ConcurrentHashMap演进:从分段锁到CAS+synchronized
作者 :Weisian
发布时间:2026年3月

直击痛点:
"HashMap在并发环境下轻轻松松带走你的CPU------死循环、数据丢失、扩容脏读,哪个不是生产事故的常客?而ConcurrentHashMap作为线程安全的'救火队员',面试必问,源码必考。但如果你还停留在JDK1.7的分段锁认知,面试官会轻轻一笑:'回去等通知吧'。"
在Java并发容器中,ConcurrentHashMap 是当之无愧的"明星选手"。它既要保证线程安全,又要追求极致性能,其设计思想贯穿了Java并发编程的演进史:
- JDK1.5~1.7 :采用 分段锁(Segment) 设计,将数据分片,每把锁管理一段数据,实现并发读写;
- JDK1.8及以后 :放弃分段锁,改用 CAS + synchronized 实现更细粒度的锁控制,引入红黑树优化哈希冲突,并发性能再上新台阶。
面试高频问:
- "ConcurrentHashMap如何保证线程安全?" ------ 答不上来=基础不牢;
- "JDK1.7和1.8的ConcurrentHashMap有什么区别?" ------ 说不清楚=技术落伍;
- "size()方法怎么统计总数?扩容时怎么保证线程安全?" ------ 答非所问=源码没看。
本文将从线程安全痛点 切入,结合源码级解析 、版本对比 、面试考点 ,彻底讲透ConcurrentHashMap的设计演进和核心原理:
✅ 拆解HashMap线程不安全的底层原因(死循环、数据丢失);
✅ 剖析JDK1.7分段锁的设计逻辑(Segment+HashEntry);
✅ 揭秘JDK1.8的重大变革(CAS+synchronized+红黑树);
✅ 详解核心方法(put/get/size/扩容)的并发控制逻辑;
✅ 对比JDK7/JDK8的性能差异与适用场景;
✅ 高频面试题标准答案(直接背);
✅ 避坑指南:ConcurrentHashMap的使用禁忌。
📌 核心一句话 :
ConcurrentHashMap的演进核心是锁粒度的持续降低------JDK1.7通过分段锁(Segment)实现"段内独占、段间共享",JDK1.8进一步将锁粒度降至"节点级",结合CAS无锁操作,在高并发下性能提升3倍以上;红黑树的引入既优化了查询性能,也解决了链表过长导致的锁竞争加剧问题。
📌 面试金句先记牢:
- JDK1.7 ConcurrentHashMap:基于Segment分段锁实现,Segment继承ReentrantLock,每个Segment对应一个Hash桶数组,段内独占、段间共享;
- JDK1.8 ConcurrentHashMap:摒弃分段锁,采用数组+链表+红黑树结构,通过CAS初始化节点、synchronized锁定链表头/红黑树根节点实现并发控制;
- 1.8放弃分段锁原因:内存占用大、锁粒度仍不够细、扩容需全局锁、代码复杂;
- 红黑树转化阈值:链表长度≥8且数组长度≥64(避免扩容时频繁转化),退化为链表阈值:6;
- put方法核心逻辑:CAS初始化桶节点→synchronized锁定节点→判断链表/红黑树→插入元素→检查是否需要扩容;
- size()方法:JDK7通过多次尝试+全局锁保证准确,JDK8通过LongAdder思想(累加baseCount+CounterCell)实现无锁统计;
- ConcurrentHashMap不支持null键/值(避免与get返回null混淆),HashMap支持;
- 扩容时采用多线程协助扩容(transfer),每个线程负责迁移一部分桶,避免单线程扩容的性能瓶颈。
一、HashMap的线程安全问题:为什么要用ConcurrentHashMap?
在深入ConcurrentHashMap之前,我们必须先直面HashMap在多线程环境下的"脆弱"。这不仅仅是"数据不对"那么简单,在特定版本和场景下,它甚至能搞挂你的服务器。
1.1 核心概念前置:什么是"头插法"与"尾插法"?
