Windows 11 Arm64 环境使用 Docker 部署本地 SLM
-
- 前言
- 环境准备
- 项目结构
- 部署步骤
-
- 第一步:下载模型
- [第二步:配置 Docker Compose](#第二步:配置 Docker Compose)
- [第三步:创建 Modelfile](#第三步:创建 Modelfile)
- 第四步:启动容器
- 第五步:创建并运行模型
- [API 使用方式](#API 使用方式)
- 模型选择指南
- 性能优化建议
-
- [1. 线程数调优](#1. 线程数调优)
- [2. 并发控制](#2. 并发控制)
- [3. 量化选择](#3. 量化选择)
- [4. 上下文长度](#4. 上下文长度)
- 常用管理命令
- 故障排查
- 完整清理
- 实际应用场景
-
- [1. 本地代码助手](#1. 本地代码助手)
- [2. 本地文档问答](#2. 本地文档问答)
- [3. 本地 API 服务](#3. 本地 API 服务)
- 总结
- 参考资源
前言
随着 ARM 架构的普及和本地大模型的需求增长,越来越多的开发者开始在 Windows 11 Arm64 设备上运行本地 AI 模型。本文将详细介绍如何在 骁龙 X Elite 等 ARM64 架构的 Windows 11 Pro 系统上,利用 Docker 部署并运行 Qwen3.5 系列本地化 SLM(Small Language Models, SLMs / 小型语言模型)。
环境准备
硬件要求
- 处理器 :
ARM64架构(推荐骁龙 X Elite 12 核) - 内存 : 建议
16GB以上,推荐32GB - 存储 : 至少
20GB可用空间
软件要求
- Windows 11 ARM64 系统
- Docker Desktop for Windows (确保启用
WSL2后端) - Python 3.12+ (用于下载模型,此处使用
Python 3.14.3)
项目结构
本文使用的项目结构如下:
bash
DockerAI/
├── docker-compose-arm64.yaml # Docker Compose 配置文件
├── download_model.py # 模型下载脚本
├── gguf-models/ # 模型文件存储目录
├── ollama/
│ ├── data/ # Ollama 数据持久化目录
│ └── models/ # Modelfile 配置文件
└── QUICK_START.md # 快速开始指南项目地址:
部署步骤
第一步:下载模型
使用 ModelScope 下载 Qwen3.5-0.8B GGUF 格式的模型:
bash
python download_model.py该脚本会自动下载模型到 gguf-models/ 目录。下载脚本内容如下:
python
from modelscope.hub.snapshot_download import snapshot_download
import os
# 确保目标目录存在
os.makedirs('./gguf-models', exist_ok=True)
# 下载模型
model_dir = snapshot_download(
model_id="unsloth/Qwen3.5-0.8B-GGUF",
cache_dir="./gguf-models"
)
print(f"Model successfully downloaded to: {model_dir}")执行脚本输出信息:
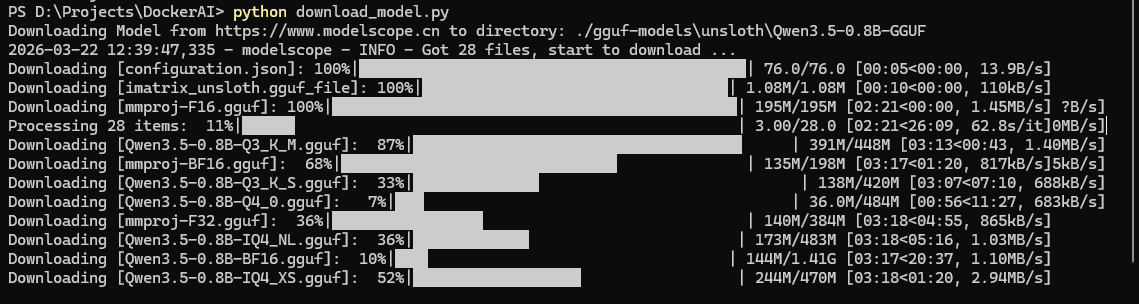
第二步:配置 Docker Compose
创建 docker-compose-arm64.yaml 文件,针对 ARM64 架构进行优化:
yaml
services:
ollama:
image: ollama/ollama:latest
platform: linux/arm64
container_name: ollama-server-arm64
restart: unless-stopped
ports:
- "11434:11434"
volumes:
- ./ollama/data:/root/.ollama
- ./gguf-models:/models:ro
environment:
- OLLAMA_NUM_PARALLEL=2
- OLLAMA_MAX_QUEUE=4
- OLLAMA_LOAD_TIMEOUT=5m
- OLLAMA_KEEP_ALIVE=30m
- OLLAMA_DEBUG=1
