引言
分布式系统的核心痛点,是如何让多个独立的节点对系统状态达成一致共识:谁是集群的Master节点、全集群配置是否同步、分布式锁该由谁持有、服务实例上下线如何实时感知。这些问题如果由业务自行实现,不仅会重复造轮子,更极易出现一致性漏洞。分布式协调中间件就是解决这类问题的基础设施,目前业界最主流的实现就是ZooKeeper与Nacos。
一、分布式协调中间件的核心能力
无论是ZooKeeper还是Nacos,其本质都是为分布式系统提供可靠的协同能力,核心价值集中在5个维度:
-
强一致的元数据存储:为分布式系统提供全集群可见、一致性有保障的元数据、配置信息、集群状态存储。
-
故障感知与生命周期管理:实时感知节点上下线、客户端会话存活状态,自动处理节点故障带来的状态变更。
-
分布式协同原语:封装好分布式锁、Master选举、分布式栅栏、队列等常用协同工具,避免业务重复实现。
-
实时事件通知:当关注的数据或状态发生变化时,能实时推送给订阅的客户端,实现动态感知。
-
高可用集群能力:自身支持集群部署,少数节点故障不影响整体服务的可用性。
二、ZooKeeper 深度拆解:经典分布式协调内核
ZooKeeper是Apache旗下的顶级开源项目,诞生于Hadoop生态,专为分布式协调场景设计,是业界公认的经典协调中间件,被Kafka、Flink、Dubbo等大量主流中间件深度集成。
2.1 ZooKeeper核心架构
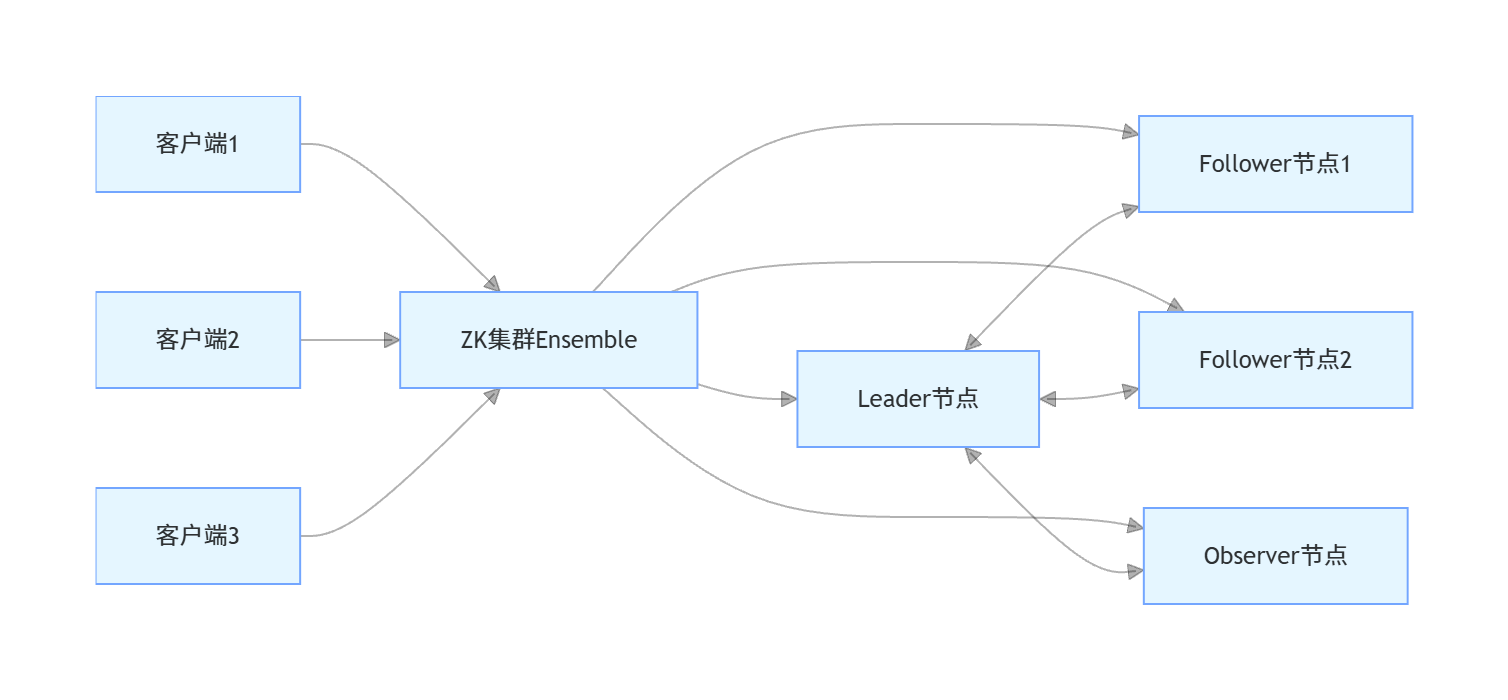
ZooKeeper集群被称为Ensemble,采用主从架构,包含三类核心角色,职责划分清晰:
-
Leader节点:集群唯一的写入口,处理所有客户端的写请求,负责协调分布式事务的一致性,发起投票与提案。
-
Follower节点:处理客户端读请求,参与Leader选举投票与写请求的过半ACK确认,同步Leader的事务数据。
-
Observer节点:与Follower一致处理读请求,但不参与任何投票流程,仅同步数据,用于提升集群读吞吐量的同时,不影响写操作的性能。
2.2 ZooKeeper核心数据模型:ZNode
ZooKeeper的存储结构采用树形层级结构,与Linux文件系统完全一致,树中的每个节点被称为ZNode ,每个ZNode通过唯一的绝对路径标识(如/lock/order)。ZNode不仅能存储数据,还附带完整的状态信息(Stat结构体)。
2.2.1 ZNode的4种类型
ZNode的类型决定了其生命周期与特性,是实现所有分布式协同能力的基础,必须严格区分:
-
持久节点(PERSISTENT):创建后永久存在,除非主动手动删除,与客户端会话无关。
-
持久顺序节点(PERSISTENT_SEQUENTIAL):在持久节点的基础上,ZooKeeper会自动为节点名追加一个全局自增的数字后缀,保证节点名的顺序唯一性。
-
临时节点(EPHEMERAL):生命周期与创建它的客户端会话完全绑定,会话失效(超时、主动断开)后,节点会被自动删除;临时节点不允许创建子节点。
-
临时顺序节点(EPHEMERAL_SEQUENTIAL):在临时节点的基础上,追加全局自增的数字后缀,是实现分布式锁、Master选举的核心载体。
2.2.2 ZNode核心状态字段(Stat)
每个ZNode都附带Stat结构体,存储节点的核心元数据,关键字段如下:
-
czxid:节点创建时对应的全局事务ID -
mzxid:节点最后一次修改对应的全局事务ID -
pzxid:节点的子节点最后一次变更对应的事务ID -
ephemeralOwner:临时节点对应的客户端会话ID,持久节点该值为0 -
dataLength:节点存储的数据长度 -
numChildren:节点的直接子节点数量
2.3 ZooKeeper灵魂:ZAB一致性协议
ZooKeeper的一致性保障,完全依赖其专属的ZAB(ZooKeeper Atomic Broadcast)原子广播协议,该协议专为分布式协调场景设计,保证了集群的全局顺序一致性与崩溃恢复能力。
ZAB协议的核心设计原则:
-
全局顺序性:所有写请求都会被分配一个全局唯一、单调递增的事务ID(zxid),集群所有节点严格按照zxid的顺序处理事务,保证全局有序。
-
过半写入原则:一个写请求只有被集群过半的节点成功持久化后,才会被正式提交,保证少数节点故障时数据不丢失。
-
崩溃恢复能力:当Leader节点故障时,集群能自动选举出新的Leader,且保证新Leader拥有集群最新的已提交事务,同时同步所有节点的数据到一致状态。
2.3.1 消息广播模式(集群正常运行)
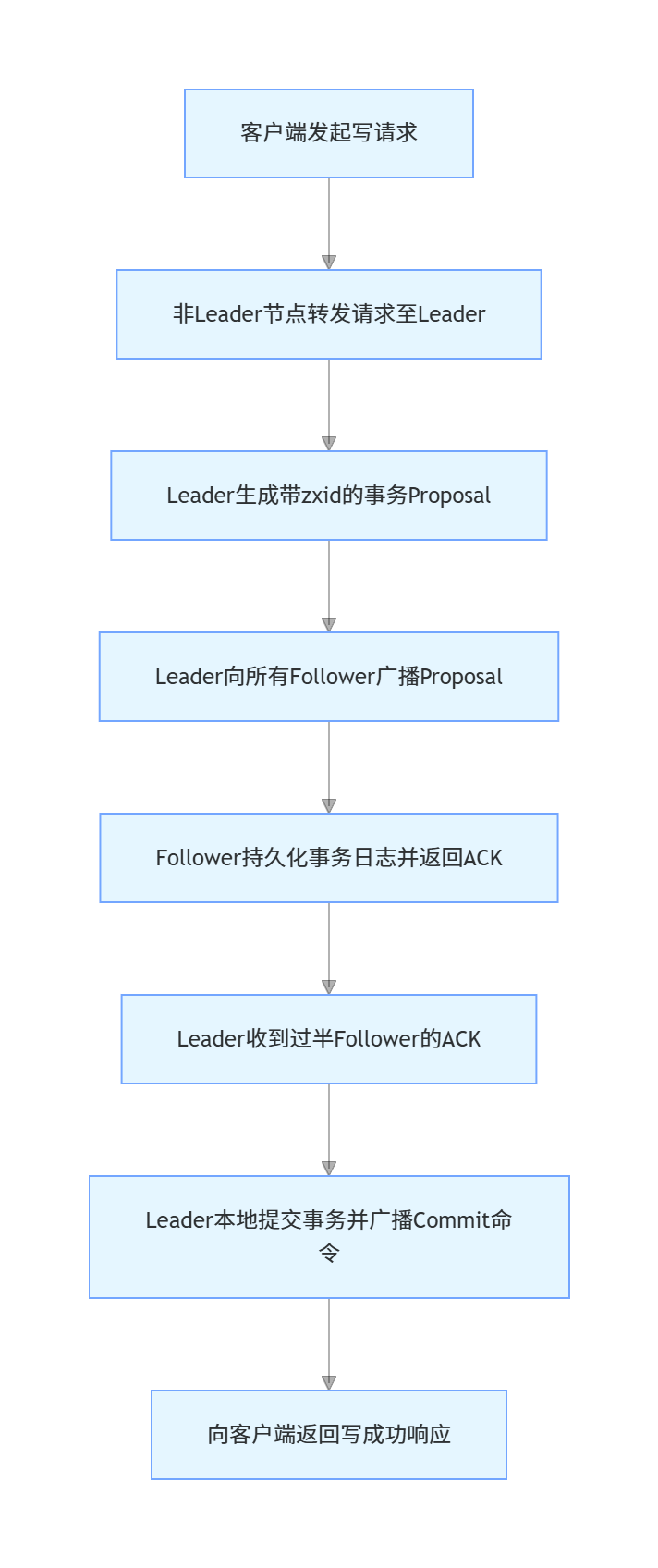
当集群正常运行时,ZAB处于消息广播模式,处理所有客户端的写请求,流程如下:
-
客户端的写请求无论发送到哪个节点,若接收节点不是Leader,都会被转发给唯一的Leader节点处理。
-
Leader收到请求后,生成带全局唯一zxid的事务提案(Proposal)。
-
Leader将提案广播给所有Follower节点,Follower收到后先将事务持久化到本地磁盘,再向Leader返回ACK确认。
-
当Leader收到过半Follower的ACK后,认为该提案可提交,先本地提交事务,再向所有Follower广播Commit命令。
-
Follower收到Commit命令后提交本地事务,完成整个写流程。
