1、分布式并行策略
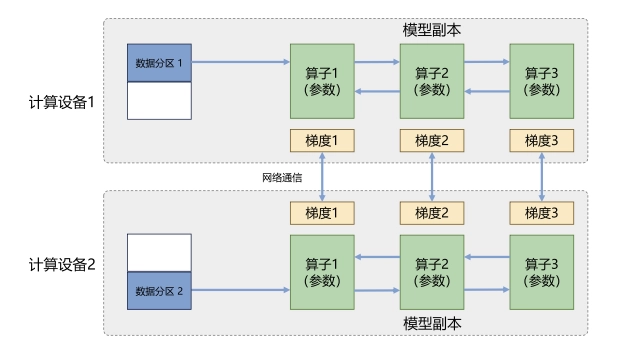
1、数据并行
2、模型并行
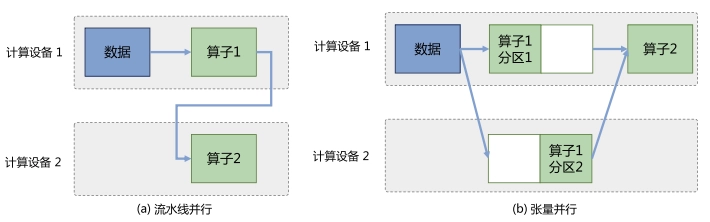
1、流水线并行
1F1B 非交错式调度模式
1F1B 交错式调度模式
2、张量并行
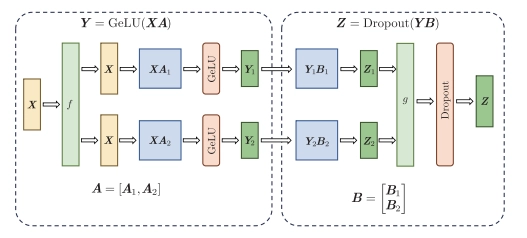
FNN 结构的张量并行示意图
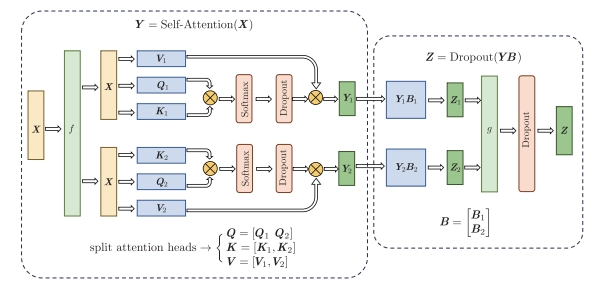
多头自注意力机制的张量并行示意图
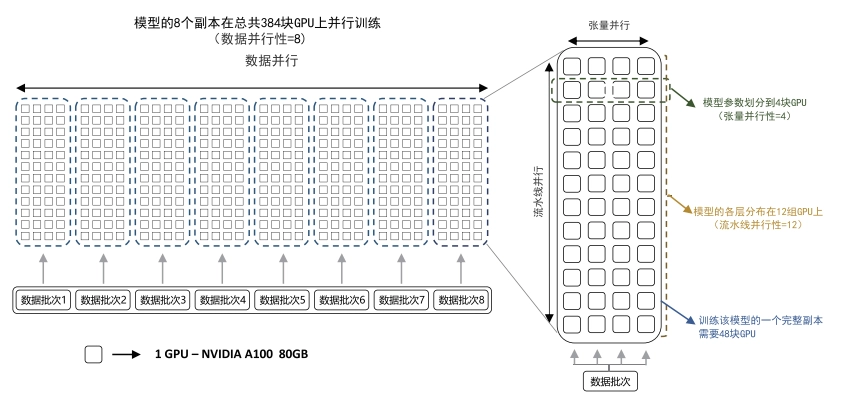
3、混合并行
混合并行将多种并行策略如数据并行、流水线并行和张量并行等混合使用
2、内存优化
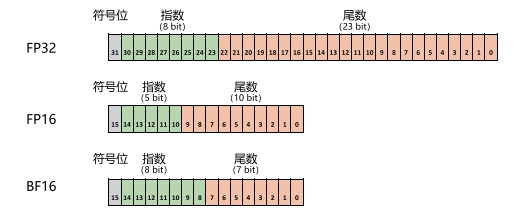
1、混合精度
动态损失缩放(Dynamic Loss Scaling)和混合精度优化器(Mixed Precision Optimizer)
由于 FP16 的值区间比 FP32 的值区间小很多,所以在计算过程中很容易出现上溢出和下溢出。
BF16 相较于 FP16 以精度换取更大的值区间范围。
2、Adam 优化器
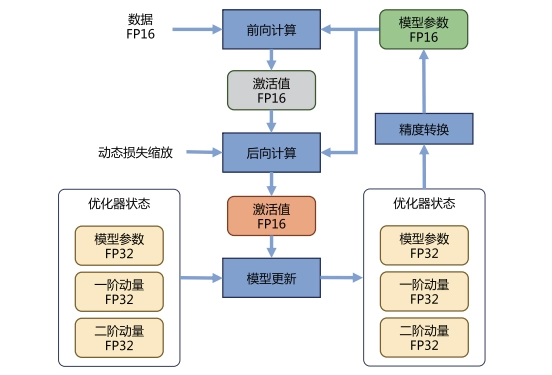
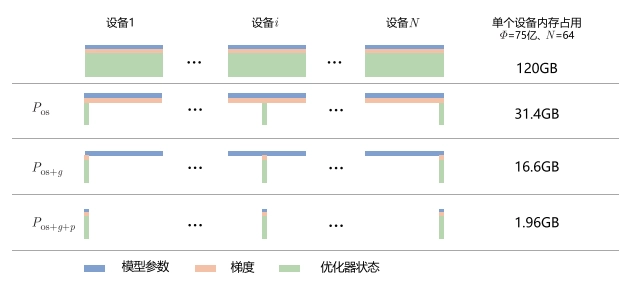
Adam 优化器状态包括采用 FP32 保存的模型参数备份,一阶动量和二阶动量也都采用 FP32 格式存储。假设模型参数量为 Φ,模型参数和梯度都是用 FP16格式存储,则共需要 2Φ + 2Φ + (4Φ + 4Φ + 4Φ) = 16Φ 字节存储。
