深入浅出解析AI中的Tokens
随着大语言模型的普及,Token 这个概念出现在越来越多的场景中:看模型介绍时的 "128k 上下文支持",调用 API 时按输入输出 Token 计费的规则,优化提示词时被反复提醒的 "别浪费 Token"......
这些场景都指向同一个问题:Token 到底是什么?它为何成为大语言模型使用中的核心概念?
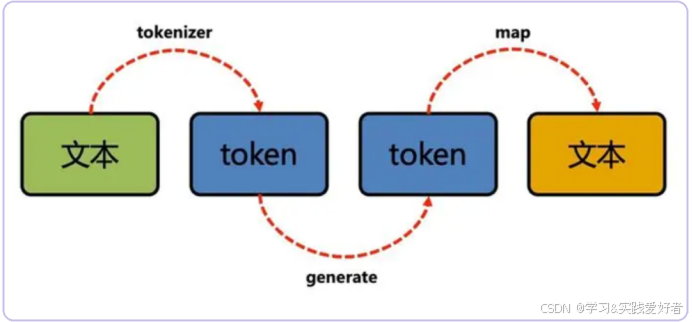
简单来说 ,Token(词元)是大语言模型处理文本的基本单位。我们看到的完整语句,在模型眼中,实则是一串被切分后的 Token 序列。不妨将它理解为 AI 世界里搭建语言的 "积木",而这一块块 "积木",同时承担着文本处理、计费、上下文长度计量三大核心角色,模型的理解逻辑、处理能力、使用成本,都与它密切相关。
一、Token 的本质:并非天然的语言单位
很多人初次接触 Token,会将其等同于 "字" 或 "单词",这种理解有一定道理,但并不精准。
真正的 Token,是文本经过Tokenizer(分词器) 切分后,模型用于处理语言的专属单位。它不是语言本身自带的单位,而是模型为了便于计算,将文字拆解成的 "可处理片段",既不严格等于单个字符,也不一定对应完整单词。
在中文语境中,一个汉字可能是一个 Token,一个完整的词也可能被视作一个 Token,部分词汇还会被拆分为多个 Token;在英文里这种特征更明显,普通单词通常为 1 个 Token,较长或生僻的单词会被拆分成多个 Token,甚至空格、标点、数字,有时也会单独占用 Token。
对模型而言,人类眼中的完整句子,最终都会转化为一串 Token 序列,这是它理解语言的基础。
二、为何大模型必须用 Token?一种高效的折中方案
计算机无法像人类一样直接理解语言,文本在进入模型前,必须经过拆分和编码,转化为模型可计算的数字形式,这个过程就是:文本→Token→数字编号(Token ID)→模型计算。模型真正处理的并非文字本身,而是代表文字片段的数字,而选择 Token 作为中间载体,是兼顾效率与灵活性的最优解。
如果仅以 "单个字符" 为处理单位,英文会被拆解得过于细碎,导致序列过长、语义单位太小,不仅理解效率低,还会大幅增加计算成本;如果只以 "完整单词" 为单位,模型会难以处理生僻词、新词、人名和地名,词表规模会无限扩大,遇到未见过的词汇便会无法应对。
Token 则介于 "字符" 和 "词" 之间,是一种灵活的切分单位。比如英文中的复杂单词,会被拆成几个常见片段,即便模型没见过完整单词,也能通过这些片段进行处理。正是这样的特性,让 Token 在表达能力、灵活性和计算效率之间取得了平衡,成为大模型处理语言的通用选择。
三、Tokenizer:Token 的 "创造者" 与语言的 "翻译官"
Token 由 Tokenizer 切分生成,Tokenizer 常被称作 "切词器" 或 "分词器",但它的核心作用远不止传统分词,而是完成面向模型的文本编码 ,核心任务有两个:一是将文本精准切分为 Token,二是把 Token 转化为模型可处理的数字 ID。
当我们向模型输入一句话时,模型并不会直接 "看见" 文字,而是先由 Tokenizer 完成切分和编码;模型生成回答时,也会先生成 Token ID,再由 Tokenizer 还原为人类能理解的文字。
从技术层面来说,模型处理的核心是 Token ID,而 Token 则是连接人类文本与模型计算的重要桥梁,实现了自然语言到机器语言的转化。
四、Token 的核心价值:决定处理能力、使用成本与运行效率
Token 之所以成为大模型的核心概念,并非单纯的技术细节,而是因为它直接影响着大模型使用中的三个关键问题:能处理多长内容、调用需要花多少钱、运行速度和效果如何。
1. 衡量上下文窗口大小的核心单位
我们常看到的 8k、32k、128k 上下文,其中的 "k" 指的就是 Token 数量,代表模型一次最多能处理的 Token 总量。这个总量并非仅计算当前输入,而是包含系统提示词、历史对话、当前提问、附加材料和模型输出的总和 ------ 模型一次能 "看到" 的内容有固定预算,而这个预算的计量单位就是 Token。
