目录
- [1. 引言:为什么数据库是现代应用的核心](#1. 引言:为什么数据库是现代应用的核心)
- [2. SQLite与MySQL对比选型指南](#2. SQLite与MySQL对比选型指南)
- [2.1 SQLite:轻量级嵌入式数据库](#2.1 SQLite:轻量级嵌入式数据库)
- [2.2 MySQL:企业级关系型数据库](#2.2 MySQL:企业级关系型数据库)
- [2.3 选型决策矩阵](#2.3 选型决策矩阵)
- [3. 数据库连接建立与连接池管理](#3. 数据库连接建立与连接池管理)
- [3.1 连接字符串配置详解](#3.1 连接字符串配置详解)
- [3.2 连接池的工作原理](#3.2 连接池的工作原理)
- [3.3 异常处理与连接回收](#3.3 异常处理与连接回收)
- [4. CRUD操作核心实战](#4. CRUD操作核心实战)
- [4.1 创建表与数据模型设计](#4.1 创建表与数据模型设计)
- [4.2 插入数据:单条与批量操作](#4.2 插入数据:单条与批量操作)
- [4.3 查询数据:筛选、排序与聚合](#4.3 查询数据:筛选、排序与聚合)
- [4.4 更新数据:条件更新与事务保证](#4.4 更新数据:条件更新与事务保证)
- [4.5 删除数据:安全删除策略](#4.5 删除数据:安全删除策略)
- [5. 查询优化:从秒级到毫秒级的飞跃](#5. 查询优化:从秒级到毫秒级的飞跃)
- [5.1 索引原理与创建策略](#5.1 索引原理与创建策略)
- [5.2 查询重写与执行计划分析](#5.2 查询重写与执行计划分析)
- [5.3 性能监控与瓶颈定位](#5.3 性能监控与瓶颈定位)
- [6. 事务处理与并发控制深度解析](#6. 事务处理与并发控制深度解析)
- [6.1 ACID特性数学形式化](#6.1 ACID特性数学形式化)
- [6.2 隔离级别与并发异常](#6.2 隔离级别与并发异常)
- [6.3 锁机制与死锁预防](#6.3 锁机制与死锁预防)
- [7. 综合实战案例:电商订单管理系统](#7. 综合实战案例:电商订单管理系统)
- [7.1 数据库设计](#7.1 数据库设计)
- [7.2 核心业务实现](#7.2 核心业务实现)
- [7.3 性能优化实践](#7.3 性能优化实践)
- [8. 总结与最佳实践](#8. 总结与最佳实践)
- [8.1 技术选型建议](#8.1 技术选型建议)
- [8.2 开发规范](#8.2 开发规范)
- [8.3 学习路径推荐](#8.3 学习路径推荐)
1. 引言:为什么数据库是现代应用的核心
数据是数字化时代的核心资产,数据库技术支撑着几乎所有现代应用的后端架构。掌握数据库操作技能已成为开发者必备能力。本文将从零开始,系统讲解SQLite和MySQL两大主流数据库的核心操作,覆盖数据库选型、连接管理、CRUD操作、查询优化和事务处理等关键主题,通过理论结合实战的方式帮助你构建完整的数据库知识体系。
2. SQLite与MySQL对比选型指南
选择适合的数据库是项目成功的第一步。SQLite和MySQL虽然都使用SQL语言,但在架构设计、性能特性和适用场景上存在显著差异。
2.1 SQLite:轻量级嵌入式数据库
SQLite采用"无服务器"架构,数据库以单个文件形式存储在磁盘上。这种设计带来了独特的优势:
核心特性:
- 零配置部署:无需安装数据库服务器,直接通过库文件访问
- 事务完整性:支持ACID事务,即使在系统崩溃后也能保持数据一致性
- 跨平台兼容:支持Windows、Linux、macOS、iOS、Android等主流平台
- 存储效率高:数据库文件紧凑,支持多种数据类型和索引
技术细节:
