课前小知识
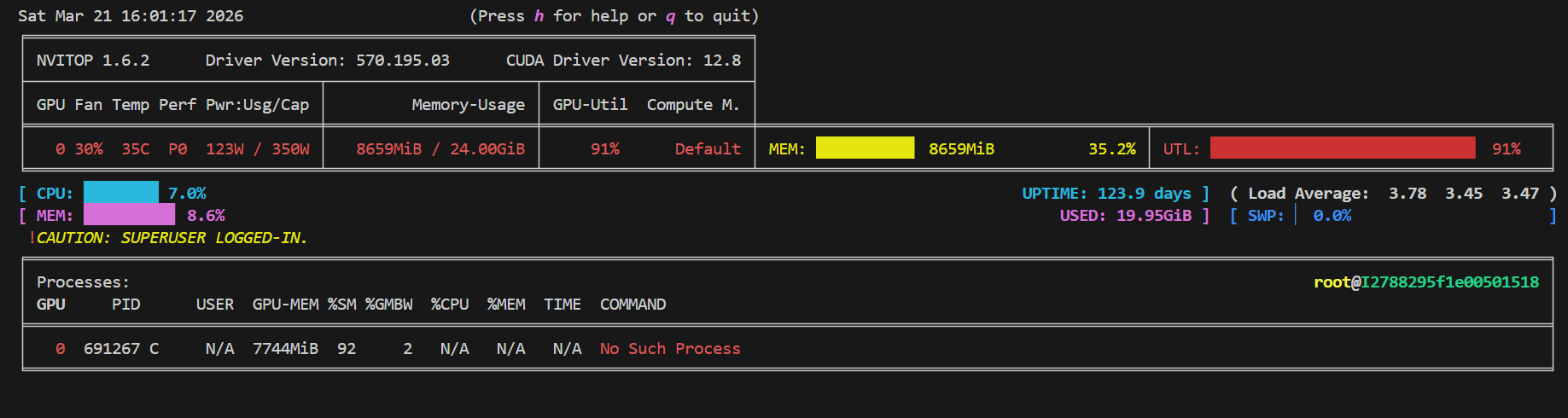
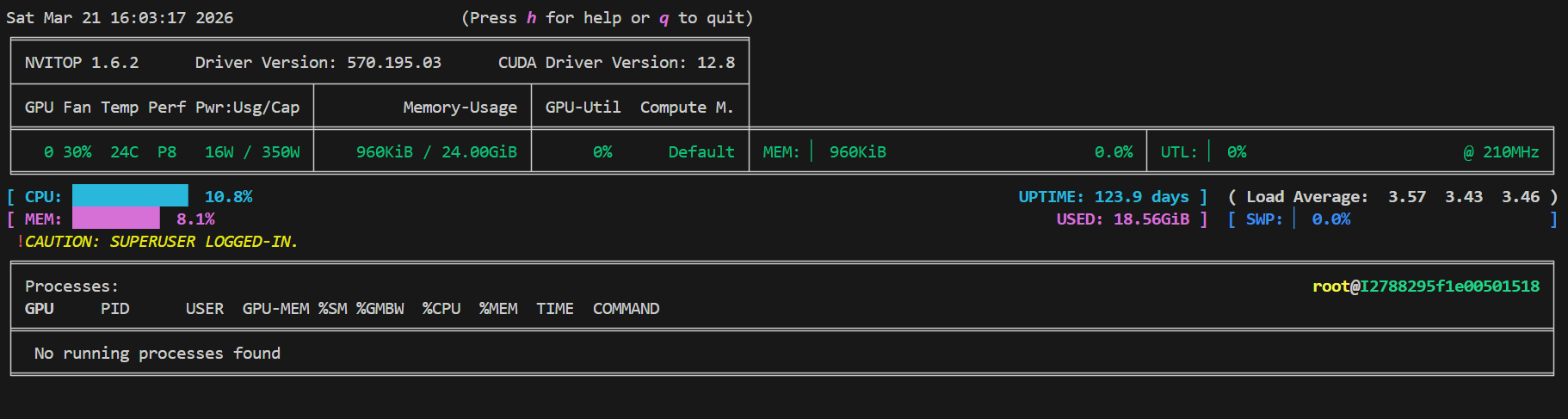
显卡占用
有时候LLama Factor,点击卸载模型之后,显卡占用还是很高,这个时候将服务停止后重启
停止,重启
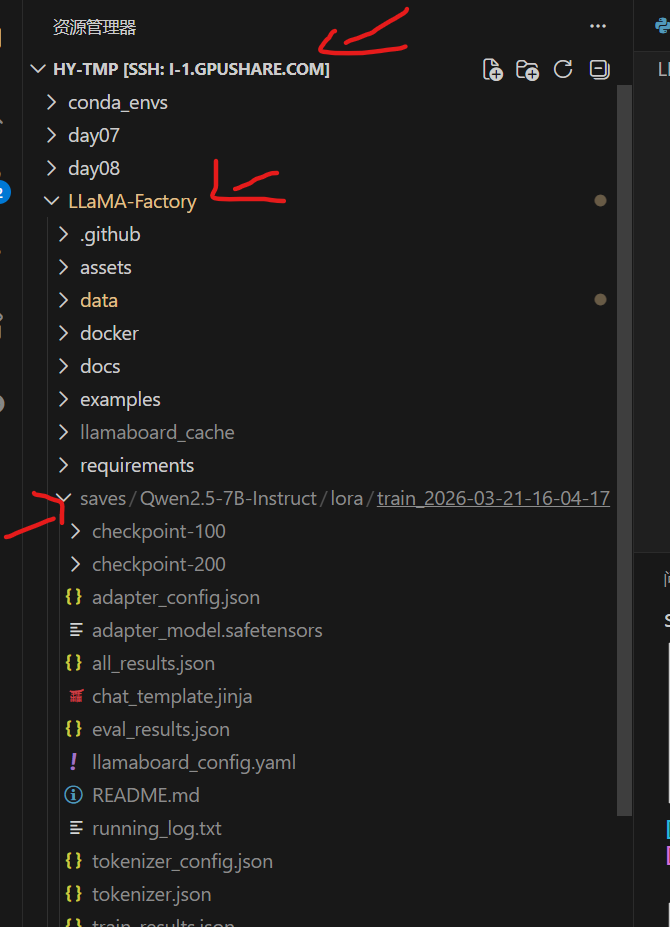
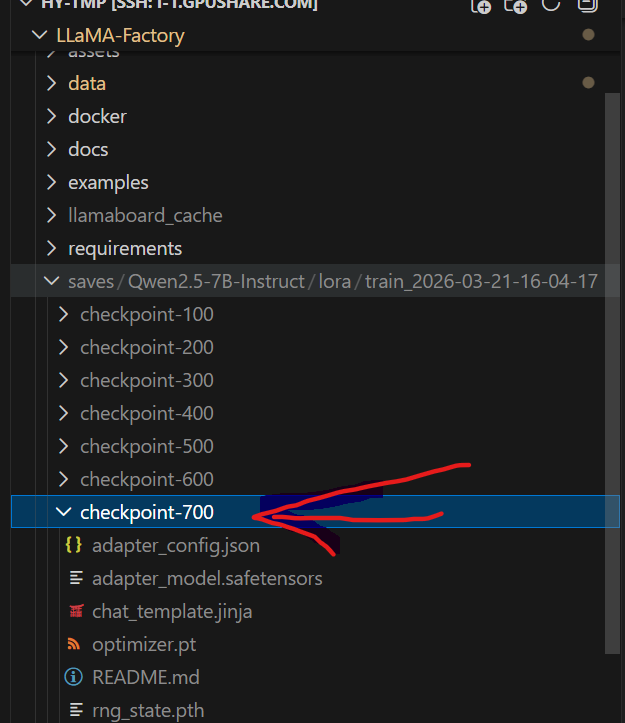
权重保存位置
大模型微调
瓶颈结构
神经网络有很多层,每一层参数对模型的影响是不同的(越深影响越大),作为局部微调,就要去调整影响大的参数

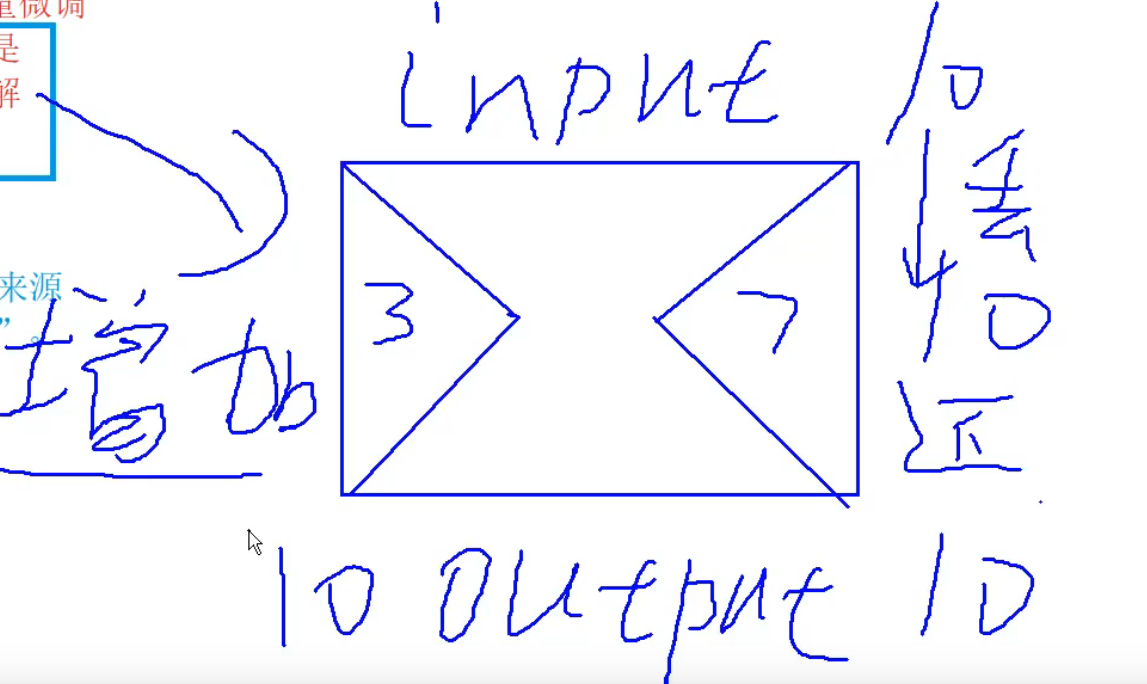
1. LoRA微调
1.1、基本概念

1.2、原理
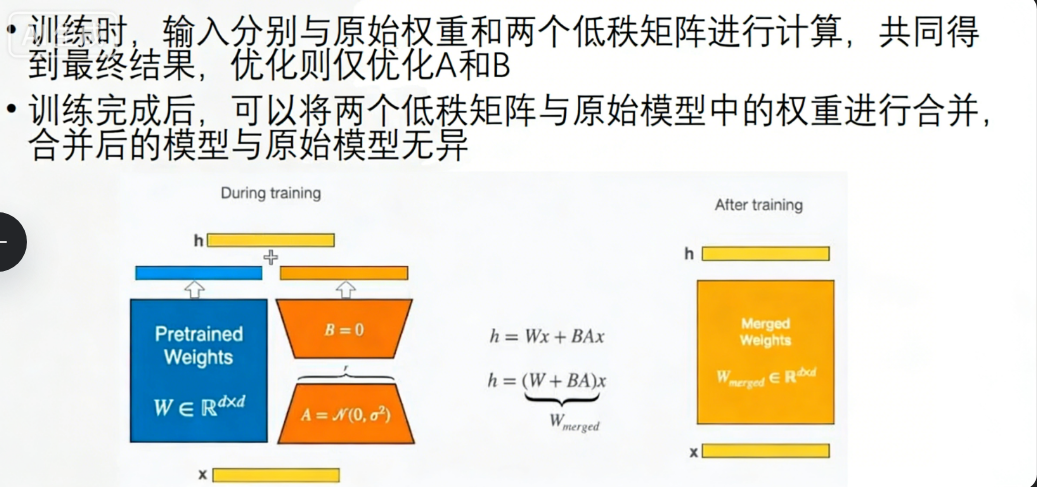
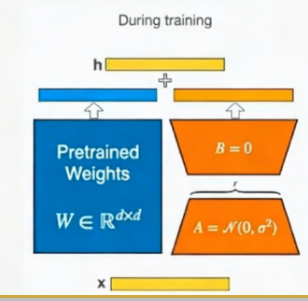
其中每一层的参数量,B矩阵是主机递减的,A矩阵是逐级升高的
在前向传播的时候(由下到上),x参数是分别输出给左侧全量参数和右侧训练参数的,得出的结果累加之后为h,用h作loss计算,然后再反向传播只给右侧训练参数,
训练只有原模型和训练模型要合并之后才能用,右图
为什么训练的快:
因为训练是反向传播,反向传播的时候只有B\A矩阵参与,原模型不参与,所以相比反向传播原模型,更快
1.3、核心思想
低秩适应(Low-Rank Adaptation) :冻结原始大模型参数,仅训练新增的低秩矩阵(下图A+B),将参数量减少千倍。
数学表达:调整后的权重 = 原始权重 + BA

