RLT:VLA 学会"在岗练习"
Physical Intelligence 最新工作 RL Token (RLT) 解读。VLA 模型什么都会但什么都不精?用几分钟真机强化学习做 last-millimeter 精化,速度甚至超越人类遥操作。本文结合论文原文与个人思考,聊聊 RLT 做对了什么、还差什么。
1. VLA 的"最后一毫米"困境
大规模 VLA(Vision-Language-Action)模型是当前机器人操控的主流范式。它们在海量遥操作数据上训练,能处理各种各样的任务------但精度和速度往往不尽人意。
具体来说,VLA 在执行高精度任务时有一个典型症状:反复试探。比如插网线时,它会靠近插口、后退一点、微调、再尝试,来回好几次才成功。这不是 VLA "不会",而是示教数据本身就存在噪声和不一致------人类遥操作的精度上限,就是 VLA 的天花板。
强化学习(RL)是突破这个天花板的天然选择:让机器人自己练习,发现比人类示教更快、更准的策略。但问题是,VLA 模型动辄数十亿参数,直接拿来做在线 RL,计算量和数据量都不现实。
RLT 的核心问题就是:如何在几分钟到几小时的真机交互中,高效地用 RL 精化一个大型 VLA?
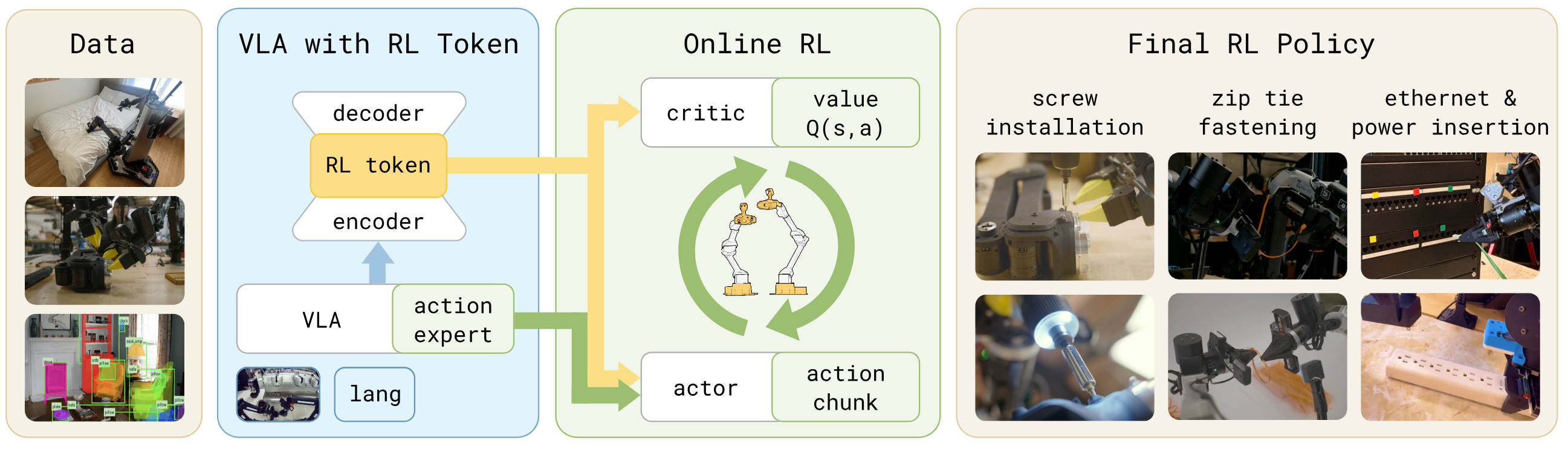
2. RLT 的核心方法
RLT 的思路非常简洁:冻住 VLA,只在上面接一个极轻量的 RL 模块。
2.1 RL Token:把 VLA 的知识"蒸馏"成一个向量
VLA 内部有丰富的特征表示,但维度太高(数千个 token,每个 2048 维),不适合直接拿来做 RL。RLT 在冻结的 VLA 上加了一个小型 encoder-decoder transformer,训练出一个 RL token------一个 1×2048 的紧凑向量。
训练方式是自回归重建:decoder 需要从这个单一向量恢复出 VLA 的完整 token 序列。这迫使 RL token 保留尽可能多的任务相关信息,同时足够紧凑,可以作为下游 RL 的状态输入。
2.2 轻量 Actor-Critic 做在线精化
冻结 VLA 和 RL token 后,RLT 训练一个很小的 actor-critic 网络(2-3 层 MLP,隐藏维度 256-512)。
关键在于:actor 不是从零生成动作。它接收两个输入:
- RL token + 本体感知状态:告诉它当前的场景
- VLA 的参考动作块(action chunk):告诉它 VLA "打算怎么做"
actor 的任务是在 VLA 参考动作的基础上做局部精化,而不是重新发明轮子。
3. 五个关键设计选择
- Action Chunking(动作块): RL 策略一次输出 C=10 步的动作块而非单步动作,这使得强化学习能够看得更长远。
- BC 正则化: actor 的训练目标不是纯粹地最大化 Q 值,还有一个约束项:输出动作不要偏离 VLA 参考动作太远。
- 参考动作直通(Pass-Through): VLA 采样的参考动作 ã 直接作为 actor 网络的输入。这让 actor 能"看到" VLA 打算做什么,然后决定在哪里微调。去掉这个输入(w/o Pass-Through),学习速度明显变慢,训练过程中失败更多。
- 参考动作dropout: 训练时随机 50% 的概率将参考动作置零。这防止 actor 偷懒------如果它总能看到参考动作,最简单的策略就是直接复制,那 RL 就白训了。Dropout 强迫 actor 维持一条独立的动作生成通路。奇怪的是文章中没有提到对dropout做消融实验。
4. 为什么还需要 Action Expert?
