Prompt 为什么有"好坏"?
当你写提示词时,你是否注意到,为什么多加一个词(如"Step by Step"),模型表现会天差地别?我们知道提示词工程本质上是在通过外部输入,人为干预模型内部的注意力权重分布。
所以:Prompt 的好坏 = 是否构造了"高质量注意力分布"
自注意力机制回顾(Self-Attention)
自注意力机制(Self-Attention)是现代深度学习(尤其是 Transformer 模型)的核心。它的目标:让模型在处理一个序列时,能够根据上下文自动判断哪些部分更重要。
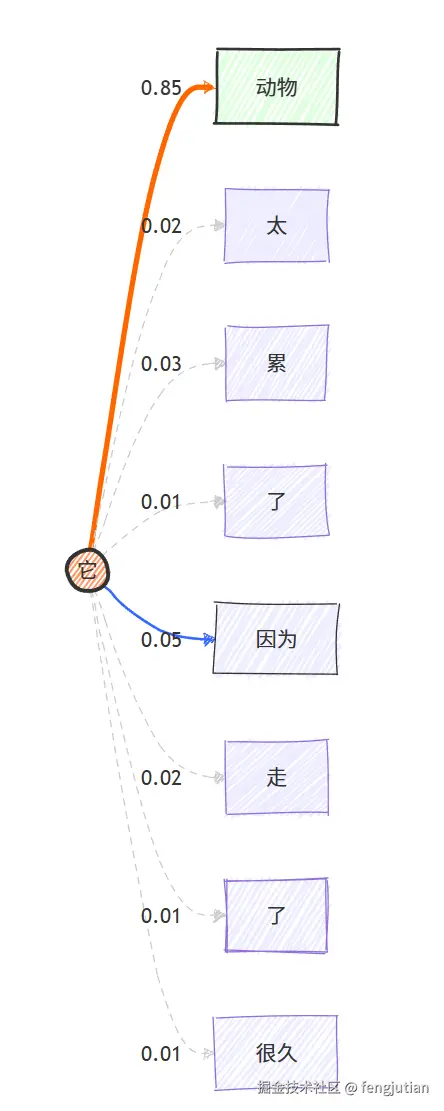
想象你在读一句话: "动物太累了,因为它走了很久。"
当你读到"它"这个词时,你的大脑会自动将其与"动物"联系起来,而不是"很久"。自注意力机制的作用就是通过数学计算,给"动物"分配极高的注意力权重,而给其他词较低的权重。
重点关注: "它" ,因为它是指代词,需要找前面的主体。
为什么模型能判断"它 = 动物"?
因为模型在语料训练过程中学到了对应的模式:
1️⃣ 语法模式(coreference)
- "它"通常指代前面的名词
2️⃣ 语义匹配
- "动物"可以"走"
- "动物"可以"累"
3️⃣ 距离偏置
- 越近的词,权重通常越高
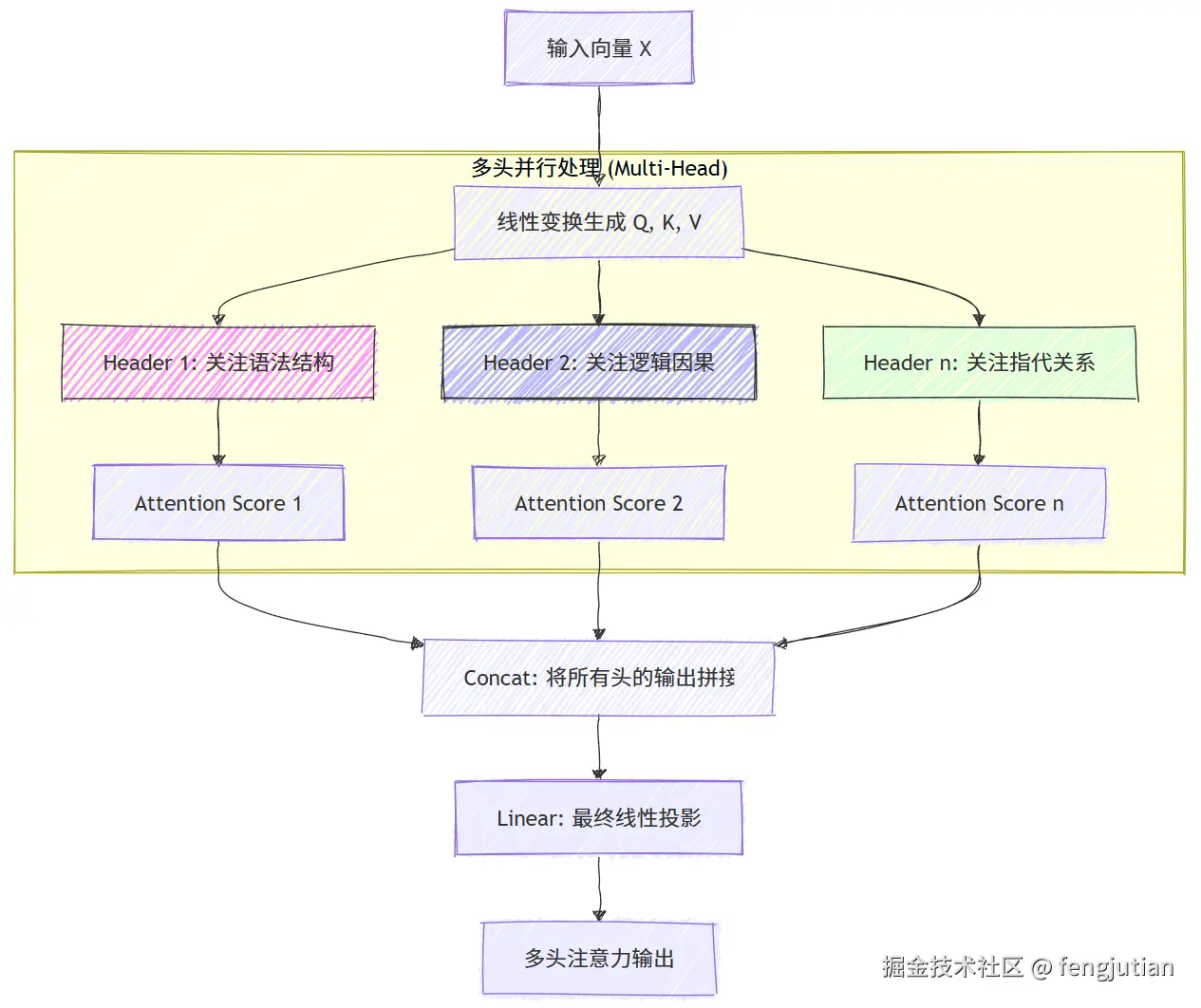
多头注意力的作用(Multi-Head Attention)
多头注意力(Multi-Head Attention)的设计,本质上是为了解决单头注意力在处理复杂语言时的"信息瓶颈"问题。
如果把模型比作一个正在读书的人,单头注意力就像是只能盯着一个重点看 ,而多头注意力则让模型拥有了多双眼睛,从不同维度同时观察一个词。
"动物太累了,因为它走了很久。 "
- 头 A(语法视角): 关注"它"作为代词,在语法结构上指向前面的名词(动物)。
