如何使用LangGraph studio 可视化查看工作流?
配置文件清单(项目根目录结构)
一个标准的、准备好接入 Studio 的项目目录应该是这样的:
text
my_agent_project/
├── .env # 1. 环境变量配置(密钥)
├── langgraph.json # 2. Studio 核心配置文件(导航图)
└── agent.py # 3. 你的图逻辑代码(引擎)详细配置步骤
第一步:配置密钥环境 (.env 文件)
在使用 Studio 时,强烈建议把密钥抽离出来,Studio 在启动时会自动读取它们。
在项目根目录新建一个名为 .env 的文本文件,填入你的配置:
env
# .env 文件内容
DEEPSEEK_API_KEY=sk-da217ba... (你的真实密钥)
# LangSmith 追踪配置 (强烈建议开启,Studio 严重依赖它)
LANGSMITH_TRACING=true
LANGSMITH_API_KEY=lsv2_pt_... (你的真实密钥)(在 Python 代码里,可以把 os.environ["..."] = "..." 那些硬编码删掉了。)
第二步:配置 Studio 导航仪 (langgraph.json)
这是启动 Studio 最核心的配置文件。它告诉 Studio 该去哪里加载代码、加载哪些依赖。 (强烈建议就取名为Langgraph.json,大小写无所谓。这样LangStudio就会自动识别到)
在项目根目录新建 langgraph.json,复制以下标准模板:
json
{
"dependencies": ["."],
"graphs": {
"math_agent": "./agent.py:agent"
},
"env": ".env"
}
配置项深度解析:
"dependencies": ["."]:告诉 Studio,项目运行所需的依赖就在当前目录。"graphs":这是核心。你可以把它理解为一个注册表。"math_agent":这是你的图在 Studio 左上角下拉菜单里显示的UI 名称 (你可以随便起,比如DeepSeek_Calculator)。"./agent.py:agent":这是物理路径映射 。冒号前面是 Python 文件相对路径,冒号后面是你代码中builder.compile()赋值的那个变量名。
"env": ".env":明确告诉 Studio 去读取刚才第一步配置的密钥文件。
第三步:代码端"去记忆化"配置 (agent.py)
为了让 Studio 接管可视化和时光倒流功能,你的代码在导出给 Studio 使用时,必须是"裸编译"的。
确保你的 agent.py 文件底部是这样配置的:
python
# ... 前面的 Nodes 和 Edges 逻辑保持不变 ...
builder = StateGraph(MessagesState)
builder.add_node("llm_node", llm_node)
# ... 其他连线 ...
# 【关键配置】:不要加 checkpointer=MemorySaver()
agent = builder.compile()
# 上面这个叫 "agent" 的变量,必须和 langgraph.json 里冒号后面的名字完全一致!最终启动与验证
1. 启动服务 在项目根目录打开终端(进入到当前项目的父目录),输入:
bash
langgraph dev参考示例如下:输入cd graph_api 
2. 进入界面 在终端打印出的图案下方,找到 Studio UI 的链接: https://smith.langchain.com/studio/?baseUrl=http://127.0.0.1:2024
按住 Ctrl (或 Cmd) 点击它,浏览器就会自动打开。
