《数据结构选型指南》笔记
数据结构选型从来没有放之四海而皆准的最优解,本质上就是在业务的各类约束条件里做取舍、找平衡------ 你优先把某一类操作的性能拉满,就必然要在其他操作上付出性能代价,不存在样样都强的 "完美数据结构"。
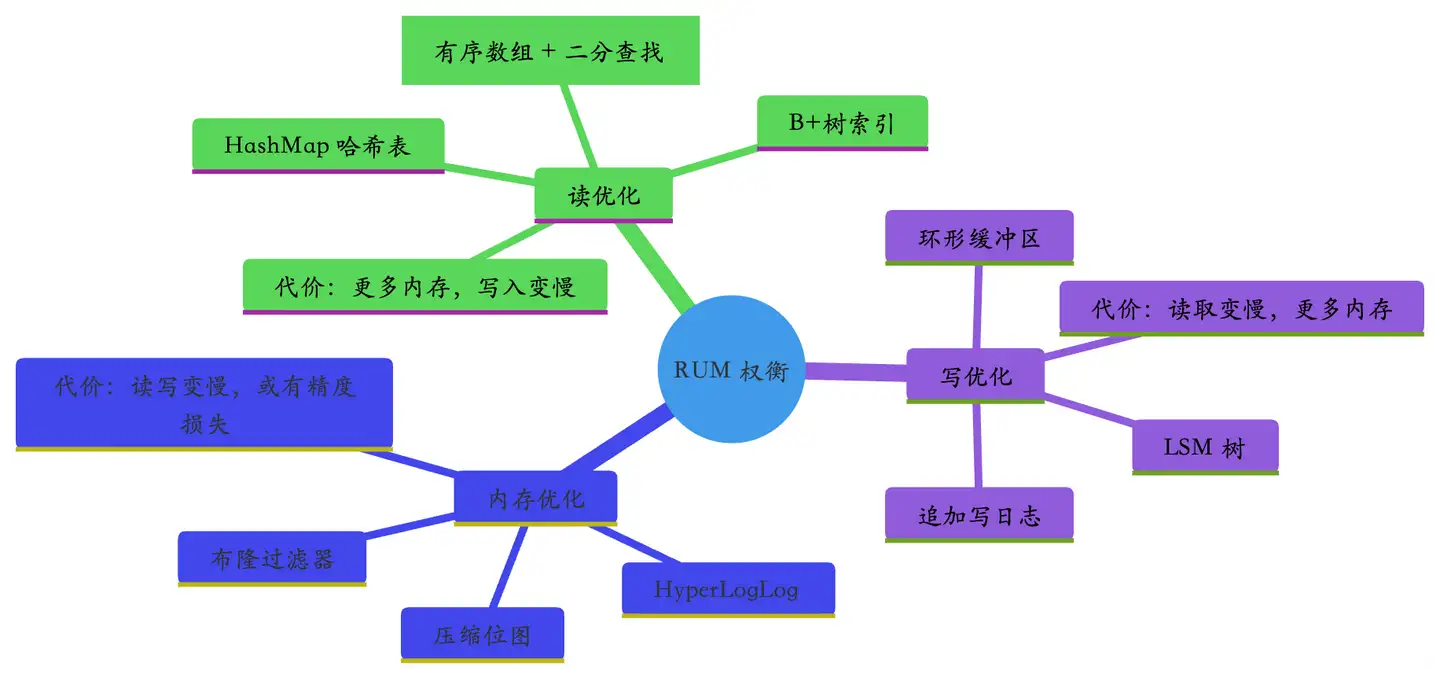
一、数据结构的 "不可能三角":RUM 猜想
没有任何一种数据结构,能同时做到「读得快(低读取开销 Read)、写得快(低更新写入开销 Update)、还省内存 / 磁盘(低内存占用 Memory)」。三者天生互斥,最多只能同时满足两项,必须妥协牺牲其中一项。
1. 要读得快,就得牺牲写入性能和存储空间
想让数据查得快,最直接的办法就是做「目录 / 索引」、给热点数据做缓存。
这就像给一本厚书做详细目录,找某一章内容几秒钟就能定位,但代价也很明确:
-
目录本身要占用书页(额外占用内存 / 磁盘空间);
-
书里新增、修改、删除内容时,目录也要同步更新,反而拖慢了内容修改的效率。
最典型的就是数据库给高频查询字段建索引:建完索引后,查询速度能提升数百上千倍,但每次插入、更新数据,都要同步修改所有相关索引,写入速度会明显下降,同时索引文件也会占用额外的存储空间。
数据库里如果某些字段经常出现在查询条件里,比如 user_id、email 之类,就会考虑给这些高频查询字段建立索引。建索引之前数据库每次查询都可能要像"全表翻找"一样扫描大量数据行,筛出符合条件的记录,所以数据量一大就会很慢;而建了索引之后,数据库多了一份类似"目录/索引表"的结构,查询时可以先根据目录快速定位到可能命中的位置,再去取具体数据,从"扫很多行"变成"快速定位少量行",因此查询速度就有可能出现数百到上千倍的提升。代价是:索引并不是只负责加速读,它还会跟着写入一起维护,所以每次插入、更新数据时,数据库不仅要更新主表数据,还要同步维护相关索引(必要时更新索引里的条目),这会增加额外的计算和磁盘/存储操作,从而让写入速度明显下降;同时索引本身也会占用额外存储空间,消耗磁盘容量,写入频繁时还可能带来更高的缓存和维护开销。总之,索引本质上是用"更快的查询"换"更慢的写入"和"更多的存储"。
2. 要写得快,就得牺牲读取性能
想让数据写得飞快,就要砍掉多余的索引、简化辅助结构,省去写入时的维护开销,最好只做 "往后追加写",完全不修改之前的内容。
这就像写流水账日记,每天只管在本子最后一页接着写,不用管之前的内容,一分钟就能写完;但如果之后想找某一天关于某件事的记录,就得从头翻完整本日记,找起来特别慢。