SQLite使用B-tree索引结构,查询时间复杂度为 O ( log n ) O(\log n) O(logn)。对于典型的CRUD操作,性能表现如下:
- 插入操作:约 5 × 10 4 5\times10^4 5×104 条/秒(无事务批量插入)
- 查询操作:简单查询 < 1 <1 <1 ms,复杂连接查询 10 − 100 10-100 10−100 ms
- 并发支持:通过文件锁实现,写操作互斥,读操作可并发
适用场景:
- 移动应用:iOS/Android应用的本地数据存储
- 桌面软件:单用户应用的配置和缓存管理
- 嵌入式系统:物联网设备的数据采集与存储
- 开发测试:快速原型验证和单元测试
2.2 MySQL:企业级关系型数据库
MySQL采用客户端-服务器架构,支持多用户并发访问和分布式部署:
核心特性:
- 高并发处理:支持数千并发连接,InnoDB引擎优化了锁机制
- 复制与高可用:主从复制、集群部署保证服务连续性
- 存储引擎可插拔:支持InnoDB(事务型)、MyISAM(非事务型)等多种引擎
- 安全机制完善:用户权限管理、SSL加密、审计日志
技术架构:
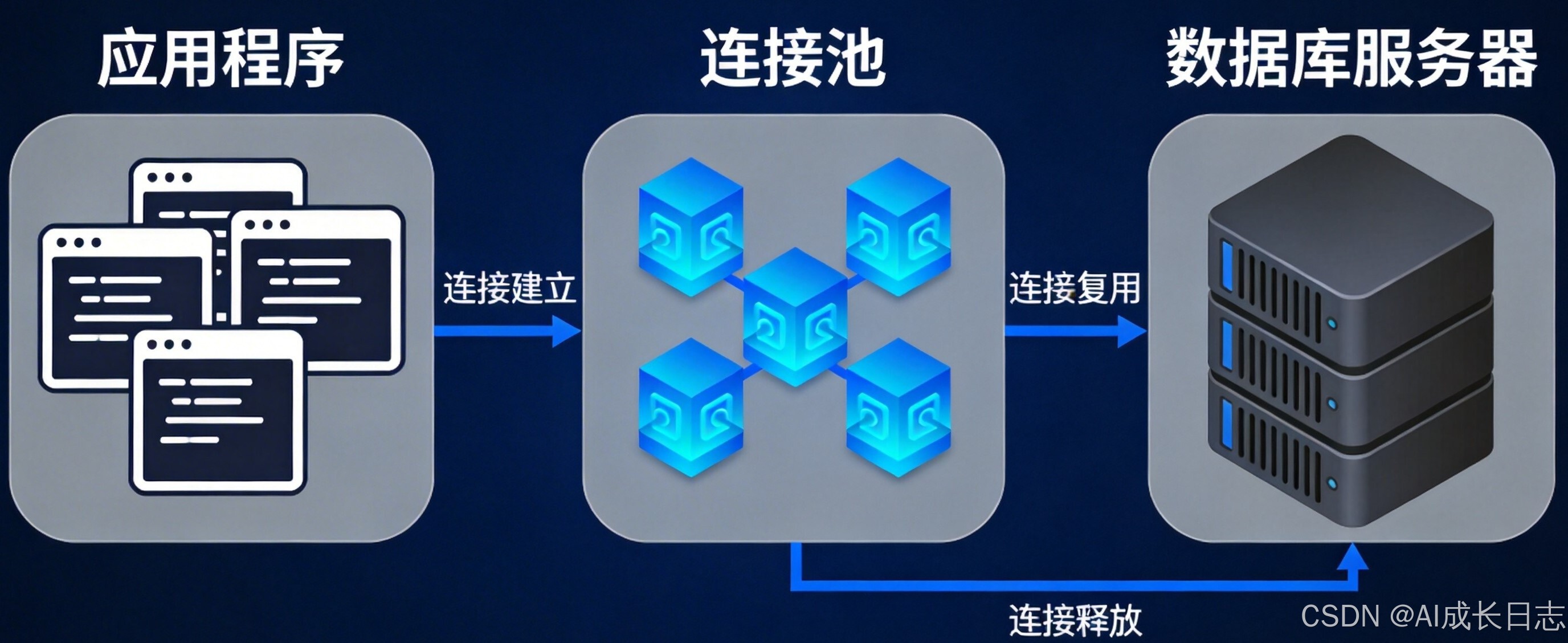
性能指标:
- 连接池:支持连接复用,减少连接建立开销
- 查询缓存:缓存查询结果,提升重复查询性能
- 分区表:支持水平分区,优化大数据量查询
- 并发控制:MVCC(多版本并发控制)减少锁竞争
适用场景:
- Web应用:电商平台、内容管理系统等
- 企业系统:ERP、CRM等业务管理系统
- 数据分析:数据仓库、报表系统
- 高可用服务:需要7×24小时连续运行的关键业务
2.3 选型决策矩阵
| 维度 | SQLite优势 | MySQL优势 | 推荐场景 |
|---|---|---|---|
| 部署复杂度 | ⭐⭐⭐⭐⭐ (无服务器) | ⭐⭐ (需要安装配置) | 快速原型选SQLite,生产环境选MySQL |
| 并发性能 | ⭐⭐ (文件锁限制) | ⭐⭐⭐⭐⭐ (连接池+MVCC) | 多用户并发选MySQL |
| 数据安全 | ⭐⭐⭐ (文件加密) | ⭐⭐⭐⭐⭐ (用户权限+审计) | 企业级安全要求选MySQL |
| 运维成本 | ⭐⭐⭐⭐⭐ (零运维) | ⭐⭐ (需要专业DBA) | 资源有限团队选SQLite |
| 扩展性 | ⭐⭐ (单文件限制) | ⭐⭐⭐⭐⭐ (集群+分区) | 大数据量选MySQL |
数学决策模型:
设项目需求向量为 R = ( r 1 , r 2 , ... , r n ) \mathbf{R} = (r_1, r_2, \ldots, r_n) R=(r1,r2,...,rn),数据库特性向量为 D = ( d 1 , d 2 , ... , d n ) \mathbf{D} = (d_1, d_2, \ldots, d_n) D=(d1,d2,...,dn),匹配度计算公式:
Score = R ⋅ D ∥ R ∥ ∥ D ∥ \text{Score} = \frac{\mathbf{R} \cdot \mathbf{D}}{\|\mathbf{R}\| \|\mathbf{D}\|} Score=∥R∥∥D∥R⋅D
通过量化评估,可以科学选择最适合的数据库方案。
3. 数据库连接建立与连接池管理
高效的连接管理是数据库性能的基石。本节将深入讲解连接建立、连接池原理和异常处理机制。
3.1 连接字符串配置详解
连接字符串是应用程序与数据库通信的"钥匙",包含了认证信息、连接参数和数据库位置。
SQLite连接字符串:
python
# 基本连接
conn_str = "file:example.db?mode=rwc"
# 带参数的连接
conn_str = """
file:data/app.db?
