HTTP 系列(1/4):HTTP 是什么 → 请求与响应 → 状态码 → HTTPS
一、你每天都在用 HTTP,但你真的了解它吗?
打开浏览器访问一个网页,用 requests.get() 调一个模型的推理 API,或者用 curl 测试后端接口。这些动作背后,都在说同一种语言:HTTP。
作为 ML 工程师,你可能对梯度下降了如指掌,但当你要把模型部署成 API、调试一个返回 500 的推理服务、或者搞清楚为什么跨域请求被拦截时,HTTP 的基础知识就变得不可或缺了。
这个系列不会把 RFC 文档翻译一遍给你看。我们会用最直觉的方式,把 HTTP 的核心概念讲清楚。今天从最基本的问题开始:HTTP 到底是什么?
二、先用一个类比建立直觉
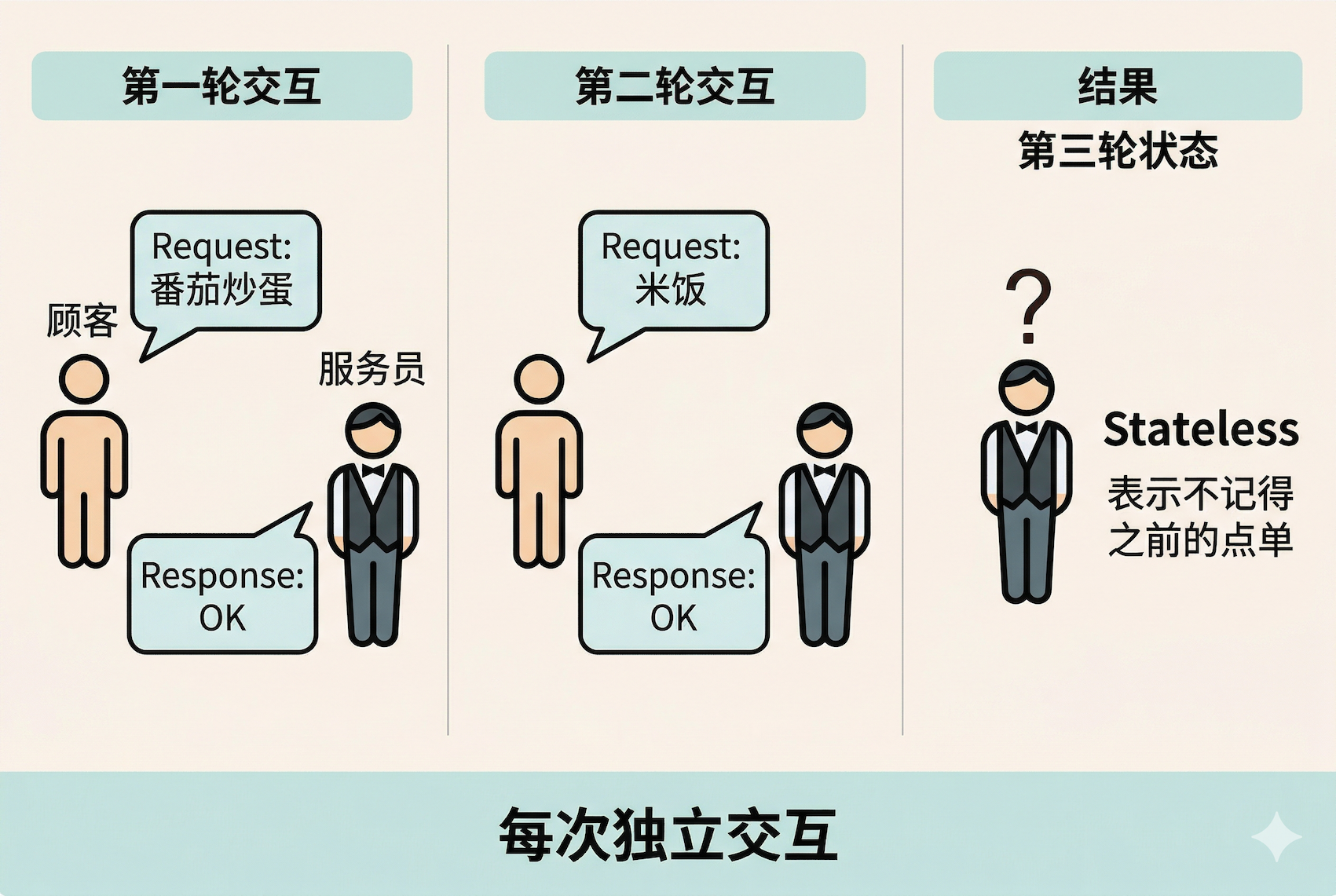
HTTP 的工作方式,很像在餐厅点餐。
你坐下来,跟服务员说:"来一份番茄炒蛋。" 服务员去后厨,回来告诉你:"好的,马上做" 。有时,厨房的食材可能用完了,我们会等到服务员过来对我们说: "抱歉,番茄用完了。"
2.1 关键特征
-
一来一回:你说一句,服务员回一句。你不说话,服务员不会主动端菜过来。
-
你来主导:永远是你先开口(请求),服务员再回应(响应)。
-
服务员不记得你:每次点餐都是独立的。你昨天来过、点过什么,服务员完全不记得。
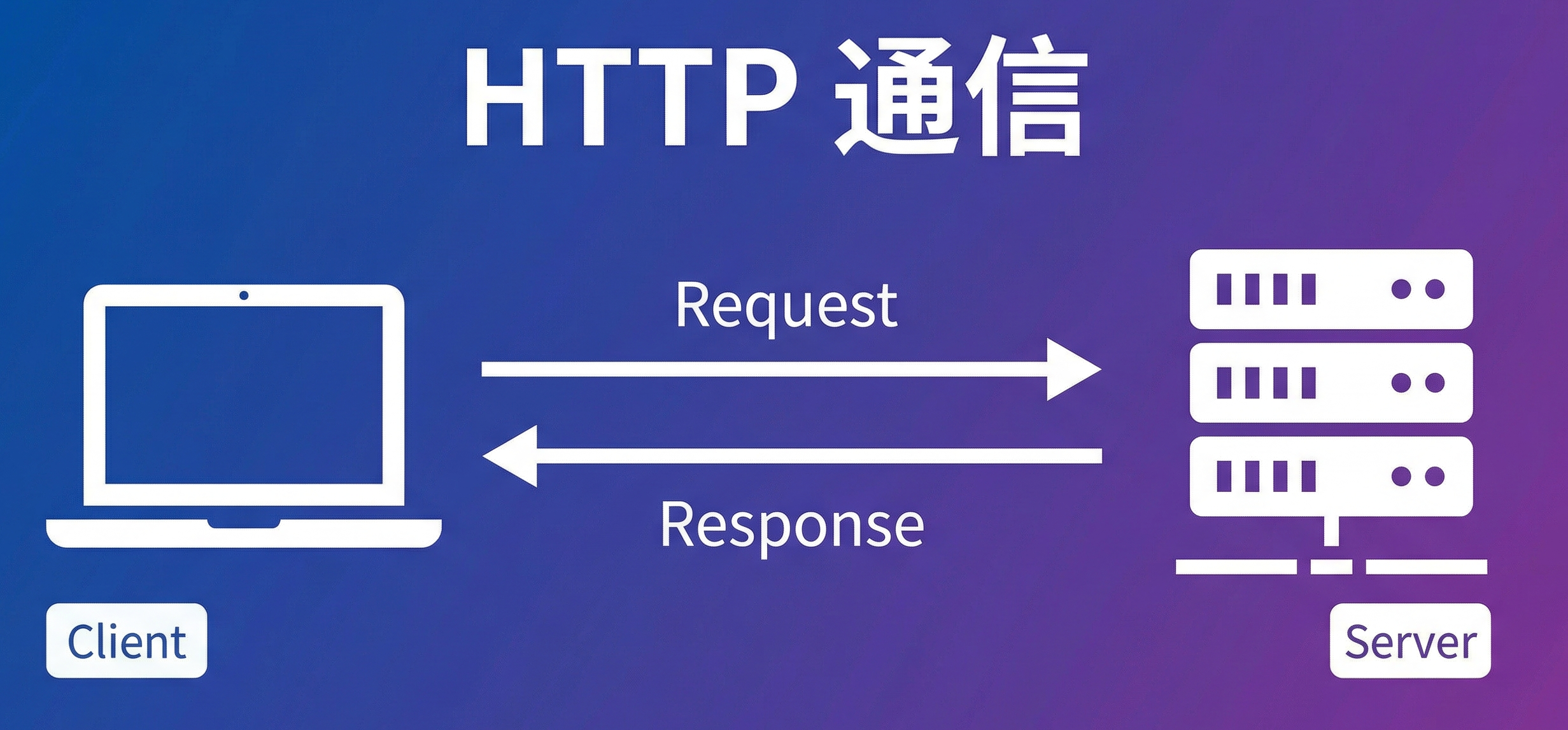
这就是 HTTP 的三个核心特征:请求-响应模型 、客户端驱动 、无状态。
2.2 类比
