Spring Bean生命周期与基础
SpringBean的生命周期是怎么样的?
Bean的生命周期分为 创建、使用、销毁
进一步分细化就是 实例化、初始化、注册Destruction回调、Bean的正常使用以及Bean的销毁。
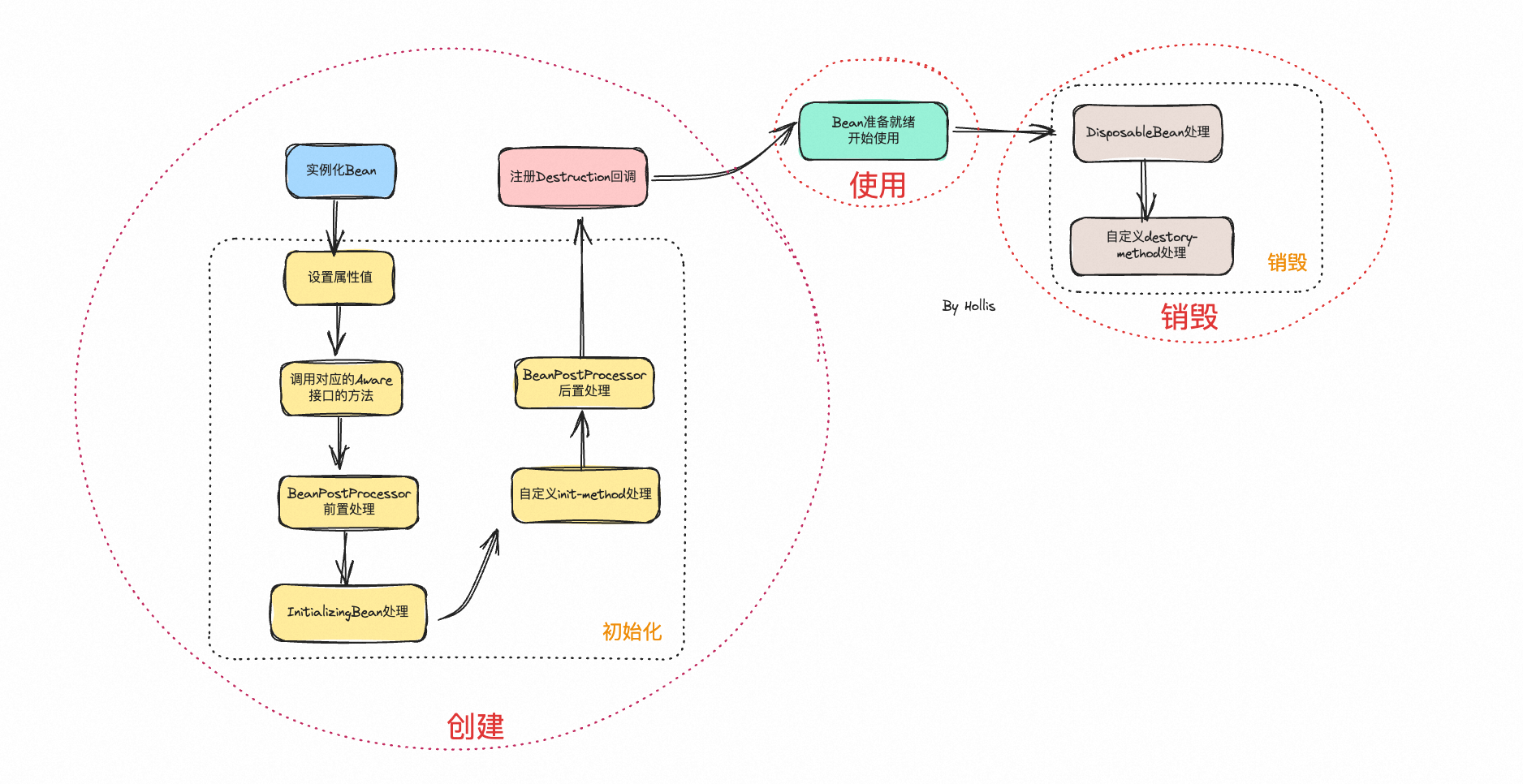
第一阶段:创建
- 实例化阶段:执行构造函数(创建Bean实例)→ 源码:createBeanInstance()
- 设置属性:注入@Autowired等依赖 → 源码:populateBean()
- 感知Aware:执行BeanNameAware/BeanFactoryAware等接口方法 → 源码:invokeAwareMethods()
- BeanPostProcessor前置处理:postProcessBeforeInitialization → 源码:applyBeanPostProcessorsBeforeInitialization()
- 初始化阶段:
-
- @PostConstruct(注解式初始化)
- afterPropertiesSet(实现InitializingBean接口)
- init-method(@Bean(initMethod)配置式初始化)→ 源码:invokeInitMethods()
- BeanPostProcessor后置处理:postProcessAfterInitialization → 源码:applyBeanPostProcessorsAfterInitialization()
第二阶段:注册销毁回调(创建阶段收尾,为销毁做准备)
- 注册销毁回调:Spring为Bean绑定销毁逻辑(等到程序要结束的时候会执行这部分逻辑)→ 源码:registerDisposableBeanIfNecessary()
-
- 识别Bean是否实现DisposableBean接口、是否有@PreDestroy注解、是否配置destroy-method;
- 将销毁逻辑封装到DisposableBeanAdapter,绑定到BeanDefinition中。
第三阶段:使用(Bean就绪)
- Bean就绪:Bean进入容器单例池(单例Bean)/ 每次getBean创建(原型Bean),对外提供服务 → 核心:此时Bean完全初始化,依赖、增强逻辑全部就绪。
第四阶段:销毁(仅单例Bean触发,原型Bean不销毁)
- 触发销毁:仅JVM优雅关闭(Spring Shutdown Hook)/ 手动关闭容器(context.close())时触发 → 源码:DisposableBeanAdapter.destroy()
- 销毁执行顺序:
-
- @PreDestroy(注解式销毁)
- DisposableBean.destroy(实现DisposableBean接口)
- destroy-method(@Bean(destroyMethod)配置式销毁)
- 容器销毁:Spring容器释放所有资源(连接池、线程池等),生命周期结束。
上面的初始化前置-初始化-初始化后置,这一部分整个都是可以被我们控制增强的
案例:
package com.example.demo.testtt;
import org.springframework.beans.BeansException;
import org.springframework.beans.factory.config.BeanPostProcessor;
import org.springframework.stereotype.Component;
/**
* @Author: Daylight
* @Date: 2026-03-15 20:39
*/
@Component
public class MyBeanPostProcessor implements BeanPostProcessor {
// 初始化前置增强
@Override
public Object postProcessBeforeInitialization(Object bean, String beanName) throws BeansException {
if ("userService".equals(beanName)) { // 只处理指定名称的Bean
System.out.println("前置处理:" + beanName + ",实例:" + bean);
// 可以修改Bean的属性、状态,甚至返回新的Bean实例替换原有的
((UserService) bean).setName("自定义名称");
((UserService) bean).setAge(100);
}
return bean;
}
// 初始化后置增强
@Override
public Object postProcessAfterInitialization(Object bean, String beanName) throws BeansException {
if ("userService".equals(beanName)) {
System.out.println("后置处理:" + beanName + ",实例:" + bean);
}
return bean;
}
}
/**
* @Author: Daylight
* @Date: 2026-03-15 20:40
*/
@Component("userService")
public class UserService {
String name;
int age;
@PostConstruct
private void init() {
System.out.println("执行初始化方法");
}
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
public int getAge() {
return age;
}
public void setAge(int age) {
this.age = age;
}
}
前置处理:userService,实例:com.example.demo.testtt.UserService@271f18d3
执行初始化方法
后置处理:userService,实例:com.example.demo.testtt.UserService@271f18d3SpringBean的初始化过程是怎么样的?