典型场景就是系统日志、设备时序数据:几乎不建索引,只做顺序追加写入,保证每秒几十万条数据能快速落盘;但后续要筛选、检索特定内容时,只能全量扫描,查询性能会非常差。
典型场景里,像系统日志和设备的时序数据这类"写多读少"的数据,通常会尽量不建索引,核心原因是:索引会拖慢写入,而这些业务往往要求把数据以非常高的吞吐量、低延迟快速落到磁盘上,比如每秒几十万条、甚至更多,最直接的做法就是把数据按时间顺序做顺序追加写入(append-only),让写磁盘尽量保持连续、减少随机读写带来的开销,从而更容易达到很高的写入性能;但当过了某个时间点需要筛选或检索"某个特定条件/关键字段"的历史数据时,因为几乎没有索引可用,数据库就只能把数据从头到尾依次读出来做过滤,也就是全量扫描(全表/全分区扫描),这样查询会非常慢、性能差,尤其是数据量一大时差距会被进一步放大。总的来说,这是一种"用写入换查询"的取舍:前期优先保证海量写入能力,后期如果要做复杂检索,就得依赖扫描或额外的离线/二级处理手段来弥补。
3. 要极致省空间,就得牺牲读写性能
想把内存 / 磁盘占用压到最低,最常用的办法就是数据压缩、稀疏存储。
这就像把一堆文件打包成压缩包,体积能缩小好几倍,但每次要打开、修改里面的文件,都得先解压、改完再重新压缩,多了好几步操作,自然就慢了。
比如对海量的用户埋点、日志文本做高压缩比存储,或是用稀疏结构存大量空值的表格,能把存储空间压缩数倍;但每次读写都要额外做编码、解码、解析处理,读写两端的速度都会同步下降。
比如对海量用户埋点和日志文本这类数据,如果采用高压缩比的存储方式(例如把文本做强压缩存起来),或者用稀疏结构来存那些大量为空值的字段表格,就可以显著减少需要落盘的数据量,通常能把存储空间压缩到原来的数分之一甚至更低;但代价是数据在写入时不再只是"直接存原样",而要先做编码/压缩或稀疏化转换,同时在读取时还要再进行解码/解压和解析,甚至可能要先把压缩块或稀疏索引还原成可用的数据,再继续完成业务处理,因此每次读写都会引入额外的 CPU 开销和延迟,最终表现为读写两端的吞吐量和响应速度都会同步下降。
二、工业界经典选型
案例 1:MySQL InnoDB 为什么选 B+ 树做索引?------ 优先保障读性能
补充 B + 树核心知识点
B + 树是一种多叉平衡树,和课本里学的二叉搜索树、红黑树最大的区别,是它专门为磁盘存储设计,核心解决「磁盘 IO 太慢」的行业痛点,核心设计有 3 点:
-
