第1章:为什么需要CHI?------现代多核系统的挑战
1.1 从单核到多核:处理器演进的必然趋势
1.1.1 单核时代的终结
让我们从一个简单的比喻开始:想象一下早期的计算机处理器就像一个单人厨房。厨师(CPU核心)需要完成所有工作------切菜、炒菜、摆盘。为了提高效率,厨师会在手边放几个小碗(缓存),存放常用的食材(数据)。这个系统简单直接,但有一个根本问题:无论厨师多快,一次只能做一道菜。
随着时间推移,人们对"上菜速度"(计算性能)的要求越来越高。单纯让厨师动作更快(提高时钟频率)遇到了物理极限:就像人类跑步有极限一样,晶体管开关速度也有极限。更糟糕的是,厨师越快,厨房(芯片)温度越高,能耗越大。
1.1.2 多核时代的开启
解决方案很直观:增加厨师数量 。于是我们有了双核、四核、八核甚至更多核心的处理器。这就像把单人厨房改造成专业餐厅的后厨,有专门负责切配的厨师、专门负责炒菜的厨师、专门负责摆盘的厨师。
但新的问题立即出现:
- 协调问题:多个厨师如何协同工作?
- 资源竞争:如果两个厨师都需要同一把刀(内存数据)怎么办?
- 效率问题:如何确保所有厨师都不闲着?
1.1.3 多核系统的真实挑战
在实际的计算机系统中,这些"厨师协调问题"表现为:
示例1:数据共享问题
假设我们有一个双核处理器,运行一个简单的程序:
// 共享变量
int counter = 0;
// 核心1执行
void core1_task() {
counter = counter + 1;
}
// 核心2执行
void core2_task() {
counter = counter + 1;
}如果两个核心同时执行这段代码,理想情况下counter应该从0变为2。但在没有协调机制的情况下,可能发生:
- 核心1读取counter(值=0)到自己的缓存
- 核心2也读取counter(值=0)到自己的缓存
- 核心1计算0+1=1,写回counter
- 核心2计算0+1=1,写回counter
- 最终结果:counter=1,而不是2
这就是著名的缓存一致性问题。
1.1.4 从同构到异构多核
现代处理器不仅核心数量增加,核心类型也多样化:
- 大核心:高性能,高功耗,用于复杂计算
- 小核心:高能效,用于后台任务
- GPU核心:并行计算,用于图形和AI
- 专用加速器:特定任务优化,如视频编解码
这种异构多核系统就像后厨不仅有厨师,还有糕点师、调酒师、洗碗工等不同专业人员。协调他们需要更复杂的机制。
1.2 缓存一致性问题:多核系统的"通信难题"
1.2.1 缓存层级结构
现代处理器采用多级缓存架构,通常分为:
- L1缓存:每个核心独享,速度最快,容量最小(几十KB)
- L2缓存:可能共享或部分共享,速度中等,容量中等(几百KB到几MB)
- L3缓存(最后一级缓存LLC):所有核心共享,速度较慢,容量最大(几MB到几十MB)
- 主内存(DRAM):速度最慢,容量最大(几GB到几TB)
这就像:
- L1缓存:厨师手边的调料架(最常用,最快拿到)
- L2缓存:厨房的中央调料台(共享,稍远)
- L3缓存:餐厅的储藏室(更大,需要走几步)
- 主内存:外部供应商仓库(最慢,需要开车去取)
1.2.2 一致性问题的本质
缓存一致性问题的核心是:如何确保所有核心看到的数据视图是一致的?
示例2:缓存不一致的场景
假设一个四核系统,共享变量data = 10存储在内存中:
时间线:
t0: 核心1读取data → 缓存中data=10
t1: 核心2读取data → 缓存中data=10
t2: 核心1修改data=20 → 只更新了自己的缓存
t3: 核心2读取data → 从自己缓存读到旧值10!
t4: 核心3读取data → 从内存读到旧值10!结果:三个核心看到三个不同的data值(20, 10, 10),系统状态混乱。
1.2.3 一致性协议的基本要求
任何缓存一致性协议必须满足四个基本条件(MSI协议基础):
- 单写者多读者:同一时刻,要么只有一个核心能写入,要么多个核心只能读取
- 数据最终传播:写入最终必须传播到所有副本
- 写入序列化:所有核心看到的写入顺序必须一致
- 写入原子性:写入要么完全生效,要么完全不生效
1.2.4 传统解决方案的局限性
在CHI之前,Arm系统主要使用:
- 软件管理一致性:由操作系统或应用程序显式管理,效率低
- 基于总线的侦听协议:所有核心监听总线上的所有事务,扩展性差
- 基于目录的协议:维护共享状态目录,复杂度高
随着核心数量增加(从几个到几十个、上百个),这些方案都遇到了瓶颈。
1.3 AMBA总线家族演进史:从AHB到CHI
1.3.1 AMBA的诞生:AHB时代
AMBA(Advanced Microcontroller Bus Architecture) 是Arm于1996年推出的片上总线标准。第一代AHB(Advanced High-performance Bus) 的设计目标是:
- 简单高效:支持流水线操作
- 主从架构:明确的主设备发起,从设备响应
- 基础功能:支持突发传输、分割事务
AHB示例:读取内存
主设备(CPU) 从设备(内存控制器)
|---地址/控制--->|
|<-----数据------|AHB就像单车道公路,一次只能有一辆车(事务)通行。对于单核系统足够,但多核系统就像多辆车要同时使用单车道,必然拥堵。
1.3.2 演进到AXI:多通道并行
2003年推出的AXI(Advanced eXtensible Interface) 解决了AHB的关键限制:
AXI的核心改进:
- 分离的通道:读地址、读数据、写地址、写数据、写响应五个独立通道
- 乱序完成:事务可以乱序完成,提高效率
- 多未完成事务:支持多个并发事务
AXI示例:并行读写
读通道: 地址1 ---> | 地址2 ---> | 地址3 --->
<---数据1 | <---数据3 | <---数据2 (乱序返回!)
