项目 :新型电力系统平台
云平台 :华为云
安全等级 :等保二级
说明:本文为公开版复盘,已去除不适合公开的部署细节;AI 工具只作为实施过程的一部分记录,不替代人的架构决策和验收责任。
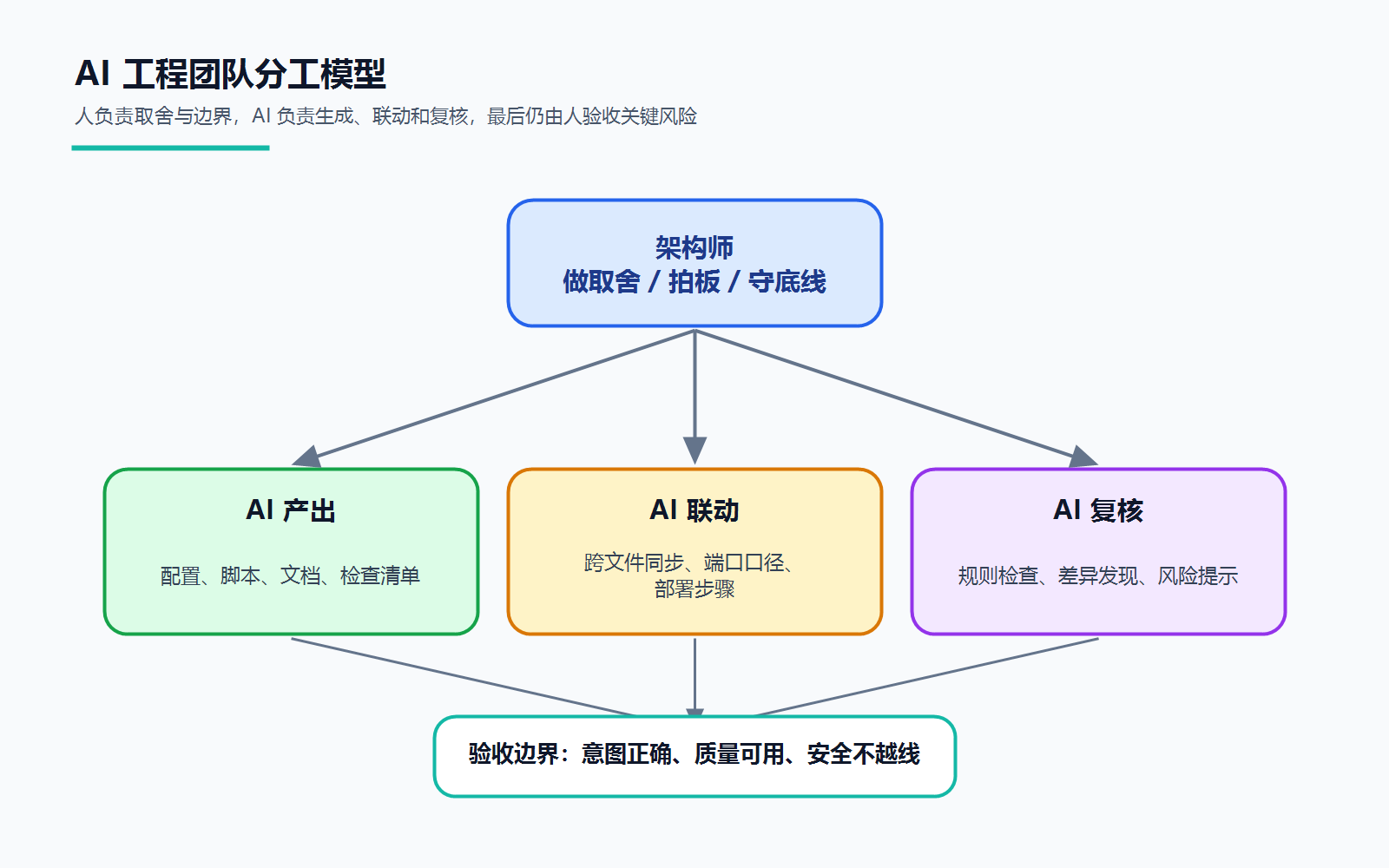
一、项目一开始,并没有"生产方案"
这个项目启动时,手里能用的东西并不多:一份演示环境的一键启动配置,一批历史数据导出包,以及一些分散的部署经验。
这些东西可以证明系统"能跑",但离生产落地还差很远。生产环境要考虑安全分区、访问边界、账号权限、日志审计、数据持久化、备份恢复、监控告警、故障切换和后续测评。任何一项没想清楚,都会在上线或送测时变成返工。
最终要做的事情包括:四层安全域隔离,30+ 容器编排,10+ 中间件协同部署,围绕等保二级 80 项检查项完成主体加固与送测清单梳理,6 个数据库备份导入后约 1500 万行脱敏样例数据完成清理与验证,以及端到端数据链路贯通。
我在这个项目里的主要工作,不是把每条命令都亲手敲出来,而是先把边界和取舍定下来,再让工具辅助生成配置、脚本和文档,最后逐项验收。这个顺序很重要。工具可以提高执行效率,但不能替你判断哪些风险能接受、哪些红线不能碰。

二、安全架构先定骨架
等保二级不是在系统快上线时补几条规则。它更像一套约束:系统怎么分区、网络怎么连、访问怎么管、日志怎么留、出了问题怎么追。
这次我先把安全设计分成两层。
第一层是结构安全,重点是四件事:
- 安全分区:把生产控制、管理信息、数据组件和运维管理分开。
