很多刚接触大模型应用开发的同学,都会先遇到一个非常现实的问题:模型看起来很聪明,但一旦问题超出训练语料,或者涉及企业内部文档、最新业务规则、私有知识库,它就开始一本正经地胡说八道。
这不是模型"故意骗人",而是大语言模型的工作方式决定了它并不会主动承认"我不知道"。如果没有额外上下文,它只能基于参数里已有的统计规律去补全答案。工程上,这个问题通常被归为两个字:幻觉。
如果你要做一个真正可用的 AI 助手,第一步往往不是继续堆 Prompt,而是想办法把"模型不知道但业务需要它知道的知识"补进去。RAG 的价值就出现在这里。
RAG 不是一个神秘的新概念,它本质上是在回答前多做了一步检索:先从外部知识库里找资料,再把资料塞进 Prompt,让模型基于这些资料生成结果。这个思路并不复杂,难点在于另一个问题:
当用户的提问表达方式和文档原文不完全一致时,你怎么找到真正相关的那几段内容?
这篇文章就专门讲清楚这件事。我们从问题背景出发,先解释为什么关键词搜索不够用,再讲向量、Embedding、向量数据库和 RAG 之间的关系,最后用一个可运行的 LangChain demo,把"文档向量化 + 语义检索 + 回答生成"整条链路跑通。
RAG 解决的到底是什么问题
先把几个边界讲清楚。
大模型擅长的是"基于已有知识和上下文生成语言",但它并不天然具备以下能力:
- 访问企业内部私有文档
- 感知训练完成之后发生的新信息
- 稳定遵循你业务系统里的事实约束
这意味着,只要问题依赖外部知识源,单纯调用 LLM 就不够。
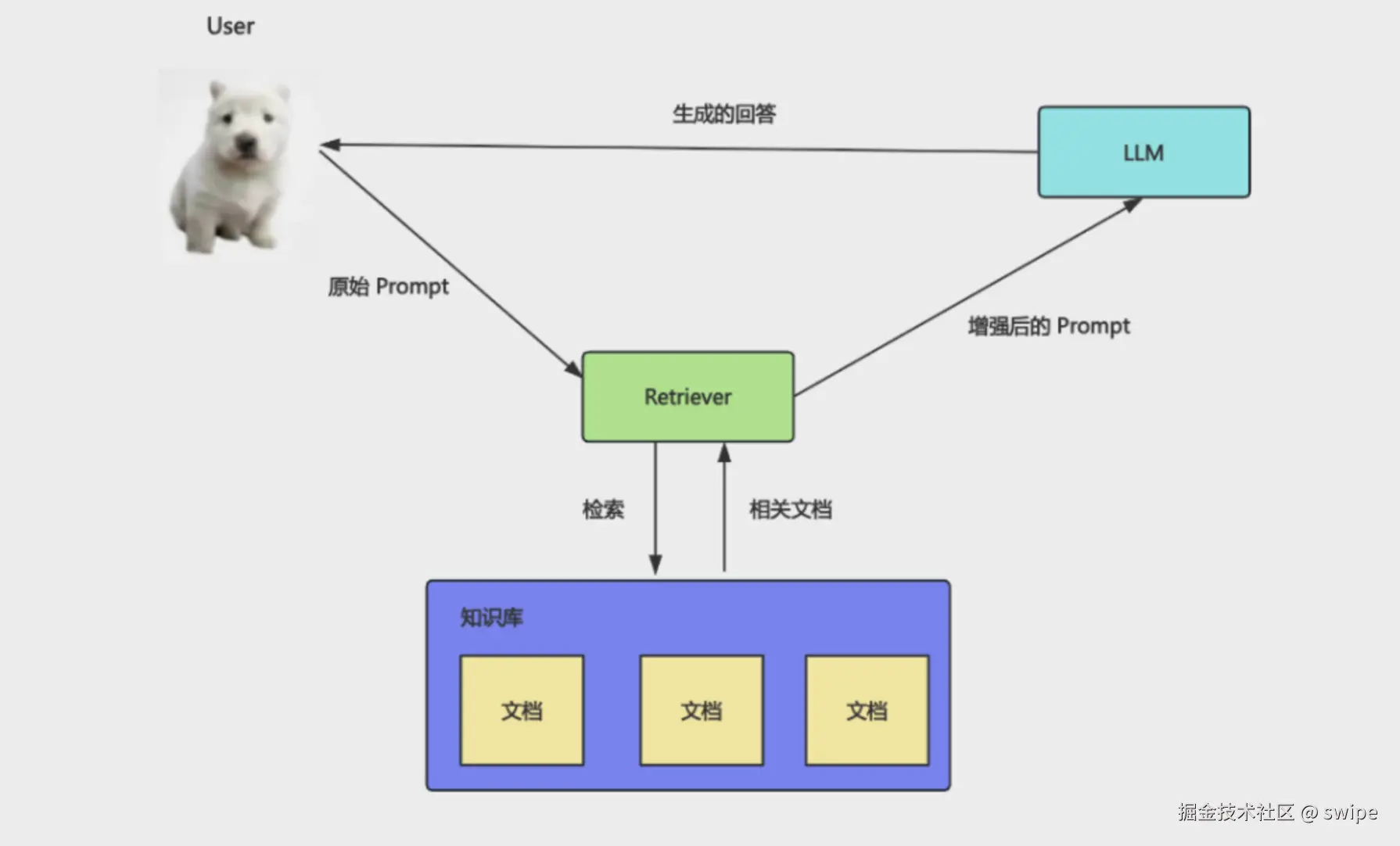
RAG 的核心思想可以概括为三步:
Retrieval:先从知识库里检索和问题最相关的内容。Augmented:把检索结果拼进 Prompt,作为额外上下文。Generation:让大模型基于这些上下文生成回答。
它的价值不是"让模型更聪明",而是"让模型回答时有依据"。对企业问答、文档助手、客服知识库、代码知识库、合同检索这类场景来说,这一点非常关键。
关键词搜索为什么不够
很多人第一次实现 RAG,会直觉地想到全文检索:把文档存起来,用户提问时按关键词查不就行了?
如果你的问题和文档用词高度一致,这么做确实能返回结果。但一旦用户换一种说法,关键词搜索就开始暴露局限。
比如文档里写的是:
员工离职后,账号权限会在 24 小时内回收。
用户提问时却可能写成:
人员离岗之后系统访问什么时候会被关闭?