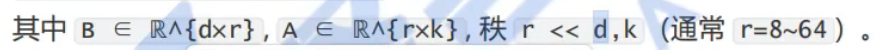
1.4、为什么高效?
参数效率:仅训练 : 0.1% ∼ 1% 的参数量(如70B模型仅需70M参数)。
内存友好:梯度只计算小矩阵,显存占用降低3~5倍。
即插即用:训练后的LoRA权重可独立保存(adapter_model.bin),动态加载到原模型。
✅ 适用场景: 指令跟随、角色扮演、领域知识注入等轻量化微调。
2. LLaMA Factory介绍
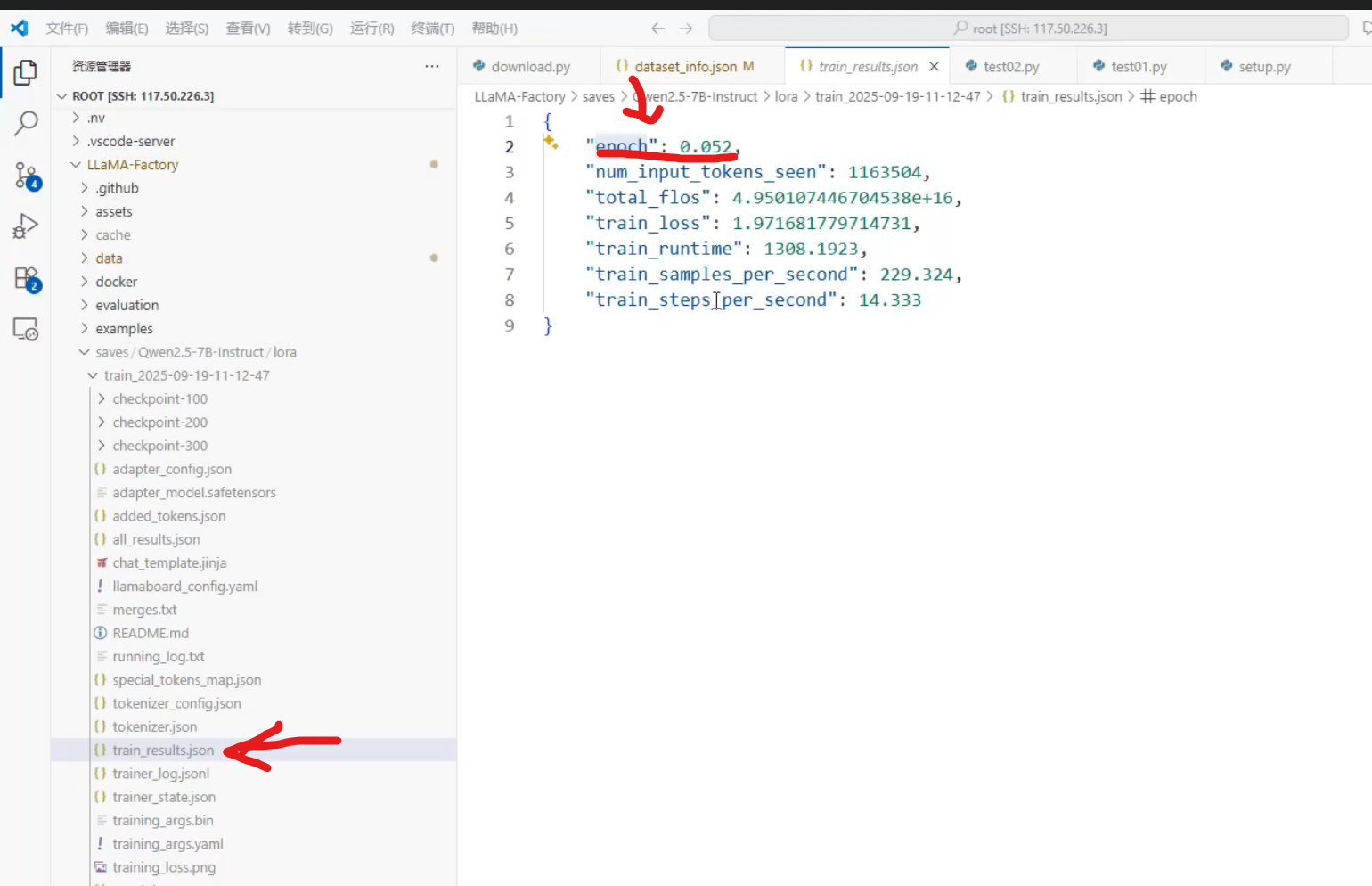
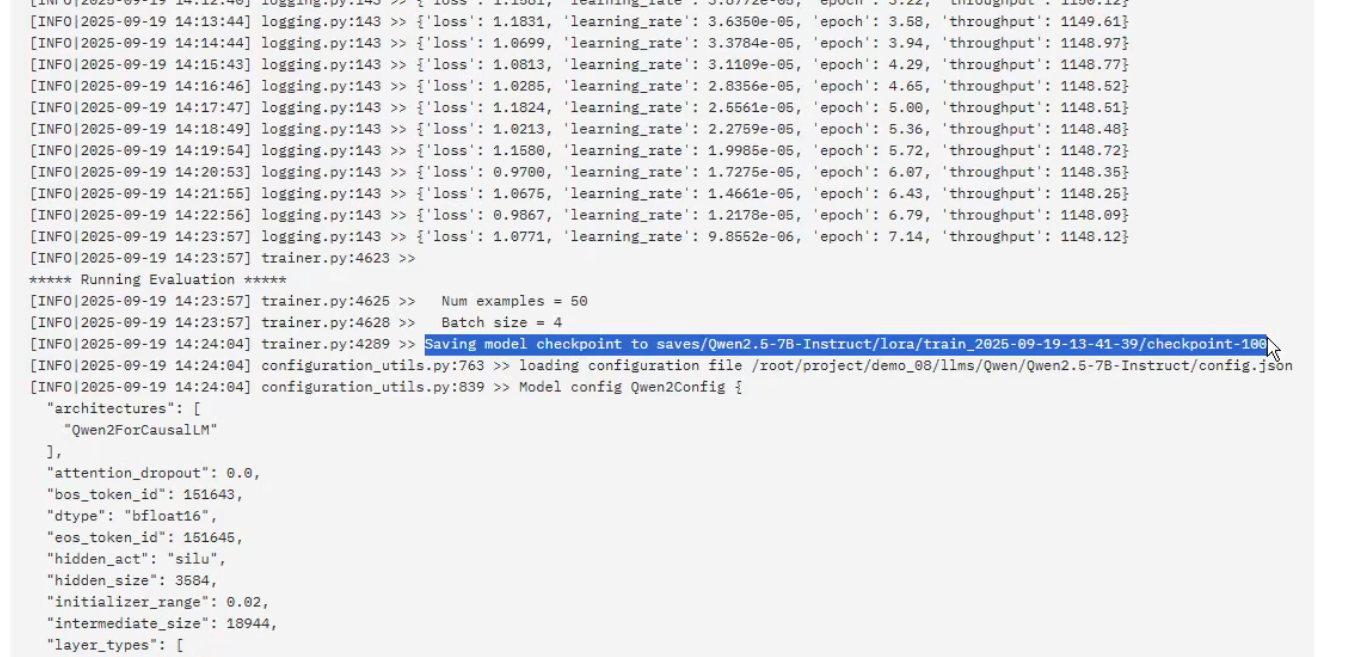
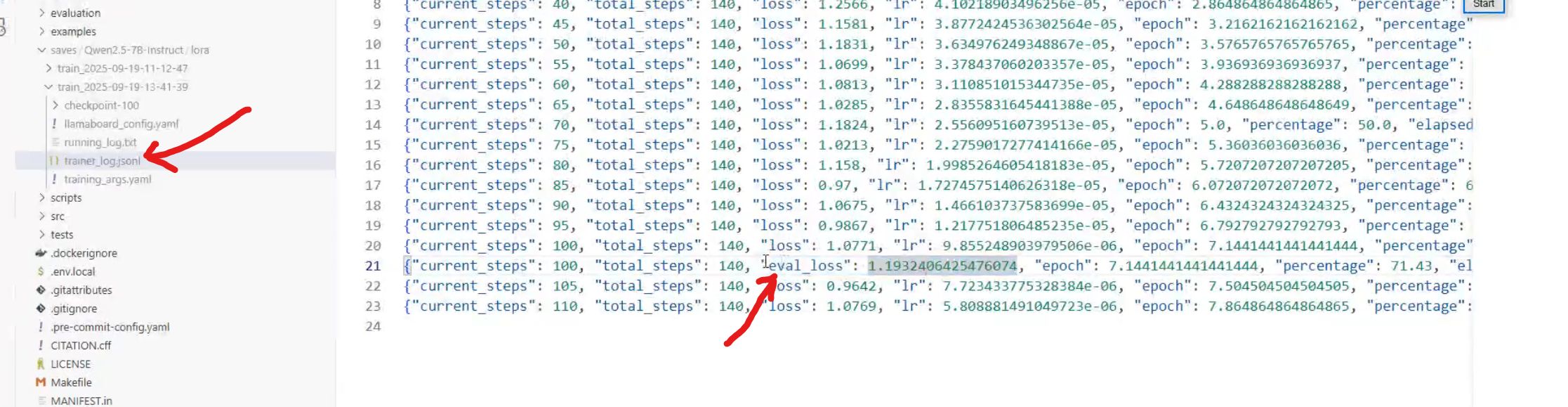
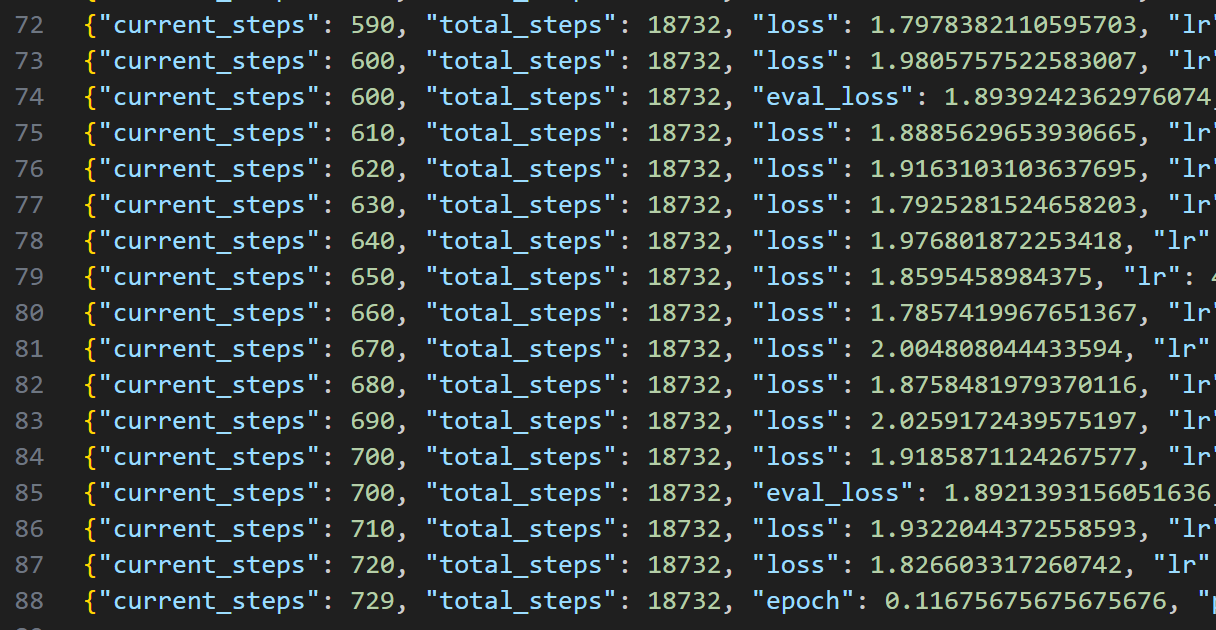
这是训练的返回数据,下一行的log是训练日志(loss),这里的epoch训练完成总体是1
每一百轮保存一次参数,还会保存web页面的配置文件
支持非常多的模型
2.1、核心功能
统一框架:支持 LLaMA/Qwen/Baichuan/ChatGLM 等 100+ 模型
高效训练:集成 LoRA/QLoRA/全参数微调,支持多GPU、DeepSpeed
零编码:提供可视化Web UI,无需写代码即可启动训练
数据集智能处理:自动格式化 instruction/input/output 三列数据
2.2、环境配置
创建环境
python
# 1. 设置 conda 的环境目录到 /hy-tmp
conda config --append envs_dirs /hy-tmp/conda_envs
# 2. 查看当前配置
conda config --show envs_dirs
# 创建环境,实时查看要求的python版本
conda create -n llama_factory python=3.11 -y
conda activate llama_factory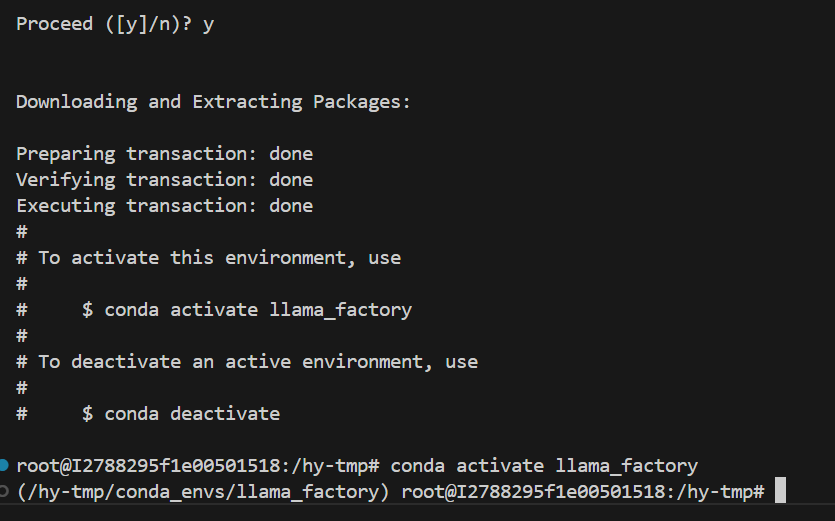
安装依赖
确认在数据盘

确认开启kexue上网,否则报错

python
# 安装依赖
git clone https://github.com/hiyouga/LLaMA-Factory.git
cd LLaMA-Factory
pip install -e .
2.3、启动
方式01
进入conda环境后,一定要在对应的目录下
下面,见方案一(3.实战)