Observer节点不参与ACK投票,仅同步事务数据、处理读请求,因此新增Observer节点不会降低集群的写性能。
2.3.2 崩溃恢复模式(Leader故障)
当Leader节点故障、或过半Follower与Leader断开连接时,集群会自动进入崩溃恢复模式,分为两个核心阶段:
-
Leader选举阶段
-
选举核心规则:优先对比节点的zxid,zxid最大的节点拥有最新的已提交事务,优先成为Leader;zxid相同时,对比节点配置的myid,myid越大优先级越高。
-
选举流程:故障发生后,剩余节点进入选举状态,每个节点先给自己投票,再将投票信息(自身zxid、myid)广播给其他节点;每个节点收到投票后,按规则对比优先级,若对方优先级更高则改投对方,并广播新投票;当某个节点收到过半投票后,成为新的Leader。
-
-
数据同步阶段
-
新Leader确认自身所有已提交的事务,与所有Follower对比数据,将Follower缺失的事务同步过去,同时回滚Follower中未提交的脏事务,保证所有节点数据与Leader完全一致。
-
当过半节点同步完成后,集群退出崩溃恢复模式,重新进入消息广播模式,恢复正常服务。
-
2.3.3 ZAB与Raft协议的核心区别(易混淆点澄清)
很多开发者会混淆ZAB与Raft协议,二者核心差异如下:
| 对比维度 | ZAB协议 | Raft协议 |
|---|---|---|
| 设计目标 | 专为ZooKeeper设计,优先保障分布式协调的全局顺序一致性 | 通用分布式一致性算法,适用范围更广 |
| 事务顺序保障 | 严格保证全局唯一的递增zxid,所有事务严格按顺序执行 | 按任期(Term)+日志索引保证顺序,同一任期内日志有序 |
| 提交规则 | 只有当前Leader的提案,才能通过过半ACK提交 | 只要日志被过半节点写入,即可提交,包括前任Leader的日志 |
| 应用场景 | 仅ZooKeeper使用 | 广泛应用于Etcd、Nacos、RocketMQ等多个中间件 |
2.4 ZooKeeper核心机制
2.4.1 Watcher事件通知机制
Watcher是ZooKeeper实现动态感知的核心,客户端可以在指定ZNode上注册Watcher监听器,当ZNode发生指定的事件时,服务端会向客户端发送事件通知,触发客户端的回调逻辑。
Watcher核心特性(高频踩坑点):
-
一次性触发:一个Watcher注册后,只会被触发一次,触发后立即失效,若需要持续监听,必须重新注册。
-
轻量级通知:Watcher通知仅告知客户端"发生了什么事件",不会携带变更后的具体数据,客户端需要主动重新获取最新数据。
-
会话绑定:Watcher与客户端会话绑定,会话失效后,注册的所有Watcher都会自动失效。
-
有序性:ZooKeeper严格保证事件通知的顺序与事件实际发生的顺序一致。
核心事件类型:
-
NodeCreated:监听的节点被创建 -
NodeDeleted:监听的节点被删除 -
NodeDataChanged:监听的节点的数据内容被修改 -
NodeChildrenChanged:监听的节点的直接子节点发生新增/删除
❝
注意:
NodeChildrenChanged仅监听直接子节点的变更,子节点的子节点变化不会触发该事件,这是高频踩坑点。
2.4.2 Session会话机制
ZooKeeper客户端与服务端之间通过Session建立连接,每个Session拥有唯一的sessionId与会话超时时间,是临时节点生命周期的核心依赖。
Session生命周期:
-
客户端与服务端建立连接时创建Session,服务端分配唯一的sessionId与协商好的超时时间。
-
客户端与服务端通过心跳(ping)维持会话,客户端在超时时间内发送心跳,服务端就会刷新会话的超时时间。
-
若客户端在超时时间内未发送心跳,服务端会判定会话失效,自动删除该会话创建的所有临时节点,同时触发对应的Watcher事件。
❝
关键澄清:临时节点的生命周期绑定的是Session,不是TCP连接。TCP连接断开但会话仍在超时时间内时,客户端重连同一个Session后,临时节点不会被删除;只有会话彻底失效,临时节点才会被自动清理。
2.5 ZooKeeper核心场景与实战代码
2.5.1 分布式锁
分布式锁是ZooKeeper最常用的场景,基于临时顺序节点+Watcher机制实现,完美避免羊群效应,保证锁的公平性与安全性。
实现原理:
-
为锁创建持久根节点,如
/distributed_lock/order,代表订单业务的锁。 -
加锁逻辑:客户端请求加锁时,在根节点下创建临时顺序节点;获取根节点下所有子节点并排序,判断自己创建的节点是否为序号最小的节点,若是则加锁成功;若不是,则监听自己前一个序号节点的
NodeDeleted事件,进入等待状态。 -
释放锁逻辑:客户端释放锁时,主动删除自己创建的临时顺序节点;节点删除后,会触发下一个节点的Watcher,该节点收到通知后重新判断自己是否为最小节点,若是则加锁成功。
-
异常容错:客户端宕机导致会话失效时,临时节点会被自动删除,锁自动释放,不会出现死锁。
Maven依赖
<dependency>
<groupId>org.apache.curator</groupId>
<artifactId>curator-recipes</artifactId>
<version>5.6.0</version>
</dependency>