首先需要注意:初始化和实例化是两个不同的概念
实例化
- 实例化就是创建对象的过程。在Spring中,一般指调用构造方法创建Bean实例的过程,也就是最开始的阶段。
- 主要对应doCreateBean中的createBeanInstance方法。
初始化
- 初始化时在Bean实例化完成之后,设置属性设置一个步骤。
- 也就是广义上的初始化,其实是包含了依赖注入、感知Aware、初始化+初始化前后置整个流程
- 主要对应doCreateBean中的populateBean和initializeBean方法。
实例化+初始化整个流程:
实例化Bean:
主要是在AbstractAutowireCapableBeanFactory类中的createBeanInstance方法中实现
对应源码(不用记)
protected BeanWrapper createBeanInstance(String beanName, RootBeanDefinition mbd, Object[] args) {
// 解析Bean的类,确保Bean的类在这个点已经被确定
Class<?> beanClass = resolveBeanClass(mbd, beanName);
// 检查Bean的访问权限,确保非public类允许访问
if (beanClass != null && !Modifier.isPublic(beanClass.getModifiers()) && !mbd.isNonPublicAccessAllowed()) {
throw new BeanCreationException(mbd.getResourceDescription(), beanName,
"Bean class isn't public, and non-public access not allowed: " + beanClass.getName());
}
// 如果Bean定义中指定了工厂方法,则通过工厂方法创建Bean实例
if (mbd.getFactoryMethodName() != null) {
return instantiateUsingFactoryMethod(beanName, mbd, args);
}
// 当重新创建相同的Bean时的快捷路径
boolean resolved = false;
boolean autowireNecessary = false;
if (args == null) {
synchronized (mbd.constructorArgumentLock) {
// 如果构造方法或工厂方法已经被解析,直接使用解析结果
if (mbd.resolvedConstructorOrFactoryMethod != null) {
resolved = true;
autowireNecessary = mbd.constructorArgumentsResolved;
}
}
}
if (resolved) {
// 如果需要自动装配构造函数参数,则调用相应方法进行处理
if (autowireNecessary) {
return autowireConstructor(beanName, mbd, null, null);
}
else {
// 否则使用无参构造函数或默认构造方法创建实例
return instantiateBean(beanName, mbd);
}
}
// 通过BeanPostProcessors确定构造函数候选
Constructor<?>[] ctors = determineConstructorsFromBeanPostProcessors(beanClass, beanName);
// 如果有合适的构造函数或需要通过构造函数自动装配,则使用相应的构造函数创建实例
if (ctors != null || mbd.getResolvedAutowireMode() == AUTOWIRE_CONSTRUCTOR ||
mbd.hasConstructorArgumentValues() || !ObjectUtils.isEmpty(args)) {
return autowireConstructor(beanName, mbd, ctors, args);
}
// 没有特殊处理,使用默认的无参构造函数创建Bean实例
return instantiateBean(beanName, mbd);
}逻辑:
- 确保这个Bean对应的类已经加载了并且这个类必需是public,如果有工厂方法,会直接通过工厂方法来创建这个Bean,没有就是调用构造方法创建
不过这里需要注意的就是,在真正执行createBeanInstance 前,其实会先检查Bean定义的作用域,如果发现是单例模式,就检查Bean缓存池是否已经存在,存在就复用,否则才进入**createBeanInstance()**逻辑进行创建
具体的代码就是:
BeanWrapper instanceWrapper = null;
if (mbd.isSingleton()) {
instanceWrapper = this.factoryBeanInstanceCache.remove(beanName);
}
if (instanceWrapper == null) {
instanceWrapper = createBeanInstance(beanName, mbd, args);
}下一步是设置属性值,不过还有一个Spring解决循环依赖问题的三级缓存需要了解一下
主要在doCreateBean中,源码:
protected Object doCreateBean(final String beanName, final RootBeanDefinition mbd, final Object[] args)
throws BeanCreationException {
// 实例化bean
// ...
// Eagerly cache singletons to be able to resolve circular references
// even when triggered by lifecycle interfaces like BeanFactoryAware.
boolean earlySingletonExposure = (mbd.isSingleton() && this.allowCircularReferences &&
isSingletonCurrentlyInCreation(beanName));
if (earlySingletonExposure) {
if (logger.isDebugEnabled()) {
logger.debug("Eagerly caching bean '" + beanName +
"' to allow for resolving potential circular references");
}
addSingletonFactory(beanName, new ObjectFactory<Object>() {
@Override
public Object getObject() throws BeansException {
return getEarlyBeanReference(beanName, mbd, bean);
}
});
}
// ...
//设置属性值
//初始化Bean
// ...
// 注册Bean的销毁回调
return exposedObject;
}不过这个在 Spring解决循环依赖一定需要三级缓存吗? 进行介绍
设置属性值:
主要是在doCreateBean中调用populateBean()去完成的
populateBean 主要是处理了自动装配、属性注入、依赖检查等多个方面:
源码:
protected void populateBean(String beanName, RootBeanDefinition mbd, BeanWrapper bw) {
// 获取Bean定义中的属性值
PropertyValues pvs = mbd.getPropertyValues();
// 如果BeanWrapper为空,则无法设置属性值
if (bw == null) {
if (!pvs.isEmpty()) {
throw new BeanCreationException(
mbd.getResourceDescription(), beanName, "Cannot apply property values to null instance");
}
else {
// 对于null实例,跳过设置属性阶段
return;
}
}
// 在设置属性之前,给InstantiationAwareBeanPostProcessors机会修改Bean状态
// 这可以用于支持字段注入等样式
boolean continueWithPropertyPopulation = true;
// 如果Bean不是合成的,并且存在InstantiationAwareBeanPostProcessor,执行后续处理
if (!mbd.isSynthetic() && hasInstantiationAwareBeanPostProcessors()) {
for (BeanPostProcessor bp : getBeanPostProcessors()) {
if (bp instanceof InstantiationAwareBeanPostProcessor) {
InstantiationAwareBeanPostProcessor ibp = (InstantiationAwareBeanPostProcessor) bp;
if (!ibp.postProcessAfterInstantiation(bw.getWrappedInstance(), beanName)) {
continueWithPropertyPopulation = false;
break;
}
}
}
}
// 如果上述处理后决定不继续,则返回
if (!continueWithPropertyPopulation) {
return;
}
// 根据自动装配模式(按名称或类型),设置相关的属性值
if (mbd.getResolvedAutowireMode() == RootBeanDefinition.AUTOWIRE_BY_NAME ||
mbd.getResolvedAutowireMode() == RootBeanDefinition.AUTOWIRE_BY_TYPE) {
MutablePropertyValues newPvs = new MutablePropertyValues(pvs);
// 如果是按名称自动装配,添加相应的属性值
if (mbd.getResolvedAutowireMode() == RootBeanDefinition.AUTOWIRE_BY_NAME) {
autowireByName(beanName, mbd, bw, newPvs);
}
// 如果是按类型自动装配,添加相应的属性值
if (mbd.getResolvedAutowireMode() == RootBeanDefinition.AUTOWIRE_BY_TYPE) {
autowireByType(beanName, mbd, bw, newPvs);
}
pvs = newPvs;
}
// 检查是否需要进行依赖性检查
boolean hasInstAwareBpps = hasInstantiationAwareBeanPostProcessors();
boolean needsDepCheck = (mbd.getDependencyCheck() != RootBeanDefinition.DEPENDENCY_CHECK_NONE);
// 如果需要,则进行依赖性检查
if (hasInstAwareBpps || needsDepCheck) {
PropertyDescriptor[] filteredPds = filterPropertyDescriptorsForDependencyCheck(bw, mbd.allowCaching);
if (hasInstAwareBpps) {
for (BeanPostProcessor bp : getBeanPostProcessors()) {
if (bp instanceof InstantiationAwareBeanPostProcessor) {
InstantiationAwareBeanPostProcessor ibp = (InstantiationAwareBeanPostProcessor) bp;
pvs = ibp.postProcessPropertyValues(pvs, filteredPds, bw.getWrappedInstance(), beanName);
if (pvs == null) {
return;
}
}
}
}
if (needsDepCheck) {
checkDependencies(beanName, mbd, filteredPds, pvs);
}
}
// 应用属性值
applyPropertyValues(beanName, mbd, bw, pvs);
}主要就是先校验负责包装Bean实例的容器是否为null,如果为null,且这个时候有需要设置的属性值,会直接报错,否则就return
然后检查前置拦截,其实就是一个拓展点,就是检查开发人员是否配置了主动终止特定Bean的实例注入功能
接着就是进行属性注入功能(这里会判断按照名称装配 还是类型装配)
最后就是进行依赖性检查,比如有些字段我们不允许为null之类的
检查完成就将应用属性加载Bean实例中
initializeBean方法:
这个方法更像是后续方法的一个总入口,用来编排 检查Aware、初始化前置、初始化、初始化后置 几个方法
protected Object initializeBean(final String beanName, final Object bean, RootBeanDefinition mbd) {
//...
