从缓慢的双向视频扩散模型到快速的自回归视频扩散模型
paper title:From Slow Bidirectional to Fast Autoregressive Video Diffusion Models
paper是MIT发表在CVPR 25的工作
Code:链接

图 1. 传统的双向扩散模型(上)虽然能够生成高质量结果,但存在显著的延迟问题,生成一个 128 帧视频需要 219 秒。用户必须等到整个序列全部生成完成后才能看到任何结果。相比之下,我们将双向扩散模型蒸馏为一个少步自回归生成器(下),从而显著降低了计算开销。我们的方法(CausVid)将初始延迟降低到仅 1.3 秒,之后即可通过流式方式以约 9.4 FPS 的速度连续生成视频帧,从而支持更具交互性的视频内容创作流程。
Abstract
当前的视频扩散模型虽然已经展现出令人印象深刻的生成质量,但由于双向注意力依赖,在交互式应用中仍然面临困难。生成单帧时,模型需要处理整个序列,包括未来帧。我们通过将一个预训练的双向扩散 Transformer 改造为可在线逐帧生成的自回归 Transformer,来解决这一限制。为了进一步降低延迟,我们将分布匹配蒸馏(DMD)扩展到视频领域,将一个 50 步扩散模型蒸馏为 4 步生成器。为了实现稳定且高质量的蒸馏,我们引入了一种基于教师 ODE 轨迹的学生初始化方案,以及一种非对称蒸馏策略,用双向教师模型监督因果学生模型。该方法有效缓解了自回归生成中的误差累积问题,使得模型即使仅在短视频片段上训练,也能够生成长时长视频。我们的方法在 VBench-Long 基准上取得了 84.27 的总分,超过了此前所有视频生成模型。借助 KV cache,我们的方法能够在单张 GPU 上以 9.4 FPS 的速度流式生成高质量视频。我们的方法还能够以零样本方式实现流式视频到视频转换、图像到视频生成以及动态提示。我们将公开代码和预训练模型。
1. Introduction
扩散模型的出现彻底改变了我们从文本生成视频的方式 3, 5, 25, 29, 63, 98, 111。许多最先进的视频扩散模型依赖于扩散 Transformer(DiT)架构 2, 61,该架构通常在所有视频帧之间采用双向注意力。尽管生成质量令人印象深刻,但这种双向依赖意味着生成单帧时必须处理整个视频。这会带来较高的延迟,并阻碍模型应用于交互式和流式场景,因为在这些场景中,模型需要根据可能随时间变化的用户输入持续生成帧。当前帧的生成依赖于未来的条件输入,而这些输入在当下尚不可得。当前的视频扩散模型还受限于生成速度。其计算和内存开销会随着帧数平方增长,再加上推理过程中需要大量去噪步骤,使得长视频的生成变得极其缓慢且成本高昂。
自回归模型为解决其中一些限制提供了很有前景的方案,但它们也面临误差累积和计算效率方面的挑战。与同时生成所有帧不同,自回归视频模型按顺序逐帧生成。用户一旦第一帧生成完成,就可以开始观看视频,而无需等待整个视频生成结束。这降低了延迟,消除了视频长度限制,并为交互式控制打开了大门。然而,自回归模型容易出现误差累积:每一帧的生成都建立在前面可能存在缺陷的帧之上,从而导致预测误差被不断放大,并随时间推移而恶化。此外,尽管延迟降低了,现有自回归视频模型距离以交互式帧率生成真实感视频仍有很大差距 7, 29, 37。
在本文中,我们提出了 CausVid,这是一种面向快速、可交互因果视频生成的模型。我们设计了一种在视频帧之间具有因果依赖关系的自回归扩散 Transformer 架构。类似于流行的仅解码器大型语言模型(LLMs)6, 66,我们的模型通过在每次迭代中利用来自所有输入帧的监督实现了高样本效率训练,并通过键值(KV)缓存实现了高效的自回归推理。为了进一步提升生成速度,我们将分布匹配蒸馏(DMD)101, 102 这一最初为图像扩散模型设计的少步蒸馏方法扩展到了视频数据上。我们没有简单地将一个自回归扩散模型 8, 29 蒸馏为少步学生模型,而是提出了一种非对称蒸馏策略:将一个预训练的、具有双向注意力的教师扩散模型中的知识蒸馏到我们的因果学生模型中。我们表明,这种非对称蒸馏策略显著减少了自回归推理过程中的误差累积。这使得我们能够支持自回归地生成比训练时所见视频长得多的视频。
大量实验表明,我们的模型在视频质量上可与最先进的双向扩散模型相媲美,同时具备更强的交互性和更快的速度。据我们所知,这是首个在生成质量上能够与双向扩散竞争的自回归视频生成方法(见附录图 11 和图 12)。此外,我们还展示了该方法在图像到视频生成、视频到视频转换以及动态提示等任务中的通用性,而这些都可以在极低延迟下实现(图 2)。

图 2. 我们的方法支持多种视频生成任务。模型既可以仅根据单个文本提示生成视频(第一行),也可以在额外图像输入的条件下生成视频(第二行)。我们的方法还支持低延迟响应用户输入的交互式应用。例如,它可以为一个能够根据用户输入实时响应的基础游戏引擎渲染结果添加真实的纹理和光照(第三行)。此外,它还支持动态提示(第四行),允许用户在视频的任意时刻输入新的提示,从而构建具有持续演化动作与环境的长篇叙事。
2. Related Work