- 网络专用:关键链路走专网或受控入口,端口按最小必要开放。
- 横向隔离:区域之间不能随意互通,必须走边界策略。
- 纵向认证:调用链路上要有身份鉴别和最小权限控制。
第二层是综合防护,也分成四类:
- 态势感知:监控、告警、日志、审计先行。
- 加固免疫:主机基线、最小服务、补丁治理和安全配置。
- 数据安全:账号权限、备份恢复、敏感信息治理。
- 基础设施安全:主机、防火墙、安全组和统一运维入口。
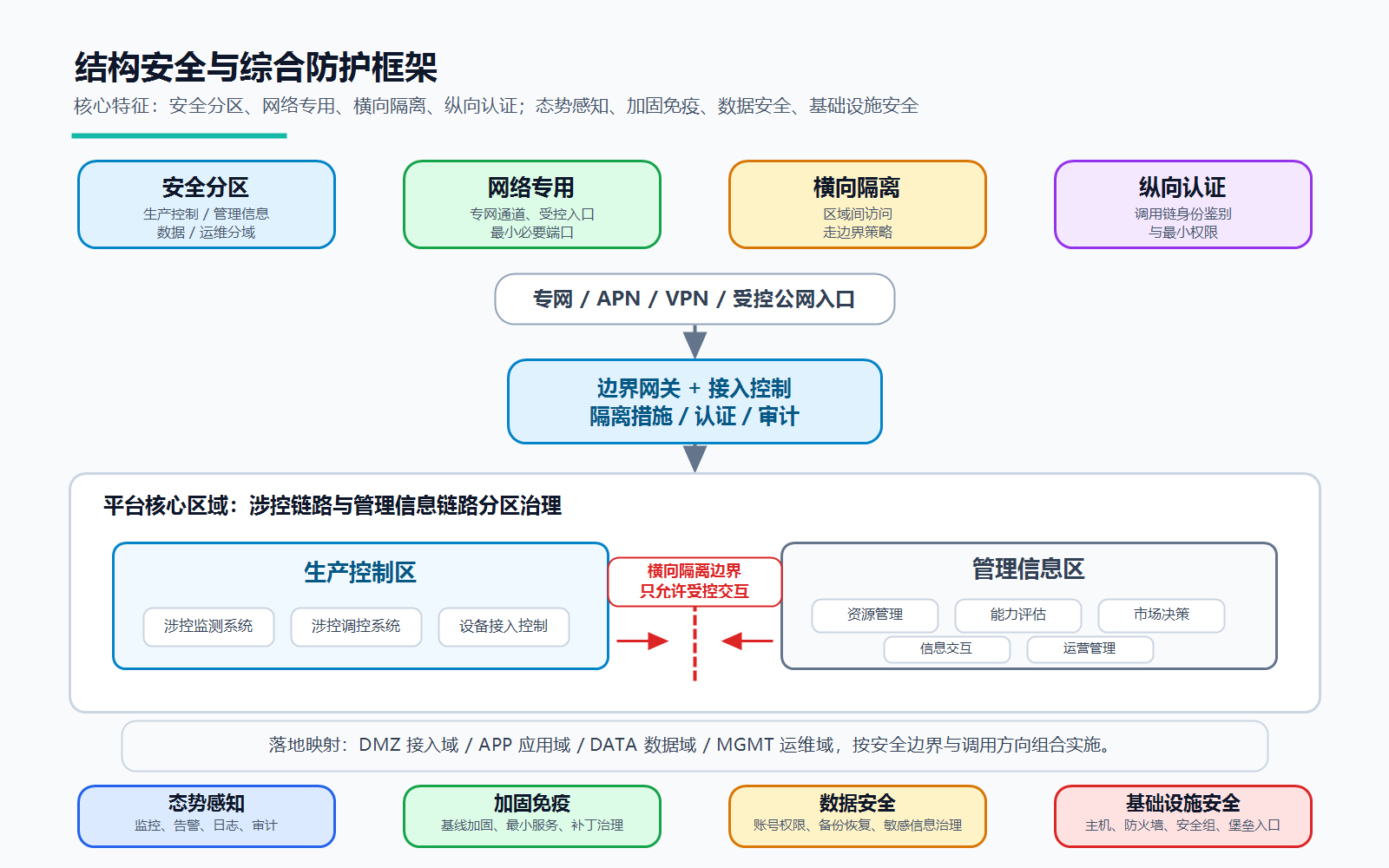
基于这套骨架,平台最终落到 DMZ / APP / DATA / MGMT 四个安全域。DMZ 负责接入,APP 放业务服务,DATA 放数据库、缓存、消息队列和配置中心,MGMT 放监控与运维能力。涉控链路与管理信息链路分开治理,横向访问走受控边界,纵向调用做身份鉴别和权限收敛。
这里最容易出问题的地方,是把"网络打通"误认为"架构完成"。生产环境里,能连通只是第一步。真正要回答的是:谁能访问谁,为什么能访问,访问失败怎么发现,访问异常怎么审计,临时放开的口子什么时候回收。
三、资源有限时,不做看起来很美的架构
这个项目的资源并不宽裕。5 台 ECS 里,应用、数据、接入、运维都要分工清楚。很多看上去"更高可用"的方案,放到这个资源条件下并不成立。
Kafka 就是典型例子。两节点 KRaft 看起来像集群,但 quorum 过不了数学关:挂掉一个节点后 leader 选不出来。与其做一个会给人错误安全感的伪集群,不如明确采用两套独立单节点,接受边界,避免脑裂。
