同一个 UE,至少有 5 层:
-
源代码层 (
.cpp/.h/.cs) -
构建规则层(怎么按平台/配置编译,依赖哪些 SDK/库)
-
依赖内容层(第三方库、工具链、平台资源,不全放在 Git)
-
目标二进制层(Win/Mac/Linux/Android/iOS 各自编译结果)
-
分发安装层(Launcher 给普通用户的"可直接用"版本)
你问"为啥不统一",实际上是在问:
为什么第 5 层不能完全覆盖第 1~4 层所有需求。
UnrealBuildTool 是 C# 程序(net8.0),并且会把平台扩展源码按路径 glob 进来编译。
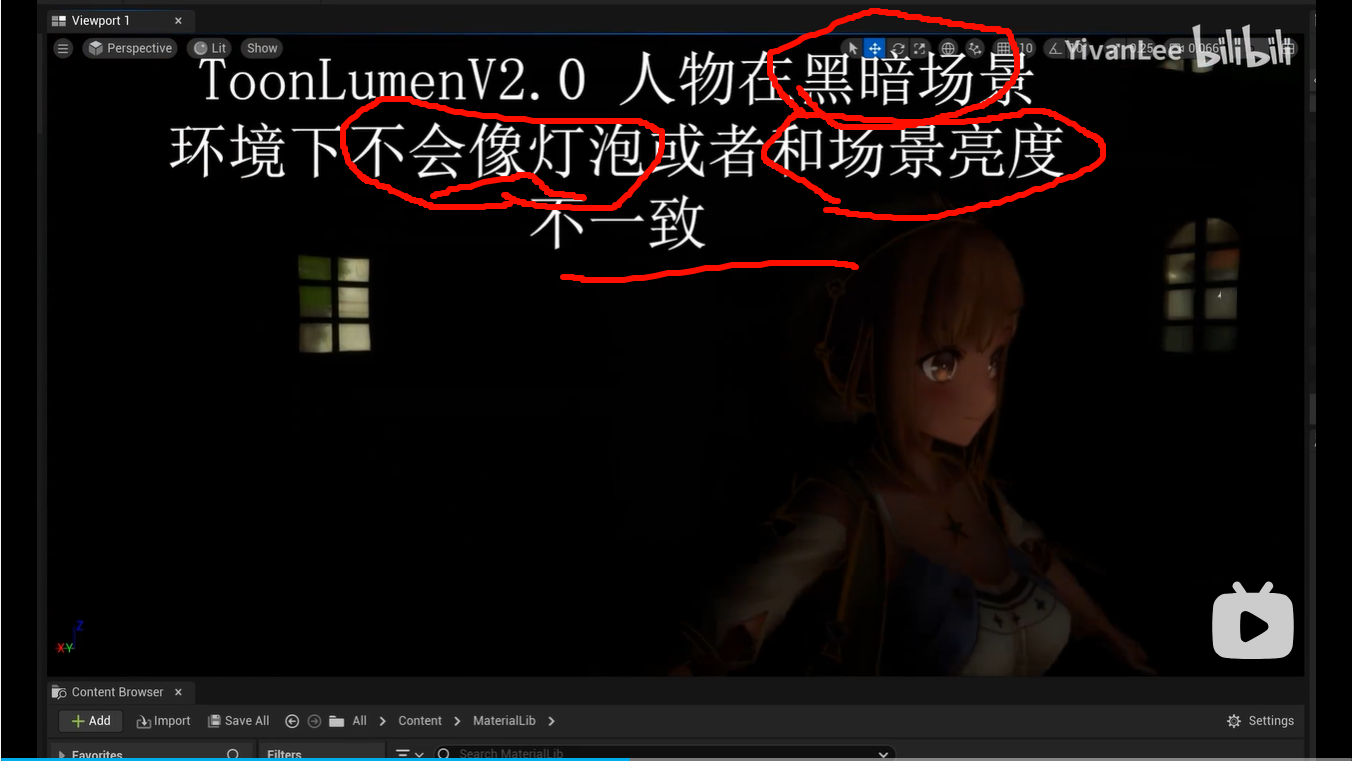
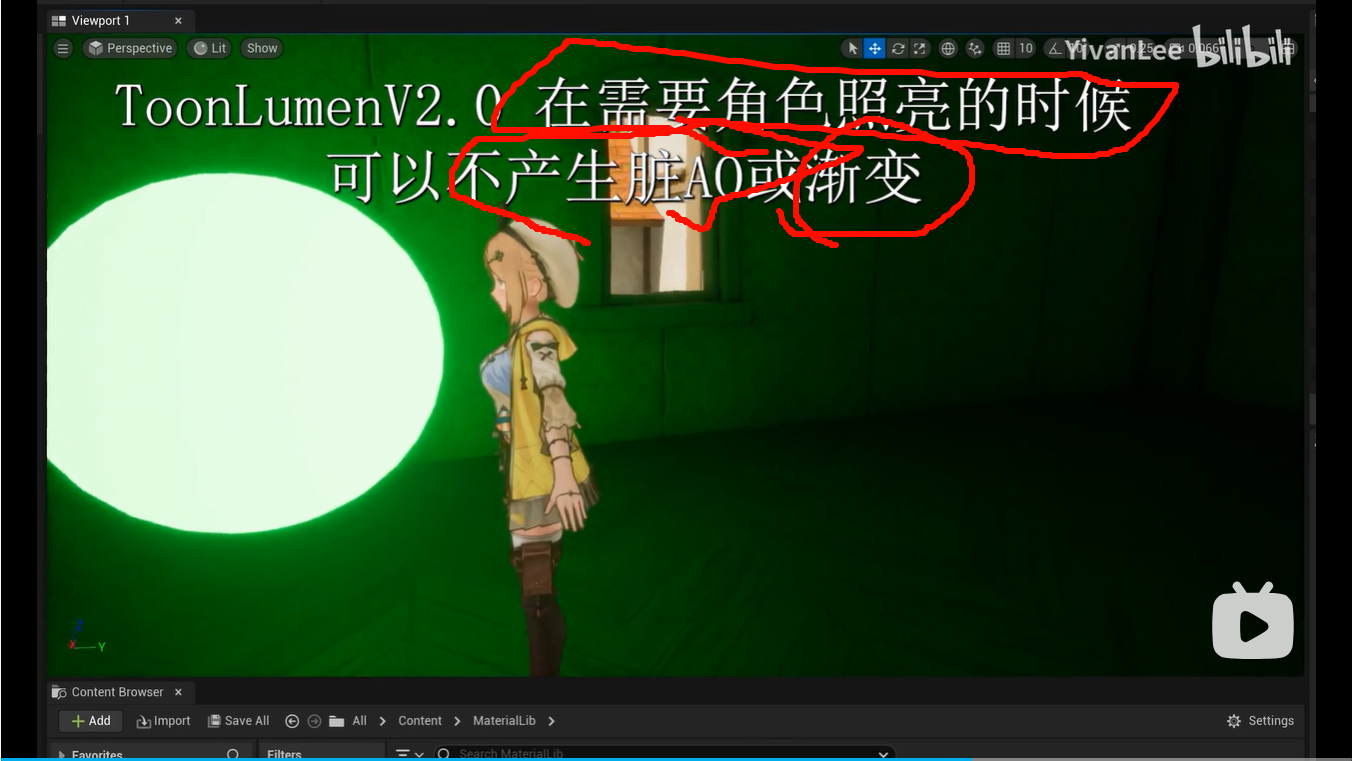
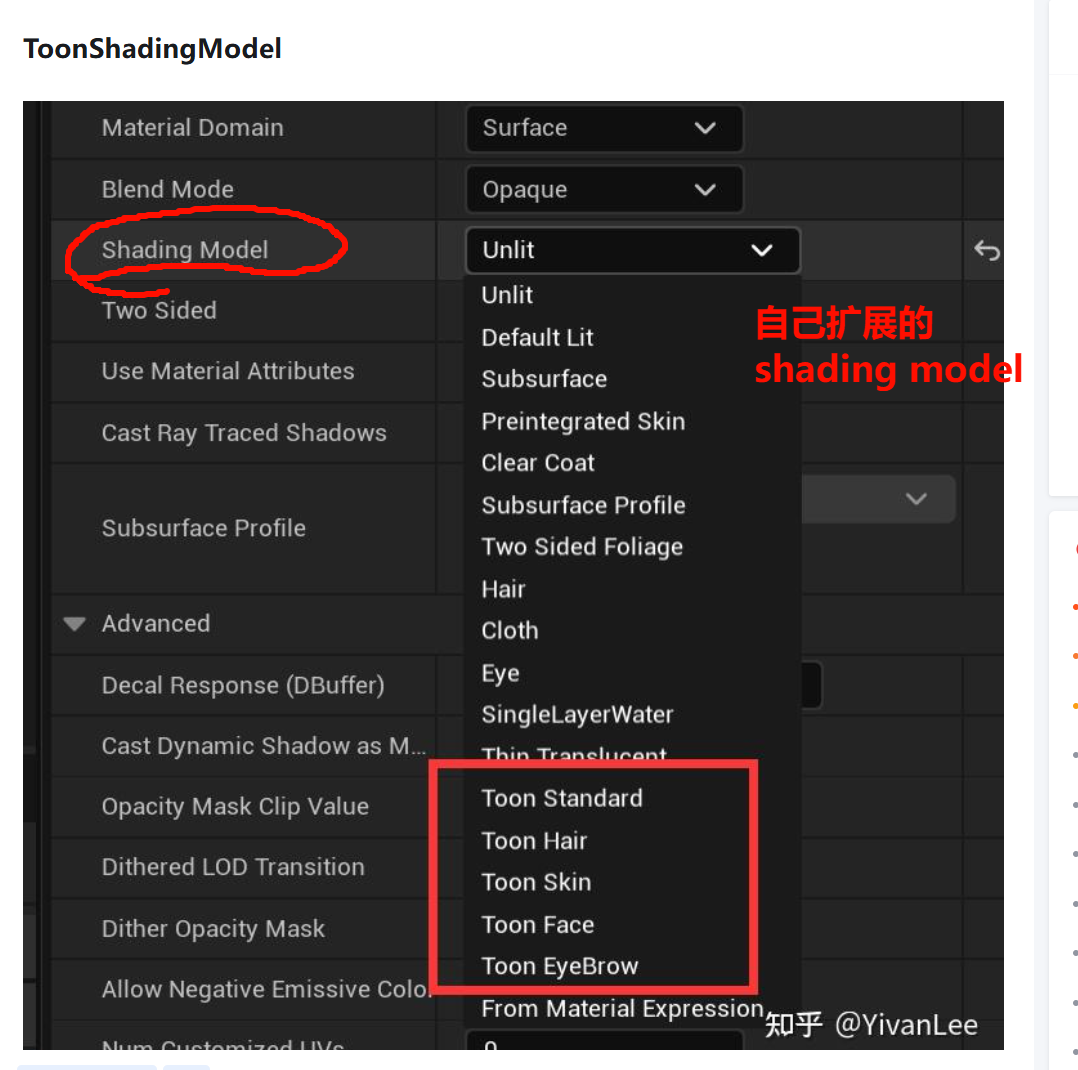
接进引擎光照体系,风格化材质才能保留"被场景照亮"的可信度。你搜到的 UE 自定义 cel shading 视频里,作者会强调"true lighting calculation""fully reactive to Unreal's lighting system, including Lumen",这就是他们在追求的点:不是屏幕后处理套一层,而是材质本身仍然是受光表面。YouTube+1
材质本身仍然是受光表面。如果你只是做 Unlit + 手写一点 NdotL,当然能出图,但通常会牺牲一部分体系兼容性。Unity 官方对自定义光照的定位也很清楚:它可以带来独特外观或更低成本,但你是在控制光照模型本身,这意味着你要自己决定保留哪些系统、放弃哪些系统。能出图当然牺牲兼容性保留哪些系统系统放弃系统