只有叶子节点存真实数据,非叶子节点只存索引键:这是 B + 树和 B 树最核心的区别。非叶子节点不存数据,就能在同样大小的磁盘页里,放下更多的索引键,让树的高度变得极矮 ------ 百万级别的数据,B + 树的高度通常只有 3\4 层,意味着一次查询最多只需要 3\4 次磁盘 IO;而红黑树这类二叉树,树高能到 20 层,要 20 次磁盘 IO,速度差了几个量级。
-
所有叶子节点用双向链表有序串联:所有数据都按顺序排好存在叶子节点里,且前后节点通过指针串联,无需回溯父节点就能连续访问。
-
范围查询、分页遍历天生友好:比如要查「订单金额 100~200 元的所有订单」,只要找到 100 元对应的叶子节点,顺着链表往后走就能拿到所有符合条件的数据,效率极高。
选型的取舍逻辑
MySQL 的主流业务,都是读多写少 的场景(比如电商订单、用户信息查询,读请求占比通常超 90%),核心诉求就是把读性能拉满。
B + 树完美适配了这个需求:单点查询、范围查询、排序分页的效率都做到了极致;但代价也非常明确:
-
插入、更新、删除数据时,为了维持树的平衡,经常要做页分裂、页合并(就像笔记本的页写满了,要撕成两半重新调整,还要更新目录),写入和更新的开销会大幅拉高;
-
索引本身要占用大量磁盘空间,大表的索引文件甚至能比数据文件本身还大。
案例 2:Cassandra、RocksDB 为什么用 LSM 树?------ 优先保障写性能
补充 LSM 树核心逻辑
LSM 树全称「日志结构合并树」,核心设计思路就是把随机写转化为批量顺序写,彻底规避磁盘随机 IO 的性能损耗:
-
所有新增、修改的数据,先写进内存里的缓冲区(MemTable),内存写满后,就把这部分数据排序,一次性顺序写到磁盘上,生成一个不可修改的有序文件(SSTable);
-
后台会定期把多个小的 SSTable 合并成大文件,清理重复、已删除的数据,避免文件过多影响查询。工业界通常会搭配布隆过滤器,快速判断数据是否在某个文件里,缓解读放大问题。
选型的取舍逻辑
这类数据库面向的是海量日志、时序数据、高吞吐写入 的场景(比如物联网设备上报数据、系统监控指标),一秒钟要写入几十万甚至上百万条数据,核心诉求就是极致的写入性能。
LSM 树把随机写全变成了顺序写,写入能力比 B + 树高了几个量级;但短板也非常明显:
- 数据分散在多层的 SSTable 文件里,查询的时候要从新到旧逐层遍历、合并检索,读放大问题严重(本来只想查 1 条数据,结果要读好几个文件),读取效率被大幅牺牲。
案例 3:Redis 近似 LRU 淘汰策略 ------ 优先保障内存占用
补充 LRU 背景知识