写通道: 地址A ---> 数据A ---> | 地址B ---> 数据B --->AXI就像多车道高速公路 ,不同方向的车道独立,车辆可以超车。但AXI本身不支持缓存一致性,多核系统需要额外机制。
1.3.3 ACE的引入:一致性扩展
2011年的ACE(AXI Coherency Extensions) 在AXI基础上增加了缓存一致性支持:
ACE的关键特性:
- 侦听通道:增加侦听地址、侦听数据、侦听响应通道
- 一致性事务:定义一致性读/写操作
- 共享缓存状态:支持多个缓存共享数据
ACE示例:一致性读取
CPU1读数据X:
1. CPU1发送ReadShared请求
2. 互连向所有其他CPU发送侦听(Snoop)
3. 其他CPU响应缓存状态
4. 互连决定数据来源(内存或其他CPU缓存)
5. 数据返回给CPU1但ACE存在限制:
- 扩展性差:侦听广播方式,核心越多开销越大
- 拓扑不灵活:基于总线或交叉开关,不适合大规模系统
- 效率问题:某些场景下数据路径不最优
1.3.4 CHI的诞生:面向未来的设计
2013年左右推出的CHI(Coherent Hub Interface) 是专门为大规模多核系统设计的:
CHI相对于ACE的革命性改进:
- 包化通信:所有消息打包成标准格式
- 分层架构:协议层、网络层、链路层清晰分离
- 拓扑灵活:支持环形、网状等多种拓扑
- 中心协调:Home Node统一协调一致性操作
1.4 CHI的定位:AXI/ACE的下一代演进
1.4.1 CHI不是简单的"ACE v2"
理解CHI的关键是认识到它不仅仅是ACE的升级版,而是设计理念的根本转变:
| 特性 | ACE(旧理念) | CHI(新理念) |
|---|---|---|
| 通信模型 | 基于通道的信号交换 | 基于包的报文交换 |
| 扩展性 | 有限扩展(~10核心) | 大规模扩展(100+核心) |
| 拓扑限制 | 总线/交叉开关为主 | 任意拓扑(环、网等) |
| 一致性点 | 分布式 | 集中式(Home Node) |
| 数据路径 | 固定路径 | 优化路径(DMT/DCT) |
1.4.2 CHI的核心设计哲学
哲学1:集中协调,分布式执行
- Home Node作为"交通指挥中心",知道全局状态
- 实际数据传输可以绕过中心,直接点对点(DMT/DCT)
- 就像快递系统:调度中心知道所有包裹位置,但包裹可以直接从仓库发到客户
哲学2:协议与传输分离
- 协议层只关心"做什么"(读/写/一致性操作)
- 网络层关心"怎么路由"(哪个路径最优)
- 链路层关心"怎么传输"(可靠交付)
- 这种分离让每层可以独立优化
哲学3:提示而非命令
- 许多CHI特性(如Cache Stashing、PrefetchTgt)是提示
- 接收方可以选择忽略提示而不违反协议
- 这提供了灵活性:系统可以根据当前负载动态调整
1.4.3 实际对比:ACE vs CHI处理相同场景
场景:四核系统,核心1读取数据,核心2拥有脏副本
ACE处理方式:
1. 核心1:ReadShared请求 → 互连
2. 互连:广播侦听到核心2、3、4
3. 核心2:发现自己是脏副本 → 准备数据
4. 核心2:数据 → 互连 → 核心1
5. 核心2:脏数据 → 互连 → 内存(写回)数据路径:核心2 → 互连 → 核心1(绕路)
CHI处理方式(使用DCT):
1. 核心1:ReadShared请求 → Home Node
2. Home Node:查目录 → 发现核心2有脏副本
3. Home Node:向核心2发送侦听,附带"直接转发给核心1"指令
4. 核心2:数据直接 → 核心1(绕过Home Node!)