command: serve
shm_size: 2gb
healthcheck:
test: ["CMD", "ollama", "list"]
interval: 30s
timeout: 10s
retries: 3
start_period: 40s
networks:
default:
name: qwen-arm64-network关键配置说明:
platform: linux/arm64: 明确指定ARM64架构shm_size: 2gb: 设置共享内存为2GB,提升模型加载性能OLLAMA_NUM_PARALLEL=2: 允许同时处理2个请求OLLAMA_MAX_QUEUE=4: 最大队列4个请求OLLAMA_KEEP_ALIVE=30m: 模型在内存中保持30分钟
浏览器输入 http://localhost:11434/ 查看 ollama 是否运行:
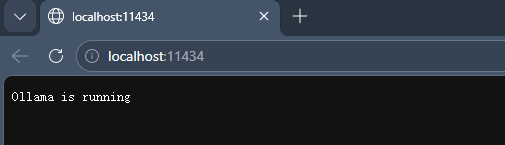
看到如上信息,说明成功运行 ollama。
第三步:创建 Modelfile
在 ollama/models/ 目录下创建 qwen35-08b-gguf.modelfile:
dockerfile
FROM /models/unsloth/Qwen3___5-0___8B-GGUF/Qwen3.5-0.8B-Q4_K_M.gguf
# 设置系统提示
TEMPLATE """{{ if .System }}<|im_start|>system
{{ .System }}<|im_end|>
{{ end }}{{ if .Prompt }}<|im_start|>user
{{ .Prompt }}<|im_end|>
{{ end }}{{ if .Response }}<|im_start|>assistant
{{ .Response }}<|im_end|>
{{ end }}"""
# 设置系统消息
SYSTEM "You are Qwen3.5, a helpful AI assistant developed by Alibaba Cloud."
# 设置参数
PARAMETER temperature 0.7
PARAMETER top_p 0.9
PARAMETER num_ctx 4096
PARAMETER num_thread 10参数说明:
temperature: 创造性参数(0-1),越高越随机top_p: 核采样参数(0-1),控制生成多样性num_ctx: 上下文长度,决定模型能记住多长的对话num_thread: 线程数,建议设置为CPU 核心数 -2
第四步:启动容器
bash
docker-compose -f docker-compose-arm64.yaml up -d等待容器启动完成(约 30-60 秒)。可以通过以下命令检查状态:
bash
docker ps | grep ollama第五步:创建并运行模型
bash
# 复制 Modelfile 到容器
docker cp ollama/models/qwen35-08b-gguf.modelfile ollama-server-arm64:/root/.ollama/models/
# 创建模型(首次需要,约 1-2 分钟)
docker exec ollama-server-arm64 ollama create qwen35 -f /root/.ollama/models/qwen35-08b-gguf.modelfile
# 运行模型测试
docker exec -it ollama-server-arm64 ollama run qwen35 "你好"本地容器化运行 SLM 模型,聊天测试如下:
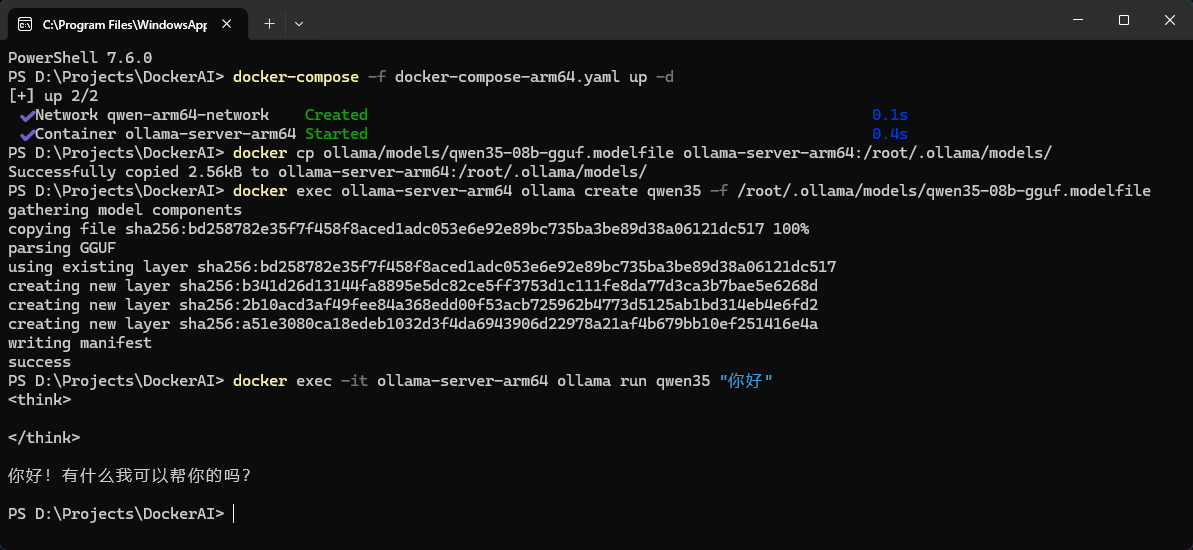
docker 容器聊天信息:
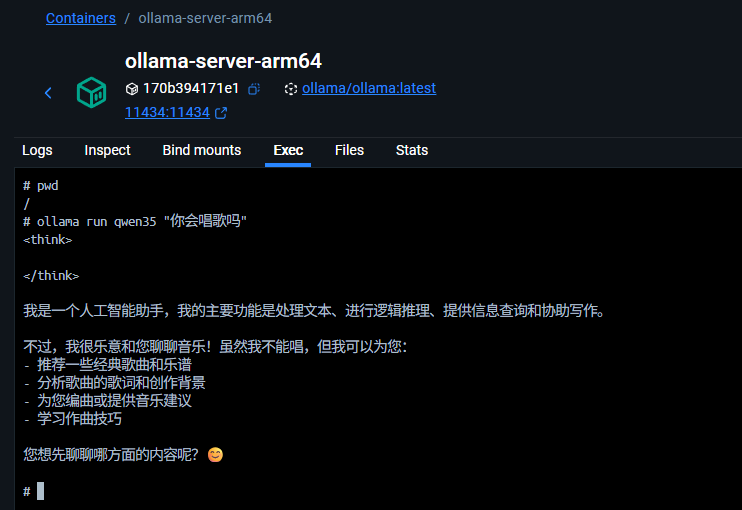
API 使用方式
Ollama 提供了 RESTful API,方便在应用中集成。
查看已安装模型
bash
curl http://localhost:11434/api/tags文本生成
bash
curl http://localhost:11434/api/generate -d '{
"model": "qwen35",
"prompt": "你好,请介绍一下你自己?",
"stream": false
}'对话模式
bash
curl http://localhost:11434/api/chat -d '{
"model": "qwen35",
