1. Charles
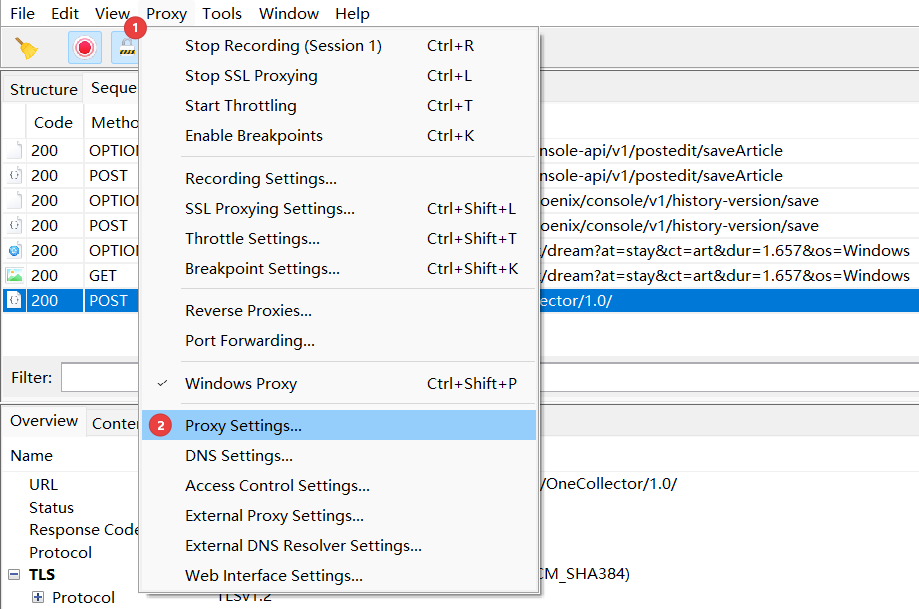
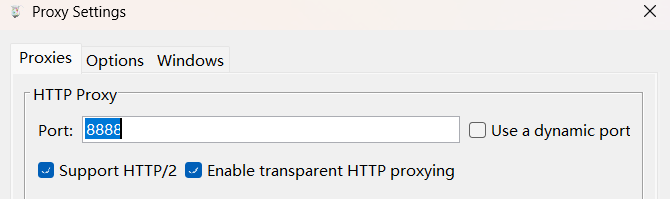
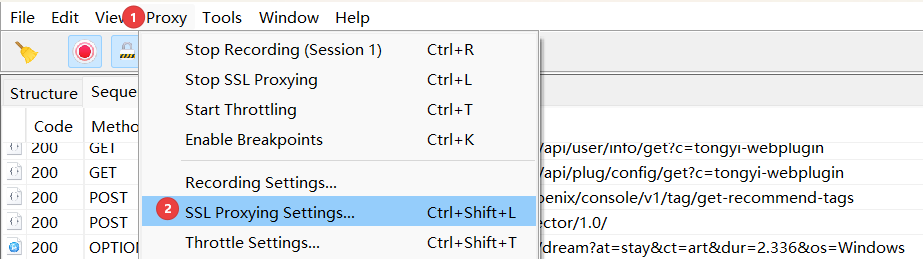
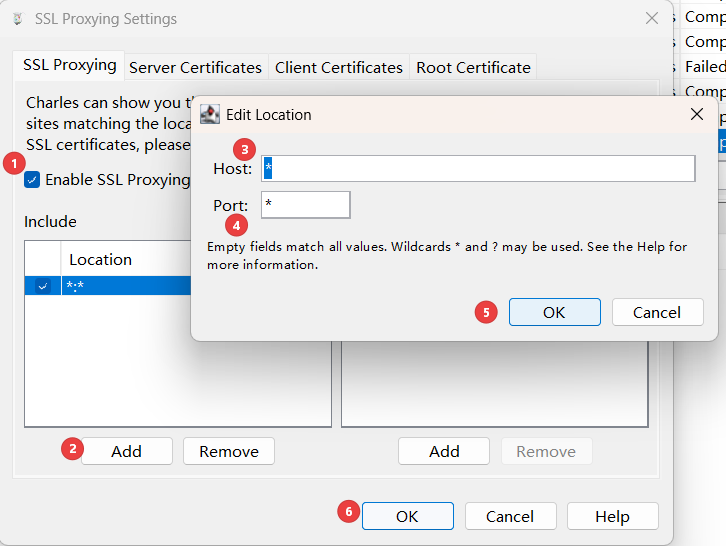
1.1. 代理设置
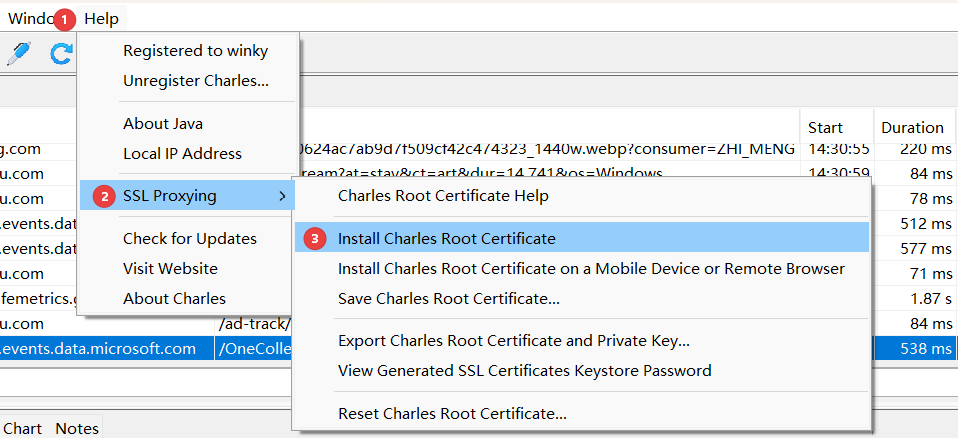
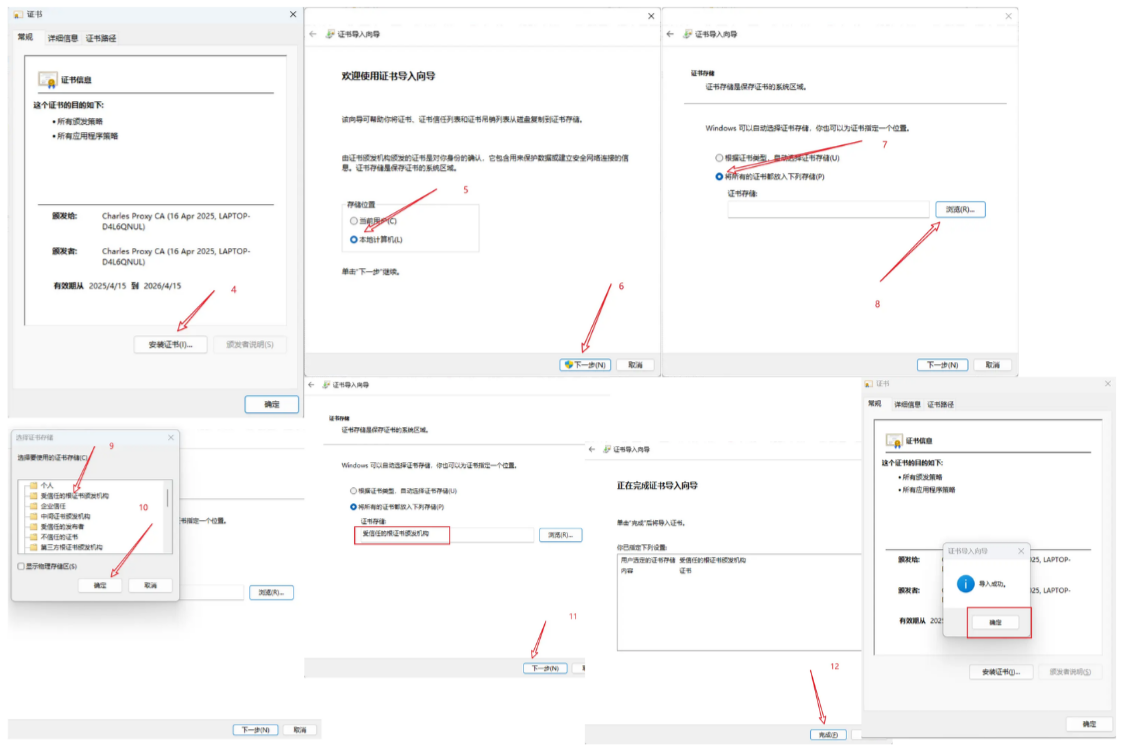
1.2. HTTP 请求报文
以"AA巴士"为例
点击所需页面之前可以用小扫把把页面清空。
点进其中一条线路页面,Charles会出现与之对应的网络请求日志和HTTP 请求报文。
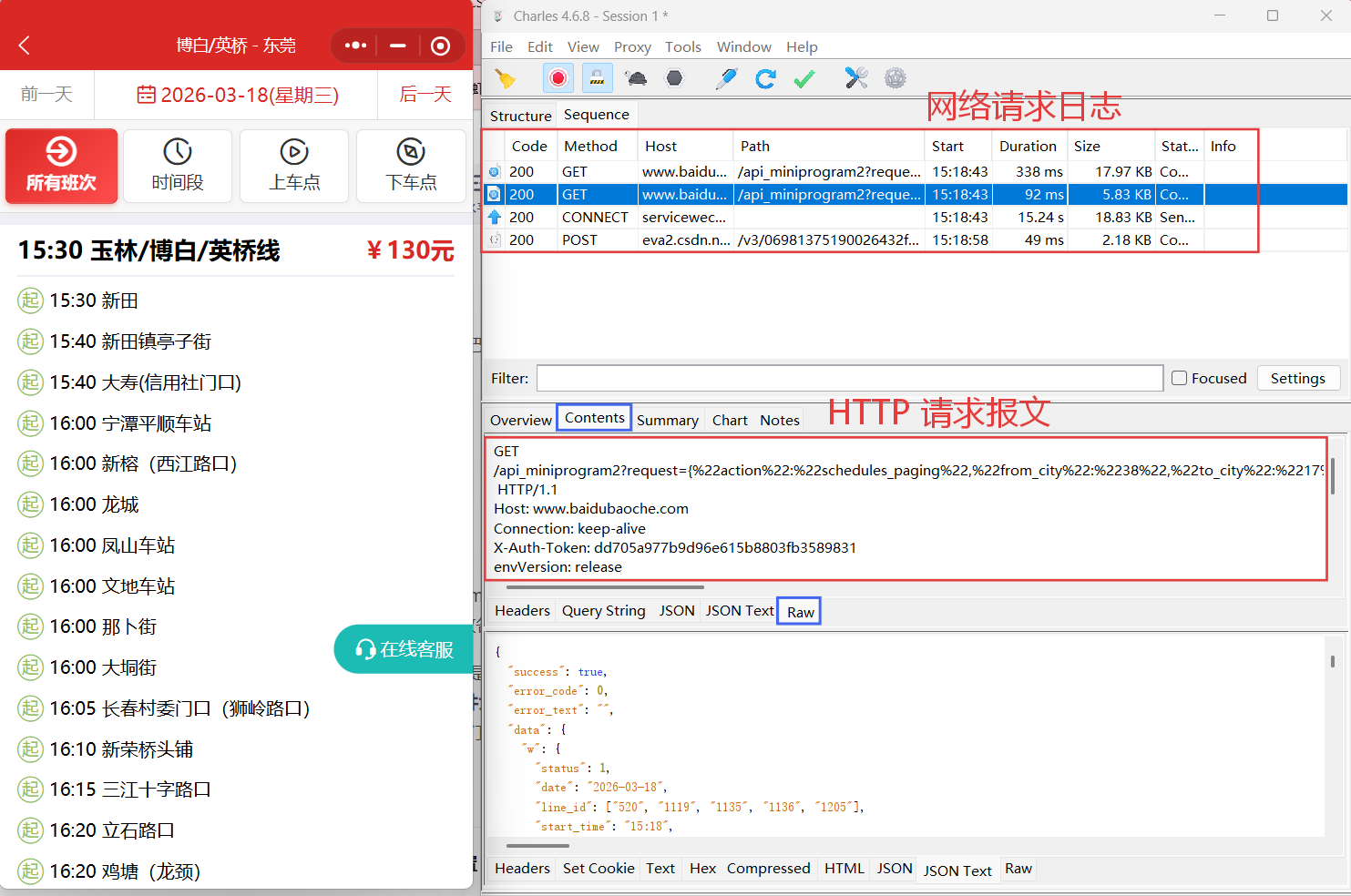
我要批量抓取所有线路的信息,但是一个一个抓取太慢了。
所以我要知道这个小程序的HTTP 请求报文是如何设计的。
1.2.1. 请求行Request Line
python
:method: POST(请求方法)
:authority: 256841v3-api.ylxweb.com(域名)
:scheme: https(协议)
:path: /api/wg.do(请求路径)1.2.2. 请求头部Request Headers
python
content-length: 236
challenge: 019d0904902176929514fddd7bd1ef7e_00
bucket: 270
user-agent: Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/132.0.0.0 Safari/537.36 MicroMessenger/7.0.20.1781(0x6700143B) NetType/WIFI MiniProgramEnv/Windows WindowsWechat/WMPF WindowsWechat(0x63090a13) UnifiedPCWindowsWechat(0xf254173b) XWEB/19027
xweb_xhr: 1
content-type: application/x-www-form-urlencoded
x-ca-nonce: 019d0904902176929514fddd7bd1ef7e270
accept: */*
sec-fetch-site: cross-site
sec-fetch-mode: cors
sec-fetch-dest: empty
referer: https://servicewechat.com/wxfa5086861b29aa4f/58/page-frame.html
accept-encoding: gzip, deflate, br
accept-language: zh-CN,zh;q=0.9
priority: u=1, i1.2.3. 请求体Request Body
python
corpID=qbs&action=interval.intervalListV2&tripDate=2026-03-20&startCityId=020&endCityId=440300&start=0&limit=100&startAreaId=&endAreaId=&corpid=qbs&subAppid=wxfa5086861b29aa4f&appid=wxfa5086861b29aa4f&openid=oi8265WtSNIvz0D90DBcrZ2A-yhQ从Charles得到的信息:
- ✅ 请求地址
- ✅ 请求方法
