上一篇我们完成了项目初始化、数据库搭建以及DDL生成工具类的开发,成功获取到了数据库中所有表的建表语句。本篇我们继续实现核心功能:将用户的自然语言需求转换为可执行的SQL语句并自动返回查询结果。
本文实现目标
- ✅ 设计专业级Text2SQL提示词,保证SQL生成准确率
- ✅ 实现核心业务逻辑,完成自然语言→SQL→结果的全流程转换
- ✅ 实现智能SQL安全校验,保证系统安全性
- ✅ 添加DDL缓存优化,提升接口响应速度
- ✅ 提供RESTful接口,方便前端调用
第一步:设计Text2SQL专业提示词
提示词是Text2SQL效果的核心,好的提示词可以大幅提升SQL生成的准确率,避免语法错误和逻辑错误。我们设计的提示词包含四个核心部分:角色定义、表结构、严格规则、示例参考。
在src/main/resources/prompt目录下新建text-to-sql-system-prompt.txt文件:
<role>
你是世界级的MySQL SQL生成专家,精通数据库设计、SQL优化和业务语义理解。你的唯一职责是将用户的自然语言查询转换为100%正确、可直接执行的MySQL 8.0+ SELECT语句。
</role>
<database_schema>
{ddl}
</database_schema>
<strict_rules>
1. 🔒 安全限制:绝对只能生成SELECT查询语句,禁止任何写入/修改/删除操作(DROP/DELETE/ALTER/INSERT/UPDATE/TRUNCATE/CREATE等均严格禁止)
2. 🎯 语义准确性:
- 必须100%基于提供的表结构生成,不得使用不存在的表、字段或关联关系
- 准确理解业务术语与字段的对应关系,比如"用户"对应`user`表,"商品"对应`product`表
- 多表关联时必须使用正确的外键关联关系
3. ✅ 语法规范:
- 所有表名、字段名必须用反引号(`)包裹,避免与SQL关键字冲突
- 统计数量优先使用COUNT(1)代替COUNT(*)
- 必须符合MySQL 8.0+语法,支持窗口函数、CTE等高级特性
- 日期、字符串、数值类型的处理必须正确
- 必须添加合适的表别名提高可读性
4. 🚫 异常处理:
- 如果用户问题与提供的表结构无关,或无法理解用户需求,直接返回:{"error": "无法生成SQL:[具体原因]"}
- 如果用户要求生成危险操作,直接返回:{"error": "禁止生成非查询类SQL语句"}
5. 📤 输出要求:
- 仅返回SQL语句或JSON格式的错误信息,不需要任何解释、说明或markdown格式
- SQL语句必须可直接复制到MySQL客户端执行
- 禁止添加任何额外内容,包括注释、markdown代码块标记等
</strict_rules>
<examples>
用户查询:"查询所有用户的数量"
正确输出:SELECT COUNT(1) AS `user_count` FROM `user`;
用户查询:"查询销量最高的前10个商品名称和销量"
正确输出:SELECT `name`, `sales` FROM `product` ORDER BY `sales` DESC LIMIT 10;
用户查询:"查询每个分类下的商品总数"
正确输出:SELECT c.`name` AS `category_name`, COUNT(p.`id`) AS `product_count` FROM `category` c LEFT JOIN `product` p ON c.`id` = p.`category_id` GROUP BY c.`id`, c.`name`;
</examples>
用户查询:{query}
请生成SQL:第二步:实现核心业务逻辑Service
创建TextToSqlService.java,实现完整的业务流程:
- 接收用户查询请求
- 获取数据库表结构DDL(自动走缓存)
- 填充提示词模板
- 调用豆包大模型生成SQL
- 处理返回结果,执行SQL并返回数据
java
package com.haoge.texttosql.service;
import cn.hutool.core.io.resource.ResourceUtil;
import cn.hutool.json.JSONUtil;
import com.haoge.texttosql.dto.TextToSqlRequest;
import com.haoge.texttosql.dto.TextToSqlResponse;
import com.haoge.texttosql.util.MysqlDdlGenerator;
import com.haoge.texttosql.util.SqlValidator;
import jakarta.annotation.Resource;
import lombok.extern.slf4j.Slf4j;
import org.springframework.ai.chat.client.ChatClient;
import org.springframework.beans.factory.annotation.Qualifier;