mode=rwc&
cache=shared&
journal_mode=WAL&
synchronous=NORMAL
"""MySQL连接字符串:
python
# 标准格式
conn_str = "mysql://user:password@localhost:3306/dbname"
# 带连接池参数
conn_str = """
mysql://user:password@localhost:3306/dbname?
charset=utf8mb4&
pool_size=10&
max_overflow=20&
pool_recycle=3600
"""参数解析:
mode:访问模式(ro=只读,rw=读写,rwc=读写创建)journal_mode:日志模式,WAL(Write-Ahead Logging)提升并发性能pool_size:连接池初始大小max_overflow:最大溢出连接数pool_recycle:连接回收时间(秒)
3.2 连接池的工作原理
连接池通过复用数据库连接,显著降低连接建立和销毁的开销。其核心算法如下:
- 初始化阶段:创建指定数量的连接,放入空闲队列
- 获取连接:从空闲队列取出连接,标记为使用中
- 使用连接:执行SQL操作,保持连接状态
- 归还连接:操作完成后,重置连接状态,放回空闲队列
- 超时处理:定期检查连接活跃时间,回收超时连接
连接池状态机:
创建连接 → 空闲状态 → 分配使用 → 繁忙状态
↑ ↓ ↑ ↓
回收连接 ← 检查超时 ← 操作完成 ← 执行SQLPython实现核心代码(≤20行):
python
import sqlite3
import threading
from queue import Queue
class SQLiteConnectionPool:
def __init__(self, db_path, pool_size=5):
self.db_path = db_path
self.pool_size = pool_size
self._lock = threading.Lock()
self._connections = Queue(pool_size)
self._init_pool()
def _init_pool(self):
"""初始化连接池"""
for _ in range(self.pool_size):
conn = sqlite3.connect(self.db_path, check_same_thread=False)
conn.execute("PRAGMA journal_mode=WAL") # 启用WAL模式
self._connections.put(conn)
def get_connection(self):
"""获取连接"""
return self._connections.get()
def return_connection(self, conn):
"""归还连接"""
self._connections.put(conn)
def close_all(self):
"""关闭所有连接"""
while not self._connections.empty():
conn = self._connections.get()
conn.close()性能对比:
- 无连接池:每次操作创建/销毁连接,耗时 50 − 100 50-100 50−100 ms
- 有连接池:连接复用,操作耗时 1 − 5 1-5 1−5 ms
- 连接池命中率: HitRate = 复用连接数 总连接数 × 100 % \text{HitRate} = \frac{\text{复用连接数}}{\text{总连接数}} \times 100\% HitRate=总连接数复用连接数×100%
3.3 异常处理与连接回收
健壮的异常处理机制是生产环境必备。常见异常类型及处理策略:
连接异常:
OperationalError:网络中断、数据库服务停止InterfaceError:连接中断、无效连接TimeoutError:查询超时、连接超时
事务异常:
IntegrityError:违反唯一约束、外键约束DatabaseError:SQL语法错误、数据类型不匹配
优雅降级策略:
python
def safe_database_operation(func):
"""数据库操作装饰器,提供异常处理和重试机制"""
def wrapper(*args, **kwargs):
max_retries = 3
for attempt in range(max_retries):
try:
return func(*args, **kwargs)
except (OperationalError, InterfaceError) as e:
if attempt == max_retries - 1:
raise DatabaseConnectionError(f"数据库连接失败: {e}")
time.sleep(2 ** attempt) # 指数退避
except IntegrityError as e:
raise BusinessLogicError(f"数据完整性错误: {e}")
except Exception as e:
logger.error(f"未知数据库错误: {e}")
raise
return wrapper连接健康检查:
定期执行SELECT 1验证连接有效性,失效连接自动重建。
4. CRUD操作核心实战
CRUD(Create, Read, Update, Delete)是数据库操作的基石。本节通过完整示例演示每个操作的最佳实践。
4.1 创建表与数据模型设计
良好的表结构设计是高效查询的基础。设计原则:
- 规范化:减少数据冗余,保证一致性
- 适当反规范化:提升查询性能,减少连接操作
- 索引策略:为主键、外键和频繁查询字段创建索引
用户表设计示例:
sql
-- SQLite/MySQL通用语法
CREATE TABLE users (
id INTEGER PRIMARY KEY AUTOINCREMENT, -- 自增主键
username VARCHAR(50) UNIQUE NOT NULL, -- 唯一用户名
email VARCHAR(100) UNIQUE NOT NULL, -- 唯一邮箱
password_hash CHAR(64) NOT NULL, -- 密码哈希值
created_at TIMESTAMP DEFAULT CURRENT_TIMESTAMP,
updated_at TIMESTAMP DEFAULT CURRENT_TIMESTAMP,
status TINYINT DEFAULT 1, -- 用户状态:1=正常,0=禁用
INDEX idx_username (username), -- 用户名索引
INDEX idx_email (email), -- 邮箱索引
INDEX idx_status_created (status, created_at) -- 复合索引
);数学规范化:
设关系模式 R ( A , B , C ) R(A,B,C) R(A,B,C),函数依赖集 F = { A → B , B → C } F = \{A \rightarrow B, B \rightarrow C\} F={A→B,B→C}。通过BCNF分解:
R 1 ( A , B ) , R 2 ( B , C ) R_1(A,B), R_2(B,C) R1(A,B),R2(B,C)
消除传递依赖,保证数据一致性。
4.2 插入数据:单条与批量操作
插入操作的性能优化对大数据量应用至关重要。
单条插入(基础):
python
def insert_user(conn, username, email, password):
"""插入单个用户"""
sql = """
INSERT INTO users (username, email, password_hash)
VALUES (?, ?, ?)
