写在前面
在云原生时代,数据存储的需求正以前所未有的速度增长。无论是容器平台的持久化存储、虚拟机的磁盘后端,还是对象存储的海量数据,企业都需要一个可扩展、高可用、无单点故障的存储方案。
而 Ceph,正是这样一个久经沙场的软件定义存储(SDS)解决方案。
本文将带你从零开始,系统地了解 Ceph 的核心架构、关键组件、数据保护机制以及多种访问方式。无论你是开发者、运维工程师还是技术决策者,读完这篇文章后,你将能够回答一个核心问题:
Ceph 为什么能成为 OpenStack、Kubernetes 和众多云平台的首选存储后端?
一、Ceph 是什么?
Ceph 是一个开源的分布式存储系统,提供三种存储接口:
| 存储类型 | 协议 | 典型场景 |
|---|---|---|
| 块存储(RBD) | iSCSI / 内核模块 | 虚拟机磁盘、容器持久化卷 |
| 文件存储(CephFS) | POSIX 文件系统 | 共享文件系统、多读写访问 |
| 对象存储(RGW) | S3 / Swift API | 云存储、数据湖、备份归档 |
Ceph 的核心优势在于:一套存储集群,同时满足块存储、文件存储和对象存储多种存储需求。
二、Ceph 的整体架构
Ceph 的架构设计遵循一个基本原则:无单点故障 。
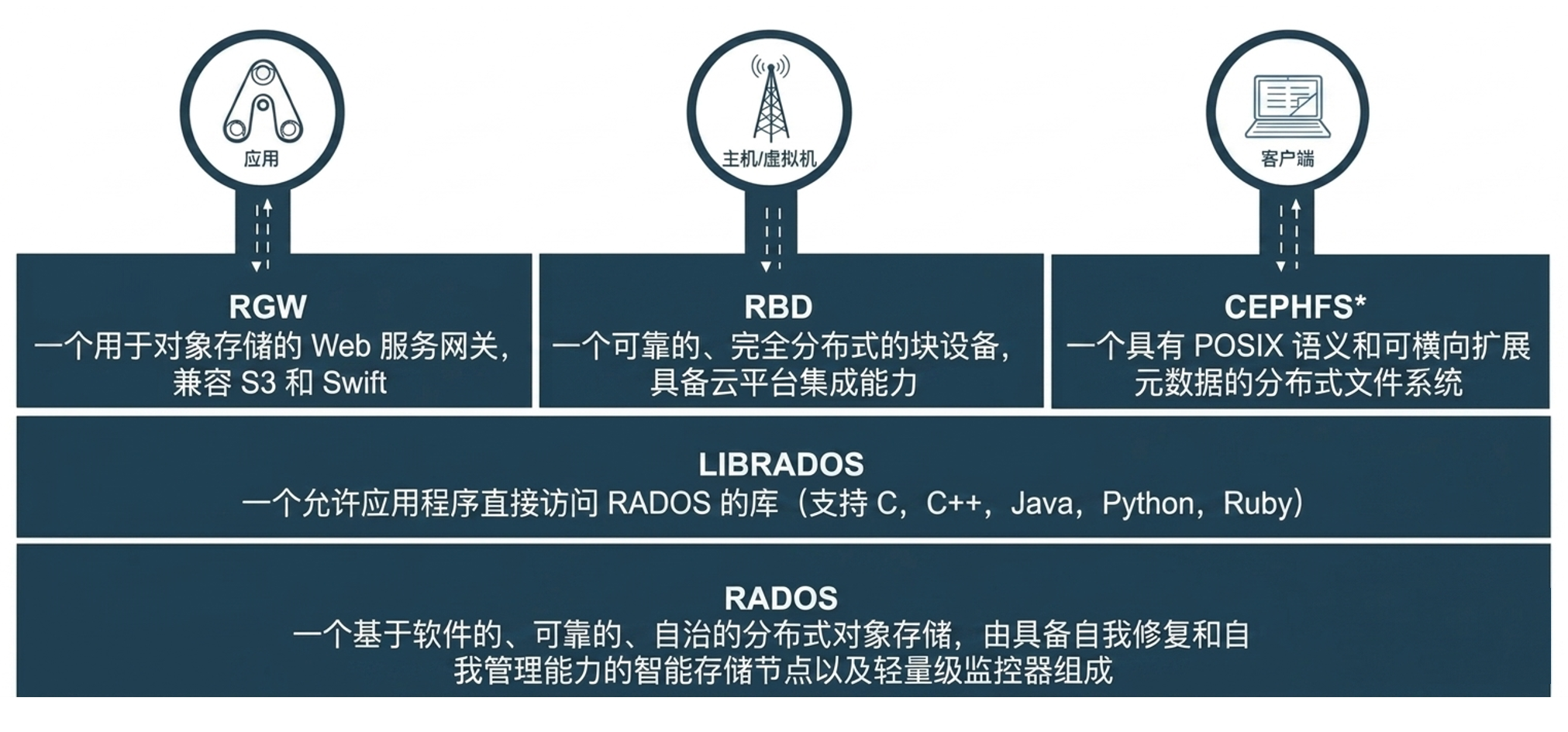
Ceph 的核心是 RADOS(Reliable Autonomic Distributed Object Store)------可靠自治分布式对象存储。它是 Ceph 的"心脏",负责提供存储能力、数据保护、一致性检查和完整性验证。
所有上层访问方式(RBD、CephFS、RGW)最终都通过 RADOS 来读写数据。RADOS层包含四个守护进程:MONs、OSDs、MGRs和MDSs。下面分别介绍。
三、四大核心守护进程
3.1 Monitor(MON)------ 集群的"大脑"
Monitor 负责维护集群的映射图(Cluster Map)和状态信息。
关键特性:
- 不在数据路径上:MON 不处理 IO 请求,只维护元数据和状态
- 分布式决策:多个 MON 通过 Paxos 协议达成共识
- 部署数量必须是奇数:通常部署 3 或 5 个,以防止"脑裂"(Split-Brain)情况
为什么是奇数?假设部署 4 个 MON,当网络分区导致 2:2 分裂时,无法形成多数派。而 3 个 MON 可以容忍 1 个故障,5 个可以容忍 2 个故障。
3.2 OSD(Object Storage Daemon)------ 集群的"肌肉"
OSD 是 Ceph 中真正干活的组件。
关键特性:
- 每个本地块设备对应一个 OSD 进程
- 集群可以扩展到数千个 OSD
- 直接服务客户端的 IO 请求