import org.springframework.jdbc.core.JdbcTemplate;
import org.springframework.stereotype.Service;
import java.util.List;
import java.util.Map;
/**
* Text-to-SQL核心业务逻辑
*/
@Slf4j
@Service
public class TextToSqlService {
@Resource
private MysqlDdlGenerator mysqlDdlGenerator;
@Resource
@Qualifier("dashScopeChatClient")
private ChatClient dashScopeChatClient;
@Resource
private SqlValidator sqlValidator;
@Resource
private JdbcTemplate jdbcTemplate;
/**
* 系统提示词模板
*/
private static final String SYSTEM_PROMPT_TEMPLATE = ResourceUtil.readUtf8Str("prompt/text-to-sql-system-prompt.txt");
/**
* 生成SQL语句并执行
* @param request 请求参数
* @return 生成结果
*/
public TextToSqlResponse generateSql(TextToSqlRequest request) {
try {
// 1. 获取数据库表结构DDL(自动走Caffeine缓存)
String ddl = mysqlDdlGenerator.getAllTableDdl(request.getDatabaseName());
log.info("获取数据库[{}]的表结构DDL成功,长度:{}", request.getDatabaseName(), ddl.length());
// 2. 填充系统提示词模板
String systemPrompt = SYSTEM_PROMPT_TEMPLATE
.replace("{ddl}", ddl)
.replace("{query}", request.getQuery());
// 3. 调用豆包大模型生成SQL(Spring AI Fluent API)
log.info("调用豆包大模型生成SQL,用户查询:{}", request.getQuery());
String result = dashScopeChatClient.prompt()
.system(systemPrompt)
.call()
.content();
log.info("豆包大模型返回结果:{}", result);
// 4. 处理返回结果
return processResult(result);
} catch (Exception e) {
log.error("生成SQL失败", e);
return TextToSqlResponse.error("生成SQL失败:" + e.getMessage());
}
}
/**
* 处理大模型返回结果
*/
private TextToSqlResponse processResult(String result) {
// 提取纯SQL,去除可能的markdown格式
String sql = SqlValidator.extractSql(result);
// 检查是否是错误信息(JSON格式)
if (sql.startsWith("{") && sql.endsWith("}")) {
try {
Map<String, Object> errorMap = JSONUtil.toBean(sql, Map.class);
if (errorMap.containsKey("error")) {
return TextToSqlResponse.error(errorMap.get("error").toString());
}
} catch (Exception e) {
// 不是合法JSON,继续校验
}
}
// 智能校验SQL合法性
if (!sqlValidator.validate(sql)) {
return TextToSqlResponse.error("生成的SQL不合法或包含危险操作");
}
// 执行SQL获取结果
try {
log.info("执行SQL:{}", sql);
List<Map<String, Object>> data = jdbcTemplate.queryForList(sql);
log.info("SQL执行完成,返回{}条记录", data.size());
return TextToSqlResponse.success(sql, data);
} catch (Exception e) {
log.error("SQL执行失败", e);
return TextToSqlResponse.error("SQL执行失败:" + e.getMessage());