- 头 B(逻辑视角): 关注"走"这个动作,寻找谁是这个动作的执行者(动物)。
- 头 C(状态视角): 关注"累"的原因,将"走"和"太久"联系起来。
如何用 Attention 分析 Prompt 好坏
Attention Map(注意力图)
Attention Map 是衡量 Prompt 质量最直接的工具。它能告诉你模型在生成每一个 Token 时,对输入 Prompt 中各个部分的关注权重。
- 好的 Prompt: 模型在处理关键指令(如"总结"、"翻译成法语")或核心约束(如"不超过50字")时,Attention 权重应该显著集中。
- 坏的 Prompt: 注意力非常分散,或者模型过分关注一些无意义的填充词(如"请"、"如果你方便的话"),这说明 Prompt 存在冗余,甚至可能干扰了模型的判断。
分析技巧: 如果你发现模型在生成结果时,Attention 几乎不流向你设置的某个特定约束条件,那么这个约束很可能失效了,你需要强化它的位置(比如移到开头或结尾)或改变措辞。
举个代码例子:
**python**
from transformers import AutoTokenizer, AutoModelForCausalLM
from bertviz import head_view
import webbrowser
import os
# 加载模型
print("🔄 Loading model...")
model_id = "gpt2"
tokenizer = AutoTokenizer.from_pretrained(model_id)
model = AutoModelForCausalLM.from_pretrained(model_id, attn_implementation="eager", output_attentions=True)
print("✅ Model loaded successfully!")
