作者:来自 Elastic Jeff Vestal
解释如何在最少设置的情况下测量 Elasticsearch 中向量搜索的召回率。
从向量搜索到强大的 REST API,Elasticsearch 为开发者提供了最全面的搜索工具集。深入了解 Elasticsearch Labs 仓库中的示例 notebooks,尝试一些新内容。你也可以立即开始免费试用,或在本地运行 Elasticsearch。
每个人都希望向量搜索是即时的。但高维向量是 "沉重" 的。一个 1,024 维的 float-32 向量会占用相当多的内存,并且将其与数百万个向量进行比较在计算上代价高昂。
为了解决这个问题,像 Elasticsearch 这样的搜索引擎使用两种主要优化策略:
- 近似搜索(分层可导航小世界 HNSW):不是扫描每个文档,而是构建一个导航图,以快速跳转到答案可能所在的邻域。
- 量化:我们压缩向量(例如,从 32 位浮点数压缩到 8 位整数,甚至 1 位二进制值),以减少内存使用并加快计算速度。
但优化通常伴随着代价:准确性。
这种担忧是合理的:"如果我压缩数据并在搜索过程中走捷径,会不会错过最佳结果?""这种优化是否会降低搜索引擎的相关性?"
为了证明 Elastic 的量化不会降低结果质量,我们使用 DBPedia-14 数据集构建了一个可重复的测试框架,用于精确计算在 Elasticsearch 中使用默认优化时,为了速度所牺牲的准确性(具体来说是召回率)。
总结:实际影响可能远小于你的想象。查看 notebook 并亲自尝试。
定义(面向非专家)
在查看代码之前,我们先统一一些术语。
- 相关性 vs 召回率:相关性是主观的(我是否找到了好的结果?)。召回率是数学上的。如果数据库中有 10 个与查询完全匹配的文档,而搜索引擎找到了其中 9 个,那么你的召回率是 90%(或 0.9)。
- 精确搜索(flat) :有时称为 "暴力" 方法。搜索引擎扫描索引中的每一个文档并计算距离。
- 优点:100% 完美召回率。
- 缺点:计算成本高,在大规模下速度慢。
- 近似搜索(HNSW) :一种"捷径"方法。搜索引擎构建一个 HNSW 图,并在图中遍历以找到最近邻。
- 优点:速度极快且可扩展。
- 缺点:如果图遍历过早停止,可能会错过某些邻居。
实验:精确 vs 近似
为了测试召回率,我们使用了 DBPedia-14 数据集,这是一个包含 14 个本体类别的标题和摘要的大型数据集,常用于训练和评估文本分类模型。具体来说,我们将重点关注 "Film" 类别。我们的目标是将优化后的生产设置与数学上完美的基准进行比较。
在本实验中,我们使用 jina-embeddings-v5-text-small 模型,这是一个最先进的多语言模型,在文本表示方面领先行业基准。我们选择该模型是因为它代表了当前高性能 embedding 的标准。通过将 Jina v5 的高精度与 Elasticsearch 的原生量化相结合,我们可以展示一种既计算高效又不牺牲检索质量的搜索架构。
我们设置了一个具有双映射的索引。我们将相同的文本同时写入两个不同的字段:
- content.raw,类型为 flat。这会强制 Elasticsearch 对完整的 Float32 向量执行暴力扫描。该方式返回精确匹配结果,并将作为我们的基准。
