一、SQL Server
单表:sp_spaceused '表名'
单库:sp_MSforeachtable "sp_spaceused '?'" --对每一张表进行单表查询,不好用
那么怎么快速统计当前库数据量?让我先介绍一下SQL Server的page概念。
在 SQL Server 中,Page(页) 是数据存储的最小物理单位,所有的数据、索引、日志等最终都会以页为单位存储在磁盘上。
页的核心基础属性
- 固定大小 :SQL Server 中每个页的大小固定为 8KB(8192 字节),这是不可更改的系统设定。
- 页标识 :每个页都有唯一的标识
FileID:PageID(文件 ID + 页 ID),用于精确定位页的位置。- 页的结构 :一个 8KB 的页包含三部分:
- 页头(Page Header):占 96 字节,存储页的元数据(如页类型、所属对象 ID、页的可用空间、上 / 下一页指针等)。
- 数据区:占约 8060 字节,存储实际的数据行、索引项等核心内容。
- 行偏移数组:存储数据行在页内的偏移量,占用剩余字节(随数据行数变化)。
了解了页属性,我们就可以使用通过页的计算来明确我们当前数据库存储数据的大小
示例:
sql
SELECT
OBJECT_SCHEMA_NAME(t.object_id) AS 架构名, -- 从sys.tables获取架构信息
t.name AS 表名, -- 从sys.tables获取表名
SUM(p.rows) AS 行数, -- 从sys.partitions获取行数
-- 总空间 (MB) - 从sys.allocation_units获取页数
CAST(ROUND((SUM(a.total_pages) * 8 / 1024.00), 2) AS NUMERIC(36, 2)) AS 总空间_MB,
-- 数据空间 (MB) - 从sys.allocation_units获取数据页
CAST(ROUND((SUM(a.data_pages) * 8 / 1024.00), 2) AS NUMERIC(36, 2)) AS 数据空间_MB,
-- 索引空间 (MB) - 计算得出(已用页 - 数据页)
CAST(ROUND(((SUM(a.used_pages) - SUM(a.data_pages)) * 8 / 1024.00), 2) AS NUMERIC(36, 2)) AS 索引空间_MB,
-- 未使用空间 (MB) - 计算得出(总页 - 已用页)
CAST(ROUND(((SUM(a.total_pages) - SUM(a.used_pages)) * 8 / 1024.00), 2) AS NUMERIC(36, 2)) AS 未使用空间_MB
FROM
sys.tables t -- 主表:所有用户表改造使用:
sql
WITH TableSpace AS (
SELECT
t.object_id,
t.name AS 表名,
SCHEMA_NAME(t.schema_id) AS 架构名,
-- 行数
(SELECT SUM(rows) FROM sys.partitions p
WHERE p.object_id = t.object_id AND p.index_id IN (0,1)) AS 行数,
-- 总空间
(SELECT SUM(total_pages) * 8 / 1024.0 FROM sys.allocation_units a
INNER JOIN sys.partitions p ON a.container_id = p.partition_id
WHERE p.object_id = t.object_id) AS 总空间_MB,
-- 数据空间
(SELECT SUM(CASE WHEN a.type IN (0,1,4) THEN a.total_pages ELSE 0 END) * 8 / 1024.0
FROM sys.allocation_units a
INNER JOIN sys.partitions p ON a.container_id = p.partition_id
WHERE p.object_id = t.object_id) AS 数据空间_MB
FROM sys.tables t
WHERE t.is_ms_shipped = 0
)
SELECT
架构名,
表名,
行数,
CONVERT(DECIMAL(18,2), 总空间_MB) AS 总空间_MB,
CONVERT(DECIMAL(18,2), 数据空间_MB) AS 数据空间_MB,
CONVERT(DECIMAL(18,2), 总空间_MB - 数据空间_MB) AS 索引及其他空间_MB,
CONVERT(VARCHAR(20), CONVERT(DECIMAL(18,2), 总空间_MB)) + ' MB' AS 总空间_显示,