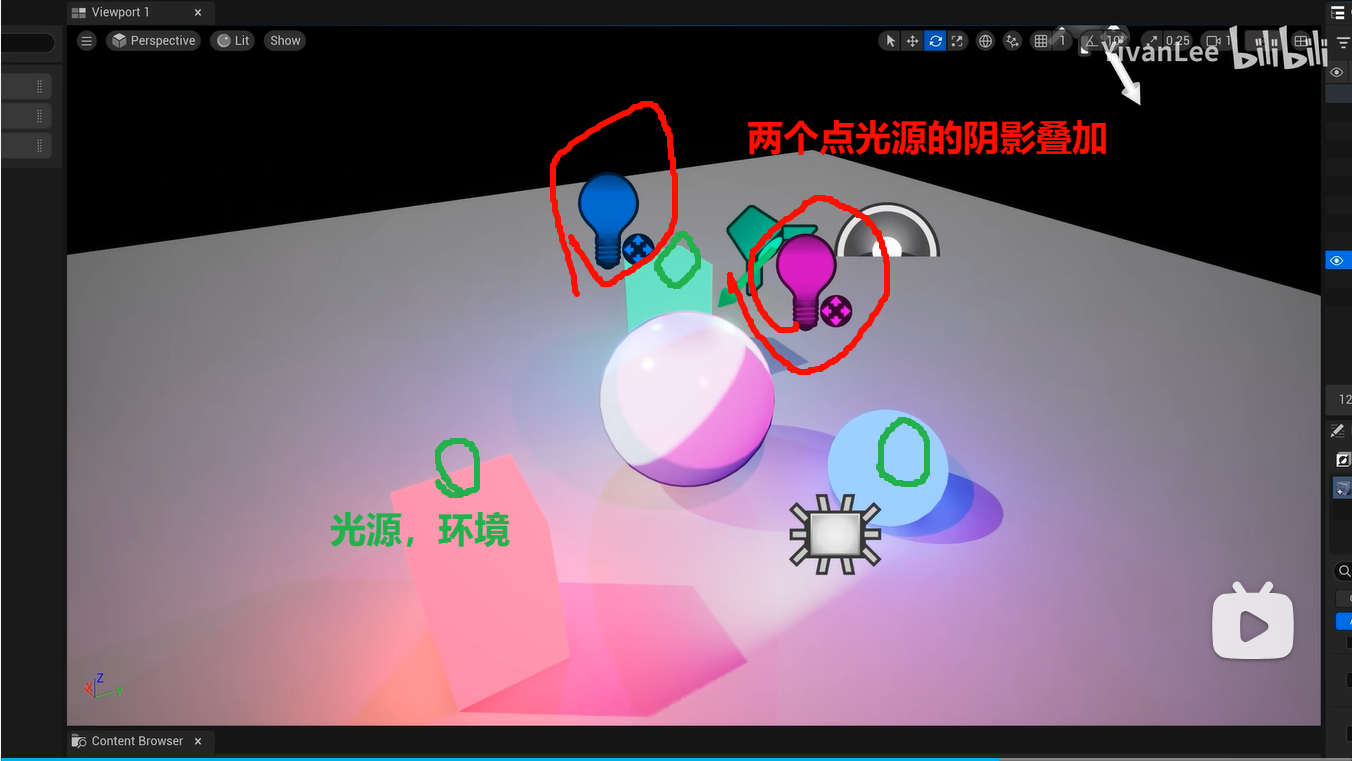
"合并 UE 阴影和自阴影 mask"
说明他关心的不是普通阴影概念,而是两类阴影信息怎么一起工作:
一类是 UE 引擎本身算出来的场景阴影
比如主光阴影、投射阴影、shadow map、VSM 一类引擎已有阴影结果。
另一类是"自阴影 mask"
通常在 NPR / toon / 风格化渲染里,指角色自己额外准备的一张控制图,或者某种基于法线、方向、区域绘制出来的假阴影/控制遮罩,用来决定脸、头发、衣服等部位该怎么分块受阴影。
他想知道的重点,大概率是这几个问题:
-
UE 原生阴影怎么拿到
也就是在材质、shader 或自定义 shading model 里,怎么读取或利用引擎已有的阴影结果。
-
自阴影 mask 怎么定义
这张 mask 是贴图、顶点色、UV 区域、方向判定,还是别的东西。
-
两者怎么合并
比如:
-
直接相乘?
-
取 min / max?
-
一部分当遮挡,一部分当风格控制?
-
怎么避免重复变黑?
-
怎么保证角色既跟场景互动,又保留二次元分块阴影风格?
-
最终为什么这么合并
也就是背后的设计原则:
-
哪些地方交给 UE 真实阴影
-
哪些地方交给自定义 mask
-
为什么这样做画面更稳定、更像动画风格

只需要一个点光源位置,对入射角和反射角的影响作用-----==BRDF
- 只需要计算一个点光源(Point Light),你只需要查一下这个函数在特定入射角和出射角下的值,乘上光强和法线夹角,就得到了结果。
- 比如 Lambert 、Phong 或 Cook-Torrance,本质上都是不同复杂程度的 BRDF 函数。


