上一篇介绍了 Harness Engineering 的官方定义(Context Engineering + Architectural Constraints + Entropy Management 三大支柱),并说明本系列聚焦运行时实现层。这一篇进入 Agent 内部,拆解它的核心运行机制。在 Harness Engineering 的语境下,本篇内容主要对应 Context Engineering (上下文管理)和 Workflow Control(工作流控制)。
Agent 三大运行时机制
Agent 的运行时可以拆解为三个核心机制,它们对应了 Agent 在每一步需要回答的三个问题:
-
循环控制(Agent Loop) :调用完大模型还要不要继续?→
Workflow Control -
输出路由( Output Routing) :LLM 这次输出后应该要做什么?调用工具?还是回答用户?→
Workflow Control -
上下文管理(Context Management) :要给模型喂什么信息,该给模型看到什么?→
Context Engineering
总的来说这三者相互协作共同搭建起来一个 Agent 的框架: 上下文管理准备弹药 → LLM 推理 → 输出路由翻译 LLM 的输出结果 → 决策 → 循环控制驱动执行 → 结果回到上下文管理 → 循环继续。
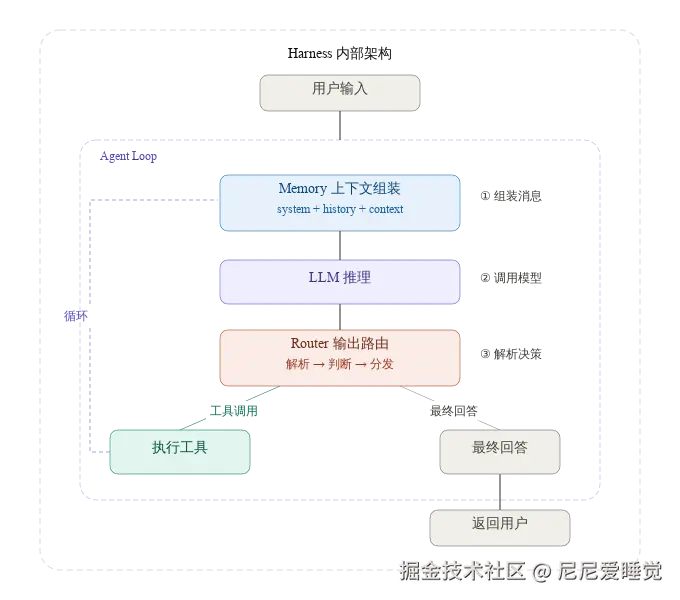
机制一:循环控制(Agent Loop)
Agent Loop 是 Harness 的心跳 ------ 它是由一个 while 循环组成,里面藏着四个很重要的设计决策:
- 什么时候终止循环?
- LLM 输出的结果显示表示"完成了"(
stop_reason = "end_turn"),这也是最常用的判断方式。 - 循环达到了最大的运行步数了, 起到保护的作用,避免陷入了死循环一直卡住。
- 执行超时了,工程实现上一般会设置一个超时时间,超过这个时间就返回给用户。
- 没有 Token 了,这也是很容易出现的问题,这种时候可能得考虑一下上下文管理是否有优化的空间了。
- 每次循环应该做多少事情
- 单工具模式:每次循环都调用一个工具,简单可控。
- 并行工具模式:一步调用多个工具,效率更高,Claude/GPT 都支持
- 执行过程中失败了要怎么办
- 立即终止:安全但体验差
- 错误回注 + LLM 自愈(推荐):把错误信息放回消息列表,让 LLM 再跑一次看看
- 自动重试:对瞬时错误有效,比如网络超时、抖动的情况
- 什么时候要用户介入
- 全自动:不需要人类介入,适合后台任务
- 关键节点确认(推荐):危险操作前暂停,Claude Code 的命令确认就是这个
- 每步确认:最安全但最慢
这些都应该是可配置的 ,好的 Harness 把它们暴露为参数,比如 Claude Code 就能让我们选择各种执行模式,还能通过 claude --dangerously-skip-permissions 跳过当前会话的所有权限检查,让其自动执行。
机制二:输出路由(Output Routing)
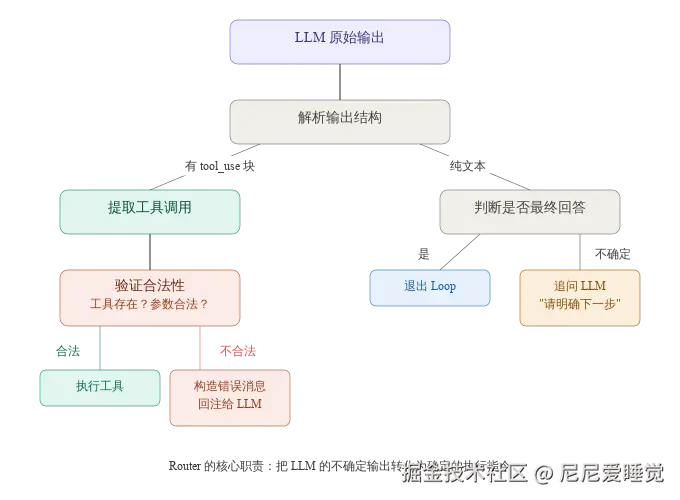
该机制主要用来回答一个问题:LLM 这次输出的到底是什么意图? 我们要怎么解析 LLM 输出的结果,进而判断模型要我们接下来做什么呢?