自回归视频生成。鉴于视频数据天然具有时间顺序,将视频生成建模为自回归过程是很自然的。早期研究使用回归损失 20, 49 或 GAN 损失 38, 58, 80, 83 来监督帧预测任务。受 LLM 6 成功的启发,一些工作选择将视频帧离散化为 token,并使用自回归 Transformer 逐个生成 token 18, 37, 43, 88, 92, 97。然而,这种方法计算开销较大,因为每一帧通常包含数千个 token。近年来,扩散模型已成为视频生成的一种有前景的方法。尽管大多数视频扩散模型具有双向依赖 5, 63, 98, 111,基于扩散模型的自回归视频生成也已被探索。一些工作 1, 29, 81, 106 训练视频扩散模型在给定上下文帧的情况下对新帧去噪。另一些工作 8, 34, 70 则在不同帧具有不同噪声水平的设定下,训练模型对整个视频进行去噪。因此,它们支持将当前帧噪声高于前面帧的情形作为一种特殊的自回归采样方式。还有一些工作探索了将预训练的文生图 36, 42, 81, 90 或文生视频 17, 23, 34, 93, 95 扩散模型适配为以上下文帧为条件,从而实现自回归视频生成。我们的方法与这一研究路线密切相关,不同之处在于我们通过扩散蒸馏引入了一种新的适配方法,显著提升了效率,并使自回归方法在视频生成上能够与双向扩散相竞争。
长视频生成。生成长视频和可变长度视频仍然是一项具有挑战性的任务。一些工作 12, 65, 79, 84, 85, 104, 108 使用在固定且有限长度视频片段上预训练的视频扩散模型,同时生成多个相互重叠的视频片段,并采用各种技术来保证时间一致性。另一种方法是分层生成长视频,先生成稀疏关键帧,再在它们之间进行插值 100, 109。与被训练为生成固定长度视频的整段视频扩散模型不同,自回归模型 17, 23, 29, 43, 88, 93 天然适合生成各种长度的视频,尽管它们在生成长序列时可能遭受误差累积。我们发现,带有双向教师的分布匹配目标对于减少误差累积有着出人意料的帮助,从而实现了高效且高质量的长视频生成。
扩散蒸馏。扩散模型通常需要大量去噪步骤才能生成高质量样本,这在计算上代价较高 24, 75。蒸馏技术通过模仿教师扩散模型的行为,训练学生模型以更少的步骤生成样本 30, 53, 60, 67, 71, 72, 78, 96, 102。Luhman 等人 53 训练单步学生网络,以逼近 DDIM 教师模型 75 得到的噪声到图像映射。Progressive Distillation 71 则训练一系列学生模型,在每个阶段将步数减半。Consistency Distillation 22, 33, 54, 76, 78 训练学生将 ODE 轨迹上的任意点映射到其起点。Rectified flow 15, 47, 48 在教师提供的噪声-图像对的线性插值路径上训练学生模型。对抗损失 19 也被使用,有时与其他方法结合,以提升学生输出的质量 30, 45, 72, 96, 101。DMD 101, 102 优化一个近似的反向 KL 散度 16, 55, 89, 99,其梯度可表示为两个 score function 之差,这两个 score function 分别在数据分布和生成器输出分布上训练。与保持轨迹的方法 33, 48, 71 不同,DMD 在分布层面提供监督,并具有一个独特优势:允许教师扩散模型和学生扩散模型采用不同的架构形式。我们的方法正是建立在 DMD 的有效性与灵活性之上,通过从双向教师扩散模型中蒸馏来训练一个自回归生成器。
近年来,研究者已开始将蒸馏方法应用于视频扩散模型,例如 progressive distillation 44、consistency distillation 40, 57, 86, 87 和 adversarial distillation 57, 107。大多数方法聚焦于蒸馏用于生成短视频(少于 2 秒)的模型。此外,它们通常关注将非因果教师蒸馏为同样非因果的学生。相比之下,我们的方法将非因果教师蒸馏为因果学生,从而支持流式视频生成。我们的生成器在 10 秒视频上训练,并且可以通过滑动窗口推理生成无限长的视频。还有另一类工作关注通过系统层面的优化(例如缓存和并行化)来提升视频扩散模型的效率 46, 105, 110, 114。然而,这些方法通常应用于标准的多步扩散模型,并且可以与我们的方法结合,以进一步提升吞吐量和降低延迟。
3. Background
本节介绍了视频扩散模型(第 3.1 节)和分布匹配蒸馏(第 3.2 节)的背景知识,我们的方法正是建立在这两者之上。
3.1. Video Diffusion Models
扩散模型 24, 74 通过对初始从高斯分布 p ( x T ) p(x_T) p(xT) 中采样得到的样本逐步去噪,从数据分布 p ( x 0 ) p(x_0) p(x0) 中生成样本。它们通过向来自数据分布的样本 x 0 x_0 x0 添加随机噪声 ϵ \epsilon ϵ 所构造出的样本来进行训练:
x t = α t x 0 + σ t ϵ , ϵ ∼ N ( 0 , I ) , x_t=\alpha_t x_0+\sigma_t \epsilon,\ \epsilon\sim \mathcal{N}(0,I), xt=αtx0+σtϵ, ϵ∼N(0,I),
其中, α t , σ T > 0 \alpha_t,\sigma_T>0 αt,σT>0 是标量,它们在步骤 t t t 处根据特定的噪声调度 31, 35, 77 共同定义信噪比。参数为 θ \theta θ 的去噪器通常被训练为预测噪声 24
L ( θ ) = E t , x 0 , ϵ ∥ ϵ θ ( x t , t ) − ϵ ∥ 2 2 . \mathcal{L}(\theta)=\mathbb{E}{t,x_0,\epsilon}\left\|\epsilon\theta(x_t,t)-\epsilon\right\|_2^2. L(θ)=Et,x0,ϵ∥ϵθ(xt,t)−ϵ∥22.