这两个句子表达的是同一件事,但表面词汇几乎没重合。关键词检索擅长匹配"字面是否出现",却很难判断"语义是否接近"。而 RAG 真正需要的,恰恰是后者。
所以,RAG 的检索层如果只停留在关键词匹配,通常只能算是"能用",很难算"好用" 。真正想把检索质量做上去,基本都会走向语义检索,而语义检索背后的核心数据结构,就是向量。
什么是向量,为什么它能表示语义
"把文本转成向量"这句话初看很抽象,但可以先用一个低维例子建立直觉。
假设我们用两个维度描述一个对象:
- 维度 1:可食用性
- 维度 2:硬度
那几个概念大致可以被表示为:
- 水果:
[0.9, 0.3] - 苹果:
[0.9, 0.5] - 香蕉:
[0.9, 0.1] - 石头:
[0.1, 0.9]
虽然这只是人为构造的二维示意,但它很好地说明了向量表示的本质:一个对象不再靠单个词描述,而是靠一组数值来表达它在多个语义维度上的位置。
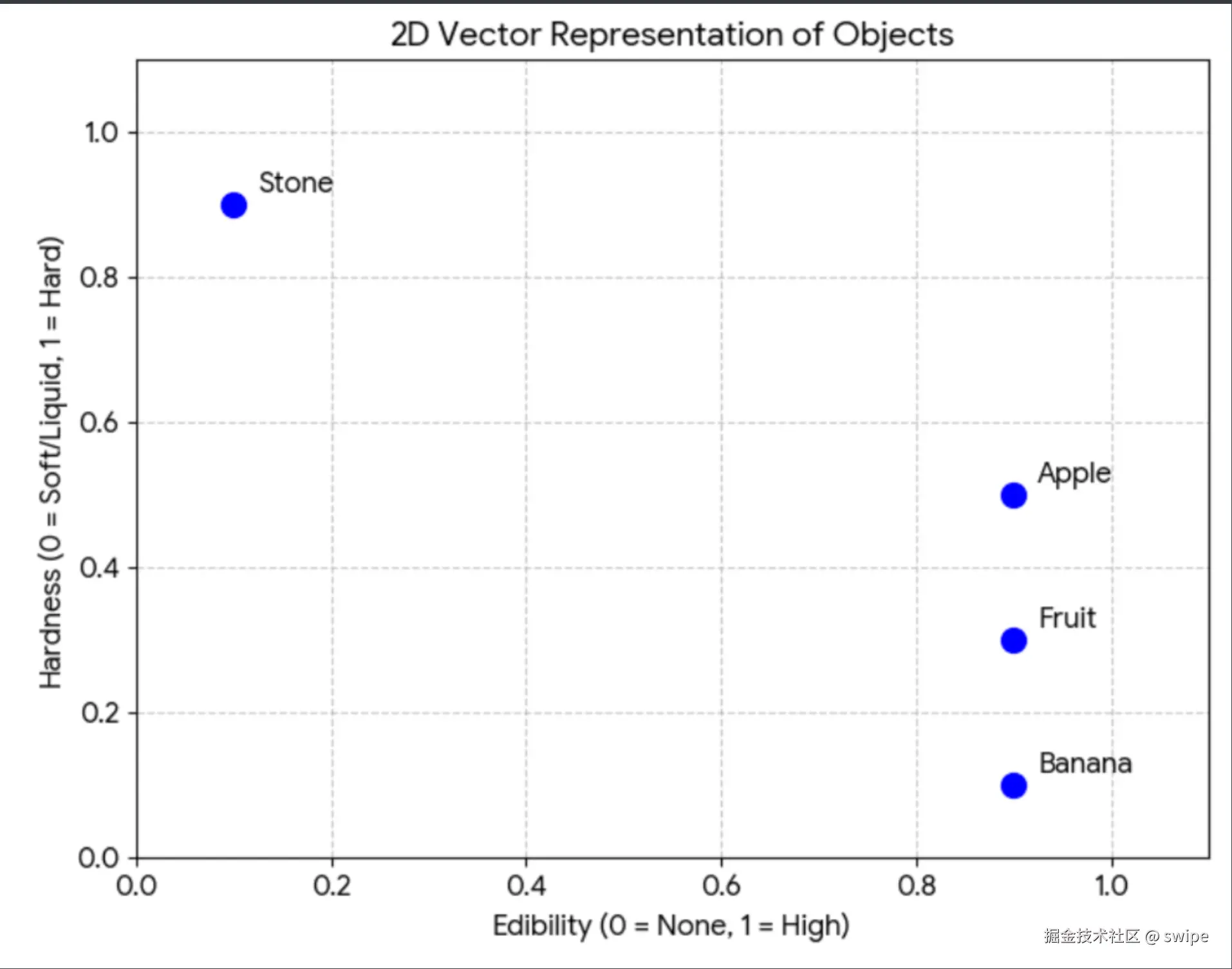
在这个空间里,苹果、香蕉、水果会更靠近,因为它们在"语义属性"上更相似;石头则会离得很远。
工程上,我们不会自己手工定义这些维度,而是交给专门的模型去学习。这个模型就是 Embedding Model,也叫嵌入模型。
Embedding 模型和 LLM 有什么区别
这两个概念很容易被混在一起,但职责其实完全不同。
LLM负责理解上下文并生成回答Embedding Model负责把文本映射成向量
Embedding 模型不负责长篇生成,它的任务是把"语义相近的内容"映射到"向量空间中距离更近的位置"。这样一来,你就可以把文档转成向量存起来,也可以把用户问题转成向量,再去做相似度匹配。
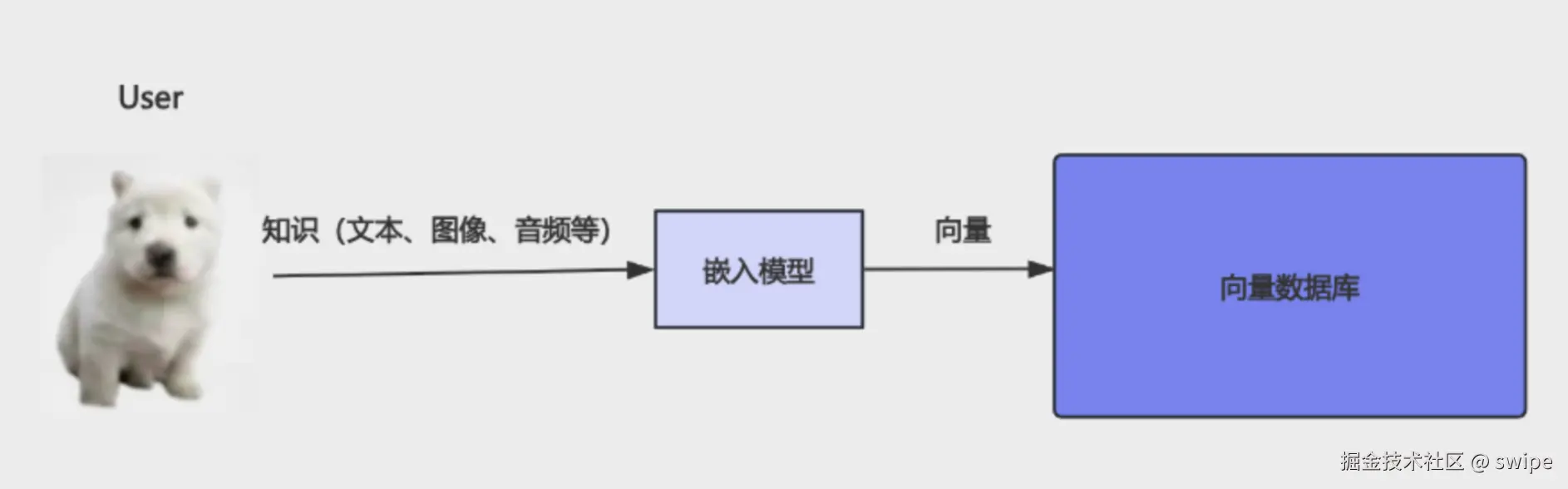
这也是为什么一个完整的 RAG 系统里,通常至少会出现两类模型:
- 生成模型:负责最后的自然语言回答
- 嵌入模型:负责检索阶段的向量化
很多初学者会误以为"有了大模型就不需要 Embedding 了"。这在工程上通常不成立。没有 Embedding,你很难把海量文档组织成一个可搜索的语义空间。
语义搜索是怎么做出来的
当文档和用户问题都被转成向量之后,检索问题就变成了一个数学问题:找出和查询向量最接近的文档向量。
常见做法是使用余弦相似度、内积或欧氏距离来衡量两个向量的接近程度。初学阶段你只需要记住一个结论:
向量越接近,通常意味着语义越相近。
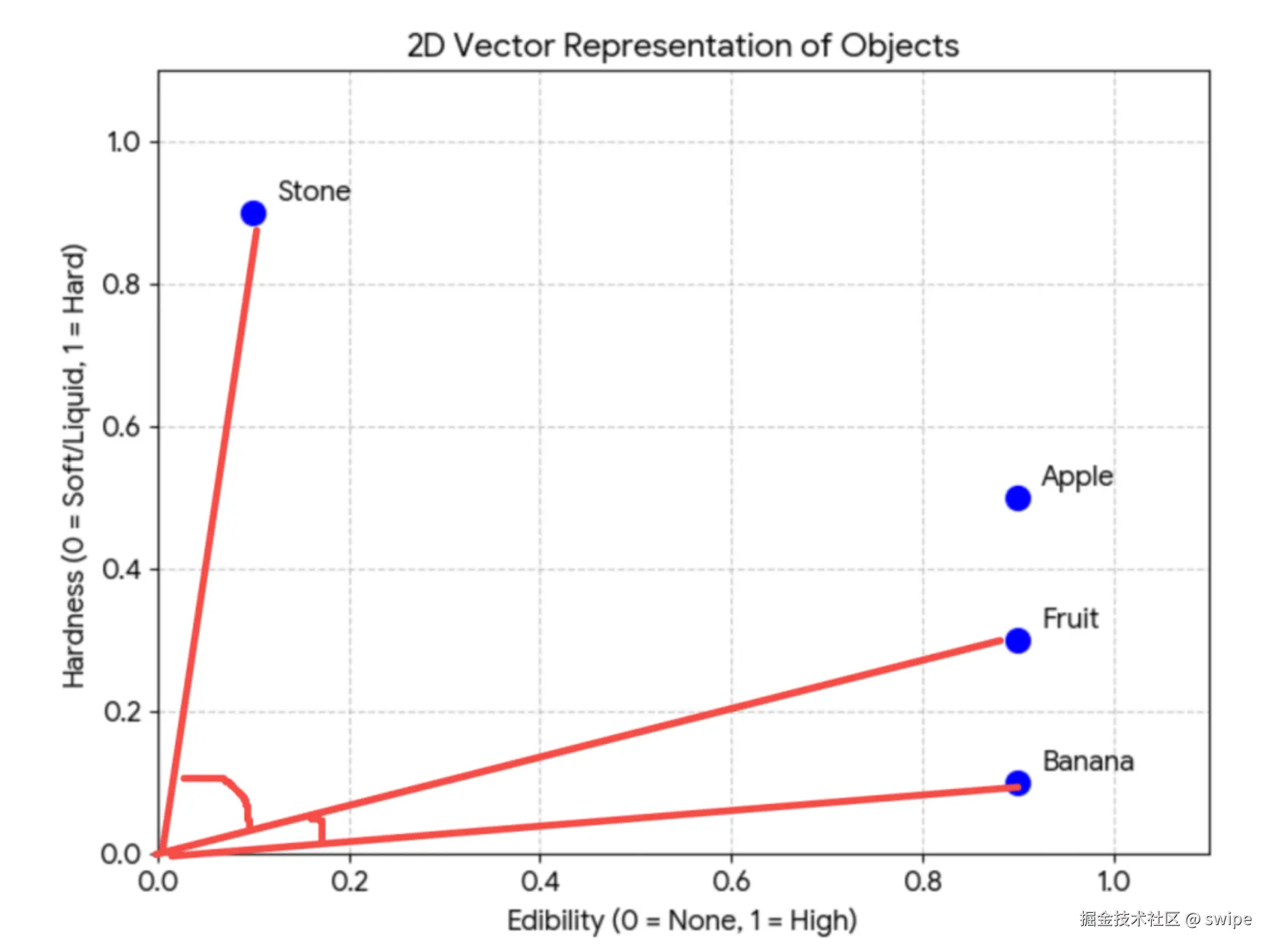