在以前是使用 ReAct 模式,LLM 输出的结果是纯文本,我们通过 prompt 教模型要是输出怎么样的数据格式,然后我们自己用正则从纯文本中"扣"出工具调用,这种实现方式又脆弱又丑陋。例如:
- 先在 system Prompt 里教模型用特定格式输出,你可能在 system prompt 中这么写:
yaml
当你需要调用工具时,请用以下格式:
Thought: 我需要搜索一下天气信息
Action: search
Action Input: {"query": "北京天气"}
当你有最终回答时,请用:
Thought: 我已经获得了所有需要的信息
Final Answer: 北京今天晴天,25°C- 然后 LLM 的输出是这样的纯文本
makefile
Thought: 用户想知道北京天气,我需要搜索一下。
Action: search
Action Input: {"query": "东京今天天气"}- 而我们在 Harness 中拿到这段文本,就要用正则去"扣"出来
Action跟Action Input分别是什么了:
python
import re
match = re.search(r"Action:\s*(.+)", response)
input_match = re.search(r"Action Input:\s*(.+)", response)
if match:
tool_name = match.group(1).strip() // 调用对应的 tool
args = json.loads(input_match.group(1)) # 很容易崩!上面 LLM 输出的纯文本可能会存在各种各样的问题:多了一个空格、少了一个引号、把 Action 写成 action 等等,假如正则一解析不出来就有问题了,要么就在 Router 中写大量的兼容逻辑,但是根本枚举不完各种可能存在的错误情况。
而现在各大模型使用的是一种叫 Function Calling 的模式,我明年再调用大模型的 API 接口的时候声明工具的 schema,告诉模型我们现在有哪些工具可用,让模型通过结构化的数据告诉我们需要调用哪些工具,直接输出结构化的 tool_use block,让解析从"猜测"变成了"读取"。
- 在模型 API 调用中声明工具 schema
ini
response = client.messages.create(
model="claude-sonnet-4-20250514",
messages=[{"role": "user", "content": "东京今天天气怎么样"}],
tools=[
{
"name": "search", // 明确声明有这个 tool
"description": "搜索网络信息",
"input_schema": {
"type": "object",
"properties": {
"query": {"type": "string", "description": "搜索关键词"}
},
"required": ["query"]
}
}
]
)- 模型返回的也是结构化的数据,不是纯文本:
css
[ { "type": "text", "text": "让我帮你查一下东京的天气。" }, { "type": "tool_use", "id": "toolu_01A09q90qw90lq917835lq", "name": "search", "input": {"query": "东京今天天气"} }]- 这个时候的 Router 的工具解析代码就很简洁了
ini
# 不需要正则!直接按类型过滤
tool_calls = [
block for block in response.content
if block.type == "tool_use"
]
if tool_calls:
# 结构化的,名称和参数都是确定的
name = tool_calls[0].name # "search"
args = tool_calls[0].input # {"query": "东京今天天气"}这种结果是模型训练出来的结果,由模型直接在内部输出结构化的 Json,不需要我们通过 prompt 进行约束,通过参数本身来进行约束,进而可以精确的匹配你声明的工具,在工程的 Router 代码上基本不需要进行任何的容错。
那么模型是怎么知道要触发 Function Calling 模式的呢?答案就是在我们调用 API 传入 tools 参数的时候,模型就会自动进入 Function Calling 模式。
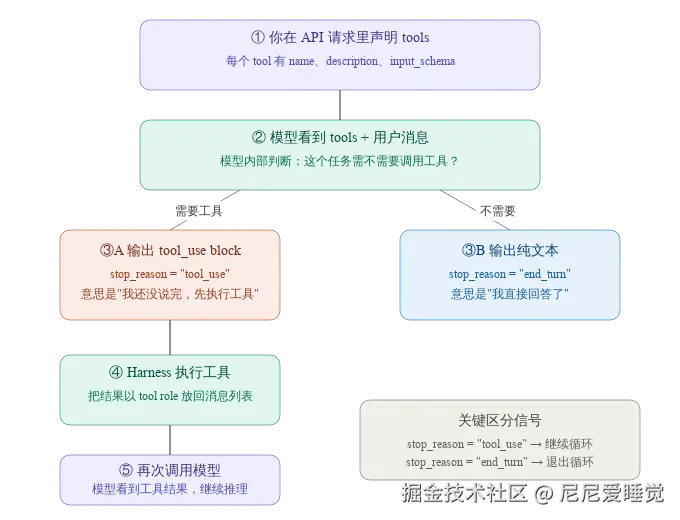
模型输出这里有个重要的参数是 Router 最重要的判断依据,那就是 stop_reason:
tool_use:模型的执行暂停了,等待我们将工具调用结果再喂给模型。Router 的判断就是要继续执行循环了end_turn:模型认为任务已经完成了。Router 的判断就是要退出循环了
Function calling 的思想是行业标准,但 JSON 结构各家略有不同:
- Claude:
response.content中有type: "tool_use"的 block - GPT-4:
response.choices[0].message.tool_calls,arguments 是字符串需 JSON.parse - Gemini:
response.candidates[0].content.parts中有functionCall
输出路由层需要做一层适配------这也是 LangChain 等框架存在的原因之一。
虽然 Function Calling 减少了格式错误,但模型偶尔会调用不存在的工具、传入不合理的参数、对危险操作缺乏审慎。验证层从"格式纠错"进化为"语义审查"。
这层验证本身就是一种 Architectural Constraint------用确定性代码防止 Agent 做出危险的工具调用。
另外调用模型传入的 API 列表也不应该全传,工具太多会导致模型选择困难,浪费 Token,增加延迟的,可以适当的增加一些任务动态筛选机制。
总的来说输出路由机制是用来解析模型的输出,判断循环下一步是否要调用工具,是否要退出。而现在有了 function calling 机制让解析模型输出发生了一个质变:
- 解析从"猜测"变成了"读取"
- 参数从"祈祷"变成了"约束"
- 工具选择从 prompt "教学"变成了"内置"
机制三:上下文管理(Context Management)

这是 Context Engineering 在 Agent 运行时的具体实现。管理三层信息:
- 第一层:持久化上下文信息
即 system prompt,system message 这部分信息永远都在、永远不变,会包含身份、规则、工具定义等,例如 AGENTS.md/CLAUDE.md 内容。
- 第二层:工作上下文
即对话历史,包含 user/ assistant/ tool message,这部分一直累积后就会膨胀起来,需要做各种策略的管理。
- 第三层:外部上下文注入
这部分不在消息列表中,但是可以按需取用,例如 Claude.md、向量数据库、完整的 Trace、skill 等知识。 上下文管理的核心职责 = 每次调用 LLM 前,从三层中拼出最优的消息列表。
代码示例
python
class ContextManager: # Context Engineering 的实现
def build_messages(self) -> list[dict]:
messages = [{"role": "system", "content": self.system_prompt + self.external_knowledge}]
for msg in reversed(self.full_history):
msg = self._maybe_truncate(msg)
if fits_budget(msg):
messages.insert(1, msg)
return messages
class OutputRouter: # Workflow Control 的实现
def parse(self, llm_response) -> RouterResult:
tool_calls = self._extract_tool_calls(llm_response)
if tool_calls:
self._validate(tool_calls) # Architectural Constraint
return RouterResult(is_final=False, tool_calls=tool_calls)
return RouterResult(is_final=True, content=self._extract_text(llm_response))
class AgentLoop: # Workflow Control 的核心
def run(self, user_input: str) -> str:
self.context.add_user_message(user_input)
for step in range(self.max_steps):
messages = self.context.build_messages() // 加载上下文
response = self.llm.chat(messages) // 调用大模型
result = self.router.parse(response) // 解析大模型的结果
if result.is_final:
return result.content // 结束
for tc in result.tool_calls: // 工具调用
tool_result = self._execute_tool(tc)
self.context.add_tool_result(tc.id, tool_result)小结
第二课的核心认知:
-
循环控制 是 Workflow Control 的核心------终止条件、并行度、错误处理、人类介入都是可配置的设计决策
-
输出路由 把 LLM 的不确定输出转化为确定指令------Function Calling 简化了它,但验证(Architectural Constraint)仍然必要
-
上下文管理 是 Context Engineering 的运行时实现------三层信息结构,核心挑战是在有限窗口里放进最相关的信息
下一篇进入最容易翻车的领域:工具调用与错误恢复。