HiAR:基于分层去噪的高效自回归长视频生成
paper title:HiAR: Efficient Autoregressive Long Video Generation via Hierarchical Denoising
paper是USTC发布在Arxiv 2026的工作
Code:链接
Abstract
自回归(AR)扩散为生成理论上无限长的视频提供了一个极具前景的框架。然而,一个主要的挑战是在保持时间连续性的同时,防止由误差积累引起的渐进式质量退化。为了确保连续性,现有方法通常以高度去噪的上下文为条件;然而,这种做法以极高的确定性传播了预测误差,从而加剧了质量退化。在本文中,我们认为高度干净的上下文是不必要的。受双向扩散模型的启发(该模型在共享的噪声水平下去噪帧,同时保持连贯性),我们提出,以与当前块处于相同噪声水平的上下文为条件,可以为时间一致性提供足够的信号,同时有效地缓解误差传播。基于这一见解,我们提出了HiAR,这是一个分层去噪框架,它颠覆了传统的生成顺序:它不再按顺序逐块完成生成,而是在每个去噪步骤中跨所有块执行因果生成,使得每个块始终以相同噪声水平的上下文为条件。这种层次结构自然允许流水线式的并行推理,在我们的4步设置中产生了 ∼ 1.8 × \sim 1.8\times ∼1.8×的挂钟加速。我们进一步观察到,在这种范式下的自展开蒸馏放大了一种低运动捷径,这种捷径是寻求模式(mode-seeking)的反向KL(reverse-KL)目标所固有的。为了对抗这种情况,我们在双向注意力模式中引入了一个正向KL(forward-KL)正则化器,它在不干扰蒸馏损失的情况下,为因果推理保留了运动多样性。在VBench(20秒生成)上,HiAR在所有比较方法中取得了最好的总体得分和最低的时间漂移。
1 Introduction
近年来,视频生成领域取得了快速进展,Diffusion Transformer (DiT) Peebles and Xie 2023 主干网络为强大的基础模型 Ho et al. 2022, Blattmann et al. 2023, Yang et al. 2024, Polyak et al. 2024, Zheng et al. 2024, Team 2025, Brooks et al. 2024 提供了动力,并且条件范式------包括图生视频和视频生视频------进一步拓宽了可控生成的范围。一个遗留的前沿领域是长时域(long-horizon),以及最终的开放式视频生成,这对于交互式智能体和世界模型 He et al. 2025, Ye et al. 2025, Mao et al. 2025, Sun et al. 2025, Hong et al. 2025, Tang et al. 2026 至关重要。为了扩展视频时长,因果自回归(AR)生成 Wu et al. 2025, Jin et al. 2024b, Teng et al. 2025a, Chen et al. 2025a 变得越来越具有吸引力:它支持流式输出、无限延伸和实时交互。
然而,这种流水线中的一个关键挑战是在连续的视频块之间保持严格的时间连续性,同时防止由误差累积引起的分布漂移(例如,过饱和、过度锐化、运动重复和语义漂移)。为了确保时间连贯性,现有方法主要在生成下一帧之前将先前的帧去噪为高度干净的上下文。因此,当前块的每个去噪步骤都以噪声水平 t c = 0 t_c = 0 tc=0(最大信噪比)的上下文为条件。虽然这种高度干净的上下文锚定了时间一致性,但它无意中导致模型以高置信度向前传播累积的预测误差,从而加剧了退化,如图 1(b) 所示。