- 负责数据保护(副本或纠删码)
- 处理故障时的数据重平衡
- 执行数据一致性检查(Scrubbing 和 Deep-Scrubbing)
OSD 是 Ceph 集群中数量最多的组件,也是性能调优的重点对象。
3.3 Manager(MGR)------ 集群的"仪表盘"
Manager 与 Monitor 紧密集成,负责收集集群统计信息,并通过可插拔的 Python 接口提供扩展能力。
常用模块:
| 模块 | 功能 |
|---|---|
| Dashboard | Web 管理界面 |
| Prometheus | 指标导出,用于监控 |
| Balancer | 自动数据均衡 |
| PG Auto-scaler | 自动调整 PG 数量 |
| RESTful | REST API 接口 |
| Zabbix | 与 Zabbix 监控集成 |
3.4 Metadata Server(MDS)------ 文件系统的"管家"
MDS 仅在配置 CephFS 共享文件系统时才需要部署。
关键特性:
- 管理 POSIX 兼容共享文件系统的元数据
- 处理目录层次结构和文件元数据(所有权、时间戳、权限模式)
- 所有元数据存储在 RADOS 中
- 不向客户端提供数据服务------客户端获取元数据后直接与 OSD 通信读写数据
四、四种访问方式
4.1 Librados ------ 原生 API
Librados 是 Ceph 的原生客户端库,允许开发者直接调用 Ceph 集群 API,实现最高效率和最小开销。
支持多种语言绑定:C、C++、Python、Java、Ruby、Erlang、Go 和 Rust。
适合需要极致性能、愿意直接与 Ceph 交互的应用场景。
4.2 RBD(RADOS Block Device)------ 块存储
RBD 提供块设备接口,广泛应用于 RHEL、OpenStack 和 OpenShift 平台。主要解决 RWO(ReadWriteOnce) 持久化卷需求。
两种实现方式:
内核模块(kRBD):
- 性能优于用户空间 librbd 方式
- 功能有限(不支持 RBD 镜像等高级特性)
用户空间 RBD(librbd):
- 在 OpenStack 环境中使用,或通过 RBD-NBD 驱动(RHEL 8.1+)在 OpenShift(基于Kubernetes的容器平台) 中使用
- 支持所有 RBD 特性,包括 RBD 镜像(Mirroring)
4.3 CephFS ------ 共享文件系统
CephFS 提供 POSIX 兼容的共享文件系统,允许多个客户端同时访问。
工作流程:
- 客户端向 MDS 查询指定 inode 对应的对象位置
- 客户端直接与 OSD 通信进行 IO 操作