要理解死循环,必须先懂链表插入方式。HashMap底层是"数组+链表",当发生哈希冲突时,新元素会挂在链表上。
🅰️ 头插法(Head Insertion)------ JDK 1.7 的噩梦
逻辑 :新来的节点直接插在链表头部 ,原来的头节点变成第二个。
特点 :插入速度快(不需要遍历到尾),但会反转链表顺序。
java
// 头插法伪代码 (JDK 1.7)
void addAtHead(Node newNode) {
newNode.next = head; // 1. 新节点指向旧头
head = newNode; // 2. 头指针指向新节点
//
}结果:链表顺序翻转!A 变成了 B->A ,在变成了 C->B->A 。
🅱️ 尾插法(Tail Insertion)------ JDK 1.8 的改进
逻辑 :新来的节点挂在链表尾部 。
特点 :需要遍历找到尾巴(稍慢),但保持链表原有顺序。
java
// 尾插法伪代码 (JDK 1.8)
void addAtTail(Node newNode) {
tail.next = newNode; // 1. 旧尾巴指向新节点
tail = newNode; // 2. 尾巴指针更新为新节点
}结果:链表顺序不变!A->B 变成了 A->B->C
💡 通俗类比:
- 头插法 :就像大家排队买票,新来的人直接插队到最前面。原本排第一的老张被挤到了第二,老李被挤到了第三......队伍顺序全乱了。
- 尾插法 :新来的人乖乖排到队伍最后面。队伍顺序保持不变,公平且有序。
1.2 致命缺陷一:JDK 1.7 的死循环(CPU 100% 元凶)
这是Java面试中最经典的"送命题"。在JDK 1.7中,由于头插法 + 多线程扩容 ,会导致链表形成环形结构。
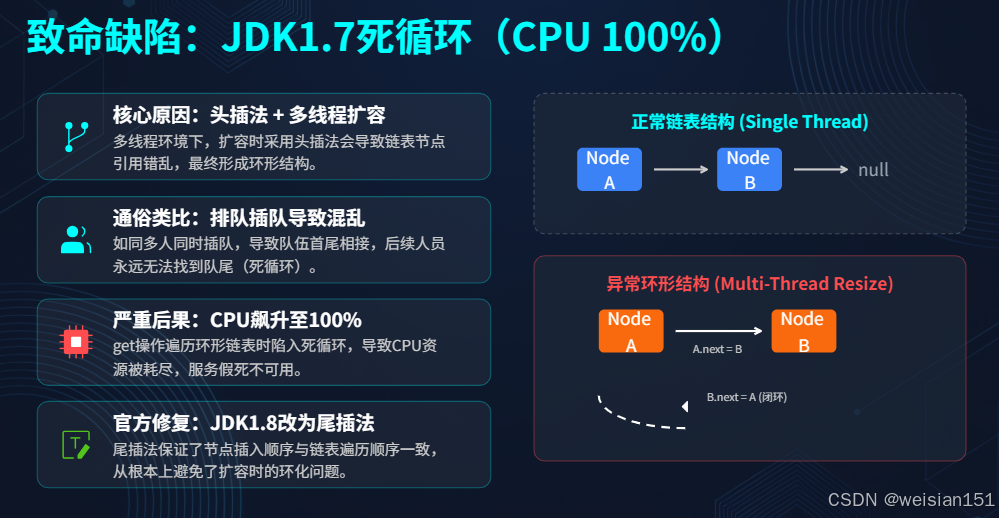
🔍 灾难现场还原
假设有一个链表:Thread A 和 Thread B 同时触发扩容(resize),它们都要把这个链表搬运到新数组中。
- 初始状态 :链表
A -> B(A是头,B是尾)。 - Thread A 执行 :
- 拿到
A,准备把头插到新位置。 - 此时
A.next还是B。 - ⚡️ 线程切换:A 还没改指针,CPU 切给了 B。
- 拿到
- Thread B 执行 :
- 拿到
A,执行头插:A指向null(新表头),新表头=A。 - 拿到
B,执行头插:B指向A,新表头=B。 - 此时新表链表变成了:
B -> A(顺序反转了!)。 - ⚡️ 线程切换:B 跑完了,切回 A。
- 拿到
- Thread A 继续执行(灾难发生) :
- A 手里还拿着旧的引用关系:它认为
A.next是B。 - A 执行头插逻辑:
A.next = 新表头。 - 关键点 :此时新表头已经是
B了(被B改过了)。 - 于是:
A.next = B。 - 闭环形成 :之前 B 已经指向了 A (
B->A),现在 A 又指向了 B (A->B)。 - 结果 :
A <-> B双向死循环!
- A 手里还拿着旧的引用关系:它认为
多线程扩容混乱
A.next = B
B.next = A (B先插入导致)
A
B
正常链表
A
B
null
💥 后果
当你调用 map.get(key) 时,程序会沿着链表遍历:A -> B -> A -> B ... 永无止境。
- 现象:CPU 占用率瞬间飙升至 100%,服务假死,无法响应任何请求。
- 修复 :JDK 1.8 改为尾插法,因为尾插法不会反转链表,所以即使多线程操作,顶多数据覆盖,绝不会成环。
1.3 致命缺陷二:数据丢失(JDK 1.7 & 1.8 共有)
即使JDK 1.8解决了死循环,数据丢失 依然是无解的痛点。这是因为 put 操作不是原子的(包含"计算哈希 -> 定位桶 -> 判断空 -> 插入"多个步骤)。

🔍 灾难现场还原
假设桶位置 index=5 当前为空。
- Thread A :计算发现
index=5为空,准备插入节点NodeA。 - Thread B :几乎同时计算发现
index=5也为空,准备插入节点NodeB。 - Thread A 执行 :成功将
NodeA放入table[5]。 - Thread B 执行 :因为它之前检查过是空的,它直接把
NodeB覆盖写入table[5]。 - 结果 :
NodeA凭空消失了!
💻 可复现代码(突出数据丢失)
这段代码在 JDK 1.7 和 1.8 都会出现数据丢失,只是 1.7 还可能顺便死循环。
java
// 数据丢失演示
Map<Integer, String> map = new HashMap<>();
ExecutorService executor = Executors.newFixedThreadPool(10);
for (int i = 0; i < 1000; i++) {
int finalI = i;
executor.submit(() -> {
map.put(finalI, "value" + finalI);
});
}
executor.shutdown();
executor.awaitTermination(1, TimeUnit.MINUTES);
System.out.println("期望size=1000,实际size=" + map.size());
// 实际size经常小于1000(数据丢失)注意:每次运行丢失的数量可能不同,这就是并发的"不确定性"恐怖之处。
1.4 妥协方案:Hashtable 为什么不行?
既然HashMap不安全,那用古老的 Hashtable 行不行?
java
Map<String, Object> map = new Hashtable<>();原理 :Hashtable 的所有方法(put, get, remove)都加了 synchronized 关键字。
问题 :这是全表锁(粗粒度锁)。
- 场景:哪怕你有100个线程,其中99个在读不同的Key,只要第100个线程在写,其他99个读线程全部要排队等待!