//检查Aware
invokeAwareMethods(beanName, bean);
//调用BeanPostProcessor的前置处理方法
Object wrappedBean = bean;
if (mbd == null || !mbd.isSynthetic()) {
wrappedBean = applyBeanPostProcessorsBeforeInitialization(wrappedBean, beanName);
}
//调用InitializingBean的afterPropertiesSet方法或自定义的初始化方法及自定义init-method方法
try {
invokeInitMethods(beanName, wrappedBean, mbd);
}
catch (Throwable ex) {
throw new BeanCreationException(
(mbd != null ? mbd.getResourceDescription() : null),
beanName, "Invocation of init method failed", ex);
}
//调用BeanPostProcessor的后置处理方法
if (mbd == null || !mbd.isSynthetic()) {
wrappedBean = applyBeanPostProcessorsAfterInitialization(wrappedBean, beanName);
}
return wrappedBean;
}检查Aware:
private void invokeAwareMethods(final String beanName, final Object bean) {
if (bean instanceof Aware) {
if (bean instanceof BeanNameAware) {
((BeanNameAware) bean).setBeanName(beanName);
}
if (bean instanceof BeanClassLoaderAware) {
((BeanClassLoaderAware) bean).setBeanClassLoader(getBeanClassLoader());
}
if (bean instanceof BeanFactoryAware) {
((BeanFactoryAware) bean).setBeanFactory(AbstractAutowireCapableBeanFactory.this);
}
}
}就是检查这个Bean是不是实现了BeanNameAware、BeanClassLoaderAware等这些Aware接口,Spring容器会调用它们的方法进行处理。
这些Aware接口其实就是一个工具,有了这个,Bean就可以和Spring内部的组件进行交互
- BeanNameAware: 通过这个接口,Bean可以获取到自己在Spring容器中的名字。这对于需要根据Bean的名称进行某些操作的场景很有用。
- BeanClassLoaderAware: 这个接口使Bean能够访问加载它的类加载器。这在需要进行类加载操作时特别有用,例如动态加载类。
- BeanFactoryAware:通过这个接口可以获取对 BeanFactory 的引用,获得对 BeanFactory 的访问权限
如果没有Aware,Bean就只能干活,而有了Aware,Bean不仅能干活,并且我们可以获取这个Bean在容器中信息
调用BeanPostProcessor的前置处理方法(其实就是初始化前置执行方法):
BeanPostProcessor 是Spring提供的一个拓展机制,有前置和后置两个方法,主要是在初始化执行的前后分别执行
初始化: @PostConstruct、init-method和afterPropertiesSet执行顺序
调用BeanPostProcessor的后置处理方法
这三个合起来的样例
package com.example.demo.testtt;
import org.springframework.beans.BeansException;
import org.springframework.beans.factory.config.BeanPostProcessor;
import org.springframework.stereotype.Component;
/**
* @Author: Daylight
* @Date: 2026-03-15 20:39
*/
@Component
public class MyBeanPostProcessor implements BeanPostProcessor {
// 初始化前置增强
@Override
public Object postProcessBeforeInitialization(Object bean, String beanName) throws BeansException {
if ("userService".equals(beanName)) { // 只处理指定名称的Bean
System.out.println("前置处理:" + beanName + ",实例:" + bean);
// 可以修改Bean的属性、状态,甚至返回新的Bean实例替换原有的
((UserService) bean).setName("自定义名称");
((UserService) bean).setAge(100);
}
return bean;
}
// 初始化后置增强
@Override
public Object postProcessAfterInitialization(Object bean, String beanName) throws BeansException {
if ("userService".equals(beanName)) {
System.out.println("后置处理:" + beanName + ",实例:" + bean);
}
return bean;
}
}
/**
* @Author: Daylight
* @Date: 2026-03-15 20:40
*/
@Component("userService")
public class UserService {
String name;
int age;
@PostConstruct
private void init() {
System.out.println("执行初始化方法");
}
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
public int getAge() {
return age;
}
public void setAge(int age) {
this.age = age;
}
}
前置处理:userService,实例:com.example.demo.testtt.UserService@271f18d3
执行初始化方法
后置处理:userService,实例:com.example.demo.testtt.UserService@271f18d3到这就完成了Bean的创建
补充:上述的一些过程中比较重要的知识点的补充
- 工厂方法不是FactoryBean,虽然两者都是创建Bean的方法,但是工厂方法创建是普通的Bean对象,而FactoryBean是创建比较特殊的,增强的Bean对象
工厂方法:
@Component
public class UserServiceFactory {
@Bean
public UserService getBean() {
UserService userService = new UserService();
userService.setName("工厂方法创建的对象");
userService.setAge(10);
return userService;
}
}- 用户提前终止属性注入:
其实就是满足一定的条件就认为可以提前结束,那么我们返回false,在属性注入阶段会调用,返回false就直接停止注入
@Component
public class CustomInstantiationAwareBeanPostProcessor implements InstantiationAwareBeanPostProcessor {
@Override
public boolean postProcessAfterInstantiation(Object bean, String beanName) {
// 对名称为"testBean"的Bean,终止属性注入
if ("testBean".equals(beanName)) {
return false; // 提前终止
}
return true;
}
}Spring中创建Bean有几种方式?
其实主要就是通过配置文件和通过注解两大类,不过配置文件的,现在基本已经很少用了
配置文件,xml(了解即可)
这种就真的是很原始了,记得我刚开始学的时候,才接触过,后面基本都是SpringBoot直接注解的形式
<beans xmlns="http://www.springframework.org/schema/beans"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://www.springframework.org/schema/beans http://www.springframework.org/schema/beans/spring-beans.xsd">
<bean id="hollisService" class="com.java.bagu.demo.HollisChuangServiceImpl"/>
</beans>通过@Component系列
- @Component
- @Service
- @Repository
- @Controller
这些注解其实底层都是一样的,都是@Component,只不过不同的命名代表不同的语义而已
Spring中@Service、@Component、@Repository等注解区别是什么?
@Service
public class UserServiceFactory {
public UserService getBean() {
UserService userService = new UserService();
userService.setName("工厂方法创建的对象");
userService.setAge(10);
return userService;
}
}它会为加了这些注解的类创建一个Bean对象出来
通过@Bean注解
这个注解一般会搭配@Configuration一起使用
- @Configuration 的作用就是让加了这个注解的类被Spring扫描到,并且创建出类的实例
- 而@Bean则是加在方法上,让该方法的返回值变成一个Bean对象
这两个一般会一起使用,@Configuration 确保类被扫到,@Bean用来自定义不同的Bean对象
不过@Bean不一定要和@Configuration 一起用,只要你的类能被扫描到就生效,也就是搭配@Component系列同样可以
@Configuration
public class UserServiceFactory {
@Bean
public UserService getBean() {
UserService userService = new UserService();
userService.setName("工厂方法创建的对象");
userService.setAge(10);
return userService;
}
}通过@Import注解
@Import 注解其实是一个非核心注解,它的作用就是将指定的类导入到Spring容器中(也就是创建Been对象),一般就是用来导入那些没有被Spring管理的普通类
然后这个注解是加载类上的,并且这个类必需得是能被扫描到的或是启动类
@SpringBootApplication
@Import({UserServiceFactory.class})
public class DemoApplication {
public static void main(String[] args) {
ApplicationContext context = SpringApplication.run(DemoApplication.class, args);
UserServiceFactory bean = context.getBean(UserServiceFactory.class);
System.out.println(bean); // com.example.demo.testtt.UserServiceFactory@76304b46
}
}通过Dubbo的@DubboService(version = "1.0.0")注解
这个注解是dubbo提供的,会在对应的类创建出实例并加载到容器中用户后续调用
@DubboService(version = "1.0.0")
public class TestImpl implements Test {
}Spring中的Bean是线程安全的吗?