# 定义 Prompt
good_prompt = "Task: Summarize. Constraint: Max 10 words. Text: The quick brown fox jumps over the lazy dog."
bad_prompt = "Hello assistant, if you are free, could you please help me to summarize this text? Please keep it under 10 words: The quick brown fox jumps over the lazy dog."
# 简化的可视化函数
def visualize_attention(prompt, output_file):
"""
可视化 prompt 的注意力分布
"""
# 处理输入
inputs = tokenizer.encode(prompt, return_tensors='pt')
outputs = model(inputs)
attentions = outputs.attentions
tokens = tokenizer.convert_ids_to_tokens(inputs[0])
# 生成可视化
html_obj = head_view(attentions, tokens, html_action='return')
# 保存结果
with open(output_file, 'w', encoding='utf-8') as f:
f.write(html_obj.data)
# 显示信息
print(f"\n📊 {output_file} generated!")
print(f"📝 Tokens: {len(tokens)}")
print(f"🧠 Layers: {len(attentions)}")
print(f"🌐 Open {output_file} in your browser to view")
# 尝试自动打开
try:
webbrowser.open('file://' + os.path.abspath(output_file))
except Exception as e:
print(f"⚠️ Browser opening failed: {e}")
# 运行可视化
print("\n=== Analyzing GOOD Prompt ===")
print("Prompt:", good_prompt)
visualize_attention(good_prompt, "good_prompt_attention.html")
print("\n=== Analyzing BAD Prompt ===")
print("Prompt:", bad_prompt)
visualize_attention(bad_prompt, "bad_prompt_attention.html")