LRU 全称「最近最少使用」,是缓存最常用的淘汰策略:内存满了的时候,就把最久没被访问过的数据删掉,给新数据腾地方。
如果要做 100% 精准的 LRU,需要维护一个双向链表,每次访问一个 Key,就要把它挪到链表头部,淘汰的时候删掉链表尾部的 Key;但在 Redis 百万级、千万级 Key 的场景下,这个链表要维护大量的指针和排序信息,内存开销极高,完全不划算。
选型的取舍逻辑
Redis 是内存数据库,内存就是最宝贵的资源,所以核心诉求是极致压缩内存开销 ,同时保证淘汰效果够用即可。
所以 Redis 放弃了严格精准的 LRU 实现,做了一个极简的设计:
-
只为每个 Key 存储一个 24 位的时钟标记,记录这个 Key 最后一次被访问的时间(精度 1 秒,24 位可记录 194 天,完全满足业务需求);
-
内存满了要淘汰的时候,随机采样 N 个 Key(默认 5 个),从中选出最久没被访问的 Key 删掉;
-
用极小的内存开销,实现了和精准 LRU 几乎一致的淘汰效果,代价只是牺牲了一点点算法的精准度,完全不影响业务使用。
补充案例:Redis 哈希对象的双编码设计 ------ 动态的 RUM 取舍
Redis 的哈希表(Hash 类型),会根据数据量自动切换两种编码,也是 RUM 三角的典型应用:
-
数据量小时,用 \\ziplist(压缩列表)\\ 存储:把所有数据紧凑地存在一段连续的内存里,极致省内存,小数据量下读写也足够快;
-
数据量超过阈值(默认元素超过 512 个,或单个元素超过 64 字节),自动切换成hashtable(哈希表):牺牲一点内存开销,换来 O (1) 的读写性能,适配大数据量的场景。
当哈希里的元素数量较少(以及/或者单个元素较短)时,Redis 会用类似 ziplist(压缩列表)的结构来存储,把多个键值尽可能紧凑地放在连续的一段内存里;这种方式非常省内存,数据也局部性好,所以在"小数据"阶段读写通常也会比较快。随着元素变多到超过阈值(例如默认情况下元素个数超过 512 个,或单个元素超过 64 字节)后,Redis 就会自动切换到真正的哈希表结构(hashtable):它会消耗更多内存来维护桶、指针等元数据,但换来的好处是读写可以更接近 O(1)的哈希查找性能,更能支撑"大数据量"下的访问效率与延迟稳定性。
三、5 步搞定数据结构选型
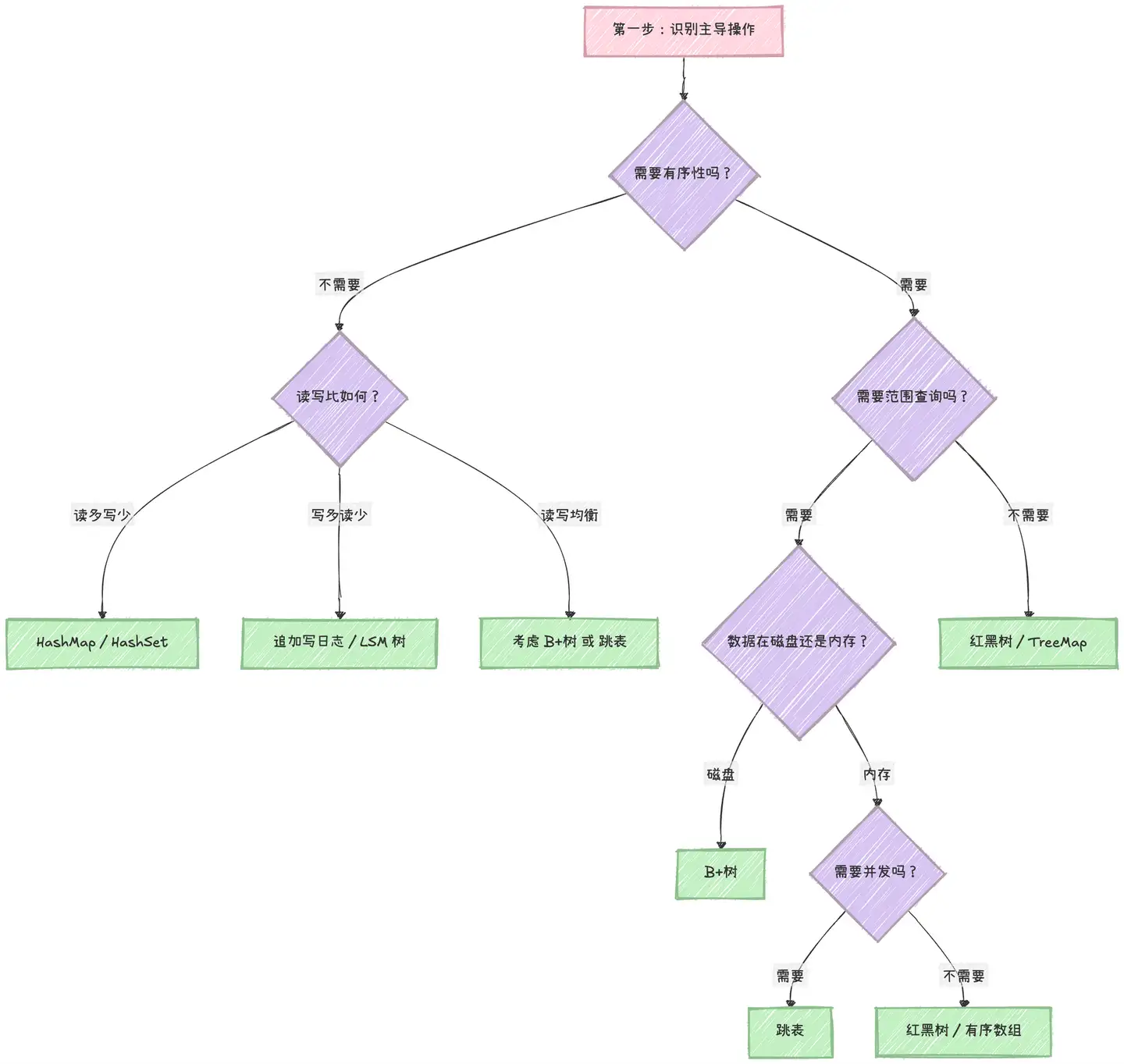
第一步:先找准「核心主导操作」
先问自己一个问题:我的业务里,哪种操作调用频次最高、延迟要求最严?
