🧩 Allocating Read 事务全流程解析

这是 ARM CHI 协议的「分配读」时序图 ,核心是:Requester 读取数据并在本地缓存中分配新行,为后续读写复用做准备,是 CPU 缓存访问的典型路径。
一、初始请求与角色
1. 发起方与事务类型
- Requester 向 Home 发起以下分配读请求:
ReadClean:请求干净副本(Shared/Clean)ReadNotSharedDirty:请求非共享脏副本ReadShared:请求共享权限(可读,不可写)ReadUnique:请求独占权限(可读可写,需回收其他副本)ReadPreferUnique:优先请求独占,可降级为共享MakeReadUnique:将已有副本升级为独占(纯权限变更)
- 核心特点:读完后在本地缓存分配行,保留数据副本以提升后续访问性能。
2. 角色分工
表格
| 角色 | 作用 |
|---|---|
| Requester | 发起读请求,分配并缓存数据行 |
| Home | 目录仲裁节点,管理地址状态、路由事务、维护一致性 |
| Subordinate | 存储 / 内存侧节点(如 DDR 控制器) |
| Snoope | 其他缓存节点,可能持有共享 / 脏副本 |
二、逐场景流程解析
场景 1:Combined response from Home(Home 合并响应)
流程
Home 直接向 Requester 发送 CompData(事务完成响应 + 数据合并)。
场景与原因
- 适用场景 :
- Home 本身持有最新数据
- 目录状态显示无需向其他节点发起 snoop / 读请求
- 设计原因 :
- 延迟最低,一步完成数据交付与缓存分配
场景 2:Separate Data and Response from Home(Home 分离响应)
流程
- Home 先向 Requester 发送
RespSepData(仅事务完成响应) - 随后向 Requester 发送
DataSepResp(仅数据载荷)
场景与原因
- 适用场景 :
- 需要严格分离控制流与数据流(如大带宽传输、时序优化)
- Home 需先确认事务状态,再异步传输数据
- 设计原因 :
- 控制面与数据面解耦,避免大数据块阻塞控制消息
- 适配不同链路带宽,提升事务并发能力
- 分配读场景下,先确认事务状态再传输数据,避免缓存分配失败导致的状态不一致
场景 3:Combined response from Subordinate(Subordinate 合并响应)
流程
- Home 向 Subordinate 发送
ReadNoSnp(无监听读请求) - (可选)若
Order != 00,Subordinate 返回ReadReceipt(流控 / 排序收据) - Subordinate 直接向 Requester 发送
CompData
场景与原因
- 适用场景 :
- 最新数据在 Subordinate(如内存)
- 目录状态显示无需 snoop 其他节点(无共享 / 脏副本)
- 典型 DMT(Direct Memory Transfer) 路径
- 设计原因 :
- 数据直接从存储节点送达请求者,减少 Home 中转开销
- 无监听操作,避免广播 snoop 带来的带宽浪费
- 适合多 Requester 并发读内存场景,提升系统吞吐量
场景 4:Response from Home, Data from Subordinate(Home 响应 + Subordinate 数据)
流程
- Home 向 Subordinate 发送
ReadNoSnpSep(分离无监听读请求) - (可选)若
Order != 00,Subordinate 返回ReadReceipt - Home 向 Requester 发送
RespSepData(完成响应) - Subordinate 向 Requester 发送
DataSepResp(数据)
场景与原因
- 适用场景 :
- 需严格分离控制流与数据流(如高并发、大带宽场景)
- 数据由 Subordinate 提供,Home 仅负责事务仲裁
- 设计原因 :
- 兼顾事务确认及时性与数据传输效率
