Causal Forcing:为高质量实时交互式视频生成正确实现的自回归扩散蒸馏
paper title:Causal Forcing: Autoregressive Diffusion Distillation Done Right for High-Quality Real-Time Interactive Video Generation
paper是THU发布在Arxiv 2026的工作
Code:链接
Abstract
为了实现实时交互式视频生成,当前方法通常将预训练的双向视频扩散模型蒸馏为少步自回归(AR)模型,而当全注意力被因果注意力替代时,这一过程中会面临架构上的鸿沟。然而,现有方法并未从理论上弥合这一差距。它们通过 ODE 蒸馏来初始化 AR 学生模型,而这要求满足帧级单射性,即在 AR 教师模型的 PF-ODE 下,每个带噪帧都必须映射到唯一的干净帧。若从双向教师蒸馏 AR 学生,则会违反这一条件,导致无法恢复教师的流映射,反而会诱导出一种条件期望解,从而使性能下降。为了解决这一问题,我们提出了 Causal Forcing,它使用 AR 教师进行 ODE 初始化,从而弥合了这种架构差距。实验结果表明,我们的方法在所有指标上都优于所有基线,在 Dynamic Degree 上相比当前最先进的 Self Forcing 提升了 19.3%,在 VisionReward 上提升了 8.7%,在 Instruction Following 上提升了 16.7%。
1. Introduction
近年来,自回归(AR)视频扩散模型取得了快速进展(Jin et al., 2024; Teng et al., 2025; Chen et al., 2025; Wu et al., 2025)。通过采用帧级自回归建模、并在每一帧内部进行扩散,AR 视频扩散支持了广泛的实时与交互式应用,包括世界建模(Mao et al., 2025; Sun et al., 2025a; Hong et al., 2025)、游戏模拟(Ball et al., 2025; Tang et al., 2025)、具身智能(Feng et al., 2025)以及交互式内容创作(Shin et al., 2025; Huang et al., 2025b; Ki et al., 2026; Xiao et al., 2025)。尽管前景广阔,多步扩散采样带来的计算负担仍然严重限制了其实时能力。为缓解这一延迟瓶颈,近期工作(Huang et al., 2025a; Yin et al., 2025)将一个强大的预训练双向视频扩散模型蒸馏为一个少步自回归学生模型。这通常通过一个两阶段流程实现:首先进行 ODE 蒸馏以初始化 AR 学生模型,随后使用 DMD(Yin et al., 2024)进一步提升性能。
然而,与标准的步数蒸馏相比,这种 AR 蒸馏除了共享的采样步数差距之外,还面临一个更根本的挑战,即架构差距。这个差距来源于将一个能够访问未来帧的双向模型,转换为一个仅依赖过去上下文进行条件建模的因果架构。经验上我们发现,即使从同一个双向教师模型蒸馏,当前最先进的 AR 蒸馏方法(Huang et al., 2025a)相较于标准 DMD 仍然存在显著差距,而后者蒸馏的是一个双向学生模型(见图 1)。在本文中,我们表明,这种性能下降源于现有方法在理论上未能正确处理这一架构差距(见图 3 和第 3.2 节)。

图 1. 现有方法的局限性。尽管都是从同一个双向基础模型进行蒸馏,像 Self-Forcing 这样的最先进自回归扩散蒸馏方法,性能仍然显著落后于标准 DMD,而后者蒸馏的是一个双向学生模型。
通过一个受控实验,我们首先表明,这一差距无法通过 DMD 阶段来弥补,而应当在之前的 ODE 初始化阶段加以解决。关键在于,ODE 蒸馏的一个核心要求是单射性(Liu et al., 2022)。在将双向教师蒸馏为双向学生的标准 ODE 蒸馏中,单射性在视频层面天然成立。相比之下,对于 AR 学生模型,单射性必须在帧层面成立:每一个带噪帧都必须在 AR 教师模型的 PF-ODE 下映射到唯一的干净帧。我们将这一要求称为帧级单射性。然而,现有方法(Huang et al., 2025a; Yin et al., 2025)直接从双向教师蒸馏 AR 学生模型,这使得同一个带噪帧可能对应多个不同的干净帧。对帧级单射性的这种违反,会导致生成的视频出现模糊和不一致。
基于上述分析,我们提出了 Causal Forcing,它通过使用 AR 教师进行 ODE 蒸馏初始化来弥合这种架构差距(见第 3.3 节)。我们首先使用 teacher forcing 训练一个 AR 扩散模型,并表明无论从理论上还是经验上看,diffusion forcing 都不如 teacher forcing 适合 AR 扩散训练。随后,以该 AR 扩散模型为教师,我们通过采样其 PF-ODE 轨迹来执行因果 ODE 蒸馏,并据此训练 AR 学生模型。关键在于,由于教师模型是自回归的而非双向的,其 PF-ODE 自然满足帧级单射性,从而使学生模型能够准确学习流映射。最后,遵循 Self Forcing 的做法,我们再施加后续的 DMD 阶段,以获得一个少步 AR 学生模型,从而实现高效的实时视频生成。
为了验证我们的方法,我们针对多种基线模型进行了全面评估(Wan et al., 2025; Ha-Cohen et al., 2024; Deng et al., 2024; Jin et al., 2024; Chen et al., 2025; Teng et al., 2025; Yin et al., 2025; Huang et al., 2025a)。实验表明,我们的方法在所有指标上都稳定优于所有基线模型,并在动态程度、视觉质量和指令跟随能力方面取得了显著提升。值得注意的是,在与现有蒸馏式自回归视频模型相同的训练预算下,我们的方法在保持相同推理延迟的同时,Dynamic Degree(Huang et al., 2024)相比当前最先进的 Self-Forcing(Huang et al., 2025a)提升了 19.3%,VisionReward(Xu et al., 2024)提升了 8.7%,Instruction Following 提升了 16.7%,这证明了我们方法的有效性。
2. Background
2.1. Diffusion Models
扩散模型(Ho et al., 2020; Song et al., 2020)通过一个前向扩散过程,逐步扰动数据 x 0 ∼ p data ( x 0 ) x_0 \sim p_{\text{data}}(x_0) x0∼pdata(x0),以学习其分布。该过程遵循如下转移核 q t ∣ 0 ( x t ∣ x 0 ) q_{t|0}(x_t|x_0) qt∣0(xt∣x0):
x t = α t x 0 + σ t ϵ , ϵ ∼ N ( 0 , I ) , t ∈ 0 , T , x_t = \alpha_t x_0 + \sigma_t \epsilon,\quad \epsilon \sim \mathcal{N}(0, I),\quad t \in 0, T, xt=αtx0+σtϵ,ϵ∼N(0,I),t∈0,T,
其中 α t , σ t \alpha_t,\sigma_t αt,σt 是预定义的噪声调度。为了匹配数据分布,模型可以在多种参数化方式下进行训练(Ho et al., 2020; Kingma & Gao, 2023; Salimans & Ho, 2022)。一种典型的参数化方式是流匹配(Lipman et al., 2022),它使用速度预测。模型 v θ v_\theta vθ 通过最小化加权均方误差进行训练:
E x 0 , ϵ , t w ( t ) ∥ v θ ( x t , t ) − v t ∥ 2 . \mathbb{E}_{x_0,\epsilon,t}\bigw(t)\\\|v_\\theta(x_t, t)-v_t\\\|\^2\\big. Ex0,ϵ,tw(t)∥vθ(xt,t)−vt∥2.
在一种典型的噪声调度(Liu et al., 2022)下,取 α t = 1 − t , σ t = t , T = 1 \alpha_t = 1 - t,\ \sigma_t = t,\ T = 1 αt=1−t, σt=t, T=1,此时 v t v_t vt 定义为
v t : = d x t d t = ϵ − x 0 . v_t := \frac{dx_t}{dt} = \epsilon - x_0. vt:=dtdxt=ϵ−x0.
此时,可以通过求解概率流常微分方程(PF-ODE)(Song et al., 2020)来进行采样:
d x t = v θ ( x t , t ) d t , x T ∼ N ( 0 , I ) , t : T → 0. dx_t = v_\theta(x_t, t)\,dt,\qquad x_T \sim \mathcal{N}(0, I),\qquad t: T \to 0. dxt=vθ(xt,t)dt,xT∼N(0,I),t:T→0.