Cascadeur uses a variety of keyboard shortcuts to streamline the animation and posing process. You can also view and customise these by going to Settings → Hotkey Editor. 1, 2, 3, 4, 5
Essential Navigation & Camera
- Alt + LMB: Rotate camera.
- Alt + RMB: Zoom camera.
- Alt + Middle Mouse (Hold): Pan/Move camera.
- T: Focus camera on the selected object.
- Ctrl + Alt: Snap the camera to the nearest axis. 3, 6, 7
Manipulators & Tools
- Q: Selector tool.
- W: Translate (Move) manipulator.
- E: Rotate manipulator.
- ~ (Tilde): Switch between Global and Local modes.
- S: Toggle between View mode and the current Edit mode.
- Shift + S: Switch between Point and Box Controller modes. 3, 6, 8, 9
Animation & Timeline
- X or Space: Play/Pause animation.
- D / A: Move to the Next/Previous frame.
- Shift + D / Shift + A: Move to theNext/Previous Keyframe.
- Z: Return to the first frame.
- F: Add or remove a Keyframe.
- Alt + F: Add/remove keyframes on a selected interval.
- Ctrl + "+" / Ctrl + "-": Increase or decrease the scroll bar max frame. 3, 5, 8, 10, 11
Visibility & Selection
- V: Hide the selected object.
- Alt + V: Make all objects visible.
- Ctrl + A: Select all objects.
- Shift + Z: Toggle AutoPosing or deactivate selected controllers. 3, 6, 7, 8, 12, 13
Interpolation & Posing
- B: Set Bezier interpolation for selected frames.
- Shift + F: Change to an FK (Forward Kinematics) key.
- R: Fix or unfix selected controllers in AutoPosing. 3, 8, 11, 13
Would you like a guide on how to customise these keys or more info on using AutoPosing?