5. 核心2:完成响应 → Home Node数据路径:核心2 → 核心1(直接路径)
CHI减少了数据跳数,降低了延迟和互连带宽压力。
1.5 CHI的应用场景:移动、网络、汽车、数据中心
1.5.1 移动设备:能效优先
挑战:
- 严格的功耗预算(电池供电)
- 热限制(设备会发热)
- 动态工作负载(待机、浏览、游戏模式切换)
CHI如何帮助:
- 细粒度电源管理:CHI支持时钟门控、电源门控
- 智能数据放置:Cache Stashing将数据提前放到常用核心附近
- QoS控制:确保关键任务(如触控响应)优先获得资源
示例:智能手机拍照
拍照流程:
1. 传感器数据 → ISP(图像信号处理器)
2. ISP处理 → 通过CHI暂存到CPU缓存
3. CPU进行AI美化 → 结果暂存到GPU缓存
4. GPU叠加特效 → 显示输出
CHI优化:数据在每个处理环节前已预取到对应加速器附近缓存,
减少内存访问,降低延迟和功耗。1.5.2 网络设备:带宽与确定性
挑战:
- 高带宽需求(100Gbps+)
- 确定性延迟(数据包必须在时限内处理)
- 复杂流量管理(优先级、拥塞控制)
CHI如何帮助:
- 高带宽支持:宽数据总线、多通道
- QoS保证:端到端服务质量
- 原子操作:实现无锁数据结构,高效处理数据包
示例:路由器数据包转发
数据包处理:
1. 网口接收数据包 → 解析头部
2. 查路由表(可能被多个核心同时访问)
3. 修改统计计数器(需要原子操作)
4. 转发到输出队列
CHI的原子操作确保路由表访问和计数器更新的原子性,
避免锁的开销,提高吞吐量。1.5.3 汽车电子:安全与可靠
挑战:
- 功能安全要求(ISO 26262 ASIL-D)
- 实时性要求(刹车、转向必须及时响应)
- 混合临界性系统(娱乐与安全控制共存)
CHI如何帮助:
- 错误检测与恢复:Data Poisoning、ECC支持
- 时间确定性:QoS和优先级保证关键任务
- 隔离机制:TrustZone、RME支持安全隔离
示例:自动驾驶感知融合
传感器融合:
摄像头 → 物体检测 → 结果
雷达 → 距离测量 → 结果
激光雷达 → 3D建模 → 结果
↓
融合算法(需要所有传感器数据)
↓
决策系统
CHI确保传感器数据在共享缓存中一致可见,
RME确保安全关键代码和数据被隔离保护。1.5.4 数据中心:可扩展与高效
挑战:
- 大规模扩展(数百核心)
- 资源虚拟化(多租户共享)
- 能效要求(降低运营成本)
CHI如何帮助:
- 大规模扩展:网状拓扑支持数百核心
- 虚拟化支持:VMID、LPID支持多虚拟机
- 能效优化:高级电源管理、智能数据放置
示例:云服务器虚拟机调度
多虚拟机运行:
VM1(Web服务器)--\
VM2(数据库) ---> 共享物理CPU
VM3(AI推理)--/
CHI通过VMID区分不同虚拟机的数据,
通过LPID区分不同进程的数据,
确保隔离同时允许智能共享(如相似VM可共享缓存数据)。1.5.5 跨场景的统一价值
无论应用场景如何不同,CHI提供的核心价值是一致的:
- 性能可扩展:核心数增加时,性能线性增长而非下降
- 能效优化:减少不必要的数据移动和内存访问
- 设计简化:清晰的分层和接口,降低系统集成复杂度
- 未来就绪:支持新特性(如MTE、RME)无需重新设计
本章小结
CHI的出现不是偶然,而是处理器架构发展的必然结果。从单核到多核,从同构到异构,从固定功能到灵活可编程,处理器的每一次演进都对其互连系统提出新的要求。
关键要点回顾:
- 多核系统需要缓存一致性,否则会出现数据不一致问题
- 传统总线协议(AHB/AXI) 缺乏一致性支持
- ACE提供了基础一致性,但扩展性和效率有限
- CHI是面向未来的设计:包化、分层、中心协调、直接传输
- CHI适用于广泛场景:从手机到数据中心,核心价值一致
在接下来的章节中,我们将深入CHI的每一个细节。但无论技术细节多么复杂,始终记住CHI的根本目标:让多核系统中的所有核心能够像单个核心一样高效、一致地工作,同时支持大规模扩展和能效优化。
思考题:
- 如果你的手机有8个CPU核心,它们如何协同处理你同时听音乐、浏览网页、接收消息?
- 为什么数据中心服务器需要比手机更复杂的缓存一致性机制?
- CHI的"提示而非命令"设计哲学在实际系统中有什么优缺点?
第2章:CHI架构全景图
2.1 三层架构模型:协议层、网络层、链路层
2.1.1 为什么需要分层?
让我们从一个现实世界的比喻开始:国际快递系统。
想象你要从北京寄一个包裹到纽约:
- 协议层 :你填写快递单(收件人、物品、价值)------定义要做什么
- 网络层 :快递公司规划路线(北京→上海→东京→洛杉矶→纽约)------定义怎么走
- 链路层 :实际运输(卡车、飞机、货车)------定义怎么运
CHI采用同样的分层思想,每层专注解决特定问题,层间通过清晰接口交互。
2.1.2 协议层:事务的"大脑"
协议层是CHI的最高层,负责定义系统的"行为规范"。
核心职责:
-
事务生成与处理
- 请求节点生成读取、写入、原子操作等请求
- 主节点接收请求,协调一致性操作
- 从属节点执行最终内存访问
-
缓存状态管理
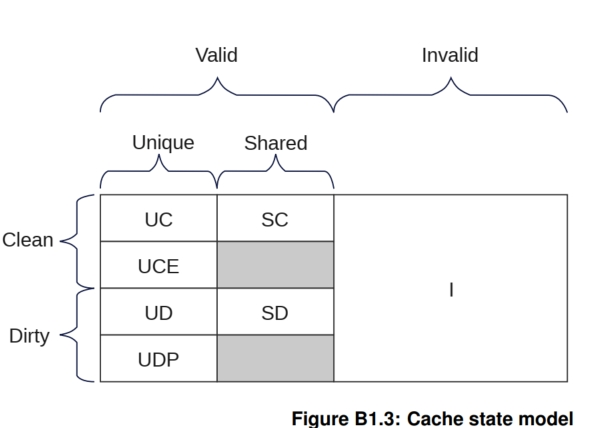