于是,一条完整的检索链路就出现了:
- 先把文档切分成若干片段。
- 用 Embedding 模型把每个片段转成向量。
- 把向量和对应的原文、元数据一起存进向量数据库。
- 用户提问时,再把问题转成向量。
- 在向量库里查找最相近的若干片段。
- 把这些片段作为上下文交给 LLM 生成回答。
这才是现代 RAG 的典型结构。
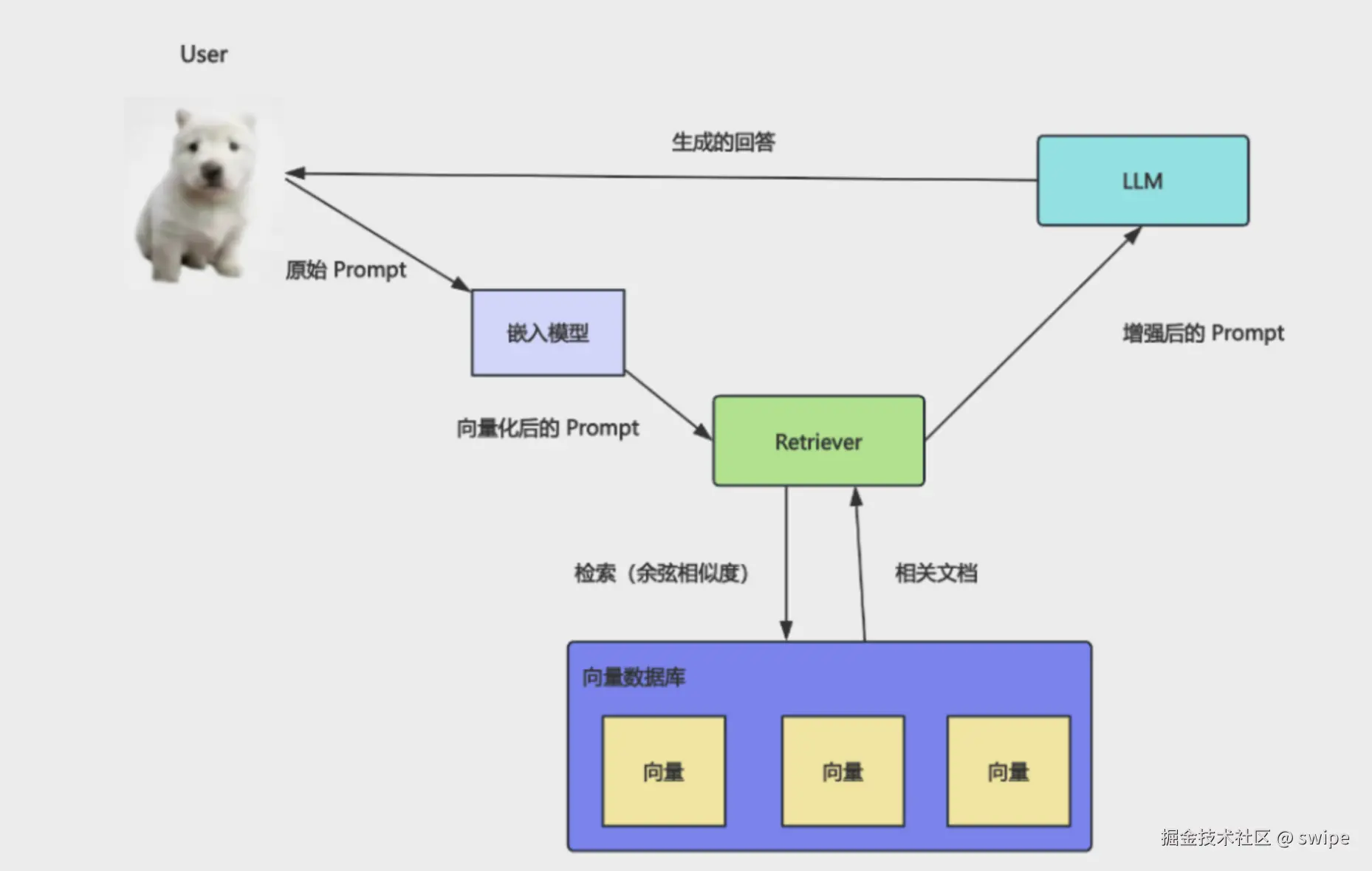
这里有一个经常被忽略但很重要的点:向量数据库存的不只是向量,还会存向量对应的原文和元信息。 否则你只能算出"第 183 个向量最相近",却不知道它对应哪段文档。
一个更符合真实业务的 demo
我们假设知识库里有三类文档:
- 报销制度
- VPN 访问规范
- 年假与请假规则
用户的问题则可能是:
新员工在家办公时,怎么申请远程访问公司的内部系统?
这个问题未必直接出现过"VPN"这个关键词,但语义上显然和远程访问规范强相关。正好适合用来演示向量检索的价值。
环境准备
先初始化一个简单项目:
bash
mkdir rag-test
cd rag-test
npm init -y
pnpm add @langchain/core @langchain/openai @langchain/classic dotenv这个 demo 里我们用到的依赖分别负责不同角色:
@langchain/openai:封装聊天模型和嵌入模型@langchain/core:提供Document等基础抽象@langchain/classic:提供内存版向量存储,适合教学和本地实验dotenv:从.env读取配置
这里特意强调一下:MemoryVectorStore 只是一个方便演示的内存向量库,适合理解流程,不适合直接拿去做生产级知识库。真实场景里,你通常会换成 Pinecone、Milvus、Qdrant、Weaviate、pgvector 之类的持久化方案。
配置模型
在项目根目录创建 .env:
ini
OPENAI_API_KEY=sk-xxx
OPENAI_BASE_URL=https://dashscope.aliyuncs.com/compatible-mode/v1
MODEL_NAME=qwen-plus
EMBEDDINGS_MODEL_NAME=text-embedding-v3这组配置说明了一个很重要的工程事实:RAG 并不绑定某一家模型厂商。 只要对方提供兼容接口,你完全可以替换成别的聊天模型和嵌入模型。
