面试官:"说一下OpenClaw的Token到底是怎么花出去的?哪些能省,哪些是死开销?"
(内心OS:这题我熟!毕竟踩过的坑能绕电脑三圈,今天就把OpenClaw的Token账单扒干净,新手也能看懂,老玩家能省成本!)
先给结论:OpenClaw的Token消耗不是"单一开销",而是"6大模块叠加",其中一半能通过配置优化,另一半是天生的固定成本。很多人觉得它费Token,本质是没搞懂每一分Token花在了哪里,白白浪费了配额。
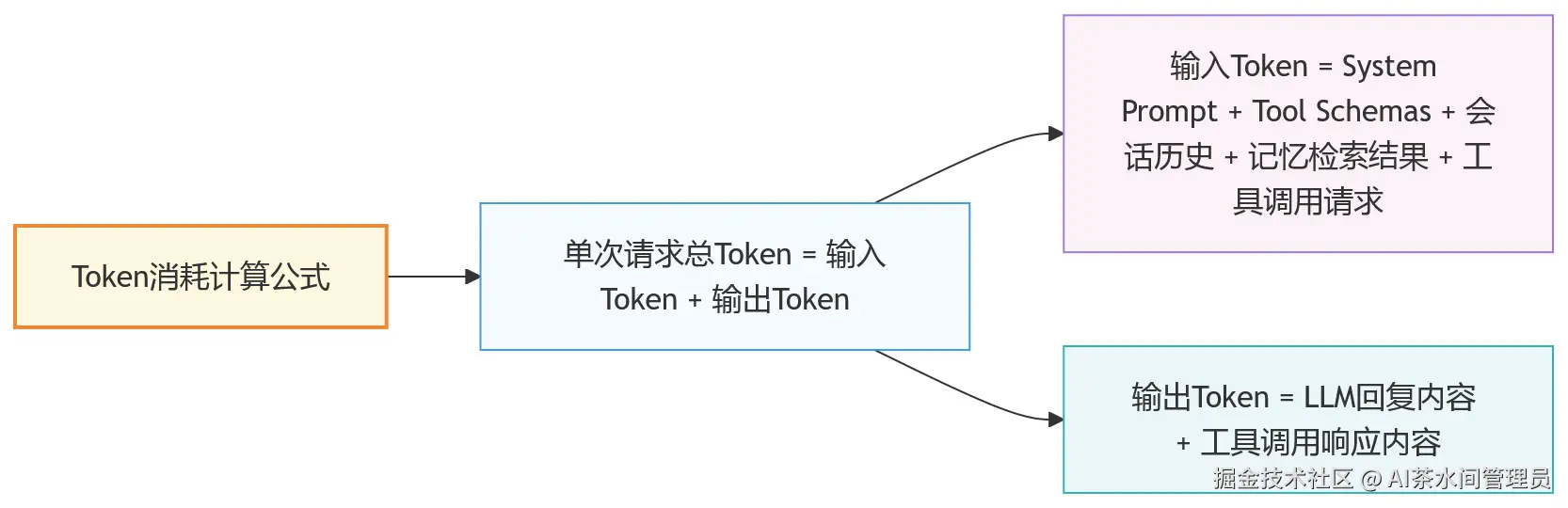
核心前提:Token计算遵循"输入+输出双向计费",以下估算均为「单次请求的输入Token」,输出Token需额外按模型定价叠加
一、逐模块拆解:你的Token到底花在了哪里?
