文章目录
- 前言
- 一、整体流程与文件准备
- [二、 pt转onnx](#二、 pt转onnx)
- 三、onnx转RKNN
- 四、RKNN板端部署运行
- 总结
前言
因工作上需要用到瑞芯微的RK3576进行部署目标检测算法,故本文以yolov8为例,记录RK3576部署过程。
一、整体流程与文件准备
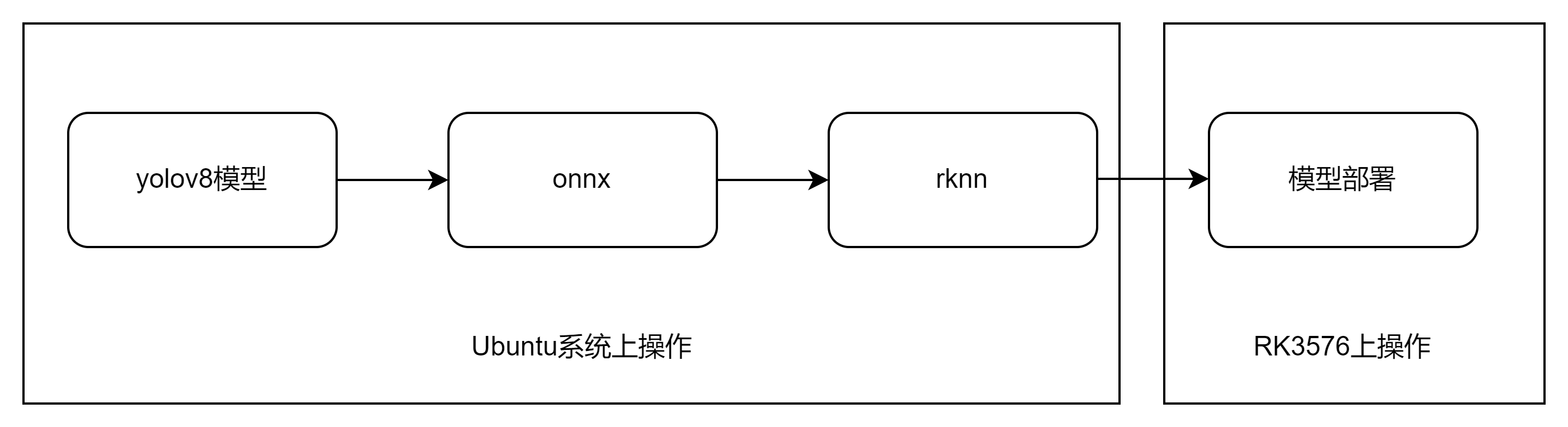
下载rknn-toolkit2工具包:https://codeload.github.com/airockchip/rknn-toolkit2/zip/refs/tags/v2.3.2
解压工具
1.在ubuntu系统对应的虚拟环境上安装rknn_toolkit:
位置为~/rknn-toolkit2-2.3.2/rknn-toolkit2/packages/x86_64/
笔者选用的是python3.10版本:
python
pip install rknn_toolkit2-2.3.2-cp310-cp310-manylinux_2_17_x86_64.manylinux2014_x86_64.whl2.在RK3576板端环境上安装rknn_toolkit_lite2:
把位置为~/rknn-toolkit2-2.3.2/rknn-toolkit-lite2/packages的rknn_toolkit_lite2的whl包复制到板端
笔者选用的也是python3.10版本:
python
pip install rknn_toolkit_lite2-2.3.2-cp310-cp310-manylinux_2_17_aarch64.manylinux2014_aarch64.whl二、 pt转onnx
yolov8pt模型->onnx不能使用原生的方式,需要使用ultralytics_yolov8项目里的export.pt文件导出onnx才行。https://github.com/airockchip/ultralytics_yolov8/
以yolov8n模型为例:
python
export PYTHONPATH=./
