前言:从"跑通"到"可用"的鸿沟
很多同学跑个 LangChain 的 Hello World,接个向量数据库,就觉得自己掌握了 RAG。但真到了生产环境,业务方的一通"夺命连环问"就能让你宕机:
- "我查上个月财务报表,为什么给我一堆毫不相关的规章制度?"
- "那个合同编号明明在里面,搜搜看却搜不到?"
- "这响应速度,我是去喝杯咖啡再回来拿答案吗?"
基础 RAG 只是玩具,企业级 RAG 才是生产力。 想要不被吊打,你的架构得经历这四次"脱胎换骨"。
1. 结构化数据的"死穴":Text-to-SQL 💻
别再指望向量检索能处理"比大小、求和、聚合"了。向量检索擅长的是"模糊意图",而财务和业务数据要的是"绝对精准"。
-
踩过的坑: 把数据库里的表全转成文本切块塞进向量库,结果查询"销售额前三"时,模型在胡言乱语。
-
硬核玩法:让 LLM 变身 SQL 架构师。
- Schema Injection: 别把几百张表全塞给模型,那是"显存自杀"。先用向量检索挑出相关的 3-5 张表定义,再喂给模型生成 SQL。
- 安全防线: 生成的 SQL 必须跑在只读权限账号下,且要做查询时间限制,防止被模型整出个"全表扫描"。
2. 拒绝"语义眼盲":混合检索(Hybrid Search)🔍
向量检索(Embedding)虽然高级,但它有个致命弱点:不认专有名词。 比如 "HT-9981-X" 这种型号,在向量空间里可能和"HT-9982-X"没啥区别。
-
解决方案: 别把老祖宗的 BM25(关键词检索) 给扔了。
-
双剑合璧: 1. 向量检索 负责捕捉"大概意思";
-
关键词检索 负责死磕"精确字符";
-
Reranking(精排层): 这步最关键!用交叉编码器(Cross-Encoder)对两边的结果重新打分。没有 Rerank 的 RAG 是没有灵魂的。
-
3. 复杂逻辑的救星:Agentic RAG 🤖
面对"对比 A 和 B 两家公司的毛利表现"这种问题,一波流检索肯定挂。因为模型得先知道 A 的毛利,再知道 B 的毛利,最后才能对比。
-
进阶思路:别把模型当成搜素引擎,把它当成"项目经理"。
- 任务拆解: 利用 ReAct 框架,让模型自问自答。第一步搜 A,第二步搜 B,第三步做计算。
- 多跳推理: 这种 Agent 模式虽然慢点,但能解决"弯弯绕"特别多的业务场景。
4. 极致性能与降本:Context Caching 🧠
如果你在做低代码平台自动生成代码 或者超长研报分析,你肯定会发现:几十万字的开发手册,每次问都要传一遍,API 费用能让你当场破产,响应还慢。
-
工程化黑科技:上下文缓存。
- KV Cache 复用: 既然那本"开发手册"是不变的,直接在服务端把它缓存成一个 ID。
- 效果显著: 响应速度(TTFT)从 10 秒直接拉到 1 秒内,成本直接打一折。对于需要频繁调用的核心业务规范,这招简直是"外挂"。
🏗️ 终极全景图:企业级混合架构
这一套架构,基本能扛住 90% 的企业级复杂业务。
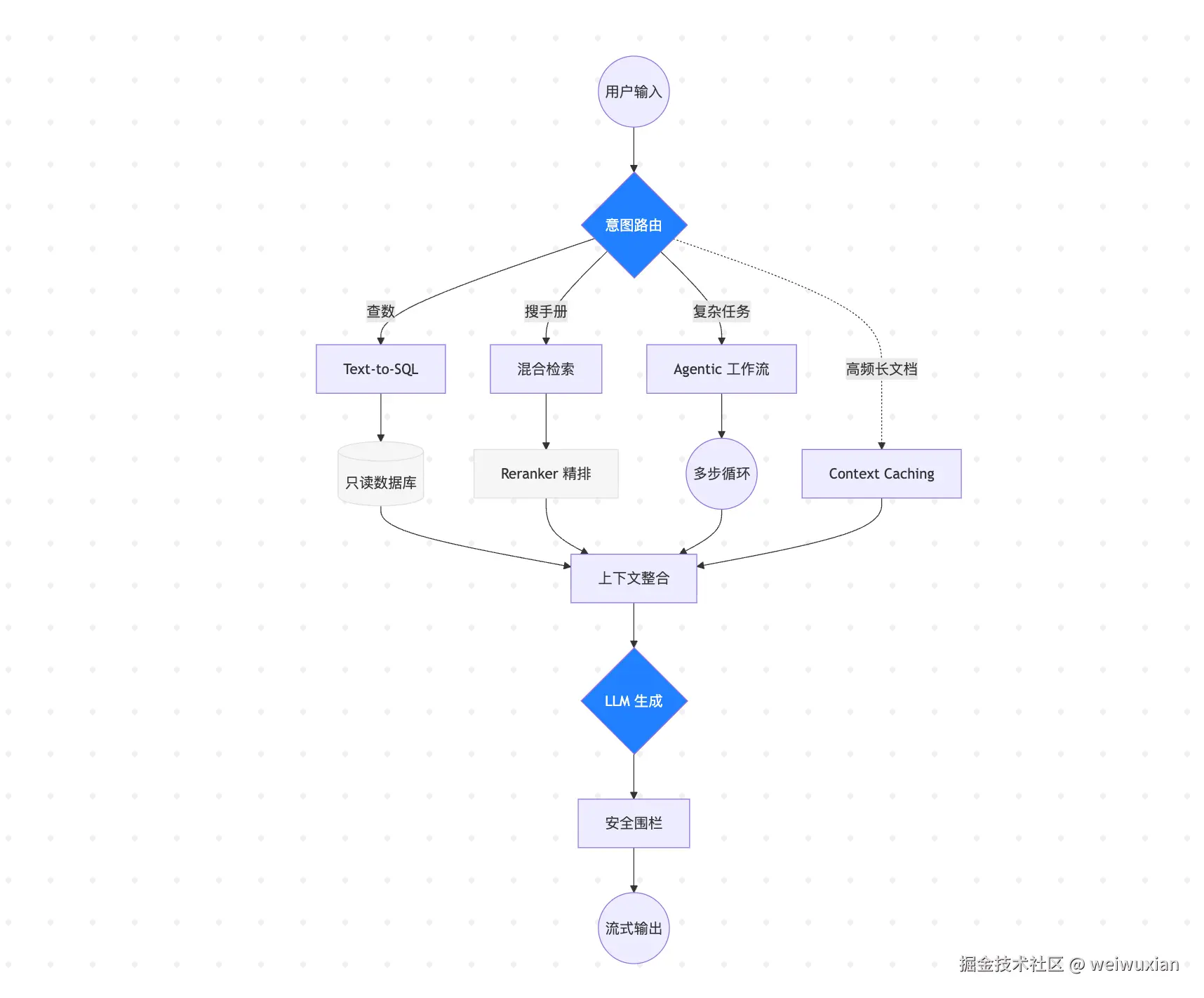
💡 碎碎念(总结)
在企业里落地 AI, "巧妙的工程策略"远比"昂贵的 API"重要。 * 别迷信大模型。
- 多做数据清洗和元数据标注。
- 善用 Rerank 和缓存。
最后,RAG 的尽头不是算法,是工程治理。
如果你在低代码平台建设或者金融/医疗等垂直领域的 RAG 落地中遇到坑,欢迎在评论区交流。 >
觉得有启发?点赞、收藏、关注三连走起!🔥