2.2. Autoregressive Video Diffusion Models
尽管全序列扩散模型在视频生成方面取得了成功(Yang et al., 2024; Kong et al., 2024),但它们会一次性生成所有帧,因此无法支持用户交互。相比之下,自回归(AR)视频扩散模型按顺序逐帧生成,旨在通过如下自回归分解来建模一个包含 N N N 帧视频的分布:
p θ ( x 0 1 : N ) = ∏ i = 1 N p θ ( x 0 i ∣ x 0 < i ) , p_\theta(x_0^{1:N}) = \prod_{i=1}^{N} p_\theta(x_0^i \mid x_0^{< i}), pθ(x01:N)=i=1∏Npθ(x0i∣x0<i),
其中每个条件分布 p θ ( x 0 i ∣ x 0 < i ) p_\theta(x_0^i \mid x_0^{< i}) pθ(x0i∣x0<i) 都由标准扩散模型来建模。这一机制使用户能够基于已经生成的内容来引导后续帧,从而实现交互性,Google 的 Genie 3(Ball et al., 2025)就是一个例子。
为了实现这一点,通常可以采用两种训练策略,即 teacher forcing(TF)(Jin et al., 2024)和 diffusion forcing(DF)(Chen et al., 2024; Song et al., 2025)。TF 的目标是在干净的历史帧前缀 x 0 < i x_0^{< i} x0<i 条件下学习 p data ( x 0 i ∣ x 0 < i ) p_{\text{data}}(x_0^i \mid x_0^{< i}) pdata(x0i∣x0<i)。为了在实践中实现这种训练范式,一个常用策略(Teng et al., 2025)是将干净视频与其带噪版本拼接起来,并施加因果注意力掩码,使得 x t i x_t^i xti 能够关注 x 0 < i x_0^{< i} x0<i。相比之下,DF 建模的是噪声条件分布
p DF ( x 0 i ∣ x t < i ) , p_{\text{DF}}(x_0^i \mid x_t^{< i}), pDF(x0i∣xt<i),
其中噪声通过 q t ∣ 0 ( x t < i ∣ x 0 < i ) q_{t|0}(x_t^{< i} \mid x_0^{< i}) qt∣0(xt<i∣x0<i) 独立地加到每一帧上。不同于 TF 中输入干净前缀,DF 让 x t i x_t^i xti 直接关注带噪前缀 x t < i x_t^{< i} xt<i。更多相关工作见附录 A。
2.3. Consistency Distillation and ODE Distillation
为了实现实时生成,多步扩散模型通常会被蒸馏为少步模型。一种典型的方法是 Consistency Distillation(CD)(Song et al., 2023; Song & Dhariwal, 2023)。其核心思想是学习一个流映射
G θ : ( x t , t ) ↦ x 0 G_\theta : (x_t, t) \mapsto x_0 Gθ:(xt,t)↦x0
将 x t x_t xt 映射到教师扩散模型 PF-ODE 的干净终点 x 0 x_0 x0。在边界条件
G θ ( x , 0 ) ≡ x G_\theta(x, 0) \equiv x Gθ(x,0)≡x
下,模型 G θ G_\theta Gθ 可通过最小化下式进行训练:
E x 0 , ϵ , t w ( t ) d ( G θ ( x t , t ) , G θ − ( x \^ t − Δ t , t − Δ t ) ) , \mathbb{E}_{x_0,\epsilon,t}\bigw(t)\\, d\\big(G_\\theta(x_t, t),\\, G_{\\theta\^-}(\\hat{x}_{t-\\Delta t}, t-\\Delta t)\\big)\\big, Ex0,ϵ,tw(t)d(Gθ(xt,t),Gθ−(x\^t−Δt,t−Δt)),
其中, x t x_t xt 由前向扩散过程得到, x ^ t − Δ t \hat{x}_{t-\Delta t} x^t−Δt 是利用教师扩散模型从 x t x_t xt 求解一步 ODE 得到的, θ − \theta^- θ− 是 θ \theta θ 的滑动平均并停止梯度, d ( ⋅ , ⋅ ) d(\cdot,\cdot) d(⋅,⋅) 是在选定范数下定义的距离。近期工作(Lu & Song, 2024; Geng et al., 2025; Zheng et al., 2025)进一步改进了该方法。
近期关于实时交互式视频生成的工作(Yin et al., 2025; Huang et al., 2025a)采用了 CD 的一个简化变体,它通过直接回归来训练学生模型 G θ G_\theta Gθ:
θ ∗ = min θ E t , x t ∥ G θ ( x t , t ) − x 0 ∥ 2 , \theta^* = \min_\theta \mathbb{E}_{t,x_t}\big\\\|G_\\theta(x_t,t)-x_0\\\|\^2\\big, θ∗=θminEt,xt∥Gθ(xt,t)−x0∥2,
其中 x t x_t xt 和 x 0 x_0 x0 位于教师模型同一条 PF-ODE 轨迹上。下文中我们将这种方法称为 ODE distillation。
2.4. Score Distillation
得分蒸馏(Score distillation)(Wang et al., 2023; Luo et al., 2023b)通过让学生模型的生成分布 p θ ( x ~ ) p_\theta(\tilde{x}) pθ(x~) 与数据分布匹配,将一个多步扩散模型蒸馏为少步学生模型。一种常用的具体实现是分布匹配蒸馏(Distribution Matching Distillation, DMD)(Yin et al., 2024),它通过沿着如下梯度下降,最小化学生分布与数据分布之间的 KL 散度:
∇ θ E t D K L ( p θ , t ∥ p d a t a , t ) = − E x ~ , t , x ~ t ( s r e a l ( x \~ t , t ) − s f a k e ( x \~ t , t ) ) ∂ x \~ ∂ θ , \nabla_\theta \mathbb{E}t\bigD_{\\mathrm{KL}}(p_{\\theta,t}\\\|p_{\\mathrm{data},t})\\big= -\mathbb{E}{\tilde{x},t,\tilde{x}_t}\left\\left(s_{\\mathrm{real}}(\\tilde{x}_t,t)-s_{\\mathrm{fake}}(\\tilde{x}_t,t)\\right)\\frac{\\partial \\tilde{x}}{\\partial \\theta}\\right, ∇θEtDKL(pθ,t∥pdata,t)=−Ex~,t,x~t(sreal(x\~t,t)−sfake(x\~t,t))∂θ∂x\~,
其中, x ~ ∼ p θ ( x ~ ) \tilde{x} \sim p_\theta(\tilde{x}) x~∼pθ(x~) 是由学生模型生成的样本,而 x ~ t ∼ q t ∣ 0 ( x ~ t ∣ x ~ ) \tilde{x}t \sim q{t|0}(\tilde{x}t \mid \tilde{x}) x~t∼qt∣0(x~t∣x~) 是 x ~ \tilde{x} x~ 的带噪版本,它诱导出分布 p θ , t ( x ~ t ) p{\theta,t}(\tilde{x}t) pθ,t(x~t)。这里,一个冻结的扩散模型 s r e a l s{\mathrm{real}} sreal 用于预测在带噪数据分布 p d a t a , t ( x ~ t ) p_{\mathrm{data},t}(\tilde{x}t) pdata,t(x~t) 下 x ~ t \tilde{x}t x~t 的 score,而一个在线可训练的扩散模型 s f a k e s{\mathrm{fake}} sfake 则用于预测在 p θ , t ( x ~ t ) p{\theta,t}(\tilde{x}_t) pθ,t(x~t) 下的 score。
3. Method
3.1. Limitations of Existing Methods
如第 2.2 节所述,实时交互式视频生成需要一个少步自回归生成器。当前最广泛使用的策略,以 CausVid(Yin et al., 2025)和 Self Forcing(Huang et al., 2025a)为代表,采用的是非对称蒸馏:给定一个预训练的双向视频扩散模型,将其蒸馏为一个少步自回归学生生成器。与标准的步数蒸馏相比,除了共同存在的采样步数差距,即将多步采样压缩为少步采样之外,更根本的挑战在于架构差距:需要将一个采用全注意力的双向模型(Peebles & Xie, 2023)转换为一种因果注意力架构,而后者只能基于过去的上下文进行条件建模,无法访问未来帧。
尽管当前自回归视频扩散蒸馏领域最先进的方法 Self Forcing(Huang et al., 2025a)已经取得了较强的性能,它仍然落后于标准 DMD,后者是从双向视频扩散模型蒸馏出一个少步双向学生模型。如图 1 所示,在视觉质量、动态程度和指令跟随能力方面,Self Forcing 明显逊于标准 DMD(Yin et al., 2024)。这一差距表明,现有的自回归扩散蒸馏流程仍然不是最优的,这也促使我们进一步研究其根本原因,并探索更有效的策略。
3.2. Analysis: Suboptimality of Existing Methods
在本节中,我们分析现有方法中观察到的性能下降原因,并识别出解决这一问题所需的关键原则。
我们首先回顾当前最先进方法 Self Forcing(Huang et al., 2025a)的流程,它采用两阶段蒸馏策略。给定一个双向扩散模型,它首先应用 ODE 蒸馏来弥合架构差距并实现少步采样。具体而言,双向模型沿其 PF-ODE 轨迹进行采样,而目标自回归模型 G θ G_\theta Gθ 学习将带噪中间状态映射到干净视频。其训练目标为
θ ∗ = min θ E t , x t 1 : N , i ∥ G θ ( x t i , x t \< i , t ) − x 0 i ∥ 2 , \theta^*=\min_\theta \mathbb{E}_{t,x_t^{1:N},i}\left\\\|G_\\theta(x_t\^i,x_t\^{ \< i},t)-x_0\^i\\\|\^2\\right, θ∗=θminEt,xt1:N,i∥Gθ(xti,xt\
其中 i ∼ U ( 1 , N ) i\sim \mathcal{U}(1,N) i∼U(1,N), ( x t 1 : N , x 0 1 : N ) (x_t^{1:N},x_0^{1:N}) (xt1:N,x01:N) 位于双向教师模型的同一条 PF-ODE 轨迹上,且 t ∈ S t\in \mathcal{S} t∈S 表示用于采样的预定义时间步集合。在这一 ODE 蒸馏阶段的基础上,它随后进一步应用非对称 DMD,使用所得模型来初始化自回归学生模型,并将双向基础模型作为教师。在下文中,我们将考察每个阶段如何有助于弥合架构差距,以及它在理论上是否真正与这一目标一致。
Self Forcing 中的 DMD 阶段并不能解决架构差距。我们首先考察 DMD 阶段是否能够弥合这一架构差距。我们使用一个通过标准 DMD 蒸馏得到的少步双向模型来初始化自回归学生模型,这样就消除了采样步数差距,而只保留架构差距。如图 2 所示,尽管消除了采样步数差距,其性能仍然显著差于标准 DMD。这说明,初始化时存在的巨大架构差距,无法通过后续的 DMD 阶段来弥补。因此,在 Self Forcing 的两阶段设计中,真正被寄予弥合架构差距希望的是 ODE 蒸馏阶段。接下来我们分析其理论合理性。

图 2. DMD 无法弥合架构差距。使用标准 DMD 初始化自回归学生模型后,采样步数差距被消除,只保留了架构差距,但其性能仍然不如标准 DMD。这表明,架构差距无法在 DMD 阶段得到解决,而应当在此前的 ODE 初始化阶段加以处理。
帧级单射性是 ODE 初始化所必需的原则。我们首先识别 ODE 蒸馏必须满足的必要条件。为了使基于回归 MSE 损失的 ODE 蒸馏具有良定义性,成对数据必须是单射的(Liu et al., 2022),这意味着在任意时间步,每个带噪样本都对应样本空间中唯一的一个干净样本。在将双向教师蒸馏为双向学生的设定中,由于扩散 PF-ODE 的单射性,这种单射性在视频层面天然成立。形式化地说,对于任意带噪视频 x t 1 : N x_t^{1:N} xt1:N,在样本空间中都存在唯一的干净视频 x 0 1 : N x_0^{1:N} x01:N,使得