<dependency>
<groupId>org.apache.zookeeper</groupId>
<artifactId>zookeeper</artifactId>
<version>3.8.4</version>
</dependency>
<dependency>
<groupId>org.projectlombok</groupId>
<artifactId>lombok</artifactId>
<version>1.18.30</version>
<scope>provided</scope>
</dependency>代码实现
package com.jam.demo.zk;
import lombok.extern.slf4j.Slf4j;
import org.apache.curator.framework.CuratorFramework;
import org.apache.curator.framework.CuratorFrameworkFactory;
import org.apache.curator.retry.ExponentialBackoffRetry;
import org.apache.curator.framework.recipes.locks.InterProcessMutex;
import org.springframework.util.ObjectUtils;
import org.springframework.util.StringUtils;
import java.util.concurrent.TimeUnit;
/**
* ZooKeeper分布式锁实战示例
*
* @author ken
*/
@Slf4j
public class ZkDistributedLockDemo {
private static final String ZK_CONNECT_STRING = "127.0.0.1:2181";
private static final String LOCK_ROOT_PATH = "/distributed_lock/order";
private static final int SESSION_TIMEOUT_MS = 30000;
private static final int CONNECTION_TIMEOUT_MS = 10000;
private static final CuratorFramework CURATOR_CLIENT;
static {
CURATOR_CLIENT = CuratorFrameworkFactory.builder()
.connectString(ZK_CONNECT_STRING)
.sessionTimeoutMs(SESSION_TIMEOUT_MS)
.connectionTimeoutMs(CONNECTION_TIMEOUT_MS)
.retryPolicy(new ExponentialBackoffRetry(1000, 3))
.build();
CURATOR_CLIENT.start();
log.info("Curator客户端初始化完成");
}
/**
* 执行带分布式锁的业务逻辑
*
* @param orderId 订单ID,用于细粒度锁隔离
* @param businessLogic 加锁后执行的业务逻辑
* @throws Exception 锁获取失败或业务执行异常
*/
public void executeWithLock(String orderId, Runnable businessLogic) throws Exception {
if (!StringUtils.hasText(orderId)) {
throw new IllegalArgumentException("订单ID不能为空");
}
if (ObjectUtils.isEmpty(businessLogic)) {
throw new IllegalArgumentException("业务逻辑不能为空");
}
String lockPath = LOCK_ROOT_PATH + "/" + orderId;
InterProcessMutex mutex = new InterProcessMutex(CURATOR_CLIENT, lockPath);
try {
boolean lockAcquired = mutex.acquire(5, TimeUnit.SECONDS);
if (!lockAcquired) {
log.error("订单[{}]获取分布式锁超时", orderId);
throw new RuntimeException("获取分布式锁超时,请稍后重试");
}
log.info("订单[{}]成功获取分布式锁", orderId);
businessLogic.run();
} finally {
if (mutex.isAcquiredInThisProcess()) {
mutex.release();
log.info("订单[{}]释放分布式锁完成", orderId);
}
}
}
public static void main(String[] args) {
ZkDistributedLockDemo lockDemo = new ZkDistributedLockDemo();
