
论文概述:SWAN-GPT提出了一种新的解码器-仅Transformer架构,该架构能够在不需要额外长上下文训练的情况下,稳健地泛化到比训练期间看到的序列长度显著更长的序列。SWAN-GPT通过交错使用没有位置编码(NoPE)的全局注意力层和配备旋转位置编码(RoPE)的滑动窗口注意力层(SWA-RoPE)来实现这一点。此外,SWAN-GPT在推理期间采用了一种简单的动态注意力评分缩放机制,进一步增强了其对长序列的稳健性。论文还展示了SWAN-GPT在计算效率上优于标准的GPT架构,降低了训练成本并提高了吞吐量。论文进一步证明了现有的预训练解码器-仅模型可以通过最少的继续训练有效地转换为SWAN架构,从而支持更长的上下文。
📄 一、论文核心信息
|---------------------------------------------------------------------------------------------------------------------------------------------------------------------------|
| 📄 论文标题:SWAN-GPT: An Efficient and Scalable Approach for Long-Context Language Modeling 👥 作者单位:NVIDIA团队 🔗 原文链接:arxiv.org/pdf/2504.08719 ✨ 核心标签:长上下文LLM、长度外推、混合注意力、低成本部署 |
✨ 二、论文主要贡献
针对长文本建模的行业痛点,SWAN-GPT提出四大核心创新点,既实现技术层面的突破,又充分兼顾工业落地实用性,具体贡献可总结为以下四点:
-
独创混合注意力架构:采用NoPE全局注意力层与SWA-RoPE滑动窗口层交替搭配的设计,摆脱训练长度限制,实现无训练依赖的高效长度外推
-
揭秘隐式位置编码协同机制:借助SWA-RoPE层稳定NoPE层的特征表征,有效解决长序列场景下的位置紊乱问题
-
动态注意力对数缩放:在推理阶段针对性优化注意力得分计算逻辑,保障超长文本场景下模型性能不滑坡、不衰减
-
存量模型低成本迁移方案:仅需少量继续预训练,即可将现有RoPE架构模型转为SWAN架构,且无额外性能损耗
🔍 三、论文内容深度解读
⚠️ 3.1 研究背景:长文本建模的行业困局
当下主流大语言模型的长文本处理能力,几乎都依靠"堆数据、堆训练"的方式实现。研发团队必须专门采集超长序列数据,对模型进行专项训练与微调,才能让模型具备长文本理解能力。这一过程不仅带来居高不下的算力成本,还无法兼容已上线部署的存量模型,后期升级改造成本极高。
更棘手的是,传统模型存在明显的长度瓶颈,一旦处理远超训练长度的文本,就会出现性能断崖式下跌,甚至直接无法正常推理,位置编码紊乱、注意力计算爆炸等问题频发,成为长文本AI商业化落地的核心拦路虎。
在这样的行业背景下,一个核心问题亟待解决:能否不用额外长文本训练,就让模型读懂超长文本,同时实现存量模型的低成本升级?
