摘要
本周学习了Network Compression的Network Pruning技术,了解了如何进行Network Pruning以及为什么要选择先训练大模型在Network Pruning成小模型
abstract
This week, I learned about the Network Pruning technique in Network Compression, understanding how to perform Network Pruning and why we choose to first train a large model and then prune it into a smaller model.
Network Compression
Network Compression是深度学习领域中的一系列技术,旨在减小神经网络模型的尺寸、降低计算复杂度、减少内存占用和能耗,同时尽可能保持模型的原始性能。核心目标是让原本庞大、笨重的深度模型能够高效地部署在资源受限的设备上。

Network Compression 软体技术包括以下几种,其中重点讲解了Network Pruning(网络剪枝)

其中Network Pruning(网络剪枝) 是网络压缩中最经典、应用最广泛的技术之一。它的核心思想是:深度神经网络中存在大量冗余参数(权重、神经元、通道等),移除这些冗余部分可以在不显著影响模型精度的前提下,减小模型体积、降低计算量、加快推理速度。
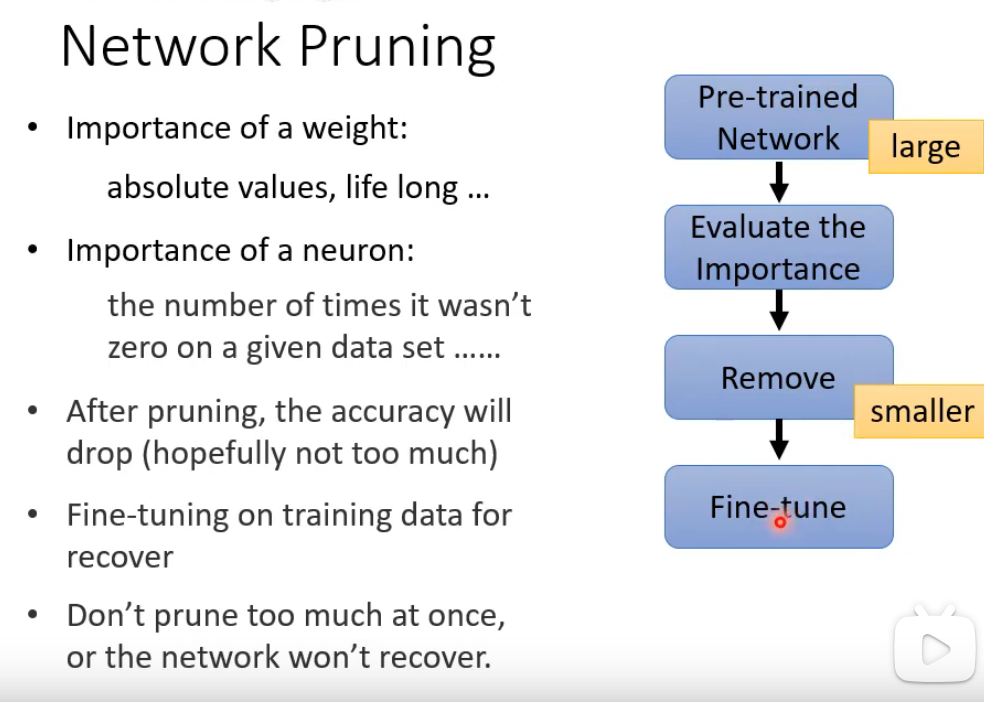
Network Pruning:首先从一个训练好的大模型出发,通过评估每个权重(比如根据绝对值大小)和每个神经元(比如根据激活次数)的重要性,判断哪些部分是冗余的;然后移除这些不重要的部分,使网络变小;由于剪枝后模型精度通常会下降,需要通过微调在训练数据上恢复性能;整个过程必须迭代进行,不能一次剪掉太多,否则模型损伤过重将无法恢复。
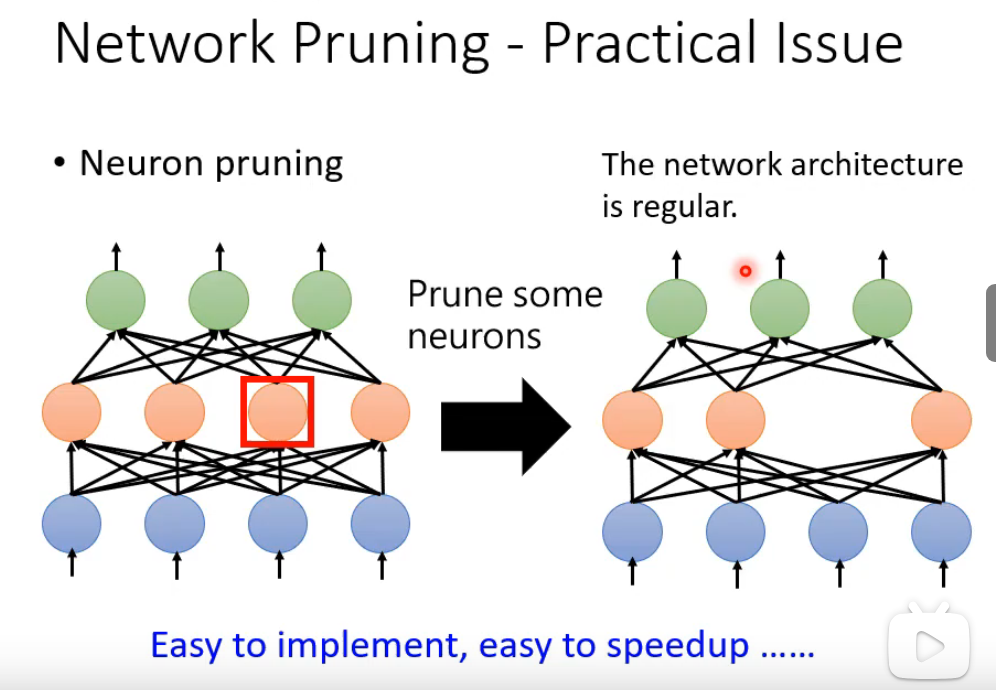
然而网络剪枝在实际应用中面临几个关键问题:一是剪枝后精度恢复困难,尤其浅层敏感,剪太多可能永久损失精度;二是各层剪枝率难以确定,统一剪枝效果差,逐层调优成本高;三是参数减少不等于实际加速,非结构化剪枝在通用硬件上效果有限,需在目标设备实测;四是迭代剪枝训练成本高,与量化叠加时精度下降可能放大;五是剪枝后的模型部署复杂,可能面临兼容性和算子优化问题。核心是在精度、压缩率和实际加速效果间找到可行平衡。
为什么先训练大模型再裁成小模型会更好?
大乐透假说:一个随机初始化的稠密神经网络中,存在一个被称为"中奖彩票"的子网络,当单独训练时,这个子网络在相同迭代次数下可以达到与原网络相当的精度。这意味着大模型并非所有参数都至关重要,而是存在一个天生就具备优秀学习能力的子结构。该假说对传统剪枝思路提出了新视角:与其先训练大模型再剪枝,不如在初始化阶段就找到这个子网络直接训练,从而以小模型的规模实现大模型的性能。