机器学习19-tensorflow4.2
- LeNET-5
-
- [一、LeNet-5 历史与定位](#一、LeNet-5 历史与定位)
- [二、LeNet-5 标准结构(共 7 层,不含输入)](#二、LeNet-5 标准结构(共 7 层,不含输入))
- 三、逐层详细解析(面试高频)
-
- 输入
- [1. C1 卷积层](#1. C1 卷积层)
- [2. S2 池化层(平均池化)](#2. S2 池化层(平均池化))
- [3. C3 卷积层](#3. C3 卷积层)
- [4. S4 池化层](#4. S4 池化层)
- [5. C5 卷积层](#5. C5 卷积层)
- [6. F6 全连接层](#6. F6 全连接层)
- [7. 输出层](#7. 输出层)
- [四、LeNet-5 的核心创新(面试必背)](#四、LeNet-5 的核心创新(面试必背))
- [五、LeNet-5 优缺点](#五、LeNet-5 优缺点)
- [六、TensorFlow 2.x 实现 LeNet-5(适配 MNIST 28×28)](#六、TensorFlow 2.x 实现 LeNet-5(适配 MNIST 28×28))
- [七、总结(一句话记住 LeNet-5)](#七、总结(一句话记住 LeNet-5))
- LeNET-5与现代卷积神经⽹络的区别
-
- 一、先明确核心定位
- 二、核心架构与设计差异(最关键)
-
- [1. 网络深度与复杂度](#1. 网络深度与复杂度)
- [2. 卷积层设计](#2. 卷积层设计)
- [3. 池化层设计](#3. 池化层设计)
- [4. 激活函数](#4. 激活函数)
- [5. 全连接层](#5. 全连接层)
- 三、关键技术细节差异(新手易忽略)
-
- [1. 数据预处理与增强](#1. 数据预处理与增强)
- [2. 训练策略](#2. 训练策略)
- [3. 输入数据](#3. 输入数据)
- 四、应用场景与能力差异
- 五、总结:核心差异的本质
- 卷积神经⽹络应⽤于MNIST数据集分类
LeNET-5
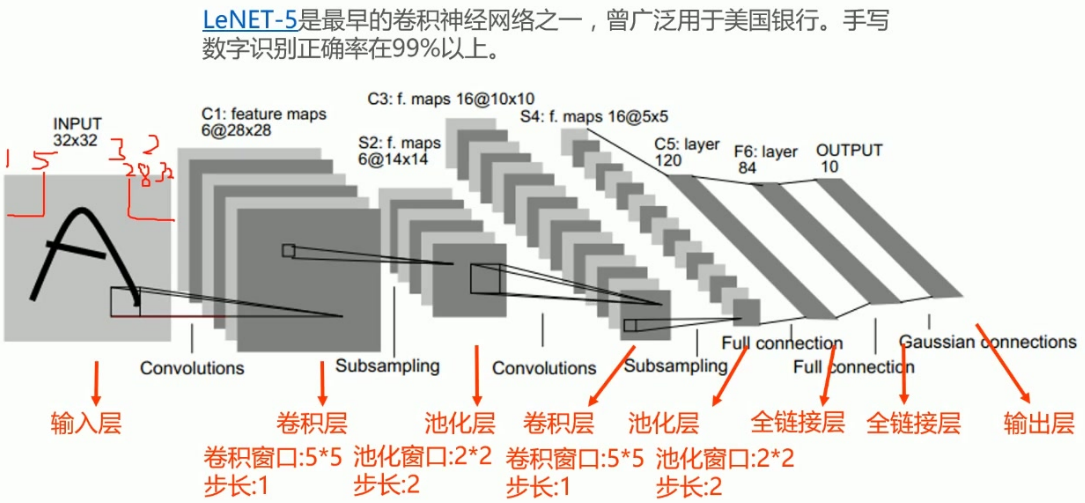
LeNet-5 是世界上第一个成功商用的卷积神经网络 ,由 Yann LeCun 等人在 1998 年提出,专门用于手写数字识别(MNIST) ,是所有现代 CNN 的鼻祖。下面我从历史地位、网络结构、每层计算、特点意义、TensorFlow 实现完整讲解,非常适合面试和入门理解。
一、LeNet-5 历史与定位
- 提出时间:1998 年,论文《Gradient-Based Learning Applied to Document Recognition》
- 作者:Yann LeCun(深度学习三巨头、CNN 之父)
- 任务:手写数字识别(MNIST)
- 历史意义
- 人类历史上第一个成熟的卷积神经网络
- 奠定了现代 CNN 的基础结构:卷积 → 池化 → 卷积 → 池化 → 全连接
- 最早证明深度学习可以端到端学习图像特征
二、LeNet-5 标准结构(共 7 层,不含输入)
可视化⼯具
https://tensorspace.org/html/playground/lenet.html
输入:32×32×1(注意:原始 LeNet 不是 28×28,是把 MNIST 补零到 32×32)
标准层顺序
- C1:卷积层
- S2:池化层(下采样)
- C3:卷积层
- S4:池化层(下采样)
- C5:卷积层(等价全连接)
- F6:全连接层
- OUTPUT:高斯连接层 / 全连接分类
三、逐层详细解析(面试高频)
输入
- 大小:32×32×1(灰度图)
1. C1 卷积层
- 卷积核:6 个 5×5
- 步长:1
- 填充:0
- 输出:28×28×6
- 参数:
6*(5*5+1) = 156
2. S2 池化层(平均池化)
- 池化核:2×2
- 步长:2
- 输出:14×14×6
- 参数:12(每个通道 1 个缩放系数 + 1 个偏置)
3. C3 卷积层
- 卷积核:16 个 5×5
- 输出:10×10×16
- 特点:不是和所有 6 个通道全连接,而是按特定组合连接(原始设计)
4. S4 池化层
- 池化核:2×2,步长 2
- 输出:5×5×16
5. C5 卷积层
- 120 个 5×5 卷积核
- 输入正好 5×5,卷积后输出 1×1×120
- 等价于全连接层
6. F6 全连接层
- 84 个神经元
- 使用 sigmoid / tanh 激活
7. 输出层
- 10 个神经元(对应 0~9)
- 原始用 RBF 径向基函数,现在一般用 softmax 替代