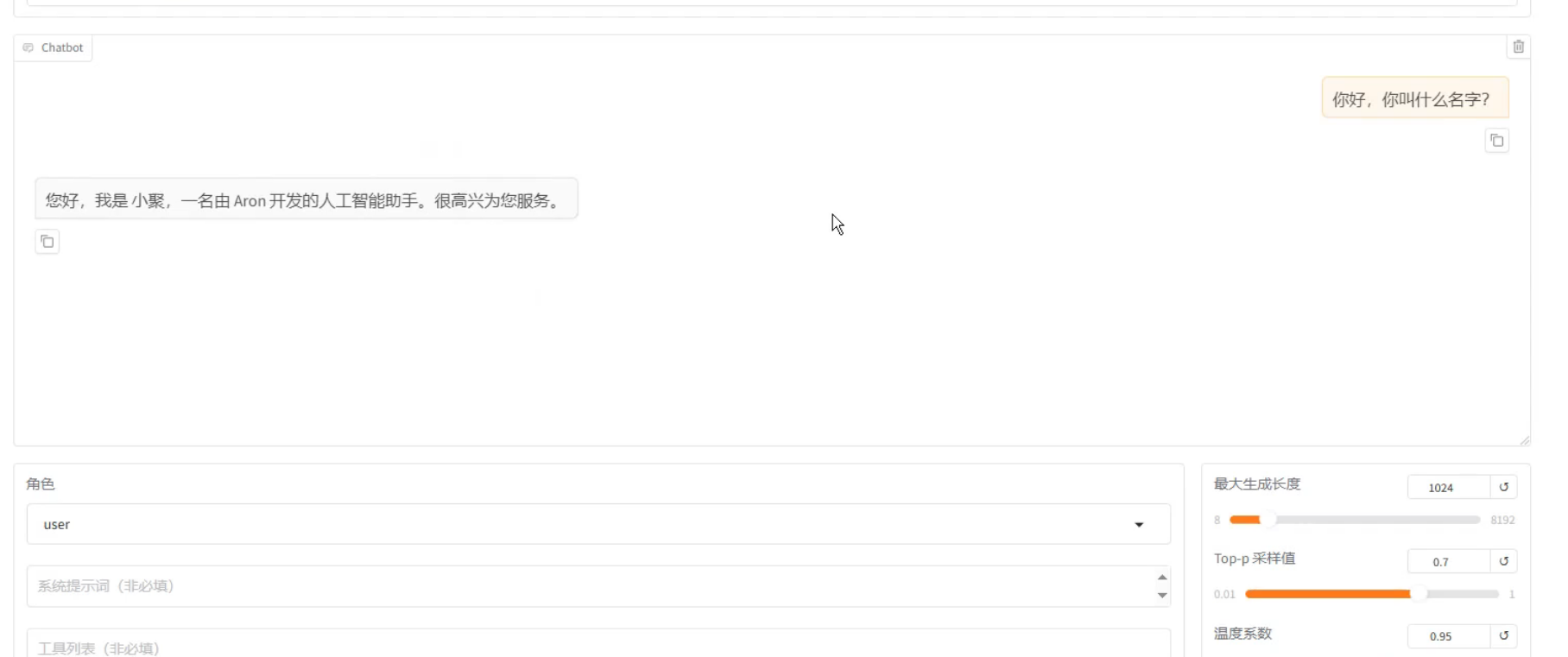
3. 实战:微调Qwen-7B自定义数据集
方案一:通过Web UI配置(推荐,无需手动创建文件)
1.启动Web服务
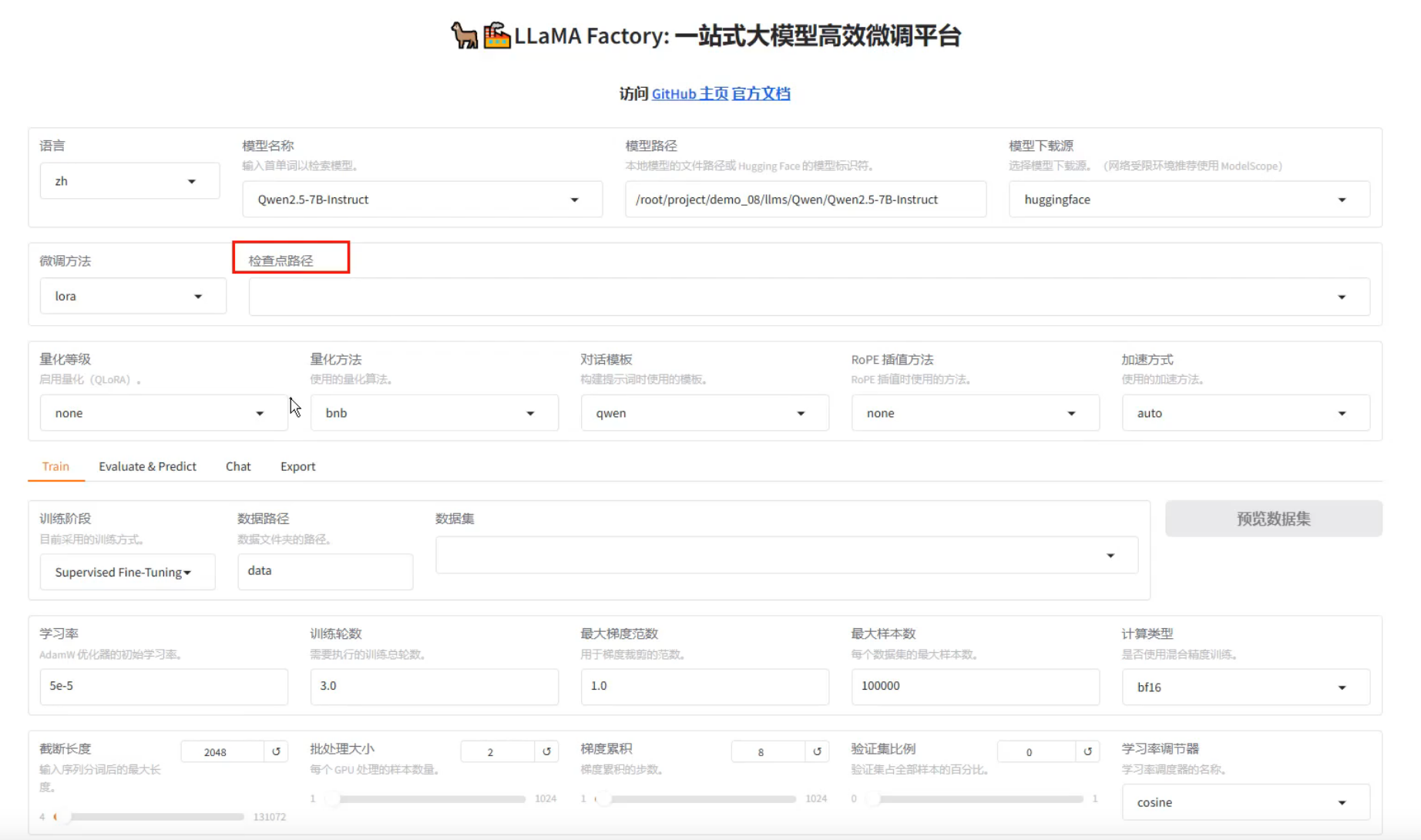
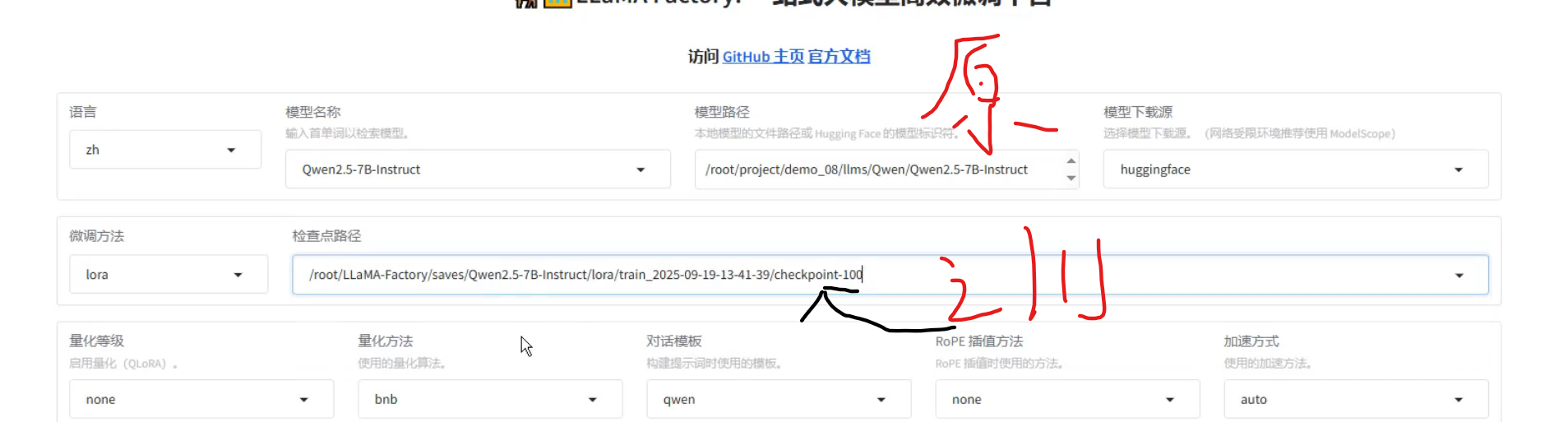
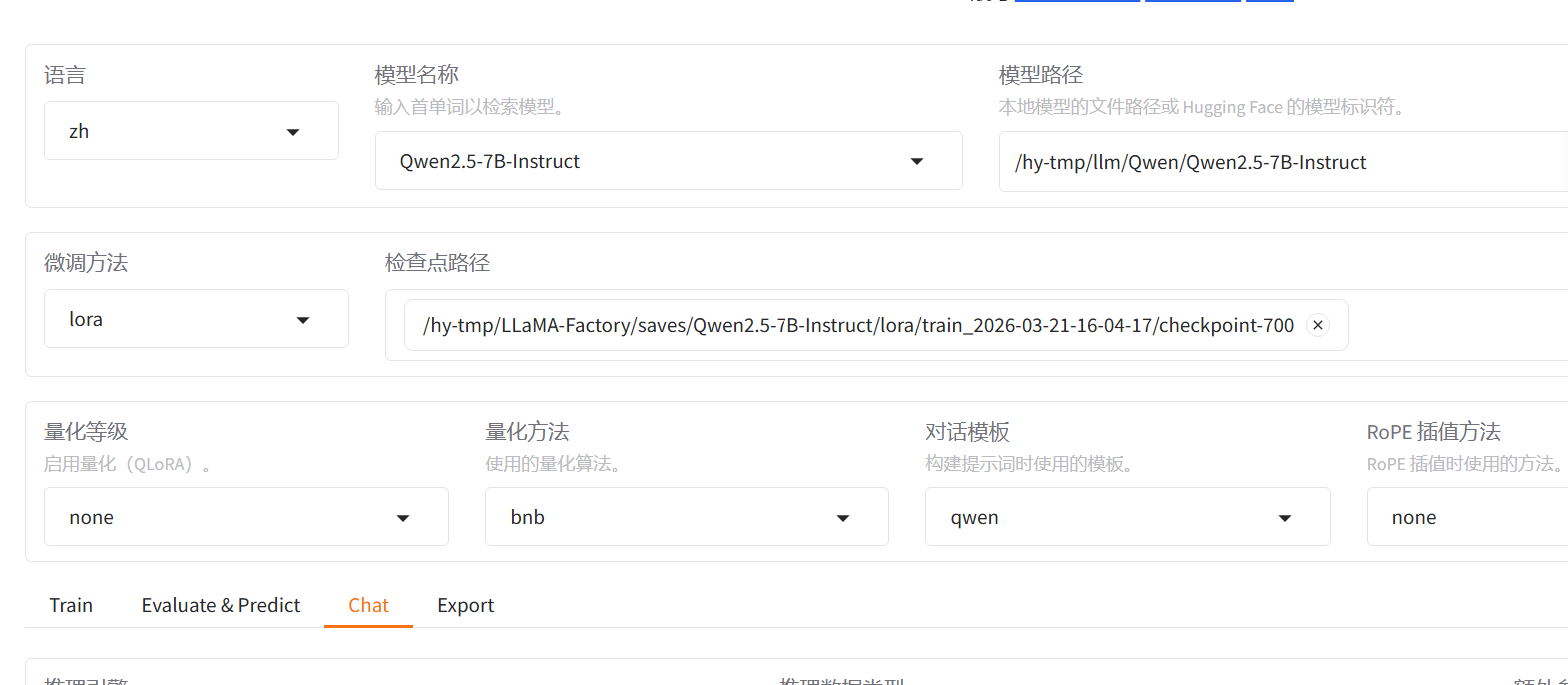
pythoncd LLaMA-Factory llamafactory-cli webui选择模型以及绝对路径
检查点路径:模型训练之后保存的权重
训练、测试、对话、