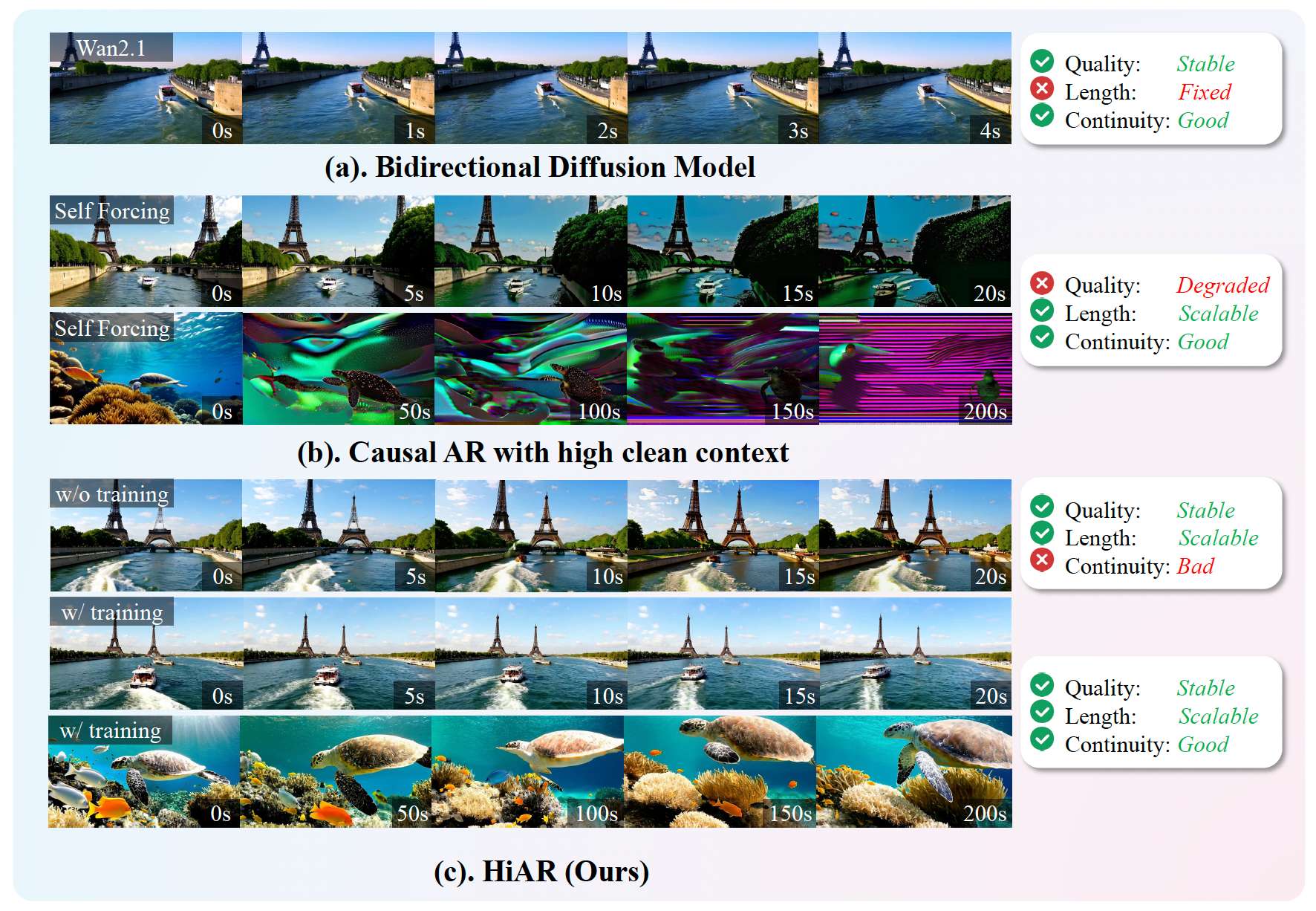
图1:动机。(a) 双向扩散 (Wan2.1) 证明了共享的噪声水平为时间连贯性提供了足够的上下文,尽管其受限于固定的时间范围。(b) 标准自回归 (Self-Forcing) 扩展了生成长度,但会遭受质量漂移,因为以完全干净的上下文为条件会放大误差传播。© 仅在推理阶段(无训练,w/o training)应用我们的分层去噪(匹配噪声的上下文)可以缓解漂移,但由于训练和测试的不匹配会破坏连续性;HiAR 在分层流水线下重新进行了训练(有训练,w/ training),实现了具有稳定质量和无缝连续性的可扩展长视频生成。
在这项工作中,我们认识到高度干净的上下文并不是先决条件。受双向扩散模型的启发,该模型在共享的噪声水平上同时对所有帧进行去噪,但仍然产生时间连贯的视频,如图 1(a) 所示,这表明噪声上下文已经为连续性提供了足够的信号,同时减少了误差传播。基于这一原理,我们引入了 HiAR,一种分层去噪范式,它交换了去噪顺序:我们不再首先对先前的块进行完全去噪,而是在每个去噪步骤中跨所有块执行因果生成,然后再移动到下一步。这个简单但根本的改变显着减少了块间的误差传递并提高了长时域稳定性,如图 1(c, w/o training) 所示。此外,分层结构在推理时实现了跨去噪步骤的流水线并行,提高了挂钟效率( × 1.8 \times 1.8 ×1.8)。
为了保持训练-测试的一致性,我们在分层去噪流水线下重新训练。然而,我们发现自展开蒸馏 Anonymous 2025, Yin et al. 2024b 表现出一种低运动捷径,这种捷径在整个训练过程中会恶化------这与 DMD 风格的反向 KL 目标的寻求模式趋势一致 Lu et al. 2025a:模型逐渐崩溃成几乎静态的输出,这些输出使蒸馏损失最小化但牺牲了动态性。分层去噪放大了这种影响,因为以多级噪声上下文为条件的学习难度增加,需要更多的训练步骤。在经验上,我们发现在双向注意力去噪下的运动多样性与在因果自回归推理下的运动多样性强烈相关。受此观察的启发,我们引入了一个基于蒸馏的正向 KL 正则化器,在双向注意力去噪模式下计算,有效地防止了因果推理路径的动态崩溃,并实现了稳定的长步数训练。
我们在 VBench Huang et al. 2024, Zheng et al. 2025 和一个专为长时域展开量身定制的专用漂移指标上进行了广泛的评估,连同彻底的消融实验,证明了 HiAR 产生了更稳定的长视频生成,并验证了每个组件的贡献。视觉结果显示在图 1(c, w/ training) 中。
我们在下面强调本文的主要贡献:
我们提出了 HiAR,一种分层去噪流水线,在每个去噪步骤中跨块执行因果生成,大大减少了块间的误差传递,并实现了跨层级的流水线推理,在我们的实现中获得了 ∼ 1.8 × \sim 1.8\times ∼1.8× 的挂钟加速。
我们通过双向注意力蒸馏引入了一个简单的正向 KL 正则化器,以防止自展开训练中的低运动捷径,从而在保持动态性的同时实现了向长训练计划的稳定扩展。
在 VBench 和专用漂移指标上的广泛实验,连同彻底的消融实验,证明了长时域稳定性以及每个组件的有效性。
2 Background
2.1 Diffusion Models and Flow Matching