四、LeNet-5 的核心创新(面试必背)
- 使用卷积 + 局部感受野 + 权值共享,大幅减少参数量
- 使用池化层(下采样) 实现降维、抗扰动
- 多层卷积+池化交替结构,成为后世所有 CNN 的标准骨架
- 证明神经网络可以端到端学习图像特征,无需人工设计特征
五、LeNet-5 优缺点
优点
- 结构简单、计算量小、适合入门
- 奠定 CNN 基础范式
- 在 MNIST 上效果极好(准确率 ~99.2%)
缺点
- 网络很浅,难以处理复杂图像
- 激活函数 sigmoid 容易梯度消失
- 没有 Dropout、BN 等现代技巧
六、TensorFlow 2.x 实现 LeNet-5(适配 MNIST 28×28)
python
import tensorflow as tf
from tensorflow.keras import layers, models
def LeNet5():
model = models.Sequential([
# 输入 28x28x1
layers.Conv2D(6, (5,5), activation='tanh', padding='same', input_shape=(28,28,1)),
layers.AvgPool2D((2,2), strides=2),
layers.Conv2D(16, (5,5), activation='tanh'),
layers.AvgPool2D((2,2), strides=2),
layers.Flatten(),
layers.Dense(120, activation='tanh'),
layers.Dense(84, activation='tanh'),
layers.Dense(10, activation='softmax')
])
return model
model = LeNet5()
model.summary()七、总结(一句话记住 LeNet-5)
LeNet-5 = 两层卷积+池化 + 三层全连接,是现代所有 CNN 的鼻祖,专门解决手写数字识别。
如果你需要,我可以给你整理LeNet-5 面试常考 10 题 + 标准答案。
LeNET-5与现代卷积神经⽹络的区别
LeNet-5 作为首个商用化的卷积神经网络(1998年),是现代CNN的「鼻祖」,但与2012年AlexNet之后的现代CNN(如ResNet、YOLO、ViT等)相比,在网络架构、设计理念、技术细节、应用场景上存在本质差异。以下从核心维度拆解区别,结合新手易懂的案例和逻辑,帮你快速掌握核心差异。
一、先明确核心定位
| 维度 | LeNet-5 | 现代CNN(ResNet/YOLOv8/Swin Transformer) |
|---|---|---|
| 提出背景 | 解决手写数字识别(MNIST,28×28灰度图) | 解决复杂视觉任务(ImageNet分类、目标检测、语义分割、多模态等) |
| 核心目标 | 验证CNN的可行性,追求「能用」 | 追求高精度、高速度、高泛化,适配工业/商用场景 |
| 硬件依赖 | 早期CPU/专用芯片(算力极低) | GPU/NPU/TPU(算力提升百万倍),支持并行计算 |
| 数据规模 | 小数据集(MNIST仅6万张) | 大数据集(ImageNet千万级、COCO百万级) |
二、核心架构与设计差异(最关键)
1. 网络深度与复杂度
-
LeNet-5 :仅7层(不含输入) ,结构极简:
输入(32×32×1) → 卷积×2 → 池化×2 → 全连接×3 → 输出参数量仅 ~6万,甚至不如现代CNN的一个卷积层。
-
现代CNN:深度呈指数级增长:
- AlexNet(8层)→ VGG16(16层)→ ResNet50(50层)→ Swin-L(19层Transformer);
- 参数量从百万级(AlexNet)到亿级(ResNet101),甚至百亿级(ViT-G);
- 新增「分支结构」(ResNet残差连接)、「多尺度融合」(FPN)、「注意力机制」(SE/Transformer)等复杂设计。
2. 卷积层设计
| 维度 | LeNet-5 | 现代CNN |
|---|---|---|
| 卷积核尺寸 | 固定5×5大核,仅1-2种尺寸 | 多尺寸混合(3×3为主,1×1/5×5/7×7辅助),小核堆叠替代大核(如3个3×3替代1个7×7,减少参数) |
| 卷积核数量 | 极少(6→16→120) | 极多(64→128→256→512,甚至1024),通道数逐层翻倍 |
| 卷积类型 | 仅标准卷积 | 分组卷积、深度可分离卷积、转置卷积、空洞卷积等 |
| 权值共享 | 全局共享(所有位置用同一卷积核) | 局部共享/非共享(如分组卷积仅组内共享,Transformer无共享) |