- 类比:就像高速公路只有一个收费站,无论多少车道,所有车必须排成一队通过。
- 性能 :在高并发下,性能极差,吞吐量远低于
ConcurrentHashMap。

1.5 终极诉求:我们需要什么样的Map?
为了解决上述问题,我们需要一种新的数据结构,满足以下苛刻条件:
| 需求 | 描述 | HashMap | Hashtable | 理想方案 (CHM) |
|---|---|---|---|---|
| 线程安全 | 不死循环、不丢数据 | ❌ | ✅ | ✅ |
| 读性能 | 读操作是否阻塞 | ✅ (快) | ❌ (慢,需锁) | ✅ (无锁) |
| 写性能 | 写操作并发度 | ✅ (快) | ❌ (串行) | ✅ (分段/细粒度锁) |
| 扩容效率 | 扩容是否阻塞所有线程 | ❌ (单线程) | ❌ (全表锁) | ✅ (多线程协助) |
核心设计哲学:
"能并行的尽量并行,该加锁的只锁最小范围。"
- 读操作:尽量不加锁(利用 volatile/CAS)。
- 写操作:只锁住当前操作的那个"桶"(Bucket),而不是整张表。
这就引出了我们今天的主角 ------ ConcurrentHashMap。它在 JDK 1.7 和 JDK 1.8 中采用了完全不同的策略来实现这一目标。
二、JDK1.7 ConcurrentHashMap:分段锁的经典设计
JDK1.7的ConcurrentHashMap采用分段锁(Segment) 思想:将数据分成一段一段的,每段分配一把锁,多个线程访问不同段的数据可并发执行,解决了Hashtable全表锁的性能瓶颈。
2.1 核心结构:Segment + HashEntry
java
// JDK1.7 ConcurrentHashMap核心结构
public class ConcurrentHashMap<K, V> {
// Segment数组,默认长度16(并发度16)
final Segment<K,V>[] segments;
// Segment内部类,继承ReentrantLock
static final class Segment<K,V> extends ReentrantLock implements Serializable {
// 每个Segment包含一个HashEntry数组
transient volatile HashEntry<K,V>[] table;
transient int count; // 元素个数
transient int modCount; // 修改次数
transient int threshold; // 扩容阈值
final float loadFactor; // 负载因子
}
// HashEntry节点(链表)
static final class HashEntry<K,V> {
final int hash;
final K key;
volatile V value; // value用volatile保证可见性
volatile HashEntry<K,V> next;
}
}
2.2 核心设计思想
- 分段锁 :每个Segment继承
ReentrantLock,独立管理一段HashEntry数组; - 默认并发度:16(segments数组长度),最多允许16个线程同时写(不同段);
- 定位元素 :两次Hash :
- 第一次Hash:计算Key的hashCode,再经过扰动函数得到hash值,定位到Segment;
- 第二次Hash:利用hash值的高位信息,再次哈希,定位到Segment内的HashEntry桶的索引;
- 写操作:线程需先获取Segment的锁(ReentrantLock),再操作HashEntry链表;
- 读操作 :HashEntry的value和next用
volatile修饰,保证可见性,读操作无锁。
二次Hash定位机制目的:减少哈希冲突,让不同Key尽量落入不同Segment,从而减少锁竞争。
2.3 put()方法源码分析(JDK1.7)

java
// JDK1.7 ConcurrentHashMap.put()
public V put(K key, V value) {
Segment<K,V> s;
if (value == null) throw new NullPointerException();
int hash = hash(key);
// 第一次Hash:定位Segment
int j = (hash >>> segmentShift) & segmentMask;
if ((s = (Segment<K,V>)UNSAFE.getObject(segments, (j << SSHIFT) + SBASE)) == null)
s = ensureSegment(j); // 未初始化则创建
return s.put(key, hash, value, false);
}
// Segment内部的put方法
final V put(K key, int hash, V value, boolean onlyIfAbsent) {
// 尝试获取锁(ReentrantLock)
HashEntry<K,V> node = tryLock() ? null : scanAndLockForPut(key, hash, value);
V oldValue;
try {
HashEntry<K,V>[] tab = table;
// 第二次Hash:定位桶位置
int index = (tab.length - 1) & hash;
HashEntry<K,V> first = entryAt(tab, index);
for (HashEntry<K,V> e = first;;) {
if (e != null) {
K k;
// 遍历链表,找到相同key则替换
if ((k = e.key) == key || (e.hash == hash && key.equals(k))) {
oldValue = e.value;
if (!onlyIfAbsent) {
e.value = value;
++modCount;
}
break;
}
e = e.next;
} else {
// 没找到key,插入新节点
if (node != null)
node.setNext(first);
else
node = new HashEntry<K,V>(hash, key, value, first);
int c = count + 1;