- 定义7种缓存状态(UC、UD、SC、SD、I、P、E)
- 管理状态转换规则(如I→SC、UD→I)
- 确保所有核心看到一致的数据视图
- 定义7种缓存状态(UC、UD、SC、SD、I、P、E)
-
事务流定义
- 为每种事务类型定义标准处理流程
- 例如:ReadClean、WriteUnique、AtomicCompare各有不同流程
-
协议级流控
- 管理事务信用(Protocol Credit)
- 防止接收方被请求淹没
实际示例:协议层处理ReadShared请求
协议层视角:
1. RN-F0: 生成ReadShared请求(地址A,TxnID=5)
2. HN-F: 接收请求,检查目录
3. HN-F: 发现RN-F1有数据(状态SC)
4. HN-F: 决定使用DCT(直接缓存传输)
5. HN-F: 向RN-F1发送SnpSharedFwd
6. RN-F1: 直接向RN-F0发送数据
7. RN-F0: 缓存状态I→SC
8. RN-F0: 向HN-F发送CompAck协议层不关心数据具体怎么传输 ,只关心应该发生什么。
2.1.3 网络层:路由的"导航系统"
网络层负责数据包的路由和转发。
核心职责:
-
数据包封装
- 将协议层消息封装成标准数据包格式
- 添加路由信息(源ID、目标ID)
-
路由决策
- 根据系统地址映射(SAM)确定目标节点ID
- 选择最优路径(基于拓扑和拥塞情况)
-
节点标识管理
- 为每个组件分配唯一节点ID(7-16位)
- 维护地址到节点ID的映射关系
关键概念:系统地址映射(SAM)
SAM是网络层的核心数据结构,相当于快递系统的邮编数据库:
SAM示例:
地址范围 节点类型 节点ID
0x0000_0000-0x3FFF_FFFF HN-F 5
0x4000_0000-0x7FFF_FFFF HN-I 6
0x8000_0000-0xBFFF_FFFF SN-F(内存) 2
0xC000_0000-0xFFFF_FFFF SN-I(外设) 3当请求节点要访问地址0x8000_1000时:
- 查询本地SAM(或通过互连查询)
- 发现属于范围0x8000_0000-0xBFFF_FFFF
- 确定目标节点ID=2(SN-F)
- 在数据包中设置TgtID=2
网络层数据包格式
+----------------+----------------+----------------+
| 路由头(24位) | 协议头(可变) | 数据载荷(可选) |
+----------------+----------------+----------------+
路由头包含:
- SrcID: 源节点ID(谁发送的)
- TgtID: 目标节点ID(发给谁)
- 其他路由控制信息2.1.4 链路层:物理的"运输队"
链路层负责数据包的实际传输,确保可靠、有序、高效的物理传输。
核心职责:
-
流控制
- 使用链路信用(L-Credit)机制
- 确保发送方不会压倒接收方
- 防止缓冲区溢出
-
死锁避免
- 管理链路通道(虚拟通道)
- 确保数据包不会在环路中卡住
-
物理传输管理
- 将数据包分割为微片(Flit)
- 微片进一步分割为物理传输单元(Phit)
- 管理时钟门控、电源门控
传输单元层次:
事务(Transaction) → 消息(Message) → 数据包(Packet) → 微片(Flit) → 物理单元(Phit)
实际CHI简化:
事务 → 消息 → 数据包(=1个微片=1个物理单元)为什么CHI简化了?
在片上系统(SoC)中,传输距离短、可靠性高,不需要复杂的分包机制。一个数据包就是一个微片,一次传输完成。
链路信用机制示例:
发送方(RN-F0) 接收方(HN-F)
初始:信用=2
发送数据包1 → 信用=1
发送数据包2 → 信用=0
(必须等待信用恢复)
处理完数据包1 → 返回信用+1
信用=1,可以继续发送2.1.5 三层协同工作示例
场景:CPU核心读取内存数据
完整流程:
┌─────────────┐ ┌─────────────┐ ┌─────────────┐
│ 协议层 │ │ 网络层 │ │ 链路层 │
├─────────────┤ ├─────────────┤ ├─────────────┤
│ 1.生成Read │ │ 1.封装数据包 │ │ 1.检查信用 │
│ Clean请求 │ │ - SrcID=1 │ │ 信用充足 │
│ TxnID=10 │→ │ - TgtID=5 │→ │ 2.发送微片 │
│ 2.期望数据 │ │ 2.查SAM路由 │ │ 到物理线 │
│ 返回 │ │ 目标HN-F │ │ 3.等待确认 │
└─────────────┘ └─────────────┘ └─────────────┘
反向流程:
┌─────────────┐ ┌─────────────┐ ┌─────────────┐
│ 协议层 │ │ 网络层 │ │ 链路层 │
├─────────────┤ ├─────────────┤ ├─────────────┤
│ 1.接收数据 │← │ 1.解封装 │← │ 1.接收微片 │
│ 更新缓存 │ │ 提取协议 │ │ 2.校验完整 │
│ SC状态 │ │ 消息 │ │ 性 │
│ 2.发送CompAck│ │ 2.更新路由 │ │ 3.返回信用 │