String orderId = "ORDER_123456";
Thread thread1 = new Thread(() -> {
try {
lockDemo.executeWithLock(orderId, () -> {
log.info("线程1执行业务逻辑-开始");
try {
TimeUnit.SECONDS.sleep(2);
} catch (InterruptedException e) {
Thread.currentThread().interrupt();
log.error("业务执行被中断", e);
}
log.info("线程1执行业务逻辑-结束");
});
} catch (Exception e) {
log.error("线程1执行异常", e);
}
});
Thread thread2 = new Thread(() -> {
try {
lockDemo.executeWithLock(orderId, () -> {
log.info("线程2执行业务逻辑-开始");
log.info("线程2执行业务逻辑-结束");
});
} catch (Exception e) {
log.error("线程2执行异常", e);
}
});
thread1.start();
thread2.start();
try {
thread1.join();
thread2.join();
} catch (InterruptedException e) {
Thread.currentThread().interrupt();
log.error("主线程等待被中断", e);
} finally {
CURATOR_CLIENT.close();
}
}
}2.5.2 其他核心场景
-
Master选举 :原理与分布式锁一致,基于临时顺序节点,序号最小的节点成为Master,Master宕机后自动触发切换,Curator已封装
LeaderSelector生产级实现。 -
集群服务发现 :服务提供者启动时,在
/services/服务名下创建临时节点,存储自身IP、端口等元数据;服务消费者获取该节点下的所有子节点,同时注册NodeChildrenChangedWatcher,实现服务上下线的动态感知,这是Dubbo早期服务发现的核心实现原理。 -
动态配置中心:将配置存储在持久节点中,应用启动时读取配置并注册Watcher,配置修改时触发Watcher通知,应用重新读取最新配置,实现动态更新。
2.6 ZooKeeper高频踩坑避坑指南
-
Watcher一次性触发陷阱:不要以为注册一次Watcher就能持续监听,触发后必须重新注册,否则会丢失后续的变更事件。
-
临时节点会话绑定误解:不要将TCP连接与会话混为一谈,会话超时时间设置过短会导致网络波动时临时节点被误删,过长会导致故障节点无法及时被剔除,推荐设置为30s。
-
羊群效应:实现分布式锁时,不要让所有客户端都监听根节点,否则锁释放时会唤醒所有等待的客户端,导致性能急剧下降,必须采用"监听前一个节点"的实现方式。
-
数据量超限:ZooKeeper不适合存储大量数据,单个ZNode的数据大小建议不超过1KB,集群总数据量不超过1GB,否则会严重影响性能。
-
集群节点数不合理:集群节点数必须为奇数,推荐3、5、7个节点,节点数越多写性能越差,不要超过7个节点。
三、Nacos 深度拆解:云原生时代的一站式协调方案
Nacos是阿里开源的云原生中间件,整合了动态配置管理、服务发现、服务治理三大核心能力,不仅具备分布式协调的核心能力,还提供了企业级的配置中心与服务注册中心功能,是Spring Cloud Alibaba生态的核心组件,目前已成为国内云原生架构的主流选择。
3.1 Nacos核心架构
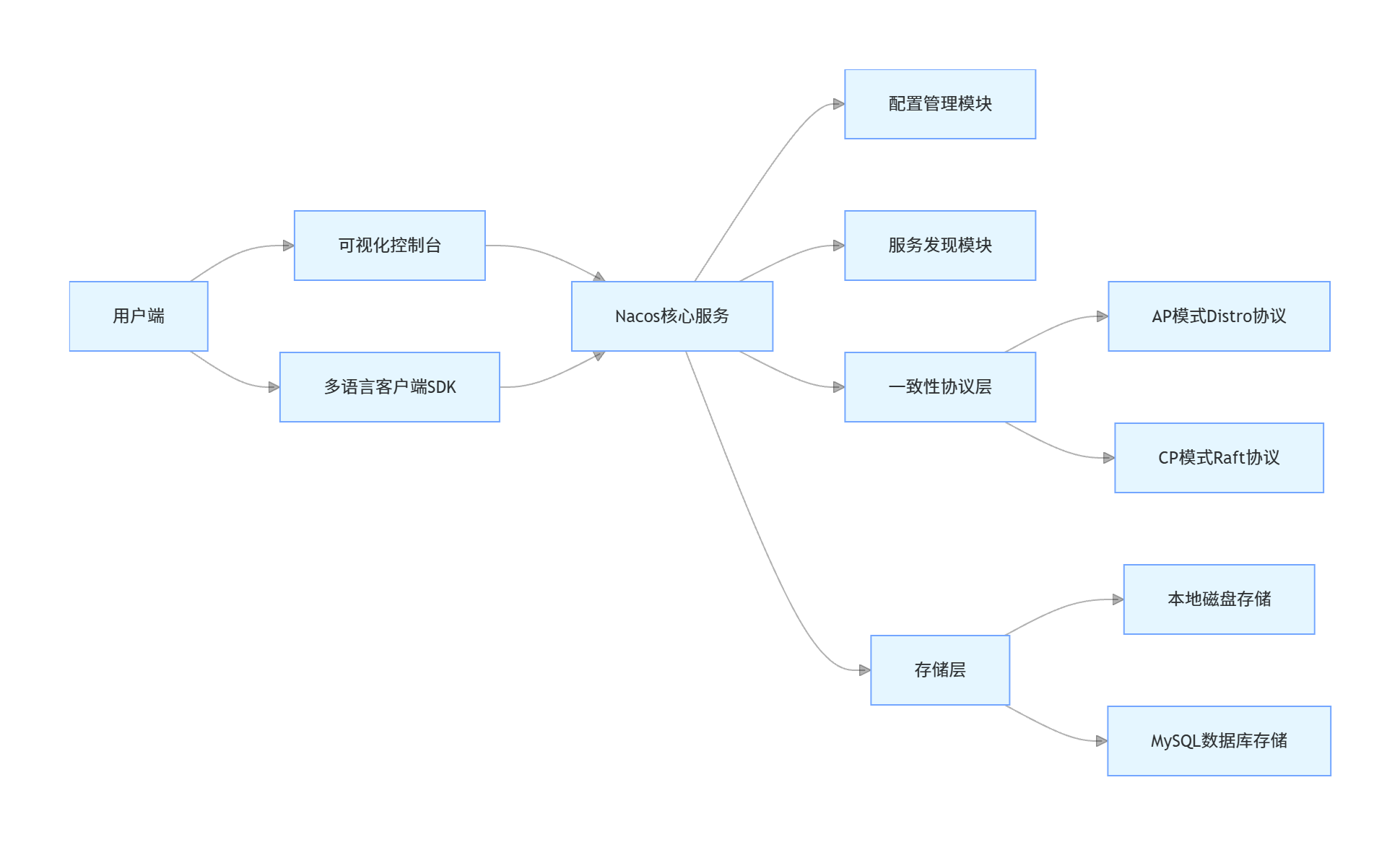
Nacos采用分层架构,模块职责清晰,原生支持AP/CP双模式,适配不同的业务场景:
-
可视化控制台:提供Web管理界面,支持配置管理、服务管理、权限控制、流量治理等可视化操作。
-
多语言客户端SDK:提供Java、Go、Python等主流语言的客户端,无缝集成Spring、Spring Boot、Spring Cloud等框架。
-
配置管理模块:负责配置的存储、版本管理、灰度发布、动态推送、回滚、加密等全生命周期管理。
-
服务发现模块:负责服务注册、健康检查、服务元数据管理、负载均衡、流量路由等核心能力。
-
一致性协议层:提供双模式一致性支持,CP模式采用Raft协议保证强一致性,AP模式采用阿里自研的Distro协议保证高可用。
-
存储层:支持本地磁盘存储与MySQL数据库存储,生产环境推荐使用MySQL 8.0保证数据可靠性。
3.2 Nacos核心数据模型
Nacos采用三层隔离的数据模型,比ZooKeeper的树形结构更贴合业务场景,原生支持多环境、多业务的隔离:
-
命名空间(Namespace):最顶层的隔离级别,通常用于隔离不同的环境(dev、test、prod),每个命名空间有唯一的namespaceId,不同命名空间之间的数据完全隔离。
-
分组(Group):第二层隔离级别,用于隔离不同的业务线或应用(如ORDER_GROUP、USER_GROUP),同一个命名空间下,不同分组的数据相互隔离。
-
数据ID(DataId):最底层的唯一标识,配置场景下对应一个配置文件,服务场景下对应一个服务名,同一个命名空间+分组下,DataId全局唯一。