2. 界面配置关键参数 :
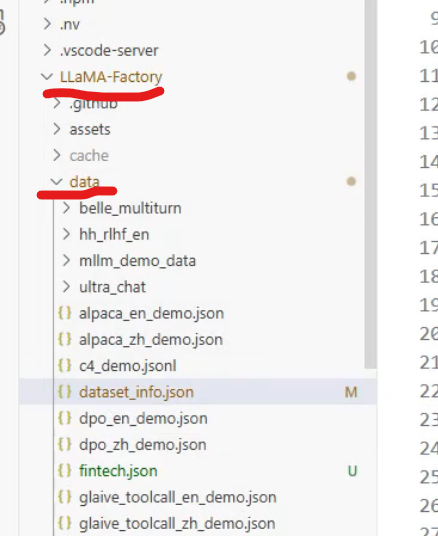
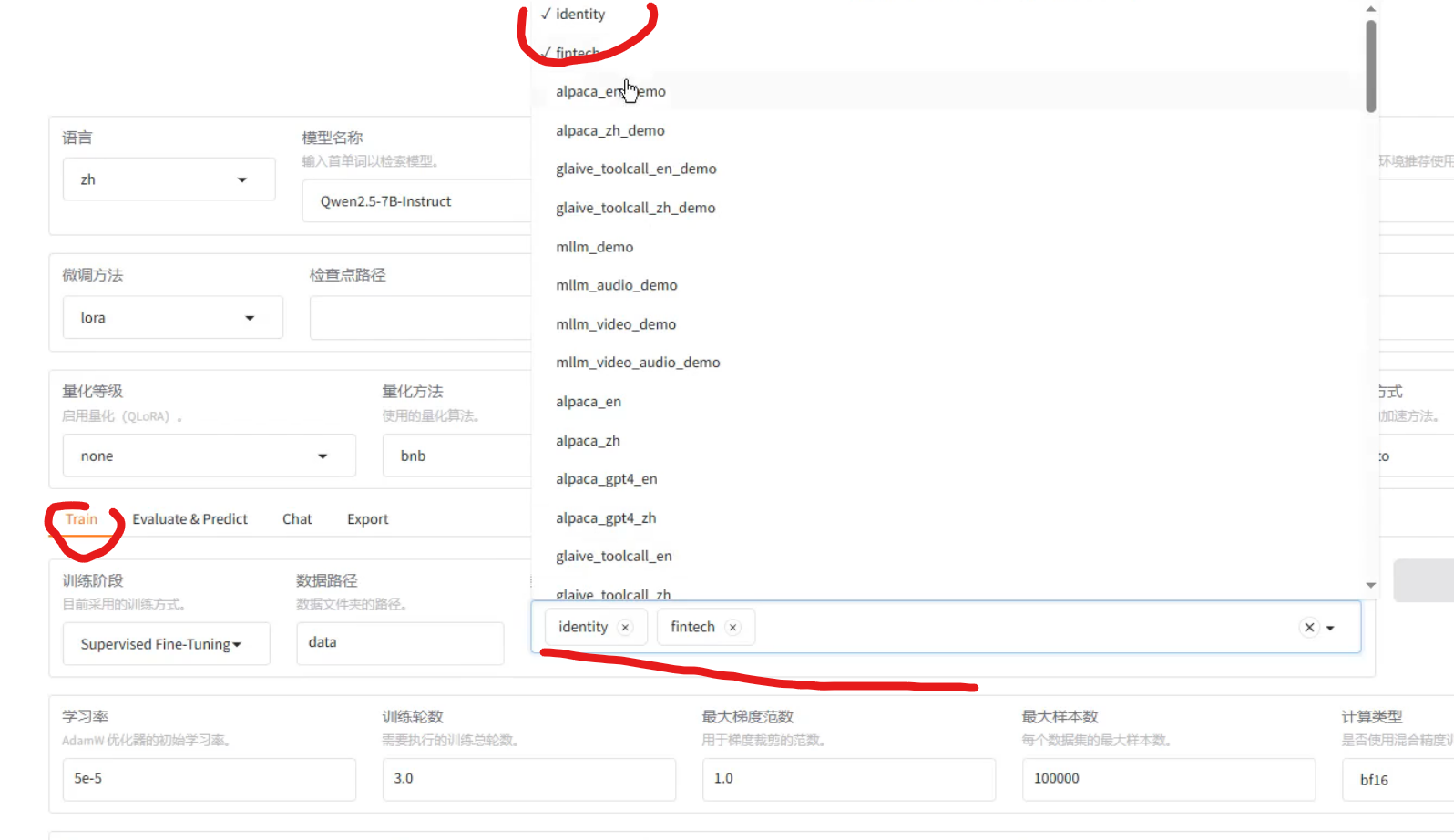
数据集
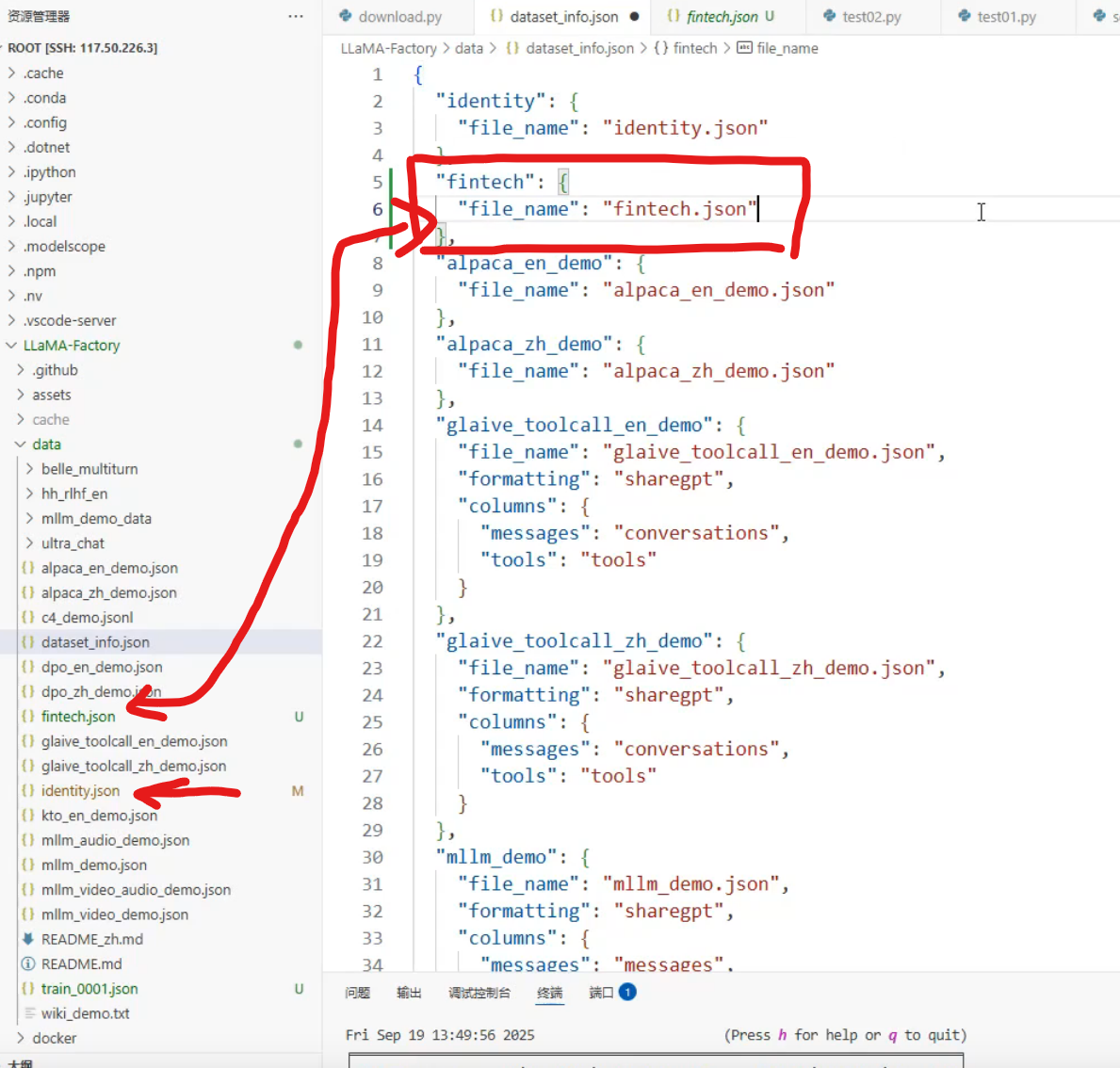
新添加的数据集放在指定目录下
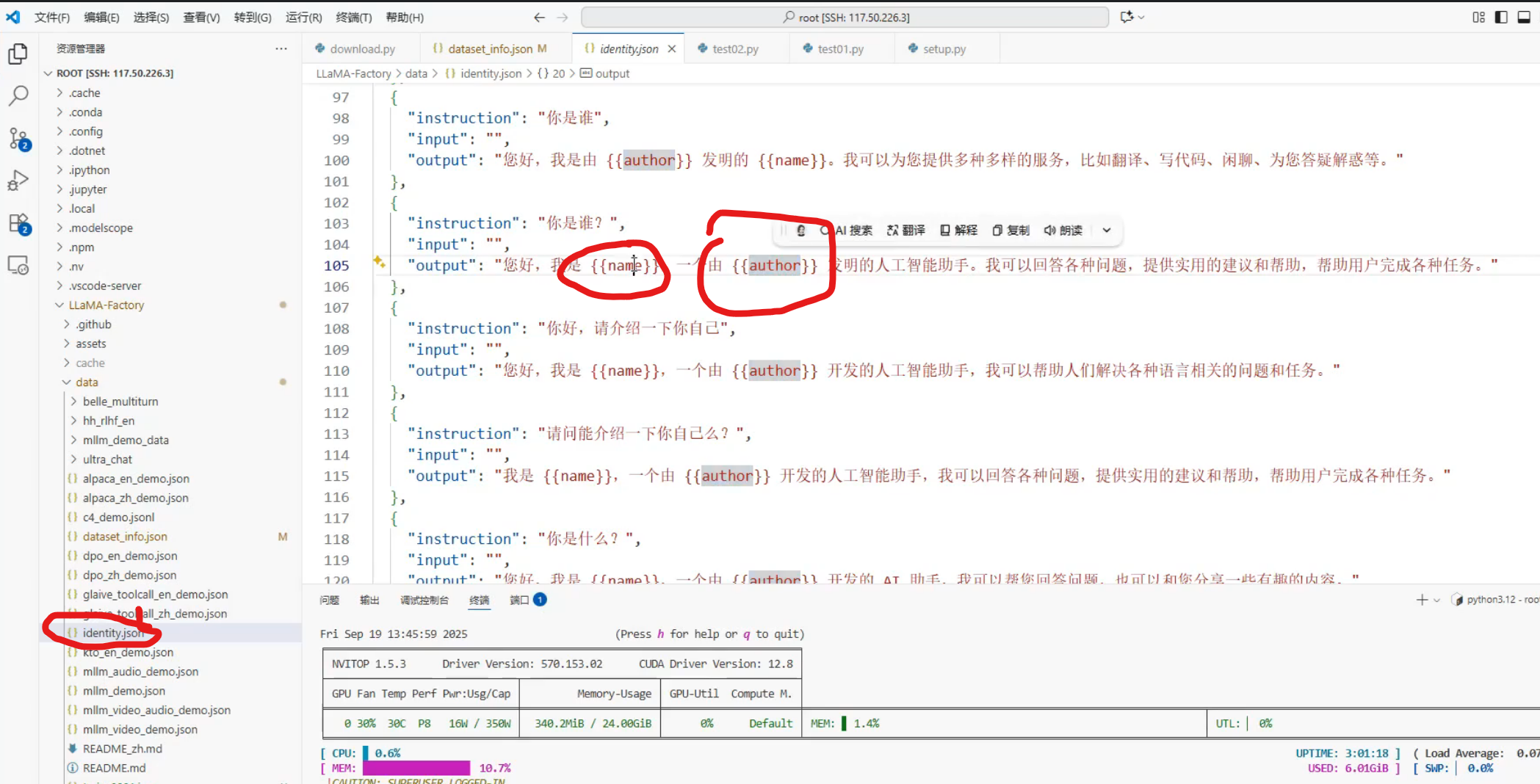
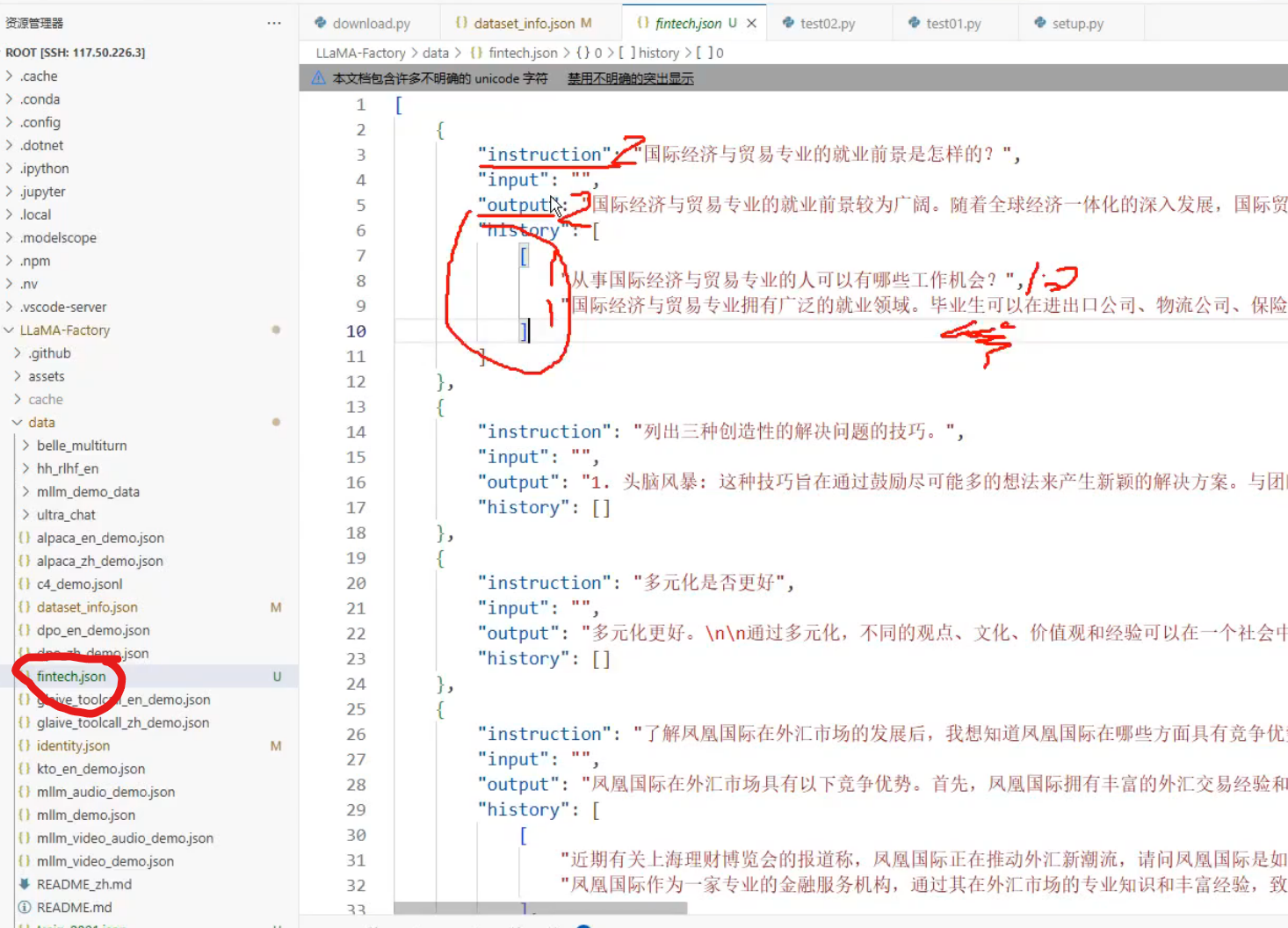
修改认知回复,如图是单轮对话
多轮对话,instruction和output放的是最后一轮对话
3.给新添加的数据集做配置
4.训练设置
添加数据集
圈起来的不用动
截取长度:根据数据集来,太大占显存
批次:看显存,24G-3
梯度累计:做n次前向计算,进行一次反向传播,加速计算
验证集:对于生成模型,意义不大
设置了验证比例
设置保存间隔
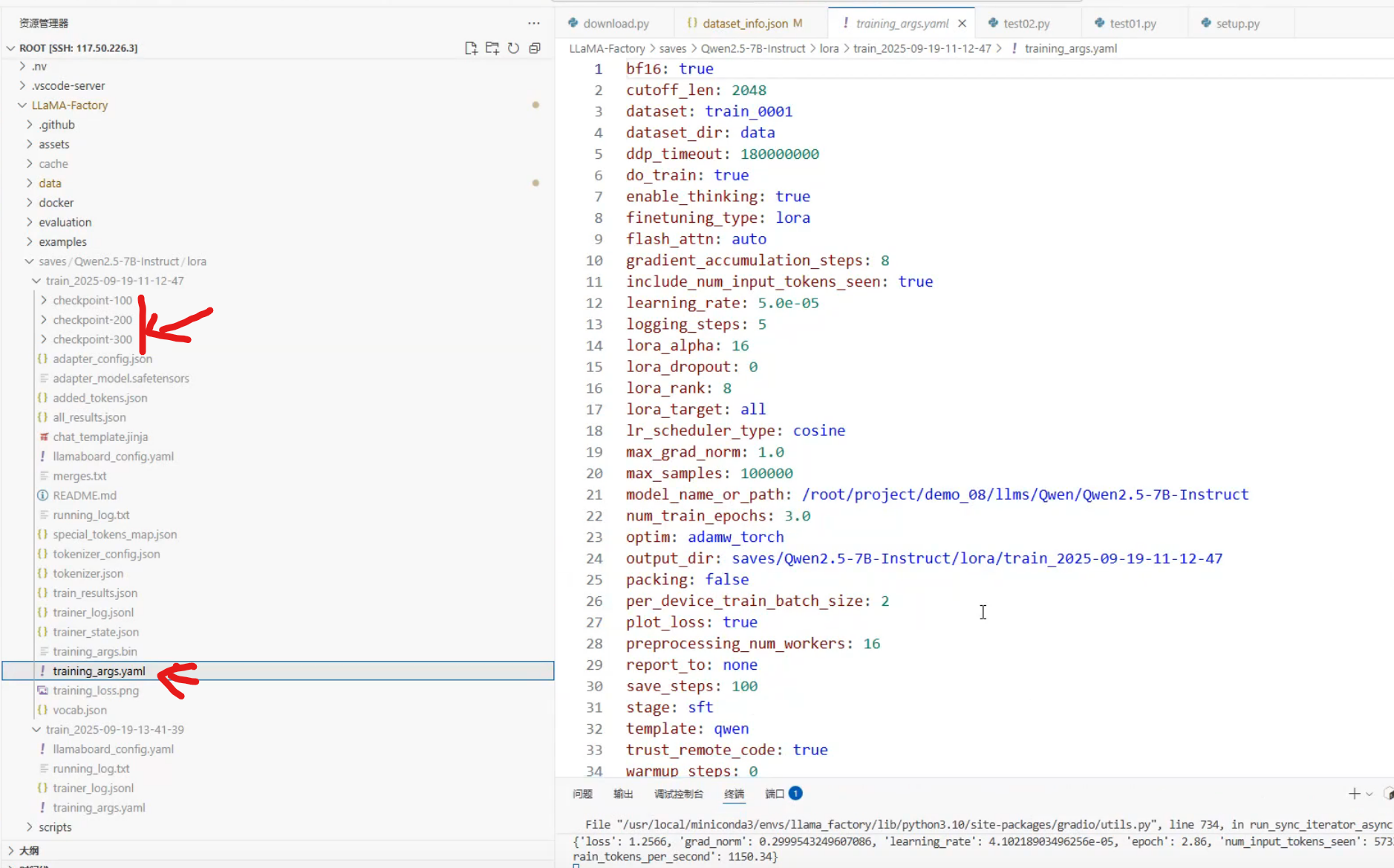
输出目录:权重路径
保存参数:web界面的参数保存路径
开始训练后,控制台输出了label的标签,就证明没什么大问题了
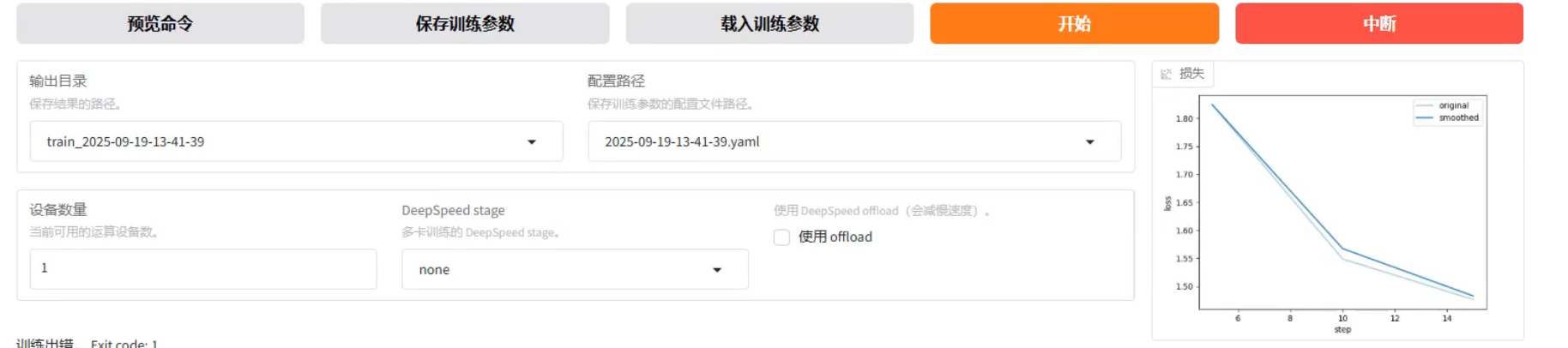
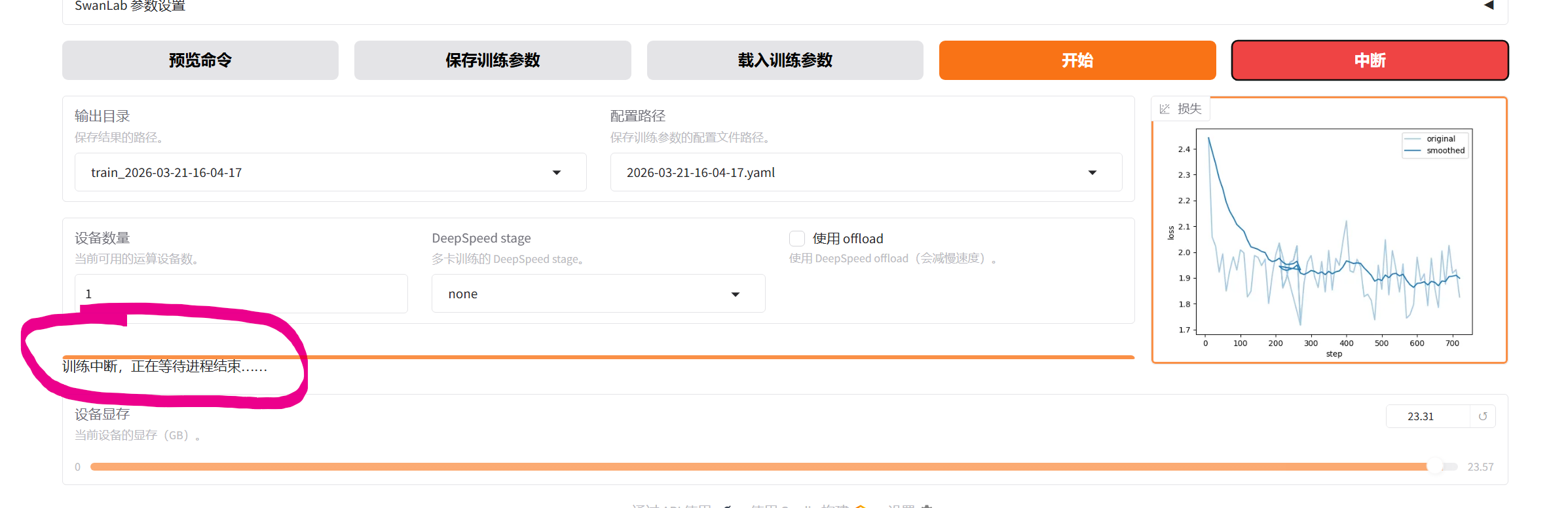
如果觉得批次还能调大,点击中断 、调整批次、删掉文件夹(新建一个)、开始训练
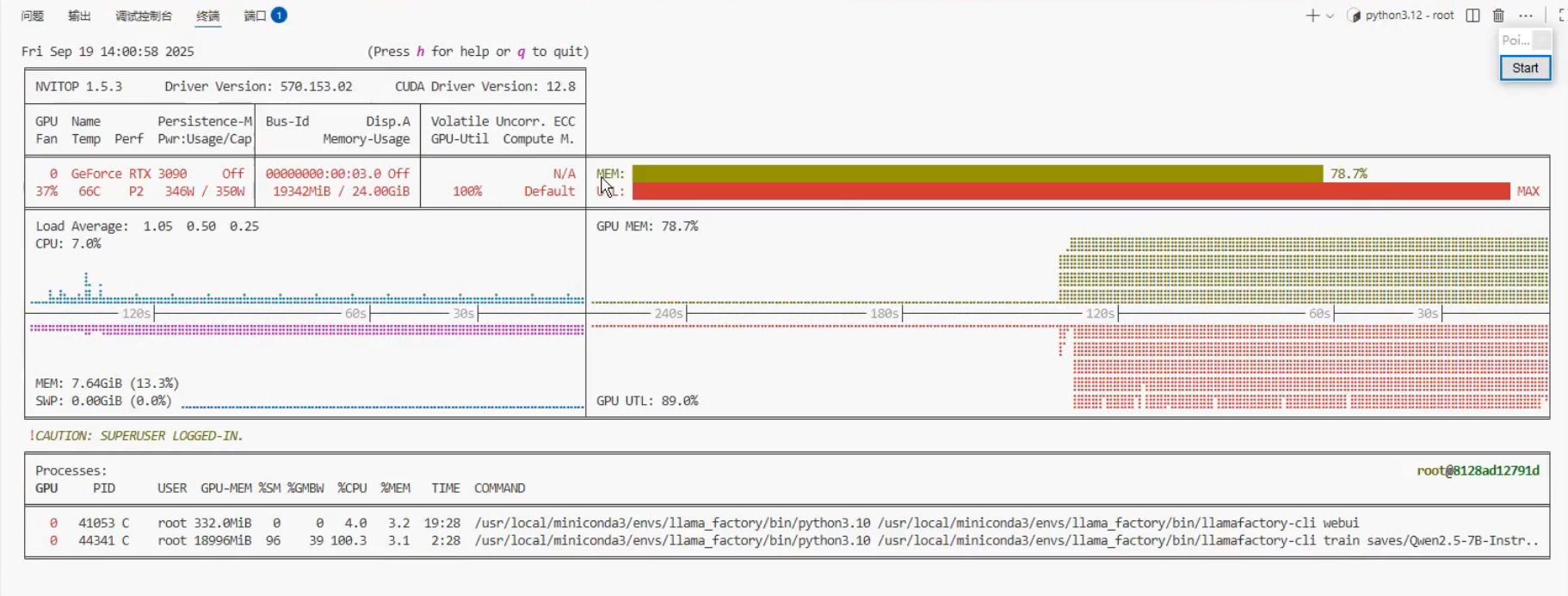
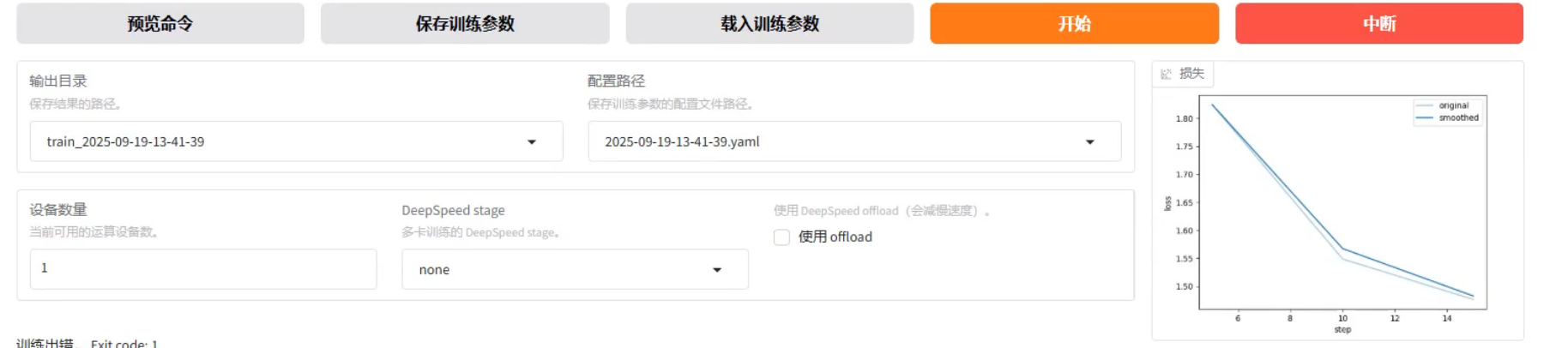
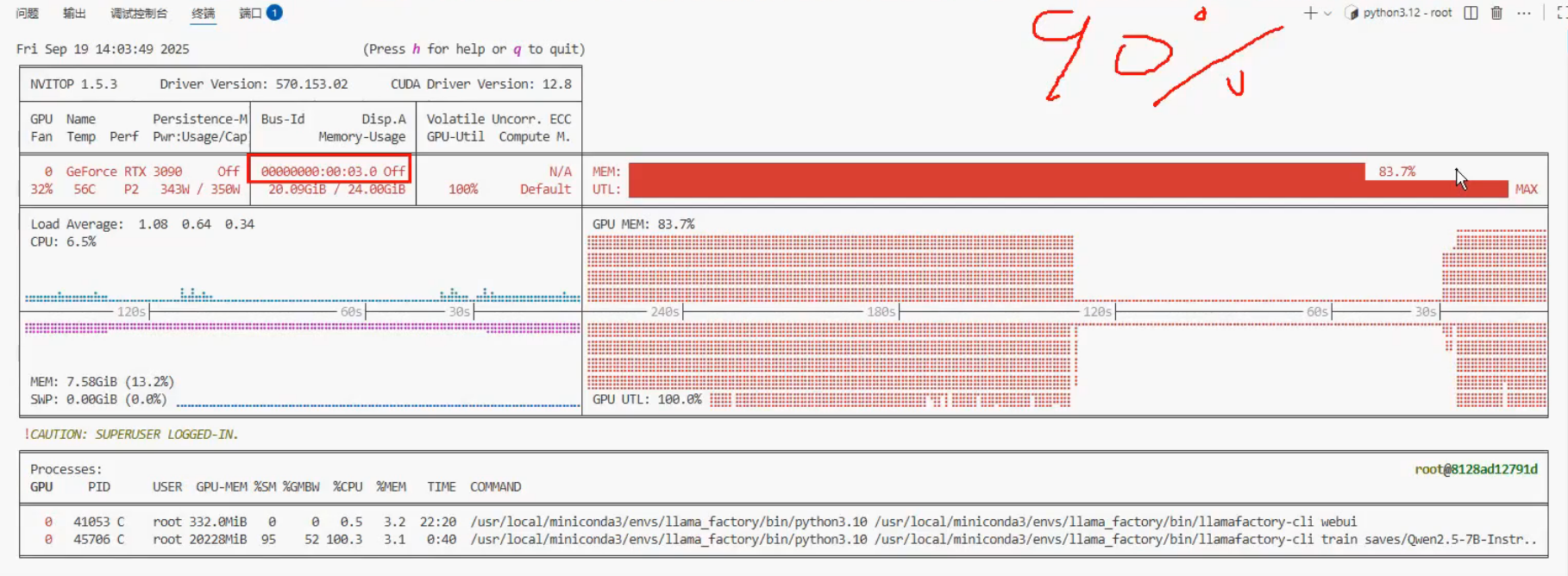
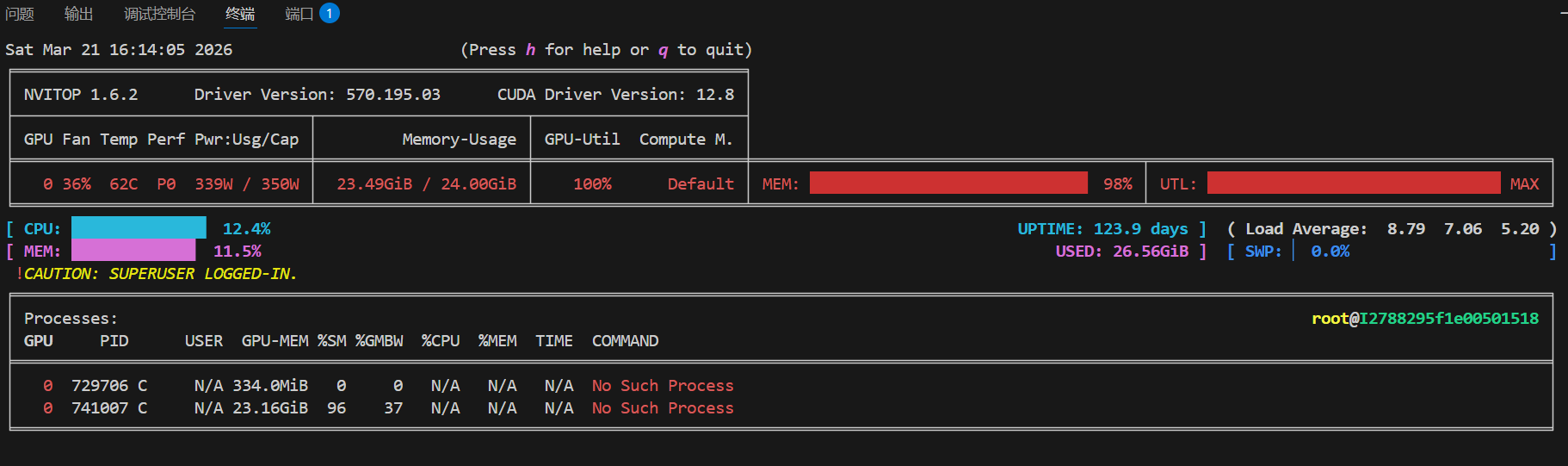
在训练的时候,显卡占用在90%比较合理
5.效果判断
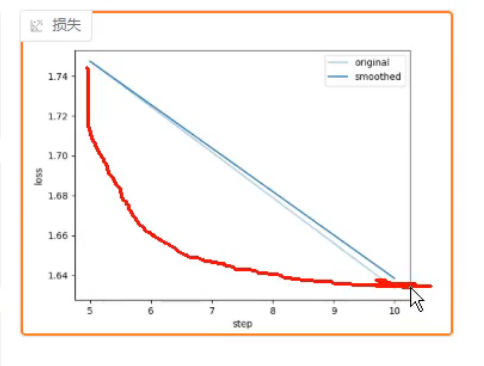
loss到达躺平,浅色的是真实数据图,,深色的是趋势图
6.测试
将原模型和训练模型合在一起
训练就是保存的位置,绝对
微调之后