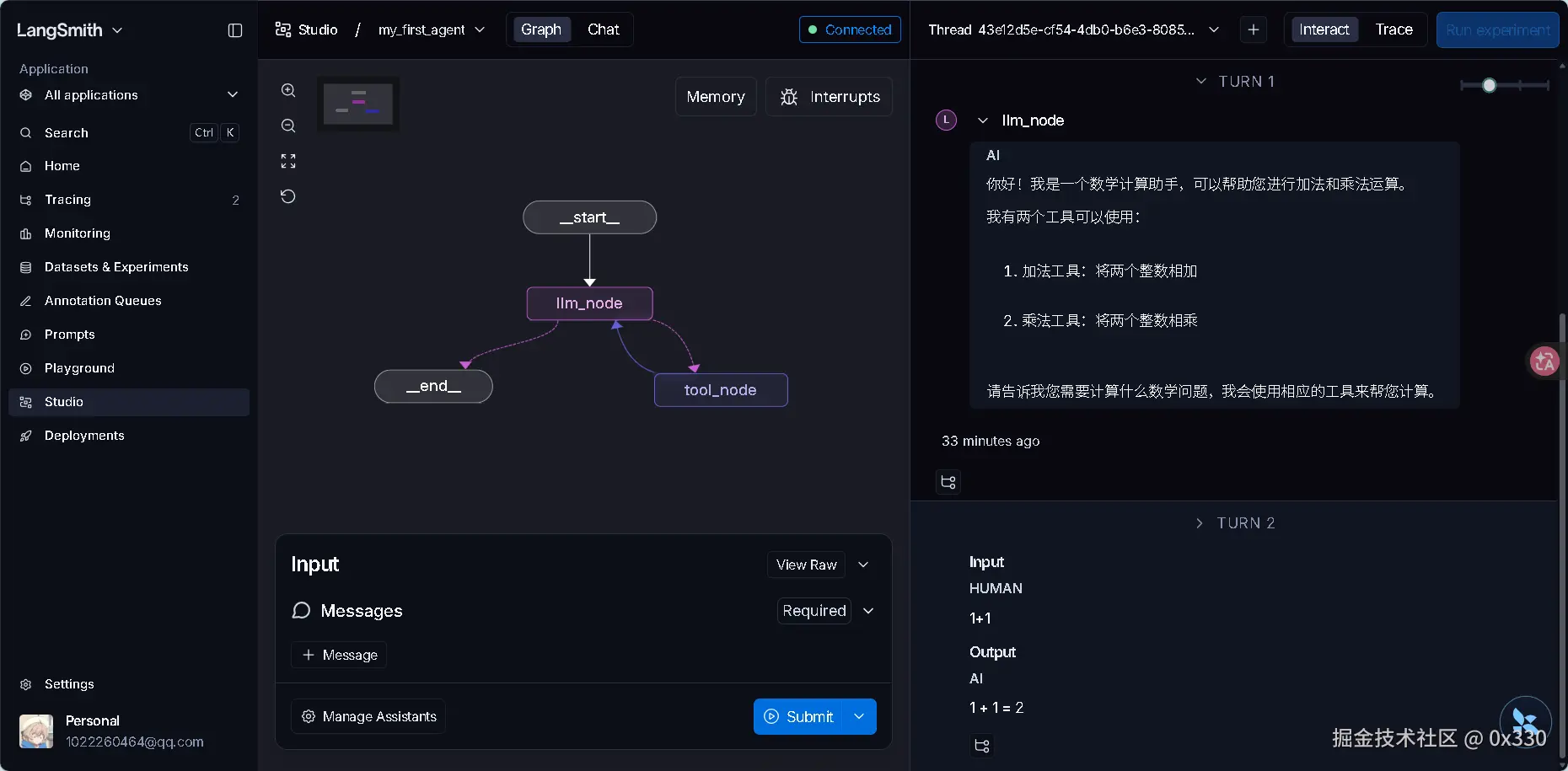
Lang Studio 可视化面板
三大核心控制面板:
当你打开 Studio,整个界面大致分为左、中、右三个核心工作区:
- 左侧面板 (Threads & Config):会话与配置中心
- Threads (线程) :这里管理着你的"记忆"。你在代码里用
MemorySaver实现的记忆,在这里被具象化了。每次新建一个 Thread,就相当于开了一个全新的干净对话上下文。 - Configuration:如果你在代码里定义了可配置项(比如切换模型种类、系统提示词),可以在这里实时调整,无需改代码。
- Threads (线程) :这里管理着你的"记忆"。你在代码里用
- 中间面板 (Interaction):交互与时间轴
- 这是你与 Agent 互动的区域(类似于 ChatGPT 的聊天框)。
- 神级细节 :当你发送消息后,这里不仅会显示最终结果,还会以时间轴 的形式,列出 Agent 经历的每一个步骤 (Steps)。
- 右侧面板 (Graph & State):全局视野与 X 光机
- Graph 视图:完美渲染了你代码中写的 Nodes(节点)和 Edges(连线)。
- State 视图 :这是最重要的地方! 实时显示当前整个图的全局变量字典。
进阶指南:可视化调试
步骤 1:审查架构图 (Visualizing the Graph)
在还没开始对话前,先看右侧的 Graph 标签页。
- 检查连线逻辑是否符合预期(比如你的
llm_node是否有一条条件边指向tool_node,tool_node是否又指回了llm_node)。 - 提示:如果有死循环或者断头的节点,在图上会非常显眼。
步骤 2:发起第一次调用 (Invoking)
- 在左侧点击 "+" 新建一个 Thread。
- 在中间底部的输入框中,输入初始状态数据。注意,这里要求输入的是 JSON 格式 (对应你的
MessagesState)。- 例如,输入:
{"messages": [{"role": "user", "content": "3乘以5等于多少?"}]}
- 例如,输入:
- 点击 Submit。
- 查看 :盯着右侧的拓扑图!你会看到
START节点闪烁,数据流入llm_node,接着条件边触发跳转到tool_node,最后再回到llm_node输出结果。
步骤 3:查看数据 (Inspecting State)
如果大模型胡言乱语,或者工具报错了,怎么办?
- 看中间面板的时间轴,点击那个报错的、或者你觉得可疑的 Step。
- 此时,右侧面板切换到 State 标签。
- 你会看到在那个特定时间点 ,全局字典(包括所有的历史消息、大模型生成的 tool_calls ID、工具的中间返回结果)长什么样。这比你在 Python 里到处写
print()要高效一万倍。
步骤 4:时光倒流 (Time-Travel Debugging)
假设你的 Agent 在第 3 步做了一个极其愚蠢的决定(比如调错了工具):
- 在中间面板,点击第 2 步(出错前的那一步)。
- 此时右侧会出现一个 "Fork" (分叉) 或 "Edit" (编辑) 按钮。
- 点击修改当时的状态(比如,你手动把大模型的系统提示词改严厉一点,或者直接篡改它发出的工具调用参数)。
- 点击 "Proceed" (继续运行)。
- Studio 会从第 2 步开始,沿着你篡改后的新现实,重新往下执行,并生成一条全新的分支记录!
热重载 (Hot Reload)
由于是带着 [inmem] 启动的,这个 Studio 是监听着你的本地文件的。 当在 Python 代码里修改了一个节点的逻辑,或者加了一个新的连线,只要按下 Ctrl+S 保存,浏览器里的 Graph 拓扑图会瞬间自动刷新