3.3 Nacos一致性协议:AP+CP双模式灵活切换
Nacos与ZooKeeper最大的区别,就是同时支持AP和CP两种一致性模式,用户可根据业务场景灵活选择,兼顾强一致性与高可用性。
3.3.1 CP模式:Raft协议
Nacos的CP模式采用标准的Raft一致性协议,保证强一致性,写请求需要过半节点写入成功后才会提交,适合对数据一致性要求极高的场景,如持久化服务实例、分布式锁、核心配置数据等。
Raft协议核心角色与流程:
-
角色分为Leader、Follower、Candidate,集群同一时间只有一个Leader,负责处理所有写请求。
-
领导者选举:Leader故障后,Follower转为Candidate发起投票,获得过半投票的节点成为新Leader。
-
日志复制:Leader收到写请求后生成日志条目,广播给Follower,收到过半ACK后提交日志,返回客户端成功。
-
安全性保证:只有拥有最新已提交日志的节点,才能被选举为Leader,保证已提交的数据不会丢失。
3.3.2 AP模式:Distro协议
Distro协议是阿里专为服务发现场景自研的最终一致性协议,核心目标是保证高可用与分区容错性,即使集群出现网络分区,每个节点仍然能正常提供服务注册与发现能力,不会中断业务。
Distro协议核心原理:
-
数据分片:Nacos集群中的每个节点,负责一部分服务实例的数据,服务实例的归属节点通过服务名的hash值计算得出。
-
数据同步:每个节点仅负责自身分片数据的写操作,写操作完成后异步同步给集群所有其他节点,保证数据最终一致性。
-
本地读优先:所有读请求直接从本地节点读取,无需转发给Leader,读性能极高,延迟极低。
-
故障容错:某个节点故障后,其负责的分片数据会自动转移到其他节点,不影响集群整体服务能力。
-
网络分区容错:集群出现网络分区时,每个分区内的节点仍能处理写请求,网络恢复后自动合并数据,保证最终一致性。
Distro协议完美适配服务发现场景:服务发现场景中,业务可用性的优先级远高于强一致性,哪怕服务实例数据有短暂的不一致,也远胜于服务注册中心整体不可用。
3.4 Nacos核心机制
3.4.1 长轮询事件通知机制
对比ZooKeeper的一次性Watcher,Nacos的事件通知机制更强大、更易用,没有一次性触发的限制:客户端注册监听器后,只要不主动取消,就会一直有效,服务端通过HTTP长轮询的方式,实时推送数据变更事件给客户端,无需重复注册。
长轮询核心流程:
-
客户端发起HTTP长轮询请求给服务端,默认超时时间30s。
-
服务端收到请求后,检查客户端关注的配置/服务是否有变更,若有变更,立即返回变更内容给客户端。
-
若无变更,服务端将请求挂起,直到有变更发生,或超时时间快到(默认29.5s)时,返回空响应给客户端。
-
客户端收到响应后,无论是否有变更,都会立即发起下一次长轮询请求,保证持续监听变更。
该机制彻底解决了ZooKeeper一次性Watcher的痛点,监听器持久有效,实时性高,网络开销低。
3.4.2 双模式健康检查机制
Nacos提供了两种服务实例类型,对应不同的健康检查机制,比ZooKeeper的临时节点更灵活,适配更多业务场景:
-
临时实例(AP模式)
-
健康检查采用客户端主动上报心跳模式,默认5s上报一次心跳,服务端15s未收到心跳将实例标记为不健康,30s未收到心跳将实例从服务列表中剔除。
-
临时实例数据仅存储在内存中,不会持久化到数据库,节点重启后临时实例会消失,需要客户端重新注册。
-
采用AP模式的Distro协议,保证高可用性,是服务发现场景的首选。
-
-
持久化实例(CP模式)
-
健康检查采用服务端主动探测模式,默认TCP探测,每隔20s探测一次,3次探测失败将实例标记为不健康。
-
持久化实例数据会持久化到MySQL数据库,节点重启后数据不会丢失,自动恢复。
-
采用CP模式的Raft协议,保证强一致性,适合需要严格保证实例元数据不丢失的场景。
-
3.5 Nacos核心场景与实战代码
3.5.1 动态配置中心
动态配置中心是Nacos的核心场景,基于三层数据模型+长轮询机制,实现配置的全生命周期管理,支持动态刷新,无需重启应用。
Maven依赖
<parent>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-parent</artifactId>
<version>3.2.5</version>
<relativePath/>
</parent>
<dependencies>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-web</artifactId>
</dependency>
<dependency>
<groupId>com.alibaba.boot</groupId>
<artifactId>nacos-config-spring-boot-starter</artifactId>
<version>0.2.12</version>
</dependency>
<dependency>
<groupId>org.springdoc</groupId>
<artifactId>springdoc-openapi-starter-webmvc-ui</artifactId>
<version>2.5.0</version>