- 控制响应由 Home 发出,保证事务状态同步与缓存分配安全
- 数据由 Subordinate 直传,避免 Home 成为性能瓶颈
- 分配读场景下,先确认事务状态再传输数据,防止缓存分配失败
场景 5:Forwarding snoop(转发监听)
流程
- Home 向 Snoope 发送
Snp*Fwd(转发监听请求,如SnpSharedFwd/SnpUniqueFwd) - 进入 4 个互斥分支(
alt):- 5a. With response to Home :
- Snoope → Home:
SnpRespFwded(已向 Requester 转发响应) - Home → Requester:
CompData
- Snoope → Home:
- 5b. With data to Home :
- Snoope → Home:
SnpRespDataFwded(已向 Requester 转发响应 + 数据) - Home → Requester:
CompData
- Snoope → Home:
- 5c. Failed, must use alternative :
- Snoope → Home:
SnpResp(转发失败,仅响应) - Home → Snoope:
Use alternative(fallback 到 Home 中转)
- Snoope → Home:
- 5d. Failed, must use alternative :
- Snoope → Home:
SnpRespData/SnpRespDataPtl(转发失败,带完整 / 部分数据) - Home → Snoope:
Use alternative
- Snoope → Home:
- 5a. With response to Home :
场景与原因
- 适用场景 :
- 最新数据在其他缓存节点(Snoope)
- 目录状态显示需要 snoop 监听以获取共享 / 独占副本
- 典型 DCT(Direct Cache Transfer) 路径
- 设计原因 :
- 缓存间直传数据,避免 Home 中转,大幅提升读性能
- 分配读场景下,直接在 Requester 分配缓存行,复用 Snoope 的最新副本
- 监听转发保证缓存一致性:Snoope 副本状态会根据请求类型(Shared/Unique)调整(如 Shared→Shared,Unique→Invalid)
- 失败时自动 fallback 到 Home 中转 / 读内存,保证事务可靠性
场景 6:MakeReadUnique only(仅升级独占权限)
流程
- Requester 向 Home 发起
MakeReadUnique - Home 向 Requester 发送
Comp(仅事务完成响应) - Requester 向 Home 发送
CompAck(完成确认)
场景与原因
- 适用场景 :
- Requester 已持有该缓存行的有效副本(通常是 Shared 状态)
- 需要将权限从「共享」升级为「独占可读(ReadUnique)」,为后续写操作做准备
- 设计原因 :
- 纯权限升级事务,不传输数据,避免冗余带宽消耗
- 前提是其他缓存副本已提前失效(或不存在),因此 Home 无需发
SnpInvalidate - 轻量级事务,仅更新目录状态,快速完成权限变更
- 分配读场景下,保证 Requester 独占缓存行,为后续写操作做准备
三、整体设计意图总结
- 分配核心:所有事务都要求 Requester 分配缓存行,保留数据副本以提升后续访问性能,是 CPU 缓存的核心工作模式。
- 路径复用:复用 DMT/DCT 路径,与非分配读保持一致的协议框架,降低实现复杂度。
- 效率优化 :
- 允许 Subordinate/Snoope 直传数据,减少 Home 中转开销
- 分离响应与数据,适配大带宽场景
- 无监听读(
ReadNoSnp)避免广播 snoop 开销
- 一致性保障 :
- 监听转发(
Snp*Fwd)保证多缓存副本间的一致性 MakeReadUnique实现权限平滑升级,为写操作做准备- 失败 fallback 机制保证事务可靠性,避免死锁
- 监听转发(
- 流控与排序 :