└─────────────┘ └─────────────┘ └─────────────┘2.2 核心设计理念:可扩展性、分层解耦、包化通信
2.2.1 可扩展性:从小型到大型系统
CHI的可扩展性体现在多个维度:
1. 规模可扩展
- 小型系统(2-8核心):简单环形拓扑,单个HN-F
- 中型系统(8-32核心):部分网状,多个HN-F分区
- 大型系统(32-100+核心):完全网状,分布式HN-F
2. 带宽可扩展
-
数据宽度可配置:128位、256位、512位
-
通道可复制:高带宽需求时可复制REQ/DAT通道
标准接口: 高带宽接口:
TXREQ ──┐ TXREQ0 ──┐
RXRSP ──┤ TXREQ1 ──┤
RXDAT ──┤ RXRSP0 ──┤
RXSNP ──┘ RXRSP1 ──┤
RXDAT0 ──┤
RXDAT1 ──┤
RXSNP ───┘
3. 功能可扩展
- 可选特性:原子操作、缓存暂存、DMT/DCT等
- 按需启用:系统根据需求选择特性子集
- 向前兼容:新特性不破坏基础协议
2.2.2 分层解耦:独立演进的关键
分层解耦让每层可以独立优化和演进:
协议层独立于物理实现
- 协议定义缓存一致性规则
- 无论使用什么物理拓扑(环、网、交叉开关),协议不变
- 就像交通规则独立于道路建设
网络层独立于协议细节
- 网络层只关心如何路由数据包
- 不关心数据包内是什么协议消息
- 就像快递公司不关心包裹内容
链路层独立于上层逻辑
- 链路层确保可靠传输
- 不关心传输的是什么数据
- 就像运输公司不关心货物价值
实际好处:
- 技术独立演进:可以改进网络层路由算法而不影响协议
- 实现灵活性:不同厂商可以在同一协议下优化各自层
- 验证简化:可以分层验证,降低复杂度
2.2.3 包化通信:统一的数据交换语言
包化通信是CHI相对于前代协议的核心创新:
传统信号通信 vs CHI包化通信
传统(AXI/ACE):
地址通道:{地址,控制信号,...}
数据通道:{数据,字节使能,...}
响应通道:{响应码,...}
CHI包化:
所有信息打包成一个数据包:
┌─────────────────────────────────┐
│ 路由头 │ 协议头 │ 数据(可选) │ 校验 │
└─────────────────────────────────┘
协议头包含:操作码、地址、控制字段、标识符等包化通信的优势:
- 统一处理:所有消息格式一致,简化硬件设计
- 灵活扩展:新特性只需定义新操作码或字段
- 优化路由:网络层可以基于数据包头做智能路由
- 错误隔离:一个损坏的数据包不影响其他数据包
数据包字段详解(以请求包为例):
位域 字段 描述
[13:0] QoS 服务质量优先级
[24:14] TgtID 目标节点ID
[35:25] SrcID 源节点ID
[43:36] TxnID 事务ID(唯一标识)
[49:44] Opcode 操作码(如0x04=ReadNoSnp)
[52:50] Size 数据大小(字节数)
[100:53] Addr 地址(48位物理地址)
[104:101] MemAttr 内存属性(缓存性、共享性等)
[105] SnpAttr 侦听属性
[110:106] LPID 逻辑处理器ID
[111] Order 顺序要求
... 其他字段 根据CHI版本不同2.3 CHI系统典型组件:处理器、GPU、内存控制器、互连
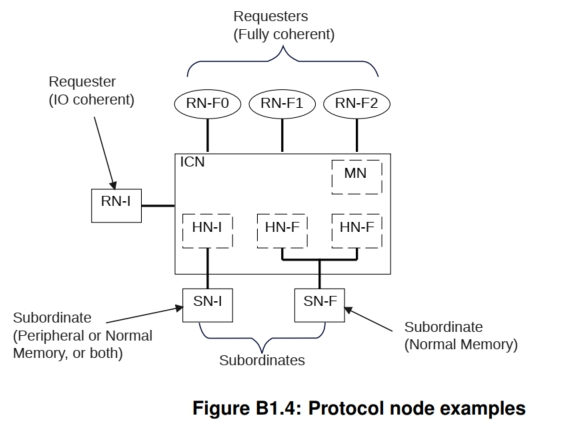
2.3.1 组件分类:节点类型视角
CHI系统由多种协议节点组成,每个节点有明确角色:
1. 请求节点(Request Node, RN)
角色 :事务的发起者
类比:餐厅的顾客(点菜)
子类型:
-
RN-F(完全一致性):包含硬件一致性缓存
- 示例:CPU大核心、GPU计算单元
- 能力:发起所有事务,响应所有侦听
- 缓存:支持完整7状态模型
-
RN-I(I/O一致性):无硬件一致性缓存
- 示例:DMA控制器、网络接口
- 能力:发起有限事务子集,不响应侦听
- 用途:访问I/O空间,不缓存一致性数据
-
RN-D(支持DVM的I/O一致性):RN-I + DVM支持
- 示例:支持虚拟化的I/O设备
- 能力:处理DVM操作(TLB无效化等)
2. 主节点(Home Node, HN)
角色 :事务的协调者
类比:餐厅的经理(协调厨房和服务员)
子类型:
-
HN-F(完全一致性):一致性内存的协调中心
- PoC(一致性点):确保所有代理看到相同数据副本
- PoS(序列化点):确定事务顺序
- 能力:处理所有一致性请求,发起侦听
- 可选:包含侦听过滤器、目录、互连缓存
-
HN-I(非一致性):I/O空间的协调中心
- 能力:处理非一致性请求(设备访问)
- 不处理:一致性操作、侦听
3. 从属节点(Subordinate Node, SN)
角色 :事务的最终执行者
类比:餐厅的厨师(实际做菜)
子类型:
-
SN-F(普通内存):内存控制器
- 连接:DRAM、持久内存
- 能力:处理内存读写、原子操作
-
SN-I(外设/内存):外设接口
- 连接:PCIe、USB、其他外设
- 能力:处理设备访问
4. 杂项节点(Miscellaneous Node, MN)