x 0 1 : N = ϕ B i ( x t 1 : N , t ) , x_0^{1:N}=\phi^{\mathrm{Bi}}(x_t^{1:N},t), x01:N=ϕBi(xt1:N,t),
其中 ϕ B i : ( x t 1 : N , t ) ↦ x 0 1 : N \phi^{\mathrm{Bi}}:(x_t^{1:N},t)\mapsto x_0^{1:N} ϕBi:(xt1:N,t)↦x01:N 表示双向模型的 PF-ODE 流映射(见图 3a),而这恰恰也是学生模型要去拟合的对象。
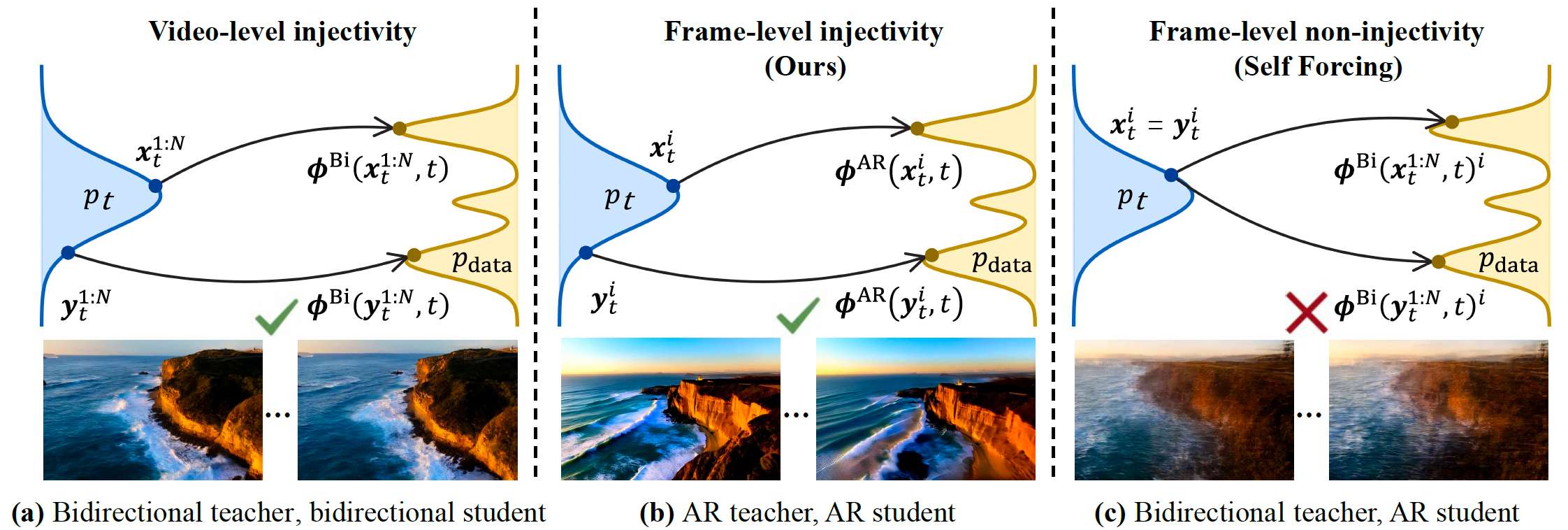
图 3. ODE 初始化所需的必要原则,以及为什么 Self Forcing 存在缺陷。ODE 蒸馏要求配对数据具有单射性。(a) 标准 ODE 蒸馏将双向教师蒸馏为双向学生,在视频层面满足这一要求。
(b) 对于 AR 学生模型,单射性必须在帧层面成立:每个带噪帧都通过 AR 教师的 PF-ODE 映射到唯一的干净帧。© 相比之下,Self Forcing 是从双向教师蒸馏 AR 学生模型,此时同一个带噪帧会对应多个不同的干净帧,违反了帧级单射性,并在 ODE 蒸馏后导致视频模糊。详见第 3.2 节。
然而,在自回归视频模型中,帧是按顺序逐帧生成的。这使得单射性要求从整个视频 x 0 1 : N x_0^{1:N} x01:N 转移到了每个单独的帧 x 0 i , i ∈ { 1 , ... , N } x_0^i,\ i\in\{1,\ldots,N\} x0i, i∈{1,...,N} 上。具体来说,对于任意带噪帧 x t i x_t^i xti,在样本空间中都必须存在唯一对应的干净帧 x 0 i x_0^i x0i,使得
x 0 i = ϕ A R ( x t i , t ) , x_0^i=\phi^{\mathrm{AR}}(x_t^i,t), x0i=ϕAR(xti,t),
其中 ϕ A R : ( x t i , t ) ↦ x 0 i \phi^{\mathrm{AR}}:(x_t^i,t)\mapsto x_0^i ϕAR:(xti,t)↦x0i 表示自回归扩散模型的 PF-ODE 流映射,也就是学生模型所学习的对象(见图 3b)。我们在下文中将这一要求形式化。
定义 3.1(帧级单射性)。对于映射
ϕ A R : ( x t i , t ) ↦ x 0 i , \phi^{\mathrm{AR}} : (x_t^i, t) \mapsto x_0^i, ϕAR:(xti,t)↦x0i,
若对任意 t ∈ ( 0 , 1 ] t \in (0,1] t∈(0,1],以及任意两个带噪视频 { x t j } j = 1 N , { y t j } j = 1 N \{x_t^j\}{j=1}^N,\{y_t^j\}{j=1}^N {xtj}j=1N,{ytj}j=1N,都有
∀ i ∈ N , x t i = y t i ⇒ ϕ A R ( x t i , t ) = ϕ A R ( y t i , t ) , \forall i \in N,\ x_t^i = y_t^i \Rightarrow \phi^{\mathrm{AR}}(x_t^i,t)=\phi^{\mathrm{AR}}(y_t^i,t), ∀i∈N, xti=yti⇒ϕAR(xti,t)=ϕAR(yti,t),
则称帧级单射性成立。也就是说, ϕ A R ( x t i , t ) \phi^{\mathrm{AR}}(x_t^i,t) ϕAR(xti,t) 是一个良定义函数,它将 x t i x_t^i xti 映射到第 i i i 个干净帧。
如果式 (4) 中的条件被违反,那么回归式学生模型将无法恢复教师模型的流映射,而是会坍缩到条件期望(Bishop & Nasrabadi, 2006):
G θ ∗ ( x t i , x t < i , t ) = E x 0 ∣ x t i , x t \< i , t . G_\theta^*(x_t^i,x_t^{< i},t)=\mathbb{E}x_0 \\mid x_t\^i,x_t\^{\< i},t. Gθ∗(xti,xt<i,t)=Ex0∣xti,xt\
直观上,学习条件均值会在多个帧之间进行平均,从而表现为模糊的视觉结果。
Self Forcing 中当前的 ODE 初始化违反了帧级单射性。Self Forcing 中当前的 ODE 蒸馏使用一个双向教师模型去蒸馏一个自回归学生模型。我们表明,这种设计违反了式 (4) 中的帧级单射性条件,从根本上使蒸馏存在缺陷。
如上所述,由双向模型诱导的 PF-ODE 轨迹仅在视频层面是单射的,而在帧层面并非如此。我们从理论上证明,这会导致同一个带噪帧 x t i x_t^i xti 以不可忽略的概率对应多个不同的干净帧(见图 3c 和引理 3.2)。形式化地说,对于固定时间步 t t t,在配对数据样本空间中,存在 x t i = y t i x_t^i = y_t^i xti=yti 但 x 0 i ≠ y 0 i x_0^i \ne y_0^i x0i=y0i 的情况,并且这种碰撞发生在一个非零测度的集合上。因此,式 (4) 中的帧级单射性条件会以不可忽略的概率被违反。这表明,Self Forcing 的 ODE 蒸馏------即从双向教师训练一个自回归学生------在理论上是不对齐的。我们在下面的引理中形式化这一问题:
引理 3.2(PF-ODE 的帧级非单射性,非正式表述)。设 x t 1 : N x_t^{1:N} xt1:N 满足双向扩散模型中式 (1) 的 PF-ODE。记 x t i x_t^i xti 为其第 i i i 帧,并令
x t o t h e r : = x t N ∖ { i } x_t^{\mathrm{other}} := x_t^{N\setminus\{i\}} xtother:=xtN∖{i}
表示其余帧。定义流映射
ϕ B i : ( x t 1 : N , t ) ↦ x 0 1 : N . \phi^{\mathrm{Bi}} : (x_t^{1:N}, t) \mapsto x_0^{1:N}. ϕBi:(xt1:N,t)↦x01:N.
如果 ϕ B i ( x t 1 : N , t ) i \phi^{\mathrm{Bi}}(x_t^{1:N}, t)^i ϕBi(xt1:N,t)i 关于 x t o t h e r x_t^{\mathrm{other}} xtother 并非几乎处处为常数,那么
∀ t ∈ ( 0 , 1 ] , ∀ x t 1 : N ∈ R d , ∃ y t 1 : N ∈ R d , s.t. y t i = x t i , and ϕ B i ( x t 1 : N , t ) i ≠ ϕ B i ( y t 1 : N , t ) i . \forall t \in (0,1],\ \forall x_t^{1:N} \in \mathbb{R}^d,\ \exists y_t^{1:N} \in \mathbb{R}^d,\ \text{s.t.}\ y_t^i = x_t^i,\ \text{and}\ \phi^{\mathrm{Bi}}(x_t^{1:N}, t)^i \ne \phi^{\mathrm{Bi}}(y_t^{1:N}, t)^i. ∀t∈(0,1], ∀xt1:N∈Rd, ∃yt1:N∈Rd, s.t. yti=xti, and ϕBi(xt1:N,t)i=ϕBi(yt1:N,t)i.
此外,
P ( V a r ( ϕ B i ( x t 1 : N , t ) i ∣ x t i , t ) > 0 ) > 0. \mathbb{P}\big(\mathrm{Var}(\phi^{\mathrm{Bi}}(x_t^{1:N}, t)^i \mid x_t^i,t) > 0\big) > 0. P(Var(ϕBi(xt1:N,t)i∣xti,t)>0)>0.
严格的形式化定义与证明见附录 B.1。
这意味着 ϕ B i ( ⋅ , ⋅ ) i \phi^{\mathrm{Bi}}(\cdot,\cdot)^i ϕBi(⋅,⋅)i 不是一个良定义函数。这个问题的一个关键直觉在于:双向扩散模型在对第 i i i 帧去噪时会使用所有帧的信息。因此,即使固定了 x t i x_t^i xti,不同的 x t > i x_t^{>i} xt>i 仍可能导致不同的 x 0 i x_0^i x0i。而在 Self Forcing 中,自回归学生模型在没有 x t > i x_t^{>i} xt>i 的情况下接受监督,这会造成信息丢失,从而违反式 (4)。
与式 (5) 中识别出的问题类似,这种帧级非单射性会阻止自回归学生模型恢复教师模型的真实流映射:
命题 3.3(当前 Self Forcing 的 ODE 蒸馏中的分布失配,证明见附录 B.1)。沿用引理 3.2 的记号,考虑使用如下 MSE 回归目标训练一个因果逐帧模型
G θ : ( x t i , t ) ↦ x 0 i G_\theta : (x_t^i,t) \mapsto x_0^i Gθ:(xti,t)↦x0i
(为简洁起见,我们省略条件 x t < i x_t^{< i} xt<i):
θ ∗ = min θ E x t 1 : N , t ∥ G θ ( x t i , t ) − x 0 i ∥ 2 , \theta^*=\min_\theta \mathbb{E}_{x_t^{1:N},t}\left\\\|G_\\theta(x_t\^i,t)-x_0\^i\\\|\^2\\right, θ∗=θminExt1:N,t∥Gθ(xti,t)−x0i∥2,
其中 ( x t 1 : N , x 0 1 : N ) (x_t^{1:N},x_0^{1:N}) (xt1:N,x01:N) 是来自双向扩散模型 PF-ODE 的配对数据。那么其最优解并不遵循数据分布,即
G θ ∗ ( x t i , t ) = E x 0 i ∣ x t i , t ≁ p d a t a ( x 0 i ) . G_\theta^*(x_t^i,t)=\mathbb{E}x_0\^i \\mid x_t\^i,t \not\sim p_{\mathrm{data}}(x_0^i). Gθ∗(xti,t)=Ex0i∣xti,t∼pdata(x0i).
如图 3c 所示,这会导致视频模糊,并且明显劣于图 3a 中使用双向学生模型的标准 ODE 蒸馏。
3.3. Causal Forcing
基于上述分析,要弥合这种架构差距,就要求 ODE 蒸馏满足式 (4) 中的帧级单射性条件,而这进一步要求使用一个自回归扩散模型作为教师。因此,我们提出 Causal Forcing,这是一种三阶段方法,依次由 teacher forcing 自回归扩散训练、因果 ODE 蒸馏以及非对称 DMD 组成。
自回归扩散训练。我们首先重新审视 AR 扩散模型的两种标准训练范式,即 teacher forcing(TF)和 diffusion forcing(DF)(见第 2.2 节),以获得作为后续 ODE 蒸馏教师的 AR 扩散模型。颇为出人意料且不同于常见看法的是,我们发现,无论在理论上还是经验上,teacher forcing 都比 diffusion forcing 更适合训练 AR 扩散模型。具体来说,在训练第 i i i 帧 x t i x_t^i xti 时,diffusion forcing 以强噪声污染的前序帧 x t < i x_t^{<i} xt<i 为条件,而推理时则以前序干净帧 x 0 < i x_0^{<i} x0<i 为条件。这种差异会引入显著的训练---推理分布失配。我们在下面的命题中形式化这一问题。
命题 3.4(自回归 diffusion forcing 中的分布失配)。在第 2.2 节的记号和附录 B.2 的正则条件下:
E y ∼ p d a t a ( x 0 < i ) D K L ( p D F ( x 0 i ∣ y ) ∥ p d a t a ( x 0 i ∣ y ) ) > 0. \mathbb{E}{y\sim p{\mathrm{data}}(x_0^{< i})}\leftD_{\\mathrm{KL}}\\big(p_{\\mathrm{DF}}(x_0\^i\\mid y)\\,\\\|\\,p_{\\mathrm{data}}(x_0\^i\\mid y)\\big)\\right > 0. Ey∼pdata(x0<i)DKL(pDF(x0i∣y)∥pdata(x0i∣y))>0.
