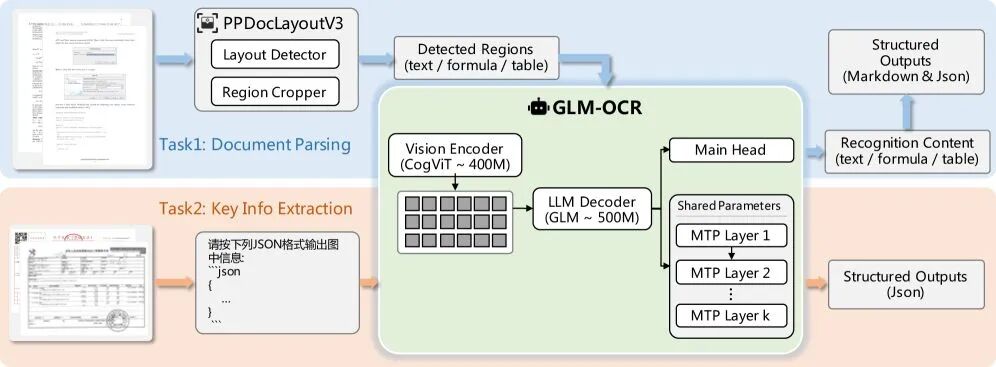
在数字化转型的浪潮中,文档智能处理已成为企业提升效率的关键环节。无论是财务部门处理海量发票,还是科研人员数字化学术论文,OCR(光学字符识别)技术 都扮演着不可或缺的角色。然而,传统 OCR 技术长期面临着一个两难困境:高精度模型往往参数量巨大、部署成本高昂,而轻量级模型又难以应对复杂场景。智谱 AI 开源发布的 GLM-OCR 模型 打破了这一僵局,以仅 0.9B 的参数量 实现了业界领先的文档解析能力,在权威榜单 OmniDocBench V1.5 中以 94.6 分取得 SOTA 性能,成为 OCR 领域的一次重要技术突破。

小模型,大能力:GLM-OCR 的核心优势
GLM-OCR 最令人瞩目的特点在于其"小尺寸、高精度"的设计理念。相比动辄数十亿参数的大型多模态模型,GLM-OCR 仅需 0.9B 参数,却在 文本识别、公式解析、表格提取和信息抽取四大核心领域**展现出卓越性能,甚至在某些维度上接近 Gemini-3-Pro 的表现水平。这种高效的参数利用率得益于智谱 AI 自研的 CogViT 视觉编码器 和 GLM-V 架构的深度融合。
从实际部署角度看,GLM-OCR 的轻量化设计带来了显著的成本优势。模型仅需 4GB 显存 即可运行,单张 A4 文档的识别时间仅为 100-200 毫秒 ,PDF 文档处理吞吐量达到 1.86 页/秒 ,图片处理速度为 0.67 张/秒 。在价格方面更是极具竞争力:API 调用成本仅为 0.2 元/百万 Tokens ,1 元即可处理约 2000 张 A4 扫描图片或 200 份 10 页简单排版 PDF ,成本约为传统 OCR 方案的 1/10。这使得 GLM-OCR 不仅适合云端大规模部署,也能够在边缘设备和移动端灵活运行,真正实现了"普惠 AI"的愿景。
技术架构:多模态融合的创新实践
GLM-OCR 的技术架构体现了多模态大模型设计的前沿思路。整个系统基于编码器-解码器架构 构建,核心包含三大组件 :在大规模图文数据上预训练的 CogViT 视觉编码器 、具有高效令牌下采样机制的轻量级跨模态连接器 ,以及 GLM-0.5B 语言解码器。这种设计使得模型能够深度理解图像中的视觉信息,并将其转化为结构化的文本输出。
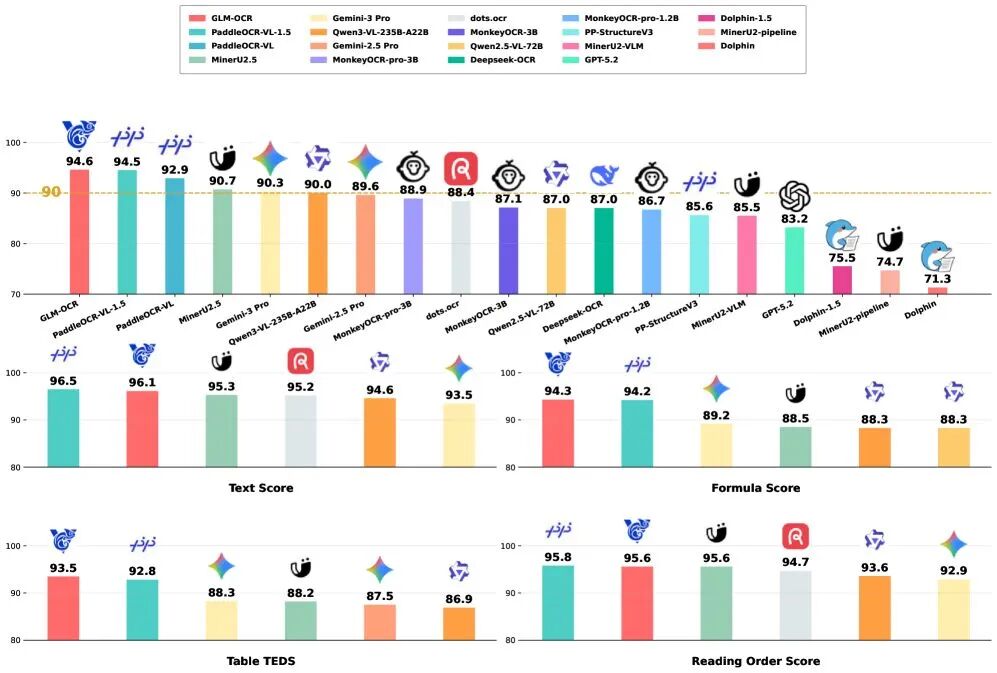
CogViT 视觉编码器 是 GLM-OCR 的技术亮点之一。不同于传统的 ViT 架构,CogViT 引入了认知增强模块和多尺度特征融合机制 ,能够同时捕捉文档中的细粒度文字信息和宏观版式结构。这种多层次的特征提取能力使得模型在处理复杂表格、手写体、印章等场景时表现出色。
更值得关注的是,GLM-OCR 引入了多令牌预测(Multi-Token Prediction, MTP)损失函数和稳定的全任务强化学习机制。MTP 技术能够在推理时预测多个 token,显著提升解码速度;而基于人类反馈的强化学习(RLHF)训练框架则针对 OCR 特定任务进行优化,使模型输出更符合实际应用需求。此外,GLM-OCR 还结合了基于 PP-DocLayout-V3 的"版面分析与并行识别"两阶段流程,先理解文档整体布局,再进行精准识别,大幅提升了训练效率和泛化能力。