Order != 00时返回ReadReceipt,保证事务顺序与流控安全CompAck用于事务收尾,确认缓存分配完成
四、一句话记忆
Allocating Read = 读数据 + 分配缓存,数据可来自 Home/Subordinate/Snoope,通过 DMT/DCT 高效交付,兼顾性能与一致性,是 CPU 缓存访问的核心路径。
🧩 Non-allocating Read 事务全流程解析
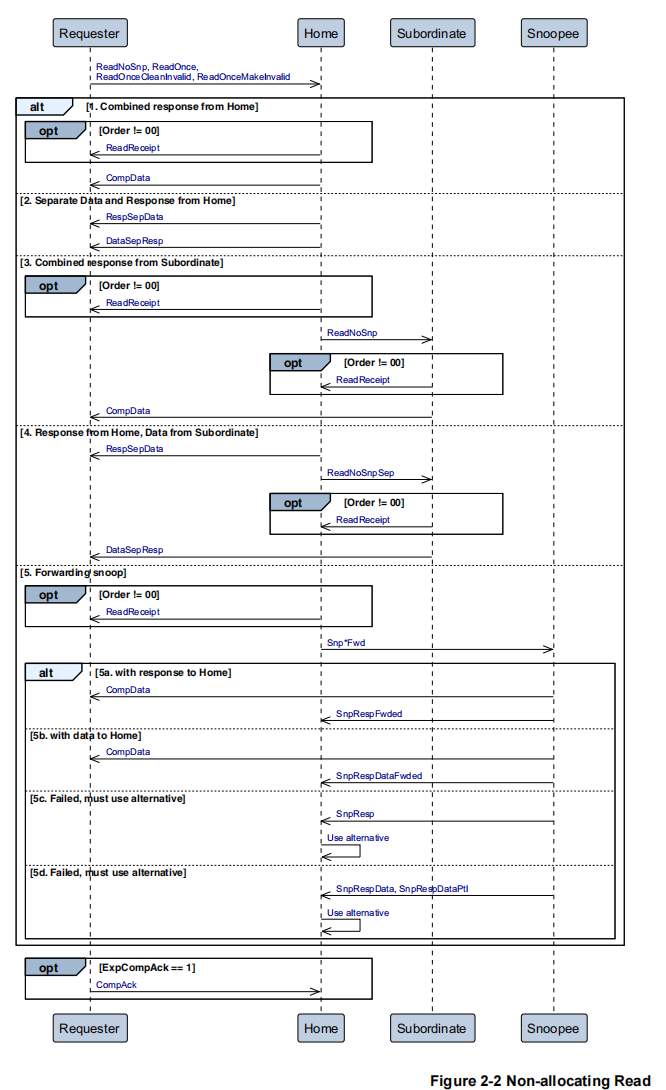
这是 ARM CHI 协议的「非分配读」时序图 ,核心是:Requester 只读取数据,不在本地缓存分配新行,适合一次性数据访问(如 I/O、DMA、临时读取)。
一、初始请求与角色
1. 发起方与事务类型
- Requester 向 Home 发起以下非分配读请求:
ReadNoSnp:无监听读,直接读 Subordinate(内存),不触发 snoopReadOnce:一次性读,不分配缓存,可接受共享副本ReadOnceCleanInvalid:一次性读,读完后要求其他节点失效干净副本ReadOnceMakeInvalid:一次性读,强制其他节点失效副本
- 核心特点:读完即丢弃,不缓存,避免占用缓存资源。
2. 角色分工
表格
| 角色 | 作用 |
|---|---|
| Requester | 发起读请求,不缓存数据 |
| Home | 目录仲裁节点,管理地址状态、路由事务 |
| Subordinate | 存储 / 内存侧节点(如 DDR 控制器) |
| Snoope | 其他缓存节点,可能持有数据副本 |
二、逐场景流程解析
场景 1:Combined response from Home(Home 合并响应)
流程
- (可选)若
Order != 00,Home 先返回ReadReceipt(流控收据,用于事务排序 / 流控) - Home 直接向 Requester 发送
CompData(事务完成响应 + 数据合并)
场景与原因
- 适用场景 :
- Home 本身持有最新数据
- 目录状态显示无需向其他节点发起 snoop / 读请求
- 设计原因 :
- 延迟最低,一步完成数据交付
- 避免额外节点交互,提升非分配读的效率
场景 2:Separate Data and Response from Home(Home 分离响应)
流程
- Home 先向 Requester 发送
RespSepData(仅事务完成响应) - 随后向 Requester 发送
DataSepResp(仅数据载荷)
场景与原因
- 适用场景 :
- 需要严格分离控制流与数据流(如大带宽传输、时序优化)
- Home 需先确认事务状态,再异步传输数据
- 设计原因 :
- 控制面与数据面解耦,避免大数据块阻塞控制消息
- 适配不同链路带宽,提升事务并发能力
- 非分配读场景下,数据无需缓存,分离传输更灵活
场景 3:Combined response from Subordinate(Subordinate 合并响应)
流程
- Home 向 Subordinate 发送
ReadNoSnp(无监听读请求) - (可选)若
Order != 00,Subordinate 返回ReadReceipt - Subordinate 直接向 Requester 发送
CompData
场景与原因
- 适用场景 :
- 最新数据在 Subordinate(如内存)
- 目录状态显示无需 snoop 其他节点(无共享 / 脏副本)
- 典型 DMT(Direct Memory Transfer) 路径
- 设计原因 :
- 数据直接从存储节点送达请求者,减少 Home 中转开销
- 非分配读不需要缓存,直传更高效
- 无监听操作,避免广播 snoop 带来的带宽浪费
场景 4:Response from Home, Data from Subordinate(Home 响应 + Subordinate 数据)
流程
- Home 向 Subordinate 发送
ReadNoSnpSep(分离无监听读请求) - (可选)若
Order != 00,Subordinate 返回ReadReceipt - Home 向 Requester 发送