TDengine 也是类似的问题。2 台机器做不了标准 3 节点集群,只能在现实条件里找折中方案:双实例接收写入,通过代理统一查询,并把故障切换验证步骤写清楚。这个方案不是"完美高可用",但它可解释、可验证,也能为后续扩容留下路径。
性能层面也一样。生产环境的瓶颈经常不是硬件不够,而是默认配置不合适。MySQL、Redis、Kafka 这些组件,如果直接沿用开发环境默认值,短期能跑,长期一定会暴露问题。因此每个中间件都按主机规格重新评估参数。
容器资源限制也不能只停留在 YAML 里。deploy.resources.limits 可以作为声明基线,但生产验收还要看实际 Docker Compose 运行方式,并用运行态检查确认限制是否生效。写了配置不等于配置生效,这是这类基础设施项目里很容易被忽略的一点。
四、真正费时间的是验证和收口
部署不是把服务启动起来就结束。很多问题恰恰发生在"看起来已经好了"的阶段。
我在这个项目里一直按三步验收:
- 先看意图。方案是不是解决了原问题,有没有跑偏。
- 再看质量。端口、路径、权限、环境变量、镜像行为是不是对。
- 最后看边界。有没有放松认证、暴露管理口、硬编码敏感信息、绕过审计。
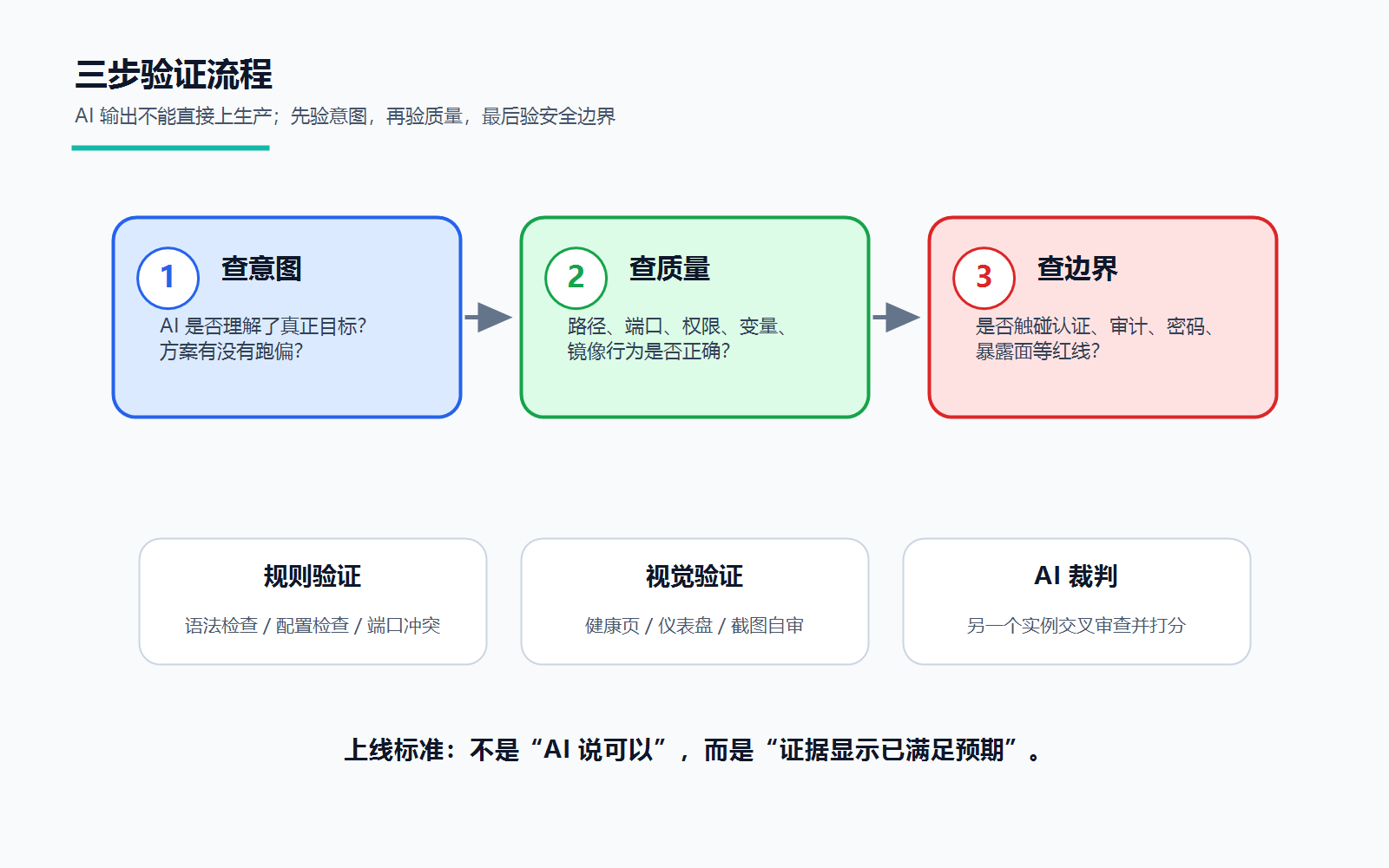
这套检查并不复杂,但顺序不能乱。比如 MySQL 从库初始化时,如果配置里提前启用了 super_read_only=ON,从"主从只读"的意图看没问题,从参数本身看也没问题,但放在容器首次初始化阶段就会阻止 entrypoint 写入,相当于门还没进就先锁上了。