全场景覆盖:从手写体到复杂表格
GLM-OCR 的另一大优势在于其出色的场景适应性。在智谱 AI 的内部测评中,模型在六大核心场景 中均取得显著优势:代码文档识别准确率达 96.7%,真实场景表格解析准确率为 92.8%,手写体识别准确率达 95.2%,多语言混排识别准确率为 94.3%,印章识别准确率为 91.5% ,票据提取表现同样出色。这种全场景覆盖能力意味着企业无需针对不同应用场景部署多个专用模型,一个 GLM-OCR 即可满足绝大多数文档处理需求。
在实际应用中,GLM-OCR 能够精准解析扫描件、PDF、表格及票据,有效解决手写、印章、竖排及多语言混排等传统 OCR 难题。无论是财务人员处理增值税发票,需要提取发票号码、开票日期、购买方信息、金额合计等结构化字段;还是科研人员数字化学术论文,需要识别复杂的数学公式并输出 LaTeX 格式;抑或是法务人员分析合同文档,需要理解复杂的版式布局和条款结构,GLM-OCR 都能提供高质量的识别结果。

从实际部署角度看,GLM-OCR 的轻量化设计带来了显著的成本优势。模型仅需 4GB 显存 即可运行,单张 A4 文档的识别时间仅为 100-200 毫秒 ,PDF 文档处理吞吐量达到 1.86 页/秒 ,图片处理速度为 0.67 张/秒 。在价格方面更是极具竞争力:API 调用成本仅为 0.2 元/百万 Tokens ,1 元即可处理约 2000 张 A4 扫描图片或 200 份 10 页简单排版 PDF ,成本约为传统 OCR 方案的 1/10。这使得 GLM-OCR 不仅适合云端大规模部署,也能够在边缘设备和移动端灵活运行,真正实现了"普惠 AI"的愿景。
更值得关注的是,GLM-OCR 引入了多令牌预测(Multi-Token Prediction, MTP)损失函数和稳定的全任务强化学习机制。MTP 技术能够在推理时预测多个 token,显著提升解码速度;而基于人类反馈的强化学习(RLHF)训练框架则针对 OCR 特定任务进行优化,使模型输出更符合实际应用需求。此外,GLM-OCR 还结合了基于 PP-DocLayout-V3 的"版面分析与并行识别"两阶段流程,先理解文档整体布局,再进行精准识别,大幅提升了训练效率和泛化能力。
在实际应用中,GLM-OCR 能够精准解析扫描件、PDF、表格及票据,有效解决手写、印章、竖排及多语言混排等传统 OCR 难题。无论是财务人员处理增值税发票,需要提取发票号码、开票日期、购买方信息、金额合计等结构化字段;还是科研人员数字化学术论文,需要识别复杂的数学公式并输出 LaTeX 格式;抑或是法务人员分析合同文档,需要理解复杂的版式布局和条款结构,GLM-OCR 都能提供高质量的识别结果。

灵活部署:从云端到边缘
GLM-OCR 提供了多种灵活的部署方式,满足不同场景的需求。对于快速验证和小规模应用,可以直接调用智谱 AI 的云端 API,无需配置环境即可开始使用。对于有本地部署需求的企业,GLM-OCR 支持 Ollama、vLLM、SGLang 等主流推理框架,能够在单张消费级 GPU 上高效运行。特别是启用 MTP 加速后,推理速度可进一步提升,更适合高并发场景。