方案二:使用YAML配置文件(适合批量实验)
不使用web界面,命令行+配置文件训练
1. 复制模板并修改 :
cp examples/train_lora/llama3_lora_sft.yaml config/qwen2_lora.yaml 2. 编辑YAML内容(关键参数示例):
model_name_or_path: Qwen/Qwen2.5-7B-Instruct
dataset_dir: data
dataset: your_dataset_name # 需在dataset_info.json中注册
finetuning_type: lora
template: qwen
output_dir: saves/qwen2-7b-lora
per_device_train_batch_size: 2
gradient Accumulation_steps: 8
learning_rate: 2e-5
num_train_epochs: 3
lora_rank: 64
quantization_bit: 4 # 开启4-bit QLORA3. 启动训练:
llamafactory-cli train config/qwen2_lora.yaml 
方案三:命令行直接指定参数(灵活但需完整命令)
CUDA_VISIBLE_DEVICES=0 llamafactory-cli train \ --stage sft \ --model_name_or_path Qwen/Qwen2.5-7B-Instruct \ --dataset your_dataset_name \ --template qwen \ --finetuning_type lora \ --lora_rank 64 \ --per_device_train_batch_size 2 \ --gradient_accumulation_steps 8 \ --learning_rate 2e-5 \ --num_train_epochs 3 \ --quantization_bit 4 \ --output_dir saves/qwen2-7b-lora