"""
conn.execute(sql, (username, email, hash_password(password)))
conn.commit()批量插入(优化):
python
def bulk_insert_users(conn, users_data):
"""批量插入用户,性能提升10-100倍"""
sql = """
INSERT INTO users (username, email, password_hash)
VALUES (?, ?, ?)
"""
# 使用事务包装批量操作
conn.execute("BEGIN TRANSACTION")
try:
conn.executemany(sql, users_data)
conn.commit()
except Exception as e:
conn.rollback()
raise性能对比:
- 单条插入: n n n次网络往返,耗时 O ( n ) O(n) O(n)
- 批量插入:1次网络往返,耗时 O ( 1 ) O(1) O(1)
- 优化比例: 批量时间 单条时间 ≈ 1 n \frac{\text{批量时间}}{\text{单条时间}} \approx \frac{1}{n} 单条时间批量时间≈n1
WAL模式优势:
SQLite的WAL(Write-Ahead Logging)模式支持读写并发,插入性能提升 2 − 3 2-3 2−3倍。
4.3 查询数据:筛选、排序与聚合
高效查询需要理解SQL执行计划和索引利用。
基础查询:
python
def query_users_by_status(conn, status=1, limit=100):
"""按状态查询用户"""
sql = """
SELECT id, username, email, created_at
FROM users
WHERE status = ?
ORDER BY created_at DESC
LIMIT ?
"""
return conn.execute(sql, (status, limit)).fetchall()复杂查询与连接:
python
def query_user_orders(conn, user_id):
"""查询用户订单详情(多表连接)"""
sql = """
SELECT
o.id AS order_id,
o.total_amount,
o.created_at AS order_date,
COUNT(oi.id) AS item_count,
SUM(oi.quantity * oi.unit_price) AS subtotal
FROM orders o
LEFT JOIN order_items oi ON o.id = oi.order_id
WHERE o.user_id = ?
GROUP BY o.id
HAVING subtotal > 0
ORDER BY o.created_at DESC
"""
return conn.execute(sql, (user_id,)).fetchall()查询优化原理:
对于查询 Q : σ A = a ( R ) Q: \sigma_{A=a}(R) Q:σA=a(R):
- 无索引:全表扫描,复杂度 O ( n ) O(n) O(n)
- 有B-tree索引:索引查找,复杂度 O ( log n ) O(\log n) O(logn)
- 性能提升: O ( n ) O ( log n ) ≈ n log n \frac{O(n)}{O(\log n)} \approx \frac{n}{\log n} O(logn)O(n)≈lognn
4.4 更新数据:条件更新与事务保证
更新操作需要保证数据一致性和并发安全。
条件更新:
python
def update_user_email(conn, user_id, new_email):
"""更新用户邮箱,确保唯一性"""
sql = """
UPDATE users
SET email = ?, updated_at = CURRENT_TIMESTAMP
WHERE id = ? AND email != ?
"""
cursor = conn.execute(sql, (new_email, user_id, new_email))
conn.commit()
return cursor.rowcount # 返回受影响行数乐观锁控制:
python
def update_with_optimistic_lock(conn, user_id, new_data, expected_version):
"""使用版本号的乐观锁更新"""
sql = """
UPDATE users
SET username = ?, email = ?, version = version + 1
WHERE id = ? AND version = ?
"""
cursor = conn.execute(sql, (
new_data['username'],
new_data['email'],
user_id,
expected_version
))
if cursor.rowcount == 0:
raise ConcurrentModificationError("数据已被其他进程修改")
conn.commit()原子性保证:
事务的原子性通过日志机制实现:
Commit ( T ) ⇒ WriteLog ( T ) → WriteData ( T ) \text{Commit}(T) \Rightarrow \text{WriteLog}(T) \rightarrow \text{WriteData}(T) Commit(T)⇒WriteLog(T)→WriteData(T)
确保系统崩溃时可通过日志恢复。
4.5 删除数据:安全删除策略
删除操作需谨慎,推荐使用软删除或归档策略。
软删除实现:
python
def soft_delete_user(conn, user_id):
"""软删除用户(标记为禁用)"""
sql = """
UPDATE users
SET status = 0, updated_at = CURRENT_TIMESTAMP
WHERE id = ?
"""
conn.execute(sql, (user_id,))
conn.commit()数据归档策略:
python
def archive_old_data(conn, days_threshold=365):
"""归档一年前的数据"""
# 1. 创建归档表(如果不存在)
conn.execute("""
CREATE TABLE IF NOT EXISTS users_archive AS
SELECT * FROM users WHERE 1=0
""")
# 2. 迁移旧数据
conn.execute("""
INSERT INTO users_archive
SELECT * FROM users
WHERE created_at < DATE('now', ?)
""", (f"-{days_threshold} days",))
# 3. 删除原数据
conn.execute("""
DELETE FROM users
WHERE created_at < DATE('now', ?)