再比如资源限制,配置里写了 CPU 和内存不代表现场一定生效;再比如健康检查路径,Spring MVC 和 Spring Cloud Gateway 的 actuator 行为不一样,不能只凭经验拼路径。
后来我把这些检查逐渐沉淀成部署前阻塞项。镜像是否就绪、目录是否对齐、环境变量是否缺失、跨主机依赖是否可达、安全组和 UFW 是否一致、业务配置是否与中间件实际部署一致,这些都要在启动服务前确认。这样做看起来慢,实际是在减少后面的无效排障。
五、工具辅助怎么用,关键在边界
这个项目确实大量使用了 AI 工具,但我不太愿意把它描述成"自动完成部署"。更准确地说,它承担了工程助理的角色:帮我读配置、生成草稿、比对差异、整理手册、复核遗漏。
真正不能交给工具的,是架构取舍。
比如 Kafka 做不做集群、配置中心认证兼容性短期怎么处理、DMZ 服务采用容器还是原生部署、哪些端口可以放开、哪些临时措施必须进入整改,这些都必须由人来拍板。工具可以提供选项和风险提示,但不能替项目负责人承担责任。
我在协作时主要做三件事。
第一,控制上下文。排查一个问题时,只给相关日志和配置,不把整个仓库都丢进去。信息越多不一定越好,尤其在基础设施项目里,无关配置会干扰判断。
第二,保留项目记忆。关键决策、主题规范、完整操作历史分层存放。下次遇到类似问题,先读记忆,再查现场状态。记忆不是权威,运行态和仓库现状才是最终依据。
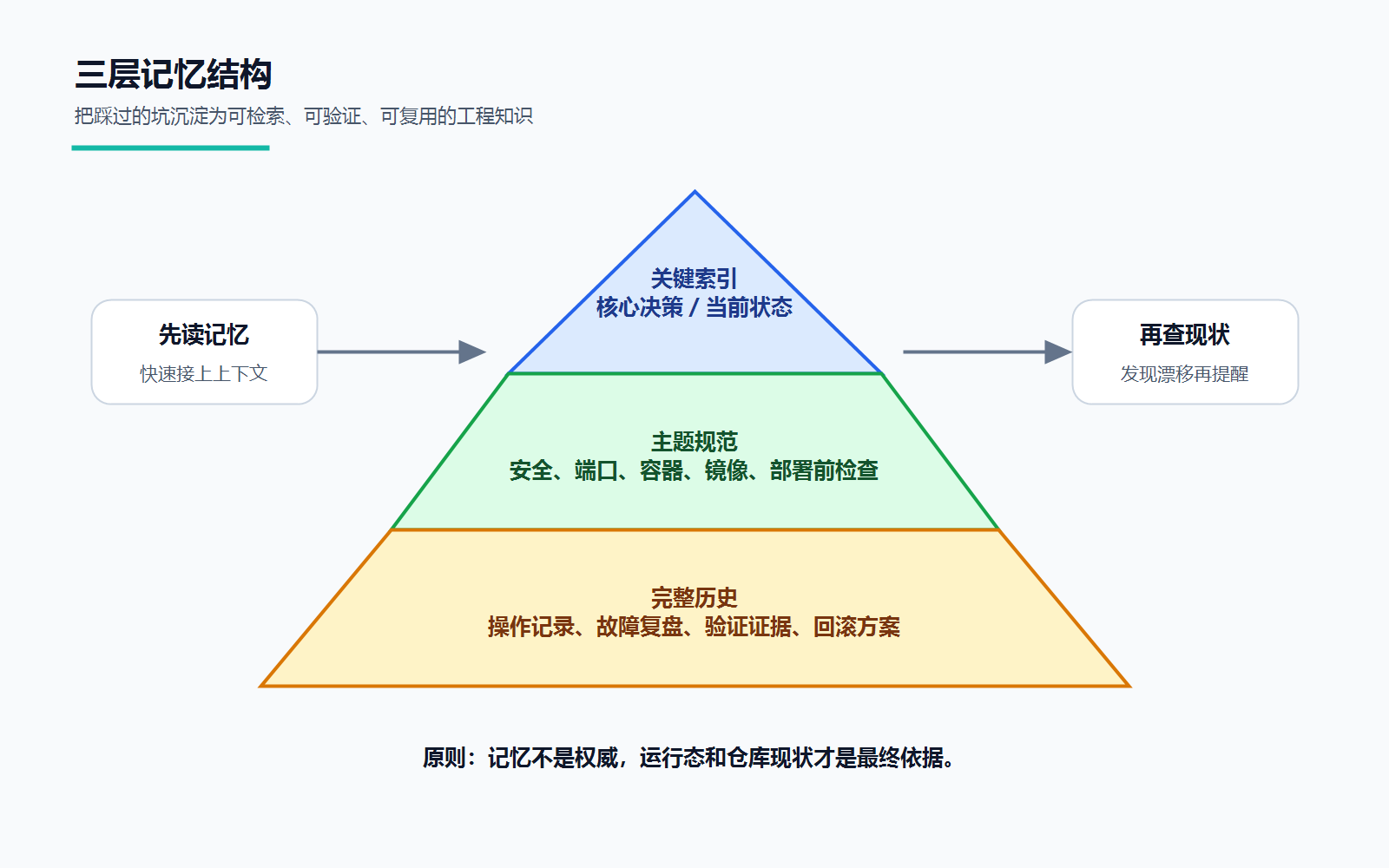