把这个类比映射到技术世界: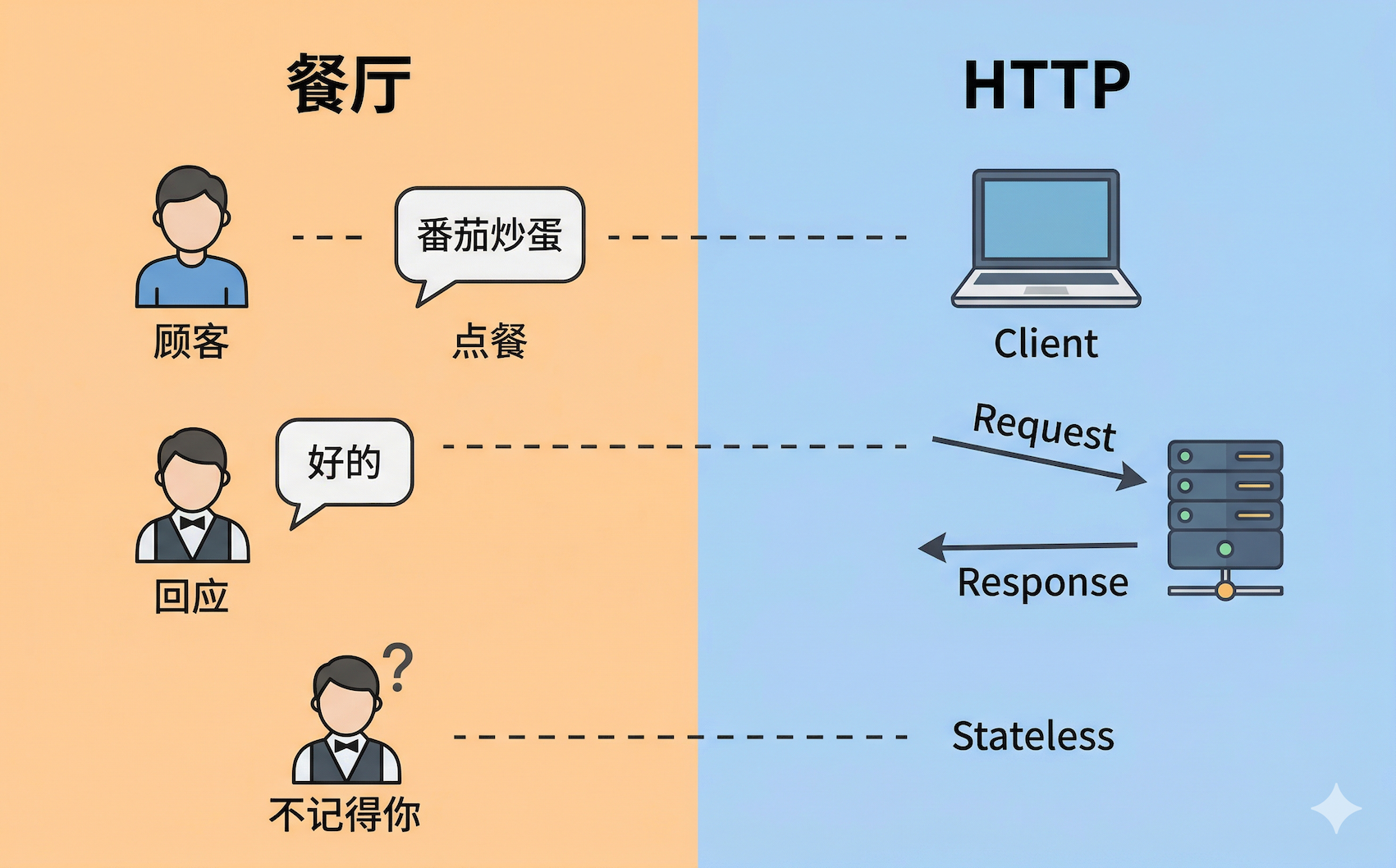
用表格再做一份文字版对照:
| 餐厅 | HTTP |
|---|---|
| 顾客 | 客户端(浏览器、Python 脚本) |
| 服务员 + 后厨 | 服务器 |
| "来一份番茄炒蛋" | HTTP 请求 |
| "好的,给您" | HTTP 响应 |
| 服务员不记得你 | 无状态(Stateless) |
三、HTTP 的正式定义
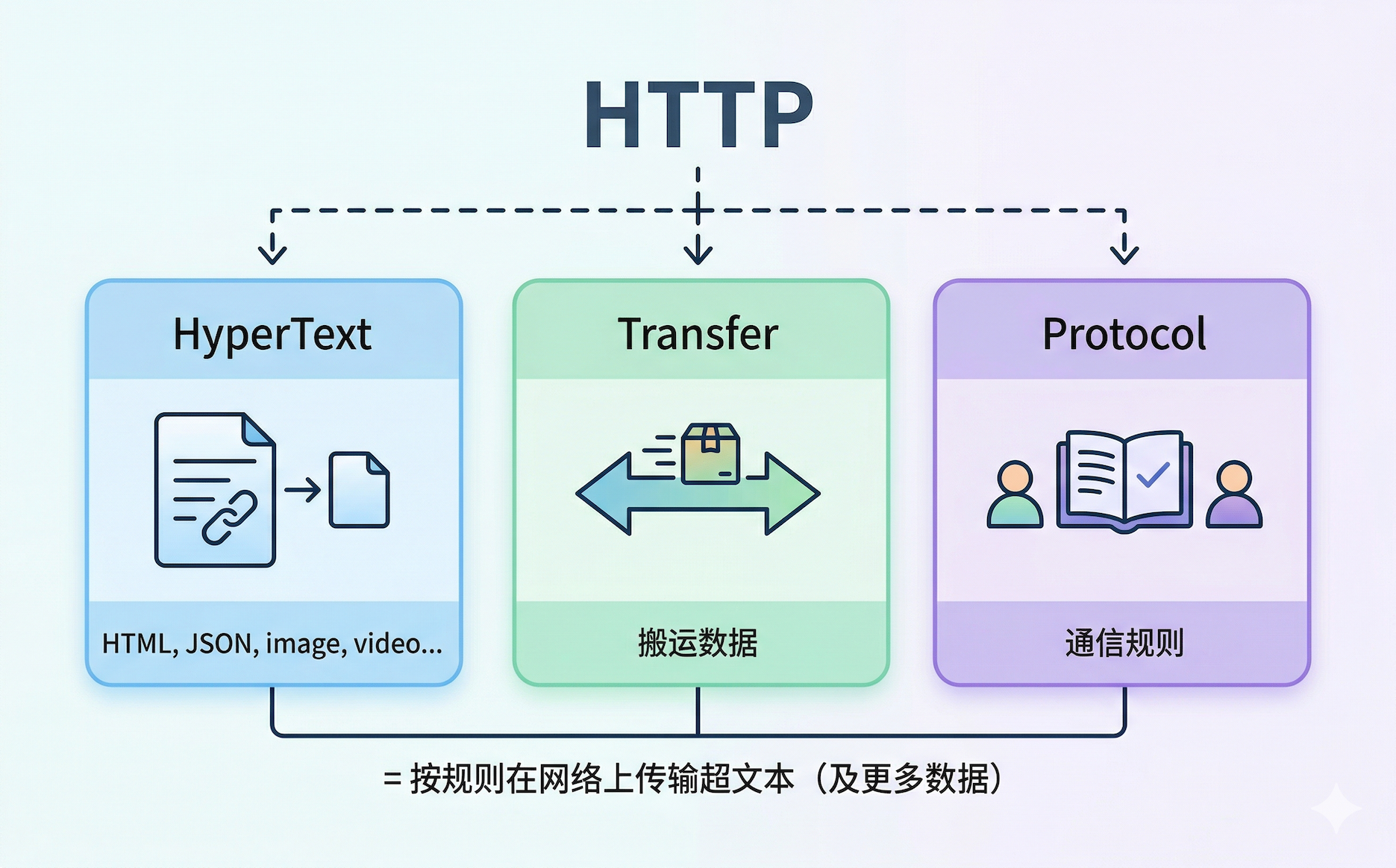
HTTP ,全称 HyperText Transfer Protocol ,超文本传输协议。
3.1 定义描述
- HyperText(超文本):最初指带链接的文本(HTML),现在 HTTP 传的远不止文本。JSON、图片、视频、模型权重文件,什么都行。
- Transfer(传输):在网络上搬运数据。
- Protocol(协议):双方约定好的通信规则。就像你和服务员都说中文,客户端和服务器都遵守 HTTP 协议,才能互相理解。
HTTP 是一个应用层协议,跑在 TCP 之上。 如果你熟悉网络分层模型,HTTP 处于最顶层。它不关心数据包怎么在网线里传输(那是 TCP/IP 的事),它只关心"我要什么数据"和"给你什么数据"。
3.2 代码实现
用一段 Python 来感受一下:
python
import requests
response = requests.get("https://www.google.com") 这一行代码做了什么?