这个问题其实要看Bean的一个作用域,比较当前的就是Singleton和Prototype
Prototype 是每次从容器请求的时候都会从容器中获取一个新的Bean,每次都是新的,相当于不会出现bean多线程共享,所以不存在线程安全问题
Singleton 是整个容器中只存在有一个Bean实例,所以每个线程共享的是同一个Bean
如果这个bean存在成员变量并且对外提供了对成员变量的写操作,在多线程情况下往往是线程不安全的
例如:
@Component
public class Test {
int cnt;
public int incr() {
cnt ++;
return cnt;
}
}这种情况就是线程不安全的
总结一下:
- 如果一个Bean的生命周期是Singleton,那么当它存在成员变量且提供对该成员变量的写操作的时候,一般就是线程不安全的,当然也看你这个变量本身的操作是否线程安全,假设你是使用CAS或是一些锁技术来进行写操作的话,就是线程安全的
- Prototype 情况下,bean是线程私有,不存在线程安全问题
那假设一个Bean就是需要提供成员变量,同时提供写操作,如何保证线程安全?
-
修改作用域为Prototype
@Component
@Scope("Prototype")
public class Test {
int cnt;
public int incr() {
cnt ++;
return cnt;
}
}
每次从容器中请求bean都是创建一个新的Bean,造成一定的资源开销,并且实现不了线程通信的情况,每次都是单独的一份数据
-
通过加锁
@Component
public class Test {
int cnt;
public synchronized int incr() {
cnt ++;
return cnt;
}
}
会影响吞吐量
-
使用并发场景下的工具
@Component
public class Test {
AtomicInteger cnt = new AtomicInteger(0);
public synchronized int incr() {
return cnt.incrementAndGet();
}
}
Spring中的Bean作用域有哪些?
Bean的作用域就是说Bean在哪个范围可以被使用。不同的作用域也对应着不同的创建方式和享受范围
常见的作用域就是Singleton、Prototype、Request、Session、Application
这个作用域的声明方式就是通过注解@Scope进行指定
@Scope("prototype")
@Component
public class Test {}- Singleton(单例)
-
- 默认作用域
- 每个SpringIOC容器,只创建一个Bean实例,且这个实例是全局共享的状态
- 适合全局共享的场景
- Prototype(原型)
-
- 每次请求SpringIOC容器的适合都会创建一个新的Bean实例
- 适合所有状态都是非共享的情况
- Request(请求)
-
- 仅在web应用程序中生效
- 每来一个Http请求,就会创建一个对应的Bean实例
- 适合以请求为维度进行数据存储和处理的场景
- Session(会话)
-
- 仅在web应用程序中生效
- 每个Session都会创建一个新的Bean实例
- 适合会话级的数据存储和处理
- websocket
-
- Spring为webSocket创建了专属级别的作用域
- 每建立一个链接就创建一个新的Bean,访问范围就是这条websocket
大多数场景,我们只用到Singleton和Prototype
此外还要注意的一点就是Spring在解决循环依赖的时候,其实只解决了单例作用域的Bean的循环依赖,其它的作用域还没有解决
Spring中@Service、@Component、@Repository等注解区别是什么?
这些注解在Spring框架中的主要区别在于它们的语义意图,在功能上几乎没有差异!只是为了让我们识别出我们标注的Bean到底是个什么角色,是一个Service、还是一个Repository、又或者是一个Controller。
- @Component:是一个通用的组件声明注解,表示该类是一个Spring组件。它可以用于任何Spring管理的组件。
- @Service:通常用于标记服务层的组件。虽然它本质上与@Component相同,但这个注解表示该类属于服务层,这有助于区分不同层次的组件。
- @Repository:用于标记数据访问层的组件,即DAO(Data Access Object)层。这个注解除了将类标识为Spring组件之外,还能让Spring为它提供一些持久化特定的功能,比如异常转换。
- @Controller:用于标记控制层的组件,特别是在Spring MVC中用于定义控制器类。这个注解通知Spring该类应当作为控制器处理HTTP请求。
Spring中注入Bean有几种方式?
首先需要知道的一点,想要实现Bean注入的话,只能注入给同样受到SpringIOC管理的类,也就是一般只能注入给Service或是Controller之类的
那也就是说Bean注入其实是在我们已经有一个Bean的情况下,这个时候进行Bean注入
基于配置文件的方式:XML
<beans>
<bean id="hollisRepository" class="com.java.bagu.demo.HollisRepository"/>
<bean id="hollisService" class="com.java.bagu.demo.HollisService">
<property name="hollisRepository" ref="hollisRepository"/>
</bean>
</beans>使用@Autowired 注解
这个注解是自动注入的
可以标注在字段(成员变量)、构造器、以及setter方法上
- 字段注入
@Repository
public class UserServiceFactory {
@Autowired
private Test test;
}-
构造器注入
@Repository
public class UserServiceFactory {
private Test test;@Autowired public UserServiceFactory(Test test) { this.test = test; }}
-
setter方法注入
@Repository
public class UserServiceFactory {
private Test test;@Autowired public void setTest(Test test) { this.test = test; }}
使用 @Resource 和 @Inject 注解
除了@Autowired 之外,还有Resource、Inject同样能实现注入的功能
Autowired、Resource、Inject三者的关系?
@Repository
public class UserServiceFactory {
@Resource
private Test test;
}
@Repository
public class UserServiceFactory {
@Inject
private Test test;
}构造器注入
这也是Spring官方推荐的,无需给字段单独添加注解,只要在构造器中声明,并且你当前类能被扫描到,那么只要Bean容器中有你需要的Bean,就会自动的帮你完成注入
@Repository
public class UserServiceFactory {
private Test test;
public UserServiceFactory(Test test) {
this.test = test;
}
}为什么Spring不建议使用基于字段的依赖注入?
Spring 不推荐字段注入的核心原因:
-
违背设计原则:易忽略单一职责,因为字段注入实在是太方便了,所以我们用的时候更多就是直接使用,很少去考虑该不该在这个类来实现这个功能,随着一个Bean的依赖项越来越多,很容易出现这个Bean携带了很多额外的功能,破坏了单一职责原则;使用构造器的话,因为需要我们手动修改,所以我们往往会更加去思考合理性
-
破坏封装性,字段注入的时候,Spring一般通过反射的方式进行注入,这会破坏封装性
-
运行风险高:初始化顺序问题易引发 NPE,比如:
@Component
class Test {
@Autowired
private Bean bean;private final String beanName; public Test() { // 此时bean尚未被初始化,会抛出NPE this.beanName = bean.getName(); }}
-
测试成本高:强依赖 Spring 容器,单元测试需启动容器,效率低下。
Spring 推荐的注入规范:
- 强制依赖用构造器注入(保证依赖非空、显式声明依赖);
- 可选依赖用setter 注入(灵活控制依赖是否注入)。
构造器注入的注意事项: 会暴露循环依赖问题(本质是代码设计缺陷),临时解决方案可在构造器中加 @Lazy延迟初始化,但核心需重构代码消除循环依赖。
@Component
public class BeanOne implements Bean{
Bean beanTwo;
@Lazy
public BeanOne(Bean beanTwo) {
this.beanTwo = beanTwo;
}
}Autowired、Resource、Inject三者的关系?