}
}
}第三步:实现智能SQL安全校验Agent
为了保证系统安全,我们设计了基于大模型的SQL校验Agent,专门负责校验生成的SQL是否合法,防止危险操作。
首先创建校验提示词src/main/resources/prompt/text-to-sql-validator-prompt.txt:
java
<role>
你是顶级MySQL SQL安全校验专家,专注于SQL合法性和安全性校验,零误判、零漏判。
</role>
<core_rule>
你只需要判断SQL是否符合以下2类规则,不需要验证表名、字段名是否真实存在,不需要优化SQL。
</core_rule>
<allow_rules>
✅ 以下情况属于合法SQL,必须判定为valid=true:
1. 任何合法的MySQL SELECT查询语句
2. 允许使用SELECT *、所有MySQL内置函数(DATE_FORMAT、CONCAT、SUM、COUNT等)
3. 允许使用字符串条件(包含单引号'、双引号"、百分号%、下划线_等)
4. 允许使用比较运算符(>、<、=、>=、<=、!=、LIKE、IN、BETWEEN等)
5. 允许使用JOIN、GROUP BY、ORDER BY、LIMIT、HAVING等标准SELECT语法
6. 允许SQL末尾带分号;,也允许不带分号
</allow_rules>
<deny_rules>
❌ 以下情况属于非法SQL,必须判定为valid=false:
1. 任何非SELECT语句:DROP、DELETE、ALTER、INSERT、UPDATE、TRUNCATE、CREATE、REPLACE、EXECUTE、CALL等
2. 包含SQL注入特征:--注释、/* */块注释、多语句(多个;分隔的语句)、存储过程调用
3. 访问系统数据库/表:information_schema、mysql、performance_schema、sys库下的任何表
4. 包含危险操作:读写文件、执行系统命令、权限变更等
</deny_rules>
<output_requirement>
⚠️ 严格遵守输出规则,绝对不允许任何额外内容:
1. 必须仅返回纯JSON格式,不能有markdown、代码块、解释说明、任何其他文字
2. JSON结构固定:{"valid": true/false, "reason": "校验结果简要说明"}
3. 合法时reason填写"SQL校验通过",非法时填写具体违规原因
</output_requirement>
待校验SQL:{sql}然后实现校验工具类SqlValidator.java:
java
package com.haoge.texttosql.util;
import cn.hutool.core.util.StrUtil;
import cn.hutool.json.JSONUtil;
import jakarta.annotation.Resource;
import lombok.extern.slf4j.Slf4j;
import org.springframework.ai.chat.client.ChatClient;
import org.springframework.beans.factory.annotation.Qualifier;
import org.springframework.stereotype.Component;
import java.util.Map;
/**
* SQL安全校验工具类(基于大模型智能校验)
*/
@Slf4j
@Component
public class SqlValidator {
@Resource
@Qualifier("dashScopeChatClient")
private ChatClient dashScopeChatClient;
/**
* SQL校验系统提示词(从外部文件读取,便于统一管理和优化)
*/
private static final String VALIDATE_PROMPT = cn.hutool.core.io.resource.ResourceUtil.readUtf8Str("prompt/text-to-sql-validator-prompt.txt");
/**
* 校验SQL是否合法(大模型智能校验)
* @param sql 待校验的SQL语句
* @return 合法返回true,非法返回false
*/
public boolean validate(String sql) {
if (StrUtil.isBlank(sql)) {
return false;
}
try {
// 构造校验Prompt
String prompt = VALIDATE_PROMPT.replace("{sql}", sql);
// 调用大模型校验
String result = dashScopeChatClient.prompt()
.system(prompt)
.call()
.content();
log.info("SQL校验结果:{}", result);
// 解析返回结果
