前些天,著名 AI 技术作家 Sebastian Raschka 发布了一份「LLM 架构画廊」,获得了 AI 社区的高度关注和赞扬,参阅《DeepSeek、GPT、Qwen,所有大模型架构图都有,Karpathy:宝藏画廊!》。

图 1 :LLM 架构图库及其视觉模型卡片概览。
这个 LLM 架构画廊是如此受欢迎,也让 Raschka 找到了合作伙伴开始生产实体海报。目前来看,销量还很不错。

图 2 :带有用于对比大小的随机物体的架构图库海报版本。
现在,时间才刚过去一周多,Raschka 又放出了另一篇重磅博客《现代 LLM 中注意力变体的可视化指南》。在这篇文章中,他回顾了近年来开发的并在著名的开放权重架构中使用的所有注意力变体。他表示: 「我的目标是使这个集合既能作为参考资料,又能作为轻量级的学习资源。」

博客地址:magazine.sebastianraschka.com/p/visual-at...
机器之心编译了这篇出色的博客,以飨读者:
1. 多头注意力 (MHA)
自注意力机制允许每个 token 查看序列中其他可见的 token ,为它们分配权重,并利用这些权重构建一个新的具有上下文感知的输入表示。
多头注意力 (MHA) 是该理念在 Transformer 中的标准版本。它并行运行多个具有不同学习投影的自注意力头,然后将它们的输出组合成一个更丰富的表示。
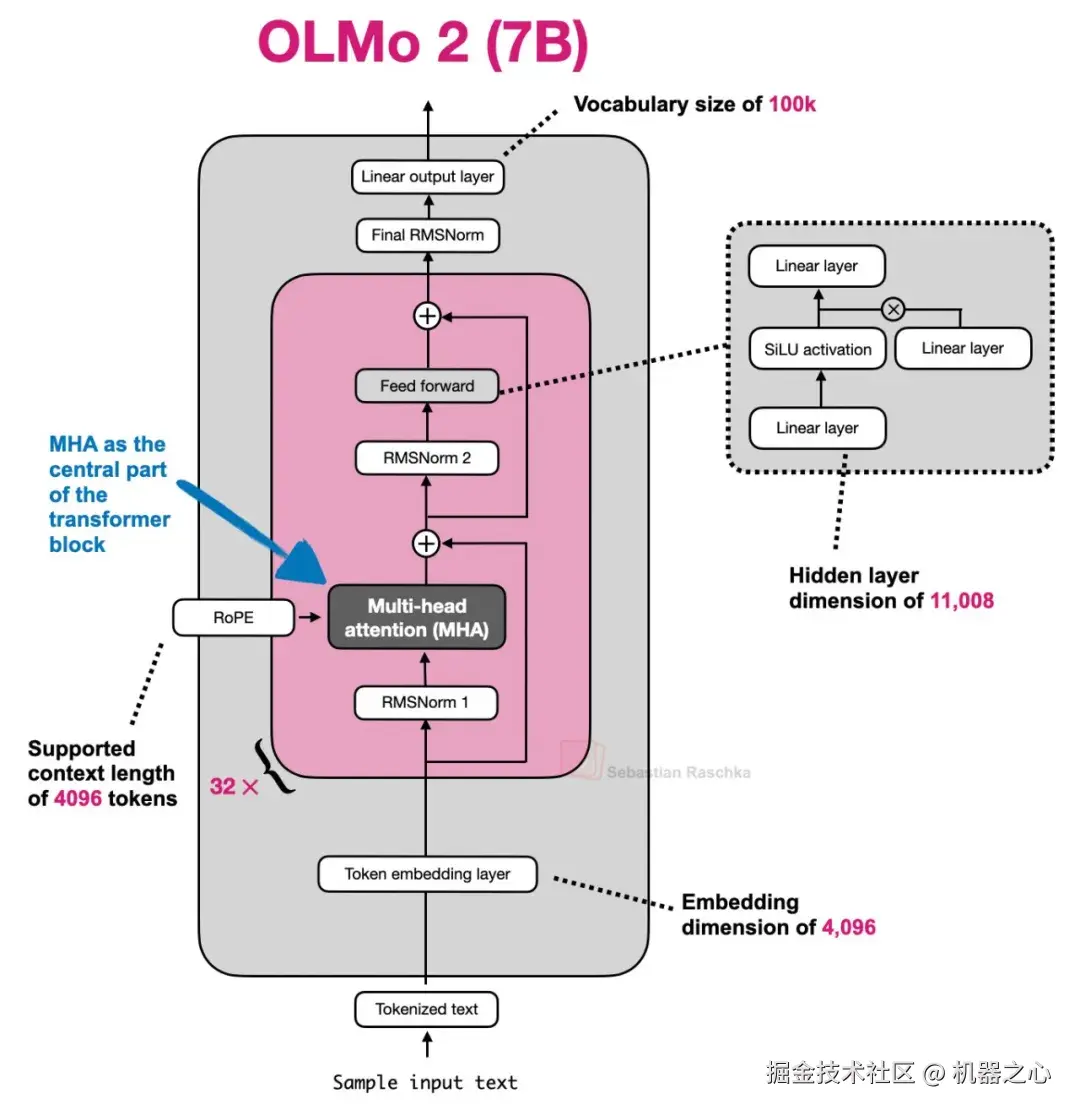
图 3 :以 Olmo 2 为例的 MHA 架构。
下面的部分首先快速介绍自注意力机制以解释 MHA。这主要是作为一个快速概述,为相关的注意力概念(如分组查询注意力、滑动窗口注意力等)奠定基础。如果你对更长、更详细的自注意力机制内容感兴趣,你可能会喜欢我的一篇较长的文章《理解并编写 LLM 中的自注意力、多头注意力、因果注意力与交叉注意力》。
地址: magazine.sebastianraschka.com/p/understan...
示例架构:GPT-2、OLMo 2 7B 和 OLMo 3 7B
1.2 历史趣闻以及发明注意力机制的原因
注意力机制的出现早于 Transformer 和 MHA。它的直接背景是用于翻译的编码器和解码器 RNN。
在那些较旧的系统中,编码器 RNN 会逐个 token 地读取源句子,并将其压缩为隐藏状态序列,或者在最简单的版本中压缩为一个最终状态。然后,解码器 RNN 必须从这个有限的摘要中生成目标句子。这在简短和简单的情况下是有效的,但是一旦下一个输出词的相关信息位于输入句子中的其他位置,它就会产生明显的瓶颈。
简而言之,局限性在于隐藏状态无法存储无限多的信息或上下文,有时直接回顾整个输入序列会非常有用。
下面的翻译示例展示了这种想法的一个局限性。例如,当模型将问题过度视为逐词映射时,句子可能保留了许多局部合理的词汇选择,但翻译仍然会失败。(顶部面板显示了一个夸张的示例,我们逐词翻译句子;显然,结果句子中的语法是错误的。)实际上,正确的下一个单词取决于句子级别的结构以及在该步骤中哪些早期的源单词起作用。当然,使用 RNN 仍然可以很好地进行翻译,但在处理较长序列或知识检索任务时它会遇到困难,正如前面提到的,隐藏状态只能存储有限的信息。
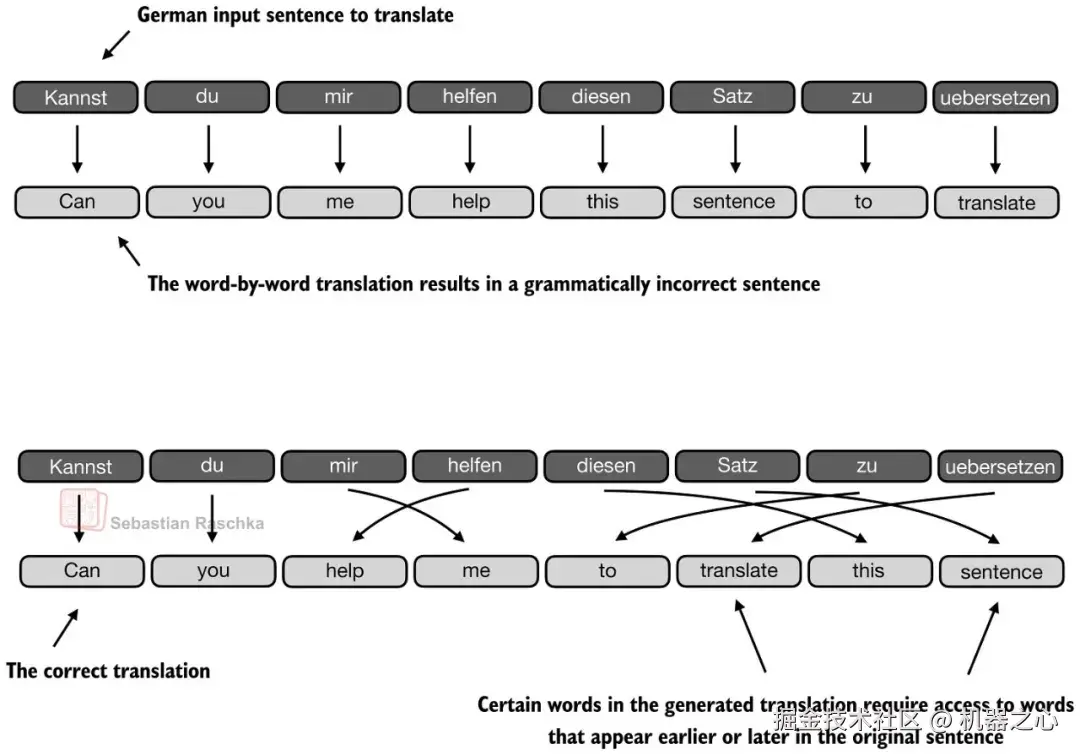
图 4 :即使许多单独的词汇选择看起来很合理,翻译也可能失败,因为句子级别的结构仍然很重要。
下图更直接地展示了这种变化。当解码器生成一个输出 token 时,它不应受限于单一的压缩内存路径。它应该能够直接追溯到更相关的输入 token。
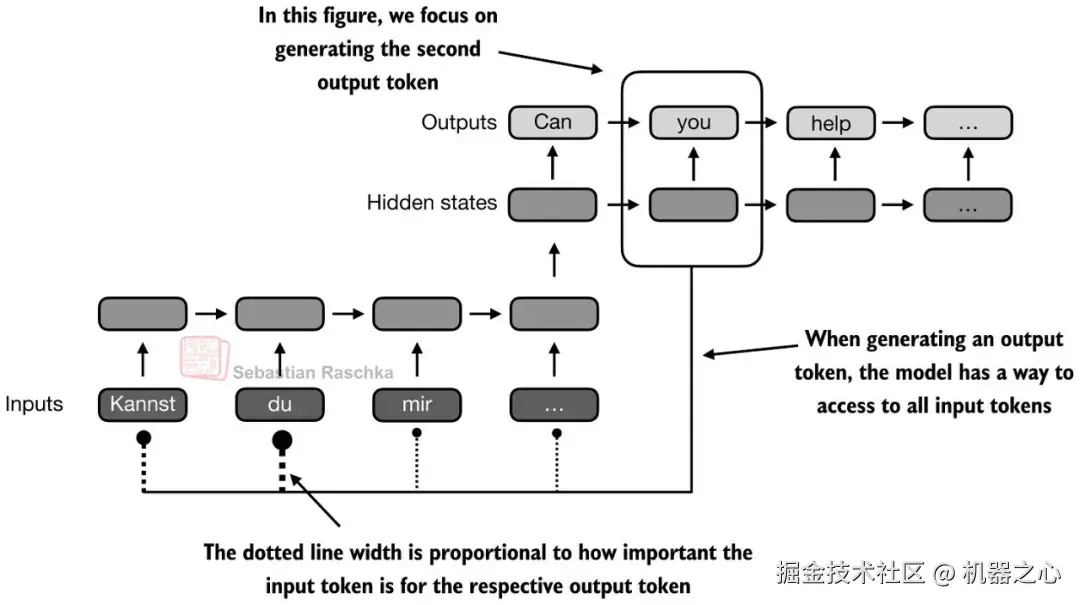
图 5 :注意力机制通过让当前输出位置回顾整个输入序列,打破了 RNN 的瓶颈,其机制抛弃了仅依赖单一压缩状态的做法。