""", (f"-{days_threshold} days",))
conn.commit()删除性能优化:
- 批量删除使用
DELETE ... WHERE id IN (...)替代循环删除 - 大表删除使用分批次操作,避免长事务锁表
- 定期清理索引碎片,维持查询性能
5. 查询优化:从秒级到毫秒级的飞跃
查询性能优化是数据库应用的核心竞争力。本节通过实例演示优化技巧。
5.1 索引原理与创建策略
索引是查询优化的第一利器,但需要合理使用。
B-tree索引结构:
B-tree保持平衡,确保查询复杂度 O ( log n ) O(\log n) O(logn)。对于 m m m阶B-tree:
- 每个节点最多 m m m个子节点
- 根节点至少2个子节点(除非为叶子节点)
- 非叶子节点有 ⌈ m / 2 ⌉ \lceil m/2 \rceil ⌈m/2⌉到 m m m个子节点
- 所有叶子节点在同一深度
索引创建准则:
- 高选择性字段优先 : Selectivity = Distinct Values Total Rows \text{Selectivity} = \frac{\text{Distinct Values}}{\text{Total Rows}} Selectivity=Total RowsDistinct Values
- 复合索引遵循最左前缀原则
- 避免过度索引:每个索引增加写操作开销
创建示例:
sql
-- 单列索引
CREATE INDEX idx_users_email ON users(email);
-- 复合索引(覆盖查询)
CREATE INDEX idx_users_status_created
ON users(status, created_at, username, email);
-- 唯一索引
CREATE UNIQUE INDEX idx_unique_username
ON users(username);索引选择性计算:
Selectivity = 1 − 1 DistinctCount \text{Selectivity} = 1 - \frac{1}{\text{DistinctCount}} Selectivity=1−DistinctCount1
选择性接近1时索引效果最佳。
5.2 查询重写与执行计划分析
相同的查询逻辑,不同的SQL写法可能导致性能差异巨大。
低效查询示例:
sql
-- 使用子查询(可能低效)
SELECT * FROM users
WHERE id IN (SELECT user_id FROM orders WHERE total_amount > 1000);优化后版本:
sql
-- 使用连接查询(通常更高效)
SELECT u.* FROM users u
JOIN orders o ON u.id = o.user_id
WHERE o.total_amount > 1000
GROUP BY u.id;执行计划分析:
sql
-- MySQL
EXPLAIN FORMAT=JSON
SELECT * FROM users WHERE status = 1 ORDER BY created_at DESC LIMIT 100;
-- SQLite
EXPLAIN QUERY PLAN
SELECT * FROM users WHERE status = 1 ORDER BY created_at DESC LIMIT 100;执行计划关键指标:
type:访问类型(const, ref, range, index, ALL)key:使用的索引rows:预估扫描行数Extra:额外信息(Using where, Using index, Using filesort)
查询复杂度分析:
设表 R R R有 n n n行,查询 Q Q Q涉及 k k k个条件:
- 全表扫描: O ( n ) O(n) O(n)
- 索引扫描: O ( k log n ) O(k \log n) O(klogn)
- 覆盖索引: O ( log n ) O(\log n) O(logn)
5.3 性能监控与瓶颈定位
持续监控是性能优化的基础。
关键性能指标:
- QPS(Query Per Second):每秒查询数
- TPS(Transaction Per Second):每秒事务数
- 平均响应时间 : T ˉ = 1 n ∑ i = 1 n T i \bar{T} = \frac{1}{n}\sum_{i=1}^{n} T_i Tˉ=n1∑i=1nTi
- 慢查询比例 : 慢查询数 总查询数 \frac{\text{慢查询数}}{\text{总查询数}} 总查询数慢查询数
慢查询日志分析:
sql
-- MySQL慢查询配置
SET GLOBAL slow_query_log = 1;
SET GLOBAL long_query_time = 2; -- 2秒以上为慢查询
SET GLOBAL slow_query_log_file = '/var/log/mysql/slow.log';性能瓶颈定位:
- CPU瓶颈:复杂计算、排序操作
- IO瓶颈:全表扫描、大结果集
- 锁瓶颈:热点数据并发更新
- 网络瓶颈:大数据量传输
优化效果量化:
设优化前后查询时间分别为 T before T_{\text{before}} Tbefore、 T after T_{\text{after}} Tafter,优化比为:
Improvement = T before − T after T before × 100 % \text{Improvement} = \frac{T_{\text{before}} - T_{\text{after}}}{T_{\text{before}}} \times 100\% Improvement=TbeforeTbefore−Tafter×100%
通过系统化优化,典型查询性能可提升 10 − 100 10-100 10−100倍。
6. 事务处理与并发控制深度解析
事务是保证数据一致性的核心机制。本节从数学原理到工程实践全面解析。
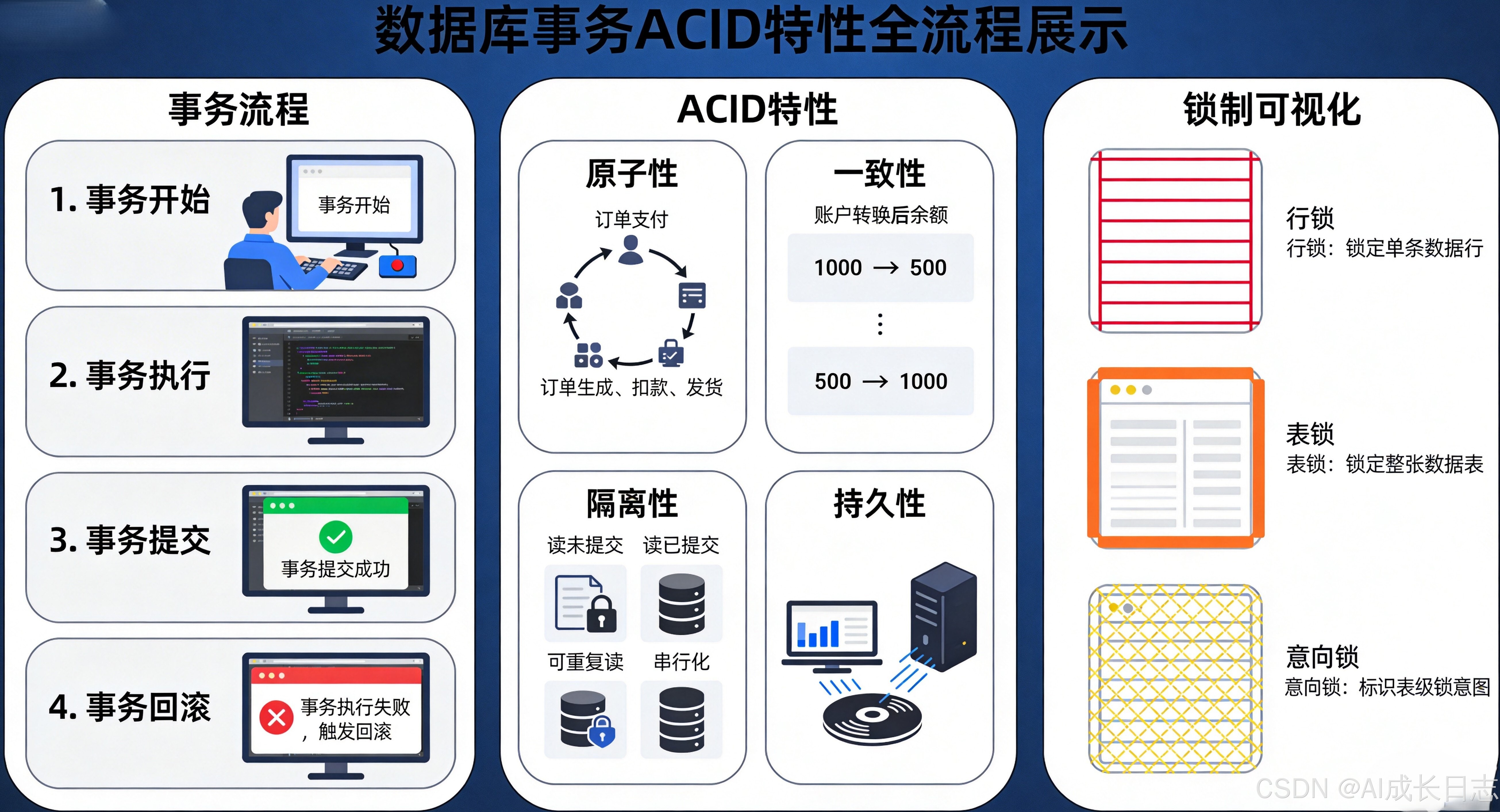
6.1 ACID特性深度解析