- ✅ 请求头格式
- ✅ 请求体结构
- ❓ 但不知道这些加密参数怎么来的
2. 逆向
2.1. 找到.wxapkg文件
C:\Users\Wuyiq\AppData\Roaming\Tencent\xwechat\radium\users\650f192eb46f6ed139fd2eb1bcfbb0b6\applet\packages中存放各种微信小程序。
根据"请求头部"的Referer知道小程序对应的【AppID】。根据【AppID】点开对应文件夹,文件夹里面会有一个或多个.wxapkg文件,通常选择 文件大小最大的那个(一般命名为__APP__.wxapkg或带版本号的文件,如1.0.0.wxapkg),这就是我们需要反编译的核心文件。
2.2. 解密
superdashu/pc_wxapkg_decrypt_python: PC微信小程序 wxapkg 解密
运行该代码的main.py文件,对原文件进行解密。
python main.py --wxid 【AppID】 --file 【"原wxapkg文件路径"】 --output 【"解密后的wxapkg文件路径"】2.3. 解包
YangChengTeam/wxappUnpacker: 微信小程序反编译工具
使用基于 Node.js 开发的**wxappUnpacker,**把.wxapkg 格式的 "打包文件",转换成能看懂的源代码(HTML、CSS、JavaScript 文件)
(在该wxappUnpacker 的文件夹路径下)安装依赖。它会在当前目录下查找 package.json 文件 。根据 package.json 中列出的依赖项,下载安装到当前目录的 node_modules 文件夹中。(仅首次需要)
npm install(在该项目的文件夹路径下)再执行以下命令,运行wuWxapkg.js:
node wuWxapkg.js 【"解密后解包前的wxapkg文件路径"】2.4. 分析文件
解包后的文件中包含的app-service.js是小程序全局业务逻辑与核心代码的主入口,是分析小程序业务流程、数据流向、接口请求的最关键文件,大部分核心功能(登录、支付、数据获取)都能在这里找到痕迹。在这里靠app-service.js能找到加密逻辑。
javascript
// 搜索 "intervalList" 找到这个函数:
function getIntervalList(params) {
return new Promise((resolve, reject) => {
// 先获取challenge
getChallenge().then(challenge => {
// 生成随机字符串
const nonce = generateRandomString(32);
// 计算bucket(工作量证明)
const bucket = calculateBucket(challenge, nonce);
// 构建请求参数
const requestParams = {
startCityId: params.startCityId,
endCityId: params.endCityId,
date: params.date,
limit: params.limit || 100,
openid: app.globalData.openid
};
// 构建请求头
const headers = {
'Content-Type': 'application/x-www-form-urlencoded',
'x-ca-nonce': nonce + bucket,
'challenge': challenge + '_00',