Transformer 保留了上述改进版注意力 RNN 的核心思想,同时移除了循环结构。在经典的《Attention Is All You Need》论文中,注意力机制本身成为了主要的序列处理机制,它取代了以往仅作为 RNN 编码器和解码器一部分的角色。
在 Transformer 中,这种机制被称为自注意力,序列中的每个 token 会计算所有其他 token 的权重,并利用这些权重将来自这些 token 的信息混合成一个新的表示。多头注意力是并行运行多次的相同机制。
1.3 掩码注意力矩阵
对于一个包含 T 个 token 的序列,注意力机制需要为每个 token 提供一行权重,因此总体上我们得到一个 TxT 矩阵。
每一行回答一个简单的问题。在更新这个 token 时,每个可见的 token 应该有多重要?在仅包含解码器的 LLM 中,未来的位置会被掩码遮蔽,这就是为什么下图中矩阵的右上部分被置灰的原因。
自注意力的本质是在因果掩码下学习这些 token 到 token 的权重模式,然后利用它们来构建具有上下文感知的 token 表示。
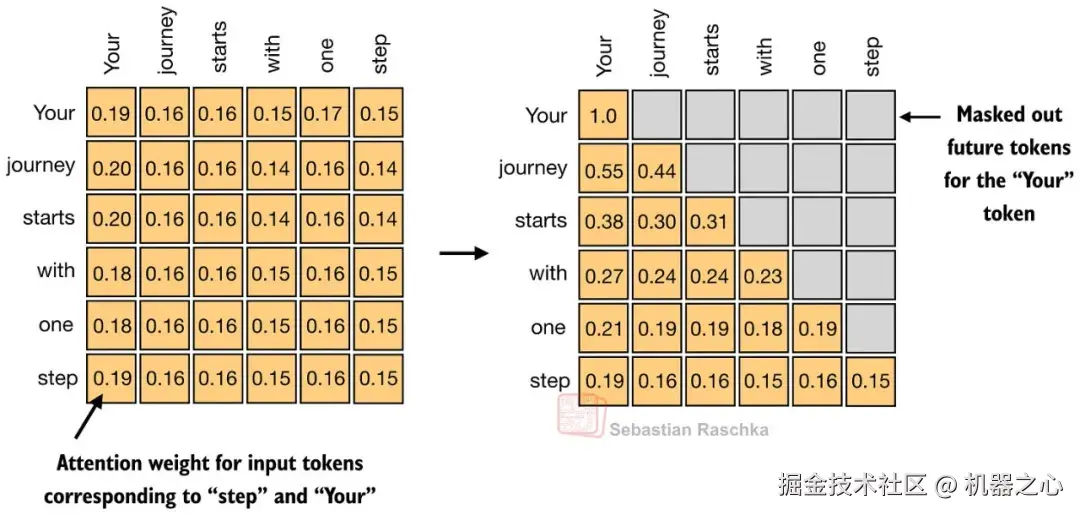
图 6 :一个具体的掩码注意力矩阵,其中每一行属于一个 token ,每个条目是一个注意力权重,未来 token 的条目被因果掩码移除
1.4 自注意力内部机制
下图展示了 Transformer 如何从输入嵌入 X 计算注意力矩阵(A),然后将其用于生成转换后的输入(Z)。
这里的 Q、K 和 V 代表查询、键和值。一个 token 的查询代表该 token 正在寻找的内容,键代表每个 token 提供用于匹配的内容,而值代表在计算出注意力权重后混合到输出中的信息。
步骤如下:
-
Wq、Wk 和 Wv 是将输入嵌入投影到 Q、K 和 V 的权重矩阵
-
QK^T 生成原始的 token 到 token 的相关性得分
-
softmax 将这些得分转换为我们在上一节中讨论的归一化注意力矩阵 A
-
将 A 应用于 V 以生成输出矩阵 Z
请注意,注意力矩阵并非单独手动编写的对象,它产生自 Q、K 和 softmax 过程。
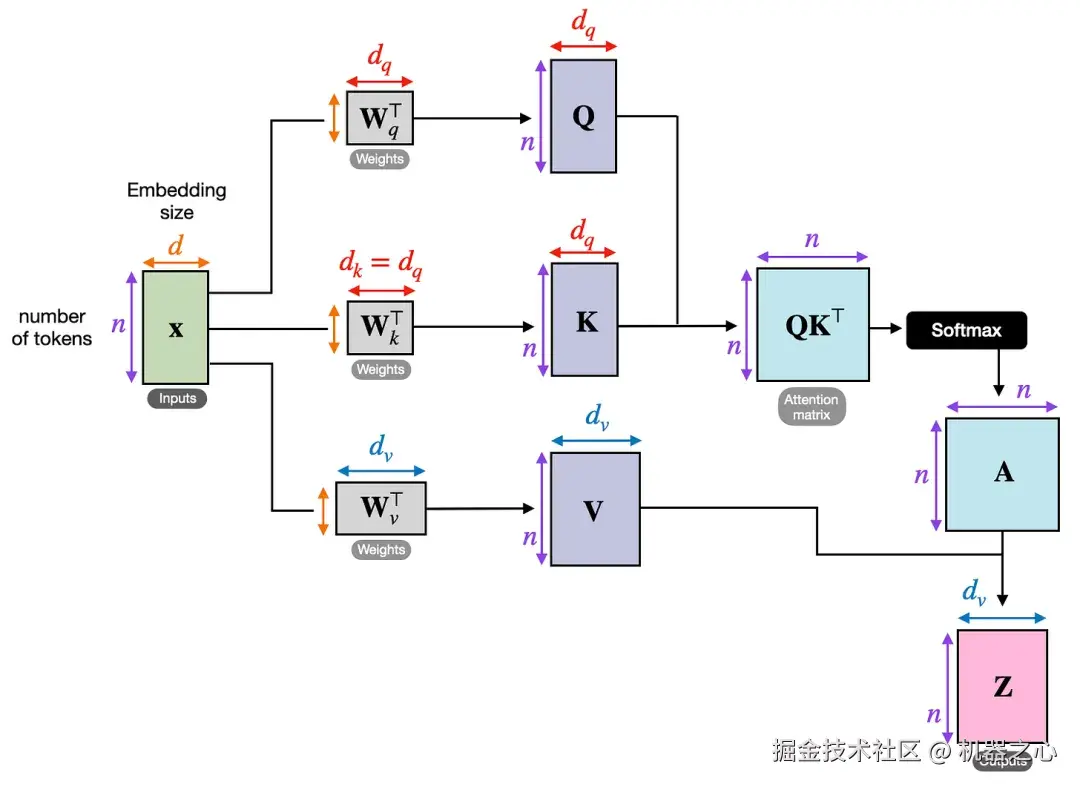
图 7 :完整的单头流水线,从输入嵌入 X 到归一化的注意力矩阵 A 和输出表示 Z。
下图展示了与上图相同的概念,区别在于注意力矩阵的计算隐藏在「缩放点积注意力」框中,并且我们仅针对一个输入 token 执行计算,不再针对所有输入 token。这是为了展示单头自注意力的紧凑形式,随后在下一节中将其扩展为多头注意力。
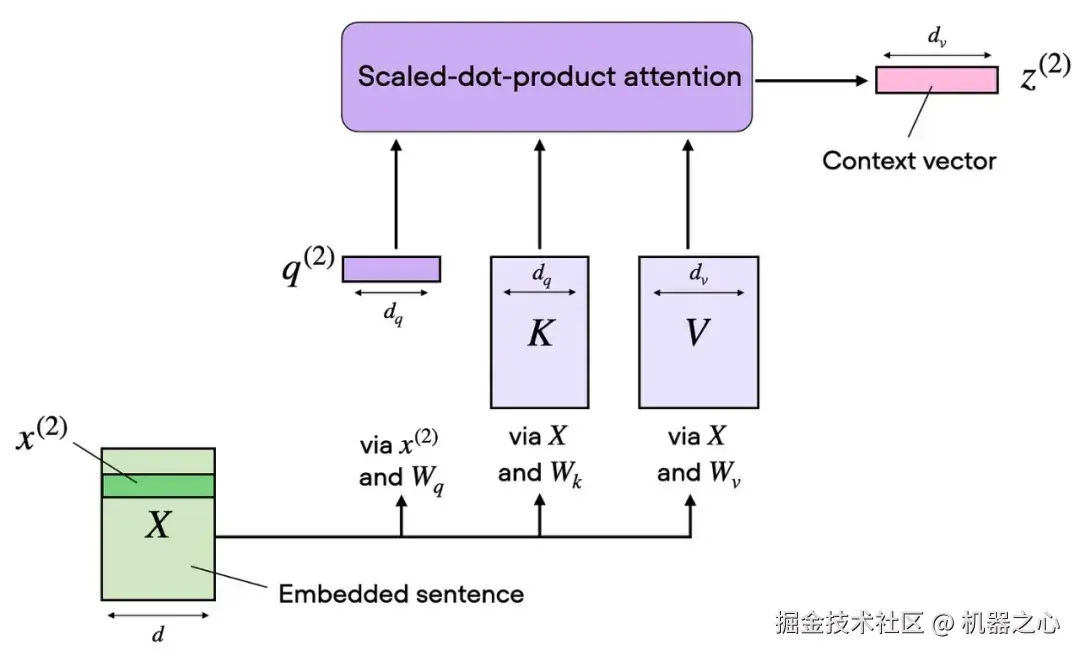
图 8 :一个注意力头已经是一个完整的机制。一组学习到的投影会生成一个注意力矩阵和一个具备上下文感知的输出流。
1.5 从单头到多头注意力
一组 Wq/Wk/Wv 矩阵为我们提供了一个注意力头,这意味着一个注意力矩阵和一个输出矩阵 Z。(此概念在上一节中已说明。)
多头注意力只需使用不同的学习投影矩阵并行运行几个这样的头。
这是很有用的做法,因为不同的头可以专门处理不同的 token 关系。一个头可能专注于短暂的局部依赖关系,另一个头关注更广泛的语义链接,还有一个头关注位置或句法结构。
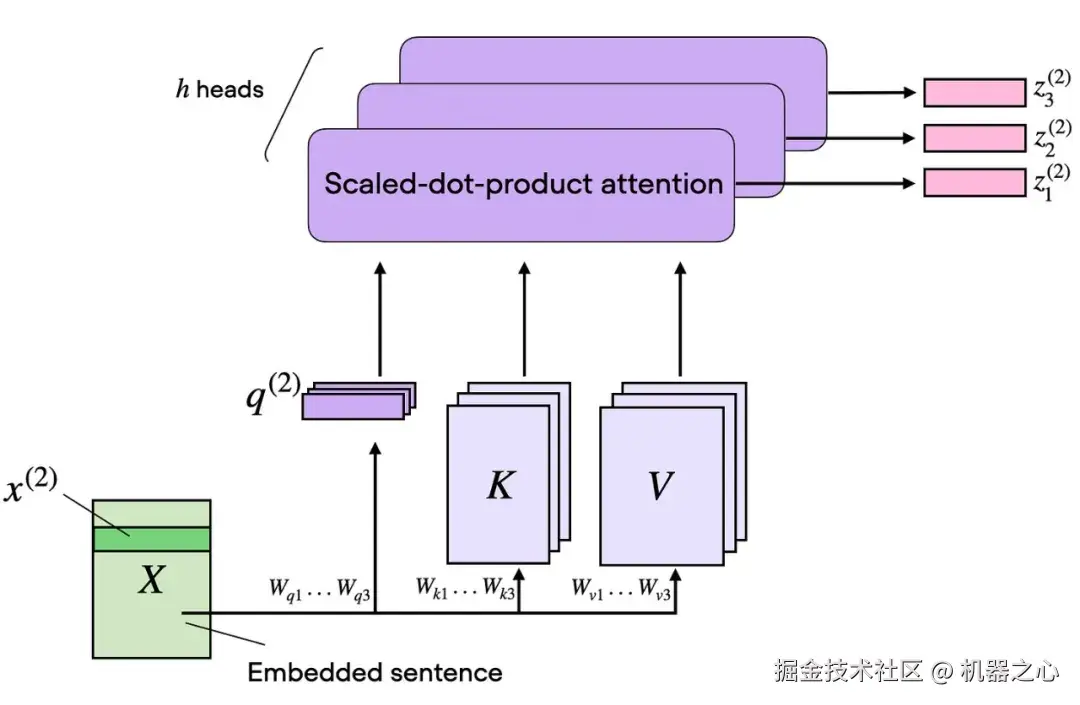
图 9 :多头注意力保持相同的基本注意力方法,但在多个头之间并行重复该方法,以便模型可以同时学习多个 token 到 token 的模式。
2. 分组查询注意力 (GQA)
分组查询注意力是源自标准 MHA 的注意力变体。它由 Joshua Ainslie 及其同事在 2023 年的论文《GQA: Training Generalized Multi-Query Transformer Models from Multi-Head Checkpoints》中提出。
它的做法让几个查询头共享相同的键值投影,摒弃了为每个查询头提供各自键和值的做法。这使得 KV 缓存的成本更低(主要是减少了内存),同时也没有对整体解码器方案进行太大的改变。