# 分析指南
print("\n=== How to Analyze ===")
print("1. Open both HTML files in your browser")
print("2. Compare the attention patterns between good and bad prompts")
print("3. Look for these key differences:")
print(" - Good prompt: Focus on 'Text:' section and 'Constraint'")
print(" - Bad prompt: Distracted by greeting and extra words")
print("4. Darker colors = stronger attention")
print("5. Try different layers to see how attention evolves")


good_prompt = "Task: Summarize. Constraint: Max 10 words. Text: The quick brown fox jumps over the lazy dog."
好的提示词更关注Task,Constraint,Text 描述任务的各个子部分。
信息熵(Entropy)指标
信息熵在 Attention 分析中用于衡量注意力的集中程度。
- 低 熵 (Low Entropy ): 注意力高度集中在少数几个 Token 上。这通常意味着模型对当前指令的理解非常清晰,逻辑路径明确。
- 高 熵 (High Entropy ): 注意力均匀地散布在所有 Token 上。这往往是 Prompt 模糊不清 的信号------模型不知道该听谁的,导致输出可能出现幻觉或随机性增强。
H(Ai)=−∑jαijlogαij
应用场景: 如果你的 Prompt 在关键步骤点产生的 Attention 熵值过高,说明该指令存在歧义,建议添加 Few-shot 示例 来降低模型的不确定性。
为了让你更直观地理解这个概念,我们通过两个典型的对比案例来分析:
低熵场景:逻辑明确的指令
场景: 翻译一个简单的专业词汇。
Prompt: "将 'Artificial Intelligence' 翻译成中文。"
- Attention 分布: 当模型生成"人工"这个词时,它的注意力会向输入中的
Artificial倾斜。 - 计算表现: 假设权重分配为 0.95给
Artificial,0.05给其余 Token。 - 结果:
- H(Ai)=−(0.95log0.95+0.05log0.05)≈0.198
- 诊断: 熵值极低。模型目标明确,输出结果非常稳定且准确。

高熵场景:存在歧义的指令
场景: 模糊的代词或多义词。
Prompt: "那个东西在桌子上,把它拿给王明。"(在没有上下文的情况下)
- Attention 分布: 当模型尝试处理