角色 :特殊操作处理器
类比:餐厅的行政人员(处理特殊事务)
- 专长:处理DVM操作(虚拟内存管理)
- 不参与:普通内存事务的一致性排序
2.3.2 实际系统示例:智能手机SoC
典型智能手机SoC(8核CPU + GPU):
┌─────────────────────────────────────────────────┐
│ CHI互连网络 │
│ ┌─────┐ ┌─────┐ ┌─────┐ ┌─────┐ ┌──────────┐ │
│ │CPU0 │ │CPU1 │ │CPU2 │ │CPU3 │ │ GPU │ │
│ │RN-F │ │RN-F │ │RN-F │ │RN-F │ │ RN-F │ │
│ └─────┘ └─────┘ └─────┘ └─────┘ └──────────┘ │
│ │ │ │ │ │
│ ┌─────┐ ┌─────┐ ┌─────┐ ┌─────┐ ┌──────────┐ │
│ │CPU4 │ │CPU5 │ │CPU6 │ │CPU7 │ │ ISP │ │
│ │RN-F │ │RN-F │ │RN-F │ │RN-F │ │ RN-I │ │
│ └─────┘ └─────┘ └─────┘ └─────┘ └──────────┘ │
│ │ │ │ │ │
│ ┌─────────────────┐ ┌──────────────────────┐ │
│ │ HN-F集群 │ │ HN-I │ │
│ │(一致性域管理) │ │(I/O域管理) │ │
│ └─────────────────┘ └──────────────────────┘ │
│ │ │ │
│ ┌─────────────┐ ┌──────────────────────────┐ │
│ │ SN-F │ │ SN-I │ │
│ │(内存控制器) │ │(PCIe/USB/其他外设) │ │
│ └─────────────┘ └──────────────────────────┘ │
│ │ │ │
│ DDR内存 外设设备 │
└─────────────────────────────────────────────────┘2.3.3 互连拓扑:连接的艺术
CHI不规定具体拓扑,但支持多种模式:
1. 环形拓扑(小型系统)
RN-F0 RN-F1 RN-F2
│ │ │
└───HN-F───┴───HN-F───┘
│ │
SN-F SN-I特点:简单、低面积、延迟随节点数线性增长
2. 网状拓扑(中型到大型系统)
RN-F0 ─── HN-F0 ─── RN-F1
│ │ │
HN-F1 ─── 交换 ─── HN-F2
│ │ │
RN-F2 ─── SN-F ─── RN-F3特点:多路径、高带宽、复杂路由
3. 交叉开关(极致性能)
RN-F0 RN-F1 RN-F2 RN-F3
│ │ │ │
├───┬───┼───┬───┼───┬───┤
│ │ │ │ │ │ │
HN-F0 HN-F1 HN-F2 HN-F3
│ │ │ │ │ │ │
├───┴───┼───┴───┼───┴───┤
│ │ │ │
SN-F0 SN-F1 SN-I0 SN-I1特点:全连接、最低延迟、高面积成本
2.4 关键特性总览:一致性粒度、缓存模型、事务类型
2.4.1 一致性粒度:64字节缓存行
缓存行(Cache Line) 是CHI一致性管理的基本单位。
为什么是64字节?
-
历史兼容:与x86、ARM架构主流选择一致
-
平衡选择:
- 太小:管理开销大(更多元数据)
- 太大:伪共享严重(不同数据被迫一起管理)
- 64字节是经验上的最佳平衡点
-
现代内存系统优化:
- DDR内存突发长度通常为64字节
- 与内存控制器设计匹配
一致性粒度影响示例:
假设两个核心访问同一缓存行内的不同数据:
缓存行(64字节):
[数据A][数据B][数据C]...[数据N]
↑ ↑
核心1访问 核心2访问
偏移8字节 偏移32字节即使访问不同数据,因为属于同一缓存行,CHI仍需要维护一致性。
部分缓存行支持
CHI支持部分缓存行状态(P状态),允许:
- 只缓存部分数据(如只缓存前32字节)
- 减少不必要的数据传输
- 特别适合I/O设备的不规则访问
2.4.2 缓存模型:七状态扩展
CHI在传统MESI/MOESI基础上扩展为七状态模型:
状态维度分析:
三个维度决定状态:
1. 唯一性:Unique(唯一) vs Shared(共享)
2. 干净度:Clean(干净) vs Dirty(脏)
3. 完整性:Full(完整) vs Partial(部分) vs Empty(空)七状态详解:
-
I(Invalid)无效
- 缓存行不存在或无效
- 不能使用数据,需要从别处获取
-
UC(Unique Clean)唯一干净
- 唯一副本,与内存一致
- 可以读取,可以写入(变为UD)
- 示例:核心独占读取后未修改
-
UD(Unique Dirty)唯一脏
- 唯一副本,比内存新
- 必须最终写回内存
- 示例:核心独占写入后
-
SC(Shared Clean)共享干净
- 可能有其他共享副本,与内存一致
- 只能读取,不能直接写入
- 示例:多个核心只读共享数据
-
SD(Shared Dirty)共享脏