</dependency>
<dependency>
<groupId>org.projectlombok</groupId>
<artifactId>lombok</artifactId>
<version>1.18.30</version>
<scope>provided</scope>
</dependency>
<dependency>
<groupId>com.google.guava</groupId>
<artifactId>guava</artifactId>
<version>32.1.3-jre</version>
</dependency>
</dependencies>application.yml配置
spring:
application:
name: order-service
nacos:
config:
server-addr: 127.0.0.1:8848
namespace: dev
group: ORDER_GROUP
data-id: order-service.properties
auto-refresh: true配置类(支持自动刷新)
package com.jam.demo.nacos.config;
import com.alibaba.nacos.api.config.annotation.NacosConfigurationProperties;
import com.alibaba.nacos.api.config.annotation.NacosValue;
import lombok.Data;
import org.springframework.stereotype.Component;
/**
* 订单服务配置类,支持动态自动刷新
*
* @author ken
*/
@Data
@Component
@NacosConfigurationProperties(
dataId = "order-service.properties",
groupId = "ORDER_GROUP",
autoRefreshed = true
)
public class OrderServiceConfig {
/**
* 订单创建超时时间,单位:秒
*/
@NacosValue(value = "${order.create.timeout:30}", autoRefreshed = true)
private Integer orderCreateTimeout;
/**
* 订单支付超时时间,单位:分钟
*/
@NacosValue(value = "${order.pay.timeout:30}", autoRefreshed = true)
private Integer orderPayTimeout;
/**
* 是否开启订单限流
*/
@NacosValue(value = "${order.limit.enable:false}", autoRefreshed = true)
private Boolean orderLimitEnable;
/**
* 订单限流阈值,单位:次/秒
*/
@NacosValue(value = "${order.limit.threshold:1000}", autoRefreshed = true)
private Integer orderLimitThreshold;
}测试Controller(带Swagger3注解)
package com.jam.demo.nacos.controller;
import com.jam.demo.nacos.config.OrderServiceConfig;
import io.swagger.v3.oas.annotations.Operation;
import io.swagger.v3.oas.annotations.tags.Tag;
import lombok.extern.slf4j.Slf4j;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.web.bind.annotation.GetMapping;
import org.springframework.web.bind.annotation.RequestMapping;
import org.springframework.web.bind.annotation.RestController;
/**
* 订单配置测试Controller
*
* @author ken
*/
@Slf4j
@RestController
@RequestMapping("/order/config")
@Tag(name = "订单配置管理", description = "订单配置查询与动态刷新测试")
public class OrderConfigController {
@Autowired
private OrderServiceConfig orderServiceConfig;
/**
* 获取当前生效的订单配置
*
* @return 订单配置信息
*/
@GetMapping("/get")
@Operation(summary = "获取订单配置", description = "查询当前生效的订单服务配置,验证动态刷新效果")
public OrderServiceConfig getOrderConfig() {