python ./ultralytics/engine/exporter.py执行完毕后,生成一个 .onnx文件和一个配套的 .onnx.data文件。假如原始模型为 yolov8n.pt,则生成 yolov8n.onnx 模型与yolov8n.onnx.data权重参数。
这里给出原生导出的onnx与ultralytics_yolov8项目导出的onnx的图。
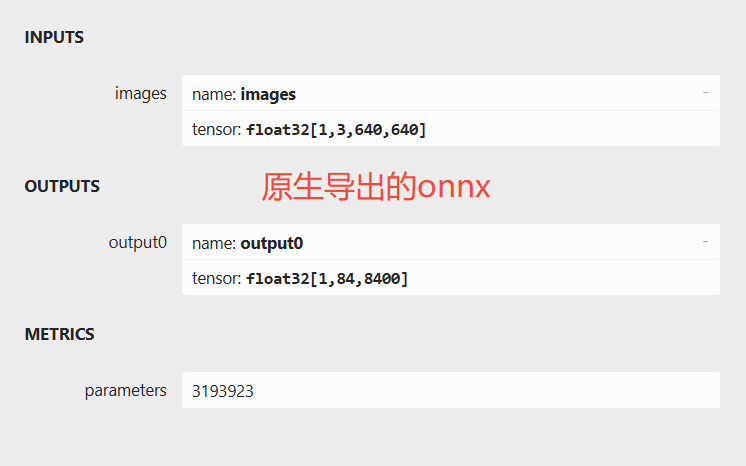
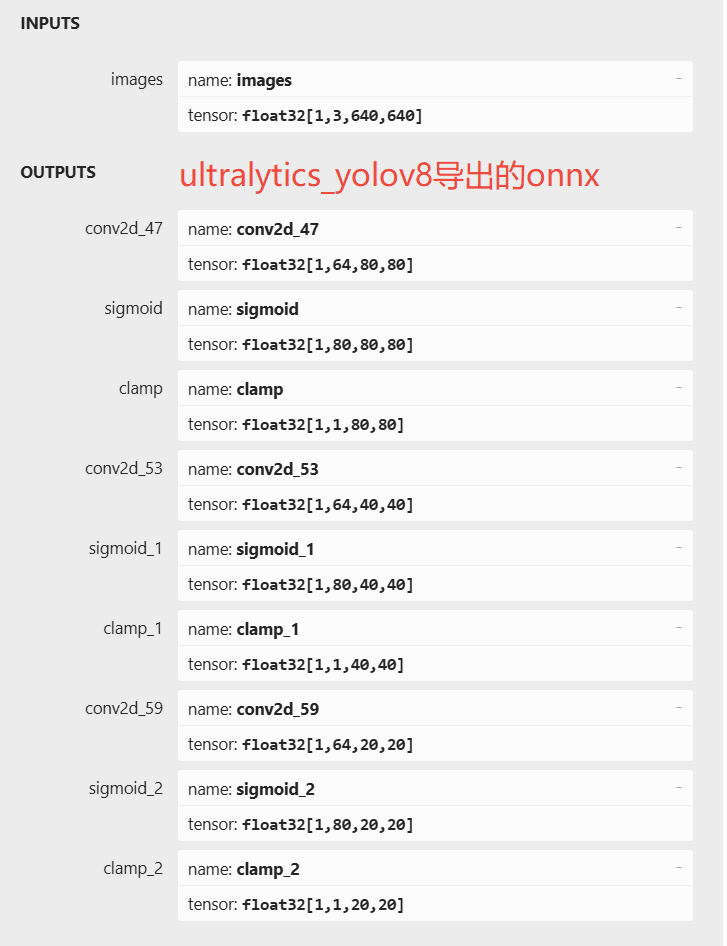
在基于不影响输出结果, 不需要重新训练模型的条件下, 有以下改动:
-
修改输出结构, 移除后处理结构. (后处理结果对于量化不友好)
-
dfl 结构在 NPU 处理上性能不佳,移至模型外部的后处理阶段,此操作大部分情况下可提升推理性能。
-
模型输出分支新增置信度的总和,用于后处理阶段加速阈值筛选。
三、onnx转RKNN
3.1准备量化数据文件
新建creat_dataset.py文件
python
import os
import random
# 配置路径
image_dir = './quant_dataset/coco_data'
output_file = 'dataset.txt'
num_samples = 1000
def generate_calibration_dataset():
# 1. 获取目录下所有图片文件
valid_extensions = ('.jpg', '.jpeg', '.png', '.bmp')
all_images = [
os.path.join(image_dir, f) for f in os.listdir(image_dir)
if f.lower().endswith(valid_extensions)
]
# 2. 检查图片数量是否足够
if len(all_images) < num_samples:
print(f"警告:目录下只有 {len(all_images)} 张图片,将全部使用。")
selected_images = all_images
else:
# 3. 随机抽取
selected_images = random.sample(all_images, num_samples)
