目录
[1.1 问题背景](#1.1 问题背景)
[1.2 本文目的](#1.2 本文目的)
[1.3 一句话先建立直觉](#1.3 一句话先建立直觉)
[二、DP 的基本概念](#二、DP 的基本概念)
[2.1 DP 的定义](#2.1 DP 的定义)
[2.2 DP 的两个核心特征](#2.2 DP 的两个核心特征)
[2.2.1 最优子结构](#2.2.1 最优子结构)
[2.2.2 重叠子问题](#2.2.2 重叠子问题)
[2.3 DP 的本质](#2.3 DP 的本质)
[三、DP 的基本求解流程](#三、DP 的基本求解流程)
[3.1 第一步:定义状态](#3.1 第一步:定义状态)
[3.2 第二步:建立状态转移方程](#3.2 第二步:建立状态转移方程)
[3.3 第三步:初始化边界条件](#3.3 第三步:初始化边界条件)
[3.4 第四步:确定递推顺序](#3.4 第四步:确定递推顺序)
[四、DP 的简单例子](#四、DP 的简单例子)
[4.1 爬楼梯问题](#4.1 爬楼梯问题)
[4.2 状态定义](#4.2 状态定义)
[4.3 状态转移](#4.3 状态转移)
[4.4 边界条件](#4.4 边界条件)
[4.5 含义说明](#4.5 含义说明)
[五、DP 更适合解决什么问题](#五、DP 更适合解决什么问题)
[5.1 离散决策问题](#5.1 离散决策问题)
[5.2 典型应用方向](#5.2 典型应用方向)
[5.3 在路径规划中的作用](#5.3 在路径规划中的作用)
[六、QP 的基本概念](#六、QP 的基本概念)
[6.1 QP 的定义](#6.1 QP 的定义)
[6.2 QP 的标准形式](#6.2 QP 的标准形式)
[6.3 各个符号的含义](#6.3 各个符号的含义)
[6.4 QP 的本质](#6.4 QP 的本质)
[七、为什么很多工程问题会变成 QP](#七、为什么很多工程问题会变成 QP)
[7.1 因为很多目标天然就是"平方项"](#7.1 因为很多目标天然就是“平方项”)
[7.2 一个典型代价函数](#7.2 一个典型代价函数)
[7.3 含义说明](#7.3 含义说明)
[八、QP 更适合解决什么问题](#八、QP 更适合解决什么问题)
[8.1 连续变量优化问题](#8.1 连续变量优化问题)
[8.2 典型工程场景](#8.2 典型工程场景)
[8.3 在路径规划中的作用](#8.3 在路径规划中的作用)
[九、DP 和 QP 的本质区别](#九、DP 和 QP 的本质区别)
[9.1 问题对象不同](#9.1 问题对象不同)
[9.1.1 DP 面向离散状态](#9.1.1 DP 面向离散状态)
[9.1.2 QP 面向连续变量](#9.1.2 QP 面向连续变量)
[9.2 求解思路不同](#9.2 求解思路不同)
[9.2.1 DP 依靠递推](#9.2.1 DP 依靠递推)
[9.2.2 QP 依靠优化建模](#9.2.2 QP 依靠优化建模)
[9.3 表达方式不同](#9.3 表达方式不同)
[9.3.1 DP 的典型形式](#9.3.1 DP 的典型形式)
[9.3.2 QP 的典型形式](#9.3.2 QP 的典型形式)
[9.4 直观理解不同](#9.4 直观理解不同)
[十、为什么工程中常常把 DP 和 QP 结合使用](#十、为什么工程中常常把 DP 和 QP 结合使用)
[10.1 只用 DP 的问题](#10.1 只用 DP 的问题)
[10.2 只用 QP 的问题](#10.2 只用 QP 的问题)
[10.3 组合思路](#10.3 组合思路)
[10.4 组合方式的本质](#10.4 组合方式的本质)
[10.5 一句话总结](#10.5 一句话总结)
[11.1 问题描述](#11.1 问题描述)
[11.2 用 DP 做离散粗搜索](#11.2 用 DP 做离散粗搜索)
[11.3 DP 输出结果](#11.3 DP 输出结果)
[11.4 用 QP 做平滑优化](#11.4 用 QP 做平滑优化)
[11.5 各项物理意义](#11.5 各项物理意义)
[11.6 加入约束](#11.6 加入约束)
[11.7 最终效果](#11.7 最终效果)
一、引言
1.1 问题背景
在路径规划、自动驾驶、机器人控制、最优控制等方向中,经常会接触到几个高频概念:DP、QP。这些缩写看起来都和"最优"有关,但它们并不处于同一个层级,也不是同一种方法。
很多初学者在刚接触这些概念时,容易产生两个疑问:
- DP 和 QP 到底有什么区别?