"messages": [
{"role": "user", "content": "你好"}
],
"stream": false
}'模型选择指南
项目提供了多个量化版本的 Qwen3.5-0.8B 模型:
| 模型文件 | 大小 | 特点 | 推荐场景 |
|---|---|---|---|
| Qwen3.5-0.8B-Q4_K_M.gguf | 507MB | 最佳质量/速度平衡 | 通用任务 ⭐⭐⭐⭐⭐ |
| Qwen3.5-0.8B-Q4_K_S.gguf | 484MB | 更高速度 | 实时响应 ⭐⭐⭐⭐ |
| Qwen3.5-0.8B-IQ4_NL.gguf | 483MB | 最新量化技术 | 低内存场景 ⭐⭐⭐⭐ |
如需切换模型,修改 Modelfile 中的 FROM 路径即可。
性能优化建议
1. 线程数调优
根据 CPU 核心数 调整 num_thread 参数:
dockerfile
# 骁龙 X Elite 12 核示例
PARAMETER num_thread 10建议设置为 CPU 核心数 - 2,为系统保留资源。
2. 并发控制
根据内存大小调整并发参数:
yaml
environment:
- OLLAMA_NUM_PARALLEL=2 # 16GB 内存推荐
- OLLAMA_NUM_PARALLEL=4 # 32GB 内存推荐3. 量化选择
- 内存紧张:使用
IQ4_NL量化 - 速度优先:使用
Q4_K_S量化 - 质量优先:使用
Q4_K_M量化
4. 上下文长度
根据需求调整 num_ctx:
dockerfile
PARAMETER num_ctx 2048 # 短对话,节省内存
PARAMETER num_ctx 4096 # 标准配置
PARAMETER num_ctx 8192 # 长对话,需要更多内存常用管理命令
- 容器管理
bash
# 查看容器状态
docker ps | grep ollama
# 查看容器日志
docker logs ollama-server-arm64
# 重启容器
docker restart ollama-server-arm64
# 停止容器
docker stop ollama-server-arm64
# 删除容器(保留数据)
docker rm ollama-server-arm64- 模型管理
bash
# 列出已安装模型
docker exec ollama-server-arm64 ollama list
# 删除模型
docker exec ollama-server-arm64 ollama rm qwen35
# 查看模型信息
docker exec ollama-server-arm64 ollama show qwen35- 性能监控
bash
# 查看容器资源使用情况
docker stats ollama-server-arm64
# 查看实时日志
docker logs -f ollama-server-arm64故障排查
容器启动失败
症状 : docker-compose up -d 后容器无法启动
解决方案:
- 检查
Docker Desktop是否运行在WSL2模式 - 确认端口
11434未被占用:netstat -ano | findstr 11434 - 查看详细日志:
docker logs ollama-server-arm64 - 检查
Docker Desktop是否有足够的资源分配
模型创建失败
症状 : ollama create 命令报错
解决方案:
- 确认
gguf-models/目录存在并包含模型文件 - 检查
Modelfile中的模型路径是否正确 - 验证
Modelfile格式(注意不支持max_tokens参数) - 查看详细错误信息:
docker exec ollama-server-arm64 ollama create qwen35 -f /path/to/modelfile -v
性能问题
症状 : 响应速度慢或 CPU 占用过高
解决方案:
- 调整
num_thread参数 - 使用更小的量化模型(如
IQ4_NL) - 检查系统资源使用情况:
docker stats - 关闭不必要的后台应用
内存不足
症状: 系统卡顿或应用崩溃
解决方案:
- 使用更小的量化模型
- 减少
OLLAMA_NUM_PARALLEL值 - 减少
num_ctx参数值 - 关闭其他占用内存的应用
完整清理
如需完全重置项目:
bash
# 停止并删除容器
docker-compose -f docker-compose-arm64.yaml down