第三,限定工具的工作范围。格式整理、跨文件同步、检查清单生成,可以放心让工具做;涉及安全边界、认证放松、生产数据和网络开放,必须人工复核。
这也是我后来形成的一个基本判断:工具越强,流程不一定要越复杂。复杂的编排容易让人以为系统很可靠,但真正可靠的是清楚的边界、明确的验收标准和可追溯的记录。
六、几个印象比较深的现场问题
第一个是目录权限。Kafka 使用的镜像以非 root 用户运行,现场目录属主如果还是 root,容器就会启动失败。这类问题不难,但很容易被忽略。后来我把"第三方镜像必须核实实际运行用户、环境变量名和 entrypoint 行为"写进规范。
第二个是 Tengine 健康检查。配置看起来没问题,但健康检查一直 timeout。最后定位到 Docker hairpin NAT:同一宿主机上的容器通过宿主机 IP 回连自己发布的端口,可能被丢弃或超时。修复方式是改用 Docker 内部 DNS。这个问题解决后,也被写进了容器通信规范。
第三个是配置中心认证兼容性。业务底座的自研配置加载器与标准认证机制不兼容,服务启动后持续 403。这个问题不能简单归类为密码错或网络不通,而是框架兼容性冲突。短期可以用网络隔离和访问来源收敛兜底,但这不等于合规闭环,必须记录为整改项,并明确恢复认证前的前置条件。
这些问题有一个共同点:单个问题看起来都只是"部署故障",但真正有价值的是把它们沉淀成规则。否则下一次换个人、换一轮对话、换一个服务,还是会在同一个地方摔倒。
七、这次项目沉淀下来的口径