也就是说,使用自回归 diffusion forcing 训练得到的模型,并不服从以因果前缀 y y y 为条件的数据分布。证明见附录 B.2。
相比之下,teacher forcing 在训练时以前序干净帧 x 0 < i x_0^{< i} x0<i 为条件,从而使训练目标与推理过程对齐,并消除了这一差距。图 4 中的经验比较进一步印证了这一理论分析。关于 diffusion forcing 及其近期替代方法(Wu et al., 2025; Po et al., 2025; Guo et al., 2025)的进一步讨论,见附录 C.1。因此,我们采用一个通过 teacher forcing 训练得到的自回归扩散模型。尽管这已经为非对称 DMD 提供了显著更好的初始化,但仍然会出现突兀伪影(见附录 C.2)。

图 4. AR 扩散训练中的 TF 与 DF 对比。与普遍看法相反,DF 由于训练---推理差距会导致视频坍塌,而 TF 则能够产生更高的视觉质量。
因果 ODE 蒸馏。以上述 AR 扩散模型为教师,我们接下来执行因果 ODE 蒸馏。首先,我们需要在所需时间步集合 S \mathcal{S} S 上,从 AR 扩散教师中采样并存储 PF-ODE 轨迹 { x t i } t ∈ S ∪ { 0 } \{x_t^i\}{t\in \mathcal{S}\cup\{0\}} {xti}t∈S∪{0}。为此,我们从真实数据集中采样前序干净帧 x g t < i x{\mathrm{gt}}^{< i} xgt<i,并以这些帧作为历史条件,使用教师模型和 ODE 求解器从高斯噪声
x T i ∼ N ( 0 , I ) x_T^i \sim \mathcal{N}(0,I) xTi∼N(0,I)
开始生成当前帧。随后,学生模型 G θ G_\theta Gθ 在相同历史干净帧 x g t < i x_{\mathrm{gt}}^{< i} xgt<i 的条件下,从中间带噪状态 x t i x_t^i xti 回归干净目标 x 0 i x_0^i x0i:
θ ∗ = min θ E x g t < i , t ∈ S , i ∥ G θ ( x t i , x g t \< i , t ) − x 0 i ∥ 2 . \theta^*=\min_\theta \mathbb{E}{x{\mathrm{gt}}^{< i},\, t\in \mathcal{S},\, i}\left\\\|G_\\theta(x_t\^i,x_{\\mathrm{gt}}\^{\< i},t)-x_0\^i\\\|\^2\\right. θ∗=θminExgt<i,t∈S,i∥Gθ(xti,xgt\
值得注意的是,由于这里的教师是自回归的而非双向的,它的 PF-ODE 天然满足式 (4) 中的帧级单射性条件。因此,我们的方法避免了命题 3.3 中所指出的坍缩现象,并使学生模型能够准确学习流映射。如图 3b 所示,使用这样的 AR 教师进行 ODE 蒸馏,确实能够获得很强的性能。
非对称 DMD。在上述针对 AR 学生的因果 ODE 初始化基础上,我们按照 Self Forcing 的做法执行非对称 DMD。如图 5 所示,结合我们的因果 ODE 初始化后,DMD 得到的最终模型显著优于 Self Forcing,这表明架构差距得到了有效解决。

图 5. Self Forcing(SF)与我们方法的性能比较。使用 Self Forcing 的 ODE 初始化时,DMD 表现出较弱的动态性并伴有伪影;而采用因果 ODE 初始化后,它能够实现更强的动态性和更高的视觉保真度。
3.4. Extension to Causal Consistency Models
除了上文提到的得分蒸馏范式之外,由于 ODE 蒸馏可以被视为一致性蒸馏(CD)的一种简化形式,我们的视角也自然可以扩展到 CD。在本节中,我们提出了首个因果 CD 框架,并进一步表明,它优于使用双向模型作为教师的非对称 CD。
具体来说,我们使用前述原生自回归扩散模型作为教师,并通过 teacher forcing 按如下方式训练因果一致性模型 G θ G_\theta Gθ:
θ ∗ = min θ E x g t , ϵ , t , i w ( t ) d ( G θ ( x t i , x g t \< i , t ) , G θ − ( x \^ t − Δ t i , x g t \< i , t − Δ t ) ) , \theta^*=\min_\theta \mathbb{E}{x{\mathrm{gt}},\epsilon,t,i}\Bigw(t)\\, d\\big(G_\\theta(x_t\^i,x_{\\mathrm{gt}}\^{\< i},t),\\ G_{\\theta\^-}(\\hat{x}_{t-\\Delta t}\^i,x_{\\mathrm{gt}}\^{\< i},t-\\Delta t)\\big)\\Big, θ∗=θminExgt,ϵ,t,iw(t)d(Gθ(xti,xgt\
其中 x ^ t − Δ t i \hat{x}{t-\Delta t}^i x^t−Δti 是在干净前缀 x g t < i x{\mathrm{gt}}^{< i} xgt<i 条件下,使用自回归教师模型从 x t i x_t^i xti 通过求解 ODE 得到的,其他记号与第 2.3 节保持一致。与第 3.3 节一致,这种方法利用了原生 AR 教师在帧级上的单射性,使学生模型能够学习正确的流映射。相比之下,非对称 CD 的教师会像引理 3.2 所述那样违反这种单射性,从而导致坍塌。如附录 D 的图 10 所示,我们的因果 CD 显著优于非对称 CD。
这种因果 CD 也可以作为因果 ODE 蒸馏的替代方案,为 DMD 阶段提供一个强有力的初始化。它的关键优势在于无需大规模生成 ODE 配对数据,从而节省时间和存储。然而,我们发现,以这种方式初始化的 DMD,其最终性能与 ODE 初始化相近;因此,在后续内容中我们仍然采用 ODE 初始化。
4. Experiments
4.1. Setup
实现细节。遵循 Self Forcing(Huang et al., 2025a),我们采用 Wan2.1-T2V-1.3B(Wan et al., 2025)作为微调的基础模型,该模型能够生成分辨率为 832 × 480 的 81 帧视频。我们首先在一个由基础双向模型合成的 3K 数据集 D B i \mathcal{D}{\mathrm{Bi}} DBi 上,使用 teacher forcing 训练一个自回归扩散模型,共进行 2K 步。在构建 D B i \mathcal{D}{\mathrm{Bi}} DBi 时,我们也为用于消融实验的基线 ODE 蒸馏存储带噪中间状态。随后,我们使用该自回归扩散模型作为教师,采样 3K 条因果 ODE 轨迹 D C a u s a l \mathcal{D}_{\mathrm{Causal}} DCausal,并进行 1K 步的因果 ODE 蒸馏。所得模型用于初始化非对称 DMD,并在 VidProM(Wang & Yang, 2024)上按照与 Self Forcing 相同的协议训练 750 步直至收敛。遵循 Self Forcing,我们以分块方式实现所有方法,其中每个块包含 3 个潜在帧。在后续消融实验部分的因果 CD 中,我们采用 LCM(Luo et al., 2023a)设置。更多细节见附录 D。
评估。我们遵循 Self Forcing,采用 VBench(Huang et al., 2024)作为主要评估基准。对于整体视觉评估,我们使用 VisionReward(Xu et al., 2024),该指标与人类判断具有良好的相关性;此外,我们还报告 VisionReward 的 Instruction Following 子分数,以衡量指令遵循能力。需要注意的是,VisionReward 分数可以为负,但数值越高始终越好。由于许多 VBench 提示涉及的运动较少,我们进一步整理了一个包含 100 个提示的集合,这些提示具有丰富运动和复杂动作,并在补充材料中给出。我们在这个 100 提示集合上评估 VisionReward、Instruction Following 和 Dynamic Degree。为便于阅读,所有这些指标都乘以 100 进行缩放。此外,我们还进行了用户研究,邀请 10 名参与者在 10 个提示上,对所有方法的整体视频质量进行排序。最后,为评估实时能力,我们在单张 H100 GPU 上分别以 FPS 和秒为单位报告吞吐量和延迟。更多细节见附录 D。
4.2. Results
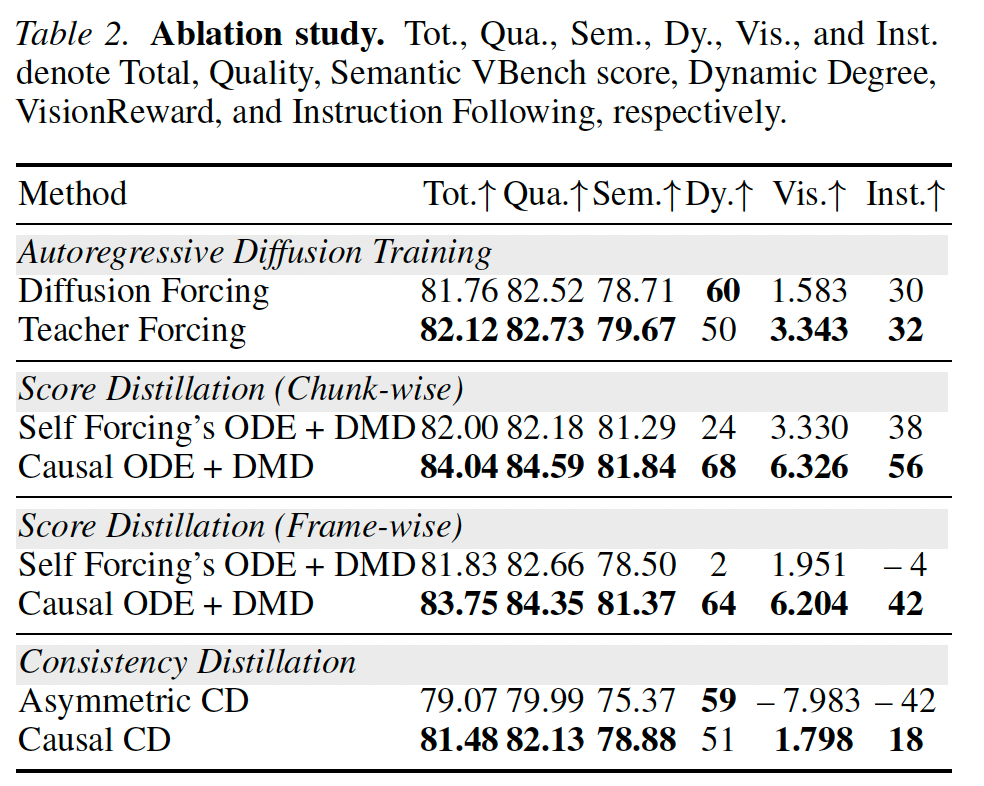
与现有模型的性能比较。我们将我们的方法与一系列规模相近的基线模型进行了比较,包括双向视频扩散模型 Wan2.1-1.3B(Wan et al., 2025)和 LTX-1.9B(HaCohen et al., 2024),自回归视频扩散模型 NOVA(Deng et al., 2024)、Pyramid Flow(Jin et al., 2024)、SkyReels-V2-1.3B(Chen et al., 2025)、MAGI-1-4.5B(Teng et al., 2025),以及蒸馏式自回归视频模型 Causvid(Yin et al., 2025)和 Self Forcing(Huang et al., 2025a)。