直接拿引擎主光 shadow map / VSM / CSM 那张贴图来采样
通常不行。UE 的阴影系统是引擎内部渲染流程的一部分,阴影会通过不同路径参与最终光照,尤其在 deferred、forward、移动端、Virtual Shadow Maps 等模式下,阴影数据的来源和使用方式并不统一。官方文档也明确把这些阴影实现分成多种系统,而不是一个统一、可在材质里随便读的"阴影贴图接口"。在材质里知道"当前像素是否在阴影中"
标准材质里也没有一个通用、官方暴露出来的"ShadowFactor"节点给你直接读。能直接做的是一些相关但不等价的东西,例如 Shadow Pass Switch,它是让材质在"阴影投射 pass"里走另一套分支,不是给你读取接收阴影结果;而且社区讨论里也提到它在某些场景下还有限制,比如 Nanite。把 shadow attenuation 或 shadow map 采样结果暴露给材质。
这条路是最"正统"的,因为确实很多自定义 shading model / toon shadow 做法都会改引擎,把光照或阴影信息塞进材质可见的数据流。Epic 社区里甚至有专门教程讲"在 Forward Renderer 里把 lighting data 暴露进 material graph",其卖点就是不再受 GBuffer 限制 ,本质上也是因为默认情况下这些数据并没有直接开放给材质图。作者是不是自己做了一张假阴影图 。
这条路在不改源码时更常见,比如用 SceneCaptureComponent 从主光方向捕一张深度到 Render Target,再自己在材质里做 shadow map 判定。论坛里有人就明确说过:如果不改引擎、又想在 base pass 前生成一张可采样的 shadow map,能想到的办法就是自己用正交 Scene Capture 抓深度,然后自己把 shadow map 系统从头做一遍 工具链对 PC/移动这些公开平台,技术约束是第一位;对主机平台,技术约束和授权约束同样重要,而且后者经常直接决定分发形态。Epic 官方 2026 年的主机开发知识库明确写了,console development resources 是免费但受 NDA 门控访问的最上面一整条,是"总控区 / 顶部工具栏"。
这里主要负责全局控制:播放、暂停、录音、速度 BPM、拍号、吸附、编辑模式、窗口切换、工程菜单之类。你可以把它理解成"驾驶舱"。它不直接放音乐内容,而是控制整个工程怎么播放、怎么编辑。左边这一大列,是"浏览器 / 素材库"。
这里用来找东西:鼓组、采样、预设、工程文件、插件数据库、FL Cloud 里的 sounds/packs 等。你现在截图里显示的就是素材浏览区域,下面那些 loop、pack 都是在这里选。它的作用很简单:找素材,然后拖到别的区域去用。
你可以把它理解成"仓库"。中间你圈出来的推子区域,是"混音台 Mixer"。
每一列是一个 Mixer Track,也就是一个混音通道。这里看音量、电平、声像、效果器链、发送路由。比如你的 808 Kick、Clap、HiHat 最终通常都会分配到某个 Mixer 插槽,然后在这里做 EQ、压缩、混响、限制器之类。可以把它理解成"调音台"。右边最大这一块,是"播放列表 Playlist / Arrangement"。
这是你真正"排歌"的地方。Pattern、Audio Clip、Automation Clip 都会摆在这里,按时间线展开。上面横向是时间,左边纵向是轨道。你把鼓点、旋律、音频、人声、自动化排进去,最终歌曲结构就是在这里完成的。
你可以把它理解成"时间轴画布"。


,YouTube 官方明确支持的是"判定机制"的大部分;"排队 2--24 小时"这种说法不是我能从官方文档里确认的,更像经验总结,不应当当成规则。
具体拆开看。
关于"判定机制",大体是真的。YouTube 官方帮助中心明确写了,视频没有自动字幕,可能原因包括:
-
还在处理复杂音频
-
该视频语言不受支持
-
视频太长
-
音质差,系统无法识别语音
-
开头有很长的静音
-
多人重叠说话,或同时存在多种语言
所以你截图里"没人说话 / 只有背景音乐,系统判断不出语音内容,所以不出自动字幕"这个方向,和官方机制是一致的。官方没有用"判断不出语音内容"这句口语化表述,但它明确说了"poor sound quality or YouTube doesn't recognize the speech"以及"long period of silence at the beginning"。
另外,截图里"只支持英语、日语等少数语言"这一句,现在看是明显不准确的。YouTube 官方当前列出的自动字幕支持语言很多,包含 Chinese、English、Japanese、Korean、French、German、Spanish、Russian 等一长串,并不是"少数语言"。
这些效果被consider为优秀的效果
Mali Graphics Debugger 这个名字基本已经退场了;工具本体被 Arm 重新品牌化为 Graphics Analyzer,并且整体又被并入 Arm 的整套性能工具链。 ARM Documentation Service+1
更具体一点:
Arm 在官方文档里明确写了,Graphics Analyzer 是 Mali Graphics Debugger 的 rebranded version ,并且会在后续版本里替代 Mali Graphics Debugger 。改名的原因也写得很直接:它不再只面向 Mali GPU 平台,而是要做更通用的图形调试工具。也就是说,MGD 作为产品名已经属于旧称 ,你现在再找 Arm 的新资料,应该优先找 Graphics Analyzer 。 ARM Documentation Service
OpenCL 是一个 开放标准的通用并行计算框架 。全称是 Open Computing Language。
它的核心目的不是图形渲染,而是:
让你把一部分计算任务从 CPU 分发到 GPU、DSP、NPU 或多核 CPU 上并行执行。
你可以把它理解成:
-
OpenGL / Vulkan:主要管图形渲染
-
OpenCL:主要管通用计算
-
也就是常说的 GPGPU(General-Purpose GPU Computing)
比如这些任务很适合 OpenCL:
-
图像处理
-
视频后处理
-
粒子/物理仿真
-
矩阵运算
-
卷积、滤波
-
一些机器学习前后处理
-
大规模并行数值计算
它的基本模型大概是这样:
-
Host
通常是 CPU 侧程序,负责准备数据、创建上下文、分配 buffer、下发 kernel。
-
Device
真正执行并行计算的设备,比如 GPU 或 CPU。
-
Kernel
你写的计算函数,运行在 device 上。
并行执行模型:
-
kernel 会启动很多个 work-item
-
work-item 会组成 work-group
-
很像 CUDA 里的 thread / block
一些 GPU 调试工具不只支持:
-
图形 API:OpenGL / Vulkan
还支持:
-
计算 API:OpenCL
也就是说,这类工具不只是抓 draw call,也能看:
-
OpenCL kernel 提交
-
buffer/image 读写
-
kernel 执行耗时
-
device 端计算过程
-
CPU/GPU 同步问题
这在移动端 SoC 上很常见,因为同一颗 GPU 既能做渲染,也可能被拿来做计算。
现在工程实践看,OpenCL 的位置没有以前那么强势了,原因大致有几个:
-
在移动端和图形引擎里,很多通用计算被转向 Vulkan Compute
-
苹果生态基本转向 Metal
-
NVIDIA 生态更多是 CUDA
-
一些 AI/视觉链路会走更专门的推理框架
所以今天你仍然会看到 OpenCL,但它已经不是所有平台上的"唯一通用 GPU 计算方案"。
在 PC/主机开发 里:
-
NVIDIA:Nsight Graphics
-
AMD:Radeon GPU Profiler / Memory Visualizer / GPU Detective
-
Windows D3D:PIX
这几套已经覆盖了绝大多数核心需求。GPUOpen+3NVIDIA Developer+3GPUOpen+3
在 移动开发 里:
-
Arm:Graphics Analyzer / Streamline / Frame Advisor 这一系
-
Qualcomm:Snapdragon/Qualcomm Profiler 这一系
-
Imagination:PVRTune
-
同时跨厂商越来越多人会直接用 AGI 、RenderDoc 这类更通用的工具做第一轮定位
所以移动端不是没有 vendor profiler,而是只有当你真要吃透某家 GPU 的硬件 counter、tiler、带宽、shader ISA 特征时,它们才重新变得必要 。Qualcomm Developer+2ImgTec Docs+2
如果换成更工程化的表述:
-
通用调试抓帧:越来越趋向通用工具
-
深度性能归因:仍然离不开厂商工具
- 市场形态:移动GPU市场几乎全部为集成GPU(集成在SoC中),受手机游戏和端侧AI需求推动。
- 核心玩家 :移动GPU的核心设计/制造商包括 ARM (Mali/Immortalis) 、高通 (Adreno) 、苹果 (Apple GPU)
- 联发科 (MediaTek) :份额约为 34%,凭借在安卓市场的强劲出货量位居第一。其高端系列通常采用ARM的最新GPU(如Immortalis)。
- 苹果 (Apple) :份额约为 23%,在高端手机市场拥有绝对份额。其GPU为自研架构,图形性能和能效长期处于行业领先。
- 高通 (Qualcomm) :份额约为 21%,Adreno GPU被广泛用于旗舰和高端骁龙芯片,在游戏手机和高端市场中表现极强。
- 紫光展锐 (UNISOC) :份额约为 14%,在入门级和中低端市场出货量很大。
- 海思 (HiSilicon) :份额约为 4%,随着麒麟芯片的回归逐步回升。
Arm(安謀控股,Arm Holdings plc)
是一家總部位於英國的全球頂尖半導體智慧財產權(IP)提供商 。它在半導體產業鏈中處於上游 ,不從事晶片生產,而是設計 CPU(中央處理器)架構 。與「ARM」的區別: 通常提到的「ARM 架構」(如 ARMv8、ARMv9)是指技術,而「Arm 公司」則是設計這些技術的實體。
Mali 和 Immortalis 是
Arm 公司 設計的兩種不同定位的圖形處理器(GPU)Mali/Immortalis:由 Arm 公司設計、授權給高通、聯發科、三星等廠商使用的 GPU IP。它們專為行動裝置(如手機)提供圖形與 AI 運算效能。
Key GPU IP Solutions and Technologies:
- Imagination DXT/DXTP GPU: Designed for high-performance mobile gaming and AI acceleration in smartphones, emphasizing ray tracing and energy efficiency.
- Imagination E-Series & A-Series: Tailored for automotive, embedded systems, and consumer electronics, providing high performance and configurable scalability.
- VeriSilicon Vivante: Scalable IP covering low-power IoT devices to high-performance SoCs, featuring 2D composition and AI-capable 3D GPU cores.