2. API 调用计费的核心依据
几乎所有主流大模型 API 都按 Token 计费,且通常分为输入 Token 和输出 Token 两部分:输入文本越长,消耗的输入 Token 越多;模型回答越详细,消耗的输出 Token 也越多。
一次调用的大致总消耗 = 输入 Token + 输出 Token,部分平台还会根据模型类型、Token 用途(缓存、推理)区分单价,但核心规律始终不变:消耗的 Token 越多,调用成本通常越高。
3. 影响模型的运行速度与回答效果
Token 数量直接关联模型的运行效率,文本越长、Token 越多,模型的处理时间就越长。同时,过长的上下文还会导致 "重点稀释":即便内容未超出窗口上限,模型也无法对所有信息做到同等关注,输入信息过于繁杂,反而会让回答变得模糊、分散,难以抓住核心。
由此可见,Token 并非 "越多越好",把 Token 用在有效信息上,才是提升模型使用效率的关键。
五、Token 切分示例:无固定规则,因内容而异
不同模型的 Tokenizer 切分规则不同,同一句话在不同模型中的 Token 切分结果也会存在差异。以下为通用示意示例,帮助理解 Token 的切分逻辑:
示例 1:中文
原句:我喜欢人工智能。切分方式 1:我、喜欢、人工、智能、。切分方式 2:我、喜、欢、人工智能、。结论 :中文 Token 常接近 "字" 或 "词",无固定切分规则。
示例 2:英文
原句:I love artificial intelligence.切分方式 1:I、love、artificial、intelligence、.切分方式 2:I、love、artificial、intel、ligence、.结论 :英文中复杂、生僻词被拆分为多个 Token 是常见现象。
示例 3:数字与符号
原句:2025 年增长了 12.5%切分方式:2025、年、增长、了、12、.、5、%结论 :数字、标点、特殊符号,通常会单独占用 Token。
六、Token 与字数的粗略换算:无固定公式,仅作经验参考
Token 和字数、词数之间没有严格的换算公式,但实际使用中,可通过经验值做粗略估计,不同文本、不同模型会存在小幅差异。
英文换算经验
1 个 Token≈0.75 个英文单词,或 100 个英文单词≈130 个 Token。
中文换算经验
1 个汉字大致接近 1 个 Token,但若涉及词汇合并、数字和符号单独切分,实际 Token 数量会略有变化。
日常使用中,经验值可满足基本估算需求;若涉及成本控制、上下文上限把控,需以模型实际计算结果为准。
七、不同模型中 Token 数不同的原因:Tokenizer 规则差异
Token 并非文本本身的固定属性,而是由 "文本 + 特定 Tokenizer 切分规则" 共同决定的结果。因此,同一句话在不同模型中,Token 数量可能相差甚远:在 A 模型中是 20 个 Token,在 B 模型中可能是 24 个,在 C 模型中又可能是 18 个,这都是正常现象。
若需要精确估算 API 成本或控制文本长度,切勿凭感觉判断,最好使用对应模型的 Tokenizer 工具或官方计数工具进行实际测算。
八、Token 与上下文窗口的关系:模型的 "短时工作记忆" 容量
上下文窗口(Context Window),本质就是模型一次最多能处理的 Token 总量,这里的 "总量" 是核心关键,很多人会误以为 "128k 上下文" 就是能输入 128k Token 的内容,实则不然。
模型的 Token 总预算,需要分配给系统提示词、历史聊天记录、当前输入,以及模型即将生成的输出。例如,某模型支持 128k Token,若系统提示占 2k、历史对话占 20k、当前输入占 5k,那么留给模型生成回答的 Token 空间就会大幅缩减。
这也是长对话中模型有时会 "忘记" 前文的原因:并非模型真的具备 "遗忘" 的特性,而是那些内容的 Token 已经超出了当前上下文窗口的范围,模型无法再获取。从这个角度来说,Token 就是模型 "短时工作记忆" 的容量单位。