如表 1 所示,我们的方法在所有指标上都稳定优于所有基线,在动态程度、视觉质量和指令跟随能力方面均取得了最佳表现。与参数规模相近的双向扩散模型相比,我们的方法达到了当前最先进的 Wan2.1 的性能,甚至超过了它,同时实现了高出 2079% 的吞吐量和显著更快的推理速度。与现有自回归扩散模型相比,我们的方法相对于最佳基线在动态程度上提升了 47.8%,在 VisionReward 上提升了 56.0%,在指令跟随上提升了 75.0%。与蒸馏式自回归视频模型相比,我们在保持同样极高吞吐量的同时,相较于当前最先进的 Self Forcing,在动态程度上提升了 19.3%,在 VisionReward 上提升了 8.7%,在指令跟随上提升了 16.7%。图 6 中的定性结果与这些定量结果一致,表明我们的方法显著优于当前最先进的蒸馏式自回归模型。
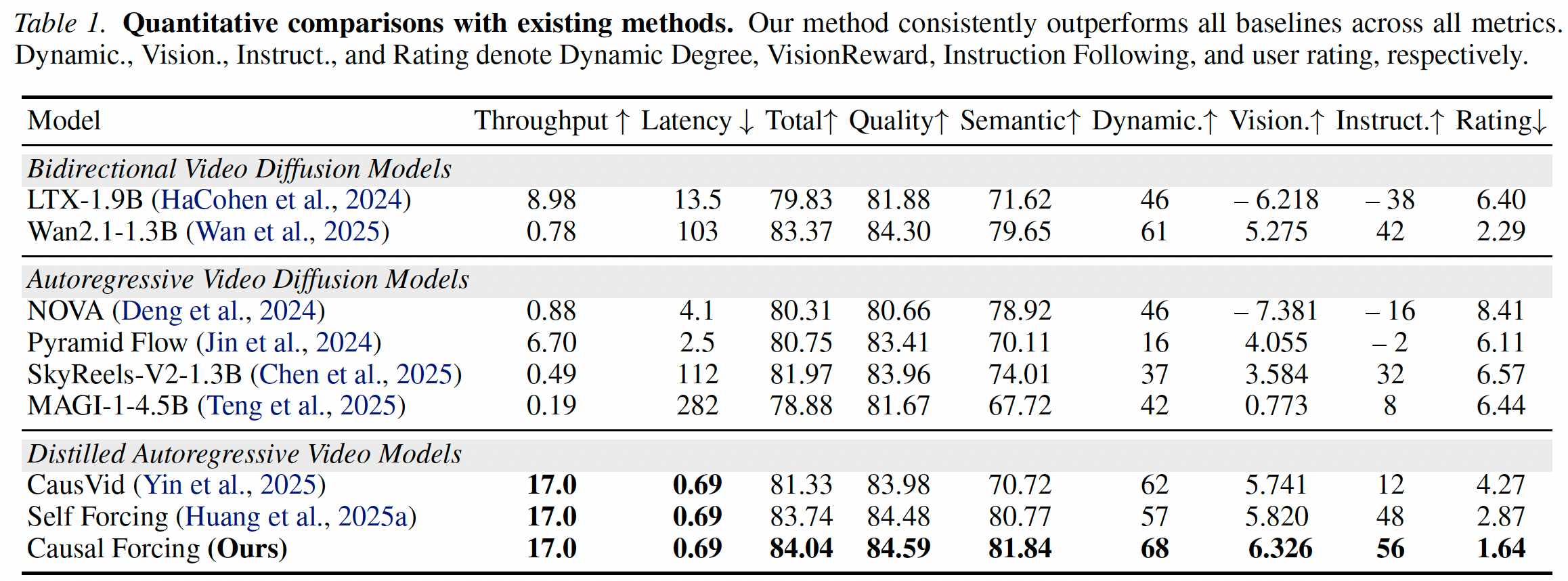

图 6. 与现有方法的定性比较。我们的方法相比现有蒸馏式自回归视频模型(Causvid 和 Self Forcing)实现了显著更强的动态性和更好的视觉质量,同时能够达到甚至超过双向扩散模型(Wan2.1)的表现。更多视频演示以及本文使用的全部提示词均见补充材料。
值得注意的是,基线蒸馏式自回归模型在 DMD 之前也都至少进行了 3K 步的 ODE 初始化,这与我们的方法相同。因此,我们的方法使用了完全相同的训练预算,却取得了显著提升。
消融实验。我们比较了自回归扩散训练、得分蒸馏以及一致性蒸馏(CD)中的不同策略。对于自回归扩散训练、Self Forcing 的 ODE 初始化以及 CD,我们使用 D B i \mathcal{D}{\mathrm{Bi}} DBi 数据集;对于我们的因果 ODE 初始化,我们使用 D C a u s a l \mathcal{D}{\mathrm{Causal}} DCausal。由于这两个数据集都是使用相同提示构造的内部合成数据,因此我们确保数据质量一致,从而保证比较的公平性。我们在分块设置下报告所有结果。此外,对于 ODE 初始化和 DMD,我们也报告逐帧设置下的结果。更多细节见附录 D。
表 2 表明,在自回归扩散训练过程中,teacher forcing 在所有指标上都优于 diffusion forcing,其中 VisionReward 提升了 111.2%,这与图 4 一致。虽然 diffusion forcing 获得了更高的动态程度,但这很大程度上来自模型坍塌对运动指标的病态性抬升。对于采用 ODE 初始化的 DMD,我们的因果 ODE 初始化显著优于 Self Forcing 的 ODE 初始化。在分块设置下,使用我们的因果 ODE 初始化的 DMD 将 VisionReward 提升了 90.0%,动态程度提升了 183.3%,指令跟随提升了 47.4%。在逐帧设置下,这种提升更为明显:动态程度提升了 3100%,VisionReward 提升了 218.0%。这与图 5 中的定性结果一致,说明因果 ODE 蒸馏为 DMD 提供了正确的初始化。
我们还将因果 CD 与非对称 CD 进行了比较,其中因果 CD 将 VisionReward 提升了 9.781,指令跟随提升了 60。定性可视化结果见附录 D 图 10。值得注意的是,我们当前的 CD 仍然是一个较为初步的实例化方法,直接采用了原始 LCM(Luo et al., 2023a),因此其表现仍逊于得分蒸馏。尽管如此,我们的这一形式化为未来工作(Lu & Song, 2024; Zheng et al., 2025)铺平了道路。
5. Conclusion
在本文中,我们指出了现有自回归视频扩散蒸馏方法的局限性,并阐明了弥合架构差距的重要性。我们聚焦于 ODE 初始化,表明其中一个根本要求是帧级单射性,而现有方法违反了这一条件。在这一理论分析的基础上,我们提出了 Causal Forcing:首先通过 teacher forcing 训练一个自回归扩散模型,然后将其作为 ODE 蒸馏中的教师,用于初始化后续的 DMD 阶段。实验结果表明,我们的方法在所有指标上都稳定优于所有基线,验证了其有效性。
A. Extended Related Work
视频生成模型。在扩散模型取得巨大成功的基础上,许多工作已将其应用于视频生成(He et al., 2022; Ho et al., 2022; Singer et al., 2022; Blattmann et al., 2023a;b; Chen et al., 2023; Gupta et al., 2024; Zhao et al., 2024; Xing et al., 2024; Zhao et al., 2025b; 2022)。随着扩散 Transformer(DiT)展现出强大的可扩展性(Bao et al., 2023; Peebles & Xie, 2023),许多工作提出了基于 DiT 的大规模视频模型(Lin et al., 2024; Zheng et al., 2024; Polyak et al., 2024; Yang et al., 2024; HaCohen et al., 2024; Kong et al., 2024; Ma et al., 2025),例如 CogVideoX(Yang et al., 2024)、Vidu(Bao et al., 2024)和 Wan2.1(Wan et al., 2025)。除全序列扩散模型之外,一些工作也采用自回归的 next-token prediction 来实现视频生成(Wu et al., 2021; Hong et al., 2022; Wu et al., 2022; Weissenborn et al., 2019; Yan et al., 2021; Zhao et al., 2025c;a),例如 NOVA(Deng et al., 2024)和 VideoPoet(Kondratyuk et al., 2023)。当前,基于全序列扩散模型的视频生成在整体质量上优于自回归 next-token prediction。然而,全序列扩散模型必须一次性生成所有帧,这会带来显著延迟,并且无法在帧生成出来时即时展示给用户,从而阻碍交互性和实时使用。相比之下,自回归模型可以以流式方式生成视频,从而支持用户交互。
用于交互式视频生成的自回归扩散模型。为了将扩散模型的高质量与自回归模型的交互性结合起来,近期工作提出了自回归扩散视频模型(Jin et al., 2024; Deng et al., 2024; Teng et al., 2025; Chen et al., 2025)。这些模型采用逐帧自回归形式,同时在每一帧内部使用扩散,例如 Pyramid Flow(Jin et al., 2024)、MAGI-1(Teng et al., 2025)和 SkyReels-v2(Chen et al., 2025)。这类自回归扩散模型能够在每一帧生成后立刻展示给用户,并可根据用户反馈调整后续帧的条件,从而实现交互式生成。尽管如此,交互性通常要求实时性能,也就是说生成速度应当与视频播放速率相当。然而,扩散模型依赖多步采样,因此速度过慢,难以满足这一要求。为了解决这个问题,近期工作如 ASD(Yang et al., 2025b)、CausVid(Yin et al., 2025)和 Self Forcing(Huang et al., 2025a)引入了蒸馏策略,以获得少步生成模型。
这类实时、交互式视频生成模型前景广阔,并在许多领域具有广泛应用。一个重要应用是视频世界模型。HY-WorldPlay(Sun et al., 2025a)、RELIC(Hong et al., 2025)、Hunyuan-GameCraft-2(Tang et al., 2025)和 Yume-1.5(Mao et al., 2025)训练实时交互式视频模型以进行逼真的世界模拟,使用户能够在模拟环境中自由探索并采取行动。这种交互式世界建模范式进一步支持了具身智能,例如 Vidarc(Feng et al., 2025)中的闭环控制。
另一个重要应用在娱乐与媒体领域,可支持交互式内容生成(Sun et al., 2025b; Ki et al., 2026),包括 Knot Forcing(Xiao et al., 2025)、Live avatar(Huang et al., 2025b)和 Motionstream(Shin et al., 2025)。除了交互性之外,这些自回归扩散模型也已被证明在长视频生成方面表现出色,例如 Rolling Forcing(Liu et al., 2025)、LongLive(Yang et al., 2025a)、Self-Forcing++(Cui et al., 2025)和 Deep Forcing(Yi et al., 2025)。
B. Proofs of Propositions
我们假设下文中出现的所有期望都是良定义且有限的,并且所涉及的所有概率密度函数都是可积的;这些都是扩散建模中常见且较弱的正则性条件(Song et al., 2020)。
B.1. The Flaw of Self Forcing's ODE Distillation
在本节中,我们首先给出引理 3.2 的正式数学表述并提供其证明。在此结果基础上,我们随后证明命题 3.3。
引理 B.1(PF-ODE 的块级非单射性)。设 x t ∈ R d x_t \in \mathbb{R}^d xt∈Rd 满足 PF-ODE
d x t = v θ ( x t , t ) d t dx_t = v_\theta(x_t,t)\,dt dxt=vθ(xt,t)dt
且该方程有唯一解。定义流映射
ϕ : R d × ( 0 , 1 ] → R d \phi:\mathbb{R}^d\times(0,1]\to\mathbb{R}^d ϕ:Rd×(0,1]→Rd
满足
ϕ ( x t , t ) = x 0 ∼ p d a t a ( x 0 ) . \phi(x_t,t)=x_0 \sim p_{\mathrm{data}}(x_0). ϕ(xt,t)=x0∼pdata(x0).
