爬虫:也称网络爬虫(网络机器人),是一种按照一定的预设规则,自动浏览并抓取网络数据的程序或脚本
开始 ---> 发送Http请求 ---> 解析结果提取数据---->数据处理(清洗)-->数据存储 --->结束
数据清洗:是指对采集到的原始数据进行处理,修正,转换和标准化的过程,目的是让数据变得数据变得规范,准确
robots协议:
robots协议也称为爬虫协议,爬虫规则,是指网站根目录下存放的一份文本文件robots.txt,用于告诉爬虫那些页面可以抓取,哪些页面不能抓取。(君子协议)

User-Agent: 用户代理,通过该请求头确认爬虫的类型
Disallow: 禁止访问的资源
Allow: 运行访问的资源
Sitemap: 网站地图,帮助爬虫更高效地获取网站内容
Craw-delay: 爬取间隔时间,避免频繁访问造成网站地压力过大
怎么查看每个网站的robots协议
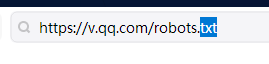
在每个网址后面加上/robots.txt
练习: 获取TIOBE编程语言排行榜单
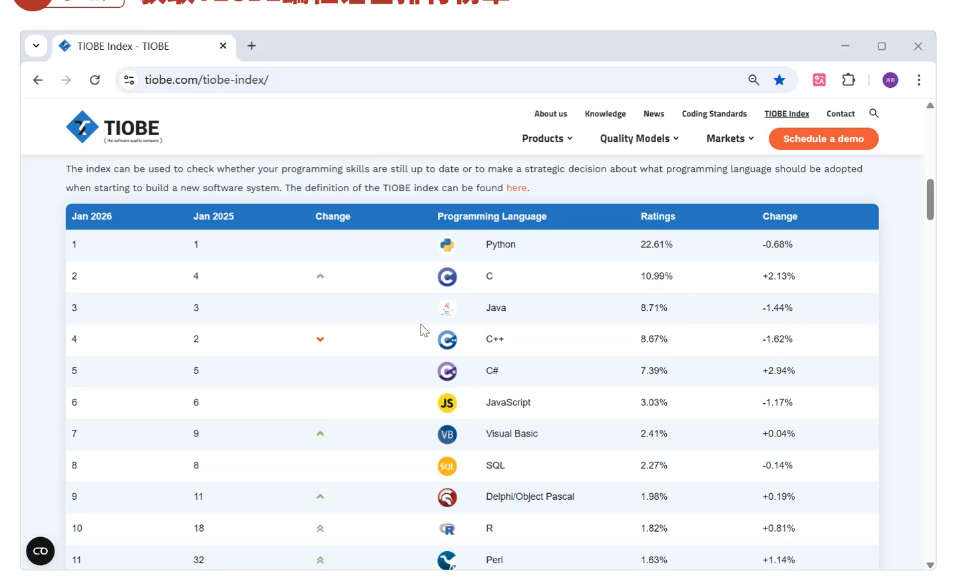
查看TIOBE网站的robots.txt文件,明确资源获取的规则
安装requests库,用于发送网络请求(pip install requests)
编写python代码,访问TIOBE网站,获取数据
代码示例
import requests # 定义url target_url = "http://www.tiobe.com/tiobe-index/" # 发送请求,获取数据 response = requests.get(target_url) # 输出到控制台 print(response.text) 这里提一嘴,所有的网络请求都是get请求另外返回的是页面的前端代码,接下来就是解析结果处理数据
处理前端数据前先说明一下网页结构也就是前端的基础知识
一个网页是由三个部分组成的,分别是:HTML,CSS,JS
HTML: 超文本语言,由一堆预设的标签构成。HTML负责网页的结构(页面元素和内容)
CSS: 层叠样式表。CSS负责网页的表现(页面元素的外观,位置等样式,如颜色,大小等)
JS: 全称:JavaScript,负责网页的行为(交互效果)
我们要抓取的是网页当中的内容 也就是HTML控制页面的内容
HTML: 超文本标记语言。
超文本: 超越了文本的限制,比普通文本更强大。除了文字信息,还可以定义图片,音频,视频等内容
