算法原理
优先级队列
概念
基本操作:1.返回最高优先级对象
2.添加新的对象
Priority底层使用了堆 (堆中某个节点的值总是不大于或不小于其父亲结点的值,堆是一颗完全二叉树)
堆分为小跟堆和大根堆
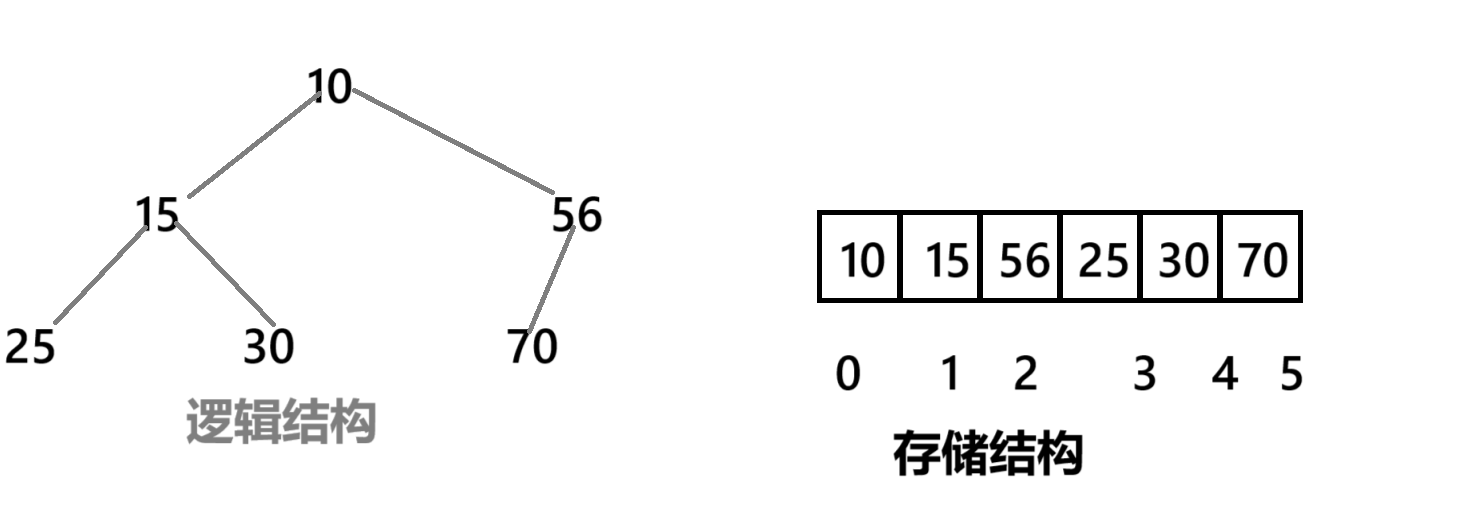
小根堆
大根堆
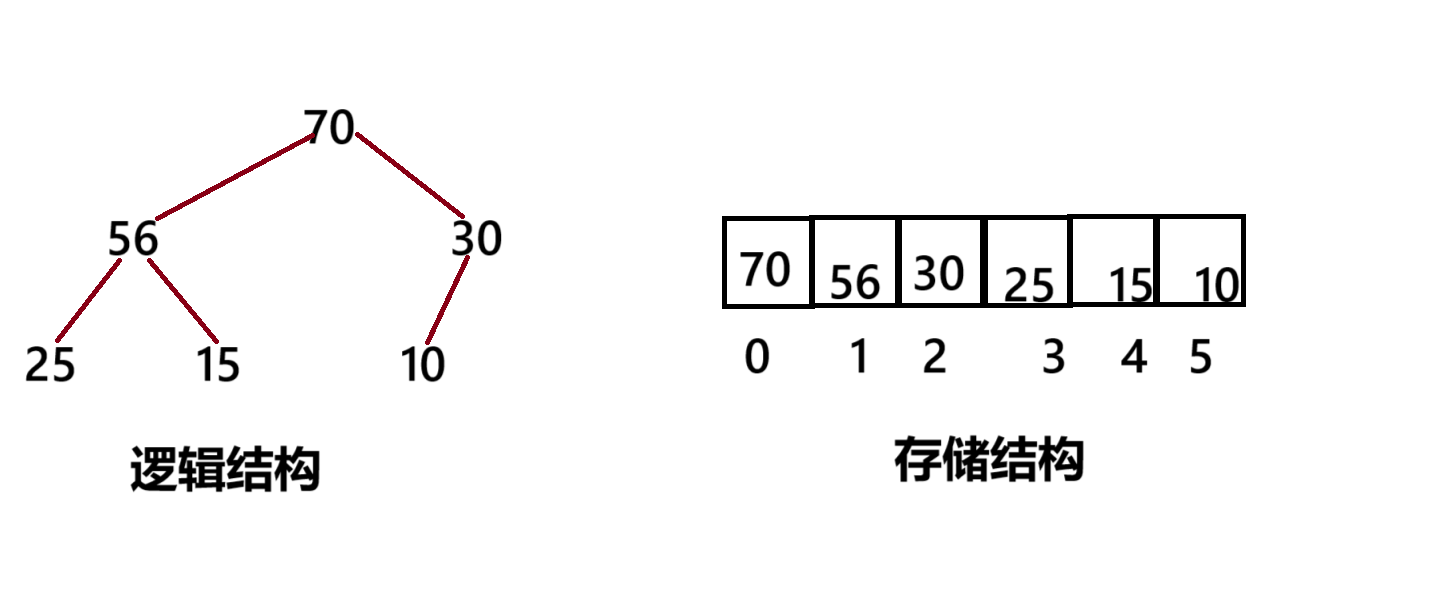
堆的存贮方式:堆是完全二叉树,可以采用顺序的方式进行高效的存储
PriorityQueue的特性:
1.导包 ;2.默认是小跟堆;3.不能插入null 4.放入的元素必须能比较大小 5.没有容量限制
6.插入和删除的时间复杂度是0(logN)
7.底层使用堆数据结构 8.线程不安全
方法:
offer()会判断是否满了,满了会扩容(1.5倍)然后会向上调整
小跟堆 return this.val-o.val
大根堆 return o.val-this.val
这里我们主要利用优先级队列来解决一类算法题
题目解析
1.最后一块石头的重量
题目描述
有一堆石头,每块石头的重量都是正整数,每一回合,从中选择最终的石头,然后把他们一起粉碎,假设石头的重量分别为x,y. 那么粉碎的结果可能如下(假设x<=y):
如果x==y,那么两块石头将会被完全粉碎;如果x!=y,那么重量为x的石头将会被完全粉碎,而重量为y的石头的新重量为y-x
最后,至多之后剩下一块石头,返回此石头的重量,如果没有石头剩下,就返回0
算法原理
解法一:暴力枚举
解法二:用堆来模拟
这里我们应该用的是大根堆
每次取出两个堆顶元素,如果两个元素相等,则不返回值继续重复操作,如果两个元素不相等,将两者的差值返回重复操作
代码实现
java
class Solution {
public int lastStoneWeight(int[] stones) {
PriorityQueue<Integer> heap=new PriorityQueue<>((a,b)->b-a);
for(int x:stones){