其他预测目标还包括干净图像 x 0 x_0 x0 31, 71,或者 x 0 x_0 x0 与 ϵ \epsilon ϵ 的加权组合,即所谓的 v-prediction 71。所有这些预测方案本质上都与 score function 有关,后者表示分布对数概率的梯度 35, 77:
s θ ( x t , t ) = ∇ x t log p ( x t ) = − ϵ θ ( x t , t ) σ t . s_\theta(x_t,t)=\nabla_{x_t}\log p(x_t)=-\frac{\epsilon_\theta(x_t,t)}{\sigma_t}. sθ(xt,t)=∇xtlogp(xt)=−σtϵθ(xt,t).
在接下来的章节中,我们通过使用 score function s θ s_\theta sθ 来简化记号,将其作为扩散模型的一般表示,同时指出它可以通过对任意预测方案的预训练模型进行重参数化而得到。在推理阶段,我们从完全高斯噪声 x T x_T xT 出发,逐步应用扩散模型,生成一系列越来越干净的样本。存在多种可能的采样方法 31, 52, 75, 103,可以基于预测噪声 ϵ θ ( x t , t ) \epsilon_\theta(x_t,t) ϵθ(xt,t),从当前时刻的样本 x t x_t xt 计算下一时间步的样本 x t − 1 x_{t-1} xt−1。
扩散模型既可以在原始数据 24, 28, 31 上训练,也可以在通过变分自编码器(VAE)32, 61, 68, 98, 111 获得的低维潜空间中训练。后者通常被称为潜扩散模型(LDMs),并已成为对视频这类高维数据进行建模的标准方法 4, 26, 98, 111, 113。自编码器通常会同时压缩视频的空间维度和时间维度,从而使扩散模型更易于学习。视频扩散模型中的去噪网络可以由不同的神经网络架构来实例化,例如 U-Net 10, 25, 69, 113 或 Transformer 5, 26, 82, 98。
3.2. Distribution Matching Distillation
分布匹配蒸馏是一种旨在将缓慢的多步教师扩散模型蒸馏为高效的少步学生模型的技术 101, 102。其核心思想是在随机采样的时间步 t t t 上,最小化平滑后的数据分布 p d a t a ( x t ) p_{\mathrm{data}}(x_t) pdata(xt) 与学生生成器输出分布 p g e n ( x t ) p_{\mathrm{gen}}(x_t) pgen(xt) 之间的反向 KL 散度。反向 KL 的梯度可以近似表示为两个 score function 之差:
∇ ϕ L D M D ≜ E t ( ∇ ϕ K L ( p g e n , t ∥ p d a t a , t ) ) ≈ − E t ( ∫ ( s d a t a ( Ψ ( G ϕ ( ϵ ) , t ) , t ) − s g e n , ξ ( Ψ ( G ϕ ( ϵ ) , t ) , t ) ) d G ϕ ( ϵ ) d ϕ d ϵ ) , \nabla_\phi \mathcal{L}{\mathrm{DMD}} \triangleq \mathbb{E}t\left(\nabla\phi \mathrm{KL}(p{\mathrm{gen},t}\|p_{\mathrm{data},t})\right) \approx -\mathbb{E}t\left( \int \left( s{\mathrm{data}}\!\left(\Psi(G_\phi(\epsilon),t),t\right)- s_{\mathrm{gen},\xi}\!\left(\Psi(G_\phi(\epsilon),t),t\right) \right) \frac{dG_\phi(\epsilon)}{d\phi}\, d\epsilon \right), ∇ϕLDMD≜Et(∇ϕKL(pgen,t∥pdata,t))≈−Et(∫(sdata(Ψ(Gϕ(ϵ),t),t)−sgen,ξ(Ψ(Gϕ(ϵ),t),t))dϕdGϕ(ϵ)dϵ),