'Referer': `https://servicewechat.com/${app.globalData.appId}/pages/index`
};
// 发送请求
wx.request({
url: 'https://qiao-api.com/api/intervalList',
method: 'POST',
header: headers,
data: requestParams,
success: (res) => resolve(res.data)
});
});
});
}
// 搜索 "getChallenge" 找到这个函数:
function getChallenge() {
return new Promise((resolve) => {
wx.request({
url: 'https://qiao-api.com/api/newChallengeV3',
method: 'POST',
data: { corpId: 'qiao' },
success: (res) => {
resolve(res.data.challenge);
}
});
});
}
// 搜索 "calculateBucket" 找到这个函数:
function calculateBucket(challenge, nonce) {
let bucket = 0;
while (true) {
const combined = challenge + nonce + bucket;
const hash = sha256(combined);
// 检查哈希前4位是否为0
if (hash.substring(0, 4) === '0000') {
return bucket;
}
bucket++;
}
}
// 搜索 "generateRandomString" 找到这个函数:
function generateRandomString(length) {
const chars = 'abcdefghijklmnopqrstuvwxyz0123456789';
let result = '';
for (let i = 0; i < length; i++) {
result += chars.charAt(Math.floor(Math.random() * chars.length));
}
return result;
}从app-service.js得到的规律:
- ✅
challenge获取方式:调用/api/newChallengeV3 - ✅
x-ca-nonce生成:随机32位字符串 + bucket值 - ✅
challenge格式:{32位字符串}_00 - ✅
bucket计算:SHA256(challenge + nonce + bucket)的前4位必须为0000 - ✅ 请求体格式:URL编码的键值对
3. 数据的批量获取
根据前面获取的信息,编写Python代码批量生成请求报文,以获取每条线路的站点数据。
python
import json
import requests
import hashlib
import time
import random
from datetime import datetime
# 读取线路数据
with open('线路.json', 'r', encoding='utf-8') as f:
route_data = json.load(f)
# 配置信息
BASE_URL = "https://256841v3-api.ylxweb.com"
CORP_ID = "qbs"
APP_ID = "wxfa5086861b29aa4f"
OPEN_ID = "oi8265WtSNIvz0D90DBcrZ2A-yhQ"