ACID是事务的四大核心特性,确保数据库操作的可靠性:
原子性(Atomicity): 事务内的所有操作要么全部成功,要么全部失败回滚。这通过事务日志实现,确保系统崩溃时数据一致性。
一致性(Consistency): 事务执行前后,数据库必须满足所有预定义的完整性约束。例如主键唯一、外键关联等。
隔离性(Isolation): 并发执行的事务相互隔离,避免相互干扰。SQL标准定义了四个隔离级别解决不同的并发异常。
持久性(Durability): 已提交的事务修改永久保存在存储介质中,即使系统故障也不会丢失。
6.2 隔离级别与并发异常
SQL标准定义了四种隔离级别,解决不同的并发异常。
隔离级别对比:
| 级别 | 脏读 | 不可重复读 | 幻读 | 性能 |
|---|---|---|---|---|
| 读未提交 | ✓ | ✓ | ✓ | ⭐⭐⭐⭐⭐ |
| 读已提交 | ✗ | ✓ | ✓ | ⭐⭐⭐⭐ |
| 可重复读 | ✗ | ✗ | ✓ | ⭐⭐⭐ |
| 序列化 | ✗ | ✗ | ✗ | ⭐ |
并发异常形式化:
- 脏读 : T 1 T_1 T1读取 T 2 T_2 T2未提交的修改
- 不可重复读 : T 1 T_1 T1两次读取同一数据得到不同结果
- 幻读 : T 1 T_1 T1执行范围查询, T 2 T_2 T2插入新数据导致结果变化
MySQL默认级别(可重复读):
sql
-- 设置隔离级别
SET TRANSACTION ISOLATION LEVEL REPEATABLE READ;
-- 查看当前级别
SELECT @@transaction_isolation;SQLite隔离级别:
SQLite默认支持序列化级别,通过WAL模式实现读写并发。
6.3 锁机制与死锁预防
锁是并发控制的基础,但需要避免死锁。
锁类型:
- 共享锁(S锁):读操作,允许多事务并发读
- 排他锁(X锁):写操作,独占资源
- 意向锁:表级锁,提高锁检查效率
锁兼容矩阵:
| 当前锁\请求锁 | S | X |
|---|---|---|
| S | ✓ | ✗ |
| X | ✗ | ✗ |
两阶段锁协议(2PL):
- 增长阶段:只能获取锁,不能释放锁
- 缩减阶段:只能释放锁,不能获取锁
保证可串行化调度。
死锁检测与处理:
死锁发生的四个必要条件:
- 互斥条件
- 占有且等待
- 不可抢占
- 循环等待
死锁预防策略:
python
def safe_transaction_execution(conn, operations):
"""带死锁预防的事务执行"""
max_retries = 3
for attempt in range(max_retries):
try:
conn.execute("BEGIN TRANSACTION")
# 按固定顺序访问资源,避免循环等待
operations.sort(key=lambda op: op.resource_id)
for op in operations:
op.execute(conn)
conn.commit()
return True
except OperationalError as e:
if "deadlock" in str(e).lower() and attempt < max_retries - 1:
conn.rollback()
time.sleep(0.1 * (2 ** attempt)) # 指数退避
continue
raise死锁检测算法:
使用等待图(Wait-for Graph)检测循环:
G = ( V , E ) , V = { T 1 , T 2 , ... } , E = { ( T i , T j ) ∣ T i waits for T j } G = (V, E), V = \{T_1, T_2, \ldots\}, E = \{(T_i, T_j) \mid T_i \text{ waits for } T_j\} G=(V,E),V={T1,T2,...},E={(Ti,Tj)∣Ti waits for Tj}
存在环 ⇒ \Rightarrow ⇒ 死锁。
并发性能模型:
设系统有 m m m个资源, n n n个事务,并发度 α = m n \alpha = \frac{m}{n} α=nm。吞吐量:
Throughput = n T avg + T lock \text{Throughput} = \frac{n}{T_{\text{avg}} + T_{\text{lock}}} Throughput=Tavg+Tlockn
通过优化锁粒度,可提升并发性能 30 − 50 % 30-50\% 30−50%。
7. 综合实战案例:电商订单管理系统
将理论知识应用于实际场景,构建完整的电商订单管理系统。
7.1 数据库设计
遵循规范化原则,设计核心表结构。
实体关系图:
用户(1) -- (n) 订单(1) -- (n) 订单项(n) -- (1) 商品
| |
| |
支付记录(1) -- (1) 订单完整DDL:
sql
-- 用户表(已在前文定义)
-- 商品表
CREATE TABLE products (
id INTEGER PRIMARY KEY AUTOINCREMENT,
name VARCHAR(200) NOT NULL,
description TEXT,
price DECIMAL(10, 2) NOT NULL,
stock INTEGER DEFAULT 0,
category VARCHAR(50),
created_at TIMESTAMP DEFAULT CURRENT_TIMESTAMP,
updated_at TIMESTAMP DEFAULT CURRENT_TIMESTAMP,
INDEX idx_category (category),
INDEX idx_price (price)
);
-- 订单表
CREATE TABLE orders (
id INTEGER PRIMARY KEY AUTOINCREMENT,
user_id INTEGER NOT NULL,
order_no VARCHAR(32) UNIQUE NOT NULL,
total_amount DECIMAL(12, 2) NOT NULL,