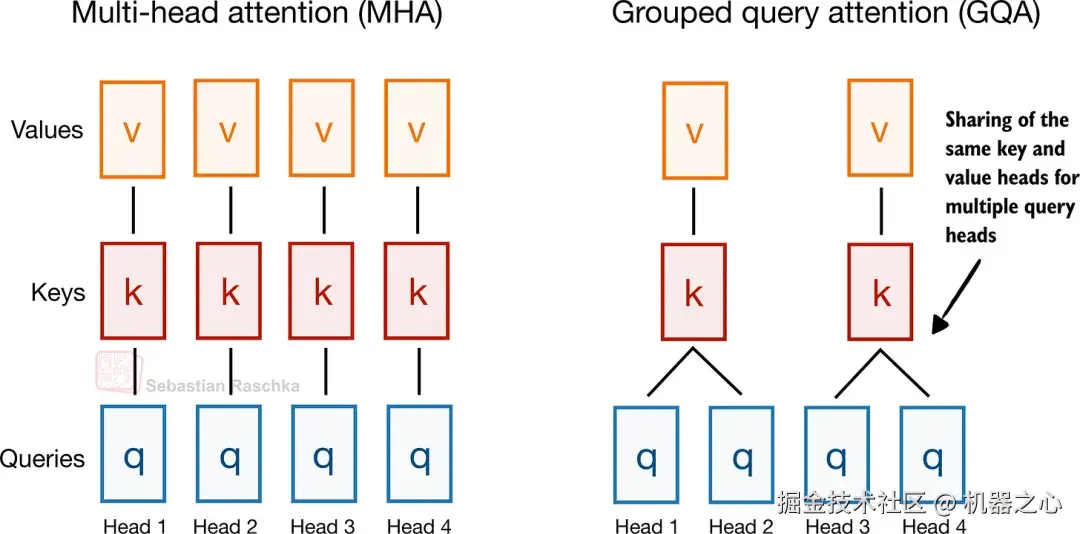
图 10 :GQA 保持与 MHA 相同的整体注意力模式,但通过跨多个查询头共享它们来减少键值头的数量。
示例架构
-
稠密模型:Llama 3 8B、Qwen3 4B、Gemma 3 27B、Mistral Small 3.1 24B、SmolLM3 3B 和 Tiny Aya 3.35B。
-
稀疏模型(混合专家):Llama 4 Maverick、Qwen3 235B-A22B、Step 3.5 Flash 196B 和 Sarvam 30B。
2.1 为什么 GQA 变得受欢迎
在我的架构比较文章中,我将 GQA 定位为经典多头注意力 (MHA) 的新标准替代方案。原因是标准 MHA 为每个头提供了自己的键和值,从建模的角度来看这是更优的,但在推理过程中一旦我们必须将所有这些状态保留在 KV 缓存中,成本就会很高。
在 GQA 中,我们保留较大的一组查询头,但我们减少了键值头的数量并让多个查询共享它们。这降低了参数数量和 KV 缓存流量,并且无需像稍后将讨论的多头潜在注意力 (MLA) 那样进行大幅度的实现更改。
在实践中,这使其成为并保持为那些希望找到比 MHA 更便宜但比 MLA 等较新的重度压缩替代方案更易于实现的实验室的非常受欢迎的选择。
2.2 GQA 内存节省
GQA 在 KV 存储方面节省了大量空间,因为每层我们保留的键值头越少,每个 token 所需的缓存状态就越少。这就是为什么随着序列长度的增加,GQA 变得更有用的原因。
GQA 也是一个光谱。如果我们一路减少到一个共享的 K/V 组,我们就实际上进入了多查询注意力的领域,它甚至更便宜,但可能会更明显地损害建模质量。最佳平衡点通常在多查询注意力( 1 个共享组)和 MHA(其中 K/V 组等于查询的数量)之间的某个位置,在这个位置,缓存节省量很大,但相对于 MHA 的建模性能下降保持在适度范围内。
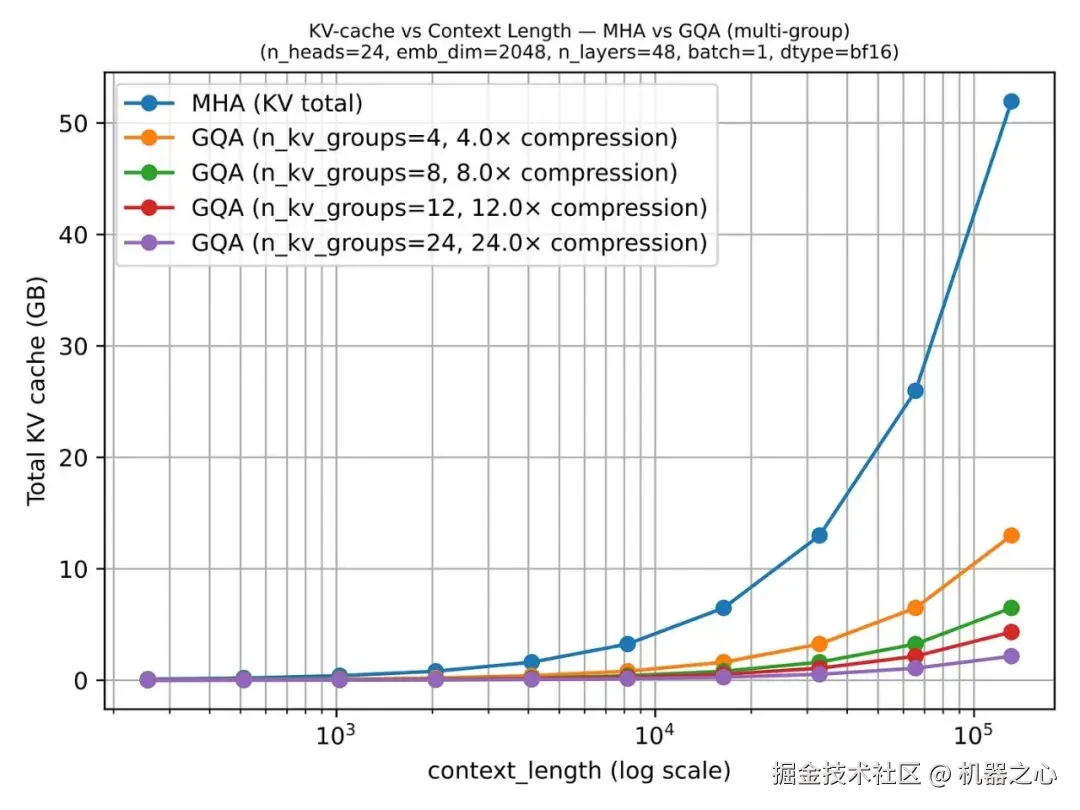
图 11 :越低越好。一旦上下文窗口扩大,KV 缓存的节省就会变得更加明显。
2.3 为什么 GQA 在 2026 年仍然重要
诸如 MLA 等更高级的变体正变得越来越受欢迎,因为它们可以在相同的 KV 效率水平下提供更好的建模性能(例如,如 DeepSeek-V2 论文的消融研究所讨论的那样),但它们也涉及更复杂的实现和更复杂的注意力堆栈。
GQA 仍然具有吸引力,因为它具有稳健性,更容易实现,并且更容易训练(根据我的经验,需要调整的超参数更少)。
这就是为什么一些较新的发布版本仍在此处刻意保持经典设计的原因。例如,在我的春季架构文章中,我提到 MiniMax M2.5 和 Nanbeige 4.1 是保持非常经典设计的模型,仅使用分组查询注意力,而没有堆砌其他效率技巧。Sarvam 也是一个非常有用的比较对象: 30B 模型保留了经典的 GQA ,而 105B 版本则切换到了 MLA。
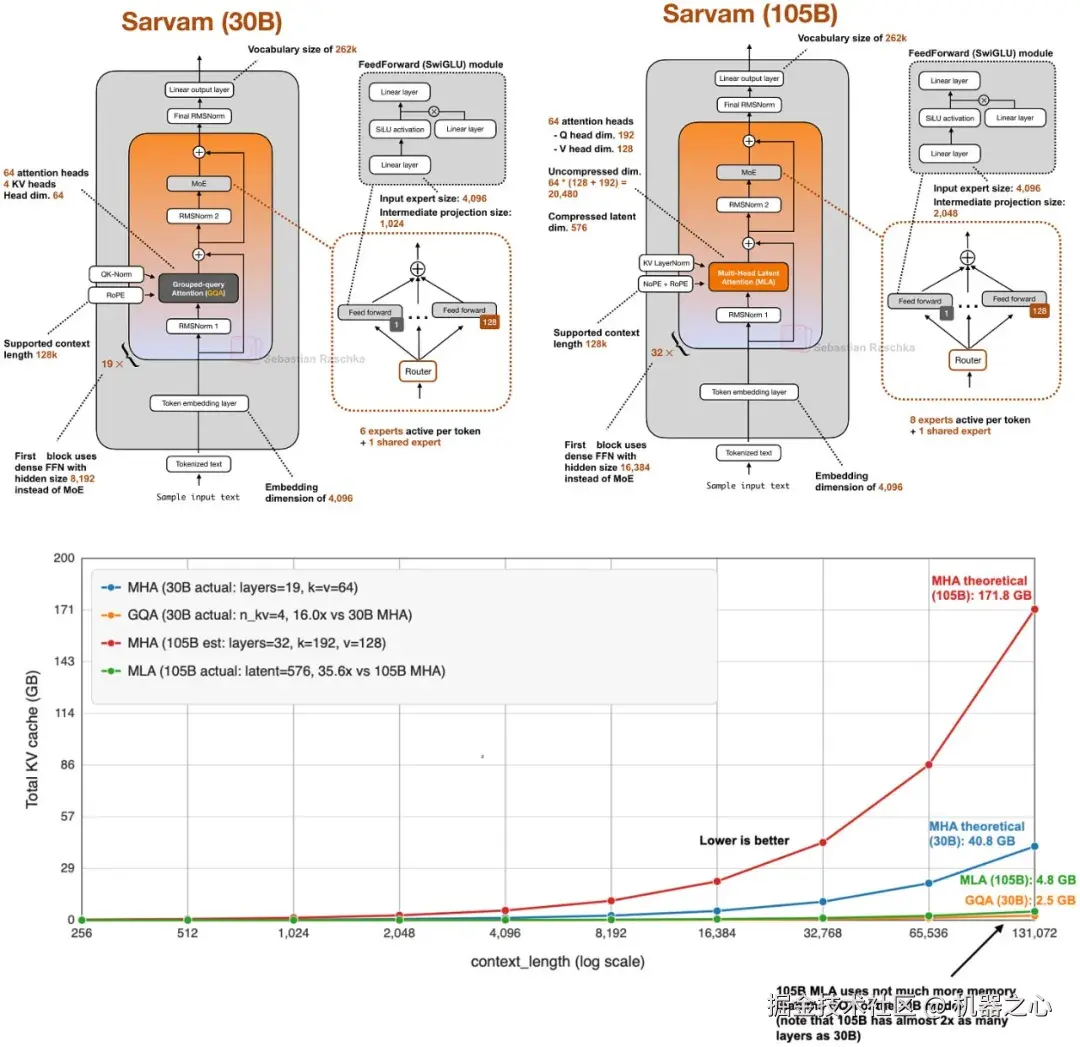
图 12 :105B Sarvam(使用 MLA)与 30B Sarvam(使用 GQA)以及使用普通 MHA 的总 KV 缓存大小对比。
3. 多头潜在注意力 (MLA)
多头潜在注意力 (MLA) 背后的动机与分组查询注意力 (GQA) 相似。两者都是用于降低 KV 缓存内存需求的解决方案。GQA 和 MLA 之间的区别在于,MLA 通过压缩存储的内容来缩小缓存,它抛弃了通过共享头来减少存储的 K/V 数量的方式。
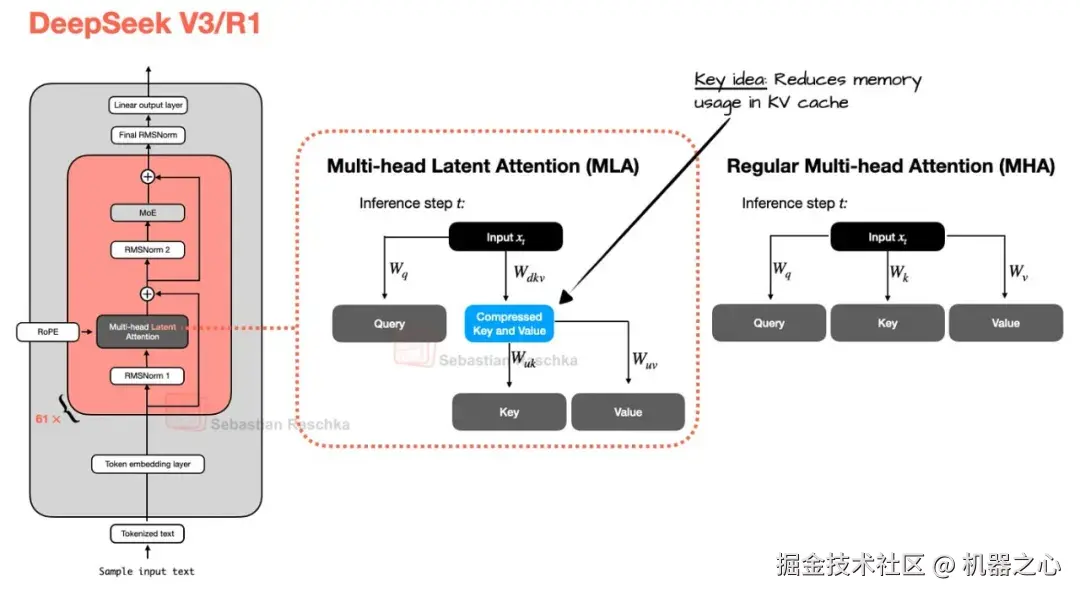
图 13 :与 GQA 不同,MLA 并非通过对头进行分组来降低 KV 成本。它通过缓存压缩的潜在表示来降低成本。请注意,它也应用于查询,为简单起见未显示