def get_challenge():
"""获取challenge值"""
try:
url = f"{BASE_URL}/api/newChallengeV3"
headers = {
'Content-Type': 'application/x-www-form-urlencoded',
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/132.0.0.0 Safari/537.36 MicroMessenger/7.0.20.1781(0x6700143B) NetType/WIFI MiniProgramEnv/Windows WindowsWechat/WMPF WindowsWechat(0x63090a13) UnifiedPCWindowsWechat(0xf254173b) XWEB/19027'
}
params = {'countString': 1}
# 生成X-Ca-Nonce
random_part = ''.join(random.choice('abcdefghijklmnopqrstuvwxyz0123456789') for _ in range(6))
time_part = str(int(time.time() * 1000))
nonce = f"{time_part}{random_part}{OPEN_ID[:10]}{CORP_ID}"
headers['X-Ca-Nonce'] = nonce
headers['corpid'] = CORP_ID
headers['v'] = '3'
response = requests.post(url, headers=headers, data=params, timeout=10)
if response.status_code == 200:
result = response.json()
if result.get('success') and result.get('data'):
data_str = result['data']
parts = data_str.split('_')
if len(parts) == 2:
return {
'challenge': parts[0],
'difficulty': parts[1],
'originalKey': data_str
}
return None
except Exception as e:
print(f"获取challenge失败: {e}")
return None
def compute_nonce(challenge, difficulty):
"""计算满足difficulty条件的nonce值"""
target = challenge
nonce = 0
difficulty_length = len(difficulty)
while True:
hash_str = hashlib.sha256((target + str(nonce)).encode()).hexdigest()
if hash_str[:difficulty_length] == difficulty:
return nonce
nonce += 1
# 设置最大迭代次数
if nonce > 10000:
return None
def get_route_stations(route, max_retries=3):
"""获取线路站点信息"""
for attempt in range(max_retries):
try:
# 获取新的challenge
challenge_info = get_challenge()