(1) 客户端构造HTTP请求
python
# 方法: GET
# 目标: /
# 发往: www.google.com(2) 服务器收到请求,处理后返回HTTP相应
python
print("Status Code: ", response.status_code) # 200 ------ 表示成功
print("Content Type: ", response.headers["Content-Type"])输出:
bashStatus Code: 200 Content Type: text/html; charset=ISO-8859-1
一来一回,这就是一次完整的 HTTP 通信。下一篇我们会详细拆解请求和响应各自长什么样,今天先抓住这个"一来一回"的核心模型。
四、请求-响应模型
HTTP 的通信永远遵循一个模式:客户端发起请求,服务器返回响应 。
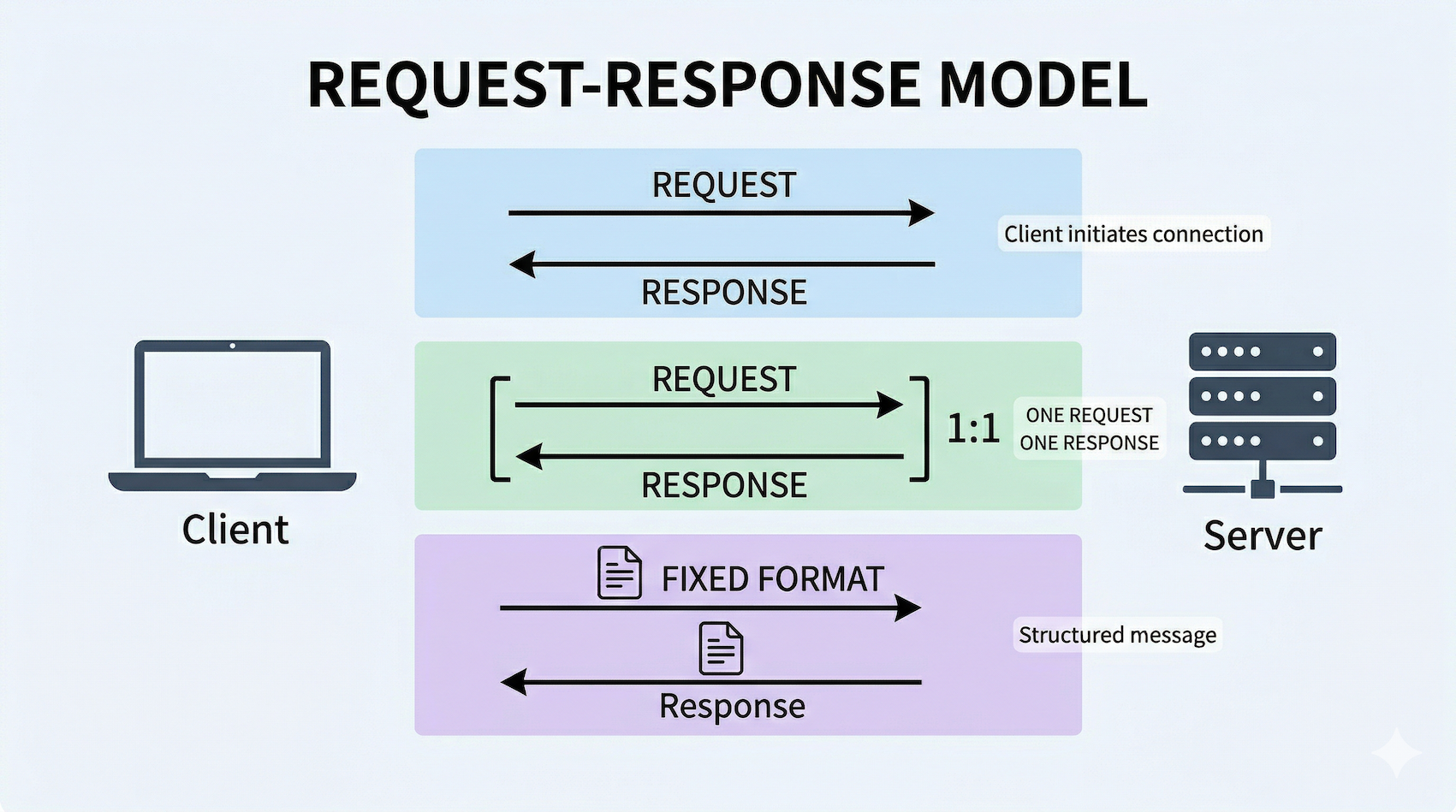
4.1 服务器只能被动回应
客户端先开口,服务器只能被动回应。 服务器不会主动推送数据给你(想实现主动推送,需要 WebSocket 等其他协议,那是另一个话题了)。
4.2 请求和响应一一对应
一个请求对应一个响应。 你发一个请求,得到一个响应。想要两份数据?发两个请求。
4.3 格式固定
请求和响应都有固定的格式。 不是随便说句话就行,得按规矩来。具体格式我们下一篇展开。
我们用 curl 来直观感受这个过程:
bash
curl -v https://www.google.com# 你发出的请求(精简版):
> GET /get HTTP/1.1
> Host: www.google.com
# 服务器返回的响应(精简版):
< HTTP/1.1 200 OK
< Content-Type: text/html
<
<!doctype html>...(Google 首页的 HTML) > 开头的是你发出去的内容,< 开头的是服务器返回的内容。一来一回,清清楚楚。
五、无状态:HTTP 最重要的设计决策
HTTP 是无状态协议。 每次请求都是独立的,服务器不会记住你之前做过什么。
5.1 什么是无状态协议
这意味着什么?你发了两个请求:
python
# 第一个请求:登录
requests.post("https://example.com/login", data={"user": "alice", "pwd": "123"})