MLA 最初在 DeepSeek-V2 论文中提出,成为 DeepSeek 时代标志性的理念(特别是在 DeepSeek-V3 和 R1 之后)。它比 GQA 的实现更复杂,服务部署也更复杂,但如今,一旦模型大小和上下文长度变得足够大以至于缓存流量开始占据主导地位,它通常也会变得更具吸引力,因为在相同的内存减少率下,它可以保持更好的建模性能(稍后会详细介绍)。
示例架构:DeepSeek V3、Kimi K2、GLM-5、Ling 2.5、Mistral Large 3 和 Sarvam 105B
3.1 压缩机制
放弃像 MHA 和 GQA 中那样缓存全分辨率的键和值张量,MLA 选择存储一种潜在表示,并在需要时重建可用状态。从本质上讲,这是一种嵌入在注意力机制中的缓存压缩策略,如上图所示。
下图显示了与常规 MHA 相比节省的空间。
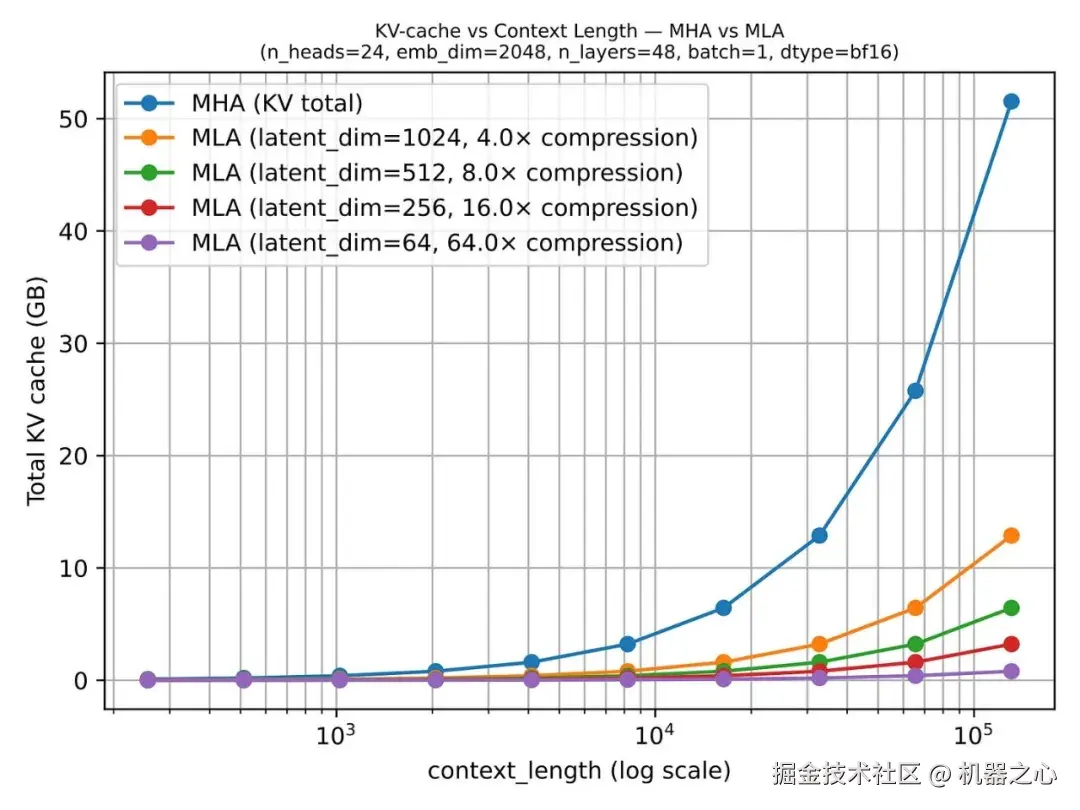
图 14 :一旦上下文长度增加,与缓存全张量 K/V 相比,缓存潜在表示所带来的节省变得非常明显
3.2 MLA 消融实验
DeepSeek-V2 论文提供了一些消融实验结果,其中 GQA 在建模性能方面表现得比 MHA 差,而 MLA 表现得更好,如果在仔细调整的情况下,甚至可以超越 MHA。这比「它(也)节省了内存」是一个强有力的多得多的理由。
换句话说,MLA 之所以成为 DeepSeek 更受青睐的注意力机制,除去其本身的高效,它在大规模下看起来也是一种保持质量的效率举措。(但同事们也告诉我,MLA 只有在特定尺寸下效果良好。对于较小的模型,比方说小于 100B ,GQA 似乎效果更好,或者至少更容易调整和完善。)
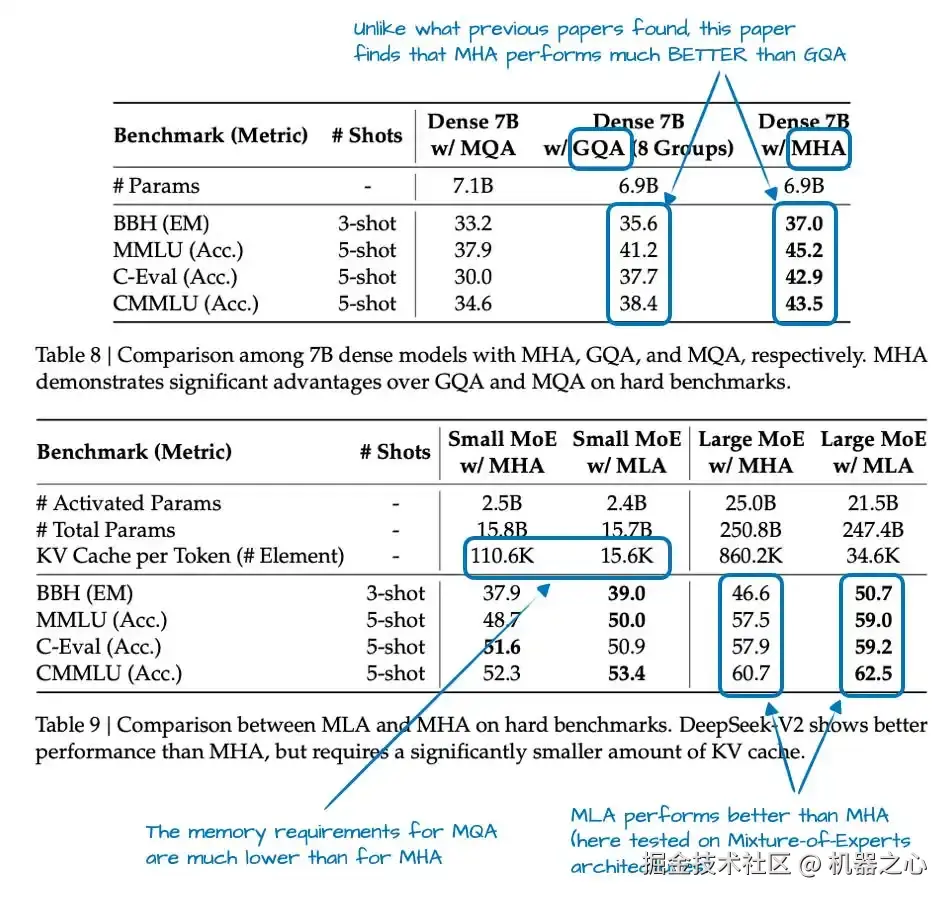
图 15 :在这里,GQA 降至 MHA 以下,而 MLA 保持竞争力甚至略微超越 MHA。底层论文:DeepSeek-V2。
下面又是 30B Sarvam 中的 GQA 与 105B Sarvam 中的 MLA 之间的比较。
图 16 :GQA 和 MLA 正在从不同方向解决同一个瓶颈。其权衡点在于简单性与大型模型更好的建模性能之间的取舍。
3.3 MLA 在 DeepSeek 之后如何传播
自从 DeepSeek V3/R1、V3.1 等版本在 V2 中引入该设计并将其标准化后,它开始出现在第二波架构中。Kimi K2 保留了 DeepSeek 的方案并对其进行了扩展。GLM-5 采用了 MLA 连同 DeepSeek 稀疏注意力(来自 DeepSeek V3.2 )。Ling 2.5 将 MLA 与线性注意力混合架构结合在一起。Sarvam 发布了两个模型,其中 30B 模型保留了经典的 GQA,而 105B 模型切换到了 MLA。
最后一对特别有用,因为它将技术复杂性的讨论放在了一边。即,Sarvam 团队实现了这两种变体,并刻意选择在一个变体中使用 GQA ,而在另一个变体中使用 MLA。因此,在某种意义上,这使得 MLA 给人的感觉少了一点理论上的替代方案的意味,多了一点家族模型扩展后具体的架构升级路径的意味。
4. 滑动窗口注意力 (SWA)
滑动窗口注意力通过限制每个位置可以关注的先前 token 数量,来降低长上下文推理的内存和计算成本。这里摒弃了关注整个前缀的做法,每个 token 仅关注其位置周围近期 token 的固定窗口。由于注意力被限制在局部的 token 邻域,这种机制通常被称为局部注意力。
一些架构将这些局部层与偶尔的全局注意力层结合在一起,以便信息仍然可以在整个序列中传播。
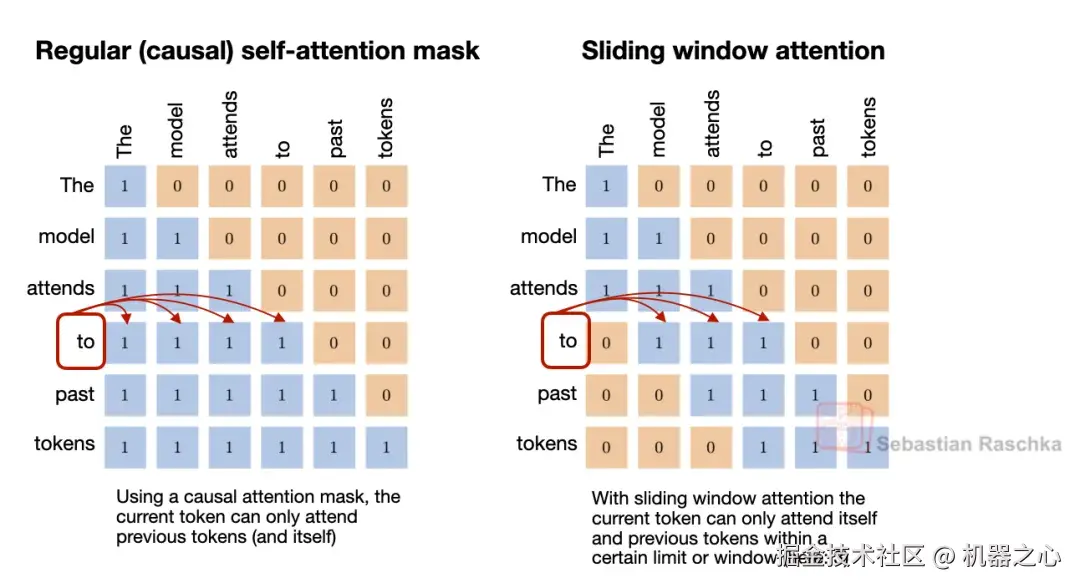
图 17 :概念上的转变很简单。常规注意力是全局注意力,而滑动窗口注意力是局部注意力。全局注意力让每个 token 都能看到完整的前缀;SWA 将许多这样的层转变为局部注意力层
示例架构:Gemma 3 27B、OLMo 3 32B、Xiaomi MiMo-V2-Flash、Arcee Trinity、Step 3.5 Flash 和 Tiny Aya