CephFS 适用于 RWX(ReadWriteMany) 持久化卷场景,也可以用于 RWO 场景。
4.4 RGW(RADOS Gateway)------ 对象存储
RGW 提供 Amazon S3 和 OpenStack Swift 兼容的对象存储接口。
关键特性:
- RGW 被标记为兼容 S3 的端点
- 支持大规模对象存储场景
五、CRUSH 算法:数据放在哪里?
CRUSH(Controlled Replication Under Scalable Hashing)是 Ceph 的数据分布算法,决定了数据存放在哪些 OSD 上。
在开始之前,有必要介绍下Pool(存储池)和Placement Group (PG)。 在 Ceph 中,Pool 和 PG 是两层逻辑抽象。
Pool
Pool 是 Ceph RADOS 存储集群中的逻辑存储分区,是用户与 Ceph 交互的基本单位。当你向 Ceph 存储或读取数据时,操作都是针对某个具体的 Pool 进行的。
Pool 本质上是一组共享相同数据管理策略的对象集合,每个 Pool 可以独立配置:
它的属性如下:
| 属性 | 说明 |
|---|---|
| ID | 不可变的唯一标识 |
| 名称 | 人类可读的标识 |
| PG 数量 | 用于对象分布 |
| CRUSH 规则 | PG 映射策略 |
| 保护类型 | 副本(Replication)或纠删码(Erasure Coding) |
| 保护参数 | 副本数量;EC 的 K 和 M 值 |
| 行为标志 | 影响 Pool 行为的各种标志 |
Ceph 支持两种主要的 Pool 类型:多副本和纠删码类型的Pool(后面详细介绍)。
数据映射路径如下:
Object(对象) → Pool → PG → OSD- Object 被分配到某个 Pool(由客户端配置决定)
- 在 Pool 内,Object 通过哈希运算映射到某个 PG
- PG 再通过 CRUSH 算法映射到一组 OSD(主 OSD + 副本 OSD)
Placement Group(归置组,简称 PG)
是 Ceph 存储池(Pool)的子集,是一组 RADOS 对象的逻辑集合。PG 的核心功能是以"组"为单位,将对象批量放置到 OSD 中。
Pool 与 PG 的关系
- 每个 Pool 拥有自己独立的一组 PG,不同 Pool 之间的 PG 互不干扰
- 创建 Pool 时需要指定 PG 数量(pg_num)
- PG 是复制和恢复的基本单位,不是单个 Object------Ceph 以 PG 为单位进行数据迁移、副本同步、故障恢复
- 一个 Pool 没有容量限制:可以消耗其 PG 所在任何 OSD 的空间
- 一个 PG 只属于一个 Pool
- 一个对象只属于一个且仅一个 PG
为什么需要 PG?