首先这三个都是用来实现Bean注入的注解
那不同点就是:
- Autowired
Autowired 是Spring 自己提供的注解,换句话说,只有在Spring容器才会生效
默认是 byType ,也就是优先按照类型进行匹配,当匹配到多个的时候,可以搭配@Qualifier("test")来精确指定要哪一个,否则默认情况下按照你的filedName名来匹配
按照类型匹配不到的时候也会退回按照fieldName来找
@Component
public class UserServiceFactory {
@Autowired
@Qualifier("test")
private Test test;
}然后@Autowired 的作用范围是比较广的,能作用字段,构造器,setter
@Repository
public class UserServiceFactory {
private Test test;
@Autowired
public void setTest(Test test) {
this.test = test;
}
}
@Repository
public class UserServiceFactory {
private Test test;
@Autowired
public UserServiceFactory(Test test) {
this.test = test;
}
}
@Repository
public class UserServiceFactory {
@Autowired
private Test test;
}它是唯一一个支持可选注入,通过设置required = false,可以在找不到bean的时候不报错
@Component
public class UserServiceFactory {
@Autowired(required = false)
@Qualifier("test")
private Test test;
}总结就是:
- @Autowired 是Spring提供的,离开了Spring容器就没有这个注解了
- 它的查找方式,优先按照类型查找,匹配到多个或者匹配不到的时候会按照filedName进行查找或是匹配
- 如果通过@Qualifier("test")指定了要找的name,那么在byType之后会根据这个name进行匹配
- 它的作用范围是最广的,可以作用字段、构造器、setter
- 唯一一个支持可选注入,在找不到bean的时候不报错
-
Resource
@Component("beanOne")
class BeanOne implements Bean {}
@Component("beanTwo")
class BeanTwo implements Bean {}
@Service
class Test {
// 此时会报错,先byName,发现没有找到bean
// 然后通过byType找到了两个Bean:beanOne和beanTwo,仍然没办法匹配
@Resource
private Bean bean;// 先byName直接找到了beanOne,然后注入 @Resource private Bean beanOne; // 显示通过byType注入,能注入成功 @Resource(type = BeanOne.class) private Bean bean;}
总结:
- Resource 是jdk自带的,它的匹配规则是,先找到名称找,找不到再按照类型找
- 它的功能比较简单,不能可选注入
- 并且作用范围也是比较少,只能作用与字段和setter
- 它是jdk标准,所以换IOC容器也同样是支持的
-
Inject
@Component
public class UserServiceFactory {@Inject @Named("test") @Nullable private Test test;}
总结:
- Inject同样是jdk自带的,在Spring环境下等同于Autowired(作用范围也一样),优先按照类型注入进行处理,如果需要处理按照类型匹配到多个bean的情况,需要通过@Named指定
- Inject 没有required 属性,所以如果想要实现可选注入的话,需要搭配@Nullable实现
- 它是jdk标准,所以换IOC容器也同样是支持的
Spring的@Autowired能用在Map上吗?
可以,并且不只是Map,而是 List/Set/Map/数组 均可
它会将IOC容器中你集合所指定的泛型的Bean对象全都找出来帮你进行注入
Map的话,key我们一般用String类型,它会帮我们注入找到的Bean的name
/**
* @Author: Daylight
* @Date: 2026-03-15 21:30
*/
@Component
public class UserServiceFactory {
@Autowired
private List<TsetService> list;
@Autowired
private Set<TsetService> set;
@Autowired
private Map<String, TsetService> map;
@Autowired
private TsetService[] arr;
@PostConstruct
public void init() {
System.out.println(list);
System.out.println(set);
System.out.println(map);
System.out.println(arr.length);
System.out.println(arr);
}
}
[TsetServiceImpl1{}, TsetServiceImpl2{}, TsetServiceImpl3{}]
[TsetServiceImpl1{}, TsetServiceImpl2{}, TsetServiceImpl3{}]
{tsetServiceImpl1=TsetServiceImpl1{}, tsetServiceImpl2=TsetServiceImpl2{}, tsetServiceImpl3=TsetServiceImpl3{}}
3
[Lcom.example.demo.testtt.service.TsetService;@17ae98d7不过我觉得比较有用的就是往Map注入这种方式,像我们在项目中遇到需要工厂模式的场景,就可以考虑使用这种方式进行注入
注意:注入的时候如果找不到Bean会报错,为了避免报错,同样可以通过:@Autowired(required = false) 的方式
@Component 与 @Bean的区别?
首先这两个都是创建Bean的方式,但是他们的使用方式和使用范围,以及适应场景都是不同的
- @Component 是加在类上,意味着为这个类创建出一个Bean放到容器中
- @Bean 是加在方法上,意味着将这个方法的返回值作为Bean对象放在容器中
- @Component 因为要加在类上,所以我们得先有类,比较适合要将我们自己写的类加载成Bean对象放到容器中;而@Bean不要求我们必需有类,并且它使用起来更加的灵活,我们可以很容易的定时类的不同属性,一般会更加的适合这个类是第三方框架的,我们拿不到源文件的类,但是可以直接创建一个它的对象作为Bean加载到容器中
- @Component 是被动扫描,@Bean是主动声明
Spring循环依赖
什么是Spring的循环依赖问题?
循环依赖就是两个Bean之间或是多个Bean之间出现了相互依赖的关系,形成了一个循环引用的情况,如果不加以处理的话,会导致启动失败
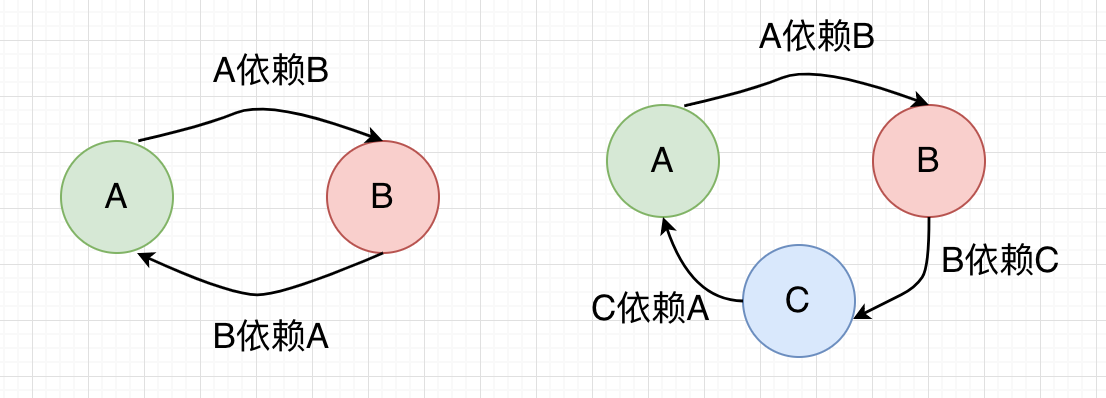
@Service
public class ServiceA{
@Autowired
private ServiceB serviceB;
}
@Service
public class ServiceB{
@Autowired
private ServiceA serviceA;
}Spring解决循环依赖的方式就是通过三级缓存:什么是Spring的三级缓存
但是三级缓存解决循环依赖的时候有一定的限制:
- 只能解决作用域为Singleton的bean
- 另外就是依赖注入的方式不能通过构造器注入的方式
为什么只支持解决单例模式的Bean呢?
Spring循环依赖的解决方案主要是通过对象的提前暴露来实现的。当一个对象在创建过程中需要引用到另一个正在创建的对象时,Spring会先提前暴露一个尚未完全初始化的对象实例,以解决循环依赖的问题。这个尚未完全初始化的对象实例就是半成品对象。
在 Spring 容器中,单例对象的创建和初始化只会发生一次,并且在容器启动时就完成了。这意味着,在容器运行期间,单例对象的依赖关系不会发生变化。因此,可以通过提前暴露半成品对象的方式来解决循环依赖的问题。
相比之下,原型对象的创建和初始化可以发生多次,并且可能在容器运行期间动态地发生变化。因此,对于原型对象,提前暴露半成品对象并不能解决循环依赖的问题,因为在后续的创建过程中,可能会涉及到不同的原型对象实例,无法像单例对象那样缓存并复用半成品对象。
因此,Spring只支持通过单例对象的提前暴露来解决循环依赖问题。
为什么不能解决构造器注入时的循环依赖问题?