4.1 以 Gemma 3 作为参考点
Gemma 3 仍然是最近最清晰的 SWA 示例之一,因为它很容易与 Gemma 2 进行比较。Gemma 2 已经使用了一种混合注意力设置,局部层与全局层的比例为 1:1 ,并具有 4096 个 token 的窗口。Gemma 3 将这一比例进一步推至 5:1 ,并将窗口大小减小到 1024。
关键发现并不在于局部注意力更便宜,因为这已经是众所周知的。从 Gemma 3 的消融研究中得出的更有趣的结论是,更激进地使用这种方法似乎对建模性能的影响微乎其微。
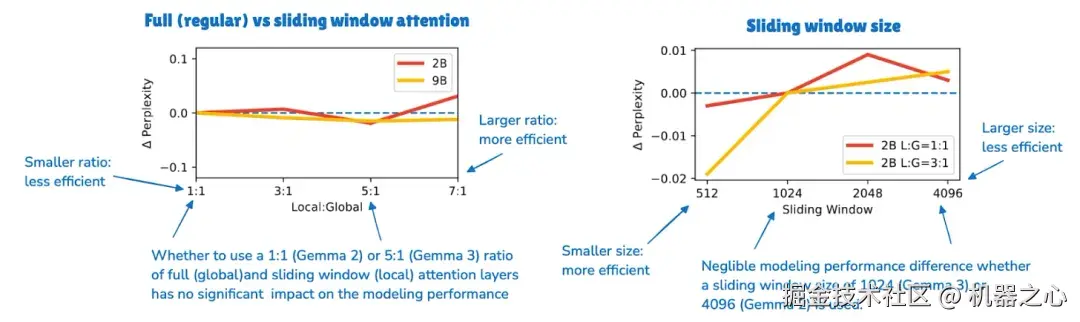
Gemma 消融研究表明,较小的窗口和更激进的局部与全局比例对困惑度的影响很小。底层论文:Gemma 3
4.2 比例与窗口大小
在实践中,说一个模型「使用 SWA」并不意味着它仅依赖于 SWA。通常重要的是局部到全局的层模式和注意力窗口大小。例如:
-
Gemma 3 和 Xiaomi 使用 5:1 的局部到全局模式。
-
OLMo 3 和 Arcee Trinity 使用 3:1 的模式。
-
Xiaomi 还使用 128 的窗口大小,这比 Gemma 的 1024 小得多,因此也更加激进。
-
SWA 本质上是一个旋钮,可以对其进行不同程度的激进调整。
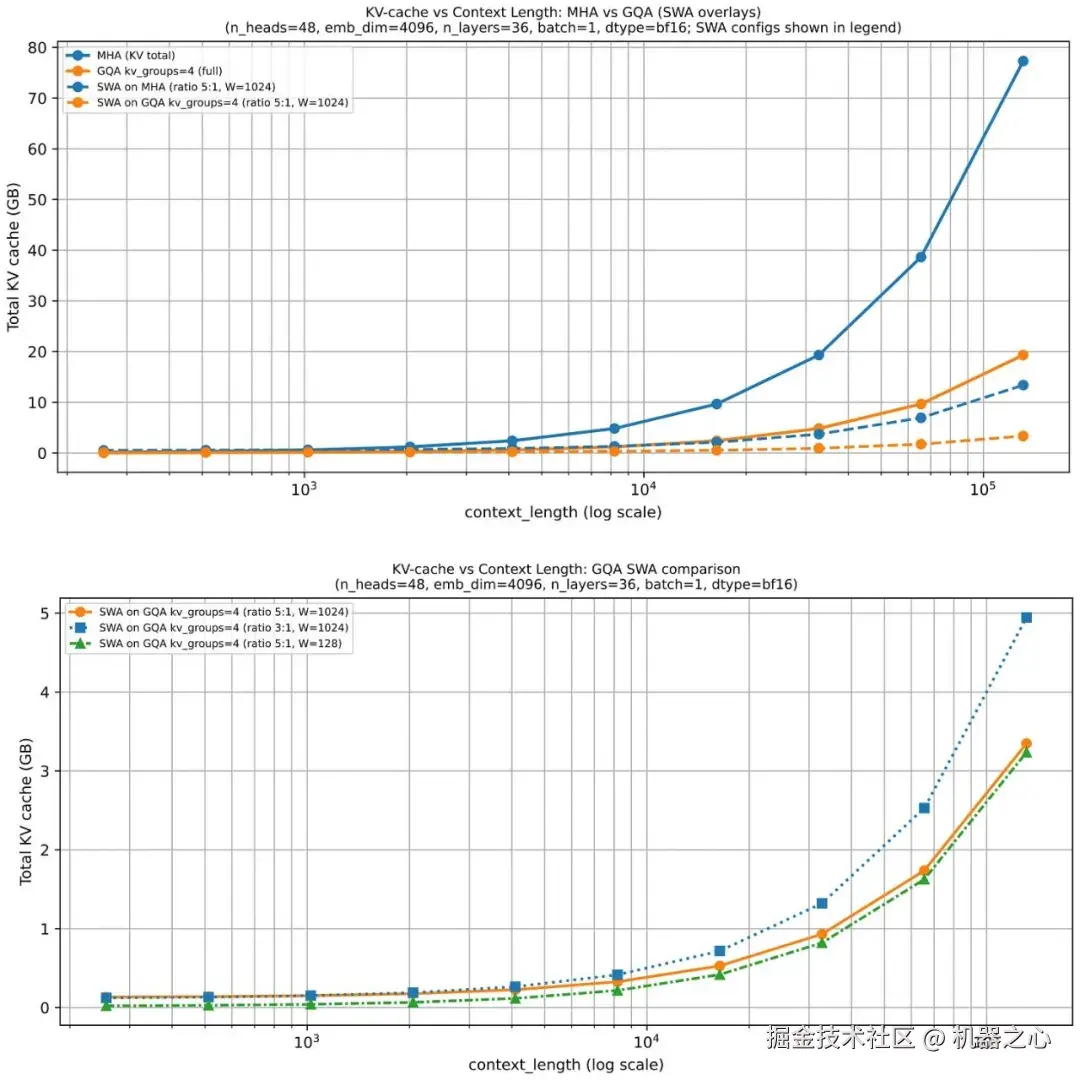
图 18 :长上下文的节省来自于将许多全注意力层转变为局部注意力层,这减少了这些层需要考虑的缓存上下文的数量
4.3 将 SWA 与 GQA 结合
SWA 经常与 GQA 一起出现,因为这两个想法解决了同一个推理问题的不同部分。SWA 减少了局部层必须考虑的上下文数量。GQA 减少了每个 token 贡献给缓存的键值状态的数量。
这就是为什么许多最近的稠密模型会同时使用两者,摒弃了将它们视为替代方案的做法。Gemma 3 在这里又是一个很好的参考点,因为它在同一个架构中结合了滑动窗口注意力和分组查询注意力。
5. DeepSeek 稀疏注意力 (DSA)
DeepSeek 稀疏注意力是出现在 DeepSeek V3.2 系列中,并随后在 GLM-5 中再次出现的架构变化之一。
具体来说,DeepSeek V3.2 将其与多头潜在注意力 (MLA) 结合使用,而 GLM-5 采用相同组合的大致原因也相同,即在上下文长度变大时降低推理成本。
示例架构:DeepSeek V3.2 和 GLM-5
5.1 相对于滑动窗口注意力的变化
在滑动窗口注意力中,当前 token 放弃关注完整的前缀,它只关注固定的局部窗口。这也是 DeepSeek 稀疏注意力背后相同的广义概念,即每个 token 也只关注先前 token 的一个子集。
然而,所选取的 token 并没有由固定宽度的局部窗口决定。作为替代,DeepSeek 稀疏注意力使用了一种学习到的稀疏模式。简而言之,它使用了一种索引器加选择器的设置,其中闪电索引器计算相关性得分,而 token 选择器仅保留一小部分得分较高的过去位置。
选取 token 子集的方式是与滑动窗口注意力的主要区别。滑动窗口注意力将局部性硬编码。DeepSeek 稀疏注意力仍然将注意力限制在一个子集上,但它让模型决定哪些先前的 token 值得回顾。
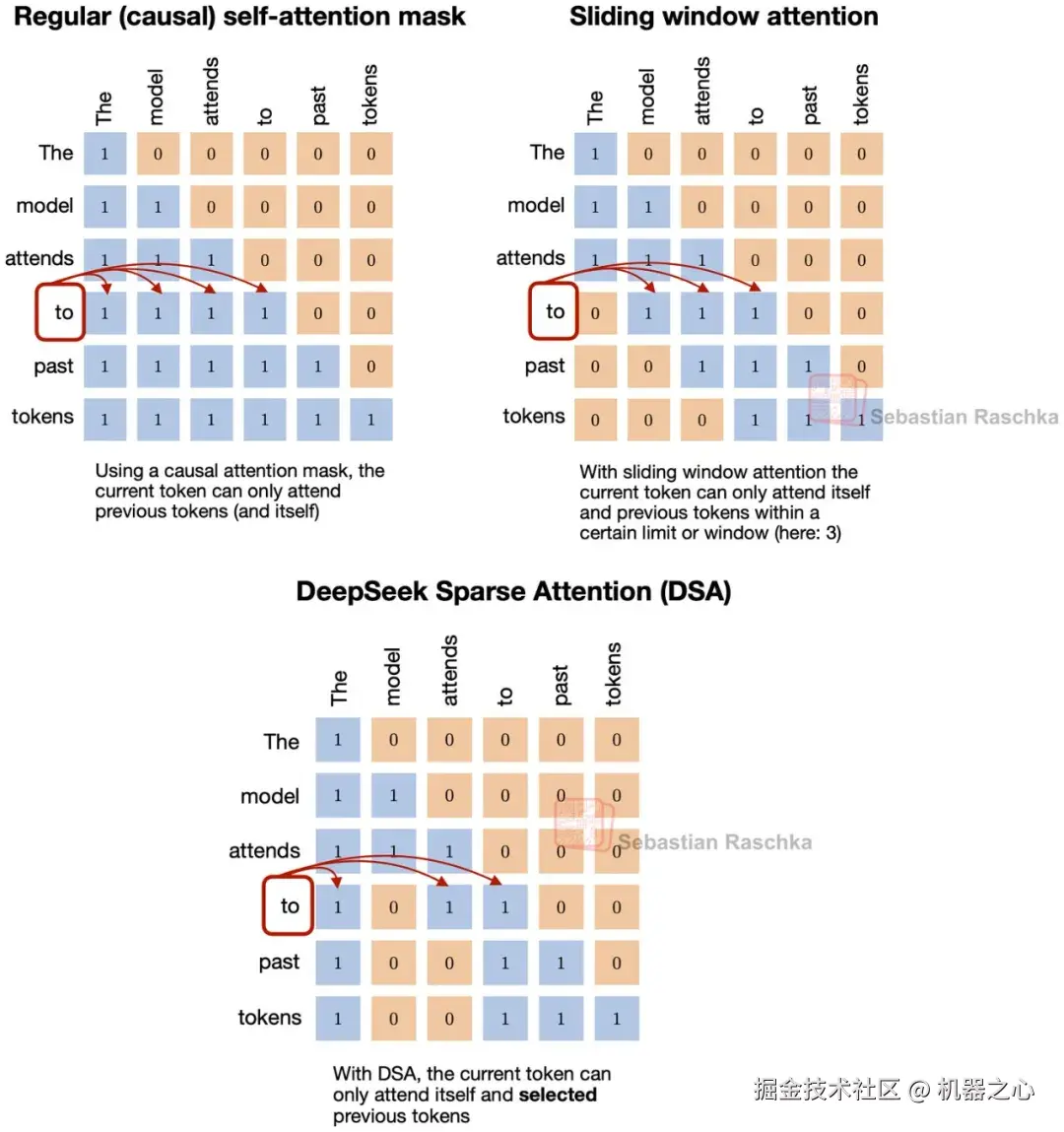
图 19 :与滑动窗口注意力类似,DeepSeek 稀疏注意力也将每个 token 限制在先前 token 的一个子集内,只不过它没有通过固定的局部窗口来实现这一点
5.2 DeepSeek 稀疏注意力与 MLA
DeepSeek V3.2 同时使用了多头潜在注意力 (MLA) 和 DeepSeek 稀疏注意力。MLA 通过压缩存储的内容来降低 KV 缓存成本。DeepSeek 稀疏注意力减少了模型必须回顾的先前上下文数量。换句话说,一个优化了缓存表示,另一个在其基础上优化了注意力模式。