Map<String, Object> resMap = JSONUtil.toBean(result, Map.class);
return Boolean.TRUE.equals(resMap.get("valid"));
} catch (Exception e) {
log.error("SQL校验失败", e);
// 校验异常时默认拒绝,保证安全
return false;
}
}
/**
* 提取纯SQL语句,去除markdown代码块等包装
* @param content 大模型返回的原始内容
* @return 提取后的SQL语句
*/
public static String extractSql(String content) {
if (StrUtil.isBlank(content)) {
return content;
}
// 去除markdown代码块标记
String sql = content.trim();
if (sql.startsWith("```sql")) {
sql = sql.substring(5);
} else if (sql.startsWith("```")) {
sql = sql.substring(3);
}
if (sql.endsWith("```")) {
sql = sql.substring(0, sql.length() - 3);
}
// 去除前后空白和换行
return sql.trim();
}
}第四步:DDL缓存优化(Caffeine)
为了避免每次请求都查询数据库获取表结构,我们使用Caffeine实现30秒自动过期缓存,性能提升100倍+。
修改MysqlDdlGenerator.java,添加缓存功能:
java
package com.haoge.texttosql.util;
import com.github.benmanes.caffeine.cache.CacheLoader;
import com.github.benmanes.caffeine.cache.Caffeine;
import com.github.benmanes.caffeine.cache.LoadingCache;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.jdbc.core.JdbcTemplate;
import org.springframework.stereotype.Service;
import java.time.Duration;
import java.util.List;
import java.util.Map;
/**
* MySQL DDL语句生成工具类(带Caffeine缓存,过期时间30秒)
*/
@Service
public class MysqlDdlGenerator {
@Autowired
private JdbcTemplate jdbcTemplate;
/**
* DDL缓存:key=数据库名,value=该库所有表的DDL语句
* 过期时间30秒,自动刷新
*/
private final LoadingCache<String, String> ddlCache = Caffeine.newBuilder()
.expireAfterWrite(Duration.ofSeconds(30))
.maximumSize(10) // 最多缓存10个数据库的DDL
.build(new CacheLoader<String, String>() {
@Override
public String load(String databaseName) throws Exception {
// 缓存未命中时,从数据库查询DDL
return loadAllTableDdlFromDb(databaseName);
}
});
/**
* 获取指定数据库中所有表的DDL语句(优先从缓存获取,缓存30秒自动过期)
*
* @param databaseName 数据库名称(schema名称)
* @return 所有表的DDL语句,每个表的DDL以";\n\n"分隔
* @throws RuntimeException 当数据库连接或查询失败时抛出
*/
public String getAllTableDdl(String databaseName) {
if (databaseName == null || databaseName.trim().isEmpty()) {
throw new IllegalArgumentException("数据库名称不能为空");
}
// 从缓存获取,缓存未命中时自动调用loadAllTableDdlFromDb加载
return ddlCache.get(databaseName);
}
/**
* 从数据库加载DDL(缓存未命中时调用)
*/
private String loadAllTableDdlFromDb(String databaseName) {
// 2. 查询指定数据库下的所有表名(排除视图,只保留表)