其中, Ψ \Psi Ψ 表示式 1 中定义的前向扩散过程, ϵ \epsilon ϵ 是随机高斯噪声, G ϕ G_\phi Gϕ 是由 ϕ \phi ϕ 参数化的生成器, s d a t a s_{\mathrm{data}} sdata 和 s g e n , ξ s_{\mathrm{gen},\xi} sgen,ξ 分别表示在数据分布和生成器输出分布上训练得到的 score function,它们通过去噪损失(式 2)进行训练。
在训练过程中,DMD 102 从一个预训练扩散模型初始化这两个 score function。数据分布对应的 score function 保持冻结,而生成器分布对应的 score function 则使用生成器的输出在线训练。同时,生成器接收梯度,以使其输出与数据分布对齐(式 4)。DMD2 101 通过将纯随机噪声输入 ϵ \epsilon ϵ 替换为部分去噪的中间图像 x t x_t xt,将这一框架从单步生成扩展到了多步生成。
4. Methods
我们的方法引入了一种自回归扩散 Transformer,以实现顺序式视频生成(第 4.1 节)。我们在图 3 中展示了训练流程,该流程采用非对称蒸馏(第 4.2 节)和 ODE 初始化(第 4.3 节),从而实现高生成质量和稳定收敛。我们还通过 KV cache 机制(第 4.4 节)实现了高效的流式推理。
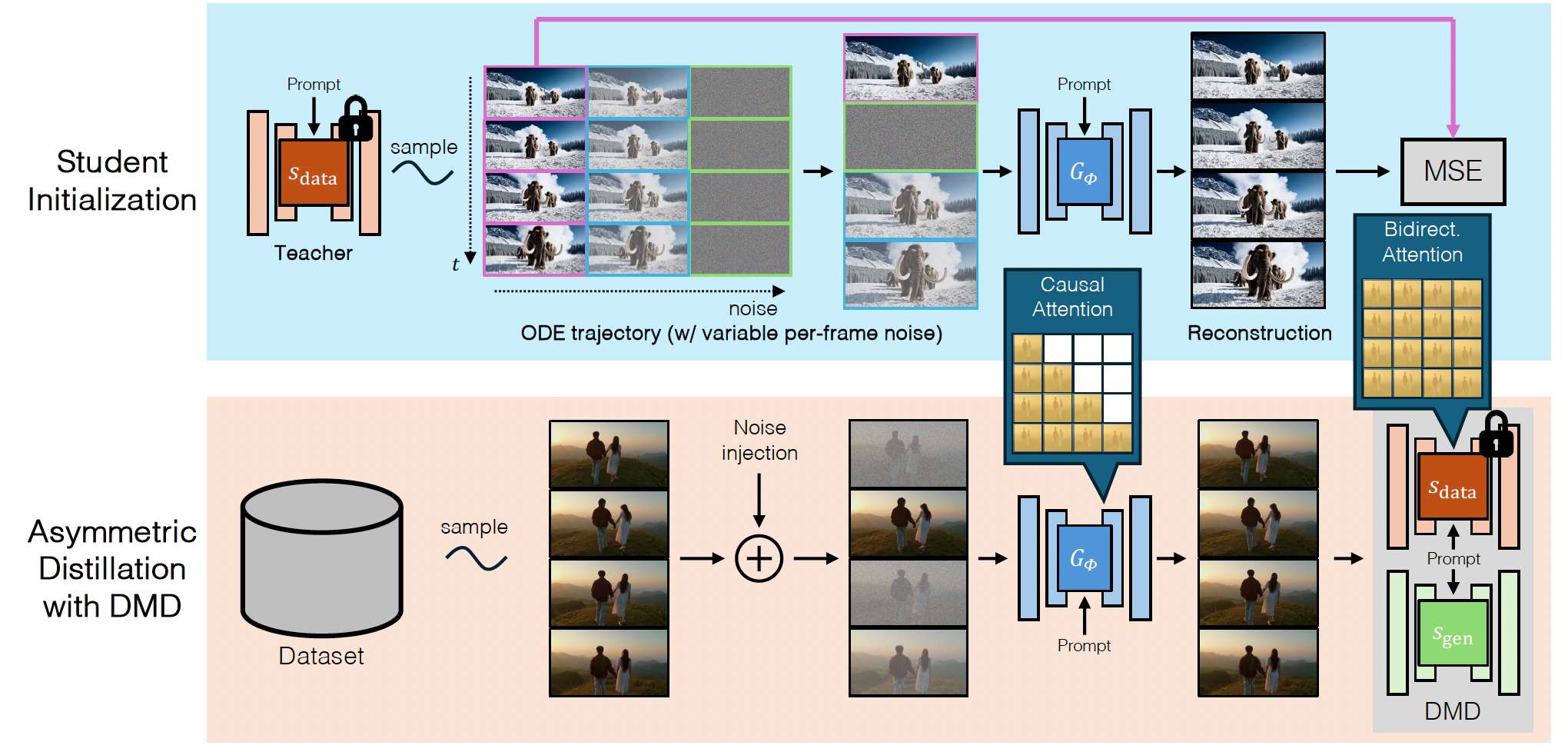
图 3。我们的方法将一个多步、双向的视频扩散模型 s d a t a s_{\mathrm{data}} sdata 蒸馏为一个 4 步的因果生成器 G ϕ G_\phi Gϕ。训练过程包含两个阶段。(上)学生初始化:我们通过在由双向教师生成的一小组 ODE 解对上进行预训练,来初始化因果学生模型(第 4.3 节)。这一步有助于稳定后续的蒸馏训练。(下)非对称蒸馏:我们利用双向教师,通过分布匹配蒸馏损失来训练因果学生生成器(第 4.2 节)。
4.1. Autoregressive Architecture
我们首先使用一个 3D VAE 将视频压缩到潜空间中。VAE 编码器独立地处理每个视频帧块,将其压缩为更短的潜帧块。随后,解码器从每个潜块中重建原始视频帧。我们的因果扩散 Transformer 在这一潜空间中工作,按顺序生成潜帧。我们设计了一种块级因果注意力机制,受到了此前将自回归模型与扩散相结合的工作 39, 41, 50, 112 的启发。在每个块内部,我们在潜帧之间应用双向自注意力,以捕获局部时间依赖并保持一致性。为了施加因果性,我们在块之间应用因果注意力。这会阻止当前块中的帧关注未来块中的帧。我们的自回归扩散 Transformer 架构的可视化示意见附录图 6。由于 VAE 解码器仍然至少需要一个潜帧块来生成像素,因此我们的设计保持了与完全因果注意力相同的延迟。形式上,我们将注意力掩码 M M M 定义为
M i , j = { 1 , if ⌊ j k ⌋ ≤ ⌊ i k ⌋ , 0 , otherwise . M_{i,j}= \begin{cases} 1, & \text{if } \left\lfloor \frac{j}{k} \right\rfloor \le \left\lfloor \frac{i}{k} \right\rfloor, \\ 0, & \text{otherwise}. \end{cases} Mi,j={1,0,if ⌊kj⌋≤⌊ki⌋,otherwise.