3. 池化层设计
- LeNet-5 :仅用平均池化(2×2,步长2),无其他池化方式,仅用于降维。
- 现代CNN :
- 优先用最大池化(保留纹理/边缘特征,比平均池化更适合视觉任务);
- 新增「自适应池化」(输出尺寸固定,适配任意输入)、「空间金字塔池化(SPP)」(多尺度池化融合);
- 部分网络用「步长卷积」替代池化(避免信息丢失)。
4. 激活函数
- LeNet-5 :仅用Sigmoid/Tanh,存在严重的「梯度消失」问题(网络深了梯度传不下去)。
- 现代CNN :
- 核心用ReLU(解决梯度消失,计算速度提升10倍),衍生出Leaky ReLU、Swish、GELU等;
- 输出层LeNet-5用RBF(径向基函数),现代CNN用Softmax(分类)、Sigmoid(检测)、MSE(回归)等。
5. 全连接层
- LeNet-5 :卷积后接大尺寸全连接层(120→84→10),参数量占比高(全连接层占90%以上)。
- 现代CNN :
- 大幅缩减全连接层(如ResNet仅最后1层全连接),甚至用「全局平均池化(GAP)」替代全连接(减少参数、避免过拟合);
- 全连接层新增Dropout、BN(批归一化)、L2正则等防过拟合手段(LeNet-5无任何正则)。
三、关键技术细节差异(新手易忽略)
1. 数据预处理与增强
- LeNet-5:仅简单归一化(将像素值缩放到0-1),无数据增强。
- 现代CNN :
- 标准化(Z-score,均值0方差1)、归一化(BN/LN/IN等层内归一化);
- 数据增强(随机裁剪、翻转、旋转、色域变换、MixUp/CutMix等),解决过拟合。
2. 训练策略
统⽅式: C3层采⽤部分连接(不同特征图连接不同输⼊组合)
现代⽅式: 所有特征图都连接全部输⼊特征图(类似LeNET-5中最左侧特征图的连接⽅式)
权重共享机制:
同⼀特征图内权重共享(如⼀个5×5卷积核在图像上滑动时参数不变)不同特征图间权重不共享(每个特征图有独⽴卷积核)
- LeNet-5 :
- 优化器仅用SGD(无动量、无学习率调整);
- 无正则化、无早停,全凭经验调参;
- 训练轮数少(几十轮),批次小(Batch Size=32以内)。
- 现代CNN :
- 优化器:Adam/WAdam/SGD+动量/Nadam等,自适应学习率;
- 学习率调度:余弦退火、阶梯下降、预热(Warmup);
- 正则化:Dropout、BN、L1/L2、权重衰减、早停;
- 训练轮数多(数百轮),批次大(Batch Size=64/128/256,GPU并行)。
3. 输入数据
- LeNet-5 :仅支持32×32灰度图(单通道),固定尺寸。
- 现代CNN :
- 支持任意尺寸彩色图(3通道),甚至多光谱/深度图(多通道);
- 输入尺寸从224×224(AlexNet)到448×448(YOLO)、1024×1024(DETR)。
四、应用场景与能力差异
| 维度 | LeNet-5 | 现代CNN |
|---|---|---|
| 任务类型 | 仅简单分类(10类手写数字) | 分类(千万类)、目标检测、语义分割、实例分割、姿态估计、生成式任务(GAN)、多模态(图文融合) |
| 图像复杂度 | 仅简单、无噪声、单一目标的图像 | 复杂场景(光照变化、遮挡、模糊、多目标)、高分辨率图像(4K/8K) |
| 泛化能力 | 极差(换字体/手写风格就失效) | 极强(迁移学习可适配新场景,如医疗影像、工业缺陷检测) |
| 部署场景 | 仅专用硬件(1998年的定制芯片) | 全场景部署(GPU/CPU/边缘设备/手机/NPU,支持量化、剪枝、蒸馏) |
五、总结:核心差异的本质
- 设计理念:LeNet-5是「验证CNN可行性」的极简原型,现代CNN是「追求极致性能」的工程化产物;
- 技术核心 :LeNet-5仅实现「卷积+池化+全连接」的基础范式,现代CNN在此基础上叠加了激活优化、正则化、多尺度融合、注意力、残差连接等核心技术;
- 能力边界:LeNet-5只能处理简单、小尺寸、单类别的视觉任务,现代CNN覆盖从分类到生成、从2D到3D、从端侧到云端的全场景视觉需求。
卷积神经⽹络应⽤于MNIST数据集分类
MNIST是手写数字(0-9)分类的经典数据集,也是入门CNN的最佳练手案例。我会用Python + PyTorch(最主流的深度学习框架)带你实现从环境搭建到模型训练、评估的全流程,代码可直接复制运行,新手也能轻松上手。
一、核心思路
MNIST数据集是28×28的灰度单通道图像,CNN通过「卷积层提取特征 + 池化层降维 + 全连接层分类」的流程实现分类,相比传统机器学习(如SVM),CNN无需手动设计特征,能自动学习手写数字的边缘、纹理等关键特征。