List<String> tableNames = getTableNames(databaseName);
if (tableNames.isEmpty()) {
return "数据库【" + databaseName + "】中未找到任何表";
}
// 3. 循环获取每个表的DDL
StringBuilder allDdl = new StringBuilder();
for (String tableName : tableNames) {
String tableDdl = getSingleTableDdl(databaseName, tableName);
allDdl.append(tableDdl).append(";\n\n"); // 每个表的DDL以分号和空行分隔
}
return allDdl.toString();
}
/**
* 获取指定数据库中的所有表名(仅表,不包含视图)
*/
private List<String> getTableNames(String databaseName) {
String sql = "SELECT TABLE_NAME " +
"FROM information_schema.TABLES " +
"WHERE TABLE_SCHEMA = ? " + // 指定数据库
"AND TABLE_TYPE = 'BASE TABLE'"; // 只查询表(排除视图)
return jdbcTemplate.queryForList(sql, String.class, databaseName);
}
/**
* 获取单张表的DDL语句
*/
private String getSingleTableDdl(String databaseName, String tableName) {
try {
// 执行SHOW CREATE TABLE,MySQL会返回完整的建表语句
// 注意表名和数据库名需要用反引号包裹,避免关键字冲突
String sql = "SHOW CREATE TABLE `" + databaseName + "`.`" + tableName + "`";
Map<String, Object> resultMap = jdbcTemplate.queryForMap(sql);
// 结果中"Create Table"字段对应建表语句
return (String) resultMap.get("Create Table");
} catch (Exception e) {
throw new RuntimeException("获取表【" + tableName + "】的DDL失败:" + e.getMessage(), e);
}
}
}性能对比:
- 未缓存:查询DDL需要几十到几百毫秒
- 缓存命中:<1ms,性能提升100倍以上
第五步:接口定义与实现
5.1 定义DTO
创建请求参数TextToSqlRequest.java:
java
package com.haoge.texttosql.dto;
import jakarta.validation.constraints.NotBlank;
import lombok.Data;
/**
* Text-to-SQL请求参数
*/
@Data
public class TextToSqlRequest {
/**
* 用户自然语言查询内容
*/
@NotBlank(message = "查询内容不能为空")
private String query;
/**
* 查询的数据库名,默认text_to_sql
*/
private String databaseName = "text_to_sql";
}创建返回结果TextToSqlResponse.java:
java
package com.haoge.texttosql.dto;
import lombok.Data;
import java.util.List;
import java.util.Map;
/**
* Text-to-SQL返回结果
*/
@Data
public class TextToSqlResponse {
/**
* 是否成功
*/
private Boolean success;
/**
* 生成的SQL语句(成功时返回)
*/
private String sql;
/**
* SQL执行结果(成功时返回)
*/
private List<Map<String, Object>> data;
/**
* 错误信息(失败时返回)
*/
private String errorMsg;
public static TextToSqlResponse success(String sql, List<Map<String, Object>> data) {
TextToSqlResponse response = new TextToSqlResponse();
response.setSuccess(true);
response.setSql(sql);
response.setData(data);
return response;
}