基于扩散的生成模型 Ho et al. 2020, Song et al. 2021 学习反转一个前向加噪过程,该过程将数据逐渐破坏为高斯噪声。在这项工作中,我们采用了流匹配(flow matching)公式 Lipman et al. 2023, Liu et al. 2023, Albergo and Vanden-Eijnden 2023。令 x 0 ∼ p data x_0 \sim p_{\text{data}} x0∼pdata 表示干净的数据样本, ϵ ∼ N ( 0 , I ) \epsilon \sim \mathcal{N}(0, I) ϵ∼N(0,I) 表示标准高斯噪声。在连续时间 t ∈ 0 , 1 t \in 0, 1 t∈0,1 处的前向插值(破坏)定义为
x t = ( 1 − σ t ) x 0 + σ t ϵ , σ t = s ⋅ t 1 + ( s − 1 ) ⋅ t , ( 1 ) x_t = (1 - \sigma_t) x_0 + \sigma_t \epsilon, \quad \sigma_t = \frac{s \cdot t}{1 + (s - 1) \cdot t}, \qquad (1) xt=(1−σt)x0+σtϵ,σt=1+(s−1)⋅ts⋅t,(1)
其中 s > 0 s > 0 s>0 是一个控制噪声调度曲率的平移参数。在 t = 0 t = 0 t=0 时,我们恢复出 x 0 x_0 x0;在 t = 1 t = 1 t=1 时,我们得到(近似的)纯噪声。训练一个神经网络 v θ ( x t , t ) v_\theta(x_t, t) vθ(xt,t) 来预测速度场
v ∗ ( x t , t ) = ϵ − x 0 , ( 2 ) v^*(x_t, t) = \epsilon - x_0, \qquad (2) v∗(xt,t)=ϵ−x0,(2)
使得干净数据可以通过从 t = 1 t = 1 t=1 到 t = 0 t = 0 t=0 反向积分概率流常微分方程(probability-flow ODE)来恢复。在实践中,人们将轨迹离散化为 S S S 个步骤 1 = t 1 > t 2 > ⋯ > t S > 0 1 = t_1 > t_2 > \dots > t_S > 0 1=t1>t2>⋯>tS>0,并应用欧拉更新(Euler update)
x t j + 1 = x t j + v θ ( x t j , t j ) ( σ t j + 1 − σ t j ) . ( 3 ) x_{t_{j+1}} = x_{t_j} + v_\theta(x_{t_j}, t_j) (\sigma_{t_{j+1}} - \sigma_{t_j}). \qquad (3) xtj+1=xtj+vθ(xtj,tj)(σtj+1−σtj).(3)
2.2 Autoregressive Video Diffusion
双向注意力扩散模型 OpenAI 2025, Wan et al. 2025, Kling 2025, Google 2025, Runway 2025 在固定的时间窗口上运行,难以轻易扩展到任意持续时间。因果自回归 (AR) 生成 Po et al. 2025, Liu et al. 2025, Lu et al. 2025b, Zhang et al. 2025, Yang et al. 2025, Lin et al. 2025 通过以流式方式生成帧克服了这一限制:它自然支持无限延伸,允许实时干预,并为交互控制提供了一个原则性的接口------使其成为迈向世界模型 He et al. 2025, Ye et al. 2025, Mao et al. 2025 的关键构建块。为了生成超出固定时间窗口的视频,最近的工作将视频潜在序列划分为 N N N 个连续块 { B 1 , ... , B N } \{B_1, \dots, B_N\} {B1,...,BN},每个块包含 k k k 帧,并自回归地生成它们:对于 n = 2 , ... , N n = 2, \dots, N n=2,...,N,块 B n B_n Bn 在以先前生成的块 B < n B_{<n} B<n 为条件的情况下被去噪。