| 指标 | 数据 |
|---|---|
| 安全域 | 4 层隔离:DMZ / APP / DATA / MGMT |
| 结构安全 | 安全分区、网络专用、横向隔离、纵向认证 |
| 综合防护 | 态势感知、加固免疫、数据安全、基础设施安全 |
| 主机规模 | 5 台 ECS,4 台 Linux + 1 台 Windows |
| 容器数 | 30+ |
| 中间件 | 10+ 种 |
| 等保检查项 | 围绕 80 项完成主体加固与送测清单梳理,遗留项纳入整改闭环 |
| 重大问题 | 10 个,完成诊断、决策、修复和规范沉淀 |
| 生成文档 | 技术方案、操作手册、checklist、归档报告 |
| 历史数据 | 6 个数据库备份导入后,约 1500 万行脱敏样例数据完成清理与验证 |
八、最后的感受
这次项目最大的体会是:AI 工具能明显放大执行力,但它不会自动带来工程质量。
质量来自更朴素的东西:边界清楚,取舍明确,配置可验证,问题可追溯,临时方案能回收。工具可以帮你更快地产出文档和配置,也可以帮你检查遗漏,但它不能替你决定一个生产系统应该怎么承担风险。
一个人借助工具,确实可以推进过去需要几个人一起做的基础设施项目。但前提是,人要把该做的判断做掉:安全先分区,网络先收口,认证先定边界,数据先有备份,所有绕行都要留下记录。
这比"让 AI 自动部署"听起来没那么酷,但更接近真实项目。
本文基于项目真实记录整理,已对公开发布不宜暴露的部署细节做降敏处理;具体送测与整改状态以正式交付材料为准。