1. 研究背景
在工程、金融、能源等领域,回归预测 是常见的任务。
但仅输出点预测值往往不足以反映不确定性,因此需要 概率预测 (如置信区间)来量化预测风险。
LightGBM 作为一种高效梯度提升树模型,适合处理大规模数据;
而 蜣螂优化算法 用于自动搜索模型超参数,避免人工调参的繁琐。
该代码在此基础上增加了 核密度估计 方法,构建多置信度的预测区间,并提供多种评估指标。
2. 主要功能
- 使用 蜣螂优化算法 自动搜索 LightGBM 的三个关键超参数(叶子节点数、学习率、树深度)
- 基于 LightGBM 构建回归模型
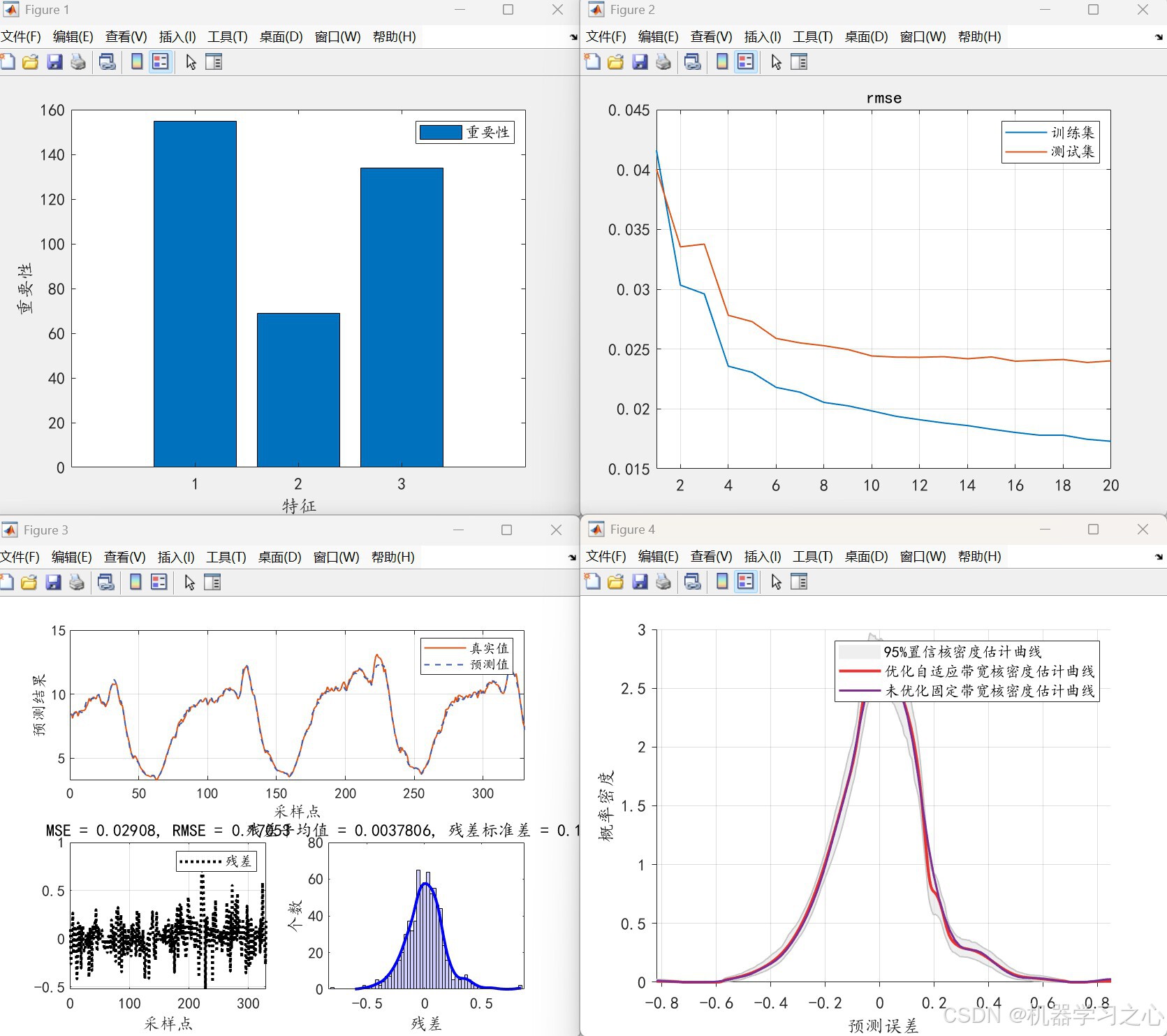
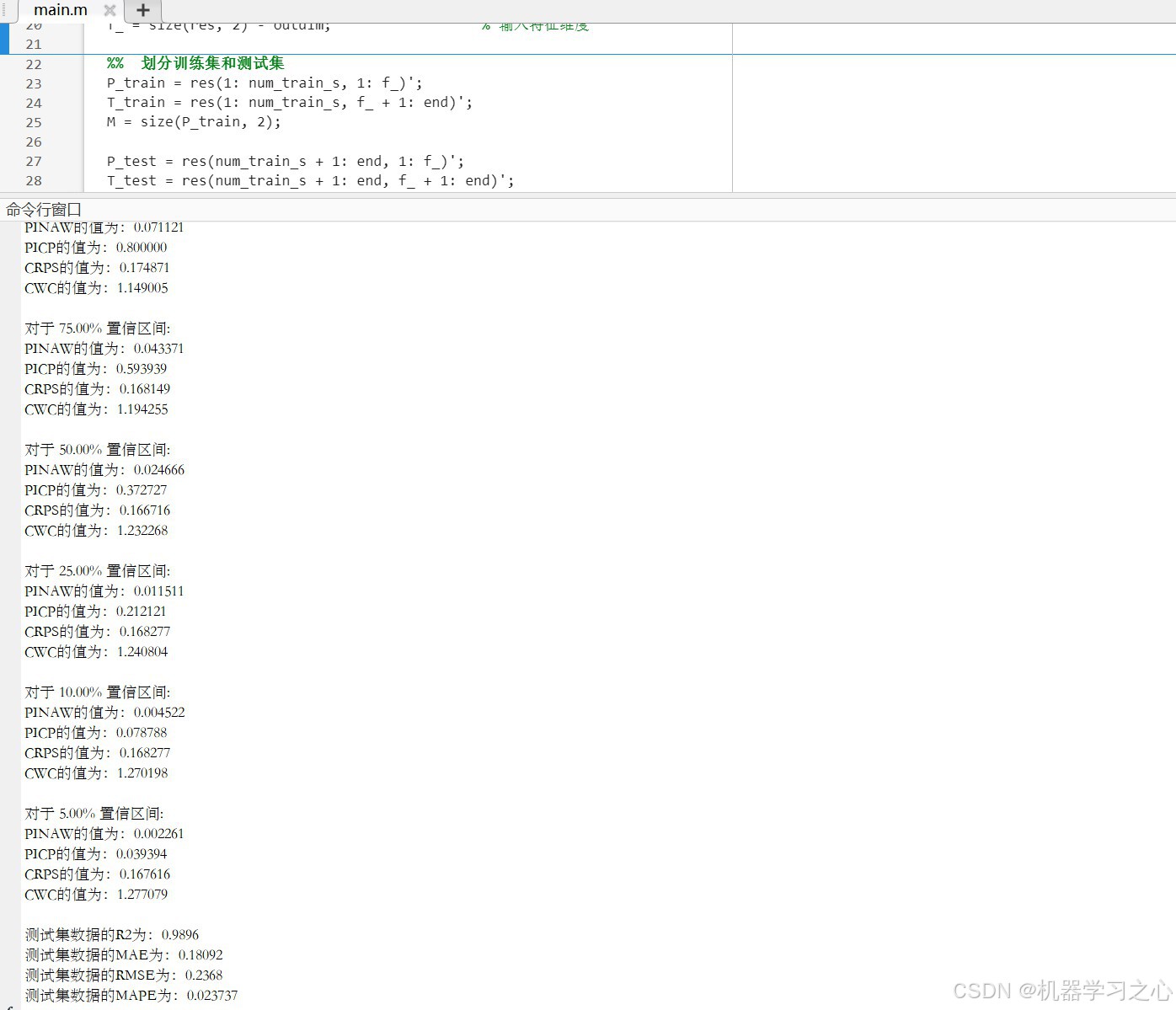
- 输出点预测结果,并计算 RMSE、MAE、MAPE、R² 等误差指标
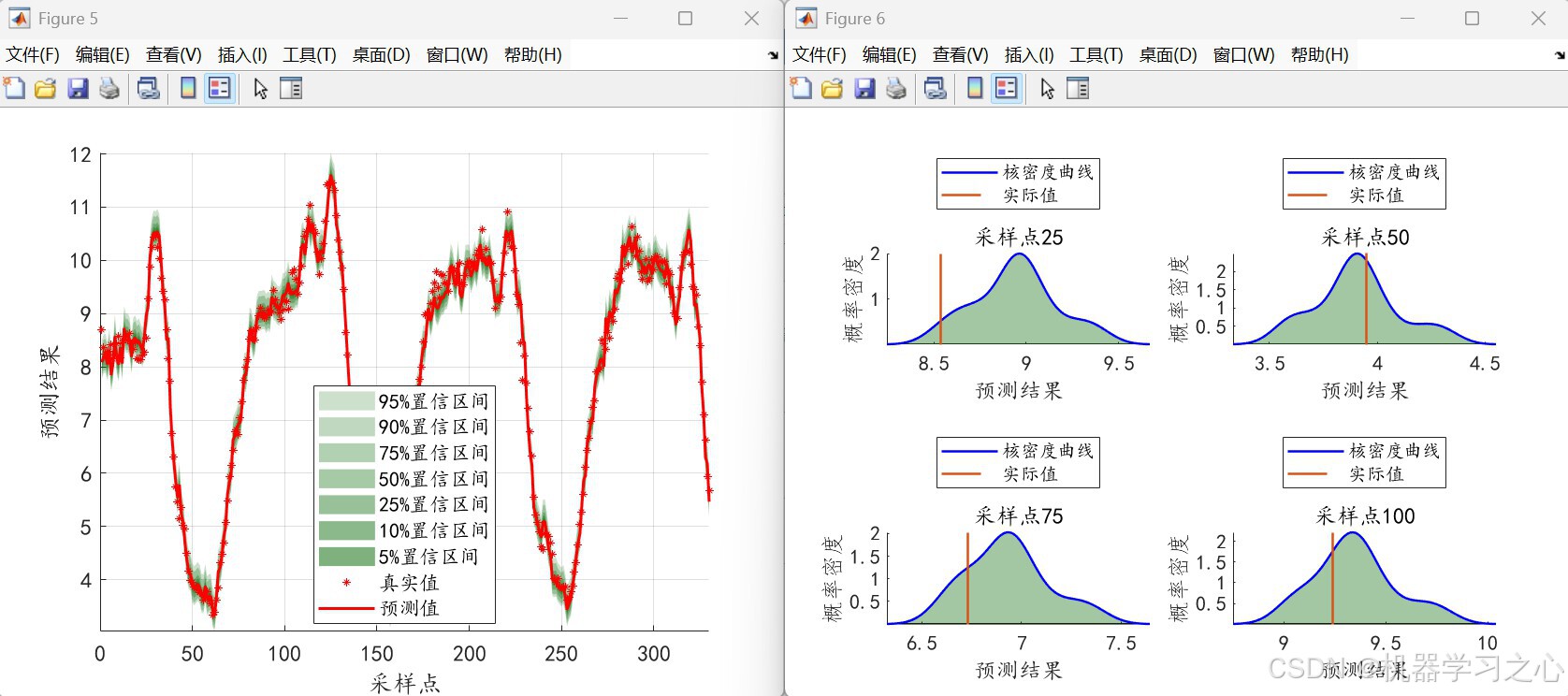
- 基于预测误差的 核密度估计 生成多置信度的预测区间(如 5%~95%)
- 输出 PICP、PINAW、CRPS、CWC 等区间预测评价指标
- 可视化特征重要性、预测曲线、残差分布、核密度估计图