CONVERT(VARCHAR(20), 行数) + ' 行' AS 行数_显示
FROM TableSpace
ORDER BY 总空间_MB DESC;查询结果

总计汇总的sql:
sql
SELECT
DB_NAME() AS 数据库名,
CAST(SUM(size) * 8 / 1024.0 AS DECIMAL(18,2)) AS 总大小_MB,
CAST(SUM(CASE WHEN type = 0 THEN size ELSE 0 END) * 8 / 1024.0 AS DECIMAL(18,2)) AS 数据文件_MB,
CAST(SUM(CASE WHEN type = 1 THEN size ELSE 0 END) * 8 / 1024.0 AS DECIMAL(18,2)) AS 日志文件_MB,
CAST(SUM(size) * 8 / 1024.0 / 1024 AS DECIMAL(18,2)) AS 总大小_GB
FROM sys.database_files;
二、MySQL
老朋友比较直接
sql
-- 展示test03数据库test_01表的大小
SELECT * FROM information_schema.`TABLES` WHERE table_schema = 'test3' AND table_name = 'test_01';
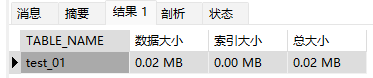
SHOW TABLE STATUS LIKE 'test_01';但是查询出来不容易读,data_length 记录的是字节数,所以需要进行换算

sql
-- 最常用的换算
SELECT
table_name,
CONCAT(ROUND(data_length / 1024 / 1024, 2), ' MB') AS 数据大小,
CONCAT(ROUND(index_length / 1024 / 1024, 2), ' MB') AS 索引大小,
CONCAT(ROUND((data_length + index_length) / 1024 / 1024, 2), ' MB') AS 总大小
FROM information_schema.TABLES
WHERE table_schema = 'test3'
AND table_name = 'test_01';结果
三、postgresql
postgresql分层为
PostgreSQL 服务器实例
│
├── 数据库1 (Database)
│ ├── 架构1 (Schema) ── 表、视图、函数等对象
│ ├── 架构2 (Schema) ── 表、视图、函数等对象
│ └── 架构3 (Schema) ── 表、视图、函数等对象
│
├── 数据库2 (Database)
│ ├── 架构1 (Schema)
│ └── 架构2 (Schema)
│
└── 数据库3 (Database)
└── 架构1 (Schema)
所以我们要明确的需要的是schema的数据量还是database的数据量
sql
-- 一个好用的函数
-- 1. 查询当前连接数据库的大小
SELECT pg_database_size(current_database());
-- 2. 查询指定名称的数据库大小
SELECT pg_database_size('数据库名');
-- 3. 查询所有数据库的大小
SELECT
datname AS 数据库名,
pg_database_size(datname) AS 字节数,
pg_size_pretty(pg_database_size(datname)) AS 可读大小
FROM pg_database
ORDER BY pg_database_size(datname) DESC;转换成好读的格式
sql
-- 查看数据库总大小(包含所有 schema)
SELECT
current_database() AS 数据库名,
pg_size_pretty(pg_database_size(current_database())) AS 数据库总大小;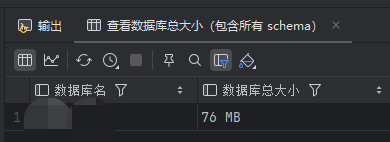
更多时候需要的会是个别schema的大小
主要使用两张表来达成我们的目的
pg_namespace- 存储所有schema(命名空间)的信息
pg_class- 存储所有数据库对象(表、索引、视图等)的信息
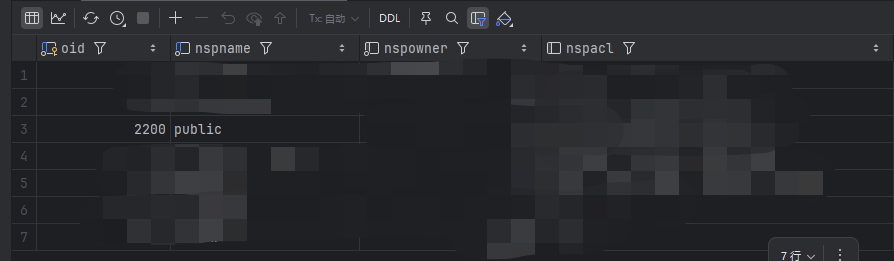
我的postgresql没有做大小写忽略,所以要拿oid去做联查
这是pg_namespace的数据,public是我要算的schema
