一、消息中间件的由来
1.1 为什么需要消息中间件?
在互联网早期,系统架构通常是单体应用 模式------所有功能模块打包部署在一起,模块间通过直接调用(如函数调用、HTTP请求)进行通信。
随着业务发展,这种模式暴露出严重问题:
| 问题场景 | 具体表现 |
|---|---|
| 系统耦合 | 订单系统直接调用支付系统,支付系统宕机导致订单系统崩溃 |
| 流量洪峰 | 秒杀活动时,瞬间高并发直接压垮数据库 |
| 异步需求 | 用户注册后需要发送邮件,同步等待邮件发送导致响应缓慢 |
| 系统异构 | Java系统需要与Python系统通信,协议不兼容 |
| 数据一致性 | 分布式环境下,多个系统间的数据同步困难 |
消息中间件(Message-Oriented Middleware, MOM) 应运而生,它通过异步消息传递解耦系统,成为分布式架构的基础设施。
1.2 历史演进
1980s │ 消息队列概念诞生,IBM MQSeries(现IBM MQ)开创先河
│
1990s │ JMS(Java Message Service)标准发布,企业级MQ成熟
│
2000s │ AMQP协议提出,RabbitMQ 2007年发布
│
2010s │ 大数据时代,Kafka(2011)专为高吞吐日志处理设计
│ RocketMQ(2012)阿里开源,兼顾低延迟与可靠性
│
2016+ │ Pulsar诞生,云原生架构,存算分离
│ 云托管服务兴起(AWS SQS/Azure Service Bus)1.3 核心设计思想
消息中间件的本质是生产者-消费者模式的工业化实现:
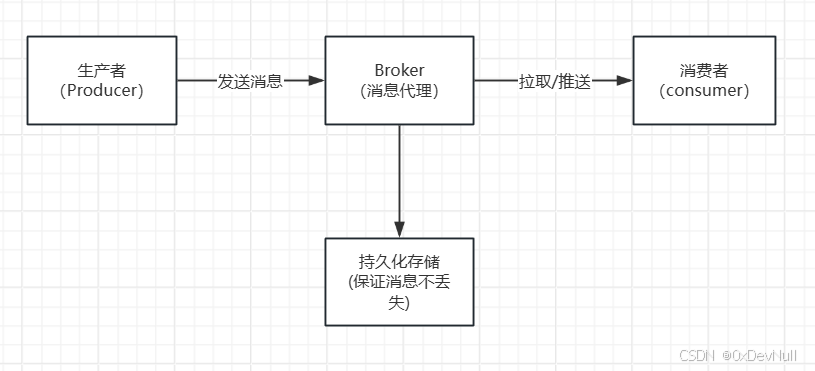
核心能力:
- 异步通信:发送方无需等待接收方处理完成
- 系统解耦:生产者和消费者互不知晓对方存在
- 流量削峰:消息暂存于Broker,消费者按能力消费
- 广播/路由:一条消息可被多个消费者处理
二、主流消息中间件详解
2.1 产品全景图
| 产品 | 诞生背景 | 核心定位 | 典型场景 |
|---|---|---|---|
| RabbitMQ | 金融企业需求 | 企业级通用MQ | 订单处理、任务调度 |
| Kafka | LinkedIn日志处理 | 高吞吐流处理 | 日志采集、实时计算 |
| RocketMQ | 阿里电商双11 | 金融级可靠性 | 交易核心链路 |
| Pulsar | Yahoo云原生实践 | 云原生架构 | 多租户、跨地域 |
| Redis Stream | 缓存系统扩展 | 轻量级消息 | 简单队列、缓存场景 |
2.2 深度对比
RabbitMQ
- 架构特点:基于Erlang的AMQP实现,Exchange-RoutingKey-Queue模型
- 优势:协议成熟、生态丰富、管理界面完善、延迟极低(微秒级)
- 劣势:吞吐量受限(万级TPS)、集群扩展复杂、Erlang学习曲线陡峭
- 适用:传统企业应用、需要复杂路由规则的场景
Apache Kafka
- 架构特点:分布式日志系统,Partition机制,ZooKeeper/KRaft协调
- 优势:吞吐量极高(百万级TPS)、水平扩展简单、生态完善(Connect/Streams)
- 劣势:延迟较高(毫秒级)、功能相对简单(无优先级队列)、运维复杂
- 适用:日志处理、实时流计算、事件溯源
Apache RocketMQ
- 架构特点:NameServer轻量级协调,Topic-Broker模型,兼顾Kafka与MQ优点
- 优势:延迟低(毫秒级)、支持事务消息、顺序消息、定时消息,Java生态友好
- 劣势:社区国际化程度不如Kafka、部分高级功能依赖商业版
- 适用:电商交易、金融支付、需要强一致性的场景
Apache Pulsar
- 架构特点:存算分离架构,BookKeeper存储,多租户设计
- 优势:无限扩展性、多机房复制、统一批流处理、云原生友好
- 劣势:成熟度相对较低、运维复杂度高、社区规模较小
- 适用:云原生部署、多租户SaaS、地理分布式应用
三、选型决策框架
3.1 选型维度矩阵
高吞吐量
↑
Kafka ◄─────┼────► Pulsar
简单运维 │ 复杂功能
低成本 │ 高成本
│
Redis ─────────┼──────── RocketMQ
Stream │ RabbitMQ
↓
低延迟3.2 决策树
- 是否需要极高吞吐量(>10万TPS)且允许一定延迟?
