停止旧容器 → 删除旧容器 → 启动新容器」的步骤操作,确保操作安全且不丢失关键数据(模型文件、日志等都已挂载到宿主机,不会丢失)。
第一步:停止正在运行的旧容器 先执行停止命令,确保容器正常退出:
```bash docker stop vllm_qwen35_9b ```
执行后会输出容器名称/ID,表示停止成功。
第二步:删除旧容器(可选但推荐) 停止后删除旧容器,避免名称冲突和残留资源:
```bash docker rm vllm_qwen35_9b ```
如果提示容器不存在,说明名称可能有误,可先用`docker ps -a`查看所有容器,确认目标容器名称/ID。
第三步:启动修改后的单卡容器 直接执行我之前给你的**修改后完整命令**(单GPU版本): ```bash docker run -d --name vllm_qwen35_9b --restart always --gpus '"device=0"' --net=host --privileged --ipc=host -v /home/hynx/models/Qwen3.5-9B:/app/model/qwen3.5-9b -v /home/hynx/vllm_cache:/root/.cache/huggingface -v /home/hynx/vllm_log:/app/log vllm/vllm-openai:latest /app/model/qwen3.5-9b --host 0.0.0.0 --port 8089 --dtype auto --max-model-len 262144 --reasoning-parser qwen3 --tensor-parallel-size 1 --gpu-memory-utilization 0.9 --no-enforce-eager --served-model-name qwen3.5-9b ```
第四步:验证是否成功运行在第一块GPU
- 先查看容器是否正常启动:
```bash docker ps | grep vllm_qwen35_9b ```
如果能看到容器信息,说明启动成功。
- 验证GPU使用情况(关键):
```bash nvidia-smi ```
在输出的「Processes」部分,会看到vllm进程只占用**GPU 0**(第一块),而不是之前的多块GPU,说明配置生效。
- 可选:测试API是否可用(确认服务没出问题): ```bash curl http://localhost:8089/v1/chat/completions \ -H "Content-Type: application/json" \ -d '{ "model": "qwen3.5-9b", "messages": {"role": "user", "content": "测试一下"} }' ```
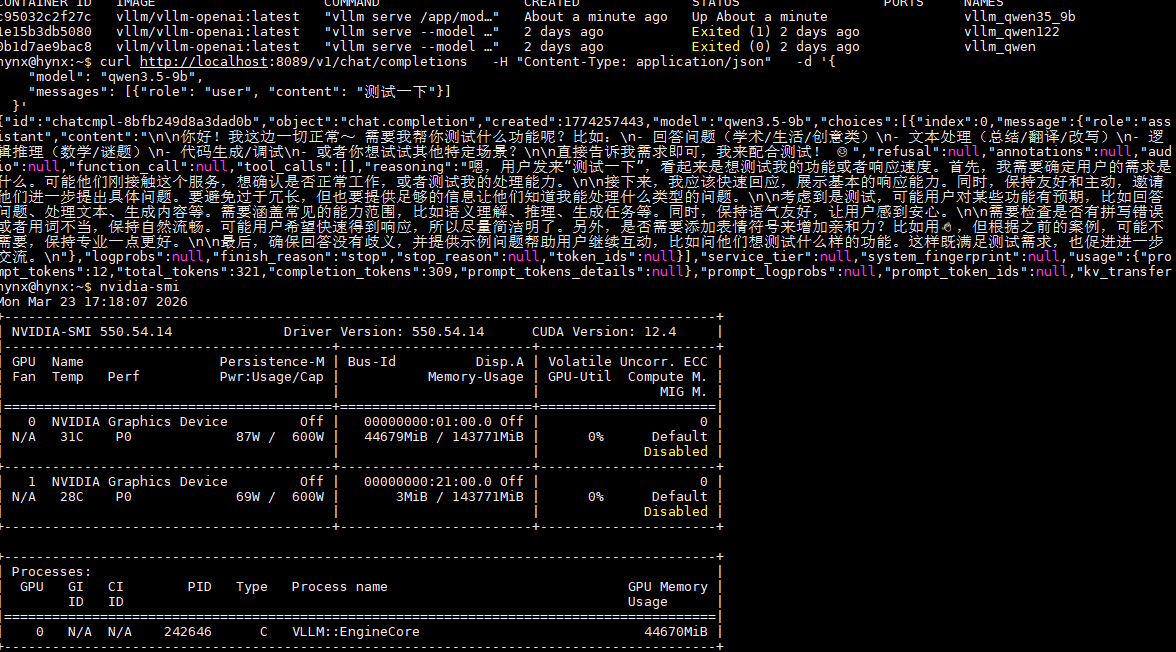
能正常返回回复,说明服务完全可用。
注意事项 - 操作过程中,模型文件、日志、缓存都挂载在宿主机目录(`/home/hynx/`下),不会因为删除/重建容器丢失; - 如果启动新容器时报「端口8089被占用」,先执行
`netstat -tulpn | grep 8089`
查看占用进程,确认是旧容器残留的话,重启Docker(`systemctl restart docker`)即可解决。
总结
-
操作流程:停止旧容器 → 删除旧容器 → 启动单GPU新容器;
-
验证重点:用`nvidia-smi`确认进程仅占用GPU 0,用curl测试API可用性;
-
数据安全:模型/日志/缓存都在宿主机,重建容器不会丢失数据。