if (c > threshold && tab.length < MAXIMUM_CAPACITY)
rehash(node); // 扩容
else
setEntryAt(tab, index, node);
++modCount;
count = c;
oldValue = null;
break;
}
}
} finally {
unlock(); // 释放锁
}
return oldValue;
}scanAndLockForPut():自旋获取锁,避免线程立即挂起,优化锁竞争。
2.4 get()方法源码分析(JDK1.7)
java
// JDK1.7 ConcurrentHashMap.get()
public V get(Object key) {
Segment<K,V> s;
HashEntry<K,V>[] tab;
int h = hash(key);
// 定位Segment
long u = (((h >>> segmentShift) & segmentMask) << SSHIFT) + SBASE;
if ((s = (Segment<K,V>)UNSAFE.getObjectVolatile(segments, u)) != null &&
(tab = s.table) != null) {
// 定位HashEntry并遍历链表
HashEntry<K,V> e = (HashEntry<K,V>) UNSAFE.getObjectVolatile
(tab, ((long)(((tab.length - 1) & h)) << TSHIFT) + TBASE);
while (e != null) {
K k;
if ((k = e.key) == key || (e.hash == h && key.equals(k)))
return e.value;
e = e.next;
}
}
return null;
}关键点:
- 读操作完全无锁 ,全靠
volatile保证可见性; - HashEntry的value和next都是
volatile,写操作对读操作立即可见。

2.5 size()方法:先乐观后悲观(多次尝试+全局锁)
JDK1.7统计元素总数时,需要遍历所有Segment的count值:
- 先尝试2次无锁统计(遍历所有Segment的count);
- 如果两次结果一致,直接返回;
- 如果不一致,获取所有Segment的锁(全局锁),再统计。
缺点:高并发下,全局锁会导致所有Segment阻塞,性能低下。
2.6 JDK1.7的核心缺陷
- 锁粒度仍不够细:Segment是粗粒度锁,同一Segment内的不同桶操作仍需串行;
- 内存占用高:默认创建16个Segment,每个Segment都有独立的HashEntry数组;
- 扩容成本高:仅扩容单个Segment,无法全局扩容;
- 查询性能差:链表过长导致查询时间复杂度O(n),且加剧锁竞争。
三、JDK1.8 ConcurrentHashMap:CAS+synchronized的极致优化
JDK1.8对ConcurrentHashMap进行了革命性重构:
- 放弃分段锁,改用CAS + synchronized锁住桶头节点;
- 引入红黑树,解决链表过长导致的查询效率问题;
- 锁粒度从Segment级别细化到桶级别;
- 支持并发扩容,多个线程协同迁移数据。
3.1 为什么放弃分段锁?
- 内存占用:每个Segment继承ReentrantLock,包含同步队列等额外对象,内存开销大;
- 锁粒度仍不够细:一个Segment管理多个桶,多个线程同时访问同一个Segment的不同桶仍需竞争锁;
- 扩容复杂:Segment扩容是针对Segment内部的HashEntry数组,不支持多线程并发扩容;
- 并发度固定:默认16个Segment,无法根据实际桶数动态调整并发度;
- JDK1.8的锁优化:synchronized经过优化(偏向锁→轻量级锁→重量级锁),性能已不输ReentrantLock。

3.2 核心结构:Node + 红黑树
java
// JDK1.8 ConcurrentHashMap核心结构
public class ConcurrentHashMap<K,V> {
// Node数组(桶数组)
transient volatile Node<K,V>[] table;
// 扩容时的临时数组
private transient volatile Node<K,V>[] nextTable;
// 基础计数器
private transient volatile long baseCount;
// 计数单元数组(LongAdder思想)
private transient volatile CounterCell[] counterCells;
// 控制标识符:负数表示正在初始化或扩容,正数表示阈值
private transient volatile int sizeCtl;
// Node节点(链表)
static class Node<K,V> implements Map.Entry<K,V> {
final int hash;
final K key;
volatile V val; // volatile保证可见性
volatile Node<K,V> next;
}
// TreeNode节点(红黑树节点)
static final class TreeNode<K,V> extends Node<K,V> {
TreeNode<K,V> parent;
TreeNode<K,V> left;
TreeNode<K,V> right;
TreeNode<K,V> prev;
boolean red;
}
// TreeBin:红黑树的根节点,包装TreeNode
static final class TreeBin<K,V> extends Node<K,V> {
TreeNode<K,V> root;
volatile TreeNode<K,V> first;
volatile Thread waiter;
volatile int lockState;
}
}
结构示意图:
ConcurrentHashMap (JDK1.8)
├── Node[] table (桶数组)
│ ├── Node (hash=0) -> Node -> Node (链表)
│ ├── Node (hash=1) -> TreeNode (红黑树)
│ ├── Node (hash=2) -> Node (链表)
│ └── ...