Ceph 集群可能存储数十亿个对象。如果 Ceph 直接跟踪每个对象映射到哪些 OSD,元数据量会爆炸式增长,导致:
- 内存消耗巨大
- 元数据查找缓慢
- 数据迁移/恢复效率极低
PG 通过两级映射解决这个问题:
对象 (数十亿个) ──哈希──> PG(几千个) ──CRUSH算法──> OSD 列表(几十个到几万个)
关键洞察:对象到 PG 的映射是静态的(通过哈希计算),PG 到 OSD 的映射是动态的(通过 CRUSH 算法)。当 OSD 发生变化时,Ceph 只需要重新计算少量 PG 的归属,而不是逐个处理每个对象。
PG数目计算
PG 总数 = (目标每 OSD 的 PG 数 × OSD 总数 × 数据分布比例) / 副本数
例如:100 个 OSD,目标 100 PG/OSD,副本数 3:
PG = (100 × 100 × 1.0) / 3 ≈ 3333(取 2 的幂,即 4096)
PG 自动调节(Ceph Nautilus 及之后)
现代 Ceph 版本提供了 PG 自动调节器(PG Autoscaler),会根据 Pool 使用量、集群大小、副本数等自动调整 PG 数量:
ceph osd pool set <pool-name> pg_autoscale_mode on简单类比:Pool 像一个"仓库分类",PG 是仓库里的"货架",OSD 是实际的"仓库位置"。数据先按分类放进仓库,再通过哈希放到某个货架上,最后由 CRUSH 决定货架摆在哪些仓库位置上。
CRUSH 的关键特性:
- 集中配置的集群拓扑:管理员可以定义存储拓扑结构
- 伪随机放置算法:确保对象均匀分布在各个 PG 上
- 规则驱动:通过 CRUSH 规则决定 PG 到 OSD 的映射
- 故障自愈:当 OSD 故障时,PG 会被重新映射到其他 OSD,并同步数据内容
六、数据保护:副本 vs 纠删码
Ceph 支持两种数据保护方式:
6.1 副本池(Replicated Pool)
优势: 性能更好(大多数情况下)
劣势: 可用容量与原始容量比低
默认 1:3 比例------1 字节可用数据需要 3 字节原始存储空间(1 份原始数据 + 2 份副本)。
6.2 纠删码(Erasure Coding)
优势: 存储成本更低
劣势: 性能低于副本方式
支持的配置:
| 配置 | 可用:原始比例 | 说明 |
|---|---|---|
| 4+2 | 1:1.666 | 4 份数据 + 2 份校验 |
| 8+3 | 1:1.375 | 8 份数据 + 3 份校验 |
| 8+4 | 1:1.666 | 8 份数据 + 4 份校验 |
纠删码提供极强的容错能力,可配置校验块数量。适用于 RGW 和 RBD 访问方式(但 RBD 使用纠删码会有性能影响)。
如何选择?
- 热数据、高性能场景 → 副本池
- 冷数据、存储成本敏感 → 纠删码
- 混合场景 → 不同 Pool 使用不同策略
七、数据分布机制
除 librados 外,所有访问方式都通过对象集合来访问数据。
举例:
- 一个 1GB 的块设备 = 一组对象的集合(每个对象支持设备扇区)
- 一个 1GB 的 CephFS 文件 = 被拆分为多个对象
- 一个 5GB 的 S3 对象 = 被划分为多个对象
默认对象大小:4MB
这意味着 Ceph 在底层将所有的数据都切分为固定大小的对象,然后通过 CRUSH 算法将这些对象分布到集群中的不同 OSD 上。
八、Ceph 为什么受欢迎?
总结 Ceph 的核心竞争力:
- 统一存储:一套集群同时提供块存储、文件存储和对象存储
- 无限扩展:可以从几个 TB 扩展到 EB 级别
- 无单点故障:分布式架构确保高可用
- 开源开放:Apache 2.0 许可,社区活跃
- 云原生友好:与 Kubernetes、OpenStack 深度集成
- 数据保护灵活:副本和纠删码按需选择
- 生态丰富:Librados 多语言 SDK、Rook 运算符、Prometheus 监控集成
九、总结
Ceph 是一个经过实战检验的软件定义存储方案,从底层 RADOS 到上层的 RBD、CephFS 和 RGW,每一层都为不同的使用场景提供了最优解。
如果你正在寻找一个可扩展、高可用、多协议支持的存储方案,Ceph 绝对值得深入了解。
参考来源:Red Hat Blog --- OpenShift Container Storage 4: Introduction to Ceph
觉得这篇文章有用?欢迎转发分享,让更多人了解 Ceph!