# 4. 写入 dataset.txt
with open(output_file, 'w') as f:
for img_path in selected_images:
f.write(img_path + '\n')
print(f"成功!已随机抽取 {len(selected_images)} 张图片,路径已保存至 {output_file}")
if __name__ == '__main__':
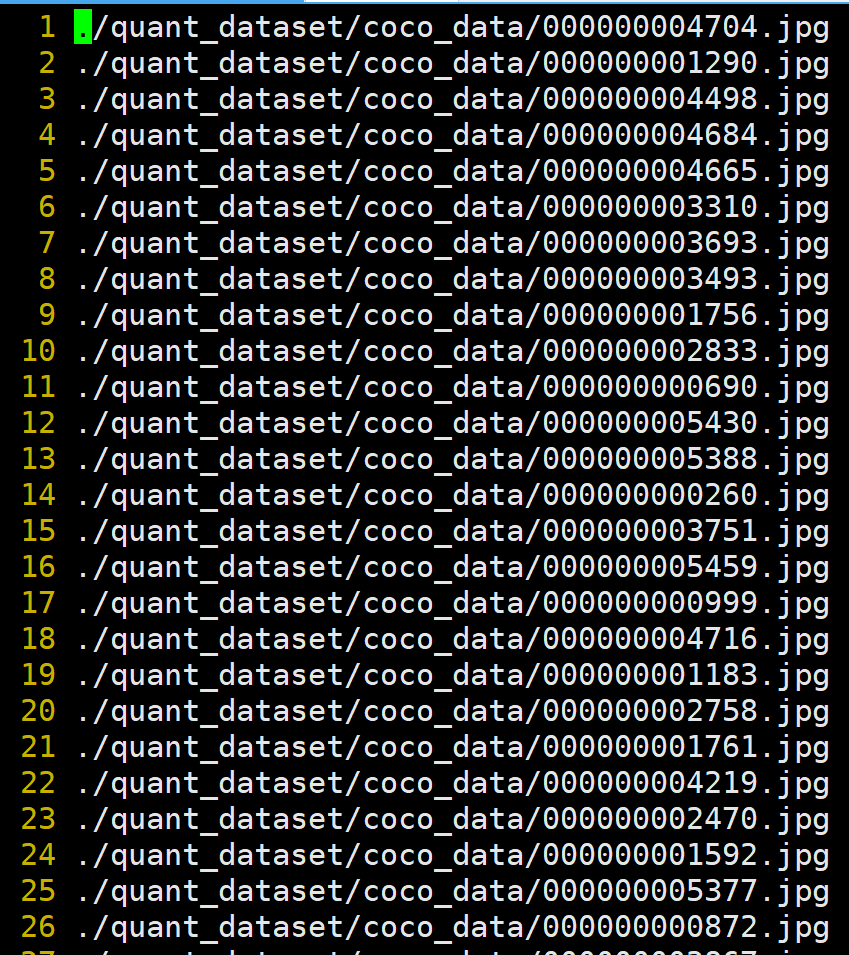
generate_calibration_dataset()其中coco_data为存放量化模型所需的数据
执行后会生成量化图像列表dataset.txt
dataset.txt内容如下:
3.2模型转换
新建onnx2rknn.py文件
python
import os
from rknn.api import RKNN
def convert_model():
# 参数设置
ONNX_MODEL = 'yolov8n.onnx'
RKNN_MODEL = 'yolov8n_rk3576.rknn'
DATASET_PATH = './dataset.txt' # 存放校准图片路径的文件
rknn = RKNN(verbose=True)
# 1. 配置 RKNN 转换参数
# target_platform 必须指定为 rk3576
# mean_values 和 std_values 对应 YOLOv8 的预处理 (归一化到 0-1)
print('--> Config model')
rknn.config(
mean_values=[[0, 0, 0]],
std_values=[[255, 255, 255]],
target_platform='rk3576',
)
# 2. 加载 ONNX 模型
print('--> Loading model')
ret = rknn.load_onnx(model=ONNX_MODEL)
if ret != 0:
print('Load model failed!')
