目录
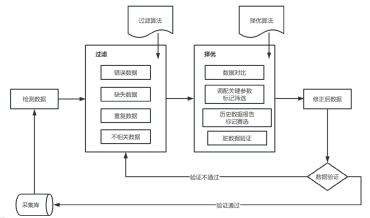
数据清洗就是把原始数据里的错误改掉、把格式标准统一、补齐缺失的部分,最终让数据完整、统一、真实有效,能直接拿来分析、建模。
很多人花大量时间研究模型、算法,可真到了实际项目里,卡住他们的往往不是模型选的对不对,而是数据不干净、不能用。
今天我给大家总结了最实用的8大数据清洗方法,能帮你解决绝大多数场景下的数据问题。
我给大家整理了一份数据仓库建设解决方案 ,里面包括数据标准的规范、数据治理的方法、数据仓库的搭建等等,都需要有明确的建设思路,有需要可以自取:https://s.fanruan.com/7igmg
一、处理缺失值
原始数据采集过程中,受采集设备故障、人工录入疏漏、数据源不完整等因素影响,必然会出现数据缺失的情况,这是数据清洗中最基础、最常见的问题。
说白了,缺失值处理就是针对数据集中空缺、未记录的内容,采取合理方式完善,避免缺失数据影响整体分析结果。
缺失值大致分三种情况:
**完全随机缺失(MCAR):**缺失和任何变量都没关系,纯粹是随机发生的,比如问卷填写时漏填了某一项。
**随机缺失(MAR):**缺失和其他已知变量有关,但和缺失变量本身无关。比如年龄较大的用户更倾向于不填收入,这时收入的缺失和年龄有关。
**非随机缺失(MNAR):**缺失本身就和那个变量的值有关。比如收入越高的人越不愿意填收入,这种情况最难处理。
搞清楚缺失类型之后,处理方式才有依据:
- 缺失比例低于5%,直接删除对应行,影响不大;
- 缺失比例在5%到30%之间,可以用均值、中位数、众数填充 ,或者用KNN插补、多重插补;
- 缺失比例超过30%,要认真考虑这一列是否还有保留价值,如果信息量太少,直接删列可能是更合理的选择;
- 对于MNAR类型的缺失,简单填充会引入偏差,建议单独建一个"是否缺失"的二值特征,把缺失本身当作一种信息保留下来。
二、处理重复数据
数据重复是数据整合、多源采集过程中的高频问题,同一数据记录多次录入、多平台同步冗余,会直接导致数据统计失真、计算结果偏大。
简单来说,删除重复项就是识别并清除数据集中完全一致或核心字段一致的冗余记录,保证每一条数据的唯一性。
- 最基础的是完全重复,每一列的值都一模一样,直接用drop_duplicates()就能解决。
- 但更麻烦的是部分重复,也叫近似重复。比如同一个用户在不同渠道注册了两次,姓名、手机号一样,但邮箱不同,这时候系统不会自动识别为重复,需要你手动定义"什么叫同一条记录"。
处理这类问题的思路是:
先确定业务主键 ,也就是能唯一标识一条记录的字段组合,然后基于主键做去重。如果同一个主键下有多条记录,再根据时间戳或数据来源优先级保留最新或最可靠的那一条。
还有一种情况是数据录入时的手误导致的近似重复 ,比如同一家公司名字写法不一致。这类问题需要用字符串相似度算法(如编辑距离、余弦相似度)来识别,再人工或半自动地合并。
三、处理异常值
异常值也被称为离群值,是数据集中与整体分布偏差极大的极端数值,这类数据可能源于录入错误、设备异常、特殊业务场景,若不处理会严重干扰统计结果、拉偏模型训练方向。
处理异常值的核心,是先精准识别,再针对性处置。
识别异常值常用的方法有几种:
- **3σ原则:**数据服从正态分布时,均值加减3个标准差之外的值可以视为异常;
- **IQR方法:**计算四分位距(Q3-Q1),低于Q1-1.5×IQR或高于Q3+1.5×IQR的值标记为异常,这个方法对非正态分布更稳健;
- 孤立森林(Isolation Forest):适合高维数据的异常检测,不依赖数据分布假设;
- **可视化检查:**箱线图、散点图是最直观的方式,很多异常值一眼就能看出来。
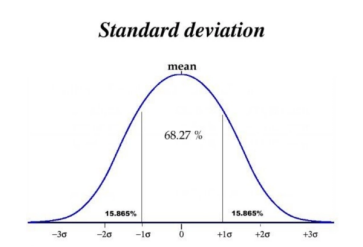
识别之后怎么处理?有几种选择:直接删除、用边界值替换(Winsorization)、单独建模处理、或者保留并标记。具体选哪种,取决于业务场景和异常值的比例。
四、数据类型转换
原始数据往往来自不同数据源,格式混乱、类型不统一是普遍问题,比如日期存在多种书写形式、数值以文本格式存储、字符编码不一致。
数据类型转换 ,就是将数据统一为标准格式、规范数据类型,让数据具备可计算、可匹配、可分析的基础属性。
最常见的几种情况:
- 日期字段被存成了字符串,导致无法做时间序列分析;
- 数值字段因为混入了特殊字符(比如货币符号、千分位逗号)而被识别成了字符串;
- 分类变量被存成了整数,但实际上这些整数没有大小关系,直接用于建模会引入错误的数值假设;
- 布尔值被存成了0/1整数,或者"是"/"否"字符串,需要统一处理。
处理的原则很简单,每一列的数据类型要和它实际代表的含义一致,比如
将不同格式的日期统一为标准日期格式,规范字符编码、单位符号、字段命名规则。
在做任何分析或建模之前,先把数据类型检查一遍,是一个好习惯。
五、标准化与归一化