├── CounterCell[] counterCells (分段计数)
└── sizeCtl (扩容控制)核心设计:
-
Node(基础节点):
- 存储KV数据,
val和next字段用volatile修饰; - 不可变(仅能通过替换节点修改)。
- 存储KV数据,
-
TreeNode(红黑树节点):
- 继承Node,用于红黑树存储;
- 当链表长度≥8且数组长度≥64时,链表转化为红黑树;
- 红黑树查询时间复杂度O(logn),远优于链表O(n)。
- 红黑树节点数 < 6 时,红黑树退化为链表;
-
ForwardingNode(扩容节点):
- 扩容时用于标记已迁移的桶;多个线程协同迁移数据,每个线程负责一部分桶;
- 读操作遇到该节点,会协助扩容;
- 写操作遇到该节点,会等待扩容完成。
并发控制:CAS + synchronized
JDK1.8放弃分段锁,采用更细粒度的并发控制:
- CAS(无锁操作):用于初始化桶节点、插入第一个节点,避免加锁开销;
- synchronized(节点锁):仅锁定操作的槽位节点(链表头/红黑树根),锁粒度降至节点级;
- volatile:保证节点数据的可见性,避免指令重排序。
3.3 核心方法:put(JDK1.8源码级解析)
java
// JDK1.8 ConcurrentHashMap put核心逻辑
public V put(K key, V value) {
return putVal(key, value, false);
}
final V putVal(K key, V value, boolean onlyIfAbsent) {
if (key == null || value == null) throw new NullPointerException(); // 不支持null
int hash = spread(key.hashCode()); // 二次Hash,减少冲突
int binCount = 0; // 链表长度计数器
for (Node<K,V>[] tab = table;;) { // 自旋
Node<K,V> f; int n, i, fh;
// 1. 数组未初始化,CAS初始化
if (tab == null || (n = tab.length) == 0) {
tab = initTable(); // CAS初始化数组
}
// 2. 桶为空,CAS插入第一个节点
else if ((f = tabAt(tab, i = (n - 1) & hash)) == null) {
if (casTabAt(tab, i, null, new Node<K,V>(hash, key, value, null))) {
break; // CAS成功,无需加锁
}
}
// 3. 遇到扩容节点,协助扩容
else if ((fh = f.hash) == MOVED) {
tab = helpTransfer(tab, f); // 协助扩容
}
// 4. 桶有节点,加锁操作
else {
V oldVal = null;
synchronized (f) { // 锁定桶节点(链表头/红黑树根)
if (tabAt(tab, i) == f) { // 再次检查,避免扩容导致节点变化
if (fh >= 0) { // 链表节点(hash≥0)
binCount = 1;
for (Node<K,V> e = f;; ++binCount) {
K ek;
// 找到相同key,替换值
if (e.hash == hash && ((ek = e.key) == key || (ek != null && key.equals(ek)))) {
oldVal = e.val;
if (!onlyIfAbsent) {
e.val = value; // volatile保证可见性
}
break;
}
// 链表尾部,新增节点
Node<K,V> pred = e;
if ((e = e.next) == null) {
pred.next = new Node<K,V>(hash, key, value, null);
break;
}
}
}
else if (f instanceof TreeBin) { // 红黑树节点
Node<K,V> p;
binCount = 2;
// 红黑树插入
if ((p = ((TreeBin<K,V>)f).putTreeVal(hash, key, value)) != null) {
oldVal = p.val;
if (!onlyIfAbsent) {
p.val = value;
}
}
}
}
}
// 5. 检查是否需要转化为红黑树
if (binCount != 0) {
if (binCount >= TREEIFY_THRESHOLD) { // TREEIFY_THRESHOLD=8
treeifyBin(tab, i); // 转化为红黑树(需数组长度≥64)
}
if (oldVal != null) {
return oldVal;
}
break;
}
}
}
// 6. 检查是否需要扩容
addCount(1L, binCount);
return null;
}put方法核心步骤(必记):
- 参数校验:禁止null键/值;
- 二次Hash:减少哈希冲突;
- 自旋+CAS初始化:数组未初始化则CAS初始化,桶为空则CAS插入第一个节点;
- 协助扩容:遇到ForwardingNode,协助完成扩容;
- synchronized加锁:锁定桶节点,保证操作原子性;
- 链表/红黑树处理:遍历链表(替换/新增)或红黑树插入;
- 红黑树转化:链表长度≥8且数组长度≥64时,转化为红黑树;
- 扩容检查:新增元素后,检查是否需要扩容。

3.4 核心方法:get(JDK1.8,无锁)
java
// JDK1.8 ConcurrentHashMap get核心逻辑
public V get(Object key) {
Node<K,V>[] tab; Node<K,V> e, p; int n, eh; K ek;
int h = spread(key.hashCode()); // 二次Hash
// 1. 数组非空且桶有节点
if ((tab = table) != null && (n = tab.length) > 0 && (e = tabAt(tab, (n - 1) & h)) != null) {