return
# 3. 构建 RKNN 模型 (进行 INT8 量化)
# do_quantization=True 表示开启量化,这能大幅提升 RK3576 的推理速度
print('--> Building model')
ret = rknn.build(do_quantization=True,
dataset=DATASET_PATH,
)
if ret != 0:
print('Build model failed!')
return
# 4. 导出 RKNN 模型
print('--> Export rknn model')
ret = rknn.export_rknn(RKNN_MODEL)
if ret != 0:
print('Export rknn model failed!')
return
print('--> Convert done!')
rknn.release()
if __name__ == '__main__':
convert_model()将之前生成 yolov8n.onnx 模型与yolov8n.onnx.data权重参数放到对应的目录下:
执行
python
python onnx2rknn.py会得到一个rknn模型:yolov8n_rk3576.rknn
四、RKNN板端部署运行
在3576板端新建test.py文件:
python
import cv2
import numpy as np
import os
import time
from rknnlite.api import RKNNLite as RKNN
# --- 配置参数 ---
OBJ_THRESH = 0.45
NMS_THRESH = 0.25
IMG_SIZE = (640, 640) # 宽度, 高度
CLASSES = ("person", "bicycle", "car", "motorbike", "aeroplane", "bus", "train", "truck", "boat", "traffic light",
"fire hydrant", "stop sign", "parking meter", "bench", "bird", "cat", "dog", "horse", "sheep", "cow", "elephant",
"bear", "zebra", "giraffe", "backpack", "umbrella", "handbag", "tie", "suitcase", "frisbee", "skis", "snowboard",
"sports ball", "kite", "baseball bat", "baseball glove", "skateboard", "surfboard", "tennis racket", "bottle",
"wine glass", "cup", "fork", "knife", "spoon", "bowl", "banana", "apple", "sandwich", "orange", "broccoli",
"carrot", "hot dog", "pizza", "donut", "cake", "chair", "sofa", "pottedplant", "bed", "diningtable", "toilet",
"tvmonitor", "laptop", "mouse", "remote", "keyboard", "cell phone", "microwave", "oven", "toaster", "sink",
"refrigerator", "book", "clock", "vase", "scissors", "teddy bear", "hair drier", "toothbrush")
# --- 核心算法函数 ---
def softmax(x, axis=None):
exp_x = np.exp(x - np.max(x, axis=axis, keepdims=True))
return exp_x / np.sum(exp_x, axis=axis, keepdims=True)
def dfl_numpy(position):
"""NumPy实现DFL: 将特征图通道转换为坐标偏移"""
n, c, h, w = position.shape
p_num = 4
mc = c // p_num
y = position.reshape(n, p_num, mc, h, w)
y = softmax(y, axis=2)
acc_matrix = np.arange(mc).reshape(1, 1, mc, 1, 1).astype(float)
y = (y * acc_matrix).sum(2)
return y
def box_process(position, grid_h, grid_w):
"""计算实际像素坐标"""
col, row = np.meshgrid(np.arange(0, grid_w), np.arange(0, grid_h))
col = col.reshape(1, 1, grid_h, grid_w)
row = row.reshape(1, 1, grid_h, grid_w)
grid = np.concatenate((col, row), axis=1)
stride = np.array([IMG_SIZE[1]//grid_h, IMG_SIZE[0]//grid_w]).reshape(1, 2, 1, 1)
position = dfl_numpy(position)
box_xy = grid + 0.5 - position[:, 0:2, :, :]
box_xy2 = grid + 0.5 + position[:, 2:4, :, :]
xyxy = np.concatenate((box_xy * stride, box_xy2 * stride), axis=1)
return xyxy
def nms_boxes(boxes, scores):
"""非极大值抑制"""
x, y = boxes[:, 0], boxes[:, 1]
w, h = boxes[:, 2] - boxes[:, 0], boxes[:, 3] - boxes[:, 1]
areas = w * h
order = scores.argsort()[::-1]
keep = []
while order.size > 0:
i = order[0]
keep.append(i)
xx1 = np.maximum(x[i], x[order[1:]])
yy1 = np.maximum(y[i], y[order[1:]])
xx2 = np.minimum(x[i] + w[i], x[order[1:]] + w[order[1:]])
yy2 = np.minimum(y[i] + h[i], y[order[1:]] + h[order[1:]])