其中, i i i 和 j j j 表示序列中的帧索引, k k k 是块大小, ⌊ ⋅ ⌋ \lfloor\cdot\rfloor ⌊⋅⌋ 表示向下取整函数。
我们的扩散模型 G ϕ G_\phi Gϕ 将 DiT 架构 61 扩展到了自回归视频生成。我们在自注意力层中引入了块级因果注意力掩码(如图 3 所示),同时保留其核心结构,从而能够利用预训练的双向权重来加快收敛。
4.2. Bidirectional ⇒ Causal Generator Distillation
一种直接的训练少步因果生成器的方法,是从一个因果教师模型进行蒸馏。这需要通过引入上述因果注意力机制并使用去噪损失(式 2)进行微调,将一个预训练的双向 DiT 模型改造为因果模型。在训练过程中,模型输入为一个由 N N N 个带噪视频帧组成并被划分为 L L L 个块的序列 { x t i } i = 1 L \{x_t^i\}_{i=1}^L {xti}i=1L,其中 i ∈ { 1 , 2 , ... , L } i\in\{1,2,\ldots,L\} i∈{1,2,...,L} 表示块索引。每个块 x t i x_t^i xti 都有其各自的噪声时间步 t i ∼ 0 , 999 t^i\sim0,999 ti∼0,999,遵循 Diffusion Forcing 8。在推理时,模型按顺序对每个块进行去噪,并以先前已生成的干净帧块为条件。尽管理论上蒸馏这一经过微调的自回归扩散教师模型似乎很有前景,但我们的初步实验表明,这种朴素方法会得到次优结果。由于因果扩散模型通常表现不如其双向对应模型,从一个较弱的因果教师训练学生模型会天然限制学生模型的能力。此外,误差累积等问题也会从教师传播到学生。为了克服因果教师的局限,我们提出了一种非对称蒸馏方法:遵循最先进的视频模型 5, 63,我们在教师模型中使用双向注意力,同时将学生模型约束为因果注意力(图 3 下)。算法 1 详细描述了我们的训练过程。

4.3. Student Initialization
由于架构差异,直接使用 DMD 损失训练因果学生模型可能会不稳定。为了解决这一问题,我们引入了一种高效的初始化策略来稳定训练(图 3 上)。
我们构建了一个由双向教师模型生成的小规模 ODE 解对数据集:
- 从标准高斯分布 L ( 0 , I ) \mathcal{L}(0,I) L(0,I) 中采样一组噪声输入序列 { x T i } i = 1 L \{x_T^i\}_{i=1}^L {xTi}i=1L。
- 使用预训练的双向教师模型,通过常微分方程(ODE)求解器 75 模拟反向扩散过程,以获得对应的 ODE 轨迹 { x t i } i = 1 L \{x_t^i\}_{i=1}^L {xti}i=1L,其中 t t t 从 T T T 变化到 0,覆盖所有推理时间步。
从这些 ODE 轨迹中,我们选择与学生生成器所使用时间步相匹配的一组 t t t 值。随后,学生模型在该数据集上通过如下回归损失进行训练:
L i n i t = E x , t i ∥ G ϕ ( { x t i i } i = 1 N , { t i } i = 1 N ) − { x 0 i } i = 1 N ∥ 2 , \mathcal{L}{\mathrm{init}}= \mathbb{E}{x,t^i} \left\| G_\phi(\{x_{t^i}^i\}{i=1}^N,\{t^i\}{i=1}^N)-\{x_0^i\}_{i=1}^N \right\|^2, Linit=Ex,ti Gϕ({xtii}i=1N,{ti}i=1N)−{x0i}i=1N 2,
其中少步生成器 G ϕ G_\phi Gϕ 由教师模型初始化。我们的 ODE 初始化在计算上是高效的,只需要在相对较少的 ODE 解对上进行少量训练迭代。
4.4. Efficient Inference with KV Caching
在推理过程中,我们使用带有 KV cache 的自回归扩散 Transformer 按顺序生成视频帧,以实现高效计算 6。我们在算法 2 中展示了详细的推理流程。值得注意的是,由于我们采用了 KV cache,推理阶段不再需要块级因果注意力。这使得我们能够利用一种快速的双向注意力实现 13。

5. Experiments
模型。我们的教师模型是一个双向 DiT 61,其架构与 CogVideoX 98 类似。该模型在由一个 3D VAE 产生的潜空间上进行训练,该 VAE 将 16 帧视频编码为一个由 5 个潜在帧组成的潜在块。该模型在分辨率为 352 × 640、帧率为 12 FPS 的 10 秒视频上进行训练。我们的学生模型与教师模型具有相同的架构,不同之处在于它采用因果注意力,其中每个 token 只能关注同一块内以及前面各块中的其他 token。每个块包含 5 个潜在帧。在推理时,它一次生成一个块,使用 4 步去噪,推理时间步均匀采样为 999 , 748 , 502 , 247 999, 748, 502, 247 999,748,502,247。我们使用 FlexAttention 21 来提高训练期间注意力计算的效率。
训练。我们遵循 CogVideoX 98,使用混合的图像和视频数据集来蒸馏我们的因果学生模型。图像和视频基于安全性和美学分数进行筛选 73。所有视频都被调整大小并裁剪到训练分辨率 ( 352 × 640 ) (352 \times 640) (352×640),我们使用来自一个内部数据集的大约 400K 个单镜头视频,并且我们对该数据集拥有完整版权。在训练过程中,我们首先生成 1000 个 ODE 对(第 4.3 节),并使用 AdamW 51 优化器和 5 × 10 − 6 5 \times 10^{-6} 5×10−6 的学习率对学生模型训练 3000 次迭代。之后,我们使用不对称 DMD 损失(第 4.2 节),配合 AdamW 优化器和 2 × 10 − 6 2 \times 10^{-6} 2×10−6 的学习率训练 6000 次迭代。我们使用 3.5 的 guidance scale,并采用来自 DMD2 101 的双时间尺度更新规则,其比率为 5。整个训练过程在 64 张 H100 GPU 上大约耗时 2 天。