一阶矩 mtm_tmt 的更新公式为
核心公式: mt=β1mt−1+(1−β1)gtm_t = \beta_1 m_{t-1} + (1 - \beta_1) g_tmt=β1mt−1+(1−β1)gt
• mtm_tmt: 当前的一阶矩(带有惯性的方向)。
• β1\beta_1β1: 遗忘因子,通常设为 0.9 。这意味着当前的方向 90% 取决于历史惯性,只有 10% 取决于当前脚下的真实梯度 gtg_tgt。
二阶矩 vtv_tvt 的更新公式为:
vt=β2vt−1+(1−β2)gt2v_t = \beta_2 v_{t-1} + (1 - \beta_2) g_t^2vt=β2vt−1+(1−β2)gt2
• vtv_tvt: 当前的二阶矩(梯度波动大小的度量)。
• gt2g_t^2gt2: 当前梯度的平方(逐元素平方,抹除了方向,只看大小)。
• β2\beta_2β2: 通常设为 0.999,说明二阶矩会参考非常久远的历史。
核心公式(完整的 Adam 更新公式):
θt=θt−1−αv^t+ϵm^t\theta_t = \theta_{t-1} - \frac{\alpha}{\sqrt{\hat{v}_t} + \epsilon} \hat{m}_tθt=θt−1−v^t +ϵαm^t
(注:m^t\hat{m}_tm^t 和 v^t\hat{v}_tv^t 是为了修正早期数据不足时的偏差,α\alphaα 是你设置的基础学习率,ϵ\epsilonϵ 是一个极小值,比如 10−810^{-8}10−8,防止分母为零。)
3、零冗余优化器(ZeRO)
ZeRO 使用分区的方法,即将模型状态量分割成多个分区,每个计算设备
只保存其中的一部分。这样整个训练系统内只需要维护一份模型状态,减少了内存消耗和通信开
销。