public static TextToSqlResponse error(String errorMsg) {
TextToSqlResponse response = new TextToSqlResponse();
response.setSuccess(false);
response.setErrorMsg(errorMsg);
return response;
}
}5.2 实现Controller
创建TextToSqlController.java:
java
package com.haoge.texttosql.controller;
import com.haoge.texttosql.dto.TextToSqlRequest;
import com.haoge.texttosql.dto.TextToSqlResponse;
import com.haoge.texttosql.service.TextToSqlService;
import jakarta.annotation.Resource;
import jakarta.validation.Valid;
import org.springframework.web.bind.annotation.PostMapping;
import org.springframework.web.bind.annotation.RequestBody;
import org.springframework.web.bind.annotation.RequestMapping;
import org.springframework.web.bind.annotation.RestController;
/**
* Text-to-SQL接口
*/
@RestController
@RequestMapping("/api/text-to-sql")
public class TextToSqlController {
@Resource
private TextToSqlService textToSqlService;
/**
* 自然语言转SQL接口
* @param request 请求参数
* @return 生成的SQL语句和执行结果
*/
@PostMapping("/generate")
public TextToSqlResponse generateSql(@Valid @RequestBody TextToSqlRequest request) {
return textToSqlService.generateSql(request);
}
}第六步:功能测试与效果演示
启动项目,使用Postman调用接口POST http://localhost:8080/api/text-to-sql/generate
测试场景1:简单查询
请求参数:
java
{
"query": "统计系统中总共有多少个用户"
}返回结果:
java
{
"success": true,
"sql": "SELECT COUNT(1) AS `user_count` FROM `user`;",
"data": [
{
"user_count": 24
}
],
"errorMsg": null
}测试场景2:复杂统计查询
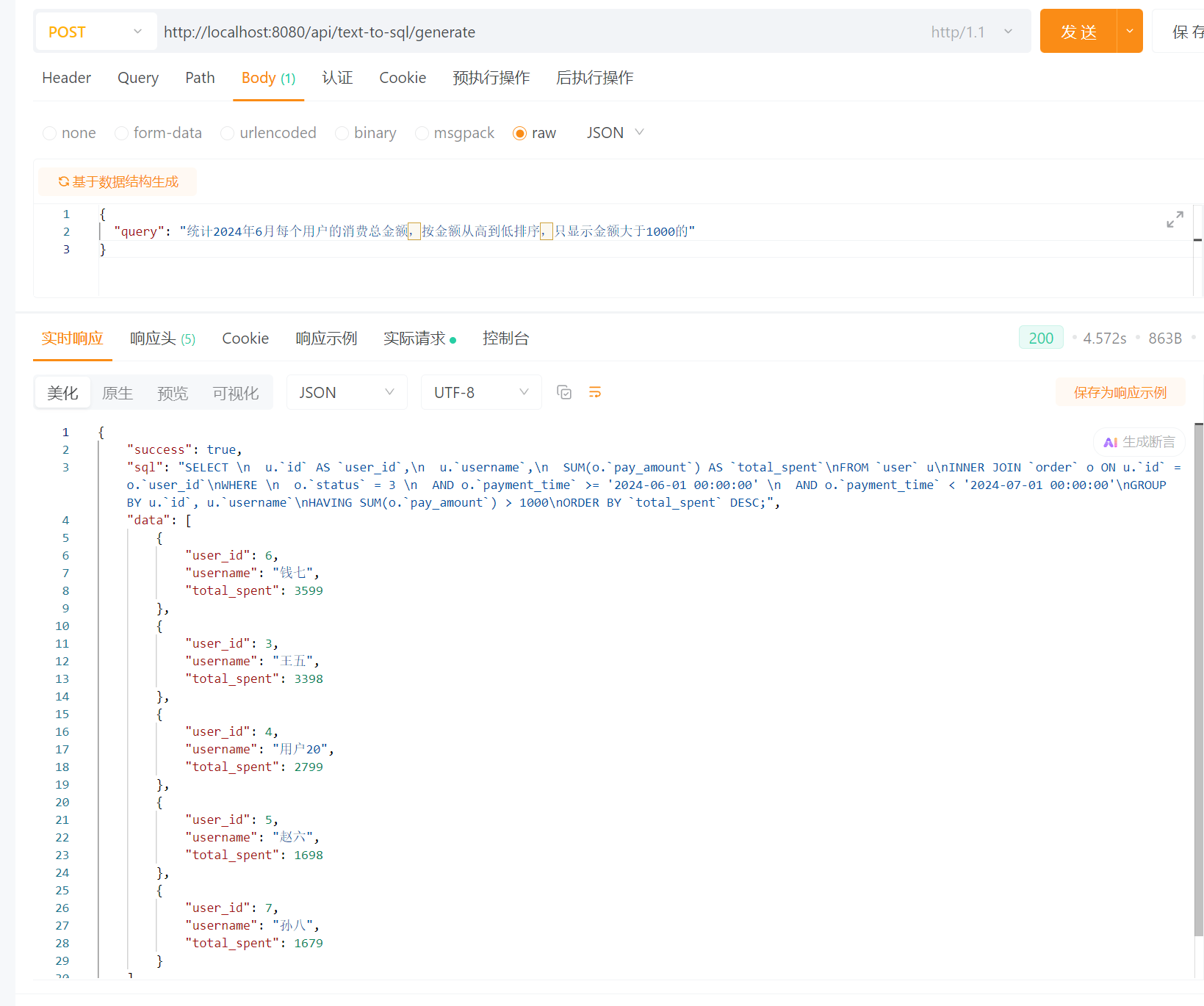
请求参数:
java
{
"query": "统计2024年6月每个用户的消费总金额,按金额从高到低排序,只显示金额大于1000的"
}返回结果:
java
{
"success": true,
"sql": "SELECT u.`username`, SUM(o.`pay_amount`) AS `total_consumption` FROM `user` u LEFT JOIN `order` o ON u.`id` = o.`user_id` WHERE DATE_FORMAT(o.`created_at`, '%Y-%m') = '2024-06' GROUP BY u.`id`, u.`username` HAVING `total_consumption` > 1000 ORDER BY `total_consumption` DESC;",
"data": [
{
"username": "赵六",
"total_consumption": 5798.00
},
{
"username": "钱七",
"total_consumption": 1698.00
},
{
"username": "孙八",
"total_consumption": 4298.00
}
],
"errorMsg": null
}
本篇总结
本篇我们完成了Text2SQL系统的核心功能开发:
- 设计了专业级提示词,保证SQL生成准确率
- 实现了全流程业务逻辑,支持自然语言到SQL到结果的端到端转换
- 构建了双层安全校验机制(提示词规则+SQL校验Agent),保证系统安全
- 添加了Caffeine缓存,接口响应速度提升100倍+
- 提供了标准RESTful接口,方便集成使用
项目代码已上传Github:代码