这是选型的第一性原理 ------ 先把最核心、最不能慢的操作保住,其他操作都可以做妥协。
举个例子:外卖平台的订单缓存模块,按订单号精准查单的调用量,是按时间范围筛选订单的 20 倍以上,那核心主导操作就是「单点精准查询」,直接把选型范围缩小到哈希表、B + 树这类单点查询高效的结构里。
第二步:判断业务是否强依赖「数据有序性」
再问第二个问题:我的业务需要排序、范围查询、Top-K 筛选、分页遍历吗?
如果答案是 "是",那哈希表、哈希集合这类无序结构 可以直接排除 ------ 它们单点查询超快,但完全没法按顺序遍历、按区间找数据。
比如电商销量榜单、朋友圈时间线、价格区间过滤、按时间范围查日志,这些场景都强依赖数据有序性,必须优先考虑跳表、B + 树、平衡树这类有序结构。
第三步:量化评估真实的「读写比例」,别靠直觉
这是选型里最容易踩的坑:很多人全凭主观感觉判断 "我的业务读写均衡",但一实测,读请求占比超 90%,选型方向完全错了。
正确的做法是:上线前在测试环境做完整的压测,用性能分析工具统计各类操作的真实调用频次、耗时占比。
-
读多写少(读占比超 80%):优先保读性能,选 B + 树、哈希表这类结构;
-
写多读少(写占比超 60%):优先保写性能,选 LSM 树、顺序日志这类结构;
-
读写极度均衡:就要做更精细的权衡,比如用 "写内存 + 异步刷盘" 的架构,兼顾读写。
第四步:结合「存储介质」和「并发场景」做适配
同样的数据结构,在内存里用和在磁盘上用,效果天差地别;单线程用和高并发用,选型也完全不一样。
先看存储介质:磁盘 vs 内存
-
磁盘(尤其是机械盘):顺序读写速度是随机读写的几千倍,所以一定要优先规避随机 IO,选 B + 树、LSM 树这类能把随机 IO 转成顺序 IO 的结构。比如 Kafka 就是靠纯日志追加的顺序写,实现了超高的写入吞吐。
-
内存:随机访问和顺序访问的速度差距极小,不用再纠结 IO 的问题,核心要关注「CPU 缓存命中率」,数组这类连续存储的结构,缓存命中率远高于链表,很多场景下性能反而更好。
再看并发场景:高并发下的锁开销
高并发内存场景里,并发安全的锁竞争,往往比算法本身的时间复杂度更影响性能。
比如跳表和红黑树的核心差异:
-
跳表的插入、删除,只需要修改局部几个节点的指针,修改范围极小,加锁的粒度可以做得很细,高并发下锁冲突的概率极低;
-
红黑树的插入、删除,经常要做全局的旋转平衡操作,几乎要锁住整棵树,锁粒度大,并发开销极高。
这也是 Redis 的有序集合 zset 不用红黑树、而用跳表的核心原因之一,同时跳表的范围查询也比红黑树更便捷。
第五步:用基准测试拍板,拒绝 "唯理论复杂度" 选型
课本里的算法时间复杂度,只统计了运算的次数,完全忽略了硬件缓存、内存布局、IO 开销这些真实世界里的关键因素,很容易误导判断。
最经典的误区:课本说「链表中间插入是 O (1),数组中间插入是 O (n),链表插入更快」。
但真实的基准测试结果完全相反:同等环境下,百万级小元素的集合里,数组的中间插入速度,比链表快上百倍。
背后的真相
-
链表的 O (1),只算了修改指针的开销,完全没算「遍历找到插入位置」的开销,还有 CPU 缓存失效的损耗;
-
CPU 的高速缓存,访问速度比主存快 100 倍以上,而缓存是按「缓存行」(通常 64 字节)加载的:数组是连续存储的,一次能加载好几个元素到缓存里,后续访问几乎全是缓存命中,速度极快;
-
而链表的节点是分散在内存各处的,每次访问一个节点,几乎都会触发缓存失效,要去主存里拿数据,速度一下子就慢下来了。
C++ 之父 Bjarne Stroustrup 也做过极端实验:五十万次有序插入场景下,链表耗时近两小时,而动态数组仅需一分多钟,性能差距悬殊。
但别走极端:数组不是永远比链表好
当元素的体积变大,比如单个元素 4KB,数组插入要拷贝大量元素,这时候拷贝的开销,就会远远超过缓存失效的损耗,链表的效率反而能领先数组 20 倍。
归根结底:脱离元素尺寸、业务负载、硬件特性,单纯对比数据结构的理论复杂度,和脱离剂量谈毒性一样,毫无意义。
所以选型的最后一步,一定是针对你的真实业务场景,做基准测试,用实测数据说话,而不是靠课本理论、靠直觉拍板。