接下来查询pg_class表,获取到11行数据,跟我们public中存储的表数量相同
sql
select * from pg_class where relnamespace = 2200 and relkind = 'r';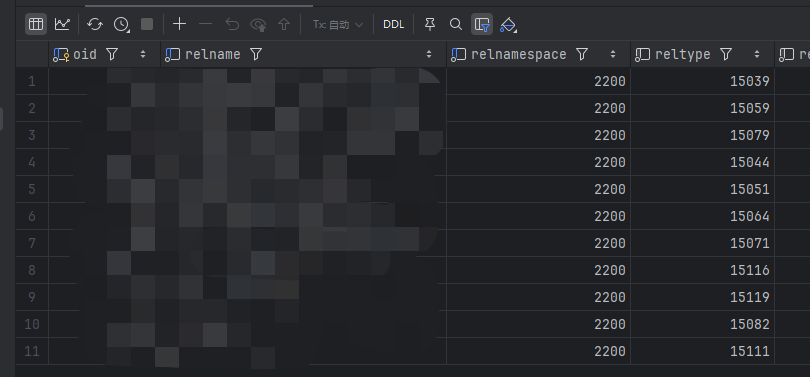
📋 pg_class 关键字段
字段 说明 在本SQL中的作用 oid对象的唯一ID 传给 pg_total_relation_size()计算大小relname对象名称 用 COUNT()统计表数量relnamespace所属schema的OID 与 pg_namespace.oid关联relkind对象类型 'r'表示普通表
relkind的可能值:
r= 普通表 (ordinary table)
i= 索引 (index)
S= 序列 (sequence)
v= 视图 (view)
m= 物化视图 (materialized view)
c= 复合类型 (composite type)
t= TOAST表
f= 外部表 (foreign table)
成品sql
sql
WITH schema_name_oid AS (
SELECT oid
FROM pg_namespace
WHERE nspname = 'public'
OR nspname ILIKE '%public%' -- 不区分大小写搜索
)
SELECT
'public' AS schema名,
COUNT(c.relname) AS 表数量,
pg_size_pretty(COALESCE(SUM(pg_total_relation_size(c.oid)), 0)) AS schema总大小
FROM pg_class c
CROSS JOIN ts_dmp_oid t
WHERE c.relnamespace = t.oid
AND c.relkind = 'r';
四、Oracle
单表查询
SELECT * FROM dba_segments WHERE owner = '架构名' AND segment_name = '表名';

读的话还是要处理一下
sql
SELECT
owner AS 所有者,
segment_name AS 段名称,
segment_type AS 段类型,
tablespace_name AS 表空间,
ROUND(bytes / 1024 / 1024, 2) AS 大小_MB,
ROUND(bytes / 1024 / 1024 / 1024, 4) AS 大小_GB,
blocks AS 块数,
extents AS 区数量
FROM dba_segments
WHERE owner = '架构名'
AND segment_name = '表名';查询当前schema(owner)的全部数据
sql
SELECT
owner,
ROUND(SUM(bytes) / 1024 / 1024, 2) AS 真实总大小_MB,
ROUND(SUM(bytes) / 1024 / 1024 / 1024, 4) AS 真实总大小_GB
FROM dba_segments
WHERE owner = 'xxxx'
GROUP BY owner;
dba_segments介绍
dba_segments是Oracle数据库中一张核心的系统视图。简单来说,你可以把它理解为一张记录了数据库中所有"储物箱"(段)详细信息的清单。在Oracle里,数据库的存储结构是分层的:数据库由多个表空间组成,表空间里又包含多个段。一个段就是一个占用存储空间的数据库对象。最常见的段就是表和索引。每当你创建一个表或索引,Oracle就会为它分配一个段来存放数据。
dba_segments表里有什么?
字段名 描述 你的关注点 OWNER段的拥有者,也就是哪个**模式(Schema)**拥有这个对象。 如果你想看某个用户(如 TS_DMP)下的所有对象,就用这个字段过滤。SEGMENT_NAME段的名称。 如果段是表,这里就是表名;如果是索引,这里就是索引名。 SEGMENT_TYPE段的类型。 这是关键字段 。它告诉你这个段到底是表、索引,还是大对象段(LOBSEGMENT)等。常见的类型有: TABLE,INDEX,LOBSEGMENT,TABLE PARTITION等。TABLESPACE_NAME这个段存储在哪个表空间中。 用于查看对象在表空间层面的分布情况。 BYTES段的实际大小,单位是字节。 这是你最关心的字段。它是计算空间占用的直接数据来源。 BLOCKS段占用的Oracle块数量。 可以结合数据库块大小(通常是8KB)来计算空间,但直接用 BYTES更准确。EXTENTS为这个段分配了多少个"区"(Extent)。 反映了段的碎片化程度和分配情况。
未完待续。。。
达梦