如果这些关系没有理顺,后面在学习轨迹规划、控制器设计或者阅读论文时,就很容易概念混淆。
1.2 本文目的
本文希望解决以下几个问题:
- DP 到底是什么;
- QP 到底是什么;
- 二者本质区别在哪里;
- 为什么工程中常常把 DP 和 QP 搭配使用;
1.3 一句话先建立直觉
如果先不管严格定义,可以先用一句比较形象的话建立直觉:
DP 更擅长在离散空间里"找路",QP 更擅长在连续空间里"修路"。
而在控制领域中:
- LQR 是一种经典的无约束最优控制方法;
- MPC 是一种带预测、带优化、可处理约束的控制框架;
- QP 往往是很多 MPC 问题在线求解时的数学落脚点。
二、DP 的基本概念
2.1 DP 的定义
DP,全称 Dynamic Programming ,中文叫动态规划。
它是一种求解最优化问题的经典思想,其核心在于:
将一个复杂问题分解为若干相互关联的子问题,通过保存子问题结果,避免重复计算,并利用递推关系逐步求得全局最优解。
2.2 DP 的两个核心特征
动态规划之所以能够成立,通常依赖两个前提。
2.2.1 最优子结构
所谓最优子结构,是指原问题的最优解可以由子问题的最优解构成。
例如最短路径问题中,从起点到终点的最优路径,往往包含若干中间节点,而从起点到这些中间节点的部分路径本身也应该是最优的。
2.2.2 重叠子问题
所谓重叠子问题,是指在求解过程中会反复遇到相同的子问题。
如果每次都重复计算这些子问题,效率会很低。DP 的做法就是把这些结果保存下来,后续直接使用。
2.3 DP 的本质
从本质上看,DP 是一种基于状态递推的离散最优化方法。
它最重要的不是"公式有多复杂",而是两个问题:
- 当前状态怎么定义;
- 当前状态如何由历史状态转移而来。
三、DP 的基本求解流程
3.1 第一步:定义状态
状态定义是 DP 中最关键的一步。
常见形式包括:
dp[i]:表示到第 i 个阶段时的最优值;dp[i][j]:表示考虑前 i 个元素、处于第 j 个条件下的最优值;dp[l][r]:表示区间 l,r 上的最优结果。
状态定义正确,后面的转移关系才容易写出来。
3.2 第二步:建立状态转移方程
状态转移方程描述的是:
当前状态由哪些之前的状态推导而来。
例如一个通用形式可以写成:

3.3 第三步:初始化边界条件
任何 DP 都需要边界条件,否则递推无法开始。
例如:
dp[0]=0dp[1]=1- 某些不可达状态初始化为 +∞ 或极大值
初始化是否正确,直接影响最终结果。
3.4 第四步:确定递推顺序
因为当前状态依赖历史状态,所以计算顺序必须正确。
常见顺序包括:
- 从小到大;
- 从左到右;
- 按区间长度递增;
- 按拓扑顺序递推。
四、DP 的简单例子
4.1 爬楼梯问题
假设每次可以走 1 阶或 2 阶,问到第 n 阶有多少种方法。
4.2 状态定义
定义:
f(n)=到第 n 阶的方法数
4.3 状态转移
到第 n 阶,最后一步只可能有两种情况:
- 从第 n−1阶走 1 步;
- 从第 n−2 阶走 2 步。
因此有:
f(n) = f(n−1) + f(n−2)
4.4 边界条件
f(1)=1 , f(2)=2