if not challenge_info:
print(f" ✗ 获取challenge失败")
return None
challenge = challenge_info['challenge']
difficulty = challenge_info['difficulty']
original_key = challenge_info['originalKey']
# 计算nonce
nonce = compute_nonce(challenge, difficulty)
if nonce is None:
print(f" ✗ 计算nonce失败")
return None
# 构建请求头
headers = {
'Content-Type': 'application/x-www-form-urlencoded',
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/132.0.0.0 Safari/537.36 MicroMessenger/7.0.20.1781(0x6700143B) NetType/WIFI MiniProgramEnv/Windows WindowsWechat/WMPF WindowsWechat(0x63090a13) UnifiedPCWindowsWechat(0xf254173b) XWEB/19027',
'X-Ca-Nonce': f"{challenge}{nonce}",
'challenge': original_key,
'bucket': str(nonce)
}
# 构建请求参数
params = {
'corpID': CORP_ID,
'action': 'interval.intervalListV2',
'tripDate': '2026-03-14',
'startCityId': route['startCityId'],
'endCityId': route['endCityId'],
'start': '0',
'limit': '100',
'startAreaId': '',
'endAreaId': '',
'corpid': CORP_ID,
'subAppid': APP_ID,
'appid': APP_ID,
'openid': OPEN_ID
}
# 转换为URL编码格式
request_body = '&'.join([f'{k}={v}' for k, v in params.items()])
# 发送请求
response = requests.post(
f"{BASE_URL}/api/wg.do",
headers=headers,
data=request_body,
timeout=15
)
if response.status_code == 200:
result = response.json()
# 检查响应状态
if isinstance(result, dict):
if result.get('success') and result.get('data'):
# 解析intervalList中的站点信息
data = result['data']
intervals = data.get('intervalList', []) if isinstance(data, dict) else []
if intervals:
return {'success': True, 'intervals': intervals}
else:
return {'success': True, 'intervals': []}