具体而言,令 x t ( n ) x_t^{(n)} xt(n) 表示时间步 t t t 时块 n n n 的含噪潜在变量。去噪器被查询为
v θ ( x t ( n ) , t ∣ c < n ) , ( 4 ) v_\theta(x_t^{(n)}, t \mid c_{< n}), \qquad (4) vθ(xt(n),t∣c<n),(4)
其中 c < n c_{< n} c<n 是通过因果注意力注入的块 B 1 , ... , B n − 1 B_1, \dots, B_{n-1} B1,...,Bn−1 的上下文表示:查询 (query) 词元来自 x t ( n ) x_t^{(n)} xt(n),而键/值 (key/value) 词元包括 c < n c_{< n} c<n。
在教师强制 (teacher forcing) Williams and Zipser 1989, Gao et al. 2024, Hu et al. 2024, Jin et al. 2024a, Zhang et al. 2025 下,训练以真实上下文 ( c < n = x 0 ( < n ) c_{< n} = x_0^{(< n)} c<n=x0(<n)) 为条件,而在推理时, c < n c_{< n} c<n 由模型预测 x ^ 0 ( < n ) \hat{x}_0^{(< n)} x^0(<n) 组成;这种训练-测试不匹配导致每一步的误差沿着自回归链累积------即曝光偏差 (exposure bias) Bengio et al. 2015------表现为渐进式的过饱和、运动重复和语义漂移,统称为分布漂移。Diffusion Forcing Chen et al. 2024, Yin et al. 2025b, Chen et al. 2025b, Gu et al. 2025, Teng et al. 2025b, Song et al. 2025, Po et al. 2025 通过使用独立的每词元噪声水平进行训练来缓解这一问题,使得模型学会了在异构噪声条件下进行去噪,并在推理时获得了对部分含噪上下文的鲁棒性。
Self-Forcing Anonymous 2025, Yin et al. 2024a,c, Yi et al. 2025 通过自展开 (self-rollout) 训练进一步缩小了训练-测试差距:在每次训练迭代中,首先使用学生模型 v θ v_\theta vθ 展开一个块以获得 x ^ 0 ( n − 1 ) \hat{x}_0^{(n-1)} x^0(n−1),然后将其用作下一个块去噪的上下文。训练目标是一个非对称分布匹配蒸馏 (DMD) 损失 Yin et al. 2024b,d,公式化为学生的单步输出分布与教师的多步输出分布之间的反向 KL 散度:
L DMD = E t , x t D K L ( p θ ( x 0 ∣ x t ) ∥ p teacher ( x 0 ∣ x t ) ) , ( 5 ) \mathcal{L}{\text{DMD}} = \mathbb{E}{t, x_t} \left D_{KL}(p_\\theta(x_0 \\mid x_t) \\parallel p_{\\text{teacher}}(x_0 \\mid x_t)) \\right, \qquad (5) LDMD=Et,xtDKL(pθ(x0∣xt)∥pteacher(x0∣xt)),(5)