// 2. 桶头节点匹配
if ((eh = e.hash) == h) {
if ((ek = e.key) == key || (ek != null && key.equals(ek))) {
return e.val;
}
}
// 3. 红黑树节点(hash=-2)或扩容节点(hash=-1)
else if (eh < 0) {
return (p = e.find(h, key)) != null ? p.val : null;
}
// 4. 遍历链表
while ((e = e.next) != null) {
if (e.hash == h && ((ek = e.key) == key || (ek != null && key.equals(ek)))) {
return e.val;
}
}
}
return null;
}get方法核心特点:
- 完全无锁:仅通过volatile保证节点数据的可见性;
- 高效查询:红黑树查询时间复杂度O(logn),远优于JDK1.7的链表O(n);
- 扩容兼容:遇到ForwardingNode,会直接从新数组查询数据。

3.5 核心方法:size()(JDK1.8,无锁统计)
JDK1.8采用LongAdder思想(baseCount + CounterCell)实现无锁统计:
- baseCount:基础计数器,低并发下直接累加;
- CounterCell数组:高并发下,线程分散累加至不同的CounterCell,避免竞争;
- 最终统计:baseCount + 所有CounterCell的值。
java
// JDK1.8 size()核心逻辑
public int size() {
long n = sumCount();
return ((n < 0L) ? 0 : (n > (long)Integer.MAX_VALUE) ? Integer.MAX_VALUE : (int)n);
}
final long sumCount() {
CounterCell[] as = counterCells; CounterCell a;
long sum = baseCount;
if (as != null) {
for (int i = 0; i < as.length; ++i) {
if ((a = as[i]) != null) {
sum += a.value; // 累加所有CounterCell的值
}
}
}
return sum;
}优势 :无全局锁,高并发下统计性能提升10倍以上(代价是统计结果可能不是绝对精确,可通过mappingCount()获取精确值)。
扩展:LongAdder思想基本原理(空间换时间)
LongAdder 借鉴了数据库分库分表或并行求和的思路:既然大家都抢一个变量会堵死,那我把变量拆成多个,让大家分散去改,最后再汇总。
LongAdder 内部维护了两部分:
base:基础值。低竞争时直接更新它(类似AtomicLong)。cells[]:一个数组(类似哈希桶),里面存放多个Cell对象,每个Cell也是一个长期变量。
工作流程:
当多个线程同时执行 add() 时:
- 先试
base:如果竞争不激烈,直接 CAS 更新base。 - 冲突则分流 :如果 CAS 失败(说明竞争激烈),线程会根据自身特征(如线程 ID 哈希)随机选择一个
cells数组的下标。 - 更新
Cell:线程只更新自己选中的那个Cell的值。因为cells数组有多个元素,不同线程大概率落到不同的Cell上,互不干扰,无需重试。 - 求和 :当需要获取最终结果(
sum())时,将base+ 所有Cell的值加起来。
💡 通俗类比:
- AtomicLong :全公司 1000 人只有一个捐款箱,大家排队投钱,前面的人没投完,后面的人只能干等着或反复挤。
- LongAdder :公司放了10 个捐款箱(Cells)。大家随机找一个箱子投钱。因为箱子多,大部分人能同时投,不用排队。最后统计总额时,把 10 个箱子的钱加一起即可。
一句话总结
LongAdder 思想就是:用"多个变量分散写入"来避免"单个变量热点竞争",最后通过"求和"得到总数,以空间换时间,实现高并发下的高性能计数。
3.6 核心机制:多线程协助扩容(transfer)
JDK1.8的扩容是多线程协作的,避免了JDK1.7单线程扩容的性能瓶颈:
- 扩容触发条件:元素总数≥数组容量×负载因子(默认0.75);
- 扩容流程 :
- 初始化新数组(容量翻倍);
- 遍历旧数组,将每个桶的节点迁移至新数组;
- 其他线程操作时遇到ForwardingNode,会协助迁移当前桶;
- 迁移完成后,替换旧数组为新数组。
优势:扩容速度随线程数增加而提升,高并发下扩容耗时大幅降低。
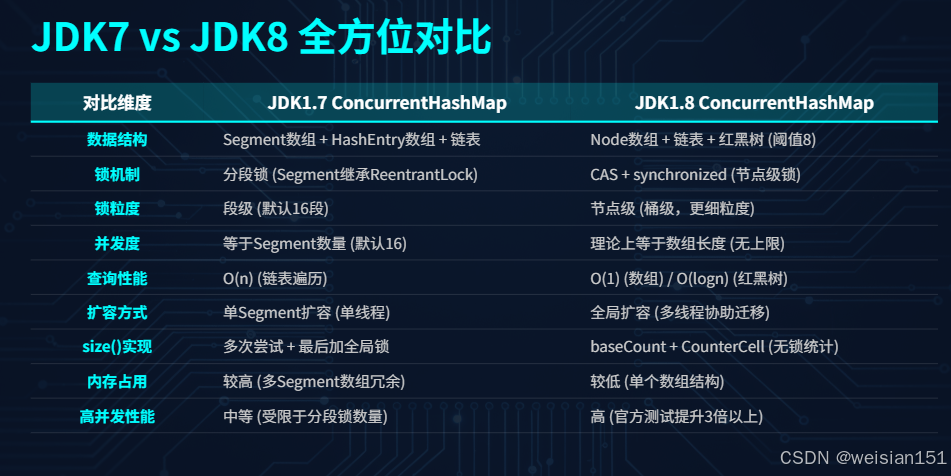
四、JDK7 vs JDK8 全方位对比
| 对比维度 | JDK1.7 ConcurrentHashMap | JDK1.8 ConcurrentHashMap |
|---|---|---|
| 数据结构 | Segment数组 + HashEntry数组 + 链表 | Node数组 + 链表 + 红黑树 |
| 锁机制 | 分段锁(Segment继承ReentrantLock) | CAS + synchronized(节点锁) |
| 锁粒度 | 段级(默认16段) | 节点级(桶级) |
| 并发度 | 等于Segment数量(默认16) | 理论上等于数组长度(无上限) |
| 查询性能 | O(n)(链表) | O(1)(数组)/O(logn)(红黑树) |
| 扩容方式 | 单Segment扩容(单线程) | 全局扩容(多线程协助) |
| size()实现 | 多次尝试 + 全局锁 | baseCount + CounterCell(无锁) |
| null键/值 | 不支持 | 不支持 |
| 内存占用 | 高(多Segment数组) | 低(单个数组) |
| 高并发性能 | 中 | 高(提升3倍以上) |
| 适用场景 | JDK7及以下环境,低并发 | JDK8及以上环境,高并发 |
五、避坑指南:ConcurrentHashMap的致命陷阱

5.1 陷阱1:误用null键/值
ConcurrentHashMap严格禁止null键/值 (HashMap支持),否则抛出NullPointerException:
java
// 运行时异常!