标记语言: 由标签"<标签名>"构成的语言
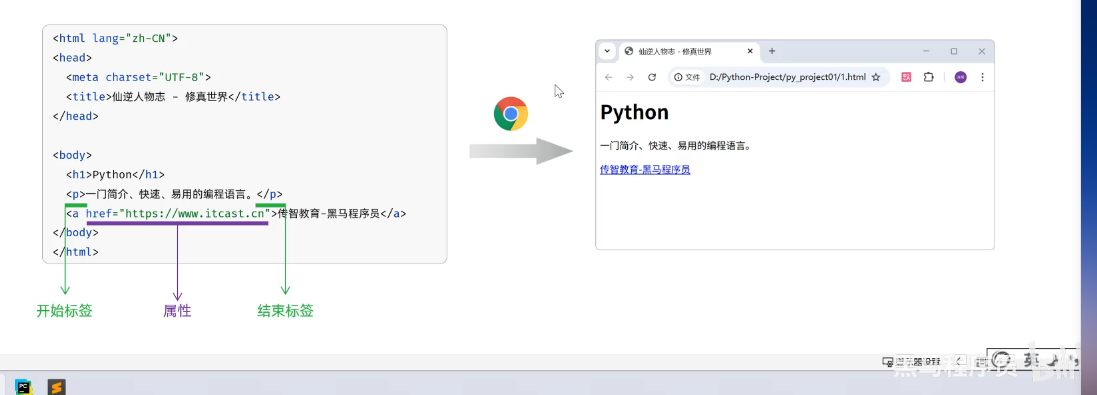
HTML标签都是预定义好的。例如:使用<h1>展示标题,使用<img>展示图片,使用<video>展示视频。
HTML代码直接在浏览器中运行,HTML标签由浏览器解析
接下来回归正轨
如何解析返回的前端代码,那就是lxml
啥事lxml
lxml: 是一个高性能的HTML/XML文档的解析库,支持Xpath语法来解析和获取网页数据
Xpath语法:
一种在HTML/XML文档中导航或定位元素的查询语言,让你能够准确的定位文档中的特定元素,属性或文本
|-------------------|----------------|---------------------|
| 表达式 | 描述 | 举例 |
| / | 从根节点的直接子元素 | /html/body/div/h1 |
| // | 从任意位置选择节点 | //h1 |
| . | 当前节点下查找 | ./a与.//a |
| n | 选择第n个元素 | //p2 |
| last() | 选择最后一个元素 | //plast() |
| @attr | 选择有该属性的元素 | //p@color |
| @attr='value' | 选择该属性指等于指定值的元素 | //p@color='red' |
| * | 匹配任何元素节点 | //body/div/* |
| @* | 匹配元素的任何属性 | //body/div/a/@* |
| text() | 获取文本内容 | //div/p/text() |
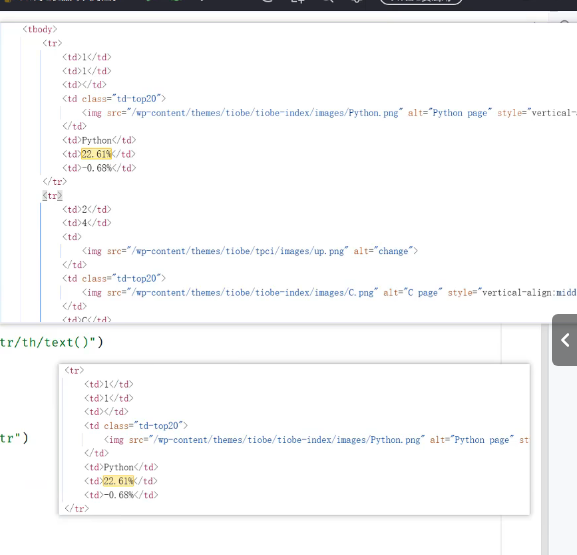
那么怎么从这个图片中解析数据

response = requests.get(target_url) document = html.fromstring(response.text) #解析数据 th_list=document.xpath("//table[@id='top20']/thead/tr/th/text()") print(th_list)
怎么讲每个tr单独占一行打印出来
tr_list=document.xpath("//table[@id='top20']/tbody/tr") for tr in tr_list: td_list=tr.xpath("./td/text()") print(td_list)