四、常用数据结构选型速查表 & 避坑指南
1. 常用数据结构选型速查表
| 数据结构 | 核心优势 | 核心短板 | 最佳适用场景 |
|---|---|---|---|
| 数组 / 动态数组 | 连续存储,缓存命中率极高,随机访问 O (1),遍历极快 | 中间插入、删除需要拷贝元素,开销大 | 读多写少、元素体积小、频繁随机访问和遍历的场景 |
| 链表 | 头尾插入删除 O (1),中间插入删除(寻址完成后)O (1),无需连续内存 | 随机访问极慢,缓存命中率极低,遍历开销大 | 元素体积大、频繁在头尾增删、极少随机访问的场景 |
| 哈希表 | 单点增删查改都是 O (1),性能极高 | 无序,无法做范围查询,有哈希冲突开销,内存占用较高 | 仅需单点精准查询,无需排序、范围查询的场景(如用户信息缓存、订单查询) |
| 跳表 | 有序,单点查询 O (logn),范围查询极方便,增删锁粒度小,并发友好 | 内存占用比红黑树略高,有多层索引开销 | 高并发内存场景、需要有序 + 范围查询的场景(如 Redis zset) |
| 红黑树 | 有序,严格平衡,查询性能稳定,无跳表的多层冗余 | 增删需要旋转平衡,锁粒度大,并发性能差,范围查询麻烦 | 单线程场景、需要有序且查询性能稳定的场景(如 C++ STL 的 map) |
| B + 树 | 专为磁盘设计,树高矮,磁盘 IO 少,范围查询极强,有序性好 | 写入更新开销大,页分裂合并耗性能,索引占用空间大 | 磁盘存储、数据库索引、读多写少、需要范围查询的场景 |
| LSM 树 | 极致写入性能,把随机写转成顺序写,高吞吐 | 读放大严重,查询性能弱,后台合并占用资源 | 写多读少、海量数据高吞吐写入的场景(时序数据库、日志存储) |
2. 选型常见避坑指南
-
避免唯时间复杂度论:不要只看 O (1)、O (logn),一定要考虑硬件特性、缓存命中率、IO 开销这些真实因素,很多时候 O (n) 的数组,比 O (1) 的链表还快。
-
避免过度设计:如果你的业务数据量只有几千、几万条,用最简单的数组、哈希表就足够了,完全没必要上 B + 树、跳表这类复杂结构,反而增加维护成本。
-
避免静态选型:业务是会动态变化的,比如一开始数据量小,用 ziplist 省内存,后来数据量暴涨,就要及时切换成 hashtable;一开始读多写少,后来变成写多读少,就要调整结构。
-
不要追求完美:永远记住 RUM 不可能三角,没有完美的数据结构,只有最适合你业务场景的取舍。
五、RUM 猜想的工程实践版
真实的业务开发里,几乎不会出现 "非黑即白硬牺牲某一项能力" 的极端场景。RUM 猜想的工程实践核心,从来不是死记 "必须牺牲一个" 的理论铁律,而是用多结构组合、分层设计、动态适配的思路,在三角约束里找动态平衡------ 先把核心业务诉求的性能拉满,再把另外两项的牺牲代价,压缩到业务完全可接受的范围,最终实现 "核心能力无短板,非核心能力不拖后腿,资源开销可控" 的工程最优解。
简单来说,理论上 RUM 三角告诉你 "鱼和熊掌不可兼得",但工程实践要解决的,是 "怎么用最小的代价,同时拿到鱼的核心营养和熊掌的核心价值,而不是直接扔掉其中一个"。就像买车的 "省油、动力强、价格低" 不可能三角,不是让你硬选 "牺牲动力买便宜省油的车",而是用混动技术,先守住日常通勤省油的核心诉求,再兼顾足够的动力,同时把价格控制在预算内,这就是工程化的平衡思路。
1. 工程实践的核心逻辑:从 "单选牺牲" 到 "组合平衡"
纯理论场景里,我们会把单个数据结构套进 RUM 三角里做取舍,但真实业务里,90% 的性能优化方案,都不是靠单个数据结构硬扛所有场景,而是用 "主索引 + 辅助索引" 的多结构组合,让每一种查询模式,都命中它最擅长的那个数据结构。
这套实践逻辑,完全遵循 RUM 三角的底层约束,但跳出了 "非此即彼" 的单选陷阱,核心只有 3 步:
- 锚定不可让步的底线:先明确业务里 "绝对不能慢、绝对不能省" 的核心诉求,把它作为 RUM 三角里的第一优先级,绝不妥协;