将坐标划分为
x t u : = ( x t ( m ) , ... , x t ( n ) ) x_t^u := (x_t^{(m)},\ldots,x_t^{(n)}) xtu:=(xt(m),...,xt(n))
以及
x t z : = x t d ∖ { m , ... , n } , x_t^z := x_t^{d\setminus\{m,\ldots,n\}}, xtz:=xtd∖{m,...,n},
其中
k : = n − m + 1 < d . k := n-m+1 < d. k:=n−m+1<d.
若对于每个固定的 ( x t u , t ) (x_t^u,t) (xtu,t), ϕ ( x t , t ) u \phi(x_t,t)^u ϕ(xt,t)u 关于 x t z x_t^z xtz 不是几乎处处常数,则
∀ t ∈ ( 0 , 1 ] , ∀ x t ∈ R d , ∃ y t ∈ R d , s.t. y t u = x t u , and ϕ ( y t , t ) u ≠ ϕ ( x t , t ) u . \forall t\in(0,1],\ \forall x_t\in\mathbb{R}^d,\ \exists y_t\in\mathbb{R}^d,\ \text{s.t.}\ y_t^u=x_t^u,\ \text{and}\ \phi(y_t,t)^u \ne \phi(x_t,t)^u. ∀t∈(0,1], ∀xt∈Rd, ∃yt∈Rd, s.t. ytu=xtu, and ϕ(yt,t)u=ϕ(xt,t)u.
此外,如果
x T ∼ N ( 0 , I ) x_T \sim \mathcal{N}(0,I) xT∼N(0,I)
且对于 Lebesgue 几乎处处的 x t x_t xt 都有 p t ( x t ) > 0 p_t(x_t)>0 pt(xt)>0,则
P ( V a r ( ϕ ( x t , t ) u ∣ x t u , t ) > 0 ) > 0. \mathbb{P}\big(\mathrm{Var}(\phi(x_t,t)^u \mid x_t^u,t)>0\big)>0. P(Var(ϕ(xt,t)u∣xtu,t)>0)>0.
证明。固定 t ∈ ( 0 , 1 ] t\in(0,1] t∈(0,1]。将任意 x ∈ R d x\in\mathbb{R}^d x∈Rd 写成
x = ( x u , x z ) , x=(x^u,x^z), x=(xu,xz),
其中 x u ∈ R k x^u\in\mathbb{R}^k xu∈Rk, x z ∈ R d − k x^z\in\mathbb{R}^{d-k} xz∈Rd−k。固定任意 x t ∈ R d x_t\in\mathbb{R}^d xt∈Rd,并记
u 1 : = x t u , z 1 : = x t z . u_1:=x_t^u,\qquad z_1:=x_t^z. u1:=xtu,z1:=xtz.
定义可测映射
f u 1 , t : R d − k → R k , f u 1 , t ( z ) : = ϕ ( ( u 1 , z ) , t ) u . f_{u_1,t}:\mathbb{R}^{d-k}\to\mathbb{R}^k,\qquad f_{u_1,t}(z):=\phi((u_1,z),t)^u. fu1,t:Rd−k→Rk,fu1,t(z):=ϕ((u1,z),t)u.
根据假设,对于这个固定的 ( u 1 , t ) (u_1,t) (u1,t),函数 z ↦ f u 1 , t ( z ) z\mapsto f_{u_1,t}(z) z↦fu1,t(z) 不是几乎处处常数(相对于 R d − k \mathbb{R}^{d-k} Rd−k 上的 Lebesgue 测度)。我们断言:对每个 z 1 ∈ R d − k z_1\in\mathbb{R}^{d-k} z1∈Rd−k,都存在某个 z 2 ∈ R d − k z_2\in\mathbb{R}^{d-k} z2∈Rd−k,使得
f u 1 , t ( z 2 ) ≠ f u 1 , t ( z 1 ) . f_{u_1,t}(z_2)\ne f_{u_1,t}(z_1). fu1,t(z2)=fu1,t(z1).
的确,如果对某个 z 1 z_1 z1 有 f u 1 , t ( z ) = f u 1 , t ( z 1 ) f_{u_1,t}(z)=f_{u_1,t}(z_1) fu1,t(z)=fu1,t(z1) 对所有 z z z 都成立,那么 f u 1 , t f_{u_1,t} fu1,t 将处处为常数,这与假设矛盾。
为上述 z 1 z_1 z1 选取这样的 z 2 z_2 z2,并令
y t : = ( u 1 , z 2 ) . y_t := (u_1,z_2). yt:=(u1,z2).
则 y t u = x t u y_t^u=x_t^u ytu=xtu,同时
ϕ ( y t , t ) u = f u 1 , t ( z 2 ) ≠ f u 1 , t ( z 1 ) = ϕ ( x t , t ) u , \phi(y_t,t)^u = f_{u_1,t}(z_2)\ne f_{u_1,t}(z_1)=\phi(x_t,t)^u, ϕ(yt,t)u=fu1,t(z2)=fu1,t(z1)=ϕ(xt,t)u,
这就证明了式 (10)。
结合上述结果以及 x T ∼ N ( 0 , I ) x_T\sim\mathcal{N}(0,I) xT∼N(0,I) 且 x t x_t xt 具有非退化概率密度这一事实,标准的测度论论证(Kallenberg, 1997; Evans, 2018)可推出如下结论:对于上述 z 1 , z 2 z_1,z_2 z1,z2,在 z 2 z_2 z2 的某个邻域内,存在不可数多个 z k z_k zk,每个都像 z 2 z_2 z2 一样映射到不同的 ϕ ( x t , t ) u \phi(x_t,t)^u ϕ(xt,t)u。等价地,
P ( V a r ( ϕ ( x t , t ) u ∣ x t u , t ) > 0 ) > 0. \mathbb{P}\big(\mathrm{Var}(\phi(x_t,t)^u \mid x_t^u,t)>0\big)>0. P(Var(ϕ(xt,t)u∣xtu,t)>0)>0.
证毕。
接下来我们证明命题 3.3。首先,我们将其形式化为如下命题。
命题 B.2(块级回归中的分布失配)。沿用引理 B.1 的记号,并且对每个固定的 ( x t u , t ) (x_t^u,t) (xtu,t), ϕ ( x t , t ) u \phi(x_t,t)^u ϕ(xt,t)u 关于 x t z x_t^z xtz 不是几乎处处常数。考虑训练一个块级模型
G θ : R k × ( 0 , 1 ] → R k G_\theta:\mathbb{R}^k\times(0,1]\to\mathbb{R}^k Gθ:Rk×(0,1]→Rk
其回归目标为
θ ∗ = min θ E x t , t ∥ G θ ( x t u , t ) − x 0 u ∥ 2 , \theta^*=\min_\theta \mathbb{E}_{x_t,t}\left\\\|G_\\theta(x_t\^u,t)-x_0\^u\\\|\^2\\right, θ∗=θminExt,t∥Gθ(xtu,t)−x0u∥2,
其中
x 0 = ϕ ( x t , t ) . x_0=\phi(x_t,t). x0=ϕ(xt,t).
则最优解是条件均值,它不服从块级数据分布,即
G θ ∗ ( x t u , t ) = E x 0 u ∣ x t u , t ≁ p d a t a ( x 0 u ) . G_\theta^*(x_t^u,t)=\mathbb{E}x_0\^u \\mid x_t\^u,t \not\sim p_{\mathrm{data}}(x_0^u). Gθ∗(xtu,t)=Ex0u∣xtu,t∼pdata(x0u).
由于基于 DiT 的双向扩散模型包含并非常数的注意力模块,这一点已被先前工作的注意力图实验所证实(Xi et al., 2025; Zhao et al., 2025d),因此引理 B.1 中的条件成立:对于每个固定的 ( x t u , t ) (x_t^u,t) (xtu,t), ϕ ( x t , t ) u \phi(x_t,t)^u ϕ(xt,t)u 关于 x t z x_t^z xtz 不是几乎处处常数。接下来我们利用式 (11) 证明命题 B.2。
证明。令
t ∼ q ( t ) t\sim q(t) t∼q(t)
为训练中使用的时间采样,并令
x 0 = ϕ ( x t , t ) . x_0=\phi(x_t,t). x0=ϕ(xt,t).
记
U : = x t u ∈ R k , Y : = x 0 u ∈ R k , Y ^ : = E Y ∣ U , t . U:=x_t^u \in \mathbb{R}^k,\qquad Y:=x_0^u \in \mathbb{R}^k,\qquad \hat{Y}:=\mathbb{E}Y\\mid U,t. U:=xtu∈Rk,Y:=x0u∈Rk,Y^:=EY∣U,t.
根据标准平方损失回归结果(Bishop & Nasrabadi, 2006),最小化器满足
G θ ∗ ( U , t ) = Y ^ = E x 0 u ∣ x t u , t . G_\theta^*(U,t)=\hat{Y}=\mathbb{E}x_0\^u \\mid x_t\^u,t. Gθ∗(U,t)=Y^=Ex0u∣xtu,t.
接下来只需证明 Y ^ ≁ Y \hat{Y}\not\sim Y Y^∼Y(因此 Y ^ ≁ p d a t a ( x 0 u ) \hat{Y}\not\sim p_{\mathrm{data}}(x_0^u) Y^∼pdata(x0u))。利用 L 2 L^2 L2 正交投影恒等式(Bishop & Nasrabadi, 2006),有
E ∥ Y ∥ 2 = E ∥ Y ^ ∥ 2 + E ∥ Y − Y ^ ∥ 2 = E ∥ Y ^ ∥ 2 + E V a r ( Y ∣ U , t ) , \mathbb{E}\|Y\|^2 = \mathbb{E}\|\hat{Y}\|^2 + \mathbb{E}\|Y-\hat{Y}\|^2 = \mathbb{E}\|\hat{Y}\|^2 + \mathbb{E}\\mathrm{Var}(Y\\mid U,t), E∥Y∥2=E∥Y^∥2+E∥Y−Y^∥2=E∥Y^∥2+EVar(Y∣U,t),
其中
V a r ( Y ∣ U , t ) : = E ∥ Y − E \[ Y ∣ U , t ∥ 2 ∣ U , t ] . \mathrm{Var}(Y\mid U,t) := \mathbb{E}\big\\\|Y-\\mathbb{E}\[Y\\mid U,t\|^2 \mid U,t\big]. Var(Y∣U,t):=E∥Y−E\[Y∣U,t∥2∣U,t].