因为构造器是最先被调用的,此时对象还未完成实例化,无法注入一个尚未完全创建的对象,因此Spring容器无法在构造函数注入中实现循环依赖的解决
**总结一下:**在属性注入中,Spring容器可以通过先创建一个空对象或者提前暴露一个半成品对象来解决循环依赖的问题。但在构造函数注入中,对象的实例化是在构造函数中完成的,这样就无法使用类似的方式解决循环依赖问题了。
也就是说三级缓存存在无法解决构造器注入时出现的循环依赖问题
如果想要解决构造器的依赖注入问题,主要有下面三种方式:
- 重新设计,从根源上解决
- 改成属性注入,不要用构造器注入
- 使用@Lazy注解(@Lazy注解能解决循环依赖吗?)
Spring默认支持循环依赖吗?如果发生如何解决?
Spring不知道,但是SpringBoot 是2.6之前默认支持,2.6之后默认不支持
不过我们的项目现在一般都是SpringBoot3.x 起步,可以认为模式是不支持的,如果想要开启三级缓存解决循环依赖,需要通过配置文件或是直接加@Lazy
Spring解决循环依赖一定需要三级缓存吗?
不一定。如果只是要解决二级缓存的话,只要二级缓存就行了。
也就是半成品对象放在二级缓存,成品对象放在一级缓存
但是Spring为了实现解耦Bean的初始化和代理这两个过程,所以一般是要求必需在使用到的时候才进行AOP代理
二级缓存之所以不行的原因就是,它只有一级合二级,两个存储的都是对象,但是当前对象不知道会不会被别的对象引用到,那么它无论是一级还是二级都会创建成代理对象进行存储,也就是说,无论是否出现循环依赖都会提前代理
而三级缓存,多个一个工厂缓存,只要在创建的过程没有被别的对象引用,而是它自己按照流程创建下去,并不会提前创建代理对象,只有在完全初始化完成之后,才会去创建代理对象
可以发现,其实就是创建代理对象的先后顺序而已,Spring的设计理念是把初始化和创建代理对象两套逻辑分开,而二级缓存会在初始化的过程就进行创建代理,造成耦合
什么是Spring的三级缓存?
三级缓存维护的地方:
public class DefaultSingletonBeanRegistry extends SimpleAliasRegistry implements SingletonBeanRegistry {
//一级缓存,保存完成的Bean对象
private final Map<String, Object> singletonObjects = new ConcurrentHashMap<>(256);
//三级缓存,保存单例Bean的创建工厂
private final Map<String, ObjectFactory<?>> singletonFactories = new HashMap<>(16);
//二级缓存,存储"半成品"的Bean对象
private final Map<String, Object> earlySingletonObjects = new ConcurrentHashMap<>(16);
}singletonObjects是一级缓存,存储的是 完整创建好 **的单例bean对象。**在创建一个单例bean时,会先从singletonObjects中尝试获取该bean的实例,如果能够获取到,则直接返回该实例,否则继续创建该bean。
**earlySingletonObjects是二级缓存,存储的是尚未完全创建好的单例bean对象。**在创建单例bean时,如果发现该bean存在循环依赖,则会先创建该bean的"半成品"对象,并将"半成品"对象存储到earlySingletonObjects中。当循环依赖的bean创建完成后,Spring会将完整的bean实例对象存储到singletonObjects中,并将earlySingletonObjects中存储的代理对象替换为完整的bean实例对象。这样可以保证单例bean的创建过程不会出现循环依赖问题。
singletonFactories是三级缓存,存储的是单例bean的 创建工厂 。 当一个单例bean被创建时,Spring会先将该bean的创建工厂存储到singletonFactories中,然后再执行创建工厂的getObject() 方法,生成该bean的实例对象。在该bean被其他bean引用时 ,Spring会从singletonFactories中获取该bean的创建工厂,创建出该bean的实例对象,并将该bean的实例对象存储到singletonObjects中。
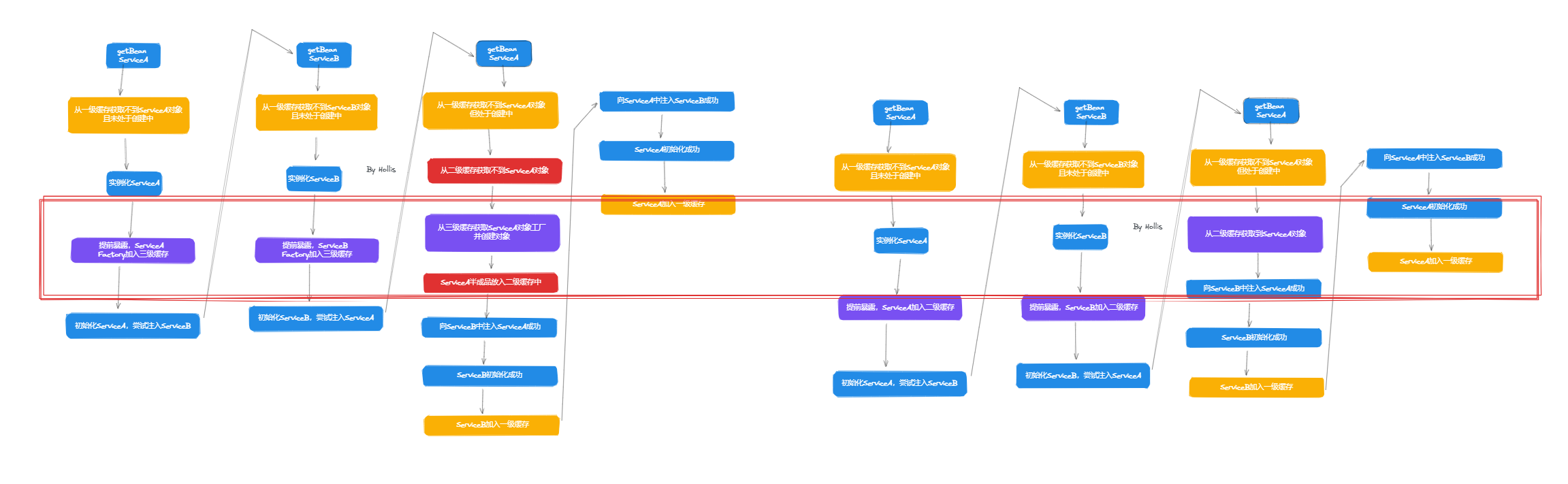
循环依赖Bean创建流程(UserService ↔ OrderService 循环依赖)
- 触发创建 UserService:查一级 / 二级 / 三级缓存均为空,标记 UserService「正在创建」,将 UserService 的创建工厂存入三级缓存。
- 实例化 UserService:new 出 UserService 半成品(未注入 OrderService),尝试注入 OrderService → 触发创建 OrderService。
- 创建 OrderService:查缓存均为空,标记「正在创建」,将 OrderService 工厂存入三级缓存,实例化 OrderService 半成品。
- 注入 UserService:OrderService 尝试注入 UserService → 查一级 / 二级缓存空,从三级缓存取 UserService 工厂。
- 生成半成品 UserService:执行工厂 getObject () 生成 UserService 半成品,存入二级缓存,删除三级缓存的 UserService 工厂。
- 完成 OrderService 创建:将半成品 UserService 注入 OrderService,OrderService 初始化完成 → 存入一级缓存。
- 恢复 UserService 创建:从一级缓存取 OrderService 注入 UserService,UserService 初始化完成。
- 最终缓存落地:UserService 存入一级缓存,删除二级缓存中的半成品 UserService,三级 / 二级缓存清空,仅一级缓存保留成品 Bean。
三级缓存是如何解决循环依赖的问题的?
