导读
本文根据 EMR Serverless Spark 团队帅镇涛的技术分享整理而成。帅镇涛负责Celeborn在EMR Serverless Spark中的研发工作,在本次分享中,他详细介绍了Celeborn这一大数据中间数据服务如何解决传统Spark Shuffle面临的存算分离、网络连接数、IO性能和容错能力等核心问题。
一、为什么需要 Celeborn?------ Spark 原生 Shuffle 的四大瓶颈
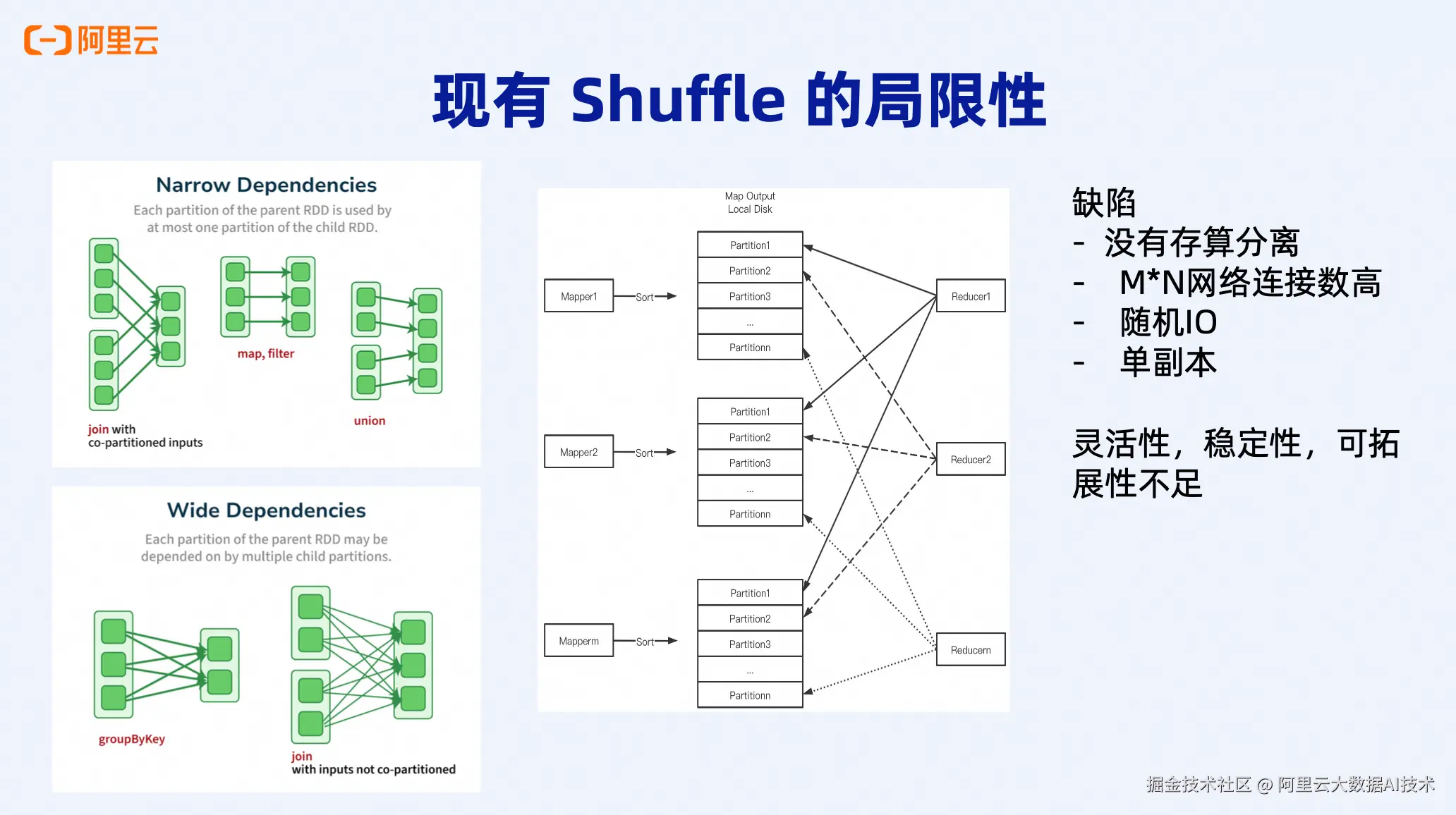
在Spark中,Shuffle主要用于解决宽依赖问题。当某些RDD操作(如group by、reduce by、repartition等)需要依赖上游每个partition的数据时,就必须通过Shuffle来重新分布数据。传统的Spark Sort Shuffle流程中,每个Map Task首先对数据进行排序操作,将有序数据写入本地磁盘,然后每个Reducer从各个Map输出的文件中拉取对应分区的数据。
这种架构存在几个显著的缺陷:
1. 缺乏存算分离能力
在传统Spark架构中,如果某个作业需要写入大量Shuffle数据,就必须为集群配置相应规模的存储资源。但如果只有少数作业有大数据量需求,其他作业实际上并不需要如此多的存储空间,这就造成了资源的严重浪费。在EMR Serverless Spark场景中,这个问题尤为突出------无法根据实际需求灵活调配存储和计算资源。
2. M×N的高网络连接数