RespSepData(完成响应) - Subordinate 向 Requester 发送
DataSepResp(数据)
场景与原因
- 适用场景 :
- 需严格分离控制流与数据流(如高并发、大带宽场景)
- 数据由 Subordinate 提供,Home 仅负责事务仲裁
- 设计原因 :
- 兼顾事务确认及时性与数据传输效率
- 控制响应由 Home 发出,保证事务状态同步
- 数据由 Subordinate 直传,避免 Home 成为瓶颈
- 非分配读场景下,分离传输更适配一次性数据访问
场景 5:Forwarding snoop(转发监听)
流程
- (可选)若
Order != 00,Home 先返回ReadReceipt - Home 向 Snoope 发送
Snp*Fwd(转发监听请求) - 进入 4 个互斥分支(
alt):- 5a. with response to Home :
- Snoope → Home:
SnpRespFwded(已向 Requester 转发响应) - Home → Requester:
CompData
- Snoope → Home:
- 5b. with data to Home :
- Snoope → Home:
SnpRespDataFwded(已向 Requester 转发响应 + 数据) - Home → Requester:
CompData
- Snoope → Home:
- 5c. Failed, must use alternative :
- Snoope → Home:
SnpResp(转发失败,仅响应) - Home → Snoope:
Use alternative( fallback 到 Home 中转)
- Snoope → Home:
- 5d. Failed, must use alternative :
- Snoope → Home:
SnpRespData/SnpRespDataPtl(转发失败,带数据) - Home → Snoope:
Use alternative
- Snoope → Home:
- 5a. with response to Home :
场景与原因
- 适用场景 :
- 最新数据在其他缓存节点(Snoope)
- 目录状态显示需要 snoop 监听以获取副本
- 典型 DCT(Direct Cache Transfer) 路径
- 设计原因 :
- 缓存间直传数据,避免 Home 中转,提升读性能
- 非分配读不需要缓存,直传更高效
- 失败时自动 fallback 到 Home 中转 / 读内存,保证事务可靠性
- 监听转发符合非分配读的一次性访问特性,不影响缓存一致性
收尾:CompAck 可选流程
流程
- 当
ExpCompAck == 1时,Requester 向 Home 发送CompAck(完成确认)
场景与原因
- 适用场景 :
- 协议配置要求事务可靠收尾
- 需要确认 Requester 已收到数据 / 响应
- 设计原因 :
- 保证事务生命周期完整,避免状态机死锁
- 适配不同实现的可靠性需求
- 非分配读场景下,确认数据已被接收,避免资源泄漏
三、整体设计意图总结
- 非分配核心:所有事务都不要求 Requester 缓存数据,适合一次性访问,避免缓存污染。
- 路径复用:复用 DMT/DCT 路径,与普通读事务保持一致的协议框架,降低实现复杂度。
- 效率优化 :
- 允许 Subordinate/Snoope 直传数据,减少 Home 中转
- 分离响应与数据,适配大带宽场景
- 无监听读(
ReadNoSnp)避免广播 snoop 开销
- 健壮性 :
opt分支处理流控 / 排序需求alt分支处理监听转发失败,自动 fallback 到可靠路径- 可选
CompAck保证事务收尾
四、一句话记忆
Non-allocating Read = 不缓存的一次性读 ,数据可来自 Home/Subordinate/Snoope,通过 DMT/DCT 高效交付,失败时自动 fallback,核心是省缓存、提效率、保可靠。
🧩 为什么要强调 Order != 00?