实际数据中,不同字段的数值范围、量纲差异极大,比如身高以厘米为单位、收入以元为单位,数值跨度差距很大,这类数据直接用于分析或建模,会导致数值大的字段占据主导地位,影响结果公平性。
数据归一化和标准化是通过将数据缩放到特定范围(如0, 1)或调整为均值为0、标准差为1来处理不同量纲和范围的特征,以提高模型的训练效果。
归一化(Min-Max Scaling) :把数据线性压缩到**0,1区间**,适合数据分布不是正态分布、或者需要把特征限制在固定范围内的场景,比如神经网络的输入层。
计算公式:x'=(x - min) / (max - min)
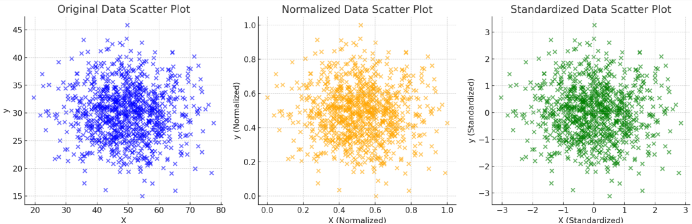
标准化(Z-score Standardization) :把数据转换成均值为0、标准差为1的分布,适合数据大致服从正态分布 、或者使用基于距离的算法(如KNN、SVM、PCA)的场景。
计算公式:z'=(x - mean) / std
归一化和标准化都只是对数据的线性变换,它们不会改变数据的分布形状,也不会消除异常值的影响。如果数据里有极端异常值,先处理异常值,再做缩放。
六、处理不一致数据
不一致数据是指同一个含义的数据在不同地方有不同的表达方式。这种问题在多数据源合并时尤其突出。
常见的不一致类型:
- **格式不一致:**日期有的写2024-01-01,有的写01/01/2024;电话号码有的带区号,有的不带;
- 单位不一致:同一个字段,有的记录用公里,有的用英里;
- **编码不一致:**性别字段有的用1/0,有的用M/F,有的用男/女;
- **大小写不一致:**城市名有的全大写,有的首字母大写,有的全小写。
处理这类问题没有特别高级的技巧,核心是建立统一的数据字典,明确每个字段的标准格式,然后用规则或映射表把所有记录统一转换过来。
当然,说起来简单,但真正落地时往往会遇到现实难题。企业内部同时运行着 ERP、CRM、MES、WMS 等多套业务系统,每套系统都有独立的字段命名、编码规则和时间格式,数据口径杂乱不一,清洗起来耗时又费力。
这种场景下,借助专业的数据集成工具能大幅提升效率。FineDataLink 正是为解决这类多源数据治理问题的一站式数据集成平台,它支持主流数据库、API 接口、文件系统等各类数据源,无需复杂编码,通过可视化低代码界面就能快速配置字段映射、格式转换、编码统一等核心清洗规则 ,轻松实现多系统数据的标准化整合。更关键的是,它支持实时增量同步,能在数据入库前就完成全流程清洗与标准化处理 ,从源头杜绝数据口径混乱,为后续的数据分析、数据仓库打好高质量的数据基础。工具链接我放在这里感兴趣的可以自行下载体验:https://s.fanruan.com/tx4dw
七、特征编码
原始数据里的分类变量,大多数模型是没办法直接处理的,需要先转换成数值形式。
常用的编码方式有以下几种:
标签编码(Label Encoding):把每个类别映射成一个整数。适合有序分类变量,比如学历(小学=1,初中=2,高中=3,大学=4)。如果用在无序分类变量上,会引入错误的大小关系。
独热编码(One-Hot Encoding):为每个类别创建一个二值列。适合无序分类变量,但当类别数量很多时,会产生大量稀疏列,增加计算开销。
目标编码(Target Encoding):用该类别对应的目标变量均值来替换类别标签。在高基数分类变量上效果好,但容易过拟合,需要配合交叉验证使用。
频率编码(Frequency Encoding):用该类别在数据集中出现的频率来替换类别标签。简单有效,不会引入目标变量信息,不存在过拟合风险。
选哪种编码方式,取决于变量是否有序、类别数量多少、以及后续使用的模型类型。树模型对编码方式不敏感,线性模型和神经网络则对编码方式的选择更挑剔。
八、处理文本数据
如果你的数据里有文本字段,清洗的工作量会比结构化数据大不少。
文本清洗的基本流程通常包括以下几步:
**去除噪声:**删除HTML标签、特殊符号、多余的空格和换行符,统一全半角字符。
**大小写统一:**英文文本全部转为小写,避免同一个词因大小写不同被识别成不同的词。
**分词:**中文文本需要分词(常用jieba),英文文本按空格分割即可,但需要处理连字符、缩写等特殊情况。
**去除停用词:**去掉"的"、"了"、"是"这类高频但无实际含义的词,减少噪声。
**词形还原或词干提取:**英文文本中,running、runs、ran都应该还原成run,避免同一个词的不同形态被当作不同特征。
**处理特殊实体:**根据业务需要,决定是否保留数字、日期、人名、地名等实体信息。
说白了,文本清洗没有固定的标准流程,每一步要不要做、怎么做,都取决于你的具体任务。情感分析和关键词提取对停用词的处理方式就不一样,不能套同一个模板。
最后
数据清洗不是一次性的工作,而是一个需要反复迭代的过程。在清洗数据的过程中,会不断发现新的问题,对数据的理解也会越来越深。数据清洗做扎实了,后面的分析和建模才有意义。