引言
在构建现代数据架构时,很多团队发现:直接把 Parquet/ORC 文件扔进 S3 或 HDFS,虽然成本低,但缺乏事务性、Schema 管理和一致性保障。于是,开放湖表格式(Open Table Format)成为湖仓一体的关键组件。
目前,Apache Iceberg、Apache Hudi、Delta Lake 和 Apache Paimon 是社区广泛采用的四个方案。它们不是数据库,而是在对象存储之上增加一层元数据管理,让数据湖具备类似数仓的能力。本文基于各项目官方文档和实际落地经验,对比四者的核心能力,结合典型场景给出选型建议,并指出容易踩的坑。
一、它们都能做什么?
根据各项目官网说明,这四个格式均支持:
- ACID 事务:保证并发写入的数据一致性;
- 时间旅行(Time Travel):通过快照 ID 或时间戳查询历史数据;
- Schema 演化:安全地添加、删除或修改字段(具体限制见各项目文档);
- 分区演化:后续可调整分区字段,无需重写全表。这些能力解决了原始数据湖"写乱了没法回退""加个字段要重跑 ETL"等痛点。
二、真实场景下的差异
场景1:需要实时更新用户标签(如"最近7天活跃度")推荐:Hudi 或 Paimon
- Hudi 的 Merge-On-Read (MOR) 模式允许写入延迟低至秒级,且支持 Flink/Spark 流式消费增量数据(Hudi 官方文档)。
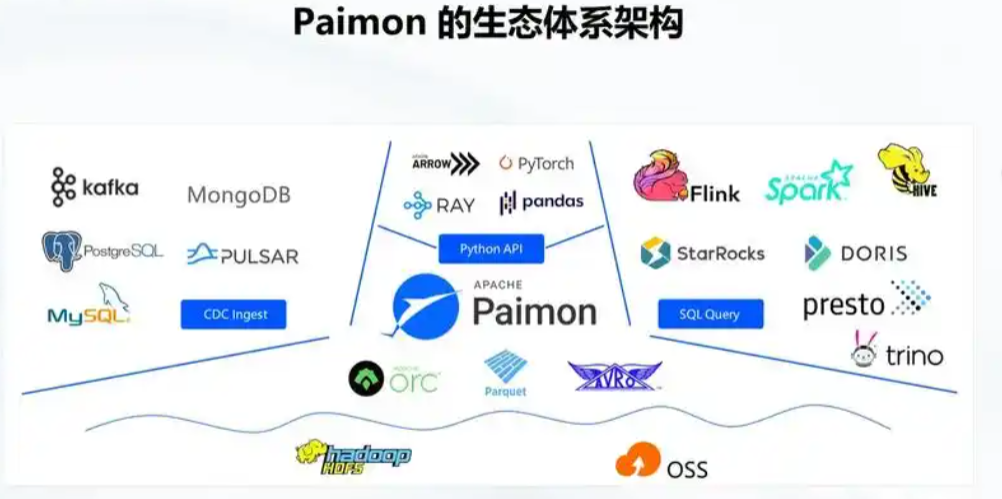
- Paimon 设计之初就面向 Flink 流批一体,主键表(Primary Key Table)天然支持 UPSERT,流作业可直接读取 changelog(Paimon 文档)。
避坑:
Iceberg 的数据写入采用 Copy-On-Write (COW) 模型。虽然它支持通过 Delete 文件 实现高效的行级删除(官方文档),但不提供类似 Hudi 的 Merge-On-Read 低延迟更新能力。在高频更新场景下,仍需频繁重写数据文件,易产生小文件问题。
使用 Paimon 时,若需流式读取 UPDATE/DELETE,必须显式开启 changelog-producer 配置,否则只能看到 INSERT。
场景2:团队同时用 Spark、Flink、Trino 查询同一张表推荐:Iceberg
- Iceberg 的元数据结构与计算引擎解耦,Trino、Spark、Flink、Hive 均有官方或社区维护的连接器,兼容性最成熟(Iceberg 多引擎支持列表)。
避坑 :
Delta Lake 开源版对非 Spark 引擎(如 Trino)仅支持只读查询,不支持任何写入操作(包括 MERGE/UPDATE/DELETE 及 OPTIMIZE 等表维护命令)(Trino 官方文档)。
Hudi 在 Trino 中仅支持快照查询,不支持增量读(截至 Trino 445 版本)。