- 共享副本,但至少一个比内存新
- 需要协调写回
- 较少见,特定优化场景
-
P(Partial)部分
- 只缓存了部分数据
- 常见于I/O设备的不对齐访问
-
E(Empty)空
- 分配了缓存行但无有效数据
- 预分配优化,减少分配延迟
状态转换示例:核心读取共享数据
初始:所有核心 I(无效)
1. 核心1读取 → 变为 SC(共享干净)
2. 核心2读取 → 也变为 SC(共享干净)
3. 核心1要写入:
a. 升级为 UC(需要使其他副本无效)
b. 写入数据 → 变为 UD(唯一脏)
4. 核心3读取:
a. 核心1写回内存(UD→UC)
b. 核心1降级为 SC
c. 核心3变为 SC2.4.3 事务类型:丰富的操作集
CHI定义了丰富的事务类型,满足不同需求:
1. 读取事务家族
基础读取:
- ReadNoSnp:非侦听读取(设备内存)
- ReadOnce*:一次性读取(不缓存或有限缓存)
一致性读取:
- ReadClean:读取干净数据(可能从内存)
- ReadShared:读取可共享数据(可能从其他缓存)
- ReadUnique:读取唯一数据(准备写入)
优化读取:
- ReadNotSharedDirty:读取非共享脏数据
- ReadPreferUnique:偏好唯一副本2. 写入事务家族
非一致性写入:
- WriteNoSnp*:直接写入内存(设备访问)
一致性写入:
- WriteUnique*:获取唯一所有权后写入
- WriteBack*:脏数据写回内存
部分写入:
- WriteUniquePtl:写入部分缓存行
- WriteNoSnpPtl:设备部分写入3. 无数据事务(Dataless)
缓存维护:
- CleanShared:清理共享副本
- CleanInvalid:清理并无效化
- MakeInvalid:使无效
- MakeUnique:使唯一(准备写入)
逐出操作:
- Evict:逐出缓存行4. 原子事务
比较交换:
- AtomicCompare:原子比较交换
- AtomicSwap:原子交换
算术运算:
- AtomicAdd:原子加
- AtomicMax:原子最大值
- AtomicMin:原子最小值
逻辑运算:
- AtomicAnd:原子与
- AtomicOr:原子或
- AtomicXor:原子异或5. 特殊优化事务
缓存暂存:
- StashOnceShared:共享暂存提示
- StashOnceUnique:唯一暂存提示
- WriteUnique*Stash:写入并暂存
预取:
- PrefetchTgt:目标预取提示
DVM操作:
- DVMOp:虚拟内存管理操作2.4.4 事务选择指南
如何选择正确的事务类型?
| 场景 | 推荐事务 | 原因 |
|---|---|---|
| CPU读取可缓存数据 | ReadShared | 可能从其他CPU缓存获取,减少内存访问 |
| CPU读取后准备写入 | ReadUnique | 提前获取独占权,减少后续写入延迟 |
| I/O设备读取内存 | ReadNoSnp | 设备不缓存,直接读取 |
| CPU写入可缓存数据 | WriteUniquePtl/Full | 需要一致性,获取独占权 |
| I/O设备写入内存 | WriteNoSnpPtl/Full | 设备直接写入,无需一致性 |
| 原子更新计数器 | AtomicAdd | 硬件原子操作,无锁高效 |
| 数据生产者→消费者 | WriteUniqueFullStash | 写入同时提示消费者预取 |
| 软件预取数据 | PrefetchTgt | 提前获取数据到内存缓冲区 |
2.4.5 高级特性概览
除了基础特性,CHI还提供一系列高级特性:
1. 直接传输优化
- DMT(直接内存传输):内存→请求者直连,绕过HN
- DCT(直接缓存传输):缓存→缓存直连,绕过HN
- DWT(直接写入传输):写入数据直连目标
2. 服务质量(QoS)
- 端到端优先级管理
- 带宽分配保证
- 延迟限制
3. 安全特性
- TrustZone:事务级安全隔离
- RME(领域管理扩展):多租户安全隔离
- MTE(内存标记扩展):内存安全检测
4. 可靠性与错误处理
- Data Poisoning:数据错误标记与传播
- ECC支持:错误检测与纠正
- 错误报告:系统级错误管理
5. 电源管理
- 微片级时钟门控
- 组件激活/休眠序列
- 协议活动指示
本章总结
CHI架构通过清晰的三层模型 、核心设计理念 、明确的组件角色 和丰富的特性集,为现代多核系统提供了一个完整、可扩展、高效的互连解决方案。
关键收获:
- 分层是成功的关键:协议、网络、链路各司其职,独立演进
- 包化通信是核心创新:统一格式简化设计,支持灵活扩展
- 组件角色明确:RN发起、HN协调、SN执行,系统清晰
- 64字节缓存行:一致性的基本单位,平衡效率与开销
- 七状态模型:在传统MESI/MOESI基础上扩展,支持更多场景
- 丰富事务类型:从基础读写到高级原子操作,满足各种需求
思考题:
- 如果让你设计一个16核服务器处理器,你会选择哪种拓扑?为什么?
- 为什么CHI需要七种缓存状态?四种(MESI)不够吗?
- 协议层、网络层、链路层,哪一层对系统性能影响最大?为什么?