评估。我们的方法在 VBench 27 上进行评估,这是一个用于视频生成的基准,设计了 16 个指标来系统性评估运动质量和语义对齐。对于我们的主要结果,我们使用来自 MovieGen 63 的前 128 条提示词来生成视频,并在 VBench 竞赛评测套件的三个主要方面上评估模型性能。使用 VBench 全部提示词的综合评估结果见附录。推理时间是在一张 H100 GPU 上测得的。
5.1. Text to Video Generation
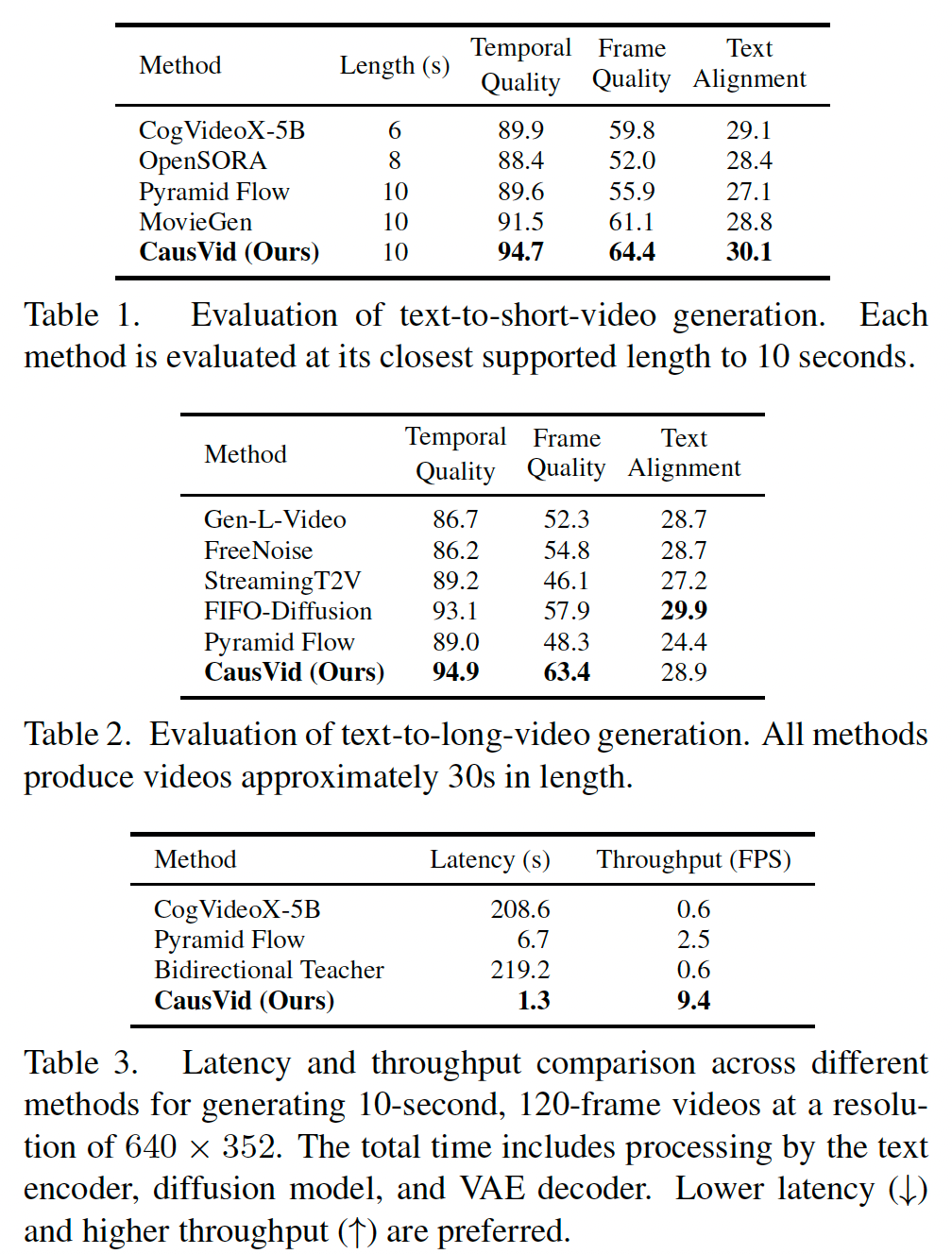
我们评估了我们的方法生成短视频(5 到 10 秒)的能力,并将其与当前最先进的方法进行比较:CogVideoX 98、OpenSORA 111、Pyramid Flow 29 和 MovieGen 63。如表 1 所示,我们的方法在三个关键指标上均优于所有基线方法:时间质量、帧质量和文本对齐。我们的模型取得了最高的时间质量分数 94.7,表明其在运动一致性和动态质量方面表现更优。此外,我们的方法在帧质量和文本对齐方面也有显著提升,得分分别为 64.4 和 30.1。在补充材料中,我们展示了我们的方法在 VBench-Long 排行榜上的表现,总分达到 84.27,并在所有经过官方评测的视频生成模型中位列第一。
我们还通过一项人工偏好研究进一步评估了模型性能。我们从 MovieGenBench 数据集中选取前 29 个提示,并通过 Prolific 平台收集独立评估者的评分。对于每一对被比较的模型以及每个提示,我们从不同评估者处收集 3 个评分,因此每个模型对总计得到 87 个评分。评估者根据视觉质量以及与输入提示在语义上的一致性,在两段生成视频之间选择更优者。具体问题和界面见附录图 9。为保证可复现性,我们对所有视频都使用固定的随机种子 0。如附录图 8 所示,我们的模型始终优于 MovieGen、CogVideoX 和 Pyramid Flow 等基线方法。值得注意的是,我们的蒸馏模型在提供数量级更快推理速度的同时,仍然保持了与双向教师模型相当的性能,这验证了我们方法的有效性。
我们还将我们的方法与先前为长视频生成而设计的工作进行了比较:Gen-L-Video 84、FreeNoise 65、StreamingT2V 23、FIFO-Diffusion 34 和 Pyramid Flow 29。我们采用滑动窗口推理策略,将前一个 10 秒片段的最后几帧作为上下文,用于生成下一个片段。相同的策略也被用于使用 Pyramid Flow 生成长视频。表 2 显示,我们的方法在时间质量和逐帧质量方面优于所有基线方法,并且在文本对齐方面具有竞争力。它还能够成功防止误差累积。如图 4 所示,我们的方法能够随着时间推移保持图像质量,而大多数自回归基线方法都会出现质量退化 8, 23, 29。
表 3 将我们的方法与竞争方法 29, 98 以及我们的双向教师扩散模型在效率方面进行了比较。与规模相近的 CogVideoX 98 相比,我们的方法将延迟降低了 160 倍,并将吞吐量提升了 16 倍。
5.2. Ablation Studies
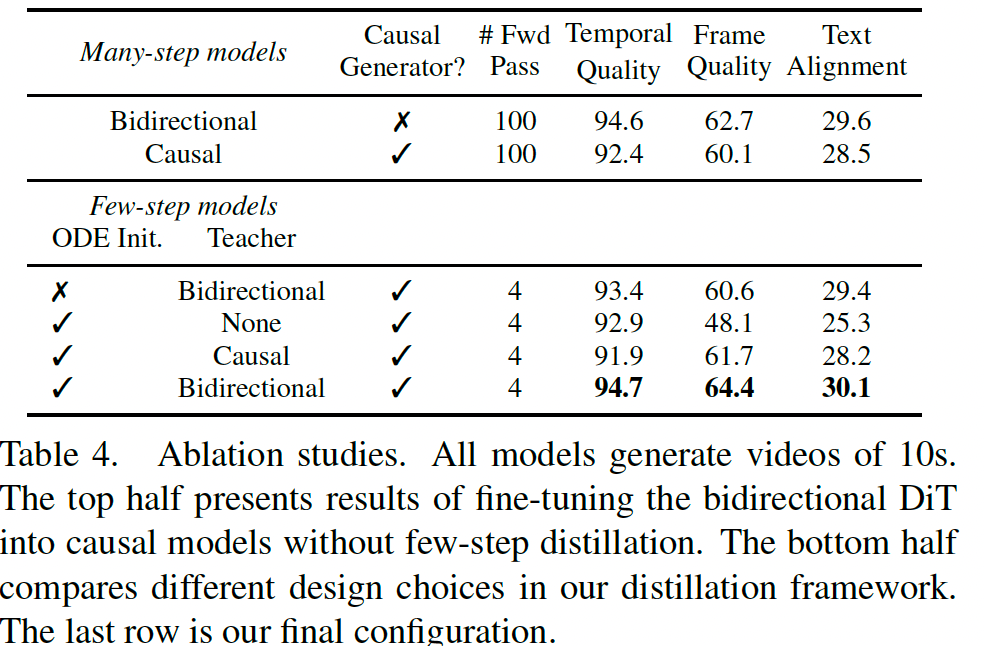
首先,我们给出了在不使用少步蒸馏的情况下,直接将双向 DiT 微调为因果模型的结果。我们对模型施加因果注意力掩码,并采用第 4.2 节中描述的自回归训练方法对其进行微调。如表 4 所示,多步因果模型的表现明显差于原始的双向模型。我们观察到,因果基线方法会遭受误差累积,导致生成质量随着时间快速下降(图 4 中的橙色曲线)。