值得一提的是,GLM-OCR 完全开源,开发者可以在 ModelScope、Hugging Face 等平台获取模型权重,根据自身业务需求进行定制化微调。自发布以来,GLM-OCR 在 ModelScope 平台上获得了超过 12000 次下载和 2500+收藏,成为最受欢迎的 OCR 模型之一,这充分反映了开发者社区对轻量级、高精度 OCR 解决方案的强烈需求。
应用场景:赋能千行百业
GLM-OCR 的应用潜力覆盖了众多行业领域。在金融行业 ,可用于自动化处理发票、票据、银行卡、身份证等各类证照,大幅提升财务审核效率;在教育科研领域 ,能够数字化手写笔记、学术论文、实验报告,特别是对数学公式的精准识别能力 ,为知识管理提供了有力支持;在法律行业 ,可以快速解析合同条款、法律文书,提取关键信息并进行结构化存储;在制造业,能够识别生产文档、技术图纸中的代码和标注信息。
更重要的是,GLM-OCR 与大语言模型的无缝集成能力,使其成为 RAG(检索增强生成)系统的理想前端。通过将文档内容精准转换为结构化文本,GLM-OCR 为下游的知识检索和智能问答提供了高质量的数据基础,真正实现了从非结构化文档到智能应用的端到端闭环。
未来展望:持续演进的技术路线
智谱 AI 团队表示,未来将持续迭代 GLM-OCR,推出更多尺寸版本 以满足不同场景需求,并将能力延伸至更多语言和视频 OCR 领域 ,全面拓宽视觉智能的应用边界。从技术发展趋势看,轻量化、多模态、端到端将成为 OCR 技术演进的主要方向,而 GLM-OCR 正是这一趋势的先行者。
随着模型的持续优化和生态的不断完善,我们有理由相信,GLM-OCR 将推动 OCR 技术从专业工具走向大众应用,从单一场景走向全场景覆盖,真正实现"让机器像人一样理解文档"的愿景。对于开发者和企业而言,现在正是探索 GLM-OCR 应用潜力的最佳时机。
更重要的是,GLM-OCR 与大语言模型的无缝集成能力,使其成为 RAG(检索增强生成)系统的理想前端。通过将文档内容精准转换为结构化文本,GLM-OCR 为下游的知识检索和智能问答提供了高质量的数据基础,真正实现了从非结构化文档到智能应用的端到端闭环。
随着模型的持续优化和生态的不断完善,我们有理由相信,GLM-OCR 将推动 OCR 技术从专业工具走向大众应用,从单一场景走向全场景覆盖,真正实现"让机器像人一样理解文档"的愿景。对于开发者和企业而言,现在正是探索 GLM-OCR 应用潜力的最佳时机。
社区地址
OpenCSG社区:https://opencsg.com/models/zai-org/GLM-OCR
hf社区:https://huggingface.co/zai-org/GLM-OCR
关于 OpenCSG
OpenCSG是全球领先的开源大模型社区平台,致力于打造开放、协同、可持续生态,AgenticOps是人工智能领域的一种AI原生方法论, 由OpenCSG(开放传神)提出。AgenticOps是Agentic AI的最佳落地实践也是方法论。核心产品 CSGHub 提供模型、数据集、代码与 AI 应用的 一站式托管、协作与共享服务,具备业界领先的模型资产管理能力,支持多角色协同和高效复用。