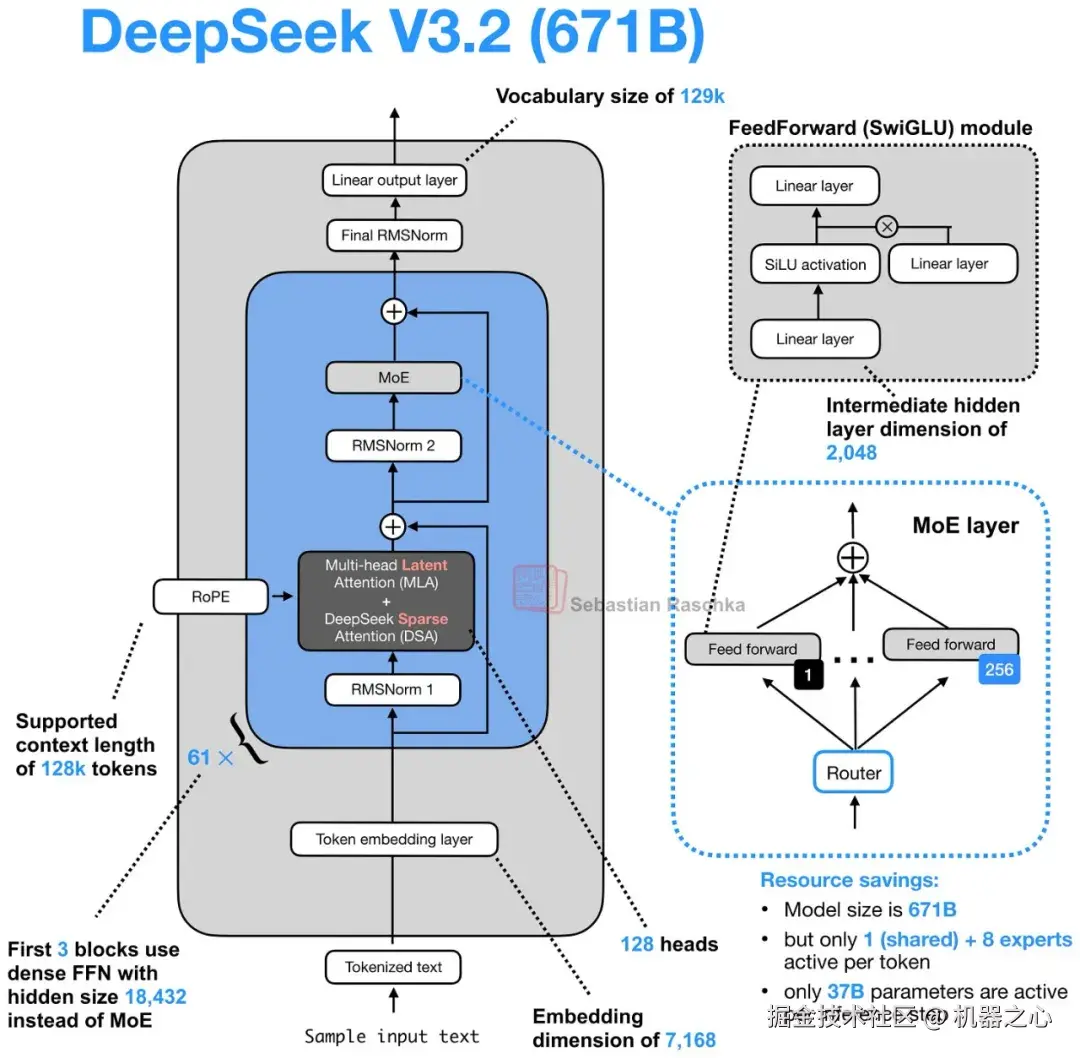
图 20 :DeepSeek V3.2 是明显的参考点,因为这是与稀疏注意力理念联系最紧密的模型家族。
稀疏模式并不随机。第一阶段是一个闪电索引器,它为每个新的查询 token 对之前的 token 进行评分。它利用 MLA 的压缩 token 表示,并在先前的上下文中计算一个学习到的相似度得分,因此模型可以对哪些早期位置值得回顾进行排名。
第二阶段是 token 选择器。它仅保留一个较小的、得分较高的子集,例如过去位置的 top-k 集合,并将该子集转换为稀疏注意力掩码。因此,重点在于 DeepSeek 稀疏注意力避开了硬编码稀疏模式的做法,它会去学习保留哪些过去的 token。
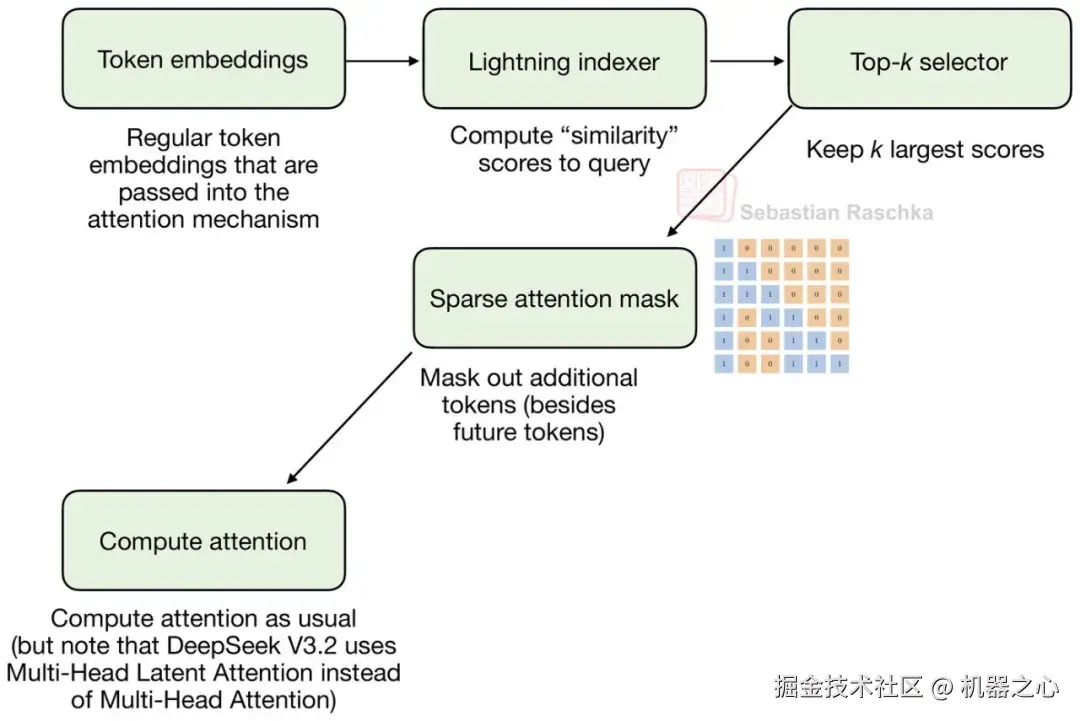
图 21 :该机制由一个为先前 token 评分的闪电索引器和一个仅保留较小子集用于注意力的选择器组成
DeepSeek 稀疏注意力相对较新且实现起来相对复杂,这也是为什么它尚未像分组查询注意力 (GQA) 那样被广泛采用的原因。
6. 门控注意力 (Gated Attention)
将门控注意力理解为一个经过修改的全注意力块最为妥当,它脱离了作为一个独立注意力家族的范畴。
它通常出现在混合堆栈中,这些堆栈仍然保留偶尔的全注意力层用于精确的内容检索,但在原本熟悉的缩放点积注意力块之上添加了一些以稳定性为导向的更改。
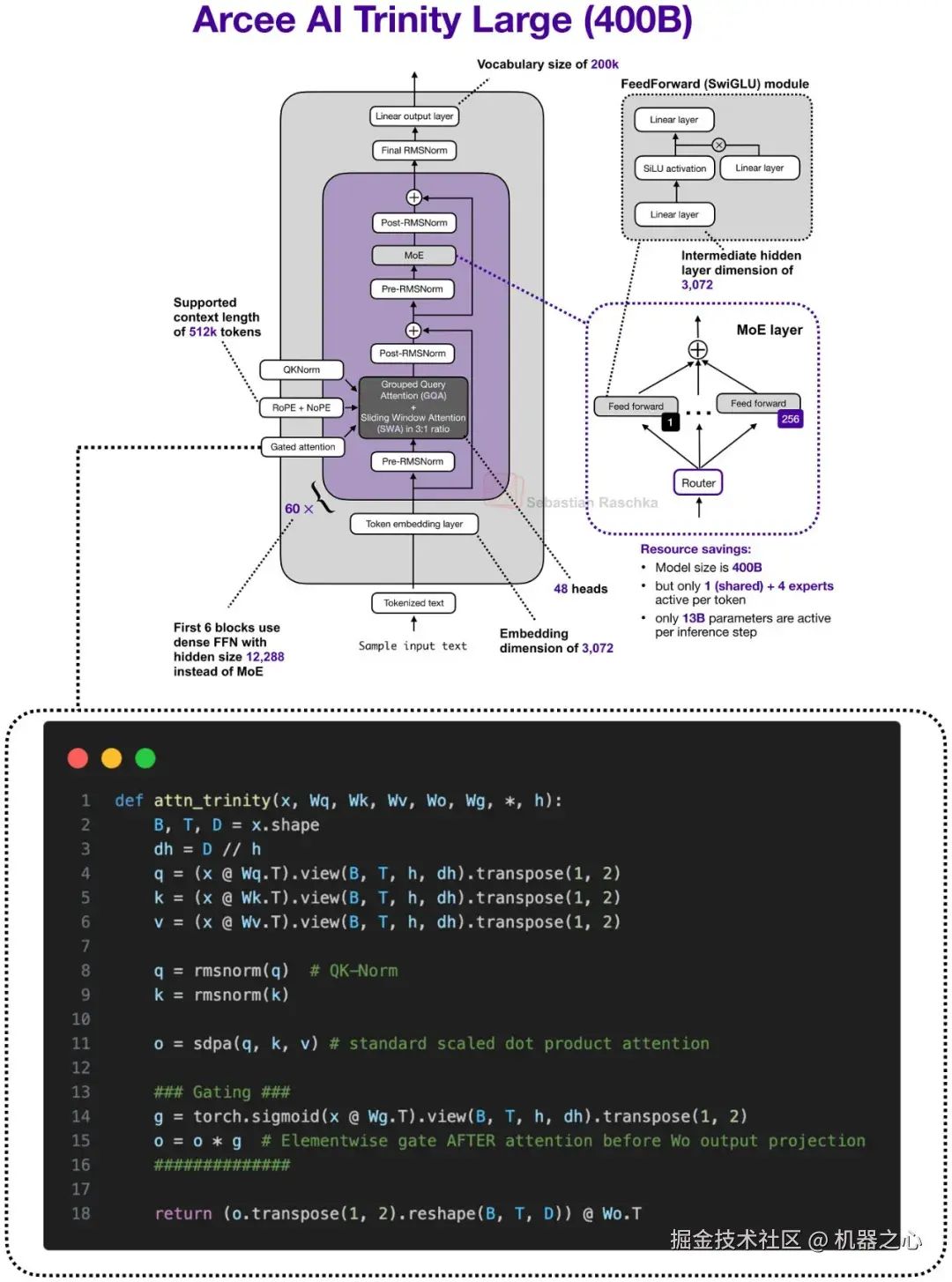
图 22 :Trinity Large 是一个有用的对比对象,因为门控注意力并不仅仅是 Qwen 的想法(稍后会详细介绍)。在这里,在一个不同的长上下文架构中,门控出现在缩放点积注意力输出之后,并在输出投影之前
6.1 门控注意力的应用位置
Qwen3-Next 和 Qwen3.5 架构表明,最近的混合架构(在下一节中介绍)并没有在所有地方取代注意力。作为一种妥协,它们用更便宜的替代方案取代了大多数注意力层,并在堆栈中保留了较少数量的全注意力层。
那些保留下来的全注意力层通常就是门控注意力出现的地方。Qwen3-Next 和 Qwen3.5 将其与 Gated DeltaNet 一起以 3:1 的模式使用。
撇开混合架构不谈,Trinity 在一个更传统的注意力堆栈中使用了相关的门控理念,如上图所示。
6.2 门控注意力与标准注意力的比较
Qwen 风格的混合架构或 Trinity(非混合架构)中的门控注意力块,本质上是标准缩悉点积注意力在之上加上了一些修改。在最初的门控注意力论文中,这些修改被视作一种方法,用于使保留在混合堆栈中的全注意力层的行为更具可预测性。
该块看起来仍然像标准的(全)注意力,但它增加了:
-
一个输出门,用于在将注意力结果加回残差之前对其进行缩放;
-
一种中心为零的 QK-Norm 变体,取代了用于 q 和 k 的标准 RMSNorm ;
-
局部 RoPE。
这些修改未达到 MLA 或线性注意力的规模,它们纯粹是应用于一个本来就熟悉的注意力块的稳定性和控制修改。
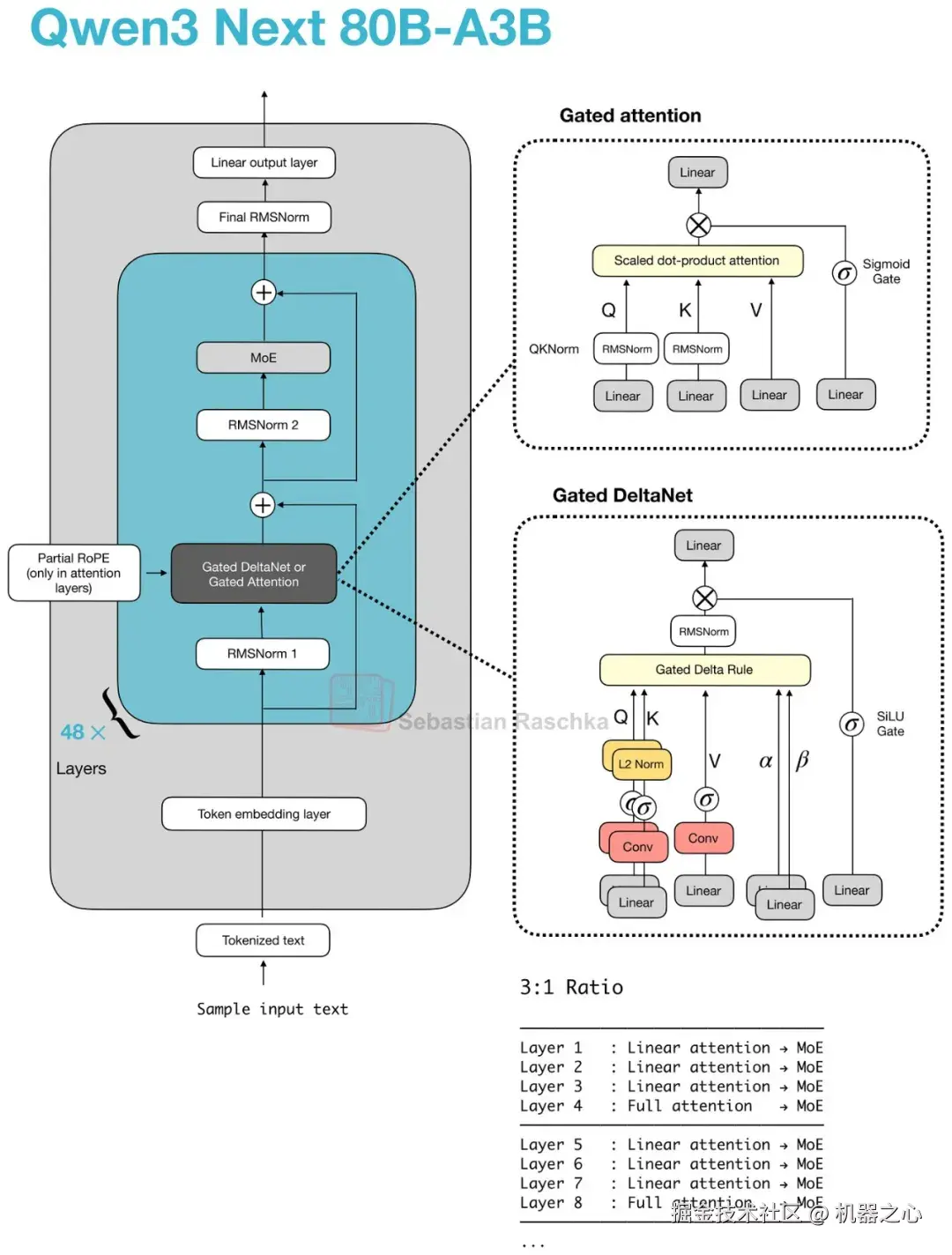
图 23 :在 Qwen3-Next 和 Qwen3.5 中,门控注意力作为全注意力层出现,它定期地阻断连续运行的 Gated DeltaNet 块。
请注意,上图还包含了 Gated DeltaNet ,我们将在下面的小节中对其进行介绍。
7. 混合注意力 (Hybrid Attention)
混合注意力是一种更广泛的设计模式,它超越了单一的特定机制。总体思路是保留类似 Transformer 的堆栈,但使用更便宜的线性或状态空间序列模块来替换大多数昂贵的全注意力层。
其动机在于长上下文效率。全注意力随序列长度呈二次方增长,因此一旦模型转向 128k 、 256k 或 1M token 这样的上下文,注意力的内存和计算成本就会变得非常高昂,以至于在大多数层中使用更便宜的序列模块,同时仅保留少量更繁重的检索层变得更加合理。(请注意,不过这会带来一些建模性能方面的权衡。)