是 → Kafka(日志/流处理)或 Pulsar(云原生)
否 → 继续判断
- 是否需要事务消息/顺序消息/定时消息等企业级特性?
是 → RocketMQ(Java生态)或 RabbitMQ(多语言)
否 → 继续判断
- 是否已有Redis基础设施且需求简单?
是 → Redis Stream(轻量、低成本)
否 → RabbitMQ(通用、易上手)
- 是否云原生部署、多租户需求?
是 → Pulsar
3.3 场景化选型建议
| 业务场景 | 推荐方案 | 理由 |
|---|---|---|
| 电商订单系统 | RocketMQ | 事务消息保证扣减库存与创建订单一致性 |
| 日志收集分析 | Kafka | 高吞吐、与Flink/Spark生态无缝集成 |
| 实时通知推送 | RabbitMQ | 路由灵活、延迟极低、管理便捷 |
| IoT设备数据 | Pulsar | 海量Topic、地理分布式、多租户隔离 |
| 秒杀活动 | RocketMQ + Redis | 消息队列削峰 + Redis限流 |
| 微服务事件总线 | Kafka/RabbitMQ | 事件溯源架构、服务间解耦 |
四、关键概念辨析
4.1 消息模型对比
| 特性 | 点对点(Queue) | 发布订阅(Topic) |
|---|---|---|
| 消息消费 | 仅一个消费者获得 | 所有订阅者都获得 |
| 典型产品 | RabbitMQ Queue | Kafka Topic |
| 使用场景 | 任务分发、负载均衡 | 广播通知、事件驱动 |
4.2 消息可靠性保障
┌─────────────┐ ┌─────────────┐ ┌─────────────┐
│ 生产确认 │ → │ 持久化存储 │ → │ 消费确认 │
│ (Producer │ │ (Broker │ │ (Consumer │
│ Ack) │ │ Durability)│ │ Ack) │
└─────────────┘ └─────────────┘ └─────────────┘
│ │ │
└──────────────────┴────────────────┘
至少一次投递
(At Least Once)RocketMQ事务消息实现最终一致性:
- 发送半消息(Half Message)到Broker
- 执行本地事务(如扣减库存)
- 根据本地事务结果提交或回滚半消息
- 提供回查机制处理超时未决消息
五、最佳实践
5.1 避坑指南
| 反模式 | 正确做法 |
|---|---|
| 单Topic堆积百万消息 | 按业务拆分Topic,设置消费告警 |
| 消息体过大(>1MB) | 消息存引用,实际数据放对象存储 |
| 消费逻辑阻塞 | 异步消费、批量处理、限流保护 |
| 无消息轨迹 | 开启消息Key追踪,便于问题排查 |
| 忽视死信队列 | 配置DLQ处理异常消息,避免阻塞 |
5.2 云原生趋势
- Serverless化:AWS Lambda + SQS/EventBridge自动伸缩
- 标准化:CloudEvents规范统一事件格式
- Service Mesh集成:Sidecar模式(如Dapr)简化应用开发
- 存算分离:Pulsar架构成为新方向
总结
消息中间件是分布式系统的神经系统 ,选型没有绝对优劣,只有场景适配:
-
追求极致吞吐 → Kafka
-
追求企业级特性 → RocketMQ
-
追求灵活路由 → RabbitMQ
-
追求云原生未来 → Pulsar
理解业务需求本质,比追逐技术潮流更重要。