status TINYINT DEFAULT 1, -- 1=待支付,2=已支付,3=已发货,4=已完成,5=已取消
payment_method VARCHAR(20),
shipping_address TEXT,
created_at TIMESTAMP DEFAULT CURRENT_TIMESTAMP,
updated_at TIMESTAMP DEFAULT CURRENT_TIMESTAMP,
FOREIGN KEY (user_id) REFERENCES users(id) ON DELETE CASCADE,
INDEX idx_user_status (user_id, status),
INDEX idx_order_no (order_no),
INDEX idx_created (created_at)
);
-- 订单项表
CREATE TABLE order_items (
id INTEGER PRIMARY KEY AUTOINCREMENT,
order_id INTEGER NOT NULL,
product_id INTEGER NOT NULL,
quantity INTEGER NOT NULL,
unit_price DECIMAL(10, 2) NOT NULL,
subtotal DECIMAL(12, 2) GENERATED ALWAYS AS (quantity * unit_price) VIRTUAL,
FOREIGN KEY (order_id) REFERENCES orders(id) ON DELETE CASCADE,
FOREIGN KEY (product_id) REFERENCES products(id),
INDEX idx_order (order_id),
INDEX idx_product (product_id)
);
-- 支付记录表
CREATE TABLE payments (
id INTEGER PRIMARY KEY AUTOINCREMENT,
order_id INTEGER NOT NULL,
transaction_no VARCHAR(64) UNIQUE NOT NULL,
amount DECIMAL(12, 2) NOT NULL,
status TINYINT DEFAULT 1, -- 1=待支付,2=支付成功,3=支付失败
paid_at TIMESTAMP,
created_at TIMESTAMP DEFAULT CURRENT_TIMESTAMP,
FOREIGN KEY (order_id) REFERENCES orders(id),
INDEX idx_order (order_id),
INDEX idx_transaction (transaction_no)
);7.2 核心业务实现
封装业务逻辑,提供原子操作。
创建订单:
python
@safe_database_operation
def create_order(conn, user_id, items, shipping_address):
"""创建订单(完整事务)"""
try:
conn.execute("BEGIN TRANSACTION")
# 1. 生成订单号
order_no = generate_order_no()
# 2. 计算总金额并检查库存
total_amount = 0
for item in items:
product = get_product(conn, item['product_id'])
if product['stock'] < item['quantity']:
raise InsufficientStockError(f"商品{product['name']}库存不足")
total_amount += product['price'] * item['quantity']
# 3. 插入订单记录
order_id = insert_order(conn, {
'user_id': user_id,
'order_no': order_no,
'total_amount': total_amount,
'shipping_address': shipping_address
})
# 4. 插入订单项并扣减库存
for item in items:
insert_order_item(conn, {
'order_id': order_id,
'product_id': item['product_id'],
'quantity': item['quantity'],
'unit_price': get_product_price(conn, item['product_id'])
})
update_product_stock(conn, item['product_id'], -item['quantity'])
conn.commit()
return order_id
except Exception as e:
conn.rollback()
raise查询用户订单:
python
def query_user_orders(conn, user_id, page=1, page_size=20):
"""分页查询用户订单(优化版本)"""
offset = (page - 1) * page_size
sql = """
SELECT
o.id, o.order_no, o.total_amount, o.status, o.created_at,
COUNT(oi.id) AS item_count,
JSON_GROUP_ARRAY(
JSON_OBJECT(
'product_name', p.name,
'quantity', oi.quantity,
'unit_price', oi.unit_price
)
) AS items_detail
FROM orders o
LEFT JOIN order_items oi ON o.id = oi.order_id
LEFT JOIN products p ON oi.product_id = p.id
WHERE o.user_id = ?