核心代码:把知识库变成可检索的向量空间
创建 src/hello-rag.mjs:
ini
import "dotenv/config";
import { ChatOpenAI, OpenAIEmbeddings } from "@langchain/openai";
import { Document } from "@langchain/core/documents";
import { MemoryVectorStore } from "@langchain/classic/vectorstores/memory";
const model = new ChatOpenAI({
model: process.env.MODEL_NAME,
temperature: 0,
apiKey: process.env.OPENAI_API_KEY,
configuration: {
baseURL: process.env.OPENAI_BASE_URL,
},
});
const embeddings = new OpenAIEmbeddings({
model: process.env.EMBEDDINGS_MODEL_NAME,
apiKey: process.env.OPENAI_API_KEY,
configuration: {
baseURL: process.env.OPENAI_BASE_URL,
},
});
const documents = [
new Document({
pageContent:
"公司员工如需在家办公访问内部系统,需要先申请 VPN 权限。审批通过后,IT 会分配专属账号,并要求开启双因素认证。",
metadata: {
category: "远程办公",
source: "IT 访问规范",
},
}),
new Document({
pageContent:
"报销单需要在费用发生后的 15 个自然日内提交。超过时限的报销申请,需要部门负责人补充说明原因。",
metadata: {
category: "财务制度",
source: "员工报销手册",
},
}),
new Document({
pageContent:
"入职满一年后,员工每年可享受 10 天年假。请假需要至少提前 3 个工作日提交,并经过直属主管审批。",
metadata: {
category: "人事制度",
source: "员工假期管理办法",