elif result.get('message') == '校验失败':
if attempt < max_retries - 1:
print(f" ⚠ 校验失败,重试 ({attempt + 1}/{max_retries})")
time.sleep(random.uniform(2, 4))
continue
else:
return {'success': False, 'error': '校验失败'}
else:
return {'success': False, 'error': result.get('message', '未知错误')}
else:
if response.status_code == 403:
if attempt < max_retries - 1:
print(f" ⚠ 被封禁,等待后重试 ({attempt + 1}/{max_retries})")
time.sleep(random.uniform(5, 10))
continue
else:
return {'success': False, 'error': f'HTTP {response.status_code} - 被封禁'}
else:
return {'success': False, 'error': f'HTTP {response.status_code}'}
except Exception as e:
if attempt < max_retries - 1:
print(f" ⚠ 请求异常,重试 ({attempt + 1}/{max_retries}): {e}")
time.sleep(random.uniform(1, 2))
continue
else:
return {'success': False, 'error': str(e)}
return None
def parse_stations(intervals):
"""解析站点信息"""
all_stations = []
for interval in intervals:
# 解析上车点
if 'addressList' in interval:
for address in interval['addressList']:
station = {
'type': '上车点',
'name': address.get('name'),
'locationId': address.get('code'),
'adcode': address.get('adcode'),
'arriveTime': address.get('arriveTime'),
'status': address.get('status')
}
all_stations.append(station)
# 解析下车点
if 'getOffAddressList' in interval:
for address in interval['getOffAddressList']:
station = {
'type': '下车点',
'name': address.get('name'),
'locationId': address.get('code'),
'adcode': address.get('adcode'),
'status': address.get('status')
}
all_stations.append(station)
return all_stations
def main():
"""主函数"""
print(f"[{datetime.now().strftime('%H:%M:%S')}] 开始批量获取乔巴士线路站点信息...")