其中 p θ ( x 0 ∣ x t ) p_\theta(x_0 \mid x_t) pθ(x0∣xt) 表示由学生从 x t x_t xt 开始的单次欧拉步引起的分布,而 p teacher p_{\text{teacher}} pteacher 是通过与教师模型进行多步 ODE 积分获得的分布。这种反向 KL 鼓励学生向教师的高密度区域进行模式寻求 (mode-seek)。在实践中,梯度是通过学生和教师分布之间学习到的分数差异来计算的。虽然 Self-Forcing 在中等时间跨度上取得了显著改善,但它仍然对上下文(即预测的干净帧)采用 t c = 0 t_c = 0 tc=0,以最大置信度传播误差。
3 Method
我们现在将第1节中形成的直觉形式化:上下文噪声水平 t c t_c tc 控制着偏差与信息之间的权衡,而最优选择是 t c ∗ = t j + 1 t_c^* = t_{j+1} tc∗=tj+1------即当前去噪步骤的输出噪声水平。我们首先解析地推导出这个结果,然后以此为基础设计分层去噪。
3.1 Context Noise Level and Error Propagation
误差分解。考虑在步骤 j j j对块 B n B_n Bn进行去噪(从噪声水平 t j t_j tj到 t j + 1 t_{j+1} tj+1)。设 x 0 ( n − 1 ) x_0^{(n-1)} x0(n−1)表示前一块的真实干净潜变量, x ^ 0 ( n − 1 ) = x 0 ( n − 1 ) + δ ( n − 1 ) \hat{x}_0^{(n-1)}=x_0^{(n-1)}+\delta^{(n-1)} x^0(n−1)=x0(n−1)+δ(n−1)表示模型的预测,其中 δ ( n − 1 ) \delta^{(n-1)} δ(n−1)是累积的预测误差。在 AR 扩散中, B n B_n Bn的上下文由 x ^ 0 ( n − 1 ) \hat{x}_0^{(n-1)} x^0(n−1)导出,并以某个噪声水平 t c ∈ 0 , 1 t_c\in0,1 tc∈0,1给出:
c n − 1 ( t c ) = ( 1 − σ t c ) x ^ 0 ( n − 1 ) + σ t c η , η ∼ N ( 0 , I ) . c_{n-1}^{(t_c)}=(1-\sigma_{t_c})\hat{x}0^{(n-1)}+\sigma{t_c}\eta,\qquad \eta\sim\mathcal{N}(0,I). cn−1(tc)=(1−σtc)x^0(n−1)+σtcη,η∼N(0,I).
展开 x ^ 0 ( n − 1 ) \hat{x}_0^{(n-1)} x^0(n−1)后,可将上下文分解为三项:
c n − 1 ( t c ) = ( 1 − σ t c ) x 0 ( n − 1 ) ⏟ 真实信号 + ( 1 − σ t c ) δ ( n − 1 ) ⏟ 传播偏差 + σ t c η ⏟ 随机扰动 . c_{n-1}^{(t_c)}=\underbrace{(1-\sigma_{t_c})x_0^{(n-1)}}{\text{真实信号}}+\underbrace{(1-\sigma{t_c})\delta^{(n-1)}}{\text{传播偏差}}+\underbrace{\sigma{t_c}\eta}_{\text{随机扰动}}. cn−1(tc)=真实信号 (1−σtc)x0(n−1)+传播偏差 (1−σtc)δ(n−1)+随机扰动 σtcη.