NVIDIA团队推出的SWAN-GPT,恰好给出了兼具可行性与实用性的破局答案,无需额外长文本训练,就能轻松解锁模型的超长文本潜力。
📚 3.2 相关工作:现有方案的局限性
当前长文本LLM优化方向主要分为三类,但各类方案均存在难以规避的短板,无法兼顾性能、效率与落地性,具体局限如下:
-
RoPE旋转位置编码方案:高度依赖固定长度训练,一旦超出训练窗口,模型性能就会急剧衰减,无法实现有效长度外推,也完全无法兼容存量模型
-
NoPE无位置编码方案:虽能自主学习隐式位置信息,但泛化能力极差,超出训练长度后位置表征彻底混乱,长序列处理稳定性极低
-
滑动窗口注意力方案:仅能捕捉局部文本语义,无法整合全文长程依赖关系,长文本整体理解能力有限,难以满足复杂场景需求
不难看出,现有长文本优化方案要么牺牲模型泛化能力,要么大幅拉高训练部署成本。而SWAN-GPT正是针对这些缺陷,打造出一款兼顾效率、性能与落地性的全新架构。
⚙️ 3.3 核心升级:SWAN-GPT创新架构解析
SWAN-GPT能够突破传统模型瓶颈,核心秘诀在于全局+局部交替的混合注意力设计。两种注意力机制互补协同,既能精准捕捉全文长程语义依赖,又能稳固位置信息表征,彻底摆脱固定长度的束缚。
🧩 (1)双层注意力交替设计
SWAN-GPT的架构核心,采用重复交替堆叠的双层注意力结构。经过团队大量实验验证,1层NoPE全局层 + 3层SWA-RoPE局部层的配比,能在长文本泛化能力与计算效率之间达到最优平衡,是最适配的架构组合。
-
NoPE全局注意力层(无位置编码):无窗口长度限制,可覆盖全文本范围,专职捕捉长程语义依赖、整合全局信息
-
SWA-RoPE滑动窗口层(带旋转位置编码):采用512token固定窗口,提供精准的局部位置信息,保障局部文本语义连贯性
这种双层交替设计,既摆脱了传统固定长度窗口的限制,又有效规避了纯NoPE模型易出现的位置紊乱问题,实现1+1>2的协同增效效果。
🔗 (2)位置编码互补协同机制
纯NoPE模型的短板十分明显,虽能自主学习隐式位置信息,但超出训练长度后就会完全失效。而在SWAN混合架构中,SWA-RoPE层承担了局部位置追踪的核心压力,让NoPE层能够专注于全局信息整合,二者形成高效互补。
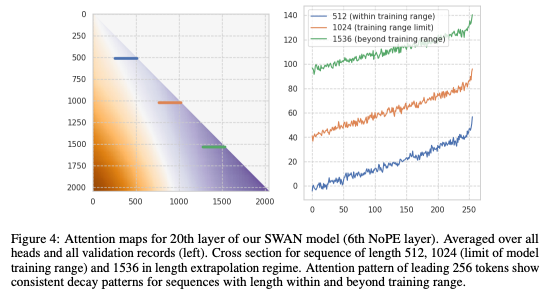
这一机制带来了亮眼的实战效果:即便序列长度达到训练长度的32倍,模型注意力衰减模式依然保持高度一致,彻底杜绝了传统模型的性能断崖式下跌问题。
📊 (3)动态对数缩放优化
为进一步提升超长文本处理的稳定性,SWAN-GPT在推理阶段加入动态注意力对数缩放策略,专门针对NoPE全局层优化注意力得分计算逻辑,强化长序列场景下的模型稳定性。
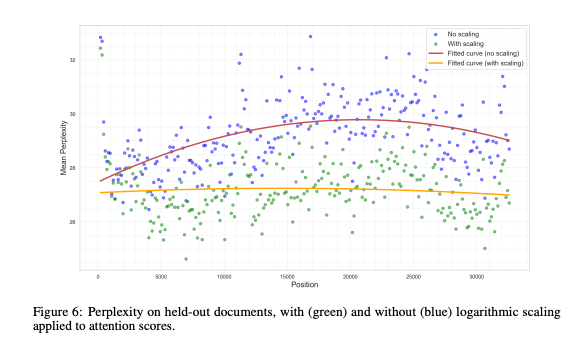
对比无缩放、YaRN缩放等常规方案,动态对数缩放能有效降低文档困惑度,让模型在超长序列场景下保持更低的预测误差,性能输出更平稳、更可靠。
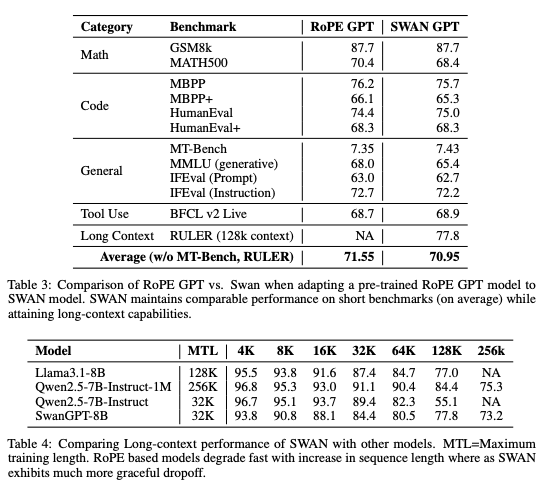