w1 = np.maximum(0.0, xx2 - xx1 + 1e-5)
h1 = np.maximum(0.0, yy2 - yy1 + 1e-5)
inter = w1 * h1
ovr = inter / (areas[i] + areas[order[1:]] - inter)
inds = np.where(ovr <= NMS_THRESH)[0]
order = order[inds + 1]
return np.array(keep)
def post_process(input_data):
if input_data is None: return None, None, None
# 1. 整理输出层
layers = {}
for out in input_data:
h, w = out.shape[2:4]
if (h, w) not in layers:
layers[(h, w)] = []
layers[(h, w)].append(out)
all_boxes, all_scores, all_class_ids = [], [], []
for res in layers:
tensors = layers[res]
box_t, score_t, obj_t = None, None, None
for t in tensors:
if t.shape[1] == 64: box_t = t
elif t.shape[1] == len(CLASSES): score_t = t
elif t.shape[1] == 1: obj_t = t
if box_t is None or score_t is None: continue
# --- 核心修复 1: YOLOv8 不需要乘 Objectness ---
# 如果你的模型是从标准 YOLOv8 转换的,通常不需要 obj_t。
# 如果 C++ 置信度高,说明 C++ 可能没乘这个 obj_t。
# 计算类别得分 (Sigmoid)
# s = 1 / (1 + np.exp(-score_t))
s = score_t
# 如果你确定模型包含独立的 Objectness 层(如某些特定的 RKNN 导出配置)
if obj_t is not None:
# o = 1 / (1 + np.exp(-obj_t))
o = obj_t
s = s * o # 只有在确定的情况下才保留这一行
# --- 核心修复 2: 转换维度并过滤低分 ---
s = s.transpose(0, 2, 3, 1).reshape(-1, len(CLASSES))
b = box_process(box_t, res[0], res[1]).transpose(0, 2, 3, 1).reshape(-1, 4)
# 找出每个 anchor 的最大得分和对应类别
max_scores = np.max(s, axis=1)
max_class_ids = np.argmax(s, axis=1)
# 初步筛选,减少 NMS 的计算量
idx = max_scores > 0.05 # 使用较低的初筛阈值
all_boxes.append(b[idx])
all_scores.append(max_scores[idx])
all_class_ids.append(max_class_ids[idx])
if not all_boxes: return None, None, None
boxes = np.concatenate(all_boxes)
scores = np.concatenate(all_scores)
class_ids = np.concatenate(all_class_ids)
# --- 使用 cv2.dnn.NMSBoxes 优化 ---
# 注意:cv2.dnn.NMSBoxes 需要的是 [x, y, w, h] 格式
# 目前 boxes 是 [x1, y1, x2, y2]
nms_boxes_format = []
for box in boxes:
nms_boxes_format.append([box[0], box[1], box[2] - box[0], box[3] - box[1]])
# 这里的 OBJ_THRESH 建议设低一点,看看是否是因为过滤太狠
indices = cv2.dnn.NMSBoxes(nms_boxes_format, scores.tolist(), OBJ_THRESH, NMS_THRESH)
if len(indices) > 0:
# 适配不同版本的 OpenCV 返回格式
if isinstance(indices, np.ndarray):
indices = indices.flatten()
return boxes[indices], class_ids[indices], scores[indices]
return None, None, None
# --- 图像预处理 ---
def letterbox(img, new_shape=(640, 640), color=(0, 0, 0)):
"""保持纵横比的缩放与填充"""
shape = img.shape[:2] # [h, w]
r = min(new_shape[0] / shape[0], new_shape[1] / shape[1])
new_unpad = (int(round(shape[1] * r)), int(round(shape[0] * r)))
dw, dh = (new_shape[1] - new_unpad[0]) / 2, (new_shape[0] - new_unpad[1]) / 2
if shape[::-1] != new_unpad:
img = cv2.resize(img, new_unpad, interpolation=cv2.INTER_LINEAR)
top, bottom = int(round(dh - 0.1)), int(round(dh + 0.1))
left, right = int(round(dw - 0.1)), int(round(dw + 0.1))
img = cv2.copyMakeBorder(img, top, bottom, left, right, cv2.BORDER_CONSTANT, value=color)
return img, r, (dw, dh)
# --- 主程序 ---
if __name__ == '__main__':
MODEL_PATH = 'yolov8n_rk3576.rknn' # 修改为你的模型路径
IMG_PATH = 'bus.jpg' # 修改为你的测试图路径
# 1. 初始化 RKNN
rknn = RKNN()
print('--> Loading RKNN model...')