真实信号项和传播偏差项共享相同的系数 ( 1 − σ t c ) (1-\sigma_{t_c}) (1−σtc),而随机项携带互补系数 σ t c \sigma_{t_c} σtc。因此,噪声水平 t c t_c tc控制着一种偏差---信息权衡:增大 t c t_c tc会减弱偏差,但同时也会按相同比例削弱有用的条件信号。特别地,先前的 AR 方法 Anonymous 2025 采用 t c = 0 t_c=0 tc=0,这会将式 7 7 7化简为 c n − 1 ( 0 ) = x 0 ( n − 1 ) + δ ( n − 1 ) c_{n-1}^{(0)}=x_0^{(n-1)}+\delta^{(n-1)} cn−1(0)=x0(n−1)+δ(n−1),并且在没有任何衰减的情况下传播全部预测误差。
时间因果性。为了生成在时间上连贯的续写,上下文至少必须携带与当前块在步骤 j j j之后所拥有的一样多的信息。在式 1 1 1下,信噪比
S N R ( t ) = ( 1 − σ t ) 2 σ t 2 \mathrm{SNR}(t)=\frac{(1-\sigma_t)^2}{\sigma_t^2} SNR(t)=σt2(1−σt)2
随着 t t t减小而单调增加,因此在步骤 j j j之后,位于 t j + 1 t_{j+1} tj+1的当前块所包含的信息严格多于位于 t j t_j tj时的信息。因此,时间因果性要求
S N R ( t c ) ≥ S N R ( t j + 1 ) ⟺ t c ≤ t j + 1 . \mathrm{SNR}(t_c)\geq \mathrm{SNR}(t_{j+1}) \Longleftrightarrow t_c\leq t_{j+1}. SNR(tc)≥SNR(tj+1)⟺tc≤tj+1.
任何满足该界的 t c t_c tc都能为步骤 j j j提供足够的信息。由于偏差系数 ( 1 − σ t c ) (1-\sigma_{t_c}) (1−σtc)随 t c t_c tc单调减小,选择 t c < t j + 1 t_c<t_{j+1} tc<tj+1只会传递更多预测误差而没有额外收益。因此,最优解就是该约束边界:
t c ∗ = t j + 1 , t_c^*=t_{j+1}, tc∗=tj+1,
即在仍然满足时间因果性的前提下,选择噪声最大的上下文水平------在保留去噪器在步骤 j j j所需全部信息的同时,减弱块间偏差。
3.2 Hierarchical Denoising
上述分析促成了对自回归去噪流程的一个简单但根本性的改变:我们不再是在进入下一个块之前将每个块完全去噪,而是在每一个去噪步骤上,对所有块执行因果生成。我们将其称为分层去噪(Hierarchical Denoising,见图 2 2 2)。
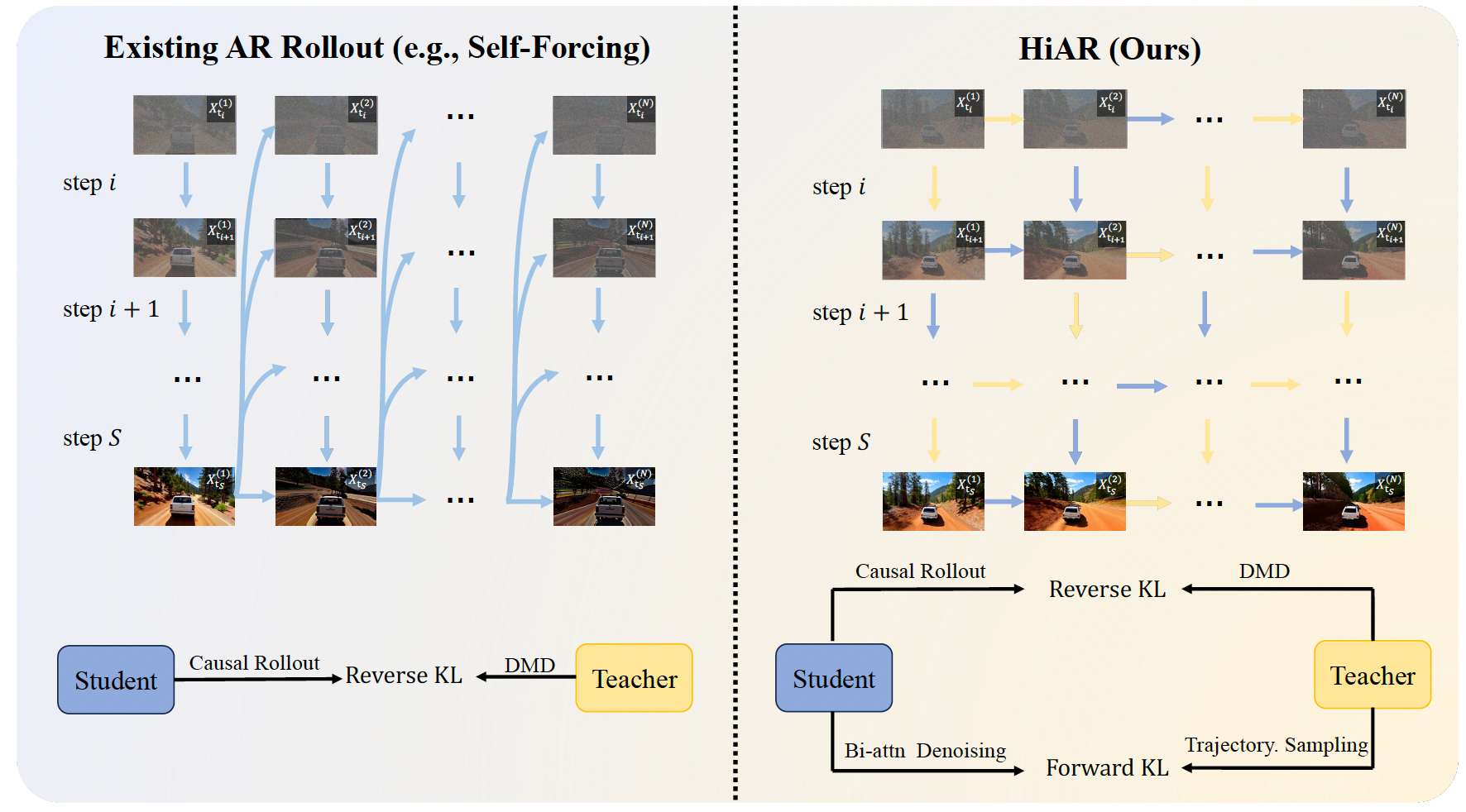
图2:HiAR 概览。左:现有的按块优先的自回归(AR)方法(例如 Self-Forcing)会在生成下一个块之前,先将当前块完全去噪,并在每一步都以预测得到的干净上下文作为条件,因此会放大块间误差传播。右:我们的分层去噪在每个去噪步骤内跨所有块执行因果生成,并在匹配的噪声水平上以上下文为条件,从而抑制误差累积。下:训练阶段结合了用于蒸馏的因果自回滚(causal self-rollout)与反向 KL(DMD)损失,以及在双向注意力模式下通过教师轨迹采样计算的前向 KL 正则项,以保留运动多样性。