GROUP BY o.id
ORDER BY o.created_at DESC
LIMIT ? OFFSET ?
"""
return conn.execute(sql, (user_id, page_size, offset)).fetchall()支付回调处理:
python
def handle_payment_callback(conn, transaction_no, amount, success=True):
"""支付回调处理(幂等性保证)"""
# 1. 检查是否已处理(幂等性)
existing = get_payment_by_transaction(conn, transaction_no)
if existing:
logger.info(f"支付记录已存在: {transaction_no}")
return existing['order_id']
# 2. 更新支付记录
payment_id = update_payment_status(conn, transaction_no,
'success' if success else 'failed')
if success:
# 3. 更新订单状态
update_order_status(conn, payment_id, 2) # 已支付
# 4. 触发后续流程(发货等)
trigger_order_fulfillment(conn, payment_id)
conn.commit()
return payment_id7.3 性能优化实践
针对电商场景优化查询性能。
热点数据缓存:
python
from functools import lru_cache
@lru_cache(maxsize=1000)
def get_product_info_cached(product_id):
"""商品信息缓存(减少数据库查询)"""
return get_product(product_id)
def get_order_with_cache(order_id):
"""订单详情缓存"""
cache_key = f"order:{order_id}"
cached = redis_client.get(cache_key)
if cached:
return json.loads(cached)
order = get_order_details(order_id)
redis_client.setex(cache_key, 300, json.dumps(order)) # 5分钟缓存
return order读写分离架构:
写操作 → 主数据库 → 复制 → 从数据库 → 读操作分库分表策略:
- 按用户ID哈希分表:
orders_${user_id % 16} - 按时间范围分区:
orders_2025q1,orders_2025q2 - 按业务垂直拆分:订单库、商品库、用户库
监控指标:
- 订单创建QPS:目标>1000/s
- 查询平均响应时间:目标<50ms
- 支付成功率:目标>99.9%
- 系统可用性:目标99.99%
8. 总结与最佳实践
通过本文的系统学习,你已经掌握了数据库操作的核心技能。以下是关键总结和建议。
8.1 技术选型建议
项目规模与数据库选择:
- 小型项目/原型:SQLite(部署简单,零运维)
- 中型Web应用:MySQL(功能全面,社区成熟)
- 大型分布式系统:MySQL集群或专业级数据库
开发环境配置:
- 本地开发:SQLite快速迭代
- 测试环境:与生产环境一致的MySQL
- 生产环境:MySQL高可用集群
8.2 开发规范
代码规范:
- SQL书写:关键字大写,使用参数化查询防注入
- 错误处理:统一异常处理,记录详细日志
- 连接管理:使用连接池,及时释放资源
安全规范:
- 权限控制:最小权限原则,避免使用root账户
- 数据加密:敏感信息加密存储
- 审计日志:记录关键操作日志
性能规范:
- 索引优化:为高频查询字段创建合适索引
- 查询优化:避免SELECT *,使用分页限制结果集
- 事务优化:短事务原则,避免长事务锁表
8.3 学习路径推荐
初级阶段:
- 掌握SQL基础语法(SELECT, INSERT, UPDATE, DELETE)
- 理解事务概念和ACID特性
- 学会基本的表设计原则
中级阶段:
- 深入理解索引原理和优化策略
- 掌握复杂查询和连接操作
- 学习数据库性能监控和调优
高级阶段:
- 研究数据库内部机制(存储引擎、锁机制)
- 掌握高可用和容灾方案
- 学习分布式数据库原理
持续学习:
- 关注数据库领域最新论文和技术发展
- 参与开源数据库项目贡献
- 在实践中不断总结经验,形成自己的方法论
资源推荐:
- 书籍:《数据库系统概念》、《高性能MySQL》
- 在线课程:Coursera数据库专项课程、极客时间数据库专栏
- 实践平台:LeetCode数据库题目、自己搭建实验环境
数据库技术日新月异,但核心原理相对稳定。掌握本文所述的基础操作和优化技巧,你将能够应对大多数数据库相关的开发挑战。