heap.offer(x);
}
while(heap.size()>1){
int x=heap.poll();
int y=heap.poll();
if(x>y){
heap.offer(x-y);
}
}
return heap.size()==0?0:heap.poll();
}
}2.数据流中的第 K 大元素
题目描述
设计一个找到第k大元素的类(class),注意这里要找的是排序后的第k大元素,而不是第k个不同的元素
请实现KthLargest类:
1.KthLargest(int k, int\[\]nums) 使用整数和整数流nums初始化对象
2.int add(int val)将val插入数据流nums后,返回当前数据流中第k大的元素
算法原理
TopK问题通常由两种解决方案:1.堆 2.快速选择
这里我们利用堆来解决
1.创建一个大小为k的堆(大根堆/小跟堆)(大小根堆的选择与题目有关)
2.循环:
1.依次进堆 2.判断堆的大小是否超过k,超过k返回堆顶元素
这里如果求的是第k大,我们利用小跟堆(这样的话大的元素在堆顶,第k大的元素就会在堆顶)
如果求的是第k小,我们要利用大根堆,这样堆顶元素是大的元素,小的元素会在堆顶
代码实现
java
class KthLargest {
//这里要找的是第k大元素,我们使用小跟堆,默认就是小跟堆,所以不用指定方法
PriorityQueue<Integer> heap;
int k;
public KthLargest(int _k, int[] nums) {
k=_k;
heap=new PriorityQueue<>();
for(int x:nums){
add(x);
if(heap.size()>_k){
heap.poll();
}
}
}
public int add(int val) {
heap.offer(val);
if(heap.size()>k){
heap.poll();
}
return heap.peek();
}
}3.前K个高频单词
题目描述