在 Qwen3-Next 中,这种模式表现为 Gated DeltaNet 和门控注意力块的 3:1 混合。Gated DeltaNet 也与 Mamba-2 密切相关(例如,请参阅《Gated Delta Networks: Improving Mamba2 with Delta Rule》论文),并且该机制可以被理解为 DeltaNet 风格的快速权重更新与 Mamba 风格门控的结合。后来的架构保留了相同的整体思路,但换成了其他的轻量级序列混合器,例如 Kimi Delta Attention 、Lightning Attention 或标准的 Mamba-2。
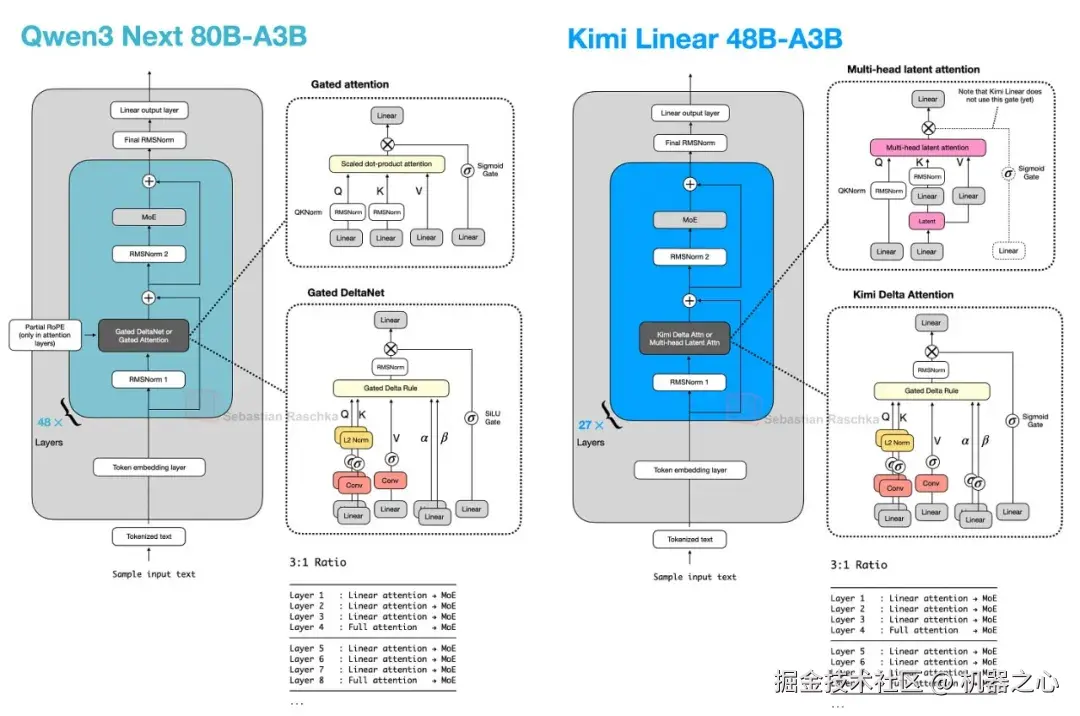
图 24 :基本的混合模式,其中大多数块是更便宜的序列混合器,每四个块恢复一个繁重的注意力层
7.1 Qwen3-Next 中的 Gated DeltaNet
据我所知,首个采用混合注意力的接近旗舰级 LLM 的显著例子是 2025 年的 Qwen3-Next ,它并未完全移除注意力机制,其做法是将三个 Gated DeltaNet 块与一个门控注意力块混合。
在这里,轻量级的 Gated DeltaNet 块承担了大部分长上下文的工作,并使内存增长比全注意力平缓得多。保留较重的门控注意力层是因为 DeltaNet 在基于内容的检索方面不够精确。
在 Gated DeltaNet 块内,模型连同两个学习到的门(α,β)一起计算查询、键和值向量。它使用 delta 规则更新写入一个小的快速权重内存,摆脱了形成通常的 token 到 token 注意力矩阵的步骤。粗略地说,内存存储了过去信息的压缩运行摘要,而门控制了添加多少新信息以及保留多少先验状态。
这使得 Gated DeltaNet 成为一种线性注意力或循环风格的机制,它绝不仅仅是对 MHA 的又一次微调。相对于 Mamba-2 ,两者的密切联系在于它们都属于线性时间门控序列模型家族,但 Gated DeltaNet 使用的是 DeltaNet 风格的快速权重内存更新,这取代了 Mamba 的状态空间更新。
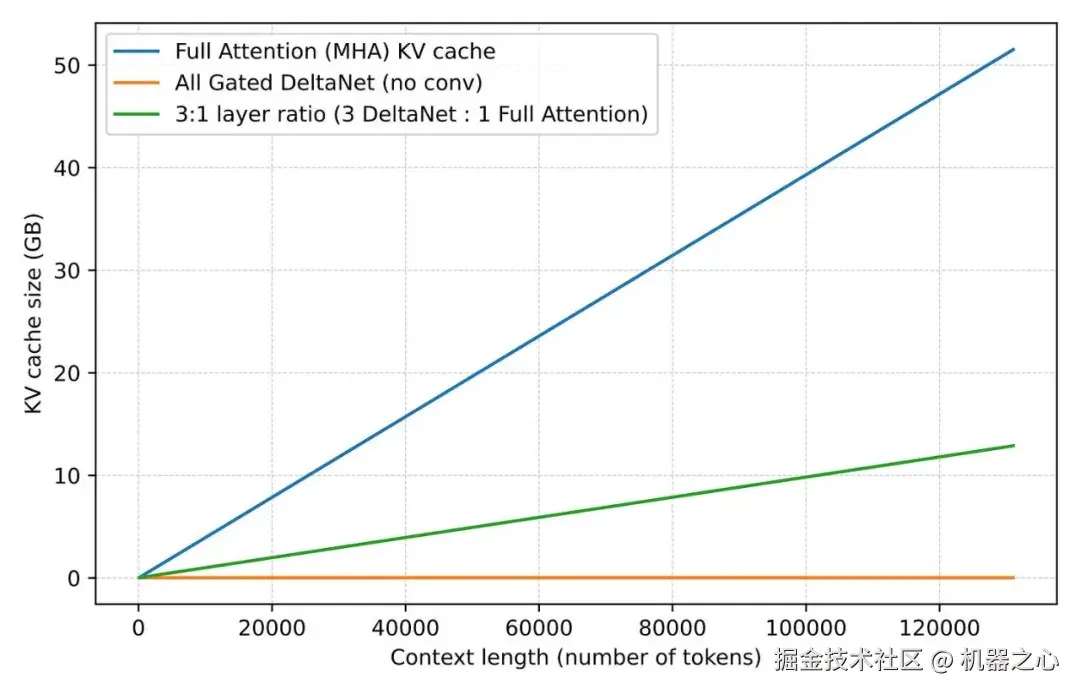
图 25 :混合架构背后的实际动机在内存曲线中显示。使用 Gated DeltaNet 的混合堆栈随着上下文长度的增长比普通的全注意力缓慢得多
Qwen3.5 将之前的 Qwen3-Next 混合架构引入了 Qwen 的主打旗舰系列,这是一个有趣的举动。这基本上标志着混合策略取得了成功,并且我们将来可能会看到更多采用这种架构的模型。
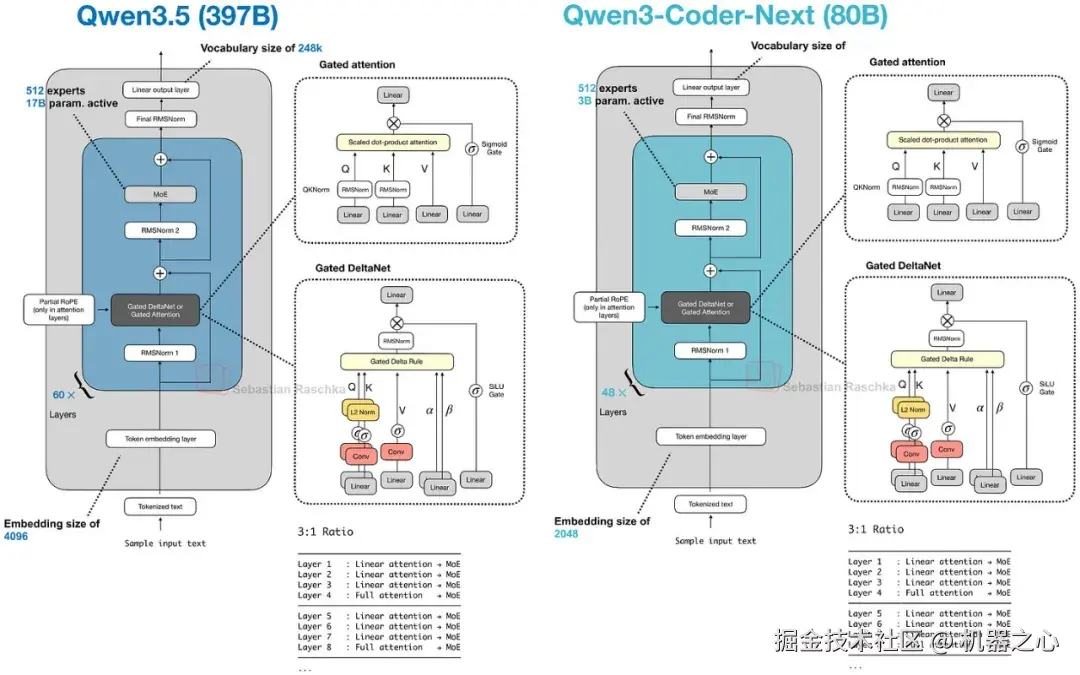
图 26 :Qwen3.5 展示了 Qwen 团队将之前的 Qwen3-Next 侧支提升到了主要模型线中,摆脱了将其作为一次性效率变体的地位
7.2 Kimi Linear 与改进的 Delta Attention
Kimi Linear 保留了相同的广泛 Transformer 骨架和相同的 3:1 模式,但它改变了配方的两半。
在轻量级方面,Kimi Delta Attention 是 Gated DeltaNet 的改进版。Qwen3-Next 为每个头使用标量门来控制内存衰减,Kimi 则使用通道级门控,这赋予了其对内存更新的更精细控制。在重量级方面,Kimi 用门控 MLA 层替换了 Qwen3-Next 的门控注意力层。
因此,这仍然是与 Qwen3-Next 和 Qwen3.5 相同的更广泛的模式,但这两个成分都发生了(轻微的)变化。即,大多数层仍然由更便宜的线性风格机制处理,并且仍然保留周期性的重型层以实现更强的检索能力。
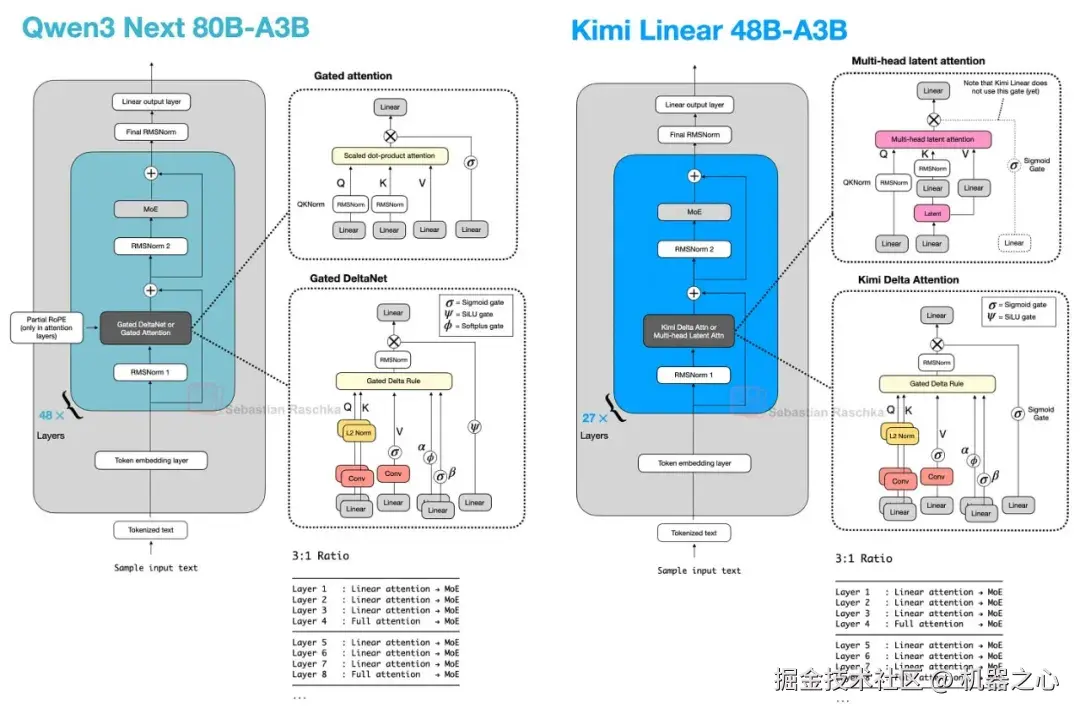
图 27 :Kimi Linear 保持了相同的整体混合模式,同时改变了堆栈的轻量级部分和较重的注意力部分