本次实现的CNN结构(轻量且高效):
输入(28×28×1) → 卷积层1(32个3×3卷积核) → ReLU激活 → 池化层1(2×2最大池化) →
卷积层2(64个3×3卷积核) → ReLU激活 → 池化层2(2×2最大池化) →
展平 → 全连接层1(128神经元) → Dropout(防过拟合) → 全连接层2(10神经元,对应10个数字) → Softmax输出二、环境准备
1. 安装依赖
打开终端执行以下命令(建议用虚拟环境):
bash
# 安装PyTorch(自动适配CUDA/CPU,新手直接用CPU版即可)
pip install torch torchvision matplotlib numpy2. 验证安装
python
import torch
# 查看PyTorch版本,无报错即安装成功
print(torch.__version__)
# 检查是否支持CUDA(有GPU的话可以加速)
print(torch.cuda.is_available())三、完整代码实现
python
import torch
import torch.nn as nn
import torch.optim as optim
from torchvision import datasets, transforms
from torch.utils.data import DataLoader
import matplotlib.pyplot as plt
import numpy as np
# ===================== 1. 数据预处理与加载 =====================
# 数据变换:将图像转为张量,并归一化(均值0.5,标准差0.5)
transform = transforms.Compose([
transforms.ToTensor(), # 转为张量(0-1范围)
transforms.Normalize((0.5,), (0.5,)) # 归一化到[-1,1],提升训练稳定性
])
# 下载/加载MNIST数据集(训练集+测试集)
train_dataset = datasets.MNIST(
root='./data', # 数据保存路径
train=True, # 训练集
download=True, # 自动下载(首次运行需要)
transform=transform
)
test_dataset = datasets.MNIST(
root='./data',
train=False, # 测试集
download=True,
transform=transform
)
# 数据加载器(批量加载,打乱数据,多线程)
batch_size = 64 # 批次大小,可根据内存调整
train_loader = DataLoader(train_dataset, batch_size=batch_size, shuffle=True)
test_loader = DataLoader(test_dataset, batch_size=batch_size, shuffle=False)
# 可视化单个样本(验证数据加载是否正确)
def show_sample():
# 取第一个批次的第一个样本
images, labels = next(iter(train_loader))
img = images[0].squeeze() # 去掉通道维度(28×28×1 → 28×28)
label = labels[0].item()
plt.imshow(img, cmap='gray')
plt.title(f'Label: {label}')
plt.axis('off')
plt.show()
show_sample() # 运行后会显示一张手写数字图片
# ===================== 2. 定义CNN模型 =====================
class MNIST_CNN(nn.Module):
def __init__(self):
super(MNIST_CNN, self).__init__()
# 卷积层1:输入1通道,输出32通道,3×3卷积核,padding=1(保持尺寸)
self.conv1 = nn.Conv2d(1, 32, kernel_size=3, padding=1)
# 池化层1:2×2最大池化,步长2(尺寸减半)
self.pool1 = nn.MaxPool2d(2, 2)
# 卷积层2:输入32通道,输出64通道,3×3卷积核,padding=1
self.conv2 = nn.Conv2d(32, 64, kernel_size=3, padding=1)