给定一个单词列表words和一个整数k,返回前k个出现次数最多的单词
返回的答案应该按单词出现频率由高到低排序,如果不同的单词有相同的出现频率,按字典顺序排序,(频次的小跟堆,频次相同的时候字典顺序的大根堆)
算法原理
topK问题
解法:利用堆来解决TopK问题
1.预处理原始的字符串数组(用哈希表先统计单词出现的次数)
2.创建大小为k的堆
3.循环: 1.让元素一次进堆 2.判断
4.提取结果 最终得到的结果需要逆序
这里堆中用Pair<String,Integer>来存,这样我们根据需要来进行堆的排序(因为这里有要求当频次相同的时候要按照字段顺序来排序)
代码实现
java
class Solution {
public List<String> topKFrequent(String[] words, int k) {
//1.先统计单词出现的次数
Map<String,Integer> hash=new HashMap<>();
for(String s:words){
hash.put(s,hash.getOrDefault(s,0)+1);
}
//2.创建一个大小为k的堆
PriorityQueue<Pair<String,Integer>> heap=new PriorityQueue<>(
(a,b)->{
if(a.getValue().equals(b.getValue())){
return b.getKey().compareTo(a.getKey());
}
return a.getValue()-b.getValue();
}
);
//3.topK的主逻辑
for(Map.Entry<String,Integer> e:hash.entrySet()){
heap.offer(new Pair<>(e.getKey(),e.getValue()));
if(heap.size()>k){
heap.poll();
}
}
List<String> ret=new ArrayList<>();
while(!heap.isEmpty()){