},
}),
new Document({
pageContent:
"首次使用 VPN 时,员工需要在公司安全门户下载客户端,并绑定动态验证码设备。未开启双因素认证的账号无法访问内网。",
metadata: {
category: "远程办公",
source: "VPN 使用说明",
},
}),
];
const vectorStore = await MemoryVectorStore.fromDocuments(documents, embeddings);
const retriever = vectorStore.asRetriever({ k: 2 });
const question = "新员工居家办公时,怎么申请访问公司内部系统?";
const retrievedDocs = await retriever.invoke(question);
const scoredDocs = await vectorStore.similaritySearchWithScore(question, 2);
console.log("问题:", question);
console.log("\n检索结果:");
retrievedDocs.forEach((doc, index) => {
const matched = scoredDocs.find(
([candidate]) => candidate.pageContent === doc.pageContent,
);
const score = matched?.[1];
console.log(`\n[片段 ${index + 1}]`);
console.log("来源:", doc.metadata.source);
console.log("分类:", doc.metadata.category);
console.log("分数:", score);
console.log("内容:", doc.pageContent);
});
const context = retrievedDocs
.map((doc, index) => `[资料 ${index + 1}]\n${doc.pageContent}`)
.join("\n\n");
const prompt = `
你是一名企业内部知识库助手。请严格基于给定资料回答问题:
1. 优先使用资料中的事实作答
2. 如果资料没有明确提到,就直接说明"当前资料不足以回答这个细节"