# 第二个请求:获取个人信息
requests.get("https://example.com/profile") 第二个请求会失败。因为服务器处理第二个请求时,完全不知道你刚刚登录过。对它来说,这是一个全新的、匿名的请求。
5.2 网站是怎么保持登录状态的
靠的是在 HTTP 之上额外加了一层机制:Cookie、Session、Token 。这些不是 HTTP 协议本身的功能,而是应用层的补丁。
无状态看起来是个缺点,但其实是精心设计的结果。正因为无状态,服务器不需要维护连接状态,可以轻松横向扩展。你的请求被分配到哪台服务器都一样,这对大规模分布式系统至关重要。
六、HTTP 的演进:从青铜到王者
HTTP 不是一成不变的。从 1991 年至今,它经历了几次重要的版本升级:
| 版本 | 年份 | 关键改进 |
|---|---|---|
| HTTP/0.9 | 1991 | 最初版本,只能 GET,只能传 HTML |
| HTTP/1.0 | 1996 | 加了请求头、状态码、多种内容类型 |
| HTTP/1.1 | 1997 | 至今最广泛使用,支持持久连接、管线化 |
| HTTP/2 | 2015 | 多路复用、头部压缩、二进制分帧,更快 |
| HTTP/3 | 2022 | 底层从 TCP 换成 QUIC(基于 UDP),更快更稳 |
你现在写的大部分代码,底层用的都是 HTTP/1.1 或 HTTP/2 。好消息是,不管版本怎么变,请求-响应的核心模型没有变。所以我们这个系列讲的概念,对所有版本都适用。
版本升级主要解决的是性能问题(更快、更省带宽),而不是改变通信模型。所以你不需要为每个版本单独学一套东西。
七、总结
回顾一下今天的核心要点:
- HTTP 是客户端和服务器之间的通信协议,全称 HyperText Transfer Protocol
- 请求-响应模型:客户端发请求,服务器回响应,永远是这个顺序
- 无状态:服务器不记得你之前做过什么,每次请求都是全新的。登录状态靠 Cookie/Session/Token 维持
- 应用层协议:跑在 TCP 之上(HTTP/3 跑在 QUIC 之上),不关心底层传输细节
- 持续演进:从 1.0 到 3,性能不断提升,但核心模型不变
下一篇,我们来拆解 HTTP 请求和响应的具体结构。请求行、请求头、请求体各自是什么,响应又长什么样。搞清楚这些,你才能真正读懂 curl -v 的输出,也才能在调试 API 时知道问题出在哪一层。