ret.add(heap.poll().getKey());
}
Collections.reverse(ret);
return ret;
}
}4.数据流的中位数
题目描述
中位数是有序整数列表中的中间值,如果列表大小是偶数,则没有中间值,中位数是两个中间值的平均值
例如:arr=2,3,4 的中位数是3
arr=2,3 的中位数是(2+3)/2=2.5
算法原理
解法一:直接sort(时间复杂度很吓人)
解法二:插入排序思想(这里不做过多展开)
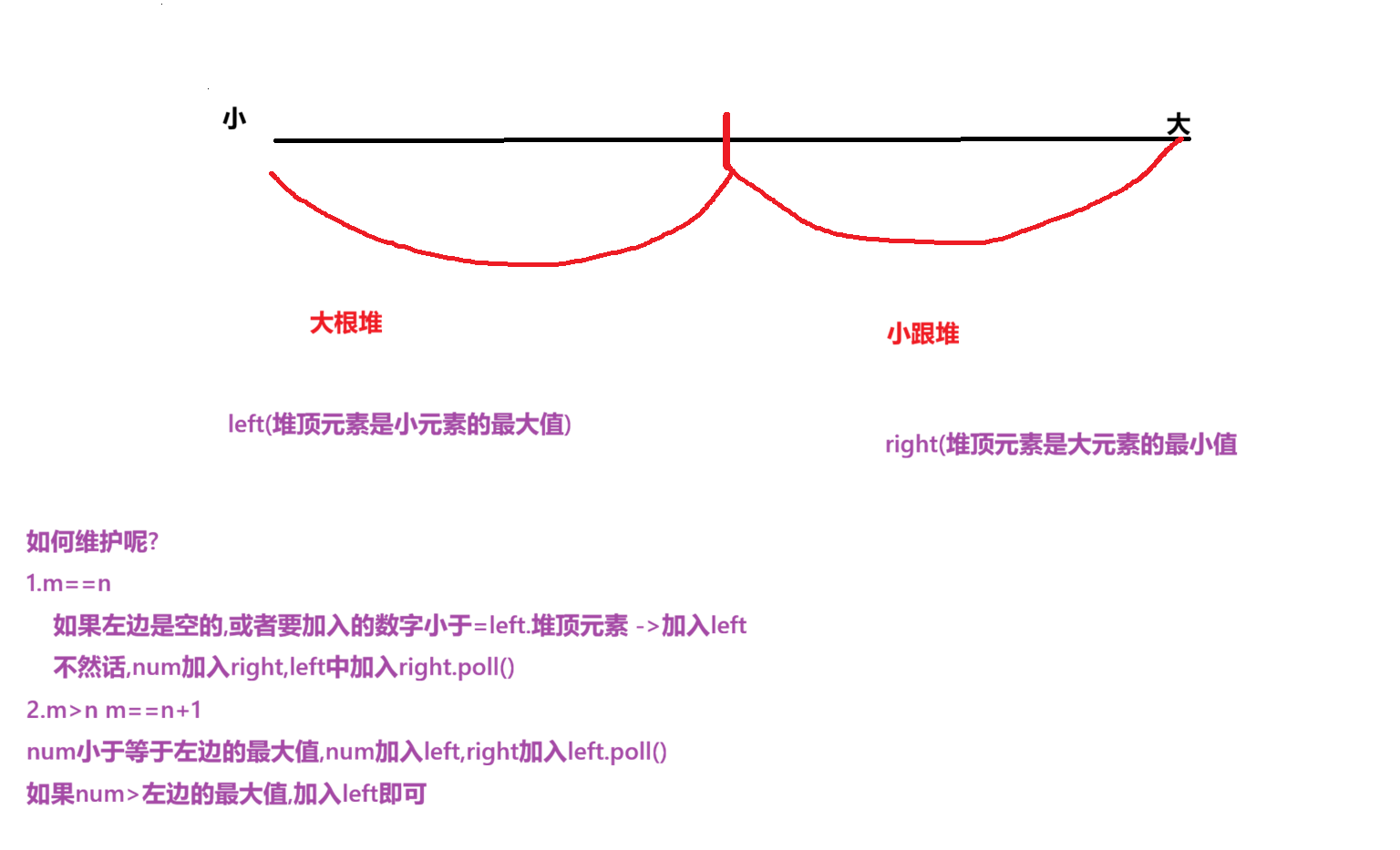
解法三:大小堆来维护数据流的中位数
代码实现
java
class MedianFinder {
PriorityQueue<Integer> left;
PriorityQueue<Integer> right;
public MedianFinder() {
left=new PriorityQueue<>((a,b)-> b-a);
right=new PriorityQueue<>((a,b)-> a-b);
}
public void addNum(int num) {
if(left.size()==right.size()){
if(left.isEmpty()||num<=left.peek()){
left.offer(num);
}else{
right.offer(num);
left.offer(right.poll());
}
}else{
if(num<=left.peek()){
left.offer(num);
right.offer(left.poll());
}else{
right.offer(num);
}
}
}
public double findMedian() {
if(left.size()==right.size()){
return (left.peek()+right.peek())/2.0;
}else{
return (double)left.peek();
}
}
}