Spring 的 Bean 创建其实是分成两步的,首先就是创建阶段,这个阶段只需要调用构造函数创建出一个空对象并分配内存,而初始化则是进行属性注入的阶段
三级缓存解决的思路就是延迟初始化阶段
比如这个:
@Service
public class ServiceA{
@Autowired
private ServiceB serviceB;
}
@Service
public class ServiceB{
@Autowired
private ServiceA serviceA;
}出现了相互依赖
可以看一下DefaultSingletonBeanRegistry::getSingleton源码:
@Nullable
protected Object getSingleton(String beanName, boolean allowEarlyReference) {
// 尝试一级缓存查找
Object singletonObject = this.singletonObjects.get(beanName);
// 一级缓存不存在,并且目前Bean正在创建状态中
if (singletonObject == null && this.isSingletonCurrentlyInCreation(beanName)) {
// 查找二级缓存
singletonObject = this.earlySingletonObjects.get(beanName);
// 二级缓存也不存在,并且运行从三级缓存查找
if (singletonObject == null && allowEarlyReference) {
// 加锁并再次查询
synchronized(this.singletonObjects) {
// 查询一级
singletonObject = this.singletonObjects.get(beanName);
if (singletonObject == null) {
// 查询二级
singletonObject = this.earlySingletonObjects.get(beanName);
if (singletonObject == null) {
// 拆线呢三级
ObjectFactory<?> singletonFactory = (ObjectFactory)this.singletonFactories.get(beanName);
if (singletonFactory != null) {
// 三级不为空,就调用getObject() 创建半成品
singletonObject = singletonFactory.getObject();
// 将半成品放入二级缓存
this.earlySingletonObjects.put(beanName, singletonObject);
// 将三级缓存的移除掉
this.singletonFactories.remove(beanName);
}
}
}
}
}
}
return singletonObject;
}整个流程我们可以梳理一下:
- 首先会标记ServiceA为创建中状态,并进行创建出ObjectFactory放入三级缓存
- 尝试注入ServiceB属性,这个时候会暂停ServiceA的初始化并触发ServiceB的创建,和ServiceA前面是一样的
- 当ServiceB发现自己需要注入ServiceA,它会先到一级缓存查找,发现找不到,然后ServiceA又确实处于创建中状态,这个时候会尝试查找二级缓存
- 如果二级缓存找不到,然后又启用了三级缓存,会加锁进行二次检查一级/二级缓存
- 找到不到就会查找三级缓存,如果能找打ServiceA的ObjectFactory就会调用它的getObject() 创建出半成品对象并放入二级缓存,然后ServiceB自己注入这个半成品对象,完成初始化,将自己放到一级缓存
- 回到ServiceA,查找一级缓存是否ServiceB,发现有,完成注入初始化并将自己放入一级缓存
@Lazy注解能解决循环依赖吗?
前面我们已经知道三级缓存是解决不了构造器的循环依赖注入问题的,那么如果一定要解决的话有什么方式吗?
就是使用@Lazy注解
当我们使用 @Lazy 注解时,Spring容器会在 需要该bean的时候才创建它 ,而不是在启动时。这意味着如果两个bean互相依赖,可以通过 延迟其中一个bean的初始化 来打破依赖循环。
通过这种方式就能手动指定其中一个Bean的加载顺序更慢,从而解决循环依赖问题
@Component
public class Class1 {
private Class2 class2;
public Class1(@Lazy Class2 class2) {
this.class2 = class2;
}
}
@Component
public class Class2 {
private Class1 class1;
public Class2(Class1 class1) {
this.class1 = class1;
}
}可以看到Class2被@Lazy标记,这也意味着Class2会在第一次使用的时候才创建bean
不过通过这种方式解决本质上还是比较丑陋的,往往会出现一些不可预测的问题
用法补充:
@Lazy 可以用在bean的定义上或者注入时。以下是一些使用示例:
@Component
@Lazy
public class LazyBean {
// ...
}在这种情况下,LazyBean 只有在首次被使用时才会被创建和初始化。
@Component
public class SomeClass {
private final LazyBean lazyBean;
@Autowired
public SomeClass(@Lazy LazyBean lazyBean) {
this.lazyBean = lazyBean;
}
}在这里,即使SomeClass在容器启动时被创建,LazyBean也只会在SomeClass实际使用LazyBean时才被初始化。
Spring AOP
介绍一下Spring的AOP
AOP就是切面编程,说人话就是把一些公用的东西抽离出来,我们只需要专注实现业务代码就行
|----------------|----------------------|--------------------|
| 术语 | 核心作用 | 通俗理解 |
| Aspect(切面) | 横切逻辑的封装(含切入点 + 通知) | "功能模块"(如日志切面、事务切面) |
| PointCut(切入点) | 定义拦截哪些方法 | "在哪里做"(指定增强的方法) |
| Advice(通知) | 拦截后执行的具体逻辑 | "做什么"(如方法执行前校验权限) |
| JoinPoint(连接点) | 被拦截的方法(Spring 仅支持方法) | "被增强的具体方法" |
| Weaving(织入) | 将切面融入业务逻辑的过程 | "把通用逻辑绑定到业务方法上" |
|------------------------|---------------------------------|
| Before Advice | 连接点执行前执行的逻辑 |
| After returning advice | 连接点正常执行(未抛出异常)后执行的逻辑 |
| After throwing advice | 连接点抛出异常后执行的逻辑 |
| After finally advice | 无论连接点是正常执行还是抛出异常,在连接点执行完毕后执行的逻辑 |
| Around advice | 该通知可以非常灵活的在方法调用前后执行特定的逻辑 |
Spring的AOP在什么场景下会失效?
SpringAOP的本质就是代理对象接管方法调用
如果方法调用绕过了代理对象或是根本就无法创建代理对象,就会出现AOP失效的情况
常见的失效场景:
-
方法内部调用,或是不受到SpringIOC管理的类
//1
public class MyService {
public void doSomething() {
doInternal(); // 自调用方法
}public void doInternal() { System.out.println("Doing internal work..."); }}
//2
public class MyService {
public void doSomething() {
doInternal(); // 自调用私有方法
}private void doInternal() { System.out.println("Doing internal work..."); }}
//3
public class OuterClass {
private class InnerClass {
public void doSomething() {
System.out.println("Doing something in inner class...");
}
}public void invokeInnerClassMethod() { InnerClass innerClass = new InnerClass(); // 这里是new出来的,不受到IOC管理 innerClass.doSomething(); // 调用内部类方法 }}
-
静态方法
public class MyService {
public static void doSomething() {
// static 方法
}
}
因为这个方法属于类的,不属于对象,所以会失效
-
final方法
public class MyService {
public final void doSomethingFinal() {
System.out.println("Doing something final...");
}
}
代理的本质是对我们的方法进行重写增强,final方法无法被重写,所以会失效
所以,那么总结一下就是以下几种情况,会导致代理失效,AOP不起作用:
1、私有方法调用
2、静态方法调用
3、final方法调用
4、类内部自调用
5、内部类方法调用
介绍@Scheduled的实现原理以及用法
@Scheduled 就是用来执行定时任务的
import org.springframework.scheduling.annotation.Scheduled;
import org.springframework.stereotype.Component;
@Component
public class ScheduledTasks {
// 每隔5秒执行一次
@Scheduled(fixedRate = 5000)
public void performTask() {
System.out.println("fixedRate task " + System.currentTimeMillis());
}
// 上一个任务完成后等待5秒再执行
@Scheduled(fixedDelay = 5000)
public void performDelayedTask() {
System.out.println("fixedDelay task " + System.currentTimeMillis());
}
// 每天晚上12点执行
@Scheduled(cron = "0 0 0 * * ?")