- RISC-V Compatibility: Modern GPU IP is increasingly optimized for RISC-V architectures to provide flexible, open-standard SoC designs.
现代 GPU IP 越来越针对 RISC-V 架构进行优化,以提供灵活的、开放标准的 SoC 设计。RISC-V 兼容性可授权的图形处理核心设计集成到用于移动、汽车和边缘人工智能应用的片上系统 (SoC) 中 领先的供应商Leading providers, notably Imagination Technologies (PowerVR) and VeriSilicon (Vivante), offer scalable IP for high-performance graphics,GPU IP (Intellectual Property) refers to licensed graphics technology
Imagination's PowerVR, Arm Mali, or VeriSilicon Vivante---integrated into Systems-on-a-Chip (SoCs) to provide specialized graphics, AI acceleration, and rendering for mobile, automotive, and IoT devices
.(SoC) Structure: A single chip containing a GPU, CPU, AI accelerators (NPU), and memory,IP Providers:晶片設計人員為了能在最短時間內將更多樣的功能整合到系統單晶片(SoC)中第三方業者提供的矽智財(SIP),而非自行開發,已逐漸成為一種趨勢。半導體製程進展到28/20奈米世代,製造與設計能力間的落差也越來越大。晶片設計人員為了能在最短時間內將更多樣的功能整合到系統單晶片(SoC)中,採用第三方業者提供的矽智財(SIP),而非自行開發,已逐漸成為一種趨勢。透過運用高品質、完整的第三方IP解決方案,晶片設計人員能將資源專注於開發具差異化特性的產品,包括連結各種IP模塊的設計方式。因此,這已使得SIP市場近年來成長的快速。特別是,在行動裝置、各類消費性電子創新設計帶動下,處理器IP市場的漲勢最高,達21.2%,表現優於整體市場。處理器IP中,GPU(繪圖處理器) IP由於具備平行處理特性,有更佳的可擴充性,已成為近來推動行動SoC效能提升的重要力量全球前20大的領先半導體與OEM業者,包括英特爾、聯發科、Sony、三星等知名業者都是採用第三方業者提供的矽智財(SIP),全球第三大SIP業者的Imagination Technologies指出,隨著消費電子產品越來越有「智慧」(GUI)需要更高的畫素處理能力以Imagination所提供的SoC IP組合來說,包括PoweVR繪圖、視訊、顯示IP、MIPS CPU IP、創新的Ensigma通訊IP,以及HelloSoft V.VolP與VoLTE IP、和Flow雲端連接性IP解決方案。此外,Imagination在今年初併購MIPS後,強化了其既有的CPU IP產品組合。Imagination原本就已積極開發CPU技術,納入MIPS後,將更能加速此計畫的實現。
GPU IP成為行動SoC差異化關鍵
Imagination成立於1985年,是英國領先的先進SoC IP開發商圖形技術基於獨特的分塊延遲渲染(TDBR)技術,從一開始就支援智慧手機市場,將遊戲和娛樂帶入數百萬使用者手中。Imagination在車載圖形方面擁有45%的市佔率,目前馬路上有超過3億輛汽車運用我們的技術------您的汽車便很有可能內建Imagination IP。Imagination設計技術,但並不製造任何實體產品。IP業務模式由獲得我們技術授權的公司將其整合至自身的解決方案中。當然,我們不只讓客戶自己去做:我們更與其密切合作。我們在授權IP許可時收取費用,也從所售產品中收取權利金,因此,客戶的產品在市場上取得成功,即肯定符合我們的利益。他們考慮前期投資時,他們沒有考慮總體擁有成本當晶片公司做出這個「設計或購買」的決定時,他們的總成本通常會增加2到5倍。即便公司對研發技術的成本有深入的認識,但就內部工程資源而言,他們往往低估了從零開始創建所需技術之挑戰。他們不僅要創造一種高度複雜的技術,而且必須設計出一種在首次嘗試時,就具有競爭力的技術,而且所有這些都不能侵犯該領域的基本專利。
使用IP對客戶的優點包括:
- 縮短上市時間
- 增加收入
- 降低技術風險和成本
- 協助保護客戶免受專利侵權等法律挑戰
- 符合業界技術標準
- 提供軟體工具、支援和協力廠商生態系統等資源
- 加快產品上市時間,因為IP供應商具有比被授權方更具競爭力的IP
https://www.eettaiwan.com/20211014nt41-why-you-should-choose-you-next-soc-with-imagination-ip/