log.info("查询订单配置,当前配置:{}", orderServiceConfig);
return orderServiceConfig;
}
}3.5.2 服务注册与发现
Nacos原生提供企业级的服务注册与发现能力,支持健康检查、负载均衡、流量路由等功能,是Spring Cloud Alibaba生态的服务注册中心首选。
Maven依赖新增
<dependency>
<groupId>com.alibaba.boot</groupId>
<artifactId>nacos-discovery-spring-boot-starter</artifactId>
<version>0.2.12</version>
</dependency>application.yml新增配置
nacos:
discovery:
server-addr: 127.0.0.1:8848
namespace: dev
group: ORDER_GROUP
service: order-service
register-enabled: true服务启动类
package com.jam.demo.nacos;
import com.alibaba.nacos.spring.context.annotation.discovery.EnableNacosDiscovery;
import org.springframework.boot.SpringApplication;
import org.springframework.boot.autoconfigure.SpringBootApplication;
/**
* 订单服务启动类
*
* @author ken
*/
@SpringBootApplication
@EnableNacosDiscovery
public class OrderServiceApplication {
public static void main(String[] args) {
SpringApplication.run(OrderServiceApplication.class, args);
}
}服务发现服务类
package com.jam.demo.nacos.service;
import com.alibaba.nacos.api.annotation.NacosInjected;
import com.alibaba.nacos.api.exception.NacosException;
import com.alibaba.nacos.api.naming.NamingService;
import com.alibaba.nacos.api.naming.pojo.Instance;
import com.google.common.collect.Lists;
import lombok.extern.slf4j.Slf4j;
import org.springframework.stereotype.Service;
import org.springframework.util.CollectionUtils;
import java.util.List;
/**
* 服务发现示例服务
*
* @author ken
*/
@Slf4j
@Service
public class ServiceDiscoveryService {
@NacosInjected
private NamingService namingService;
/**
* 获取订单服务所有健康的实例列表
*
* @return 健康实例列表
* @throws NacosException Nacos调用异常
*/
public List<Instance> getHealthyOrderServiceInstances() throws NacosException {
List<Instance> allInstances = namingService.getAllInstances("order-service", "ORDER_GROUP");
if (CollectionUtils.isEmpty(allInstances)) {
log.warn("订单服务无可用实例");
return Lists.newArrayList();
}
List<Instance> healthyInstances = allInstances.stream()
.filter(Instance::isHealthy)
.filter(Instance::isEnabled)
.toList();
log.info("获取到订单服务健康实例数量:{}", healthyInstances.size());
return healthyInstances;
}
}3.5.3 其他核心场景
-
分布式锁:基于Nacos CP模式的Raft协议,通过配置的CAS操作实现分布式锁,适合轻量级的分布式协同场景。
-
灰度发布与流量治理:支持按版本、地域、用户标签等维度进行流量路由,实现服务的灰度发布,无需修改业务代码。
-
集群管理与动态扩缩容:基于健康检查机制,实时感知服务实例的上下线,自动更新服务列表,支持服务的动态扩缩容。
3.6 Nacos高频踩坑避坑指南
-
环境隔离缺失:生产环境必须使用Namespace隔离不同环境,不要使用默认的public命名空间,避免测试环境配置影响生产。