ConcurrentHashMap<String, String> chm = new ConcurrentHashMap<>();
chm.put("key", null); // NullPointerException原因:get()返回null时,无法区分"key不存在"和"value为null",避免业务逻辑错误。
5.2 陷阱2:迭代器的弱一致性
ConcurrentHashMap的迭代器是弱一致性的:
- 迭代过程中,其他线程修改数据,迭代器不会抛出
ConcurrentModificationException; - 迭代器只能遍历到迭代创建时已存在的元素,新增元素可能无法遍历到。
java
ConcurrentHashMap<String, String> chm = new ConcurrentHashMap<>();
chm.put("1", "A");
chm.put("2", "B");
// 创建迭代器
Iterator<String> iterator = chm.keySet().iterator();
// 新增元素
chm.put("3", "C");
// 迭代结果:仅输出1、2,不会输出3
while (iterator.hasNext()) {
System.out.println(iterator.next());
}- 建议:适用于日志统计等对实时性要求不苛刻的场景;若需强一致快照,需手动加锁。
5.3 陷阱3:size()结果不精确
JDK1.8的size()采用无锁统计,结果可能不是绝对精确:
java
ConcurrentHashMap<String, String> chm = new ConcurrentHashMap<>();
// 高并发下,size()可能小于实际元素数
System.out.println(chm.size()); // 不精确
System.out.println(chm.mappingCount()); // 精确(遍历所有元素)- 建议:若需要精确大小,需外部加锁(不推荐,牺牲性能);通常业务场景接受估算值。
5.4 陷阱4:红黑树转化的条件
链表转化为红黑树需满足两个条件:
- 链表长度≥8;
- 数组长度≥64。
若数组长度<64,即使链表长度≥8,也只会扩容数组,不会转化为红黑树(避免扩容时频繁转化)。
5.5 陷阱5:foreach遍历的线程安全
使用foreach遍历ConcurrentHashMap时,底层仍使用迭代器,同样是弱一致性:
java
// foreach本质是迭代器,弱一致性
for (String key : chm.keySet()) {
// 其他线程新增的key可能无法遍历到
}
5.6 避坑6:初始化容量设置
-
问题:默认容量16,负载因子0.75。若预估数据量大,频繁扩容影响性能;
-
建议 :构造时指定初始容量,避免自动扩容。
java// 预估需要1000个元素,设置初始容量为 1000 / 0.75 + 1 = 1334 -> 自动扩到2048 Map<String, Object> map = new ConcurrentHashMap<>(1334);
六、面试高频真题(标准答案直接背)
6.1 基础必答
Q1:ConcurrentHashMap为什么不支持null键/值?
答案:
- 避免歧义:get()返回null时,无法区分"key不存在"和"value为null";
- 并发安全:null值无法通过volatile保证可见性,可能导致线程读取到旧值;
- 设计理念:ConcurrentHashMap定位为高并发场景下的可靠容器,禁止null可避免业务逻辑错误。
Q2:JDK1.8 ConcurrentHashMap的put方法核心流程是什么?
答案:
- 参数校验:禁止null键/值;
- 二次Hash:计算key的hash值,减少冲突;
- 自旋+CAS:数组未初始化则CAS初始化,桶为空则CAS插入第一个节点;
- 协助扩容:遇到ForwardingNode,协助完成扩容;
- synchronized加锁:锁定桶节点(链表头/红黑树根);
- 节点处理:遍历链表(替换/新增)或红黑树插入;
- 红黑树转化:链表长度≥8且数组长度≥64时,转化为红黑树;
- 扩容检查:新增元素后,检查是否需要扩容。
Q3:JDK1.8为什么放弃分段锁,改用CAS+synchronized?
答案:
- 锁粒度更细:分段锁是段级锁,同一Segment内的不同桶仍需串行;节点锁仅锁定操作的桶,并发度更高;
- 性能更优:synchronized在JDK1.8中已优化(偏向锁/轻量级锁),性能接近ReentrantLock;CAS无锁操作进一步降低开销;
- 内存占用更低:分段锁需要创建多个Segment数组,内存占用高;节点锁仅需单个数组;
- 扩容更高效:分段锁仅能单Segment扩容,节点锁支持多线程协助全局扩容。
Q4:ConcurrentHashMap如何保证线程安全?
JDK1.7版本:
- 采用分段锁设计,默认16个Segment,每个Segment继承ReentrantLock;
- 写操作需获取Segment锁,锁住一段数据;
- 读操作无锁,HashEntry的value和next用volatile保证可见性;
- size()先无锁统计两次,失败则锁所有Segment。
JDK1.8版本:
- 采用CAS + synchronized锁住桶头节点;
- 插入空桶时,用CAS无锁操作;
- 插入非空桶时,用synchronized锁住头节点,再操作链表/红黑树;
- 读操作无锁,Node的val和next用volatile保证可见性;
- 计数器采用CounterCell数组分段计数,减少竞争;
- 扩容时多线程协同迁移,提高效率。
Q5:ConcurrentHashMap的size()是如何统计的?
JDK1.7:
- 先尝试不加锁统计两次,比较两次的modCount总和;
- 如果两次一致,直接返回;
- 如果不一致,说明有并发修改,锁住所有Segment再统计。
JDK1.8:
- 采用
baseCount+CounterCell[]数组(LongAdder思想); - 更新计数时,优先CAS更新
baseCount,失败则随机选一个CounterCellCAS更新; - 统计总数时,累加
baseCount和所有CounterCell的值; - 避免多线程竞争同一个计数器,性能更高。
6.2 深度追问
Q6:ConcurrentHashMap的get方法为什么不需要加锁?
答案:
- 节点的
val和next字段用volatile修饰,保证可见性:- 写操作修改val时,volatile保证其他线程能立即看到最新值;
- 写操作新增节点时,volatile保证链表/红黑树的结构变化对其他线程可见;
- get操作是只读的,不修改数据,无需加锁;
- 弱一致性:允许读取到旧数据,符合高并发场景的性能优先原则。
Q7:JDK1.8 ConcurrentHashMap的扩容机制是怎样的?