由引理 B.1(式 (11)),
P ( V a r ( Y ∣ U , t ) > 0 ) > 0 , \mathbb{P}(\mathrm{Var}(Y\mid U,t)>0)>0, P(Var(Y∣U,t)>0)>0,
因此
E V a r ( Y ∣ U , t ) > 0 , \mathbb{E}\\mathrm{Var}(Y\\mid U,t)>0, EVar(Y∣U,t)>0,
从而
E ∥ Y ∥ 2 > E ∥ Y ^ ∥ 2 . \mathbb{E}\|Y\|^2 > \mathbb{E}\|\hat{Y}\|^2. E∥Y∥2>E∥Y^∥2.
如果 Y ^ \hat{Y} Y^ 与 Y Y Y 服从相同分布,则应有
E ∥ Y ^ ∥ 2 = E ∥ Y ∥ 2 , \mathbb{E}\|\hat{Y}\|^2 = \mathbb{E}\|Y\|^2, E∥Y^∥2=E∥Y∥2,
这与上式矛盾。因此 Y ^ ≁ Y \hat{Y}\not\sim Y Y^∼Y,即
G θ ∗ ( x t u , t ) = E x 0 u ∣ x t u , t ≁ p d a t a ( x 0 u ) . G_\theta^*(x_t^u,t)=\mathbb{E}x_0\^u \\mid x_t\^u,t \not\sim p_{\mathrm{data}}(x_0^u). Gθ∗(xtu,t)=Ex0u∣xtu,t∼pdata(x0u).
证毕。
B.2. Distribution Mismatch in Autoregressive Diffusion Forcing
在本节中,我们首先给出基本的正则性假设,然后证明命题 3.4。
令
Y : = x 0 < i , X : = x 0 i , Y := x_0^{< i},\quad X := x_0^i, Y:=x0<i,X:=x0i,
并令
Z : = x t < i Z := x_t^{< i} Z:=xt<i
表示在某个固定 t > 0 t>0 t>0 下,通过前向核
q t ∣ 0 ( Z ∣ Y ) q_{t|0}(Z\mid Y) qt∣0(Z∣Y)
对 Y Y Y 的每一帧独立加噪所得到的结果。我们有如下几个较弱的假设。
(A1) 在扩散训练目标下,模型能够得到最优条件分布,记为
p D F ( X ∣ Z ) : = p D F ( x 0 i ∣ x t < i ) = p d a t a ( x ∣ z ) . p_{\mathrm{DF}}(X\mid Z):=p_{\mathrm{DF}}(x_0^i\mid x_t^{< i})=p_{\mathrm{data}}(x\mid z). pDF(X∣Z):=pDF(x0i∣xt<i)=pdata(x∣z).
这是一个平凡假设,在文献中被广泛采用(Song et al., 2020)。
(A2) 在 p d a t a ( X , Y ) p_{\mathrm{data}}(X,Y) pdata(X,Y) 下, X X X 与 Y Y Y 不独立,即
p d a t a ( X ∣ Y = y ) p_{\mathrm{data}}(X\mid Y=y) pdata(X∣Y=y)
并不是关于 p d a t a ( Y ) p_{\mathrm{data}}(Y) pdata(Y) 几乎处处的常数。这个假设的直观含义是:同一视频中的不同帧并非相互独立,而是紧密相关的。
(A3) 后验核
p d a t a ( Y ∣ Z = y ) p_{\mathrm{data}}(Y\mid Z=y) pdata(Y∣Z=y)
在 p d a t a ( Y ) p_{\mathrm{data}}(Y) pdata(Y) 的支撑集上是正且非退化的。特别地,对于
y ∈ s u p p ( p d a t a ( Y ) ) , y\in \mathrm{supp}(p_{\mathrm{data}}(Y)), y∈supp(pdata(Y)),
密度
p d a t a ( Y ∣ Z = y ) p_{\mathrm{data}}(Y\mid Z=y) pdata(Y∣Z=y)
为正。
证明。由 (A1),在一个干净前缀值 y y y 上查询经过 DF 训练的模型,会诱导出
p D F ( x ∣ y ) = p D F ( x ∣ Z = y ) = p d a t a ( x ∣ Z = y ) . p_{\mathrm{DF}}(x\mid y)=p_{\mathrm{DF}}(x\mid Z=y)=p_{\mathrm{data}}(x\mid Z=y). pDF(x∣y)=pDF(x∣Z=y)=pdata(x∣Z=y).
因此,只需证明
E Y D K L ( p d a t a ( X ∣ Z = Y ) ∥ p d a t a ( X ∣ Y ) ) > 0. \mathbb{E}_Y\leftD_{\\mathrm{KL}}\\big(p_{\\mathrm{data}}(X\\mid Z=Y)\\,\\\|\\,p_{\\mathrm{data}}(X\\mid Y)\\big)\\right > 0. EYDKL(pdata(X∣Z=Y)∥pdata(X∣Y))>0.
我们用反证法证明。反设式 (22) 左边等于 0。这意味着
p d a t a ( X ∣ Z = y ) = p d a t a ( X ∣ Y = y ) 对 p d a t a ( Y ) -a.e. 的 y . p_{\mathrm{data}}(X\mid Z=y)=p_{\mathrm{data}}(X\mid Y=y)\qquad \text{对 } p_{\mathrm{data}}(Y)\text{-a.e. 的 } y. pdata(X∣Z=y)=pdata(X∣Y=y)对 pdata(Y)-a.e. 的 y.
固定 X X X 的样本空间中任意一个可测集合 A A A,并定义
f A ( y ) : = P d a t a ( X ∈ A ∣ Y = y ) . f_A(y):=\mathbb{P}_{\mathrm{data}}(X\in A\mid Y=y). fA(y):=Pdata(X∈A∣Y=y).
由式 (23),对 p d a t a ( Y ) p_{\mathrm{data}}(Y) pdata(Y)-a.e. 的 y y y,有
P d a t a ( X ∈ A ∣ Z = y ) = f A ( y ) . \mathbb{P}_{\mathrm{data}}(X\in A\mid Z=y)=f_A(y). Pdata(X∈A∣Z=y)=fA(y).
另一方面,由于 Z Z Z 是由 Y Y Y 经过独立加噪生成的,在 p d a t a p_{\mathrm{data}} pdata 下我们有马尔可夫链
X → Y → Z . X \to Y \to Z. X→Y→Z.
因此,根据塔式性质(Kallenberg, 1997),
P d a t a ( X ∈ A ∣ Z = y ) = E d a t a P d a t a ( X ∈ A ∣ Y ) ∣ Z = y \mathbb{P}{\mathrm{data}}(X\in A\mid Z=y)= \mathbb{E}{\mathrm{data}}\big\\mathbb{P}_{\\mathrm{data}}(X\\in A\\mid Y)\\mid Z=y\\big Pdata(X∈A∣Z=y)=EdataPdata(X∈A∣Y)∣Z=y
= E d a t a f A ( Y ) ∣ Z = y . =\mathbb{E}_{\mathrm{data}}\bigf_A(Y)\\mid Z=y\\big. =EdatafA(Y)∣Z=y.
结合式 (25) 和式 (27),得到
f A ( y ) = E d a t a f A ( Y ) ∣ Z = y 对 p d a t a ( Y ) -a.e. 的 y . f_A(y)=\mathbb{E}{\mathrm{data}}f_A(Y)\\mid Z=y\qquad \text{对 } p{\mathrm{data}}(Y)\text{-a.e. 的 } y. fA(y)=EdatafA(Y)∣Z=y对 pdata(Y)-a.e. 的 y.
根据正则性条件 (A3),条件期望算子
T f ( y ) : = E f ( Y ) ∣ Z = y T_f(y):=\mathbb{E}f(Y)\\mid Z=y Tf(y):=Ef(Y)∣Z=y
只允许关于 p d a t a ( Y ) p_{\mathrm{data}}(Y) pdata(Y)-a.e. 的常数有界不动点。将这一事实应用到式 (28),可知对每个可测集 A A A, f A f_A fA 都是关于 p d a t a ( Y ) p_{\mathrm{data}}(Y) pdata(Y)-a.e. 的常数。因此
p d a t a ( X ∣ Y = y ) p_{\mathrm{data}}(X\mid Y=y) pdata(X∣Y=y)
也是关于 p d a t a ( Y ) p_{\mathrm{data}}(Y) pdata(Y)-a.e. 的常数,即
X ⊥ ⊥ Y , X \perp\!\!\!\perp Y, X⊥⊥Y,
这与 (A2) 矛盾。因此,反设不成立,式 (22) 成立。于是,
E y ∼ p d a t a ( Y ) D K L ( p D F ( X ∣ y ) ∥ p d a t a ( X ∣ y ) ) > 0. \mathbb{E}{y\sim p{\mathrm{data}}(Y)}\leftD_{\\mathrm{KL}}\\big(p_{\\mathrm{DF}}(X\\mid y)\\,\\\|\\,p_{\\mathrm{data}}(X\\mid y)\\big)\\right > 0. Ey∼pdata(Y)DKL(pDF(X∣y)∥pdata(X∣y))>0.