九、Token 的双重属性:技术概念与商业概念的结合
在传统软件使用中,用户几乎无需关心底层处理单位,但在大模型时代,Token 变得尤为特殊,它既是技术层面的核心概念,也是商业层面的重要计量单位。
从技术上,Token 是模型处理语言的基本颗粒度,决定了模型的语言理解和生成逻辑;从商业和产品层面,Token 直接关系到一次请求能承载的内容量、一次 API 调用的成本,以及大模型系统的高效扩展能力。
理解 Token,本质上是在同时理解两大核心问题:大模型的工作原理,以及大模型的计费逻辑。
十、聪明管理 Token:让大模型使用更高效、更省钱
Token 是大模型使用中的 "宝贵资源",无论你是普通用户、提示词工程师,还是 API 开发者,都可以通过以下方法优化 Token 使用,实现效率与成本的平衡:
1. 精简提示词,聚焦关键信息
写提示词时避免冗长的背景铺垫,只保留核心信息:明确任务要求、输出格式、限制条件,提供必要而非冗余的上下文,避免 Token 浪费在无效内容上。
2. 长文分块处理,避免一次性输入
分析大篇幅文档时,切勿将全部内容一次性输入,可采用 "分段总结→汇总比较→生成总报告" 的方式,既节省 Token,又能让模型的处理结果更稳定、精准。
3. 明确输出要求,控制输出长度
输出 Token 往往是成本消耗的 "大头",可直接向模型明确输出约束,例如 "用 5 点概括""控制在 200 字内""只输出表格,无需解释""分别提供简版和详版",大幅减少不必要的输出。
4. 长对话阶段性总结,压缩历史内容
多轮对话中,历史消息会不断累积,消耗的 Token 也会越来越多。可定期让模型对前文做摘要,将冗长的对话压缩为核心要点,再继续交流,既节省 Token,又能让对话更聚焦。
5. 专业场景下,用工具替代经验估算
在 API 成本预算、批量调用控制、提示词优化、长上下文系统设计等精准场景中,切勿凭经验估算 Token 数量,最可靠的方式是使用对应模型的 Tokenizer 或官方计数工具进行实际测算。
十一、关于 Token 的五大常见误区,你中招了吗?
误区 1:Token 就是字数
❌ 错误。中文中二者可能大致接近,但并非严格相等;英文中 Token 与字数的差异会更明显,且数字、符号会单独占用 Token。
误区 2:Token 就是单词数
❌ 错误。一个英文单词可能是 1 个 Token,也可能因长度、生僻度被拆分为多个 Token,无固定对应关系。
误区 3:上下文越长,模型理解得越好
❌ 错误。长上下文仅代表模型 "能装下更多内容",不代表能对所有细节同等处理,过长的内容反而会导致重点稀释,影响理解效果。
误区 4:提示词越长越专业
❌ 错误。冗长的提示词会增加 Token 消耗、减慢模型处理速度,还会分散模型的注意力,简洁、聚焦的提示词往往效果更好。
误区 5:删掉所有标点和空格能大幅节省 Token
❌ 错误。不同 Tokenizer 的处理规则不同,盲目删除标点、空格,能省下的 Token 数量有限,反而可能破坏文本的可读性,影响模型的理解和判断。
十二、一句话总结 Token
精准定义 :Token 是大语言模型读写和处理文本时使用的基本单位。通俗理解 :Token 是模型处理语言的 "文字积木",它决定了模型能读多少、写多少、记多少,也决定了大部分 API 的使用成本。
在大模型时代,Token 更像是一把统一的 "尺子",用来衡量文本长度、使用成本和上下文窗口大小,是理解大模型的关键抓手。
结语
当我们与大模型对话时,表面上是输入文字、获取回答的简单交互,但在模型内部,真正流动的是一串串有序的 Token。
理解 Token,不仅能让我们看懂大模型的核心工作方式 ------ 它如何 "解读" 文本、为何受限于上下文、为何按此规则计费,更能让我们掌握高效使用大模型的技巧,让每一个 Token 都发挥最大价值。
说到底,Token 不是为人类设计的语言单位,而是为模型计算而生的专属单位,而读懂了这个单位,就等于触碰到了大模型运作逻辑的核心。