场景3:已在使用 Databricks 平台
推荐:Delta Lake
- Delta Lake 由 Databricks 主导开发,其 自动小文件合并(Auto Optimize)、Z-Order 聚簇、Serverless 查询等功能仅在 Databricks Runtime 中可用(Delta Lake 功能矩阵)。开源 Delta Lake(OSS)缺少这些运维能力。
避坑 :
不要混淆 "Delta Lake 开源版" 和 "Databricks Delta Engine"。前者是 Apache 2.0 协议的库,后者是商业优化引擎。
若未来可能迁出 Databricks,建议评估 Iceberg,因其元数据格式开放,迁移成本更低。
场景4:小团队,技术栈以 Flink 为主,希望快速搭建实时数仓
推荐:Paimon
- 流式写入(INSERT/UPDATE/DELETE)
- 流式读取(作为 Flink Source)
- 自动 Compaction 合并小文件
- Paimon 原名 Flink Table Store,深度集成 Flink SQL,支持:
- 写入延迟可控制在秒级,适合监控、风控等场景(Paimon 快速开始)。
避坑 :
Paimon 从 0.5 版本起提供原生 Spark 3.3+ 连接器(Paimon Spark 文档),但流式读取、Changelog 等高级功能目前仅在 Flink 中完整支持。
若数据存在乱序,建议使用 sequence.field 配置解决更新覆盖问题(Paimon 序列字段文档)
三、关键能力对比
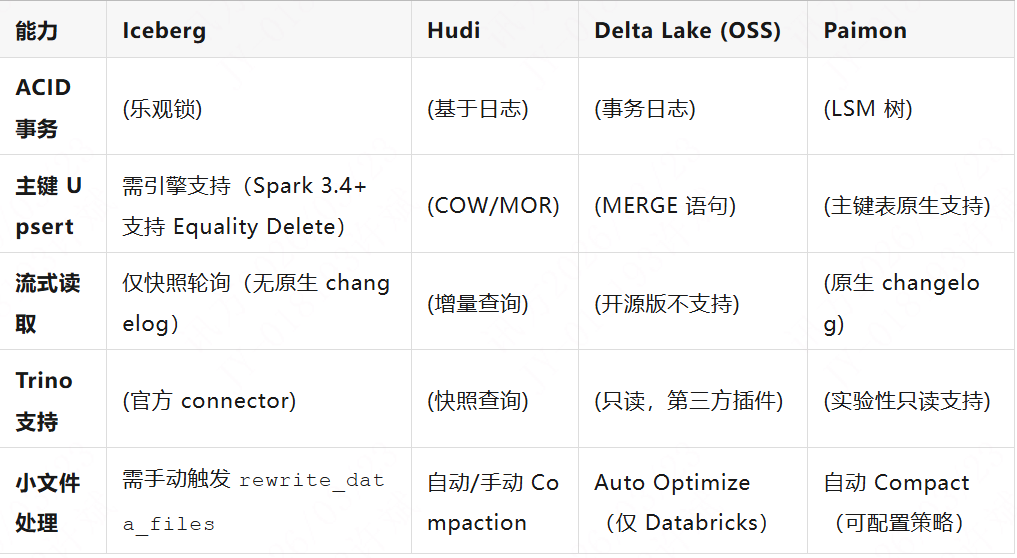
注:Delta Lake OSS = 开源版;Paimon Trino 支持参考 Trino #18942
四、未来趋势:标准化与互操作
- 元数据服务标准化:Iceberg 推出 REST Catalog,Paimon 支持 Filesystem/Hive/JDBC Catalog,未来可能统一接口;
- 计算引擎适配增强:Flink 1.18+ 对 Iceberg/Hudi/Paimon 均提供官方连接器;
- 云厂商托管服务:AWS Athena、阿里云 EMR、Azure Synapse 已支持多格式,降低运维门槛。行业共识是:四者将长期共存,选择应基于当前技术栈和业务需求,而非"哪个更火"。
总结
- 如果你用多种计算引擎,选 Iceberg;
- 如果你需要强实时更新 + CDC,选 Hudi;
- 如果你在 Databricks 上,用 Delta Lake;
- 如果你重度依赖 Flink,Paimon 更高效。
没有"最好",只有"最合适"。建议在测试环境验证关键路径(如写入吞吐、查询延迟、Compaction 开销),再决定生产选型。