【英國倫敦】─2022年1月24日─ Imagination Technologies和晶心科技(Andes Technology)聯合宣佈:雙方合作借助與RISC-V相容的Andes AX45處理器核心,成功測試和驗證了IMG B系列圖形處理器(GPU)。Andes AX45是一款64位元高性能和可配置的超標量中央處理器(CPU)。此次驗證合作為AR/VR、車載資訊娛樂系統(IVI)、工業和物聯網(IoT)產品領域的客戶提供了一種經過驗證的、完整的解決方案,並為後續的持續測試奠定了基礎。Imagination Technologies硬體工程副總裁Colin McKellar表示:「RISC-V是一種不斷發展壯大的CPU架構。我們使用Andes AX45 RISC-V CPU來驗證IMG B系列GPU的成功,突顯了這兩個平台的靈活性。Imaginations生態系統的可定制化特性使我們能夠在不到一周的時間內,就可快速開發出一個完整的工作系統原型,即從集成到實現再到驗證。」晶心是RISC-V國際協會的創始首席會員,也是第一家採用RISC-V作為其第五代架構AndeStar™基礎的主流CPU供應商。
SoC(System on Chip)通常就是把 CPU IP、GPU IP,以及一堆其他功能 IP 集成到同一颗芯片里。
更完整地说,SoC 一般包含这些大块:
-
CPU IP:负责通用控制、逻辑、游戏主线程、系统调度
-
GPU IP:负责图形渲染,很多时候也负责部分并行计算
-
内存子系统:内存控制器、缓存一致性互连、带宽仲裁
-
多媒体 IP:视频编解码、ISP、显示控制器
-
AI / NPU / DSP:推理、音频、图像、信号处理
-
I/O 与外设控制器:USB、PCIe、UFS、SDIO、网络、传感器接口
-
安全模块:TrustZone、安全启动、加解密单元
-
片上互连:NoC / bus fabric,把各 IP 连起来
所以从芯片公司视角,SoC 并不只是"一个 CPU 加一个 GPU",而是:
很多不同功能的 IP block 通过片上互连和内存系统组织成一个完整计算平台。
Intellectual Property Core ,不是网络 IP。
也就是可复用的芯片设计模块,比如:
-
Arm 提供 CPU IP:Cortex-A、Cortex-X
-
Arm 也提供 GPU IP:Mali
-
Imagination 提供 GPU IP:PowerVR
-
其他厂商可能自研 CPU、GPU、NPU,或者混合采购授权
例如一个手机 SoC 可能是:
-
CPU:Arm Cortex-X + Cortex-A7xx + Cortex-A5xx
-
GPU:Mali 或 Adreno
-
ISP:自研
-
NPU:自研
-
Modem:自研或外挂
这些一起才构成完整 SoC。
渲染优化时盯的是 GPU IP 的架构特性 线程调度、脚本、资源上传、driver interaction 时常受 CPU IP 和内存系统 影响最终性能问题往往是 整个 SoC 级别 的,而不是单看 GPU移动端为什么总提 SoC?
因为手机和平板几乎天然就是这种形态:整个平台高度集成、省电优先、板级空间极小,所以大家天天说骁龙、天玑、Exynos、Apple A 系/M 系,本质上都在谈 SoC。
所以在传统桌面 PC 语境里,大家更常讨论的是:
-
CPU
-
dGPU(discrete GPU)
-
芯片组
而不是把整个平台口语上统一叫 SoC
NVIDIA GeForce / AMD Radeon 独显 :只是 GPU 子系统,通常通过 PCIe 挂在平台上Arm Mali / Adreno / PowerVR :更接近"GPU IP 或 GPU 实现"骁龙 / 天玑 / Apple A/M :更接近 SoC移动端优化 :往往必须按 SoC 视角 看,因为 CPU/GPU/内存带宽/热限制强耦合
GPU IP 是"GPU 的设计内核/架构模块"。
独立显卡 是"把一个具体 GPU 芯片连同显存、供电、PCB、输出接口、散热等做成的一块板卡产品"。
可以这样拆:
1. GPU IP 是设计资产
它更像"蓝图"或"可授权的核心设计"。
例如:
-
Arm Mali 是 GPU IP
-
Imagination PowerVR 是 GPU IP
SoC 厂商拿到这种 IP 后,把它集成进自己的芯片里,和 CPU、NPU、ISP、内存控制器等一起组成 SoC。
独立显卡通常包含:
-
GPU 芯片
-
显存(GDDR6/GDDR7 等)
-
VRM 供电
-
散热器/风扇
-
PCB
-
显示输出接口
-
BIOS / 固件
比如:
-
GeForce RTX 4080 显卡
-
Radeon RX 7900 XTX 显卡
这是能插到 PCIe 槽里的成品设备。
两种产业路径:
一种是 IP 授权模式:
-
Arm 设计 Mali GPU IP
-
SoC 厂商把 Mali 集成进自家 SoC
-
最终出现在手机/平板芯片里
另一种是 垂直整合模式:
-
NVIDIA / AMD 通常不是"卖一个通用 GPU IP 给别人集成"
-
它们更多是自己定义架构、自己做 GPU 芯片产品,再做成独显或加速卡生态
在 PC 语境里,大家通常直接讨论:
-
GPU 架构
-
GPU 芯片
-
显卡产品
而不是经常把 NVIDIA GeForce 说成"GPU IP"。
可复用的 GPU 架构设计模块。
专利捆住了,强硬的设计保护措施,可行