推理过程。完整流程总结于算法 1 1 1。在每个步骤 j j j,块 B n B_n Bn在噪声水平 t j + 1 t_{j+1} tj+1下,以块 B < n B_{< n} B<n作为上下文进行去噪------这是仍能保持时间因果性的最噪上下文层级(第 3.1 3.1 3.1节)。
流水线并行性。在算法 1 1 1中,步骤 j j j处的块 B n B_n Bn只依赖于步骤 j j j处的 B < n B_{< n} B<n以及步骤 j − 1 j-1 j−1处的 B n B_n Bn,因此,在 N × S N\times S N×S网格中,位于同一条反对角线上的不同 ( n , j ) (n,j) (n,j)位置的块彼此独立。我们利用这一点,将每个去噪步骤分配给一个专用进程,并沿着该网格的 N + S − 1 N+S-1 N+S−1条反对角线进行遍历,各阶段之间的潜变量通过异步点对点通信进行交换。
在每个阶段内,若采用朴素方式,对块 B n B_n Bn更新 KV cache,以及对块 B n + 1 B_{n+1} Bn+1去噪,是两次彼此独立的前向传播,因此每个阶段总共需要 2 N 2N 2N次。我们观察到,在因果注意力下,这两个操作可以通过沿帧维度拼接 c ( n ) , x t j ( n + 1 ) c\^{(n)}, x_{t_j}\^{(n+1)} c(n),xtj(n+1),并配以逐帧时间步 t j + 1 , ... , t j + 1 , t j , ... , t j t_{j+1}, \\ldots, t_{j+1}, t_j, \\ldots, t_j tj+1,...,tj+1,tj,...,tj,融合为一次前向调用:第一段将 B n B_n Bn的上下文写入 KV cache,而第二段在访问这些刚写入的键和值的同时,对 B n + 1 B_{n+1} Bn+1进行去噪。
这种融合将每个阶段的开销降低到 N + 2 N+2 N+2次传播(第一个块单独去噪 1 1 1次, N − 1 N-1 N−1次融合传播,以及 1 1 1次末尾 cache 写入),从而在我们的 4 4 4步设置中带来整体约 1.8 × 1.8\times 1.8×的实际运行时间加速。
3.3 Training with Forward-KL Regulation
尽管分层去噪已经在测试时缓解了退化问题,但如果模型仍是在传统的按块优先 rollout 下训练的,那么训练与测试之间的鸿沟仍然存在。因此,我们在分层调度下采用 self-rollout 重新训练,并按照 Self-Forcing Anonymous 2025 优化 DMD 的反向 KL 目标(式 5 5 5)。整体训练流程如图 2 2 2(下)所示。
低运动捷径。随着训练推进,时间连贯性有所提升,但运动多样性却发生塌缩:模型越来越倾向于生成近乎静止的视频。其根本原因在于反向 KL 目标的寻模态特性:当学生模型将其概率质量集中在某一个高密度模态上时, D K L ( p θ ∥ p t e a c h e r ) D_{\mathrm{KL}}(p_\theta\|p_{\mathrm{teacher}}) DKL(pθ∥pteacher)会被最小化,因此它可以通过生成低运动输出降低损失,因为这类输出本质上更容易去噪,也更不容易受到 rollout 误差的影响。分层去噪会放大这种捷径,因为在不同噪声水平的上下文上进行条件建模------而不只是干净上下文------会增加学习难度,并需要更多训练步数,从而给这种寻模态目标更多迭代机会,使其塌缩到低运动模态。