3. 算法步骤
-
数据准备
- 加载 Excel 数据,划分为训练集(70%)和测试集(30%)
- 对特征和输出分别进行归一化(
mapminmax到 0,1)
-
超参数优化
- 定义优化目标函数
getObjValue(返回验证集 RMSE) - 使用蜣螂优化算法(DBO)搜索最优超参数
- 定义优化目标函数
-
模型训练
- 用最优超参数构建 LightGBM 模型
- 设置回归任务、早停机制,训练完成后保存最佳迭代轮次
-
点预测与评估
- 对训练集和测试集进行预测,反归一化
- 计算 RMSE、MAE、MAPE、R²
-
区间预测
- 计算预测误差
- 使用自适应带宽核密度估计(ABKDE)拟合误差分布
- 通过分位数反求误差上下界,叠加到点预测值,得到各置信区间
-
区间评估
- 计算 PICP(覆盖率)、PINAW(区间宽度)、CRPS、CWC 等指标
-
可视化
- 特征重要性条形图
- 训练/测试集 RMSE 曲线
- 预测值与真实值对比图
- 误差分布与核密度图
- 置信区间填充图
- 选定采样点的核密度曲线
4. 技术路线
数据加载与划分 → 归一化 → DBO 超参数优化 → LightGBM 训练 → 点预测