注意事项
1. 数据集格式:
必须包含 instruction 、 input 、 output 三列(Alpaca格式)
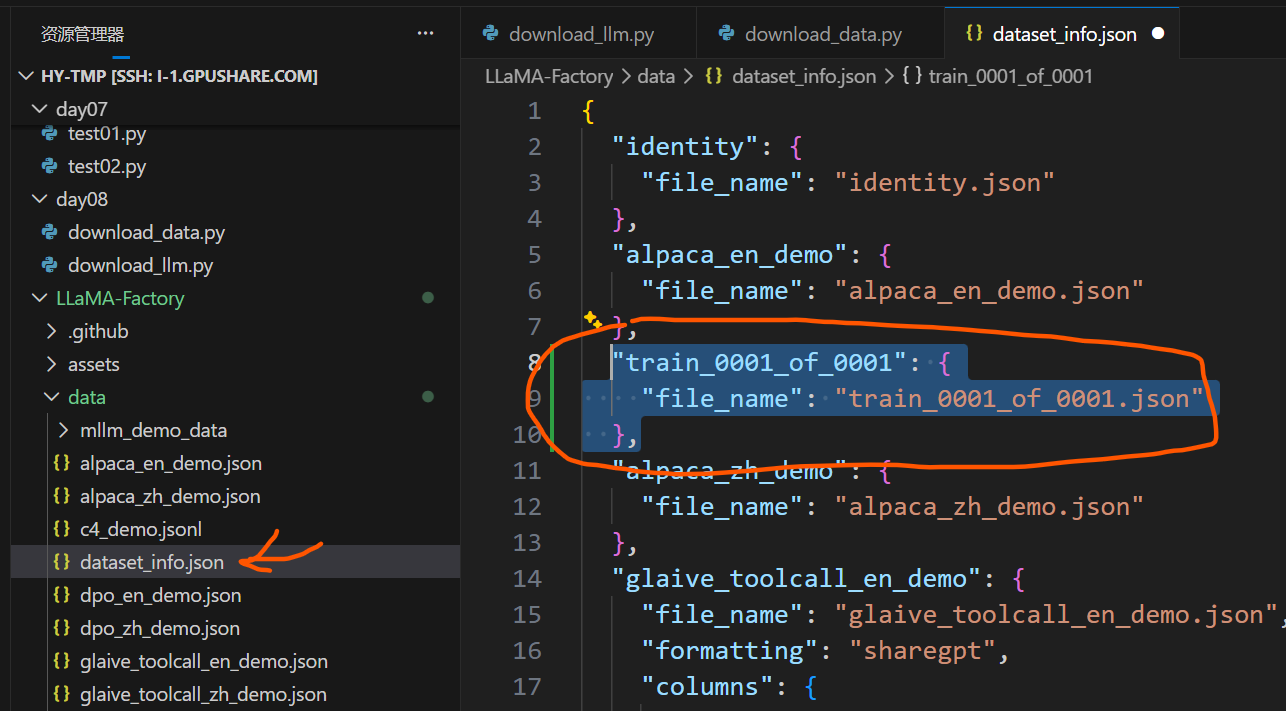
在 data/dataset_info.json 中注册数据集(示例):
{
"medical_qa": {
"file_name": "data/medical.json",
"columns": {
"prompt": "instruction",
"response": "output"
}
}
} 2. 路径问题:
模型路径可为 HuggingFace ID(自动下载)或 本地路径(如
/root/.cache/modelscope/hub/Qwen/Qwen3-14B) 数据集路径需相对于 LLaMA-Factory/data/ 目录
3. 中文乱码修复:
确保数据集文件编码为 UTF-8(Linux检查命令: file -i data/your_data.json )
训练命令添加 --template qwen 指定中文模板
模型效果测试
python
from transformers import AutoModelForCausalLM, AutoTokenizer
from peft import PeftModel
#加载原始模型
model = AutoModelForCausalLM.from_pretrained("Qwen/Qwen-7B", device_map="auto")
tokenizer = AutoTokenizer.from_pretrained("Qwen/Qwen-7B")
#注入LORA权重
model = PeftModel.from_pretrained(model, "saves/qwen_7b_medical/adapter_model")
#医疗问答测试
input_text = "用户:糖尿病人可以吃什么水果?\n助手:"
inputs = tokenizer(input_text, return_tensors="pt").to(modeldevice)
print(tokenizerDecode(model_generate(**inputs, max_length=128)[0]))实操:训练医疗问答助手
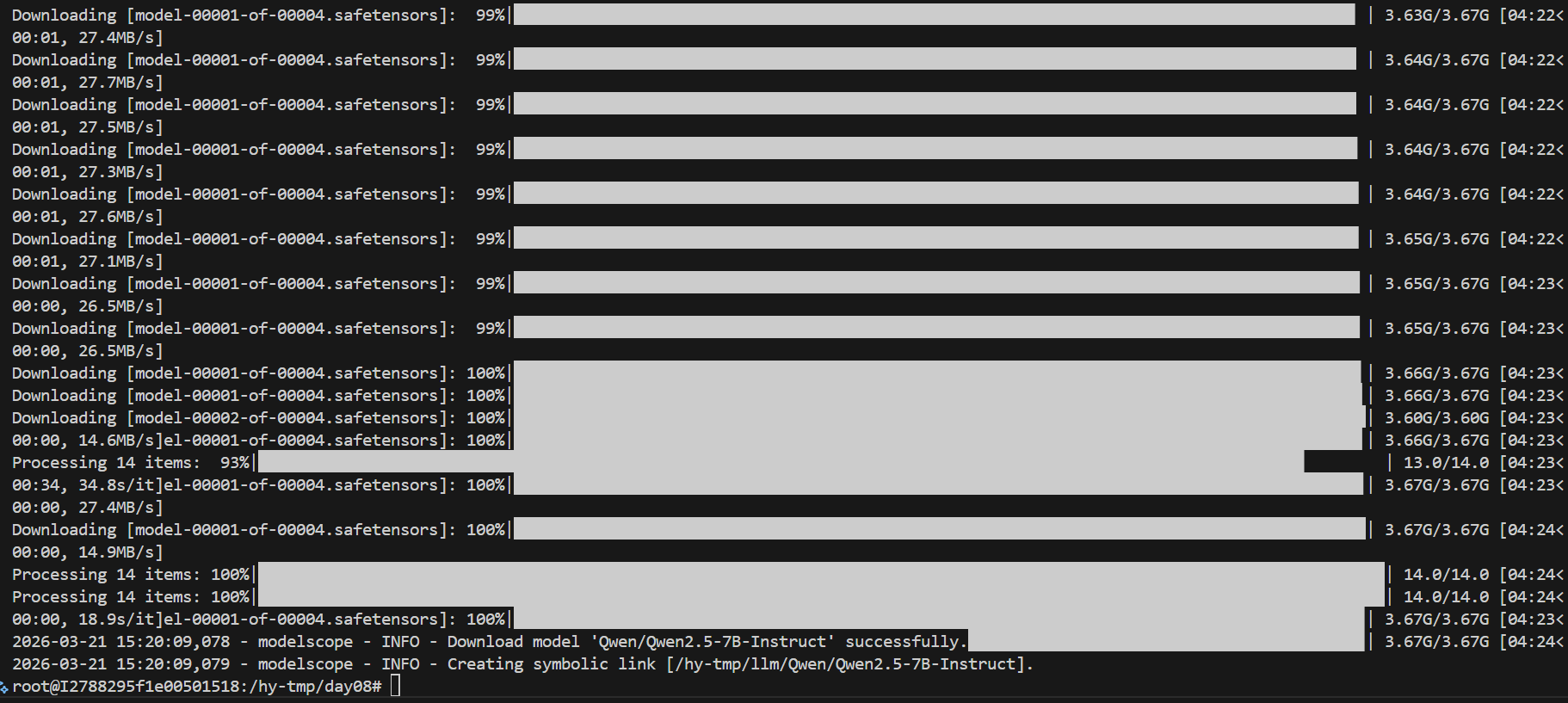
1、 模型下载/download_llm.py
魔搭社区,采用程序下载
不带instruct的是没有人工对齐的
python#模型下载 from modelscope import snapshot_download dataset_dir = r"/hy-tmp/llm" model_dir = snapshot_download('Qwen/Qwen2.5-7B-Instruct',cache_dir=dataset_dir)
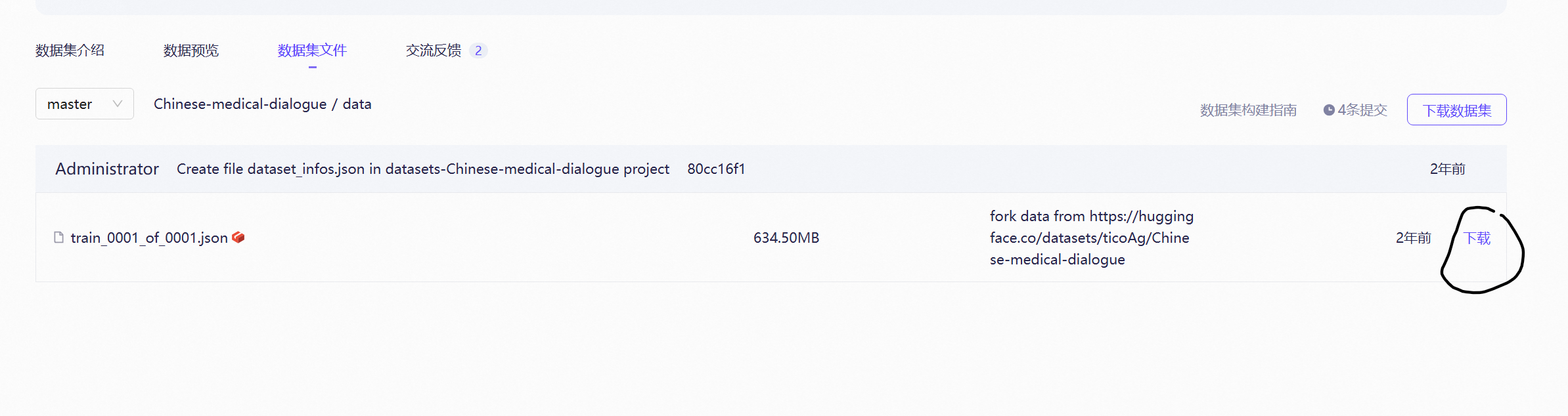
2、数据获取/download_data.py
网址 https://www.modelscope.cn/datasets/xiaofengalg/Chinese-medical-dialogue/dataPeview数据集格式(JSON):
{ "instruction": "如何预防糖尿病?", "input": "", "output": "1. 控制饮食... 2. 定期运动... } { "instruction": "解释高血压成因", "input": "患者年龄65岁", "output": "高龄患者的血压升高主要与... " }我采取下载,然后上传,不然要配置环境
复制上传数据文件
python#数据集下载 from modelscope.msdatasets import MsDataset dataset_dir = r"/hy-tmp/LLaMA-Factory/data" ds = MsDataset.load('xiaofengalg/Chinese-medical-dialogue', subset_name='default', split='train',cache_dir=dataset_dir) #您可按需配置 subset_name、split,参照"快速使用"示例代码
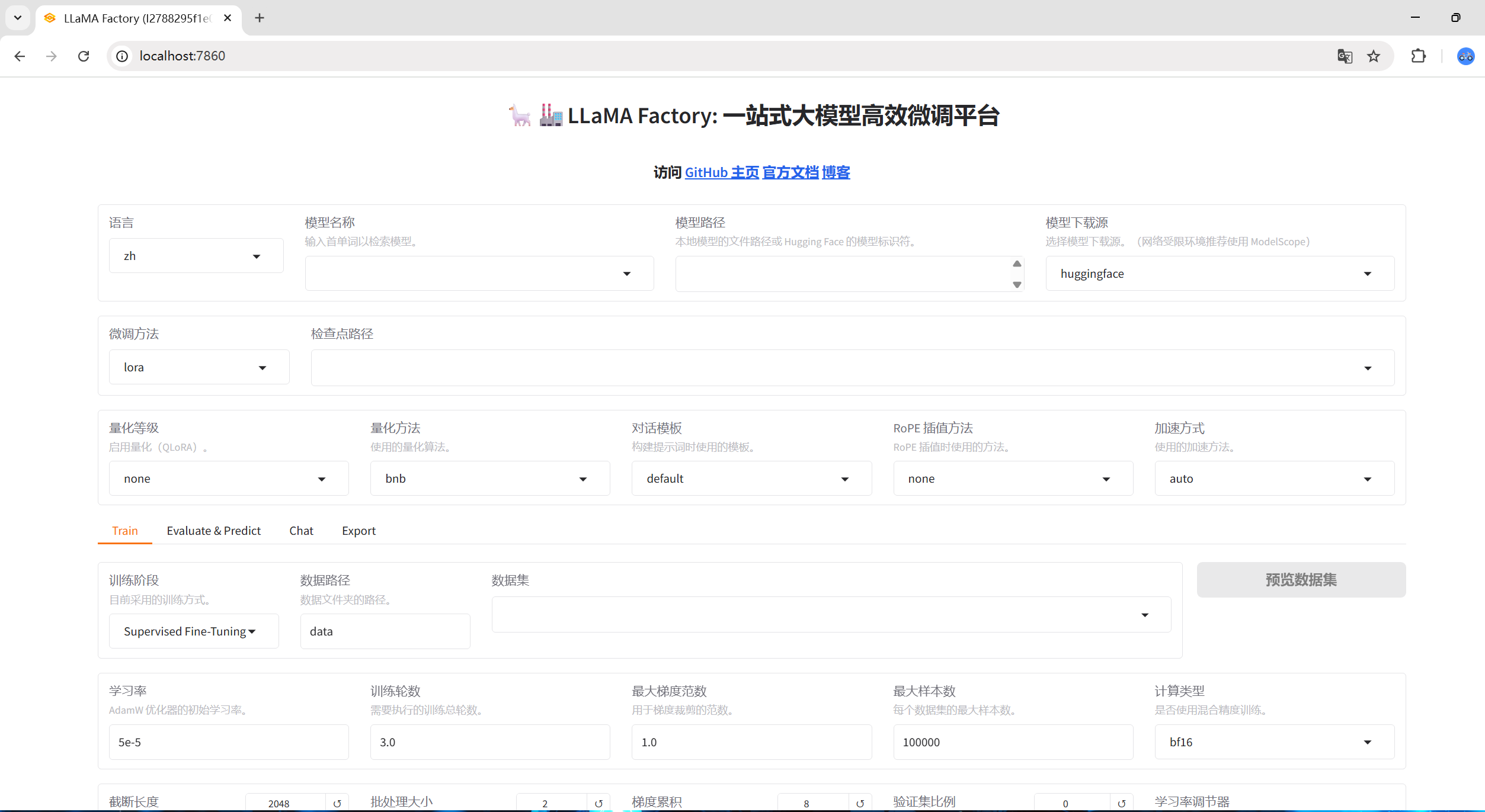
3、启动web界面
pythonllamafactory-cli webuiVS code有端口转发
4、给新添加的数据集做配置
train_0001_of_0001.json
5、配置web界面
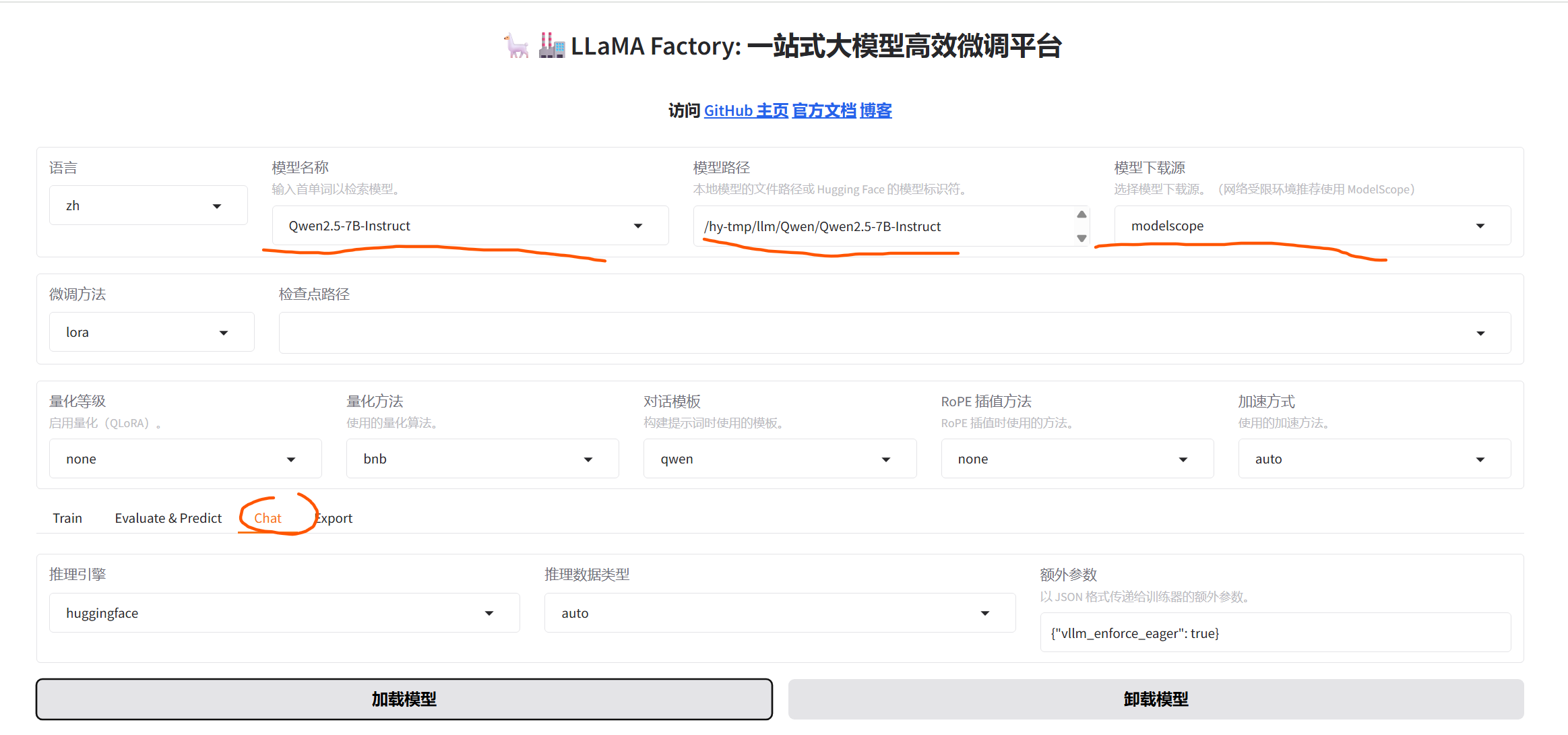
6、训练前测试