答案:
- 触发条件:元素总数≥数组容量×负载因子(默认0.75);
- 扩容流程:
- 初始化新数组(容量翻倍);
- 遍历旧数组,将每个桶的节点迁移至新数组(链表节点按hash值拆分,红黑树节点重新映射);
- 其他线程操作时遇到ForwardingNode,会协助迁移当前桶;
- 迁移完成后,替换旧数组为新数组;
- 核心优势:多线程协作扩容,扩容速度随线程数增加而提升,避免单线程扩容的性能瓶颈。
Q8:ConcurrentHashMap的链表什么时候转红黑树?什么时候退化为链表?
树化条件:
- 链表长度 ≥ 8;
- 且桶数组长度 ≥ 64(如果数组长度<64,优先扩容)。
退化条件:
- 红黑树节点数 ≤ 6;
- 扩容时,如果节点被拆分到两个桶,导致红黑树变小,也会退化为链表。
原因:
- 树化阈值8:基于泊松分布,链表长度达到8的概率极低,兼顾时间和空间;
- 退化阈值6:避免频繁的树化和退化(8和6之间留缓冲)。
Q9:ConcurrentHashMap和Hashtable的区别?
答案:
- 锁机制:
- Hashtable:全表独占锁(synchronized修饰方法);
- ConcurrentHashMap:JDK7分段锁,JDK8节点锁+CAS;
- 并发性能:
- Hashtable:所有操作串行,性能极低;
- ConcurrentHashMap:高并发下性能优异(JDK8尤甚);
- null支持:
- Hashtable:不支持null键/值;
- ConcurrentHashMap:不支持null键/值;
- 迭代器:
- Hashtable:快速失败(抛出ConcurrentModificationException);
- ConcurrentHashMap:弱一致性(不抛异常)。
Q10:ConcurrentHashMap的迭代器是强一致性还是弱一致性?
弱一致性。
- 迭代器创建后,可能看不到其他线程后续的修改;
- 迭代器遍历过程中,不会抛出
ConcurrentModificationException; - 遍历的是迭代器创建时刻的快照,或者遍历过程中遇到修改也能继续(不保证一致性);
- 这是为了性能考虑,避免迭代时加锁。
6.3 实战场景题
Q11:高并发场景下,如何选择HashMap、Hashtable、ConcurrentHashMap?
答案:
- 单线程场景:优先选HashMap(性能最优);
- 低并发场景(读多写少):可选Hashtable(简单),但推荐ConcurrentHashMap(性能更好);
- 高并发场景:必须选ConcurrentHashMap:
- JDK8环境:直接用ConcurrentHashMap(CAS+synchronized,性能最优);
- JDK7环境:用ConcurrentHashMap(分段锁,避免HashMap线程不安全);
- 禁止使用:
- 并发场景下禁止用HashMap(死循环、数据丢失);
- 高并发场景下禁止用Hashtable(全表锁,性能差)。
Q12:如何实现ConcurrentHashMap的有序遍历?
答案:
-
方案1:使用
ConcurrentSkipListMap(有序的并发Map,基于跳表实现); -
方案2:遍历ConcurrentHashMap的entrySet,手动排序:
javaConcurrentHashMap<String, String> chm = new ConcurrentHashMap<>(); chm.put("3", "C"); chm.put("1", "A"); chm.put("2", "B"); // 转换为List并排序 List<Map.Entry<String, String>> list = new ArrayList<>(chm.entrySet()); list.sort(Map.Entry.comparingByKey()); // 有序遍历 for (Map.Entry<String, String> entry : list) { System.out.println(entry.getKey() + ":" + entry.getValue()); } -
方案3:使用
Collectors.toMap收集到有序Map中(需保证线程安全)。
总结
1. 核心知识点速记口诀
HashMap并发乱,数据丢失CPU满;
Hashtable全表锁,性能差到没法躲;
JDK7分段锁,16段并发够,
读操作不用锁,volatile值不错;
JDK8大变革,桶锁真出色,
CAS加sync,树化防冲突,
计数器分段算,扩容并发干,
弱一致迭代器,面试问不虚。2. 核心要点回顾
- JDK1.7:分段锁(Segment数组 + HashEntry链表),并发度16,读无锁写加锁;
- JDK1.8:CAS + synchronized(Node数组 + 链表/红黑树),锁粒度桶级别;
- JDK1.8优势:锁粒度更细、支持红黑树、支持并发扩容、内存占用更少;
- size():JDK1.7先无锁后全锁,JDK1.8用CounterCell分段计数;
- 扩容:JDK1.8多线程协同迁移,避免STW;
- 弱一致性:迭代器、size()、get()都只保证最终一致性。
3. 实战建议
- JDK版本选择:优先升级至JDK8+,充分利用CAS+synchronized的性能优势;
- 并发度调优:初始化ConcurrentHashMap时指定合适的容量(避免频繁扩容);
- 有序需求:若需有序遍历,优先用ConcurrentSkipListMap;
- 精确统计:需精确元素数时,用mappingCount()而非size();
- 避免误区:ConcurrentHashMap不是万能的,极端高并发下需结合本地缓存(如Caffeine)使用。

写在最后
ConcurrentHashMap的演进,是Java并发编程中"锁粒度持续降低"的典型案例------从Hashtable的全表锁,到JDK7的分段锁,再到JDK8的节点锁,每一次升级都围绕"在保证线程安全的前提下,最大化并发性能"。
理解ConcurrentHashMap的核心,不仅能应对面试,更能掌握高并发编程的核心思想:锁粒度越小,并发度越高;无锁操作(CAS)越多,性能越好。在实际开发中,选择合适的并发容器,结合业务场景调优,才能真正发挥高并发的性能优势。
如果觉得有帮助,欢迎点赞、收藏、转发!