if rknn.load_rknn(MODEL_PATH) != 0:
print('Load RKNN model failed!'); exit()
print('--> Init runtime...')
if rknn.init_runtime() != 0:
print('Init runtime failed!'); exit()
# 2. 图像准备
img_src = cv2.imread(IMG_PATH)
if img_src is None:
print("Error: Could not read image!"); exit()
img_rgb = cv2.cvtColor(img_src, cv2.COLOR_BGR2RGB)
img_pad, ratio, (dw, dh) = letterbox(img_rgb, IMG_SIZE)
# 核心修复:增加 Batch 维度 (1, 640, 640, 3)
# input_data = img_pad.astype(np.float32) / 255.0
input_data = np.expand_dims(img_pad, axis=0)
# 3. 推理
print('--> Running inference...')
outputs = rknn.inference(inputs=[input_data], data_format='nhwc')
# outputs = rknn.inference(inputs=[input_data])
print(f"Output max: {np.max(outputs[0])}, min: {np.min(outputs[0])}")
# 4. 后处理
print('--> Post-processing...')
boxes, classes, scores = post_process(outputs)
# 5. 绘制结果
if boxes is not None:
print(len(boxes))
for box, score, cl in zip(boxes, scores, classes):
# 坐标还原到原图大小
x1 = int((box[0] - dw) / ratio)
y1 = int((box[1] - dh) / ratio)
x2 = int((box[2] - dw) / ratio)
y2 = int((box[3] - dh) / ratio)
# print(f"{CLASSES[cl]} @ ({x1} {y1} {x2} {y2}) {score:.3f}")
cv2.rectangle(img_src, (x1, y1), (x2, y2), (255, 0, 0), 2)
cv2.putText(img_src, f'{CLASSES[cl]} {score:.2f}', (x1, y1 - 10),
cv2.FONT_HERSHEY_SIMPLEX, 0.6, (0, 0, 255), 2)
cv2.imwrite('result.jpg', img_src)
print('Success! Result saved to result.jpg')
else:
print("No objects detected.")
rknn.release()将之前生成的yolov8n_rk3576.rknn与测试图片复制到板端相应的目录:
执行
python
python test.py

至此整个流程就算是完成了。
总结
本文记录了基于瑞芯微RK3576的yolov8部署流程。需要注意的是pt转onnx这一步不能使用原生的方式,在基于不影响输出结果, 不需要重新训练模型的条件下, 修改输出结构, 移除后处理结构;dfl 结构在 NPU 处理上性能不佳,移至模型外部的后处理阶段;模型输出分支新增置信度的总和,用于后处理阶段加速阈值筛选。经测试,yolov8n模型经过转换后的rknn模型,在3576上单线程且做NPU加速情况下约为22帧左右。
参考文档:
https://github.com/airockchip/rknn-toolkit2
https://github.com/airockchip/ultralytics_yolov8
https://github.com/airockchip/ultralytics_yolov8/blob/main/RKOPT_README.zh-CN.md
https://github.com/airockchip/rknn_model_zoo
https://blog.csdn.net/easy_eai/article/details/146945656
2026年3月20日15:15:05