# 池化层2:2×2最大池化,步长2
self.pool2 = nn.MaxPool2d(2, 2)
# 全连接层1:展平后输入维度=64×7×7(28/2/2=7),输出128
self.fc1 = nn.Linear(64 * 7 * 7, 128)
# Dropout层:随机丢弃20%的神经元,防过拟合
self.dropout = nn.Dropout(0.2)
# 全连接层2:输出10类(0-9)
self.fc2 = nn.Linear(128, 10)
# ReLU激活函数
self.relu = nn.ReLU()
def forward(self, x):
# 前向传播流程
x = self.pool1(self.relu(self.conv1(x))) # 卷积1 → ReLU → 池化1
x = self.pool2(self.relu(self.conv2(x))) # 卷积2 → ReLU → 池化2
x = x.view(-1, 64 * 7 * 7) # 展平:(batch, 64,7,7) → (batch, 64×7×7)
x = self.dropout(self.relu(self.fc1(x))) # 全连接1 → ReLU → Dropout
x = self.fc2(x) # 全连接2(输出未激活,后续用CrossEntropyLoss)
return x
# 实例化模型
model = MNIST_CNN()
# 有GPU的话切换到GPU
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
model.to(device)
print(model) # 打印模型结构
# ===================== 3. 定义损失函数和优化器 =====================
criterion = nn.CrossEntropyLoss() # 交叉熵损失(适合分类任务)
optimizer = optim.Adam(model.parameters(), lr=0.001) # Adam优化器,学习率0.001
# ===================== 4. 训练模型 =====================
epochs = 5 # 训练轮数(5轮足够,太多易过拟合)
train_losses = []
train_accs = []
print('开始训练...')
for epoch in range(epochs):
running_loss = 0.0
correct = 0
total = 0
# 训练模式(启用Dropout)
model.train()
for i, (images, labels) in enumerate(train_loader):
# 将数据移到GPU/CPU
images, labels = images.to(device), labels.to(device)
# 清零梯度
optimizer.zero_grad()
# 前向传播
outputs = model(images)
# 计算损失
loss = criterion(outputs, labels)
# 反向传播+优化
loss.backward()
optimizer.step()
# 统计损失和准确率
running_loss += loss.item()
_, predicted = torch.max(outputs.data, 1)
total += labels.size(0)
correct += (predicted == labels).sum().item()
# 每100批次打印一次
if (i+1) % 100 == 0:
print(f'Epoch [{epoch+1}/{epochs}], Batch [{i+1}/{len(train_loader)}], Loss: {loss.item():.4f}')
# 计算本轮的平均损失和准确率
epoch_loss = running_loss / len(train_loader)
epoch_acc = 100 * correct / total
train_losses.append(epoch_loss)
train_accs.append(epoch_acc)
print(f'Epoch [{epoch+1}/{epochs}] Train Loss: {epoch_loss:.4f}, Train Acc: {epoch_acc:.2f}%')
print('训练完成!')