3. 回答尽量简洁、准确、可执行
资料:
${context}
问题:
${question}
`;
const response = await model.invoke(prompt);
console.log("\nAI 回答:");
console.log(response.content);这段代码虽然不长,但已经把一个最小可用的 RAG 流程串起来了。下面按职责拆开讲。
第一步:准备两类模型
代码里同时初始化了 ChatOpenAI 和 OpenAIEmbeddings。这不是重复,而是两个阶段的明确分工。
ChatOpenAI用于最终回答生成OpenAIEmbeddings用于把文档和问题转成向量
如果你把这两个角色混在一起理解,后面写 RAG 时就容易搞不清"到底是谁在检索、谁在生成"。
第二步:构造文档和元数据
Document 里最核心的字段有两个:
pageContent:真正参与向量化和后续拼接上下文的文本内容metadata:附加信息,比如来源、分类、时间、章节、作者
为什么元数据重要?因为 RAG 在工程上不仅要"能答",还要"可追溯"。当模型引用一段知识时,你最好能告诉用户这段内容来自哪份文档、哪个知识分类,甚至哪个时间版本。
换句话说,元数据不只是锦上添花,而是后续做来源展示、权限控制、结果过滤的重要基础。
第三步:把文档向量化并存入向量库
这一行是整个 demo 的核心:
ini
const vectorStore = await MemoryVectorStore.fromDocuments(documents, embeddings);它做了两件事:
- 调用嵌入模型,把每个文档转成向量。
- 把向量、原文和元数据一起放进向量存储。
很多教程把这一步说成"把文档存进数据库",但更准确的说法应该是:把文档映射成可参与相似度检索的向量表示,并建立从向量到原始文档的关联。
这一步完成之后,知识库才真正从"文本集合"变成"可做语义搜索的数据结构"。
第四步:把向量库包装成 Retriever
ini
const retriever = vectorStore.asRetriever({ k: 2 });Retriever 可以理解成检索接口。这里的 k: 2 表示每次查询返回最相关的两个文档片段。
为什么不是越多越好?因为召回太少,模型可能拿不到足够信息;召回太多,又会把无关文本一起塞进 Prompt,导致噪声变大、成本上升、回答质量下降。
