URL https://www.aclweb.org/anthology/D19-1253.
- 68 Wanjun Zhong, Jingjing Xu, Duyu Tang, Zenan Xu, Nan Duan, Ming Zhou, Jiahai Wang, and Jian Yin. Reasoning over semantic-level graph for fact checking. ArXiv, abs/1909.03745, 2019. URL https://arxiv.org/abs/1909.03745.