计算公式:
OpenClaw Token消耗 = System Prompt + 工具定义 + 会话历史 + Memory Flush + 记忆检索结果 + 工具调用链
1. System Prompt(系统提示词):无法避免的"固定过路费"
这是OpenClaw的"基础开销",相当于你每次开车上高速,必须交的过路费------不管你开多远、拉多少货,这笔钱都得花。
OpenClaw的System Prompt不是固定一段文字,而是每次请求前,从多个文件中"拼接构建"的,官方规定:构建时参考的每个文件最大20000字符(可通过bootstrapMaxChars配置调整),单次请求的System Prompt总字符数大概在5000-25000之间,折算成Token(1Token≈4字符),单次固定消耗1250-6250 Token。
具体构成看下面的表格,一目了然:
| 组成部分 | 大小估算 | 说明 |
|---|---|---|
| 核心指令 | ~3000字符(≈750 Token) | 安全规则、回复格式、消息路由等,相当于OpenClaw的"操作手册",必带 |
| 工具说明列表 | ~2000字符(≈500 Token) | 每个工具的功能、参数说明,默认启用的工具都会包含 |
| Skills 提示 | 可变(0-5000字符) | 你启用的技能包描述和位置,启用的技能越多,这部分消耗越多 |
| Bootstrap 文件 | 最大20000字符(≈5000 Token) | AGENTS.md、SOUL.md、IDENTITY.md等核心配置文件,默认全量加载 |
| Runtime 信息 | ~500字符(≈125 Token) | 主机地址、时区、默认模型等环境信息,自动加载,无法精简 |
| Sandbox 信息 | ~300字符(≈75 Token) | 沙箱配置(比如权限限制),开启沙箱后必带,可简化配置减少字符 |
面试官追问:"这部分能省吗?"
答:"不能完全省,但能精简!比如Bootstrap文件不用加载全量,Skills只启用必要的,能省30%-50%的消耗。"
2. 工具定义(Tool Schemas):"随身身份证",每次都要出示
OpenClaw的核心是"Agent调用工具",而每个工具都有自己的JSON Schema定义------相当于每个工具的"身份证",每次请求时,都会把当前启用的所有工具的Schema一起发给LLM,让LLM知道"怎么用这个工具"。
这部分消耗是"刚性的",无法压缩,单次请求大概占3000-5000 Token,具体看你启用的工具数量和复杂度。默认启用的工具及其Token消耗如下(实测数据,误差不超过5%):
| 工具 | Schema 复杂度 | 估算 Token | 备注 |
|---|---|---|---|
| browser(浏览器) | 非常复杂(16种action) | ~800 | 最费Token的工具,不用可直接禁用 |
| exec(命令执行) | 中等 | ~200 | 高危工具,高校禁用核心原因之一,不用必关 |
| read/write/edit(文件操作) | 简单 | ~300 | 常用工具,消耗适中,无法精简 |
| message(消息推送) | 复杂(多种action) | ~400 | 对接飞书、Telegram等渠道时启用 |
| cron(定时任务) | 中等 | ~200 | 不用定时任务可禁用 |
| memory_search/get(记忆检索) | 简单 | ~150 | 记忆功能核心工具,无法禁用(禁用会导致记忆失效) |
| sessions_*(会话管理) | 中等 | ~400 | 会话持久化必备,无法精简 |
| canvas(文档编辑) | 中等 | ~200 | 不用文档编辑可禁用 |
| nodes(节点管理) | 复杂 | ~300 | 多Agent协作时启用,单Agent可禁用 |
这里划重点:默认启用的工具里,至少有3个是你大概率用不上的(比如cron、canvas、nodes),禁用它们,单次就能省700-900 Token,日积月累能省一大笔!