在 CHI 协议中,Order 字段是事务排序与流控的核心标识 ,Order != 00 本质是在说:这个事务需要严格的顺序保障或流控反馈 ,所以必须先返回 ReadReceipt 收据。
1. 先搞懂 Order 字段的含义
CHI 里的 Order 字段用来描述事务的全局有序性要求,典型取值:
Order = 00:弱序 / 无顺序要求 (Unordered / Relaxed)- 事务可以乱序完成,不要求和发起顺序一致
- 不需要流控收据,协议允许 "发完不管"
Order != 00:强序 / 有顺序要求 (Ordered / Strong Ordering)- 事务必须按发起顺序完成,不能乱序
- 或需要接收端返回收据,做流控 / 资源管理
2. ReadReceipt 的作用:给强序事务 "上保险"
当 Order != 00 时,接收方(Home/Subordinate/Snoope)必须先返回 ReadReceipt:
- 流控(Flow Control):告诉发送方 "我已收到并受理这个事务,你可以继续发下一个",避免发送端资源溢出
- 排序保证(Ordering):收据的返回顺序可以用来约束事务完成顺序,保证强序语义
- 资源预留:接收端用收据确认 "我已为这个事务分配了资源,不会丢包"
如果 Order = 00,协议允许省略 ReadReceipt,直接进入数据 / 响应阶段,提升性能。
3. 为什么在 Non-allocating Read 里特别强调?
非分配读(ReadNoSnp/ReadOnce 等)常被用于:
- I/O 设备、DMA、外设访问 :这类场景对事务顺序和可靠性要求极高(比如寄存器访问、设备状态更新),必须保证事务按序完成,不能乱序
- 高并发系统 :多个非分配读事务同时发起时,需要
ReadReceipt做流控,避免接收端缓冲区溢出 - 调试 / 观测:收据可以用来追踪事务生命周期,便于定位死锁、丢包问题
而普通缓存读(Allocating Read)因为有缓存行状态机兜底,对强序的依赖稍弱,所以 Order != 00 的场景更少。
4. 一句话总结
强调 Order != 00,本质是在说:
当事务需要强序或流控保障时,必须先返回
ReadReceipt收据,否则可以省略,直接进入数据 / 响应阶段。 这是 CHI 协议在性能 和可靠性 / 顺序性之间做的权衡:弱序场景省带宽提性能,强序场景用收据保安全。
📊 Allocating Read vs Non-allocating Read 对比表
表格
| 维度 | Allocating Read(分配读) | Non-allocating Read(非分配读) |
|---|---|---|
| 核心目标 | 读取数据 + 在本地缓存分配新行,保留副本供后续访问 | 仅读取数据,不在本地缓存分配新行,读完即丢弃 |
| 典型事务 | ReadClean、ReadShared、ReadUnique、MakeReadUnique |
ReadNoSnp、ReadOnce、ReadOnceCleanInvalid |
| 缓存行为 | 完成后缓存行状态变为 Shared/Unique,长期占用缓存资源 | 不分配缓存,无状态留存,避免缓存污染 |
| snoop 行为 | 可能触发 SnpShared/SnpUnique 监听,以获取共享 / 独占副本 |
可能触发 Snp*Fwd 监听,或直接 ReadNoSnp 无监听读内存 |
| 数据路径 | 支持 DMT(Home/Subordinate)、DCT(Snoope 直传) | 与分配读完全复用 DMT/DCT 路径 |
| 权限升级 | 支持 MakeReadUnique 纯权限升级事务,无需重传数据 |
无权限升级需求,仅一次性读取 |
| 适用场景 | CPU 核心常规读写、频繁访问的热数据、需要写前独占准备 | I/O 设备访问、DMA 传输、临时一次性读取、避免缓存污染的场景 |
| 性能侧重 | 优先长期访问效率(缓存命中),首次访问延迟稍高 | 优先单次访问效率,避免缓存资源浪费,适合冷数据 / 一次性访问 |
| 一致性影响 | 参与缓存一致性,副本状态会被其他节点 snoop 影响 | 不参与长期一致性,读完后不保留副本,对其他节点无一致性依赖 |
| 事务收尾 | 可选 CompAck 确认缓存分配完成 |
可选 CompAck 确认数据接收完成 |
💡 关键差异总结
- 缓存生命周期 :
- Allocating Read:长期持有,为后续访问做缓存预热。
- Non-allocating Read:用完即走,不占用缓存资源,适合一次性访问。
- 协议设计意图 :
- Allocating Read:优化局部性访问,提升多核系统缓存命中率。
- Non-allocating Read:优化一次性访问,避免 I/O/DMA 等场景污染 CPU 缓存。
- 一致性交互 :
- Allocating Read:深度参与一致性协议,状态变更会触发 snoop 广播。
- Non-allocating Read:仅在读取时参与一致性,读完后不影响全局状态。
🎯 一句话记忆
- Allocating Read:我要缓存下来,以后常用 ✨
- Non-allocating Read:我只看一次,看完就走 🚶♂️