- content,类型为 semantic_text。默认使用 HNSW + Better Binary Quantization(BBQ)。这是近似匹配的标准优化生产设置。
Recall@10 测试
我们的指标使用 Recall@10。
我们随机选择了 50 部电影,并在两个字段上运行相同的查询。
- 如果**精确(flat)**搜索认为前 10 个邻居的 ID 是 1, 2, 3... 10。
- 而**近似(HNSW)**搜索返回的 ID 是 1, 2, 3... 9, 99。
- 那么我们正确找到了前 10 个中的 9 个,得分为 0.9。
这是我们使用的映射:
bash
`
1. # The "Control Group": Forces exact brute-force scan
2. "raw": {
3. "type": "semantic_text",
4. "inference_id": ".jina-embeddings-v5-text-small",
5. "index_options": {
6. "dense_vector": {
7. "type": "flat"
8. }
9. }
10. }
`AI写代码结果:"平直线"的成功
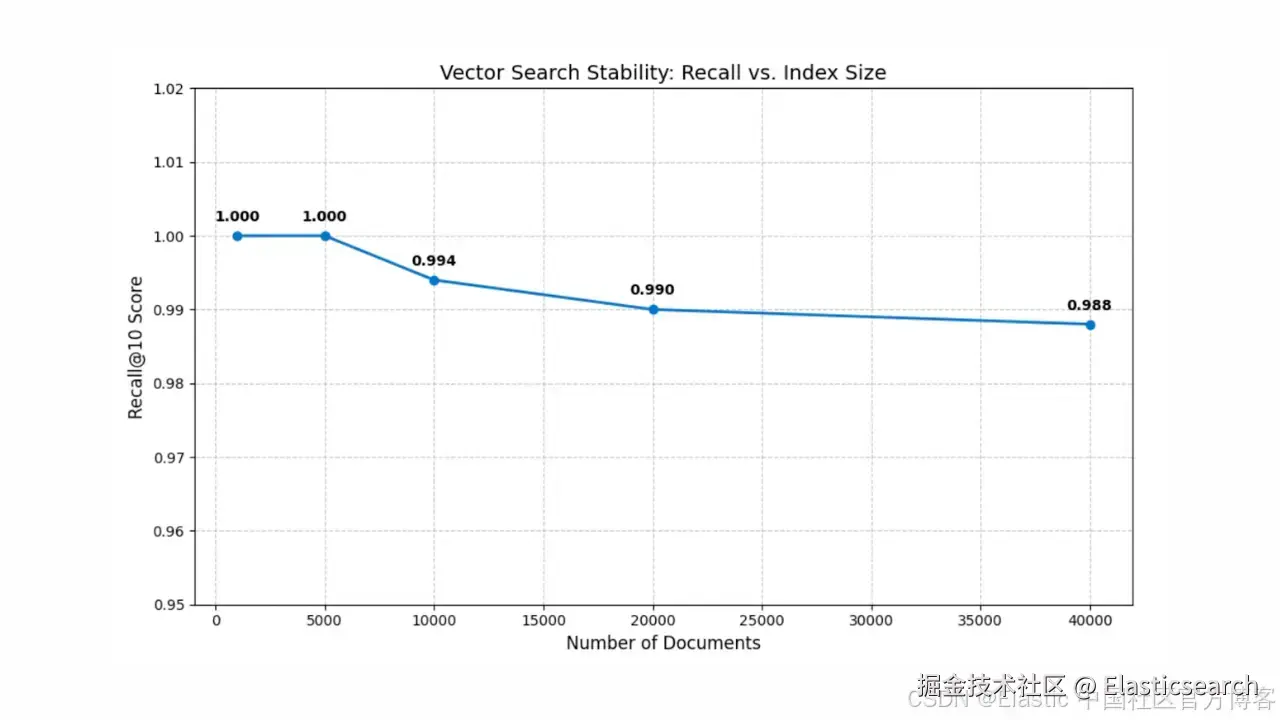
我们进行了一个规模测试,重新加载完整数据集,并针对 1,000 到 40,000 文档的索引规模进行测试。
以下是召回率得分的变化:
| 文档数 | Recall@10 得分 |
|---|---|
| 1,000 | 1.000(100%) |
| 5,000 | 0.998(100%) |
| 10,000 | 0.992(99.4%) |
| 20,000 | 0.999(99.0%) |
| 40,000 | 0.992(98.8%) |
结果非常稳定。即使在规模扩大时,近似搜索在超过 99% 的情况下与暴力精确搜索结果一致。
为什么效果这么好?
你可能会认为将向量压缩为二进制值会比实际影响的准确性更大。原因在于 Elasticsearch 如何处理检索。
如今大多数 embedding 模型输出 Float32 向量,这些向量很大。为了提高搜索效率,Elasticsearch 对高维向量使用量化。具体来说,自 9.2 版本起,它默认使用 BBQ。
BBQ 使用重评分机制:
-
遍历(Traversal):搜索引擎使用压缩(量化)向量快速遍历 HNSW 图。由于向量较小,它可以高效地过采样,收集更多候选文档(例如,前 100 个大致相似的文档),而不会带来性能损耗。
-
重评分(Rescore):一旦获取到候选文档,它只检索这些少数文档的全精度值,以计算最终的精确排序。
这让你两全其美:量化带来的速度处理大量数据,以及浮点数带来的最终排序精度。
还能做得更好吗?
值得注意的是,我们这里看到的结果使用的是默认设置和随机采样数据。可以把它看作一个高性能的起点。虽然 Jina v5 非常强大,但这些召回率并不是针对每个数据集的 "一刀切" 保证。每个数据集合都有自己的特点,虽然你可以进一步调优以获取更高性能,但你应始终针对自己的具体数据进行基准测试,以确定实际上限。
结论
这是一个非常小规模的测试。但这项练习的重点不是专门测量 embedding 模型或 BBQ,而是展示如何在最少设置下轻松测量你数据集的召回率。
如果你想在自己的数据上运行此测试,可以查看这里的 notebook 并亲自尝试。