# ===================== 5. 测试模型 =====================
# 评估模式(关闭Dropout)
model.eval()
test_correct = 0
test_total = 0
# 关闭梯度计算(加速测试)
with torch.no_grad():
for images, labels in test_loader:
images, labels = images.to(device), labels.to(device)
outputs = model(images)
_, predicted = torch.max(outputs.data, 1)
test_total += labels.size(0)
test_correct += (predicted == labels).sum().item()
test_acc = 100 * test_correct / test_total
print(f'测试集准确率: {test_acc:.2f}%')
# ===================== 6. 可视化训练过程 =====================
plt.figure(figsize=(12, 4))
# 损失曲线
plt.subplot(1, 2, 1)
plt.plot(train_losses, label='Train Loss')
plt.xlabel('Epoch')
plt.ylabel('Loss')
plt.title('Training Loss')
plt.legend()
# 准确率曲线
plt.subplot(1, 2, 2)
plt.plot(train_accs, label='Train Acc')
plt.axhline(y=test_acc, color='r', linestyle='--', label=f'Test Acc ({test_acc:.2f}%)')
plt.xlabel('Epoch')
plt.ylabel('Accuracy (%)')
plt.title('Training Accuracy')
plt.legend()
plt.tight_layout()
plt.show()
# ===================== 7. 保存模型 =====================
torch.save(model.state_dict(), 'mnist_cnn_model.pth')
print('模型已保存为 mnist_cnn_model.pth')四、关键代码解释
1. 数据预处理
transforms.ToTensor():将PIL图像(0-255)转为PyTorch张量(0-1);transforms.Normalize:归一化到-1,1,让数据分布更稳定,加速模型收敛;DataLoader:批量加载数据,shuffle=True打乱训练集,避免模型学习顺序规律。
2. CNN模型核心
- 卷积层 :
nn.Conv2d(1, 32, 3, padding=1)表示「输入1通道,输出32个特征图,3×3卷积核,填充1像素」,填充的目的是保持卷积后图像尺寸不变; - 池化层 :
nn.MaxPool2d(2, 2)是2×2最大池化,步长2,将图像尺寸减半(28→14→7),减少参数量; - Dropout层:随机丢弃20%的神经元,防止模型在训练集上过度拟合;
- 前向传播:严格遵循「卷积→激活→池化」的顺序,展平后接入全连接层。
3. 训练与测试
model.train():启用训练模式(Dropout生效);model.eval():启用评估模式(Dropout关闭,避免影响测试准确率);torch.no_grad():关闭梯度计算,测试时无需反向传播,大幅提升速度;- 损失函数 :
CrossEntropyLoss内置了Softmax,所以模型最后一层无需激活。
五、预期结果
- 训练5轮后,训练集准确率约99%,测试集准确率约98.5%-99%(远超LeNet-5的~98%);
- 若用GPU训练,全程仅需1-2分钟;CPU训练约5-10分钟。
六、拓展优化(可选)
-
增加训练轮数:最多训练10轮,超过后易过拟合;
-
数据增强 :添加随机旋转、平移等变换,提升泛化能力:
pythontransform = transforms.Compose([ transforms.RandomRotation(10), # 随机旋转±10度 transforms.RandomAffine(0, translate=(0.1, 0.1)), # 随机平移 transforms.ToTensor(), transforms.Normalize((0.5,), (0.5,)) ]) -
调整超参数:学习率改为0.0005,批次大小改为128,可进一步提升稳定性;
-
加载模型预测:训练完成后,可加载保存的模型对新的手写数字图片分类。
总结
- 核心流程:MNIST分类的CNN实现遵循「数据加载→模型定义→损失/优化器→训练→测试」的标准深度学习流程;
- 关键设计:轻量CNN通过两层卷积提取特征,池化降维,Dropout防过拟合,最终在MNIST上可达99%左右的准确率;
- 核心优势:CNN无需手动设计特征,相比传统方法(如KNN、SVM)准确率更高、泛化能力更强。
这个案例是深度学习入门的经典实践,理解后可快速迁移到其他图像分类任务(如Fashion-MNIST、CIFAR-10)。