C. More Discussion of Our Method
C.1. Further Remarks on Autoregressive Diffusion Training Strategies
在本节中,我们首先对 diffusion forcing 作进一步说明,然后报告其他训练策略的结果,包括 PFVG(Wu et al., 2025)、BAgger(Po et al., 2025)以及 Resampling Forcing(Guo et al., 2025)。
正如命题 3.4 所述,将 diffusion forcing 应用于自回归扩散训练是次优的。不过,这并不意味着 diffusion forcing 毫无用处。具体来说,diffusion forcing 最初是为视频续写中的双向扩散模型训练而提出的,以支持长视频生成(Song et al., 2025)。在这种设定下,推理时的续写会将一个干净前缀(给定视频的尾部帧)与噪声拼接,这与训练设置是一致的,因此避免了训练---推理失配。因此,这种双向 diffusion forcing 训练范式并不在我们关于"次优性"的论断范围内。此外,diffusion forcing 允许不同帧具有不同的噪声水平。即便在自回归扩散训练中,这本身也不是问题,因为每一帧实际上都是独立训练的。我们真正反驳的做法,是像 CausVid(Yin et al., 2025)以及近期工作(例如 LiveAvatar(Huang et al., 2025b))所提出的那样,在自回归扩散训练中以带噪前缀作为条件。
除了 diffusion forcing 和 teacher forcing 之外,我们还实验了若干近期替代方法,包括 PFVG(Wu et al., 2025)、BAgger(Po et al., 2025)和 Resampling Forcing(Guo et al., 2025)。然而,如表 3 所示,这些方法相对于 teacher forcing 并未带来显著改进。值得注意的是,它们中的大多数主要是为长视频训练与生成而设计的,因此在我们的 5 秒设定中收益有限是可以理解的。我们将对这些策略进行更深入的研究留待未来工作。

C.2. Multi-Step Autoregressive Diffusion as Initialization for Asymmetric DMD
在本节中,我们研究直接使用一个通过 teacher forcing 训练得到的多步自回归扩散模型来初始化非对称 DMD。我们发现,与 Self Forcing 的 ODE 蒸馏初始化相比,多步自回归扩散初始化在动态性和视觉质量两方面都带来了显著提升,如图 8 所示(中间列对比左列)。
尽管有这些提升,多步自回归扩散模型只是在多步采样(例如 50 步)下缩小了从双向到因果的架构差距,而并未在少步设定下彻底解决这一问题。具体而言,在少步采样下,自回归生成会在条件上下文中引入额外的失配:第 i i i 帧依赖于前面的第 0 ∼ i − 1 0 \sim i-1 0∼i−1 帧作为条件,而这些前序帧在低步数下质量会下降;相比之下,训练时使用的是高质量的真实前缀作为条件。因此,这种退化的条件会在整个自回归生成过程中不断累积,导致误差在各个块之间传播。如图 7(上)所示,在 DMD 阶段之前,我们仅在 4 步生成设置下评估该自回归扩散模型;它在块与块之间表现出突兀的过渡,这表明在少步设定下仍然存在显著的架构差距。
这一分析表明,在用多步自回归扩散模型初始化 DMD 之前,有必要先将其转换为一个少步模型。如图 7(下)所示,经过因果 ODE 蒸馏的模型在少步采样下表现出更强的时间一致性,因此更适合作为 DMD 的初始化。与此一致,图 8(中间列对比右列)进一步表明,用因果 ODE 初始化替换多步自回归扩散初始化,会在后续的 DMD 阶段带来明显收益。表 4 中的定量结果也支持这一点,其中因果 ODE 在 VisionReward 和 Instruction Following 指标上都取得了显著更好的分数。

C.3. Causal ODE Distillation from Bidirectional Initial Model
在本节中,我们研究直接使用一个通过 teacher forcing 训练得到的多步自回归扩散模型来初始化非对称 DMD。我们发现,与 Self Forcing 的 ODE 蒸馏初始化相比,多步自回归扩散初始化在动态性和视觉质量两方面都带来了显著提升,如图 8 所示(中间列对比左列)。

尽管有这些提升,多步自回归扩散模型只是在多步采样(例如 50 步)下缩小了从双向到因果的架构差距,而并未在少步设定下彻底解决这一问题。具体而言,在少步采样下,自回归生成会在条件上下文中引入额外的失配:第 i i i 帧依赖于前面的第 0 ∼ i − 1 0 \sim i-1 0∼i−1 帧作为条件,而这些前序帧在低步数下质量会下降;相比之下,训练时使用的是高质量的真实前缀作为条件。因此,这种退化的条件会在整个自回归生成过程中不断累积,导致误差在各个块之间传播。如图 7(上)所示,在 DMD 阶段之前,我们仅在 4 步生成设置下评估该自回归扩散模型;它在块与块之间表现出突兀的过渡,这表明在少步设定下仍然存在显著的架构差距。

这一分析表明,在用多步自回归扩散模型初始化 DMD 之前,有必要先将其转换为一个少步模型。如图 7(下)所示,经过因果 ODE 蒸馏的模型在少步采样下表现出更强的时间一致性,因此更适合作为 DMD 的初始化。与此一致,图 8(中间列对比右列)进一步表明,用因果 ODE 初始化替换多步自回归扩散初始化,会在后续的 DMD 阶段带来明显收益。表 4 中的定量结果也支持这一点,其中因果 ODE 在 VisionReward 和 Instruction Following 指标上都取得了显著更好的分数。

D. More Implementation Details
在本节中,我们给出第 4 节的更多细节。
我们方法的训练细节。我们首先构建一个数据集 D B i \mathcal{D}{\mathrm{Bi}} DBi,其中包含大约 3K 个由 Wan(双向模型)(Wan et al., 2025)结合 VidProM(Wang & Yang, 2024)提示生成的样本,并在其上训练一个 teacher forcing 自回归扩散模型,共 2K 步。接着,我们从该自回归扩散模型中采样 ODE 轨迹,以构建一个包含 3K 个样本的因果 ODE 数据集 D C a u s a l \mathcal{D}{\mathrm{Causal}} DCausal。需要注意的是,由于因果 ODE 蒸馏是在真实干净数据条件下执行 teacher forcing,因此我们保存了 D C a u s a l \mathcal{D}{\mathrm{Causal}} DCausal 中每个数据点与 D B i \mathcal{D}{\mathrm{Bi}} DBi 中对应数据之间的关系。在整个训练过程中,包括 teacher forcing 自回归扩散模型以及两种 ODE 初始化变体,我们使用的都是 D B i \mathcal{D}{\mathrm{Bi}} DBi 或 D C a u s a l \mathcal{D}{\mathrm{Causal}} DCausal,它们都由模型内部合成,并使用大致相同的提示,因此能够保证数据质量不存在差异。这确保了消融实验中比较的公平性。随后,我们在 D C a u s a l \mathcal{D}{\mathrm{Causal}} DCausal 上进行 1K 步的因果 ODE 蒸馏,并以 D B i \mathcal{D}{\mathrm{Bi}} DBi 中对应的干净数据作为 teacher forcing 条件。在这一阶段,ODE 学生模型从自回归扩散教师初始化。最后,我们将该模型用作标准非对称 DMD 的初始化,其中 s r e a l s_{\mathrm{real}} sreal 为 Wan2.1-14B, s f a k e s_{\mathrm{fake}} sfake 为 Wan2.1-1.3B,严格遵循 Self Forcing(Huang et al., 2025a)的设定,以保证公平比较。对于分块设置和逐帧设置,我们采用相同的整体公式与流程。
在所有训练阶段中,我们都使用 batch size 为 64,优化器为 Adam,学习率为 2 × 10 − 6 2 \times 10^{-6} 2×10−6, β 1 = 0 \beta_1 = 0 β1=0, β 2 = 0.999 \beta_2 = 0.999 β2=0.999,其余所有设置均与 Self Forcing 保持一致。在推理时,我们使用 4 步采样,因果 ODE 初始化与非对称 DMD 共用相同的时间步,即 1 , 0.9375 , 0.8333 , 0.625 1,\ 0.9375,\ 0.8333,\ 0.625 1, 0.9375, 0.8333, 0.625。
对于扩展的因果一致性蒸馏,我们采用 LCM(Luo et al., 2023a)方案,使用 48 个离散时间步,并采用 EMA 率为 0.99 的 UniPC ODE 求解器。我们在 D B i \mathcal{D}{\mathrm{Bi}} DBi 上训练模型 3K 步,推理时同样使用 4 步,并采用与 DMD 相同的时间步。需要注意的是,离散时间一致性蒸馏要求边界条件
G θ ( x i , x g t < i , 0 ) ≡ x i , G\theta(x^i, x_{\mathrm{gt}}^{< i}, 0) \equiv x^i, Gθ(xi,xgt<i,0)≡xi,
通常通过引入一个包裹网络 F θ F_\theta Fθ 来参数化 G θ G_\theta Gθ:
G θ ( x i , x g t < i , t ) = c s k i p ( t ) x i + c o u t ( t ) F θ ( x i , x g t < i , t ) , G_\theta(x^i, x_{\mathrm{gt}}^{< i}, t) = c_{\mathrm{skip}}(t)x^i + c_{\mathrm{out}}(t)F_\theta(x^i, x_{\mathrm{gt}}^{< i}, t), Gθ(xi,xgt<i,t)=cskip(t)xi+cout(t)Fθ(xi,xgt<i,t),
其中 c s k i p ( 0 ) = 1 , c o u t ( 0 ) = 0 c_{\mathrm{skip}}(0)=1,\ c_{\mathrm{out}}(0)=0 cskip(0)=1, cout(0)=0。然而,由于我们使用流匹配,即对扩散模型 v θ v_\theta vθ 采用 v v v-prediction 参数化,因此 G θ G_\theta Gθ 的一种 x 0 x_0 x0-prediction 形式已经天然满足所需的边界条件,而无需额外设计:
G θ ( x i , x g t < i , t ) = x i − t v θ ( x i , x g t < i , t ) . G_\theta(x^i, x_{\mathrm{gt}}^{< i}, t) = x^i - t v_\theta(x^i, x_{\mathrm{gt}}^{< i}, t). Gθ(xi,xgt<i,t)=xi−tvθ(xi,xgt<i,t).
这种简化设计未必是最优的,并为进一步探索留下了较大的设计空间(Geng et al., 2024; Lu & Song, 2024; Zheng et al., 2025),这部分留待未来工作。图 10 可视化地表明,因果 CD 优于非对称 CD:后者看起来非常模糊,并表现出突兀伪影,而我们的结果质量更高,也更稳定。这与表 2 一致,并凸显了在自回归 CD 中使用原生因果教师的必要性。

评估细节。在本节中,我们重点介绍 Dynamic Degree、VisionReward 和 Instruction Following 的设置。我们使用补充材料中提供的 100 个具有丰富动作序列和动态变化的提示。
对于 Dynamic Degree,我们使用官方 VBench 评估代码的自定义输入模式。需要注意的是,我们表格中报告的 Dynamic Degree 是在这个 100 提示动作集上评估的;然而,在计算 VBench 的 Total、Quality 和 Semantic 分数时,Dynamic Degree 这一项仍然是在标准 VBench 官方提示上评估,而不是继承自我们的自定义集合。此外,我们使用 VisionReward 来评估整体视觉质量。每个子分数都可能为正或负,并位于 − 1 , 1 -1,1 −1,1 区间内,其中 − 1 -1 −1 表示最差质量, 1 1 1 表示最佳质量。最终的 VisionReward 分数使用官方权重加权求和得到。我们还额外使用 VisionReward 的 prompt-alignment 子分数来评估指令跟随能力,具体方式是使用官方提示查询 VisionReward:
"Does the video meet some of the requirements stated in the text '\[prompt]'?" \text{"Does the video meet some of the requirements stated in the text `\[prompt]`?"} "Does the video meet some of the requirements stated in the text '\[prompt]'?"
性能比较细节。所有基线都使用与 Self Forcing 相同的空间分辨率。基线方法在 H100 GPU 上的吞吐量和延迟直接取自 Self Forcing 论文。
消融细节。对于自回归扩散训练,teacher forcing 和 diffusion forcing 都训练 3K 步。对于 Self Forcing 的 ODE 初始化,我们从双向扩散模型出发并训练 3K 步。对于因果 ODE 初始化,我们先训练一个 teacher forcing 自回归扩散模型 2K 步,再在其基础上额外执行 1K 步的因果 ODE 蒸馏。这样可以使两种 ODE 初始化变体的总体训练计算量对齐(均为 3K),从而保证公平比较。两种 CD 变体也都训练 3K 步,并且都使用 teacher forcing 自回归扩散模型作为教师,以确保 CD 内部比较的公平性。其余所有设置均遵循主实验。