读到这里你可能会想:既然已经有了 actor-critic,VLA 的 action expert(生成参考动作的 diffusion 模块)还有什么用?直接用 RL token 当状态、actor 输出动作不就行了?
这恰恰是 RLT 设计中最精妙的地方。去掉 action expert,RLT 就退化成了"换了个好 encoder 的 HIL-SERL",丢失了它最核心的优势。Action expert 扮演了三个不可替代的角色:
4.1 多模态信息的载体
VLA 的 action expert 是一个 diffusion 模型,能捕捉动作分布中的多个模式。比如面对一个插入任务,可能存在"从左侧进入"和"从右侧进入"两种合理策略。Diffusion 模型采样时自然会选择一个模式。
而 RLT 的 actor 是一个单峰高斯分布------它自身没有能力表示多模态。但如果它接收了 action expert 采样出的参考动作,就隐式地获得了"VLA 选了哪个模式"的信息,然后在这个模式的基础上做精化。参考动作不只是一个初始猜测,它还是一个模式选择信号。
4.2 将优化问题降维
想象两种任务:
- A: 在 140 维动作空间中从零找到能插进网线的动作序列
- B: 给你一个"差不多能插进去"的动作序列,微调一下让它更快更准
显然 B 比 A 简单得多。Action expert 的存在,将 RL 的问题从 A 降级为 B------从"学会做任务"变成"做得更好"。BC 正则化和 pass-through 都依赖于此:没有参考动作,这些机制就无从谈起。
4.3 降低RL工作量
训练分为两个阶段:
- Warmup 阶段:直接执行 action expert 的动作,收集初始数据给 critic 学习。没有它,critic 面对的是纯随机数据,学习信号极差
- 正式训练中:任务的非关键阶段(如抓取、搬运)仍由 VLA(含 action expert)执行,RL 只在关键阶段(如插入)接管
这种分工让 RL 可以集中火力在最难的部分,而不需要从头学整个任务流程。
4.4 消融实验的佐证
论文的消融实验直接验证了这一点:
- w/o Pass-Through(去掉参考动作输入):学习变慢,训练过程中更多失败
- w/o BC Regularizer (去掉对参考动作的正则化):所有消融中性能下降最大
两个最重要的消融都指向同一件事:action expert 提供的参考动作,是 RLT 高效学习的根基。
5. 实验:几分钟数据,3 倍提速
RLT 在四个高精度真机任务上做了验证:
| 任务 | 精度要求 | 难点 |
|---|---|---|
| 螺丝安装 | 亚毫米对准 | 螺丝刀尖到抓点 10cm 放大效应 |
| 扎带紧固 | 毫米精度 | 双臂协调,柔性物体 |
| 网线插入 | 精确位姿对齐 | 接触动力学敏感 |
| 充电器插入 | 厘米级对齐 | 插头和插座可见性差 |
核心结果:
- 关键阶段速度提升最高 3 倍
- 螺丝安装成功率从 20% 提升到 65%
- 网线插入任务中,RL 策略的速度超越了人类遥操作------一半的 RL episode 比所有人类示教都快
- 仅需约 5 分钟关键阶段数据即可超越基线
更有趣的是行为上的质变:VLA 在接触点附近反复"试探",而 RLT 训出的策略会直接靠近并流畅插入,失败时还会施加压力并轻微摆动------这种利用柔顺性的策略从未出现在示教数据中,完全是 RL 自主探索出来的。
6. RLT 还差什么?
6.1 仍然是逐任务训练
RLT 需要为每个任务独立训练:
- RL token 的 encoder-decoder(在任务示教数据上训练)
- Actor-Critic 网络(在线训练)
- VLA 本身也做了任务级 fine-tuning
虽然训练成本远低于 HIL-SERL(小 MLP vs 完整策略),但并没有解决"一次训练、多任务通用"的问题。
6.2 人工依赖
当前系统仍需要人工介入:
- 提供稀疏奖励(每个 episode 标注成功/失败)
- 在训练中提供干预纠正
- 手动决定何时从 VLA 切换到 RL 策略
论文提到可以用奖励模型和进度预测来自动化这些环节,但目前还没有实现。
6.3 只精化关键阶段
RLT 明确只用于任务的"关键阶段"(通常 5-20 秒),其余部分由 VLA 执行。这是务实的工程选择,但也意味着它不是一个端到端的解决方案。虽然反复强调了文章相对于HIL-SERL的进步,但是VLA在真机强化过程中不可替代的作用依然值得怀疑。
参考
- Charles Xu et al. "RL Token: Bootstrapping Online RL with Vision-Language-Action Models." Physical Intelligence, 2025.
- Jianlan Luo et al. "Precise and dexterous robotic manipulation via human-in-the-loop reinforcement learning." arXiv:2410.21845, 2024.
- Physical Intelligence. "π0.6 model card." 2025.