# 删除模型数据(可选)
docker exec ollama-server-arm64 ollama rm qwen35
# 删除本地模型文件(可选,谨慎操作)
rm -rf gguf-models/
# 删除 Docker 镜像(可选)
docker rmi ollama/ollama:latest实际应用场景
1. 本地代码助手
结合 VS Code 插件,实现本地代码补全和解释:
javascript
// 示例:使用 Ollama API 进行代码解释
async function explainCode(code) {
const response = await fetch('http://localhost:11434/api/chat', {
method: 'POST',
headers: { 'Content-Type': 'application/json' },
body: JSON.stringify({
model: 'qwen35',
messages: [
{
role: 'system',
content: 'You are a coding assistant. Explain the code clearly.'
},
{
role: 'user',
content: `Explain this code:\n${code}`
}
],
stream: false
})
});
return await response.json();
}2. 本地文档问答
基于 RAG(检索增强生成)构建本地知识库问答系统:
python
# 示例:结合向量数据库实现文档问答
from langchain_community.embeddings import OllamaEmbeddings
from langchain_community.vectorstores import Chroma
from langchain_community.chat_models import ChatOllama
# 初始化模型
embeddings = OllamaEmbeddings(model="qwen35")
llm = ChatOllama(model="qwen35")
# 加载文档并创建向量库
vectorstore = Chroma.from_documents(
documents=documents,
embedding=embeddings
)
# 问答
query = "如何优化 Docker 容器性能?"
docs = vectorstore.similarity_search(query)
answer = llm.invoke(f"基于以下文档回答问题:\n{docs}\n\n问题:{query}")3. 本地 API 服务
为其他应用提供本地 AI 能力:
python
# 示例:Flask API 服务
from flask import Flask, request, jsonify
import requests
app = Flask(__name__)
@app.route('/api/chat', methods=['POST'])
def chat():
data = request.json
response = requests.post(
'http://localhost:11434/api/chat',
json={
'model': 'qwen35',
'messages': data['messages'],
'stream': False
}
)
return jsonify(response.json())
if __name__ == '__main__':
app.run(host='0.0.0.0', port=5000)总结
通过本文的介绍,你可以在 Windows 11 Arm64 设备上成功部署并运行本地 "小模型" 。这种方式具有以下优势:
✅ 数据隐私 : 所有数据在本地处理,无需上传云端
✅ 零网络依赖 : 断网环境下也能正常使用
✅ 成本可控 : 一次部署,无限使用,无 API 调用费用
✅ 性能优秀 : ARM64 架构配合优化配置,响应速度快
✅ 易于集成 : 提供标准 REST API,方便集成到各类应用
随着硬件性能的提升和模型的不断优化,本地 "小模型" 部署将变得更加普及和高效。希望本文能帮助你在 ARM64 设备上顺利搭建本地 AI 环境。
参考资源
注意 : 本文基于 Qwen3.5-0.8B 模型,如需使用其他模型,请参考对应文档调整配置。不同的模型可能有不同的参数要求和性能特征。