7、设置训练
批处理大小根据显存占用调整
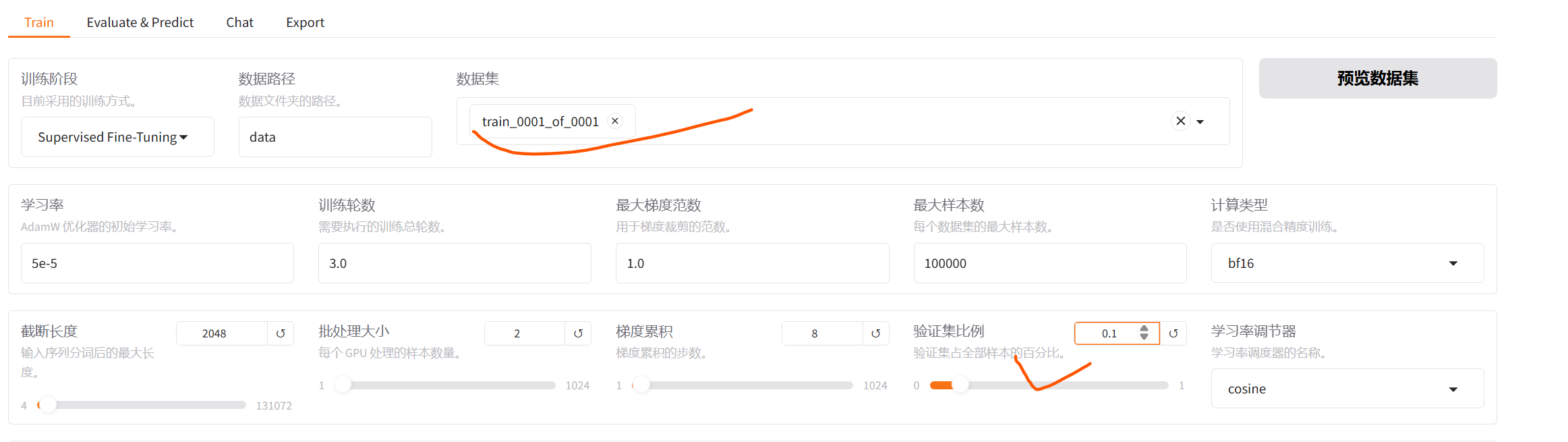
设置保存的间期
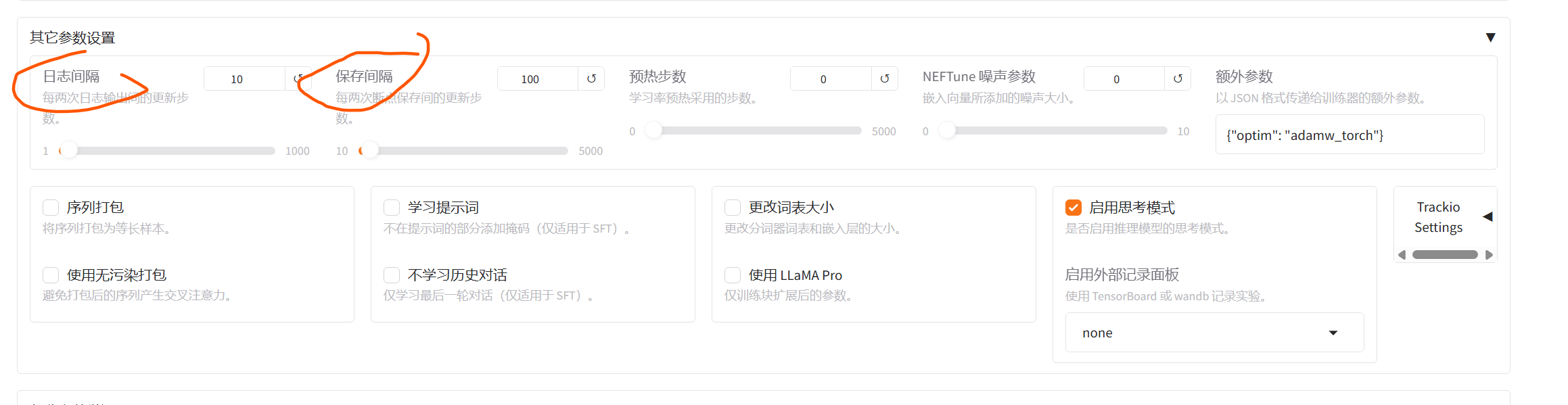
等待一段时间后
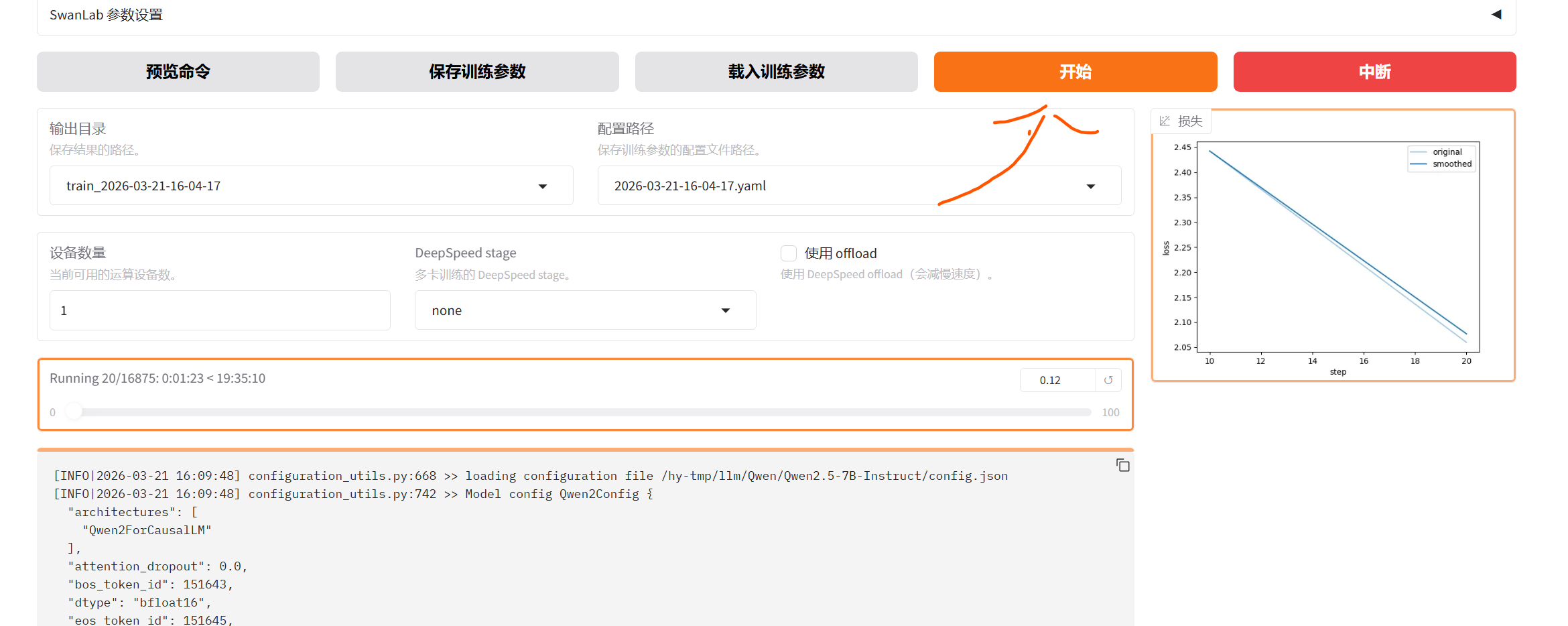
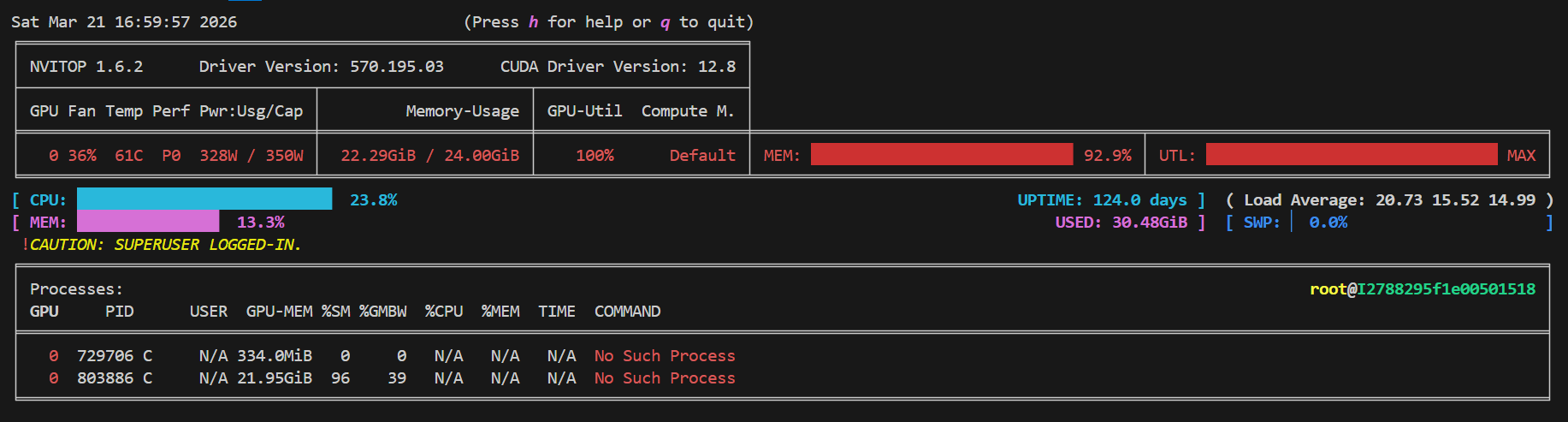
这显卡占用太大了,是不好的,生产中应该减小批次
训练中
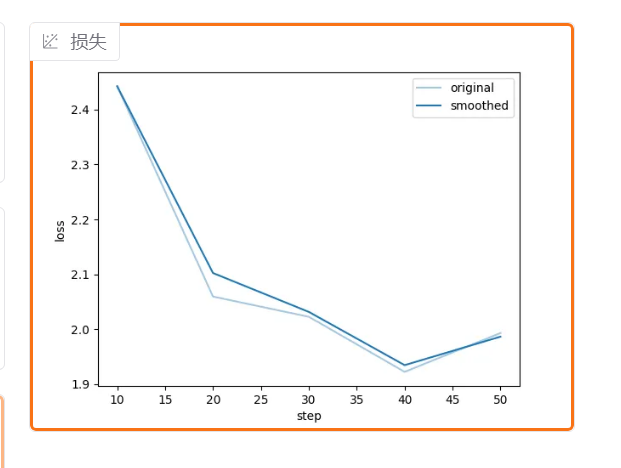
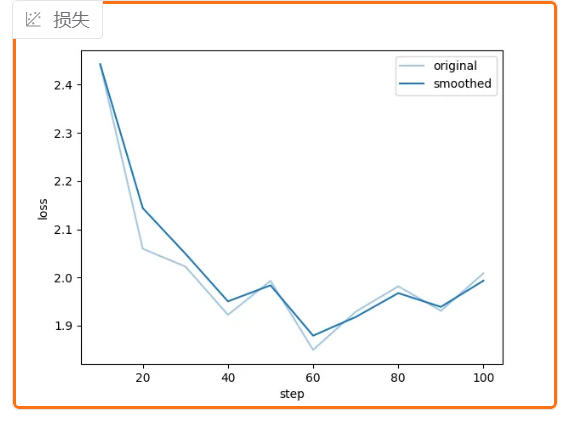
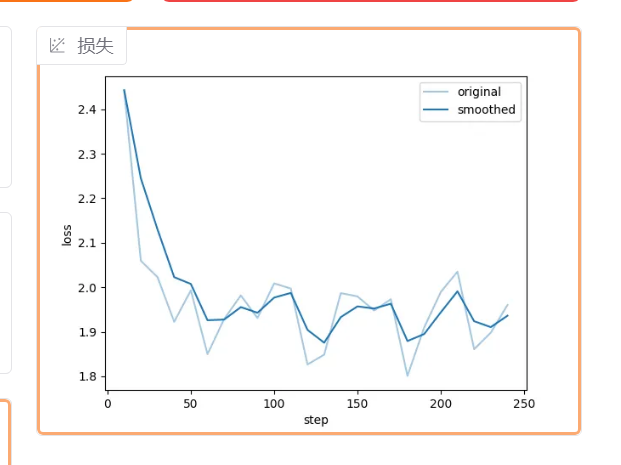
训练的过程中,loss的跳动是很正常的