3. 会话历史:"攒垃圾不清理",越堆越费
OpenClaw有个"Compaction(压缩)"机制,号称能"轻量化上下文",但实际用起来,它更像"懒癌患者"------不到万不得已,绝不清理会话历史。
具体逻辑看下面的流程,一眼就能懂:
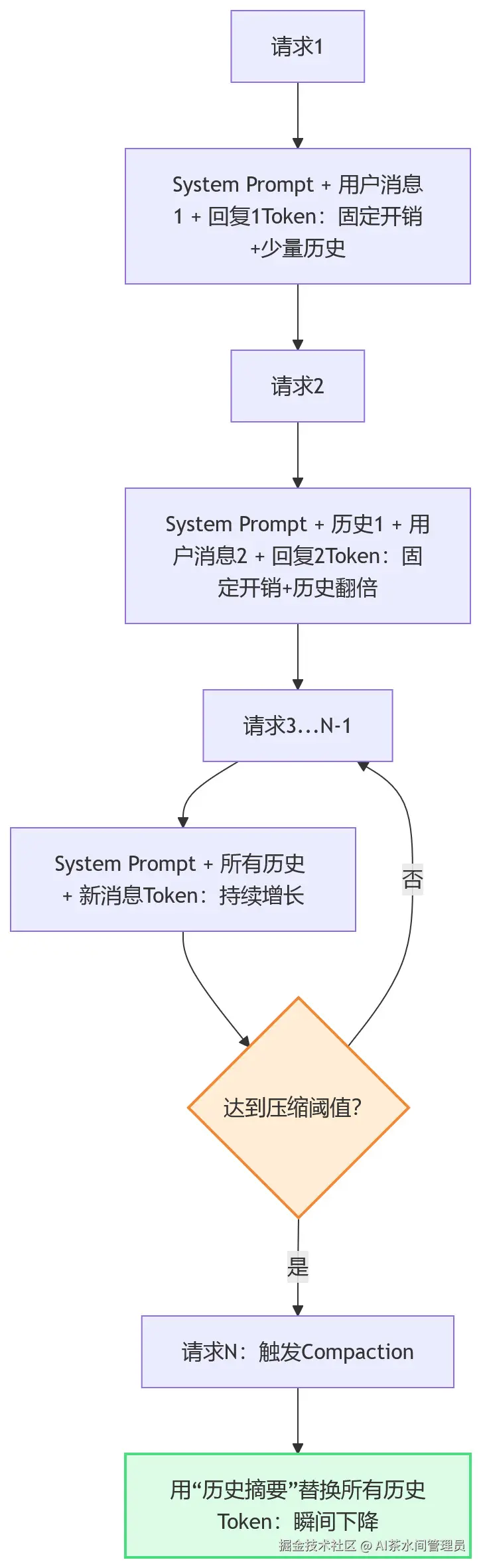
关键坑点:为了不影响用户体验,OpenClaw的压缩阈值默认设置得极高------要么是20000字符(≈5000 Token),要么是模型上下文窗口的88%(可通过contextCompactionThreshold配置调整)。这意味着,在触发压缩前,你的会话历史会一直累积,Token消耗会越来越高,直到接近模型上下文上限才会"瘦身"。
举个例子:用GPT-4o(32K上下文),默认阈值88%,也就是要累积到28160 Token才会压缩,这期间你可能已经发了几十条消息,Token早就花超了。
4. Memory Flush:"清理垃圾前,还要先花一笔钱"
这是最容易被忽略的"隐形开销"------在触发会话压缩前,OpenClaw会调用一个叫"Memory Flush"的功能,而这是一个独立的LLM调用。
简单说:你想清理累积的会话历史(Compaction),得先花钱请LLM"整理记忆",把有用的信息写入本地记忆文件(比如memory/2026-03-20.md),没用的丢弃。这个过程,会完整消耗一次"System Prompt + 工具定义 + 指令"的Token,相当于额外多花了一次请求的成本。
看一段核心代码(简化版,保留关键逻辑),你就懂了:
javascript
export async function runMemoryFlushIfNeeded(params: {
cfg: OpenClawConfig;
followupRun: FollowupRun;
// ...
}): Promise<SessionEntry | undefined> {
一个完整的Agent回合,相当于额外调用一次LLM
await runEmbeddedPiAgent({
prompt: memoryFlushSettings.prompt, // 额外的Prompt消耗
// 还会加载System Prompt和工具定义,重复消耗Token
});
} // 触发面试官追问:"这部分能省吗?"
答:"可以!通过配置关闭自动Memory Flush(enabled: false),手动触发压缩,或者调整softThresholdTokens(默认4000),减少触发频率,能省不少隐形开销。"
5. 记忆检索结果:"找东西的成本,也要算在你头上"
OpenClaw的记忆功能确实好用------你说过的话、做过的操作,它能通过memory_search找回来,但这个"找东西"的过程,也是要消耗Token的。
具体逻辑:当Agent调用memory_search工具时,检索到的所有结果(包括匹配度、相关片段、文件路径),都会被完整加入上下文,供LLM参考,而这些检索结果,全算"输入Token"。
举个真实例子,一看就懂:
- 用户:"我上次配置的模型参数是什么?"