4.5 含义说明
这个例子说明,DP 并不是去枚举所有路径,而是利用前面状态的结果递推得到当前状态。
五、DP 更适合解决什么问题
5.1 离散决策问题
DP 更适合处理变量和决策都比较离散的问题,例如:
- 选还是不选;
- 到第几个阶段;
- 当前剩余多少容量;
- 当前在第几个网格点;
- 当前处理到字符串的第几个字符。
5.2 典型应用方向
常见 DP 问题包括:
- 背包问题;
- 最长公共子序列;
- 编辑距离;
- 区间合并问题;
- 网格最短路径;
- 树形动态规划;
- 状压动态规划。
5.3 在路径规划中的作用
在路径规划中,DP 常用于:
- 离散地图搜索;
- 全局粗路径生成;
- 候选拓扑选择;
- 障碍物绕行策略初步确定。
六、QP 的基本概念
6.1 QP 的定义
QP,全称 Quadratic Programming ,中文叫二次规划。
它是一类优化问题,特点是:
- 目标函数是二次函数;
- 约束通常是线性的。
6.2 QP 的标准形式
一个标准的二次规划问题通常写为:
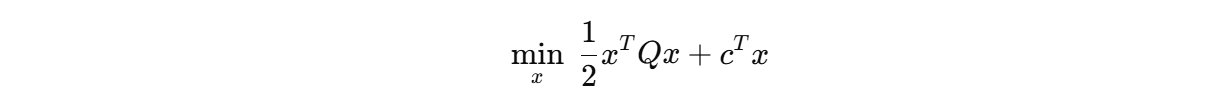
满足约束:
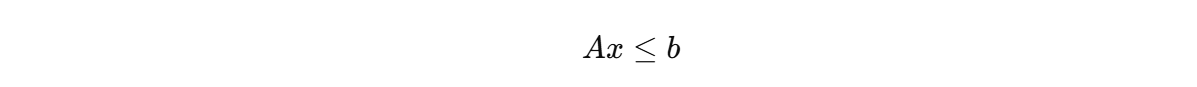
以及必要时的等式约束:
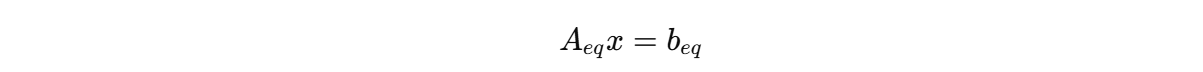
6.3 各个符号的含义
其中:
- x:待优化变量;
- Q:二次项矩阵;
- c:一次项系数;
- Ax≤b:不等式约束;
- Aeqx=beq:等式约束。
6.4 QP 的本质
QP 的本质可以概括为:
在满足约束条件的前提下,寻找一组连续变量,使总代价最小。
七、为什么很多工程问题会变成 QP
7.1 因为很多目标天然就是"平方项"
在轨迹优化和控制中,我们经常希望:
- 偏差尽量小;
- 轨迹尽量平滑;
- 控制输入变化尽量柔和;
- 加速度或 jerk 尽量小。
这些目标往往都可以写成平方项。
7.2 一个典型代价函数
例如可以写成:
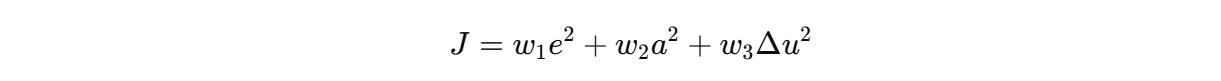
其中:
- e:偏差;
- a:加速度;
- Δu:控制输入变化量;
- w1,w2,w3:权重系数。
7.3 含义说明
这个目标函数的含义很直观:
- 第一项让系统尽量贴近目标;
- 第二项抑制过大的加速度;
- 第三项让控制量变化更平滑。
由于总代价是平方项的加权和 ,因此非常容易整理为一个二次规划问题。
八、QP 更适合解决什么问题
8.1 连续变量优化问题
QP 更适合处理如下问题:
- 轨迹点位置优化;
- 速度、加速度分配;
- 控制输入求解;
- 曲线平滑;
- 控制分配;
- 带约束最小二乘问题。
8.2 典型工程场景
QP 常出现在:
- 自动驾驶轨迹优化;
- 机器人轨迹平滑;
- 机械臂运动优化;
- 足式机器人力分配;
- 模型预测控制;
- 约束最小二乘估计。
8.3 在路径规划中的作用
在路径规划中,QP 常用于:
- 平滑参考路径;
- 限制曲率和加速度;
- 控制轨迹偏差;
- 满足边界和障碍约束;
- 生成更适合执行的连续轨迹。
九、DP 和 QP 的本质区别