它这个词时,由于不知道"那个东西"具体指代什么(是杯子?是书?还是钥匙?),它的注意力会平均地分配给句子中所有的名词。 - 计算表现: 权重可能均匀分布在
那个、东西、桌子等多个 Token 上(例如每个占 0.2)。 - 结果:
- H(Ai)=−∑j=150.2log0.2≈1.609
- 诊断: 熵值较高 。模型处于"迷茫"状态,这时候它可能会随机猜测一个物体,从而产生幻觉(比如无中生有说出一个"苹果")。

Head 分歧分析
Transformer 模型通常有多个 Attention Heads,每个 Head 关注的维度不同(有的看语法,有的看指代,有的看逻辑)。
分歧度适中
不同的 Head 各司其职,有的关注你的语气要求,有的关注你的格式要求,这说明 Prompt 层次分明。
- Prompt 示例:
- "请以鲁迅的文风 (语气),为我写一段关于人工智能 (主题)的短评(格式)。"
-
Head 分歧表现:
- Head A(语法/结构): 捕捉"。、;"等标点符号,构建鲁迅式的短句结构。
- Head B(语义/主题): 锚定"计算"、"模型"、"智慧"等词汇,确保不偏离 AI 主题。
- Head C(情感/风格): 关注"深刻"、"冷峻"、"呐喊"等风格强烈的词汇,提取文风特征。
-
分析: 专家们各忙各的,最后汇总出的结果既有鲁迅的神韵,又讲清楚了 AI。
分歧度过低
当 Prompt 中某个词汇过于强势,或者指令极度单一时,所有 Head 会被迫关注同一个点,导致模型丧失了处理细节的能力。
- Prompt 示例:
- "紧急!!!十万火急!!! 帮我写个请假条,快快快!!! "
-
Head 分歧表现:
- 几乎所有 Head: 都被吸引到了"紧急"、"火急"、"快"这些高频且带有强烈情绪色彩的词汇上。
- 后果: 模型可能忽略了请假条应有的"日期"、"事由"和"礼貌用语",甚至写出的内容也变得语无伦次,只剩下情绪。
-
分析: 这是一个典型的"关键词污染",强势词汇产生了极大的注意力权重,挤占了逻辑处理的空间。

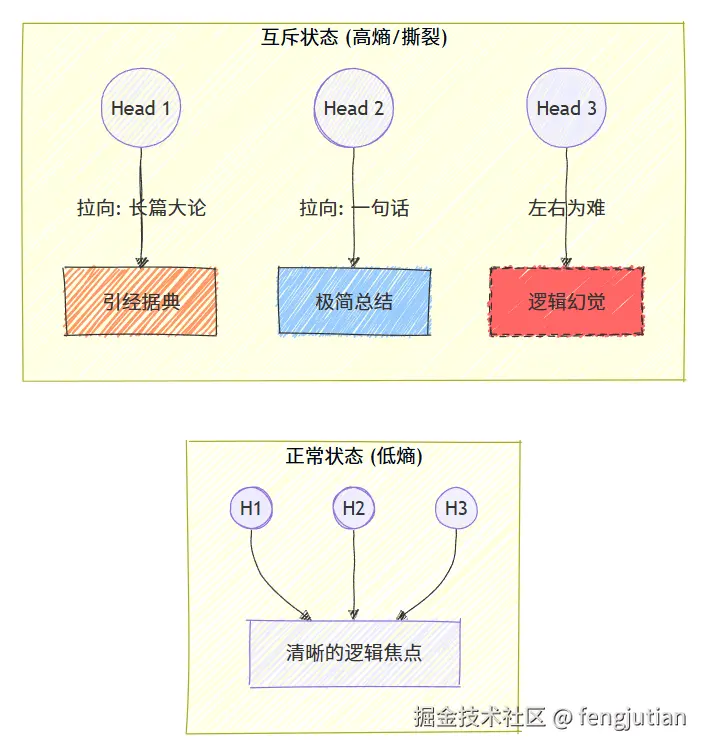
分歧度过高且混乱
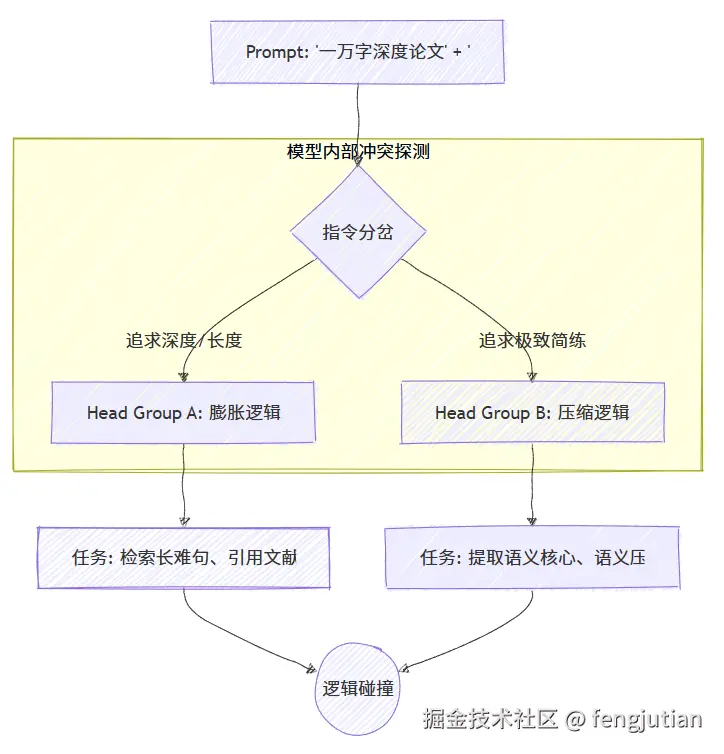
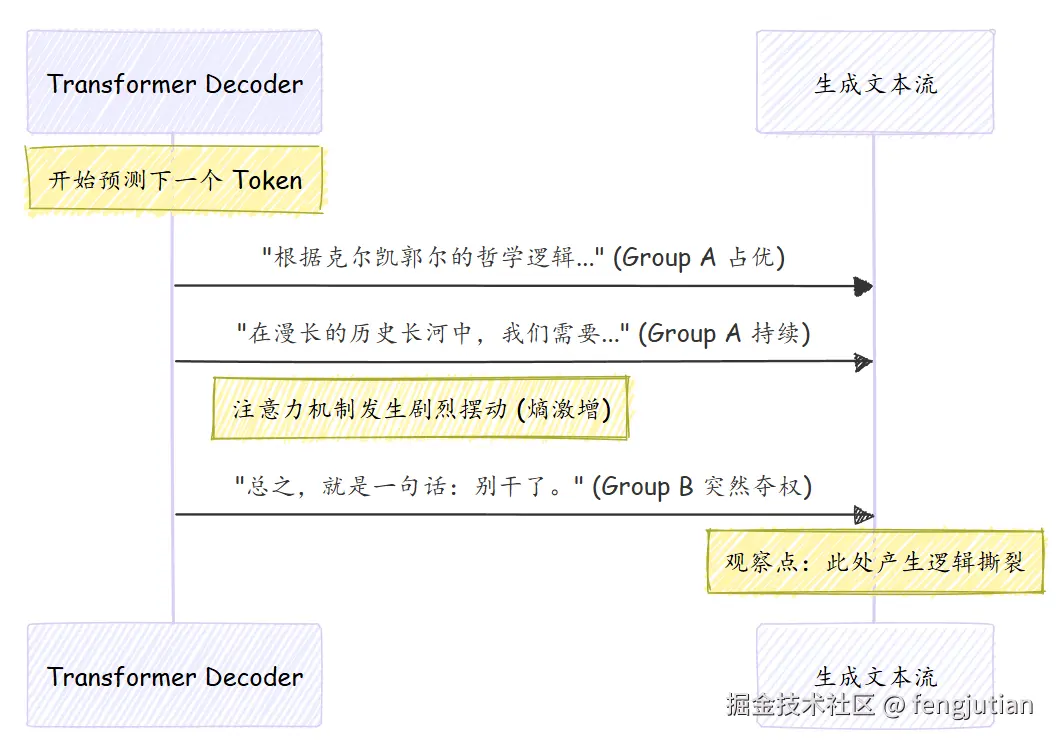
当 Prompt 存在互斥指令时,Head 之间会发生激烈的竞争,导致生成的文本逻辑断裂或出现幻觉。
- Prompt 示例:
- "请写一篇一万字 的深度论文 ,要求极其简练 ,最好一句话总结。"
-
Head 分歧表现:
- Head Group 1: 试图寻找长篇大论的学术表达和引经据典(对应"万字深度")。
- Head Group 2: 试图进行极致的压缩和信息提取(对应"一句话总结")。
-
分析: 专家团内部吵架了。模型在生成时,前半句可能在引经据典,后半句突然变成口号。这种由于指令冲突导致的注意力熵(Attention Entropy)激增,是生成质量下降的主因。