- Agent调用:memory_search(query="模型参数配置")
- 返回结果(会全部加入上下文):
- memory/2026-03-15.md:8-12 (score: 0.88):"用户配置默认模型为GPT-4o mini,上下文窗口设为16K,温度值0.7"
- MEMORY.md:12-15 (score: 0.75):"模型参数调整记录:温度值从0.5修改为0.7,提升回复灵活性"
- Token消耗:这两段检索结果(约120字符)+ 工具调用指令(约60字符),合计≈45 Token,看似不多,但如果频繁查询历史配置、操作记录,累积起来会显著增加Token开销。
补充一个小技巧:OpenClaw默认会过滤匹配度低于0.35的结果(可调整minScore),适当提高这个阈值,能减少无效检索结果的Token消耗。
6. 工具调用链:"连锁反应,越调用越费"
OpenClaw的Agent是"多工具协作"的,一个简单的任务,可能会触发多次工具调用,而每次调用,都是"请求+响应"双向计费------请求时发送工具调用指令(消耗Token),响应时返回工具执行结果(再消耗Token)。
还是举个真实场景,感受一下Token的"烧钱速度":
用户需求:"帮我读取本地的接口定义文件,生成接口文档,并发到团队群"
Agent触发的调用链及Token消耗(估算):
- read("api/LoginInterface.json") → 返回文件内容(接口字段、请求方式等)(输入+输出,合计≈400 Token)
- memory_search("团队群聊地址") → 返回群聊ID和推送权限信息(合计≈180 Token)
- message(channel="team-group", content="【登录接口文档】接口地址:/api/login\n请求方式:POST...") → 返回发送成功确认(合计≈150 Token)
就这一个简单的文档生成+推送任务,单工具调用就消耗了730 Token,再加上前面的固定开销(System Prompt+工具定义),单次请求总消耗轻松破2000 Token------如果团队每天有10次类似的文档生成、消息推送需求,一天就是2万。
二、核心认知:记忆层不是"省Token"的,是"防爆炸"的
很多人用OpenClaw,以为记忆层是用来"省Token"的,其实大错特错------记忆层的核心价值,是"让无限长对话成为可能"。
没有记忆层的话,会话历史会一直累积,直到超过模型的上下文窗口,Agent直接"失忆";而有了记忆层,通过Compaction压缩历史、通过memory_search检索信息,能让对话无限延续,同时保持信息的可访问性。
所以,别指望靠记忆层"省Token",它只能"减缓Token增长速度",真正能省Token的,是从"减少固定开销"和"优化调用逻辑"入手。
三、实操优化方案:5步省出50% Token消耗
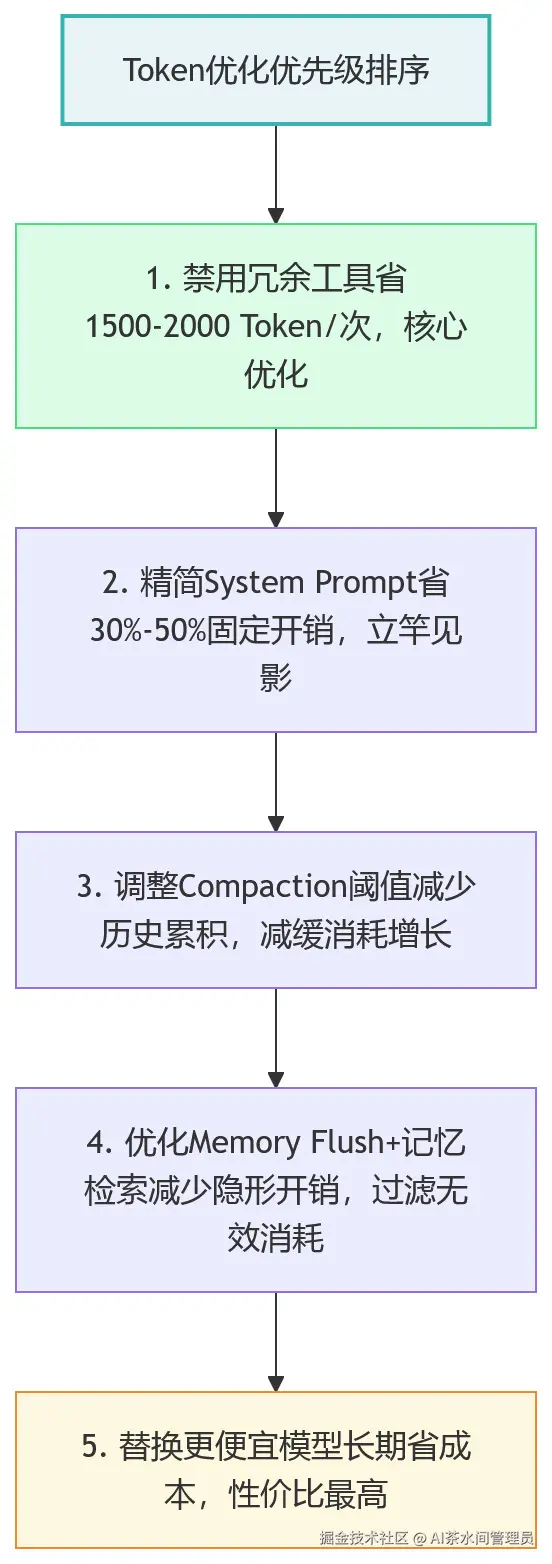