第3章:核心概念与术语详解
3.1 节点类型:RN、HN、SN、MN的职责划分
CHI协议根据组件在一致性系统中的角色,定义了四种主要节点类型:
| 节点类型 | 全称 | 核心职责 | 子类别与关键特性 |
|---|---|---|---|
| RN | 请求节点 | 向互连发起协议事务(如读、写请求),是事务的起点。 | RN-F (完全一致性) :包含硬件一致性缓存,可发起所有事务,必须接受并响应侦听 。 RN-I (I/O一致性) :无一致性缓存,发起有限事务子集,不接受侦听 。 RN-D (支持DVM的I/O一致性):同RN-I,但能接收DVM消息。 |
| HN | 主节点 | 位于互连内部,接收RN的请求,是一致性管理 和请求排序的核心。 | HN-F (完全一致性) : 1. 一致性点(PoC) :通过向RN-F发送侦听来管理全局缓存一致性。 2. 序列化点(PoS) :对发往一致性内存的请求进行排序。 3. 可包含目录或侦听过滤器以优化性能。 HN-I (非一致性):对发往I/O子系统的请求进行排序,不处理一致性请求。 |
| SN | 从属节点 | 接收来自HN的请求,是事务的最终完成者(端点)。 | SN-F :连接到支持一致性内存空间的内存设备(如DDR控制器)。 SN-I:连接到I/O外设或非一致性内存。 |
| MN | 杂项节点 | 处理由RN发送的DVM操作,完成并返回响应。 | 有时实现为HN-D节点。 |
总结:RN是事务的发起者,HN是系统的协调中枢(负责一致性和排序),SN是数据的最终归宿,MN则处理特定的系统管理操作。
3.2 缓存状态模型:MESI/MOESI的扩展与增强
CHI采用基于目录或侦听过滤器 的写无效协议,其缓存状态模型在经典的MESI/MOESI基础上进行了增强,定义了七种状态。这些状态由三个维度的属性组合而成:
- 有效/无效:缓存行是否存在。
- 唯一/共享:缓存行是否可能存在于其他缓存中。
- 干净/脏:缓存行数据是否比主内存新。
- 完整/部分/空:缓存行中有效数据的范围(CHI扩展)。
七种状态定义如下:
| 状态 | 名称 | 含义 | 对应经典模型 |
|---|---|---|---|
| UC | 唯一干净 | 数据仅存于此缓存,且与内存一致。可被直接修改。 | 独占 (Exclusive) |
| UD | 唯一脏 | 数据仅存于此缓存,且已被修改(新于内存)。此缓存负责最终写回内存。 | 修改 (Modified) |
| SC | 共享干净 | 数据可能存在于其他缓存,本缓存数据可能与内存一致。 | 共享 (Shared) |
| SD | 共享脏 | 数据可能存在于其他缓存,但已被修改(新于内存)。本缓存不负责写回,写回责任由另一个组件承担。 | 拥有 (Owned) |
| I | 无效 | 缓存行不存在或数据无效。 | 无效 (Invalid) |
| P | 部分 | 缓存行仅部分字节有效。 | (CHI扩展) |
| E | 空 | 缓存行存在,但无任何有效字节。 | (CHI扩展) |
增强点:
- 明确区分脏数据责任 :
UD(唯一脏)和SD(共享脏)状态清晰划分了谁负责更新主内存。 - 支持部分和空状态:允许更精细的缓存行管理,优化了带宽利用(如只传输有效数据)。
- 状态驱动协议:所有事务(读、写、侦听)的本质都是驱动缓存行在这些状态间进行预定义的转换,从而维护全局一致性。
3.3 事务、消息、包、微片:通信粒度的层次关系
CHI的通信架构采用清晰的分层模型,从大到小依次为:
| 层级 | 通信粒度 | 定义与关系 | 说明 |
|---|---|---|---|
| 协议层 | 事务 | 执行单一完整操作(如一次内存读取或写入)。 | 最高层逻辑概念,例如一个ReadUnique事务。 |
| 消息 | 组件间交换的协议单元。一个事务由一系列消息流完成。 | 包括:请求、响应、侦听请求、数据响应。一个数据响应消息可能由多个包组成。 | |
| 网络层 | 包 | 在互连网络上传输的基本单元。包含路由信息(目标ID、源ID)。 | 一个消息可由一个或多个包组成。例如,一个64字节的数据响应消息可能分为2个包传输。 |
| 链路层 | 微片 | 最小的流控制单元。一个包由一个或多个微片组成。 | 在CHI中,一个包只包含一个微片。所有微片在同一事务中路径相同。 |
| 物理传输单元 | 相邻网络设备间的一次物理传输。一个微片可由一个或多个物理传输单元组成。 | 在CHI中,一个微片只包含一个物理传输单元。 |
层次关系总结 :
事务 → (由多个) 消息 → (可能拆分为多个) 包 → (在CHI中等于) 微片 → (在CHI中等于) 物理传输单元。
3.4 关键点概念:PoC、PoS、PoP、PoDP
这些"点"概念定义了系统中特定功能或保证发生的位置。
| 概念 | 全称 | 定义与职责 | 典型位置 |
|---|---|---|---|
| PoC | 一致性点 | 保证所有能访问内存的代理看到同一内存地址相同数据副本的位置。是全局一致性的裁决者。 | HN-F |
| PoS | 序列化点 | 确定来自不同代理的请求之间顺序关系的位置。保证内存操作的全局顺序。 | HN-F (对内存请求) HN-I (对I/O请求) |
| PoP | 持久化点 | 在一致性点或更下游的位置,确保写入的数据在系统断电后得以保持,并在恢复供电后能可靠恢复。 | 可能在HN-F或下游的SN-F(如非易失性内存控制器)。 |
| PoDP | 深度持久化点 | 即使同时发生断电和备用电池故障,数据也能保持不丢失的位置。比PoP要求更高。 | 在具有更强持久性保证的存储介质控制器中。 |
| PoPA | 物理别名点 | 确保对一个物理地址空间的更新,对所有其他物理地址空间可见的位置。 | 与地址转换和别名管理相关的节点。 |
| PoPS | 物理存储点 | 内存层次结构中距离处理器最远 的节点,写入事务可传播的终点,即主内存。 | SN-F |
核心关系:
- PoC和PoS通常是HN-F的核心职能,它既维护一致性,也负责排序。
- PoP/PoDP是可靠性特性,定义了数据在断电等故障下的生存边界。
- PoPS是数据在内存系统中的最终归宿。