RAG 的一个常见优化方向,恰恰就是在"召回数量、相关性、上下文长度、模型成本"之间做平衡。
第五步:先检索,再生成
这一步是 RAG 和"直接问模型"最本质的区别。
ini
const retrievedDocs = await retriever.invoke(question);这里不是让模型直接回答,而是先根据问题去找相关资料。拿到资料后,我们再显式构造 Prompt,把检索结果喂给模型。
javascript
const context = retrievedDocs
.map((doc, index) => `[资料 ${index + 1}]\n${doc.pageContent}`)
.join("\n\n");这一段看似只是字符串拼接,实际上体现了一个非常重要的工程原则:RAG 的增强不是抽象概念,而是把检索到的文本以结构化方式注入 Prompt。
如果没有这一步,模型依然只能依赖自身参数作答;有了这一步,它才真正拥有"外部知识上下文"。
第六步:让模型在"有依据"的前提下回答
Prompt 里我故意加了三条限制:
- 优先使用资料中的事实
- 如果资料不足,就明确说不知道
- 回答要简洁、准确、可执行
这不是装饰,而是在控制生成阶段的行为边界。很多人做 RAG 只关注检索命中率,却忽略了生成约束,结果就是检索明明找对了,模型还是会自由发挥。
一个好用的 RAG 系统,本质上是"检索质量"和"回答约束"共同作用的结果。
运行后你会看到什么
如果向量检索工作正常,返回结果应该会优先命中与"远程办公""VPN""内部系统访问"相关的两段文档,而不是报销制度或年假规则。
最终回答通常会类似这样:
员工在家办公访问内部系统时,需要先申请 VPN 权限。审批通过后,IT 会分配专属账号。首次使用时,还需要下载 VPN 客户端并绑定动态验证码设备,同时开启双因素认证,否则无法访问内网。这时候你就能直观看到 RAG 的价值了。
如果不做检索,模型大概率会给出一段"听起来合理但未必符合公司真实制度"的泛化回答;而做了检索之后,它回答的依据来自你提供的知识库。
这个 demo 还不是真正的生产级 RAG
到这里流程已经跑通了,但如果你要做真实系统,还需要继续往下补。
最常见的几个增强方向包括:
- 文档切分:长文档不能整篇直接做 Embedding,通常要按段落或 token 长度切块
- 向量库替换:内存库适合教学,不适合多用户和持久化场景
- 检索优化:加入元数据过滤、混合检索、重排序模型
- Prompt 优化:控制引用格式、回答风格、拒答策略