通过蒸馏进行前向 KL 正则化。为了抵消这种捷径,我们引入一个互补损失,对模态丢失进行惩罚。首先,我们用大量 ODE 步运行教师模型,以获得稠密的去噪轨迹,并从中提取与学生模型 S S S步调度对齐的检查点 { x t 1 r e f , ... , x t S r e f } \{x_{t_1}^{\mathrm{ref}},\ldots,x_{t_S}^{\mathrm{ref}}\} {xt1ref,...,xtSref}。然后,监督学生通过单步 Euler 更新去匹配每一对相邻检查点:
L F K L = E i ∥ v θ ( x t i r e f , t i ) − x t i + 1 r e f − x t i r e f σ t i + 1 − σ t i ∥ 2 . \mathcal{L}_{\mathrm{FKL}}= \mathbb{E}_i\!\left \\left\\\| v_\\theta(x_{t_i}\^{\\mathrm{ref}},\\, t_i)- \\frac{x_{t_{i+1}}\^{\\mathrm{ref}}-x_{t_i}\^{\\mathrm{ref}}}{\\sigma_{t_{i+1}}-\\sigma_{t_i}} \\right\\\|\^2 \\right. LFKL=Ei vθ(xtiref,ti)−σti+1−σtixti+1ref−xtiref 2 .
由于目标 x t r e f x_t^{\mathrm{ref}} xtref是从教师模型的分布中采样得到的,优化式 10 10 10等价于最小化一个前向 KL 方向的目标;该目标鼓励学生去覆盖教师的输出模态,而不是进行寻模态,从而保留运动多样性。
与 DMD 解耦。为了防止 L F K L \mathcal{L}_{\mathrm{FKL}} LFKL与 DMD 目标之间相互干扰,我们采用了两个设计选择:
-
仅在双向注意力模式下使用。双向注意力与因果注意力下的运动动力学具有很强的正相关性(第 4.4 4.4 4.4节),因此对前者进行正则化,能够有效约束后者。因此,我们只在双向注意力模式下计算 L F K L \mathcal{L}_{\mathrm{FKL}} LFKL,保持因果 self-rollout 的 DMD 损失不变,并尽量减小梯度干扰。
-
早期步骤限制。运动动力学由最早几个去噪步骤中建立起来的低频结构所支配。因此,我们只将 L F K L \mathcal{L}_{\mathrm{FKL}} LFKL应用于 S S S个步骤中的前 K K K步,而将后续的高频细化步骤保持为不受约束。
整体训练目标为
L = L D M D + λ L F K L , \mathcal{L}= \mathcal{L}{\mathrm{DMD}} + \lambda \mathcal{L}{\mathrm{FKL}}, L=LDMD+λLFKL,
其中 λ > 0 \lambda>0 λ>0用于平衡这两项。我们在第 4.4 4.4 4.4节中对 K K K的选择以及注意力模式解耦策略进行了消融实验。