9.1 问题对象不同
9.1.1 DP 面向离散状态
DP 中关注的是:
- 第几个阶段;
- 当前处于哪个离散节点;
- 还剩多少容量;
- 当前匹配到哪里。
9.1.2 QP 面向连续变量
QP 中关注的是:
- 位置;
- 速度;
- 加速度;
- 控制输入;
- 轨迹点坐标。
9.2 求解思路不同
9.2.1 DP 依靠递推
DP 的思路是:
- 定义状态;
- 写出转移方程;
- 逐步递推;
- 得到最优解。
9.2.2 QP 依靠优化建模
QP 的思路是:
- 定义优化变量;
- 构造目标函数;
- 加入约束条件;
- 调用求解器求最优解。
9.3 表达方式不同
9.3.1 DP 的典型形式
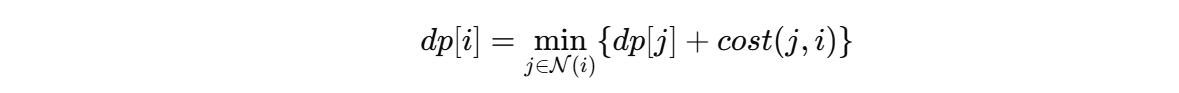
9.3.2 QP 的典型形式
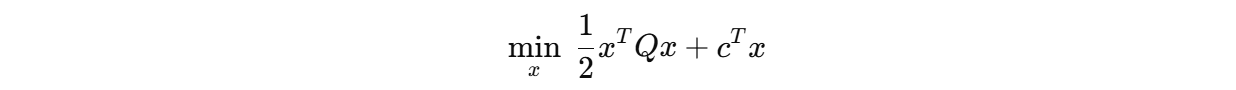
约束为:
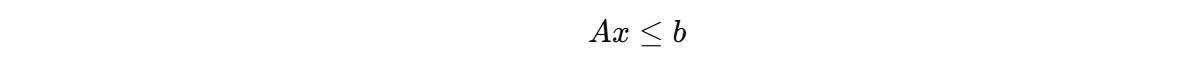
9.4 直观理解不同
可以这样理解:
- DP 是在离散候选解中找最优;
- QP 是在连续可行域中调优最优。
十、为什么工程中常常把 DP 和 QP 结合使用
10.1 只用 DP 的问题
如果只用 DP 来做路径规划,虽然可以得到一条可行路径,但往往存在以下问题:
- 路径是离散的;
- 折线感较强;
- 曲率不连续;
- 轨迹不够平滑;
- 不适合直接给控制器执行。
10.2 只用 QP 的问题
如果一开始就只用 QP 来在复杂环境中找路,也会遇到问题:
- 需要较强的全局引导;
- 障碍物绕行拓扑难以直接表达;
- 建模复杂度高;
- 计算压力较大。
10.3 组合思路
因此,工程上常用如下组合:
- 先用 DP 做粗搜索;
- 再用 QP 做精优化。
10.4 组合方式的本质
这种组合本质上就是:
- DP 负责确定"往哪儿走";
- QP 负责确定"怎样走得更平滑"。
10.5 一句话总结
所以最经典的一句话就是:
DP 负责找路,QP 负责修路。
十一、一个简化的路径规划例子
11.1 问题描述
假设机器人需要从起点到终点,中间存在多个障碍物。
11.2 用 DP 做离散粗搜索
将环境离散成网格,设从起点到网格点 i 的最小代价为 dpi,则可以写成:
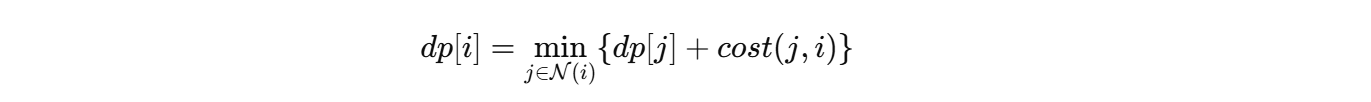
其中:
- N(i)为状态 i 的可达前驱节点;
- cost(j,i)为从节点 j 到节点 i 的代价。
11.3 DP 输出结果
DP 输出的结果通常是一条离散折线路径。
它解决的是"能不能走、往哪里绕"的问题。
11.4 用 QP 做平滑优化

11.5 各项物理意义
这个目标函数中:
- 第一项限制轨迹不要偏离参考路径太远;
- 第二项限制相邻轨迹点变化过大;
- 第三项限制二阶差分过大,从而提升平滑性。
11.6 加入约束
再加入安全约束,例如:
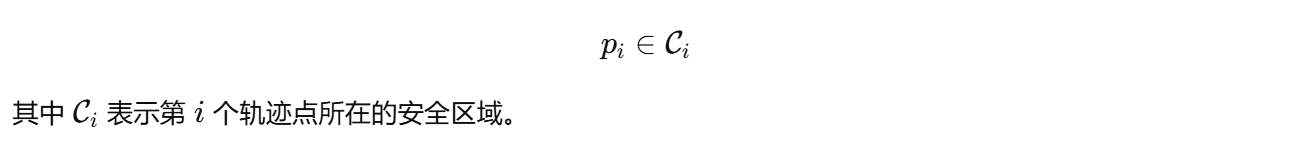
11.7 最终效果
这样,QP 就能够在 DP 给出的可行路径基础上,生成一条更加平滑、更加可执行的连续轨迹。