-
长轮询连接被中断:客户端与服务端之间的防火墙需要放开长轮询的超时限制,否则会导致配置变更无法实时推送。
-
实例类型混淆:临时实例与持久化实例的健康检查机制完全不同,不要混用,服务发现场景优先使用临时实例。
-
存储模式错误:生产环境必须使用MySQL数据库存储,不要使用本地磁盘,否则节点重启后会丢失数据,或出现集群数据不一致。
-
鉴权未开启:生产环境必须开启Nacos鉴权,配置用户名密码,禁止匿名访问,敏感配置必须开启加密存储。
四、ZooKeeper vs Nacos 核心对比与选型建议
4.1 核心维度全面对比
| 对比维度 | ZooKeeper | Nacos |
|---|---|---|
| 核心定位 | 分布式协调中间件,专注于分布式协同能力 | 一站式云原生中间件,整合配置中心、服务注册中心、协调能力 |
| CAP支持 | 仅支持CP模式,保证强一致性,网络分区时不可用 | 同时支持AP+CP双模式,可根据业务场景灵活切换 |
| 一致性协议 | ZAB专属原子广播协议 | CP模式用Raft协议,AP模式用Distro协议 |
| 数据模型 | 树形ZNode结构,类Linux文件系统 | 三层隔离模型(Namespace+Group+DataId),原生支持业务隔离 |
| 事件通知机制 | 一次性Watcher,触发后需重新注册 | 持久化长轮询监听器,注册后持续有效,自动推送变更 |
| 服务发现能力 | 仅支持基础的服务注册发现,无健康检查、流量治理能力 | 原生支持企业级服务发现,包含健康检查、负载均衡、灰度路由、流量管理 |
| 配置中心能力 | 仅支持基础的配置存储与通知,无版本管理、灰度、回滚能力 | 原生支持企业级配置中心,包含版本管理、灰度发布、配置回滚、权限控制、加密 |
| 性能表现 | 读性能优秀,写性能较差,不适合频繁写场景 | 读性能远超ZK,写性能优秀,支持高并发的配置更新与服务注册 |
| 易用性 | 客户端API复杂,学习成本高,无原生可视化控制台 | 客户端API简单,无缝集成Spring生态,有功能完善的可视化控制台,学习成本低 |
| 生态适配 | 深度适配Kafka、Flink、Hadoop等大数据生态,兼容性极强 | 深度适配Spring Cloud、Dubbo、K8s等云原生生态,是Spring Cloud Alibaba核心组件 |
| 运维成本 | 运维复杂,调优参数多,集群扩容麻烦 | 运维简单,可视化运维,集群扩容方便,原生支持K8s部署 |
4.2 选型建议
优先选择Nacos的场景
-
云原生架构,采用Spring Cloud/Spring Boot技术栈。
-
需要一站式的配置中心+服务注册中心,不想维护多套中间件。
-
服务发现场景,对可用性要求高,可接受最终一致性。
-
需要配置的版本管理、灰度发布、回滚、权限控制等企业级能力。
-
业务场景有频繁的配置更新与服务上下线,对写性能有要求。
-
团队希望使用简单易用、运维成本低的中间件。
优先选择ZooKeeper的场景
-
大数据生态,如Kafka、Flink、Hadoop、Dubbo等组件,原生适配ZK,兼容性最好。
-
对分布式协调的强一致性有极高要求的金融级场景,如分布式锁、Master选举、分布式事务协调。
-
业务场景读多写少,无频繁的写操作。
-
现有系统已深度集成ZK,迁移成本极高。
五、生产环境最佳实践
5.1 ZooKeeper生产最佳实践
-
集群部署规范:集群节点数必须为奇数,推荐3、5、7个节点,节点数越多写性能越差,不要超过7个节点;不要跨机房部署,否则网络延迟会严重影响写性能。
-
磁盘配置优化:ZK对磁盘IO敏感度极高,必须使用SSD磁盘,事务日志与快照文件分开存储在不同磁盘,避免IO竞争。
-
参数调优:会话超时时间推荐设置为30s,避免过短导致频繁会话失效,过长导致故障无法及时感知;JVM堆内存推荐设置为4-8G,避免频繁GC。
-
数据量管控:单个ZNode数据大小不超过1KB,集群总节点数不超过100万,总数据量不超过1GB,避免影响性能。
-
监控告警:必须监控节点状态、Leader选举事件、会话数、请求延迟、磁盘使用率、事务日志大小等核心指标,及时发现异常。
5.2 Nacos生产最佳实践
-
集群部署规范:生产环境推荐3节点集群,保证Raft协议过半写入的高可用;生产环境必须使用MySQL 8.0主从架构存储,禁止使用本地磁盘。
-
隔离规范:必须使用Namespace隔离不同环境,使用Group隔离不同业务线,避免数据混乱。
-
模式选择规范:服务发现场景优先使用AP模式的临时实例,保证高可用;强一致性需求场景使用CP模式的持久化实例。
-
安全规范:开启鉴权,配置用户名密码,禁止匿名访问;开启配置加密,敏感配置(如数据库密码)禁止明文存储。
-
性能调优:JVM堆内存推荐设置为4G以上,调整长轮询超时时间适配网络环境,开启集群流量控制,避免大流量冲击。
-
监控告警:监控节点状态、集群健康度、请求量、响应延迟、配置推送成功率、服务实例数等核心指标,及时告警。
总结
分布式协调中间件是分布式系统的基础设施,ZooKeeper作为经典的协调内核,在大数据生态中拥有不可替代的地位,其ZAB协议与Watcher机制是分布式协调的经典实现。而Nacos作为云原生时代的一站式解决方案,不仅具备完善的分布式协调能力,还整合了企业级的配置中心与服务注册中心功能,易用性、性能、功能丰富度都更贴合现代微服务架构的需求。