- 划定可接受的牺牲边界:剩下的两个维度,明确业务能接受的上限(比如写入延迟不超过 100ms、内存开销增幅不超过 10%),只要不超过这个边界,就属于可接受的妥协;
- 用组合设计做平衡:用不同的数据结构承接不同的操作场景,核心场景用最优结构拉满性能,非核心场景用辅助结构兜底,把牺牲的代价控制在预设的边界内。
2. RUM 工程实践的经典落地案例
所有工业界成熟的组件、业务里的性能优化方案,本质上都是这套组合平衡逻辑的落地。
案例 1:订单管理系统缓存优化 ------ 贴合业务场景的最小代价平衡
先明确场景的 RUM 约束
- 不可让步的底线:读性能(Read)。经实测,按订单号单点查询的调用频率,是其他操作的 20 倍以上,是用户支付、查单的核心主链路,延迟必须控制在毫秒级;
- 可接受的牺牲边界:写入性能(Update),订单创建、更新的频率远低于查询,只要写入延迟不超过 200ms,业务完全无感知;内存占用(Memory),只要内存开销增幅不超过 10%,完全在服务器资源预算内。
错误的 "单选" 尝试(完全贴合 RUM 理论的极端牺牲)
- 单数组存储:为了省内存、保写入,直接牺牲了核心读性能,
contains查询占了 CPU 时间的 37%,主链路出现严重卡顿; - 单哈希表存储:把核心点查性能拉满,但牺牲了范围查询、过期清理的读性能,运营筛选订单、定时清理过期数据需要全量遍历,低频操作也出现超时;
- 单排序数组存储:兼顾了范围查询的读性能,但牺牲了写入性能,插入删除需要移动大量元素,订单创建延迟超标。
最终方案:组合设计的 RUM 平衡
我们最终采用 「哈希表做主索引 + 按时间排序的数组做辅助索引」 的双结构组合,两个结构通过订单号做关联,没有全量数据冗余,完美实现了三角平衡:
- Read(读性能,底线不妥协):核心的订单号单点查询,完全交给哈希表承接,保持 O (1) 的极致性能;低频的时间范围筛选、过期订单清理,交给有序数组承接,通过二分查找快速定位区间,无需全量遍历,所有读场景的性能全部达标;
- Update(写性能,可控牺牲):订单创建、更新时,需要同时维护两个结构,确实增加了少量写入开销,但实测写入延迟仅增加了不到 50ms,远低于 200ms 的业务容忍边界,用户完全无感知;
- Memory(内存占用,可控牺牲):辅助索引只存储了 "订单号 + 创建时间" 的极简数据,没有冗余完整订单信息,内存开销仅增加了 7%,远低于 10% 的预算上限,完全可控。
这个方案的精髓,从来不是 "选哈希表还是选数组",而是用组合设计,把核心的读性能拉满,同时把写和内存的牺牲,控制在业务完全感知不到的范围内。理论上 RUM 三角必须牺牲一项,但工程实践里,我们把牺牲的代价降到了可以忽略不计的程度,这就是工程师的核心价值。
案例 2:Redis ZSet 双结构设计 ------ 工业级的三角最优解
先明确场景的 RUM 约束
- 不可让步的底线:读性能(Read)。既要保证按成员单点查分的 O (1) 性能(比如查某个用户的直播积分),也要保证按分数范围查询、排名计算的 O (logn) 性能(比如积分排行榜、Top100 筛选),两类都是业务高频操作,绝不能牺牲其中一个;
- 可接受的牺牲边界:写入性能(Update),榜单数据需要实时更新,写入延迟不超过 10ms 即可;内存占用(Memory),只要同数据量下,内存开销不超过红黑树的 20%,完全可接受。
单选的天然困境(理论上的必然牺牲)
- 单哈希表:单点查分性能拉满,但完全无法做范围查询、排名计算,直接牺牲了一半的核心读需求;
- 单跳表 / 红黑树:兼顾了范围查询和写入性能,但单点查分需要 O (logn) 遍历,牺牲了高频单点读的核心性能;
- 单双链表:能维护排序,但读写性能全不达标,完全不符合需求。
最终方案:组合设计的 RUM 平衡
Redis 最终采用 「跳表 + 哈希表」 的双端口双结构组合,两套结构共享数据实体,仅通过指针关联,无任何数据冗余,完美实现了三角平衡:
- Read(读性能,底线不妥协):按成员单点查分,完全交给哈希表承接,实现 O (1) 的极致性能;按分数范围查询、排名计算,交给跳表承接,通过 span 字段记录节点跨度,实现 O (logn) 的高效查询,两类核心读需求全部拉满,无任何妥协;