public void performTaskUsingCron() {
System.out.println("corn task " + System.currentTimeMillis());
}
}@Scheduled的原理:
- Spring启动的时候, ScheduledAnnotationBeanPostProcessor 会遍历所有被Spring管理的Bean,检查他们的每一个方法上是否有加@Scheduled注解,有的话会把方法以及它的定时规则记录下来
- 经过上一步的扫描之后,会将扫描到的方法以及定时规则交给 ScheduledTaskRegistrar ,它看了你配置的定时规则之后,会确定最终的一个执行频率,并交给 TaskScheduler
- TaskScheduler 默认就是 ConcurrentTaskScheduler ,底层其实是 ScheduledExecutorService ,也就是线程池
- 说到底,就是用定时任务来跑
注意:
- Spring6.1之前,这个线程池是默认的,是一个单线程的线程池,那假设一下子来了10个任务,就只能排队执行,一个卡住,全都卡住
- Spring6.1之后,我们必需手动指定一个线程池给它,否则不执行
使用方式:
package com.example.demo.config;
@Configuration
@EnableScheduling // 开启Spring定时任务功能
public class SchedulerConfig implements SchedulingConfigurer {
// 第一步:定义定时任务专用的线程池(Bean)
@Bean
public ThreadPoolTaskScheduler taskScheduler() {
ThreadPoolTaskScheduler scheduler = new ThreadPoolTaskScheduler();
scheduler.setPoolSize(10); // 线程池大小:同时能执行10个定时任务
scheduler.setThreadNamePrefix("scheduled-task-"); // 线程名前缀,日志里能一眼识别是定时任务线程
scheduler.setWaitForTasksToCompleteOnShutdown(true); // 优雅停机:应用关闭时,等正在执行的任务完成
scheduler.setAwaitTerminationSeconds(60); // 最多等60秒,超时就强制关闭(避免卡死)
return scheduler;
}
// 第二步:把上面定义的线程池绑定到Spring定时任务框架
// 这里用方法注入(也可以用构造器注入,更推荐)
@Override
public void configureTasks(ScheduledTaskRegistrar taskRegistrar) {
// 把自定义的线程池传给任务注册器,替代Spring默认的单线程池
taskRegistrar.setTaskScheduler(taskScheduler());
}
}可以看到,我们先是定义了一个方法来创建线程池,并且加上了@Bean,为的就是直接交给IOC进行管理,避免每次调用的时候都需要创建
然后就是继承SchedulingConfigurer重写一下configureTasks,将上面方法创建出的线程池塞入
使用
package com.example.demo.config;
import org.springframework.scheduling.annotation.Scheduled;
import org.springframework.stereotype.Component;
@Component
public class ScheduledTasks {
// fixedRate:从上一次任务「开始执行」的时间算,每隔5秒执行
@Scheduled(fixedRate = 5000)
public void performTask() {
System.out.println("fixedRate任务执行:" + System.currentTimeMillis());
}
// fixedDelay:从上一次任务「执行完成」的时间算,隔5秒执行
@Scheduled(fixedDelay = 5000)
public void performDelayedTask() {
System.out.println("fixedDelay任务执行:" + System.currentTimeMillis());
}
// cron表达式:每天凌晨0点整执行(秒 分 时 日 月 星期)
@Scheduled(cron = "0 0 0 * * ?")
public void performTaskUsingCron() {
System.out.println("cron任务执行:" + System.currentTimeMillis());
}
}为什么不建议直接使用Spring的@Async
首先就是@Async默认是使用一个假的线程池来执行的,它其实是每次调用的时候就创建一个新的线程执行,这回导致:
- 每次都是创建新的线程,没有线程池复用机制,导致大量的性能开销
- 没有设置任务上限,那么一下子来很多的任务会导致创建很多个线程,最终OOM
此外异常处理缺失,如果我们不去处理异步线程的异常的话,就会导致异常被吞掉,连日志都没记录
为了应对异常丢失的情况,可以使用一下方式:
- 在异步线程中直接就处理异常
- 封装Future,主线程同步阻塞等待
- 全局异常处理器
此外,为了避免每次都创建新的线程,我们可以传入一个线程池
所以最佳的方式就是:
-
创建全局异常捕获器
@Component
public class GlobalAsyncExceptionHandler implements AsyncUncaughtExceptionHandler {
private static final Logger log = LoggerFactory.getLogger(GlobalAsyncExceptionHandler.class);// 统一处理所有无返回值的@Async方法异常 @Override public void handleUncaughtException(Throwable ex, Method method, Object... params) { log.error("异步方法执行异常!方法名:{},参数:{}", method.getName(), params, ex); // 重试逻辑 retryFailedTask(method, params, ex); // 告警 sendAlarm(ex, method); } // 重试逻辑 private void retryFailedTask(Method method, Object[] params, Throwable ex) { int retryCount = 3; while (retryCount > 0) { try { // 反射调用原方法重试 method.invoke(method.getDeclaringClass().newInstance(), params); log.info("异步方法{}重试成功,剩余次数:{}", method.getName(), retryCount - 1); return; } catch (Exception e) { retryCount--; log.warn("异步方法{}重试第{}次失败", method.getName(), 3 - retryCount, e); // 重试间隔1秒,避免频繁重试 try { TimeUnit.SECONDS.sleep(1); } catch (InterruptedException ie) { Thread.currentThread().interrupt(); } } } log.error("异步方法{}3次重试均失败,执行降级逻辑", method.getName()); } // 告警逻辑 private void sendAlarm(Throwable ex, Method method) { // 实际开发中可以对接钉钉/企业微信/邮件告警 log.error("【异步任务告警】方法{}执行失败,异常:{}", method.getName(), ex.getMessage()); }}
-
将这个全局异常捕获器绑定到Async中
@Configuration
@EnableAsync
public class AsyncConfig implements AsyncConfigurer {
// 注入自定义的全局异步异常处理器
private final GlobalAsyncExceptionHandler globalAsyncExceptionHandler;// 构造器注入 public AsyncConfig(GlobalAsyncExceptionHandler globalAsyncExceptionHandler) { this.globalAsyncExceptionHandler = globalAsyncExceptionHandler; } // 自定义异步线程池 @Override @Bean("asyncExecutor") public Executor getAsyncExecutor() { ThreadPoolTaskExecutor executor = new ThreadPoolTaskExecutor(); executor.setCorePoolSize(10); executor.setMaxPoolSize(50); executor.setQueueCapacity(100); executor.setThreadNamePrefix("async-task-"); executor.setRejectedExecutionHandler(new ThreadPoolExecutor.CallerRunsPolicy()); executor.setWaitForTasksToCompleteOnShutdown(true); executor.setAwaitTerminationSeconds(60); executor.initialize(); return executor; } // 绑定全局异常处理器 @Override public AsyncUncaughtExceptionHandler getAsyncUncaughtExceptionHandler() { return globalAsyncExceptionHandler; }}
同时使用@Transactional与@Async时,事务会不会生效?
分具体情况
-
同一个方法加了@Transactional @Async
@Service
public class UserService {@Transactional @Async public void register(String telephone, String inviteCode) { userMapper.save(user); userStreamMapper.insertStream(user, UserOperateTypeEnum.REGISTER); throw new UnsupportedOperationException(""); }}
会生效,虽然创建了新的线程,但是新线程执行的时候register是加了@Transactional,所以生效
-
加了@Transactional 的 方法调用 加了 @Async的方法
@Service
public class UserService {@Autowired UserStreamService userStreamService; @Transactional public void register(String telephone, String inviteCode) { userMapper.save(user); userStreamService.insertStream(user, UserOperateTypeEnum.REGISTER); throw new UnsupportedOperationException(""); }}
@Service
public class UserStreamService {@Async public void insertStream(User user) { userStreamMapper.insertStream(user, UserOperateTypeEnum.REGISTER); }}
事务的范围只在register,也就是register执行出现异常,事务会回滚这部分的写操作,如果insertStream出现异常,不会生效
-
加了@Async 的 方法调用 加了 @Transactional的方法
@Service
public class UserService {@Autowired UserStreamService userStreamService; @Async public void register(String telephone, String inviteCode) { userMapper.save(user); userStreamService.insertStream(user, UserOperateTypeEnum.REGISTER); }}
@Service
public class UserStreamService {@Transactional public void insertStream(User user) { userStreamMapper.insertStream(user, UserOperateTypeEnum.REGISTER); throw new UnsupportedOperationException(""); }}
事务的范围只在insertStream,register出现异常不会回滚
那说白了就是事务是以线程为维度的,事务的作用范围只在当前线程,当你通过新的线程去调用的时候,事务是否生效就是看你执行的这个方法是否加了@Transactional,加了会失效,但是失效的范围只在这个线程
注意:上面的调用都是类的外部调用的情况,如果是内部的this调用的话,一定不会生效的