随后,我们对蒸馏框架进行了消融研究,考察了学生模型的初始化方案以及教师模型的选择。表 4 表明,在相同的 ODE 初始化方案下(如第 4.3 节所述),双向教师模型优于因果教师模型,也明显优于初始的 ODE 拟合模型(其中教师记为 None)。如图 4 所示,因果扩散教师会遭受显著的误差累积(橙色),并进一步传递到学生模型中(绿色)。相比之下,我们发现,使用非对称 DMD 损失并结合双向教师训练得到的因果学生模型(蓝色),其表现明显优于多步因果扩散模型,这突出了蒸馏对于同时实现快速且高质量视频生成的重要性。在相同的双向教师条件下,我们证明,通过拟合 ODE 对来初始化学生模型,还可以进一步提升性能。尽管我们的学生模型在逐帧质量上优于双向教师模型,但在时间闪烁和输出多样性方面表现较差。更详细的讨论见补充材料。
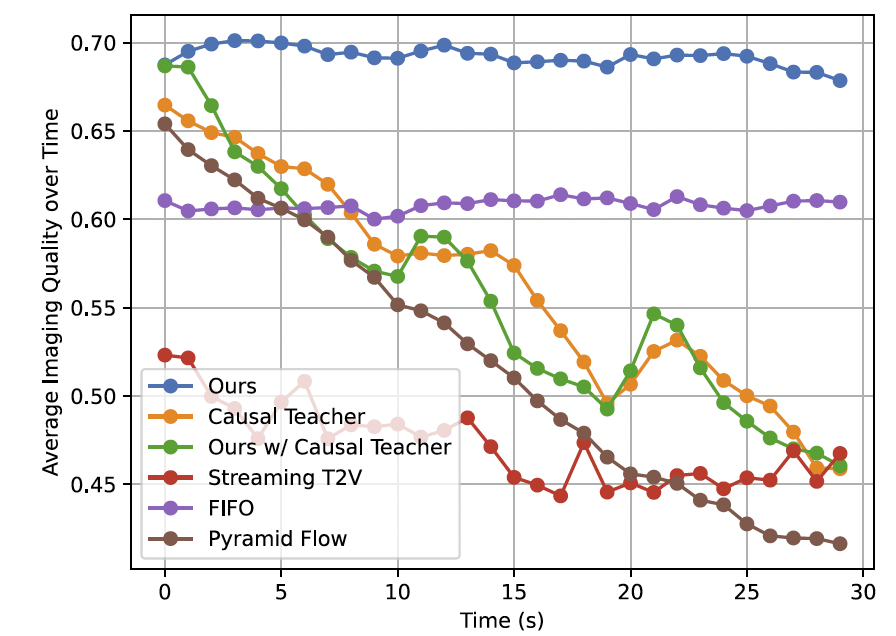
图 4. 生成视频在 30 秒时长上的成像质量得分。我们的蒸馏模型和 FIFO-Diffusion 在随时间保持成像质量方面最为有效。因果教师模型在约 20 秒处得分突然上升,是由于滑动窗口发生切换,从而带来了暂时性的质量提升。
5.3. Applications
除了文本到视频生成之外,我们的方法还支持广泛的其他应用。下面我们给出定量结果,定性样例见图 2。我们还在补充材料中提供了更多视频结果。
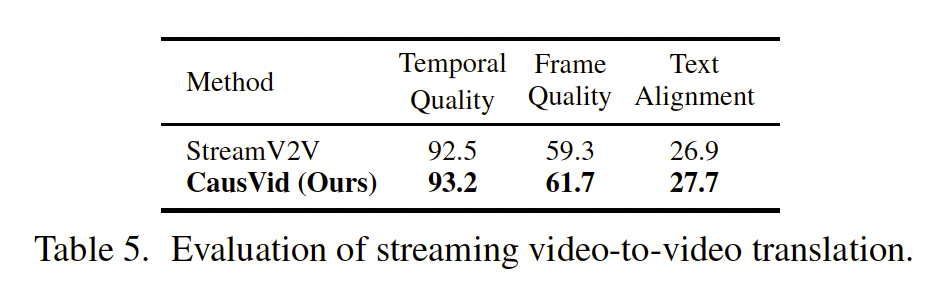
流式视频到视频翻译。我们在流式视频到视频翻译任务上评估了我们的方法,该任务旨在编辑一个帧数可以无限长的流式视频输入。受 SDEdit 59 启发,我们向每个输入视频块中注入与时间步 t 1 t_1 t1 对应的噪声,然后在文本条件下用一步去噪对其进行处理。我们将我们的方法与 StreamV2V 42 进行比较,后者是该任务中一种最先进的方法,建立在图像扩散模型之上。在 StreamV2V 用户研究所使用的 67 个视频-提示对(最初来自 DAVIS 64 数据集)中,我们选取了其中所有至少包含 16 帧的 60 个视频。为保证公平比较,我们对两种方法都不进行任何特定概念的微调。表 5 显示,我们的方法优于 StreamV2V,这表明由于模型中的视频先验,我们的方法具有更好的时间一致性。
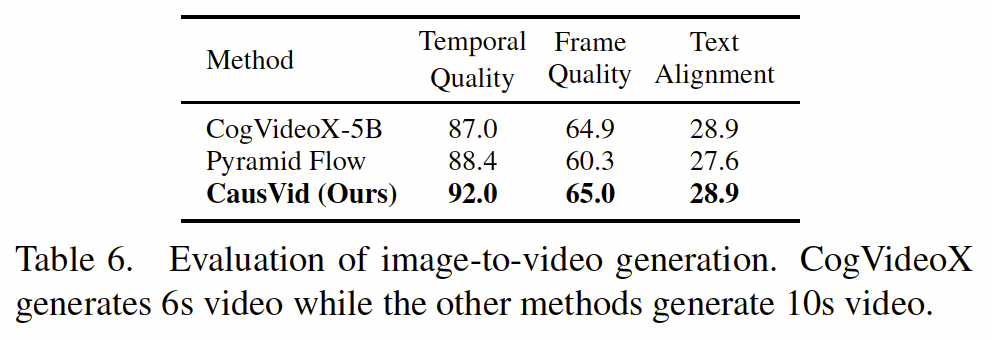
图像到视频生成。我们的模型无需任何额外训练,就可以执行文本条件控制的图像到视频生成。给定一个文本提示和一张初始图像,我们复制该图像以构造第一段帧序列。随后,模型以自回归方式生成后续帧,从而扩展视频。尽管这种方法很简单,我们仍然取得了令人信服的结果。我们在 VBench-I2V 基准上将其与 CogVideoX 98 和 Pyramid Flow 29 进行比较,因为它们是能够生成 6--10 秒视频的主要基线方法。如表 6 所示,我们的方法优于现有方法,并且在动态质量方面有显著提升。我们认为,使用少量图像到视频数据进行指令微调,还可以进一步提升我们模型的性能。