7.3 Ling 2.5 与 Lightning Attention
Ling 2.5 展示了在轻量级方面的另一种替换。Ling 放下了 Gated DeltaNet ,使用了一种称为 Lightning Attention 的稍微简单一些的循环线性注意力变体。在重量级方面,它保留了来自 DeepSeek 的 MLA。
大多数序列混合发生在更便宜的线性注意力块中,同时保留了少量较重的层以维持更强的检索。不同之处在于特定的轻量级机制现在是 Lightning Attention ,脱离了对 DeltaNet 或 Kimi Delta Attention 的依赖。
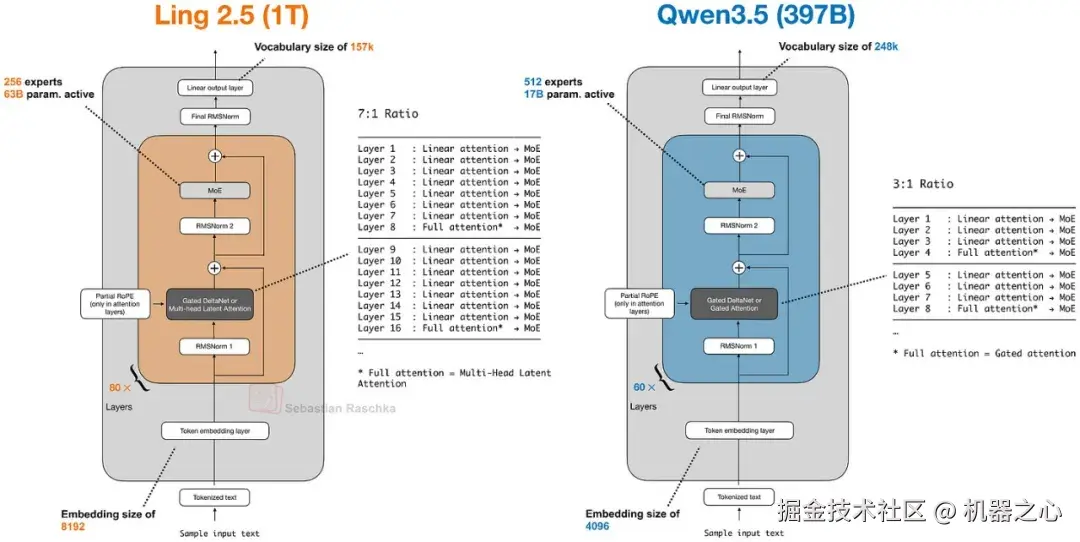
图 28 :Ling 2.5 和 Qwen3.5 都是线性注意力混合架构,尽管 Ling 采用了 Lightning Attention 和 MLA,避开了 Qwen 的方案
Ling 2.5 更多地针对长上下文效率,其目标并非绝对的基准测试领先地位。根据 Ling 团队的说法,据报道它在处理 32k token 时比 Kimi K2 快得多,这正是这些混合架构所追求的实际回报。
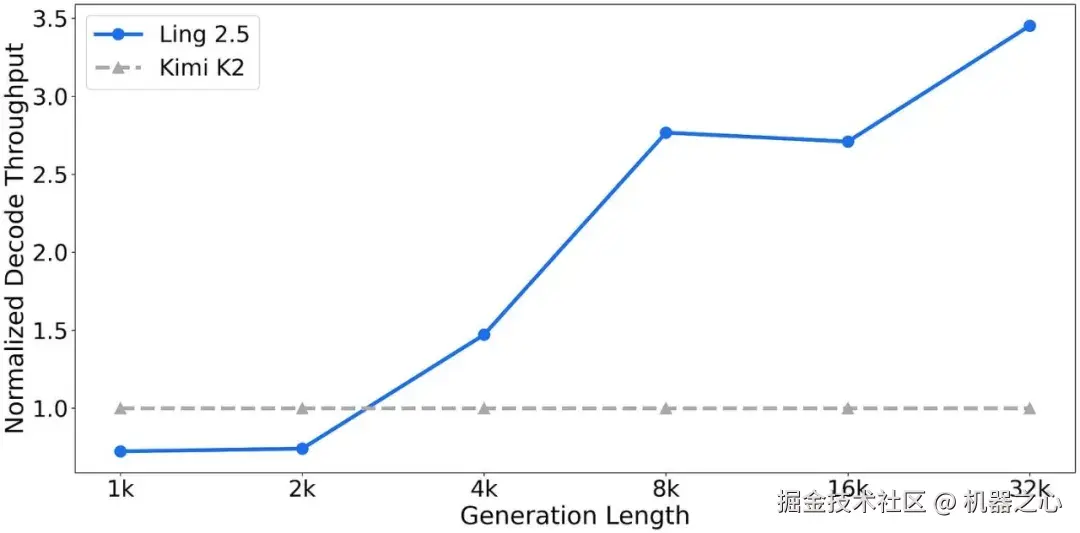
图 29 :Ling 2.5 作为一个强大的效率升级版推出,在同样的 1 万亿参数规模下,其 32k-token 的吞吐量远高于 Kimi K2
Nemotron 与 Mamba-2
Nemotron 将该模式进一步推离了 Transformer 基线。Nemotron 3 Nano 是一个 Mamba-Transformer 混合架构,它将 Mamba-2 序列建模块与稀疏 MoE 层交错排列,并且仅在一小部分层中使用自注意力。
这是上述相同基本权衡的更极端版本。在这里,轻量级序列模块是一个 Mamba-2 状态空间块,这取代了 DeltaNet 风格的快速权重更新,但基本的权衡是相似的。
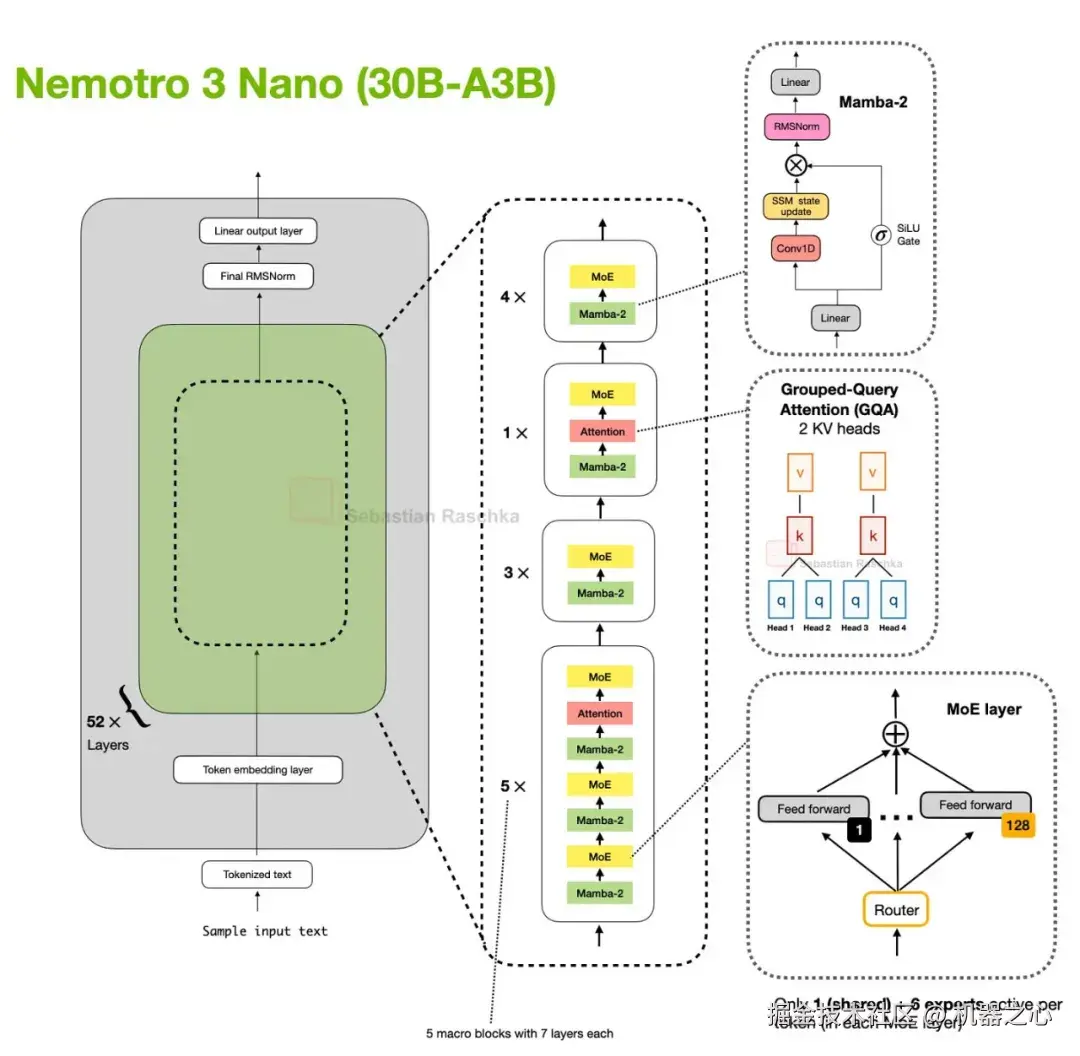
图 30 :Nemotron 3 Nano 使用 Mamba-2 完成大部分序列建模工作,自注意力仅出现在一小部分层中
更大的 Nemotron 3 Super 保留了 Mamba-2 混合注意力方法,并添加了其他以效率为导向的更改,例如潜在 MoE 和用于推测解码的共享权重多 token 预测 (MTP)。
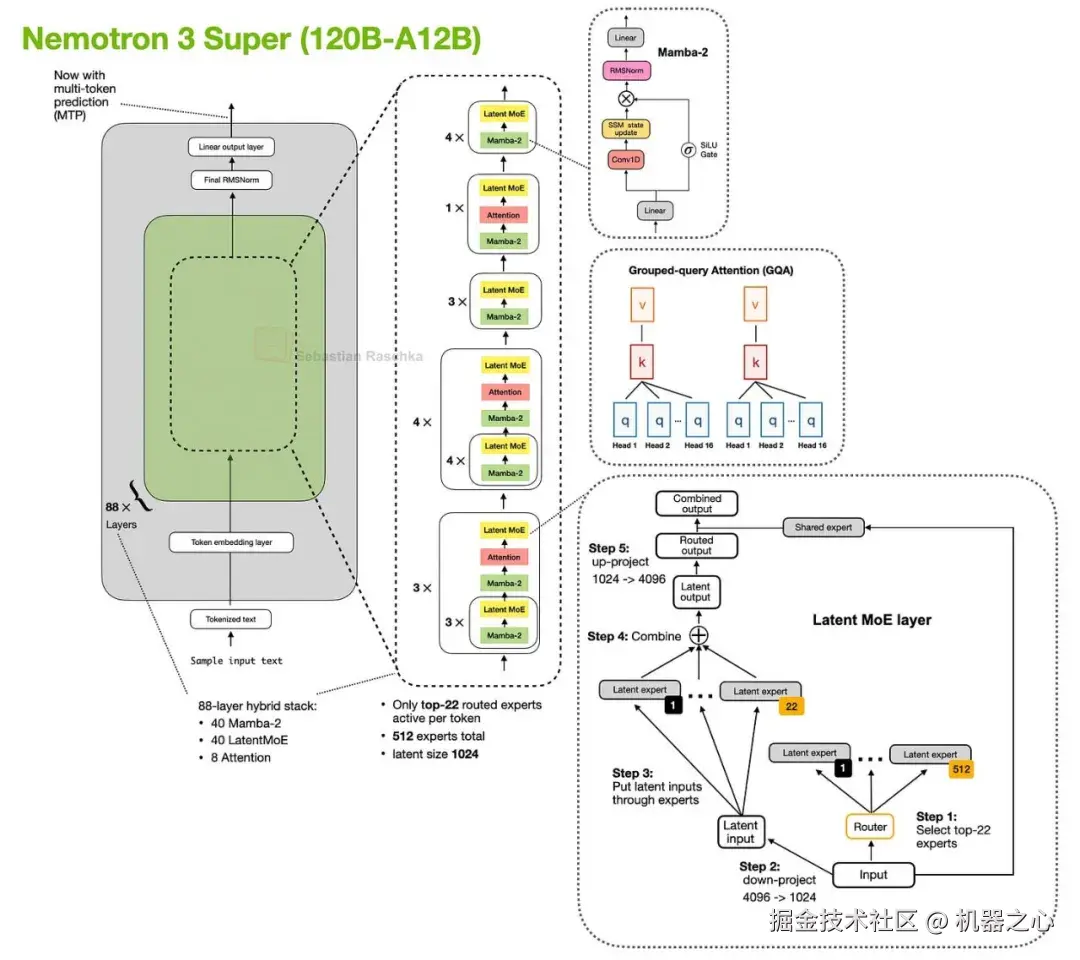
图 31 :Nemotron 3 Super 保留了 Mamba-2 混合注意力模式,同时在其基础上添加了潜在 MoE 和共享权重 MTP
结论
当然,在大量文献中还有更多(主要是小众的)注意力变体我在这里没有介绍。本文的重点集中于目前在最先进的(开放权重)模型中使用的那些变体。
我特别期待 (1) 看到全新的 Mamba-3 层被集成到上述混合架构中(替换 Gated DeltaNet ),以及 (2) 注意力残差 (attention residuals) 被广泛使用。
在实践中,你可能还会想知道目前「最好」的架构是什么。这很难回答,因为没有公开的实验在相同的训练数据上训练不同的架构等。
因此,我们目前只能回答对于给定问题最佳(经过训练的)模型选择是什么。在我看来,混合架构仍然是一个新奇事物,其主要卖点主要是(长上下文)效率,它在一定程度上抛弃了单纯强调建模性能的追求。因此,我认为它们是智能体上下文(如 OpenClaw )的绝佳选择。
就我个人而言,我认为混合架构的问题也在于推理堆栈尚未得到充分优化,我发现当使用更经典的设置(如带有分组查询注意力的 GPT-OSS )在本地运行 LLM 时,我获得了更好的 tok/sec 吞吐量。
无论如何,我很好奇 DeepSeek V4 会带来什么,因为在过去的 2 年里,DeepSeek 一直是非常可靠的趋势引领者。