✅ 3.4 实验结论:性能与效率双验证
SWAN-GPT通过多维度基准测试,全面验证了其在通用性能、长文本外推、部署成本上的优势,实验结论清晰且具备极强的说服力,具体结果如下:
🎯 (1)基准测试表现
-
10亿参数版本模型,在MTL、ARC、Hellaswag等主流LLM基准测试中,性能持平甚至超越传统RoPE-GPT模型
-
整体平均得分达51.4%,优于传统RoPE-GPT的49.5%,兼顾通用场景能力与长文本专属优势
🚀 (2)长度外推能力
-
传统RoPE-GPT模型超出训练长度后,性能急剧暴跌甚至无法正常推理,而SWAN-GPT全程保持稳健输出
-
序列长度达到训练长度32倍时,SWAN-GPT仍可维持高效性能输出,远超同类长文本解决方案
💰 (3)存量模型升级与效率表现
针对Llama3.1-8B、Qwen2.5-7B等主流开源预训练模型,SWAN-GPT仅需少量继续预训练,即可快速完成架构改造,升级成本极低:
-
短文本基准测试性能保持不变,无任何性能损耗
-
升级后直接解锁超长上下文处理能力,最高可支持128K+序列长度
-
算力成本远低于从头训练专属长文本模型,计算吞吐量大幅提升
📈 四、方案对比:SWAN-GPT vs 传统RoPE-GPT
|------------|----------|------------|---------|--------|
| 方案 | 是否需长文本训练 | 长度外推能力 | 计算效率 | 存量模型适配 |
| 传统RoPE-GPT | 必须 | 极差,易失效 | 低,复杂度高 | 无法适配 |
| SWAN-GPT | 无需 | 极强,32倍训练长度 | 高,吞吐量提升 | 可低成本迁移 |
💡 五、行业价值与应用场景
🌟 核心价值
-
学术价值:打破"长文本必须长训练"的固有思维,为LLM长度外推提供全新架构思路,填补技术空白
-
工业价值:存量模型快速升级,大幅降低长文本模型研发、训练与部署成本,加速商业化落地
📌 落地场景
SWAN-GPT适用于各类超长文本处理场景,无需高额改造即可落地:
-
文档精读:合同审核、财报分析、论文研读、书籍拆解
-
内容生成:长篇小说、行业报告、多轮对话续写
-
技术场景:代码分析、项目级代码理解、批量数据处理
-
知识库应用:企业知识库检索、跨文档语义提取
📝 六、全文总结
SWAN-GPT凭借极简架构,彻底破解长文本建模的成本与性能难题,核心优势可浓缩为四点:
-
NoPE+SWA-RoPE交替层:实现无训练长度外推,摆脱固定窗口束缚
-
动态对数缩放:加固超长序列稳定性,性能不衰减
-
低成本迁移:存量模型一键升级,无需重头训练
-
高效低耗:算力成本更低,模型吞吐量更高
对于企业和开发者而言,SWAN-GPT无疑是当前性价比最高的长文本解决方案,无需投入高额算力成本,即可快速解锁模型超长文本潜力。
你在长文本建模、模型部署中遇到过哪些瓶颈?SWAN-GPT的设计思路对你有启发吗?欢迎评论区交流~
干货持续更新,点赞+在看,下期拆解更多AI顶会前沿成果!