- 评估体系:用命中率、答案准确率、上下文利用率等指标验证效果
很多团队以为"把文档扔进向量库"就等于做完 RAG,这通常只是起点。真正影响效果的,往往是切块策略、召回质量和生成约束。
初学者最容易混淆的几个点
1. RAG 不等于向量数据库
向量数据库只是 RAG 检索层的一种常见基础设施。RAG 是一条完整链路,至少包含检索、上下文增强和生成三个环节。
2. Embedding 不负责回答问题
Embedding 模型负责把内容映射到向量空间,方便做语义检索;真正负责输出自然语言答案的,仍然是 LLM。
3. 检索结果相关,不代表答案一定正确
如果 Prompt 约束不严,或者模型理解上下文时发生偏差,最终答案依然可能不稳定。所以 RAG 不是"消灭幻觉",而是"显著降低无依据回答的概率"。
4. 关键词搜索不会完全消失
很多真实系统会把关键词检索和向量检索结合起来做混合检索。原因很简单:精确术语、产品型号、错误码、法规编号,往往还是关键词更稳。
从工程视角重新理解这件事
如果只看概念,RAG 很像是在 Prompt 前面多拼了一段文本;但从工程实现的角度看,它其实是在给大模型外挂一套"可更新、可追溯、可控的外部知识系统"。
这件事的意义非常大,因为它让大模型应用第一次真正具备了和业务知识库对接的能力。
你可以把它理解成一种分工:
- LLM 负责语言理解与生成
- Embedding 负责语义表示
- 向量库负责近邻检索
- Retriever 负责召回相关片段
- Prompt 负责把外部知识注入生成链路
把这几个角色分开理解之后,RAG 的整体结构就会清晰很多。
总结
RAG 要解决的问题,从来不是"怎么让模型回答更多",而是"怎么让模型基于真实资料回答"。
而一旦你想让检索从"字面匹配"升级到"语义匹配",向量化几乎就是绕不过去的一步。Embedding 模型负责把文本放进向量空间,向量数据库负责在这个空间里做相似度搜索,Retriever 负责把最相关的片段找回来,最后再由 LLM 基于这些片段生成答案。
所以,文档向量化不是 RAG 的附属技巧,而是高质量语义检索的核心基础设施。
如果你接下来要做企业内部文档助手、客服知识库问答、研发文档检索、合规制度问答,RAG 往往就是第一条值得认真打磨的技术路线。理解了"为什么要向量化"和"检索结果是怎么参与生成的",后面的 chunking、rerank、hybrid search、agentic retrieval 才有继续深入的基础。