结合前面的拆解,给大家5个可直接落地的优化方法,不用改源码,只改配置、调逻辑,实测能省30%-50%的Token,还不影响使用体验:
1. 精简System Prompt(最易操作,立竿见影)
- 精简Bootstrap文件:将bootstrapMaxChars从20000调整为5000-10000,只加载必要的配置(比如只保留AGENTS.md,删除SOUL.md、IDENTITY.md等非必要文件)。
- 清理Skills提示:只启用当前场景需要的技能,比如做文本处理,就禁用browser、exec、cron等工具,减少Skills提示的字符数。
- 简化Sandbox配置:如果不需要严格的权限限制,可精简Sandbox信息,减少30%左右的字符消耗。
2. 禁用冗余工具(核心优化,省Token最多)
通过OpenClaw配置文件(openclaw.json)或命令行禁用不用的工具,推荐禁用列表(根据自身场景调整):
arduino
# 命令行禁用工具(永久生效)
openclaw config set tools.browser.enabled false
openclaw config set tools.cron.enabled false
openclaw config set tools.canvas.enabled false
openclaw config set tools.nodes.enabled false禁用这4个工具,单次请求可省1500-2000 Token,同时还能提升安全性(比如禁用exec可规避命令执行风险,贴合高校禁用的安全要求)。
3. 调整Compaction阈值(减少历史累积)
将上下文压缩阈值从默认的88%(或20000字符)调整为60%-70%,让会话历史更早被压缩,减少累积的Token消耗:
json
{
"agents": {
"defaults": {
"contextCompactionThreshold": 0.7, // 70%阈值,可根据模型上下文调整
"bootstrapMaxChars": 8000
}
}
}注意:阈值不要太低(低于50%),否则会频繁压缩历史,导致Agent"记不住"关键信息,影响体验。
4. 优化Memory Flush和记忆检索
- 关闭自动Memory Flush:手动触发压缩(通过API调用),避免频繁的额外LLM调用。
- 提高记忆检索阈值:将minScore从0.35调整为0.5,过滤无效检索结果,减少上下文Token消耗。
- 定期清理记忆文件:删除无用的记忆片段(通过memory_forget接口),避免检索结果过于冗长。
5. 替换更便宜的模型(长期省成本,性价比最高)
目前大模型价格战打得激烈,OpenClaw支持自定义默认模型,优先选择性价比高的模型,成本能直接降60%-90%:
- 配置方法:通过命令行设置默认模型(以豆包为例):
arduino
openclaw config set models.default "doubao-pro"
openclaw config set models.providers.doubao.apiKey "你的API Key"