↓
误差分布(ABKDE)→ 区间预测
↓
点预测指标 + 区间预测指标- 优化器:蜣螂优化算法(DBO)
- 模型:LightGBM(回归)
- 区间构建:自适应带宽核密度估计(ABKDE)
- 评价:PICP、PINAW、CRPS、CWC、RMSE、R² 等
5. 公式原理
5.1 蜣螂优化算法(DBO)
模拟蜣螂的滚球、跳舞、觅食等行为,用于连续优化问题。
种群分为生产者、探索者、偷窃者等角色,分别执行不同更新策略,兼顾全局与局部搜索。
5.2 LightGBM
基于梯度提升框架,使用 单边梯度采样 和 互斥特征捆绑 提升训练效率。
优化目标为最小化均方误差(回归任务)。
5.3 自适应带宽核密度估计(ABKDE)
对误差分布进行非参数估计,带宽随数据局部密度自适应变化,比固定带宽更准确。
通过误差分位数确定置信区间上下界:
Qlower=F−1(α),Qupper=F−1(1−α) Q_{\text{lower}} = F^{-1}(\alpha), \quad Q_{\text{upper}} = F^{-1}(1-\alpha) Qlower=F−1(α),Qupper=F−1(1−α)
5.4 区间评价指标
- PICP:真实值落在区间内的比例
- PINAW:区间宽度占输出范围的比例
- CRPS:连续概率排序分数,衡量预测分布与真实值的距离
- CWC:综合覆盖率与宽度的惩罚指标
6. 参数设定
| 参数 | 值 | 说明 |
|---|---|---|
| 训练集比例 | 0.7 | 划分数据集 |
| DBO 种群数 | 20 | 优化算法个体数 |
| DBO 迭代次数 | 20 | 优化迭代轮次 |
| 叶子节点数范围 | 2, 64 | 超参数搜索空间 |
| 学习率范围 | 0.8, 1 | 超参数搜索空间 |
| 树深度范围 | 2, 10 | 超参数搜索空间 |
| LightGBM 迭代轮次 | 100 | 最大训练轮次 |
| 早停轮次 | 5 | 验证集无改善时停止 |
| 置信水平 | 5%~95% | 7 个分位数 |
7. 运行环境
- MATLAB2020
8. 应用场景
- 能源预测:如风电功率、光伏出力、负荷预测(需区间估计以评估风险)
- 工业过程控制:关键参数预测,用于预警与决策
- 金融时间序列:资产收益率预测与风险区间构建
- 环境监测:污染物浓度预测
- 任何需要 点预测 + 置信区间 的回归问题