- Update(写性能,可控牺牲):写入时仅需同时维护两个结构的指针,增加的开销微乎其微,跳表本身的写入就是 O (logn),且仅需修改局部指针,并发友好,实测写入延迟仅增加了不到 2ms,远低于业务容忍边界;
- Memory(内存占用,可控牺牲):两套结构仅共享数据、冗余指针,没有数据副本,内存开销仅比单红黑树高了不到 15%,远低于预设的 20% 上限,完全可控。
案例 3:Elasticsearch 多架构组合 ------ 检索场景的 RUM 集大成者
先明确场景的 RUM 约束
- 不可让步的底线:读性能(Read)。既要保证全文检索的毫秒级响应,也要保证字段过滤、聚合统计的高效性,还要能快速取回完整文档,所有检索场景的性能都不能妥协;
- 可接受的牺牲边界:写入性能(Update),日志、业务数据的写入,只要延迟不超过 1s,业务完全可接受;存储开销(Memory/Disk),只要压缩比不低于原始数据的 3 倍,就在资源预算内。
最终方案:多结构组合的 RUM 平衡
Elasticsearch 没有用单一结构硬扛所有场景,而是用一套 "多结构协同" 的架构,实现了三角的极致平衡:
- Read(读性能,底线不妥协):全文检索用倒排索引拉满性能,词条快速定位用 FST(有限状态转换器)做索引压缩,极致加速词条查找;字段过滤、聚合统计用 doc_values 列式存储,避免全文档扫描;完整文档取回用_source 行存,一次 IO 就能拿到全量数据。多结构各司其职,所有读场景的性能全部拉满,无任何核心妥协;
- Update(写性能,可控牺牲):底层采用 LSM 树架构,把随机写转化为批量顺序写,写入先进入内存缓冲区,再批量有序刷盘,同时后台异步合并索引文件,把多索引的维护开销,通过批量操作降到最低,实测写入性能完全满足海量日志的实时写入需求,延迟控制在业务可接受范围内;
- 存储开销(Memory/Disk,可控牺牲):用 FST 对倒排索引做极致压缩,内存占用比纯哈希表低 90% 以上;doc_values 用增量编码、压缩算法,磁盘占用比原始数据低数倍;_source 默认用 LZ4 压缩,存储开销直接压缩到原始数据的 1/3,完全在预算范围内。
3. RUM 工程实践的 3 个落地避坑原则
原则 1:先定 "不可让步的底线",再谈 "可接受的牺牲"
永远不要为了理论上的 "完美平衡",牺牲业务的核心生命线。先通过压测、线上 profiling 拿到真实的业务数据,明确哪个操作是核心主链路、哪个性能指标是绝对不能妥协的,把它作为选型的第一优先级,剩下的维度,只要在业务可接受的边界内,就可以做合理妥协。
反面案例:为了省一点服务器内存,不给订单表的 user_id 查询字段建索引,导致用户端查单接口超时,核心主链路出问题,就是典型的本末倒置。
原则 2:用 "多结构组合" 替代 "单一结构硬扛",用最小的空间换可控的时间
不要指望一个数据结构解决所有业务场景,就像你不能指望一把螺丝刀搞定所有装修活。高频核心操作,用最优的主索引承接性能;低频非核心操作,用极简的辅助索引兜底,用极少量的空间冗余(通常只是指针、键值的冗余,而非全量数据副本),换来全场景的性能达标。
这也是为什么几乎所有数据库、中间件,都采用 "主索引 + 多个二级索引" 的设计,本质上就是用多结构组合,平衡 RUM 三角的约束。
原则 3:用 "动态适配" 替代 "静态选型",让结构跟着业务变
业务的访问模式、数据量永远是动态变化的,今天数据量只有几千条,读多写少,明天可能就涨到百万级,变成写多读少。你的选型设计,必须预留动态适配的空间,而不是一次选型定终身。
最典型的就是 Redis 的双编码设计:数据量小时用 ziplist 极致省内存,数据量超过阈值自动切换为 hashtable 保性能;还有 MySQL 的索引优化,业务初期只需要主键索引,随着用户量增长、查询场景变多,就要逐步新增联合索引、辅助索引,适配业务的变化。
六、最终
RUM 不可能三角给了我们数据结构选型的底层逻辑,而工程实践的核心,就是把这套理论落地到真实业务里。数据结构选型的本质不是选择,是组合与权衡。而权衡的前提,是你清楚地知道自己在优化什么、愿意牺牲什么。