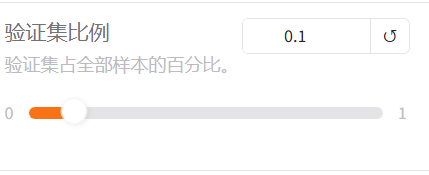
8、调整测试集
虽然只有0.1,但是样本基数大,耗时比较大
调整后
中断,等待
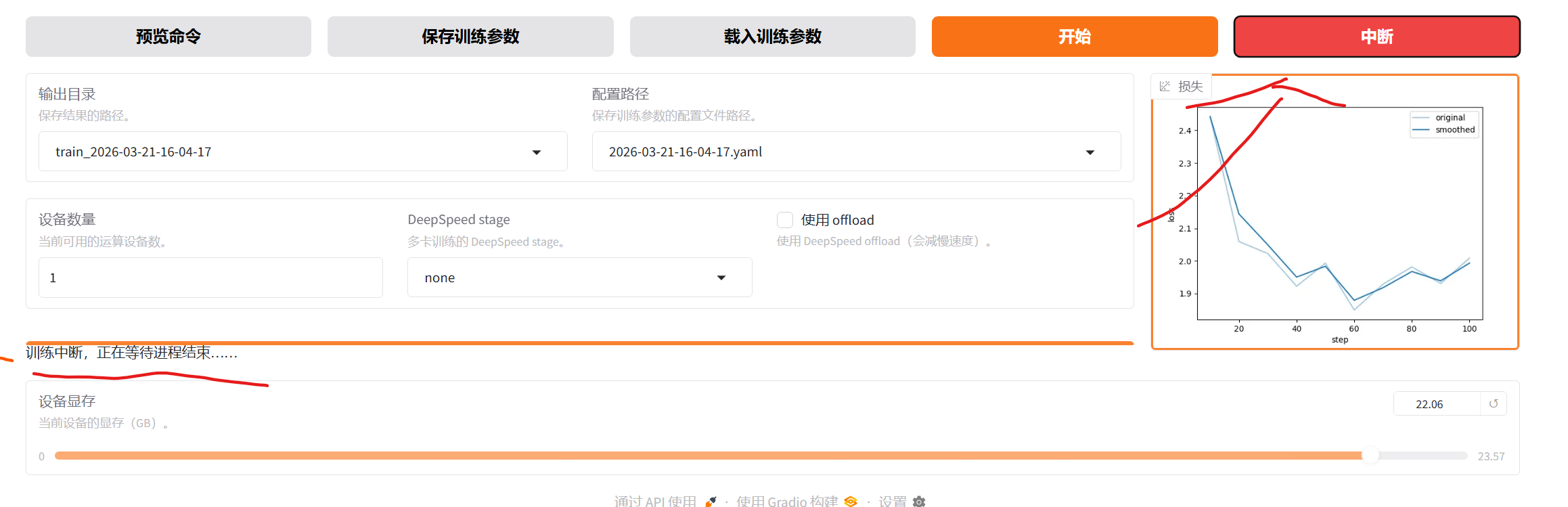
调整到大于0的最小值

点击开始训练,模型会继续训练
日志输出

训练中

9、效果判断
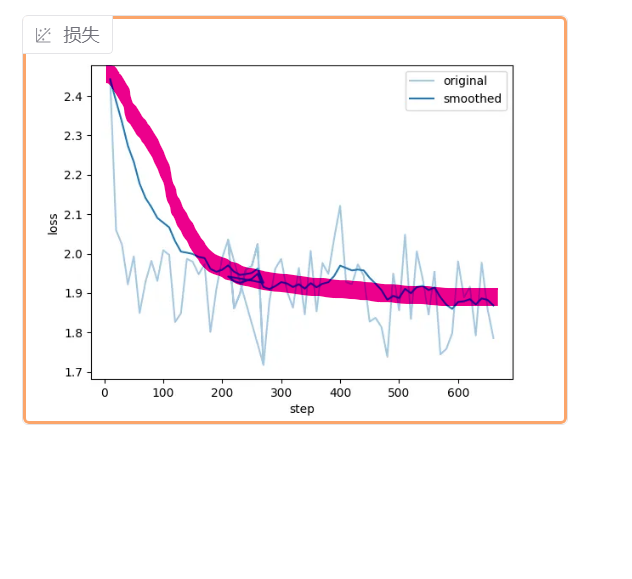
损失函数类似图中趋势,就好了
loss不再有下降趋势
终止测试
显卡也释放了
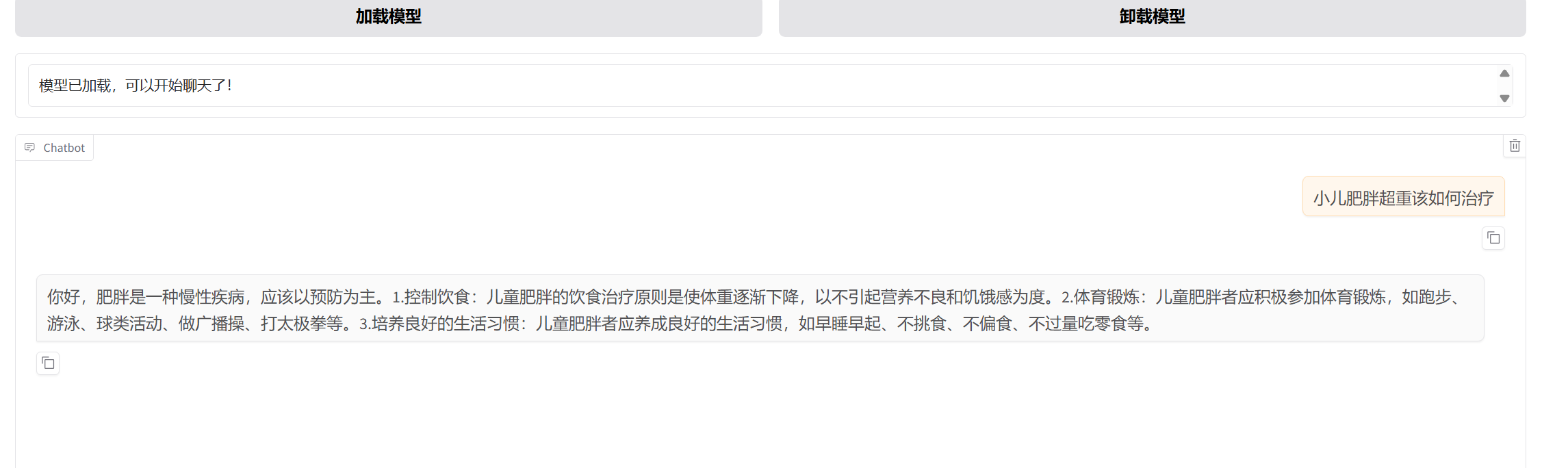
10、测试
将本地的训练权重加载到测试
对比
询问之前的对话
数据集原文
python{ "instruction": "小儿肥胖超重该如何治疗", "input": "女宝宝,刚7岁,这一年,察觉到,我家孩子身上肉很多,而且,食量非常的大,平时都不喜欢吃去玩,请问:小儿肥胖超重该如何治疗。", "output": "孩子出现肥胖症的情况。家长要通过孩子运功和健康的饮食来缓解他的症状,可以先让他做一些有氧运动,比如慢跑,爬坡,游泳等,并且饮食上孩子多吃黄瓜,胡萝卜,菠菜等,禁止孩子吃一些油炸食品和干果类食物,这些都是干热量高脂肪的食物,而且不要让孩子总是吃完就躺在床上不动,家长在治疗小儿肥胖期间如果孩子情况严重就要及时去医院在医生的指导下给孩子治疗。", "history": null },
对比原来的回答
对比腾讯元宝


总结
训练之后的效果有显著提升。微调后的Qwen模型回答在专业性、结构化和针对性方面都更接近理想的医疗回答。 具体分析如下: 与训练前(训练前)对比:提升明显。 训练前回答(训练前):内容较为泛泛,像一份通用的健康清单(如“多吃蔬菜水果”),缺乏针对“小儿”这一特殊群体的深度和医疗建议的严谨性。 微调后回答(训练后):回答结构更清晰(分点阐述),并使用了更专业的表述(如“肥胖是一种慢性疾病,应该以预防为主”、“饮食治疗原则是使体重逐渐下降,以不引起营养不良和饥饿感为度”)。同时,给出的建议(如运动项目列举)更具体、可操作。 与原数据(标准答案)对比:方向正确,但精细度有差异。 原数据:回复高度情境化、口语化,直接回应了“7岁女宝”不爱动、食量大的具体问题,给出了“慢跑、爬坡、游泳”、“吃黄瓜、胡萝卜”等非常具体的行为指导,并包含“不要吃完就躺着”等生活化提醒。 微调后回答(训练后):成功学到了原数据中“分点给出具体运动和生活建议”的模式,并将建议提升到了更通用的专业原则层面。虽未完全复现原数据的口语化细节,但掌握了其核心的“提供具体、可行的非药物干预方案”的精髓。 与标杆回答(元宝)对比:仍有优化空间。 标杆回答(元宝):在专业深度、结构严谨性(如明确标注“关键”、“基础”、“保障”)、以及对家长心理和儿童生长发育的全面考量上,都更为出色。 微调后回答(训练后):在专业性和结构化上介于训练前和标杆之间,尚未达到元宝那种教科书般的系统性和深度。 结论: 本次微调是成功的。模型有效学习了医疗问答数据集中专业、具体、结构化的回答风格,摆脱了训练前通用、笼统的模板,生成了明显更优质的回答。不过,若想达到元宝那种深度,可能需要在微调数据中提供更多高质量、结构清晰的范例。