print(f"总线路数: {len(route_data['data'])}")
print()
# 批量处理线路
all_routes = []
for i, route in enumerate(route_data['data']):
print(f"[{datetime.now().strftime('%H:%M:%S')}] 处理线路 {i+1}/{len(route_data['data'])}: {route['lineName']}")
# 获取线路站点信息
result = get_route_stations(route)
if result and result['success']:
intervals = result['intervals']
stations = parse_stations(intervals)
# 构建线路信息
route_info = {
'lineName': route['lineName'],
'startCity': route['startCityName'],
'endCity': route['endCityName'],
'color': route['color'],
'intervalCount': len(intervals),
'stationCount': len(stations),
'intervals': intervals,
'stations': stations
}
all_routes.append(route_info)
print(f" ✓ 成功获取 {len(intervals)} 个班次,{len(stations)} 个站点")
else:
error_msg = result.get('error', '未知错误') if result else '未知错误'
print(f" ✗ 获取失败: {error_msg}")
print()
# 随机延迟避免被封
delay = random.uniform(2, 5)
print(f" 等待 {delay:.1f} 秒...")
time.sleep(delay)
# 保存结果
output_file = '乔巴士完整线路站点信息.json'
with open(output_file, 'w', encoding='utf-8') as f:
json.dump(all_routes, f, ensure_ascii=False, indent=2)
# 生成统计报告
success_count = len(all_routes)
total_count = len(route_data['data'])
success_rate = (success_count / total_count * 100) if total_count > 0 else 0
total_intervals = sum(route['intervalCount'] for route in all_routes)
total_stations = sum(route['stationCount'] for route in all_routes)
report = {
'total_routes': total_count,
'successful_routes': success_count,
'failed_routes': total_count - success_count,
'success_rate': f"{success_rate:.1f}%",
'total_intervals': total_intervals,
'total_stations': total_stations,
'timestamp': datetime.now().strftime('%Y-%m-%d %H:%M:%S'),
'summary': [{
'lineName': route['lineName'],
'intervalCount': route['intervalCount'],
'stationCount': route['stationCount'],
'color': route['color']
} for route in all_routes]
}
report_file = '乔巴士完整统计报告.json'
with open(report_file, 'w', encoding='utf-8') as f:
json.dump(report, f, ensure_ascii=False, indent=2)
# 生成详细报告文本
detailed_report = []
detailed_report.append("乔巴士线路站点完整统计报告")
detailed_report.append(f"生成时间: {datetime.now().strftime('%Y-%m-%d %H:%M:%S')}")
detailed_report.append(f"")
detailed_report.append(f"总体统计:")
detailed_report.append(f" 总线路数: {total_count}")
detailed_report.append(f" 成功获取: {success_count} 条线路")
detailed_report.append(f" 失败数量: {total_count - success_count} 条线路")
detailed_report.append(f" 成功率: {success_rate:.1f}%")
detailed_report.append(f" 总班次数: {total_intervals}")
detailed_report.append(f" 总站点数: {total_stations}")
detailed_report.append(f"")
detailed_report.append(f"线路详情:")
for route in all_routes:
detailed_report.append(f" {route['lineName']} ({route['color']})")
detailed_report.append(f" 班次数: {route['intervalCount']}")
detailed_report.append(f" 站点数: {route['stationCount']}")
# 显示部分站点信息
if route['stations']:
sample_stations = route['stations'][:5] # 显示前5个站点
detailed_report.append(f" 站点示例:")
for station in sample_stations:
detailed_report.append(f" - [{station['type']}] {station['name']}")
if len(route['stations']) > 5:
detailed_report.append(f" ... 还有 {len(route['stations']) - 5} 个站点")
detailed_report.append(f"")
report_text_file = '乔巴士详细统计报告.txt'
with open(report_text_file, 'w', encoding='utf-8') as f:
f.write('\n'.join(detailed_report))
print(f"{'='*60}")
print(f"批量获取完成!")
print(f"总线路数: {total_count}")
print(f"成功获取: {success_count} 条线路")
print(f"失败数量: {total_count - success_count} 条线路")
print(f"成功率: {success_rate:.1f}%")
print(f"总班次数: {total_intervals}")
print(f"总站点数: {total_stations}")
print(f"{'='*60}")
print(f"结果已保存到:")
print(f" 1. {output_file} - 完整线路站点信息JSON")
print(f" 2. {report_file} - 统计报告JSON")
print(f" 3. {report_text_file} - 详细统计报告文本")
if __name__ == '__main__':
main()