每个Reducer都需要与所有Mapper建立连接来获取对应partition的数据。假设有M个Mapper和N个Reducer,总连接数将达到M×N,网络连接数呈指数级增长。在大规模作业中,这会导致网络连接成为严重的瓶颈。
3. 大量随机IO操作
由于每个Reducer需要从多个Map输出文件中读取数据,每次读取都是一次独立的IO操作,导致大量的随机IO,严重影响读取性能。
4. 单副本带来的稳定性风险
原生Spark ESS采用单副本机制,一旦某个节点出现故障,整个作业就会失败,需要重新执行,稳定性和可靠性都难以保证。
综合来看,传统Shuffle架构在灵活性、稳定性和可扩展性方面都存在明显不足。
二、Celeborn 是什么?------ 开源社区验证的大数据 Shuffle 新范式
Celeborn正是为了解决上述问题而诞生的大数据中间数据服务。从诞生至今,Celeborn 已经建立了活跃的开源社区,拥有众多企业用户。并且经历了多个版本迭代,当前社区版本已迭代至 0.6 版本。
Celeborn支持MapReduce、Flink、Spark(包括Gluten、Blaze等加速引擎)等多种大数据计算引擎,真正实现了存算分离的架构理念。在生产环境中,Celeborn已经得到充分验证:单个集群可支持超过2500个节点,每日处理的Shuffle数据量超过10PB,展现出卓越的性能和稳定性。
Celeborn的架构设计
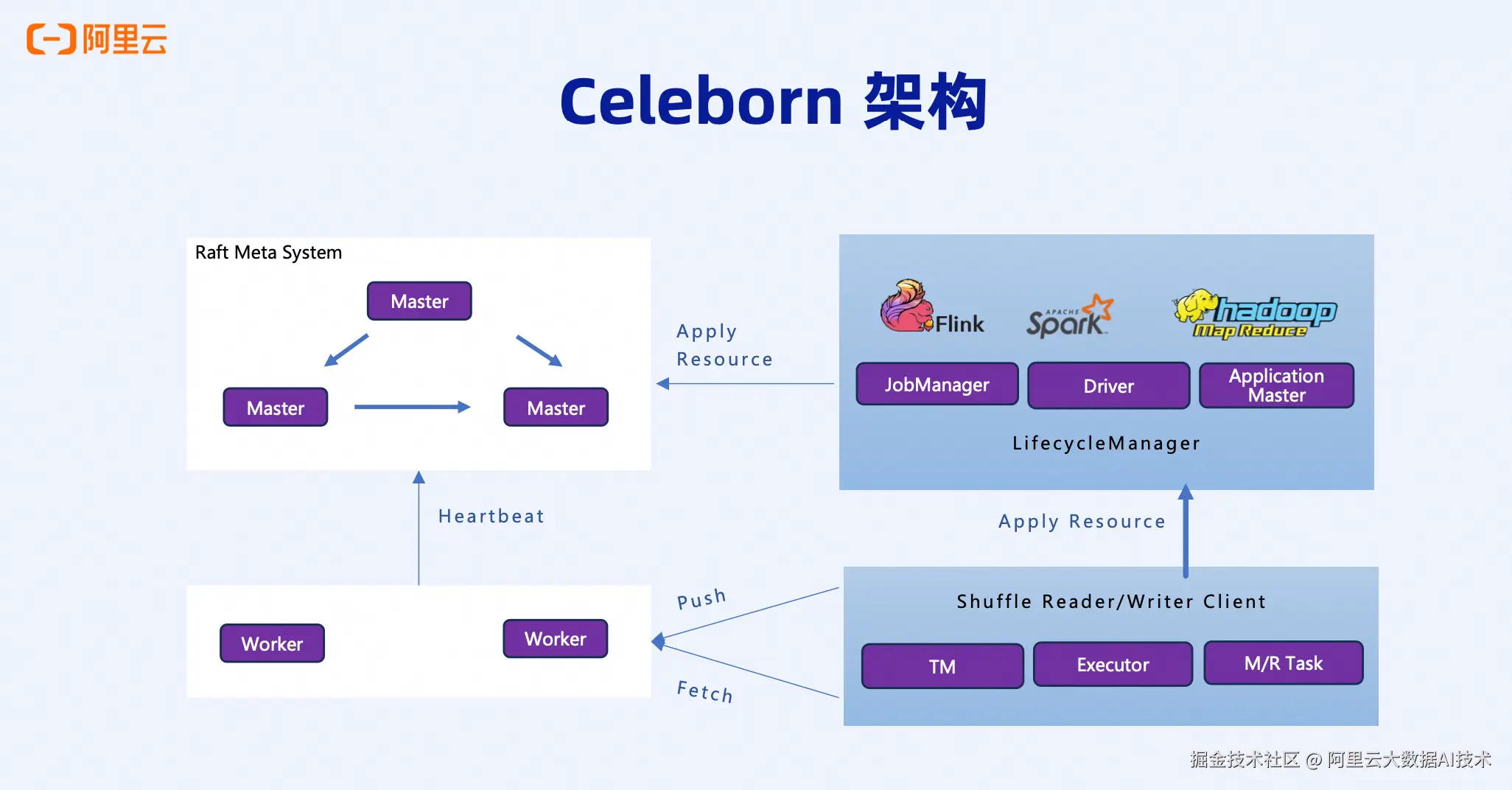
Celeborn采用Master-Worker的经典分布式架构。Master层基于Raft协议实现高可用,支持单副本和多副本部署模式,确保元数据管理的可靠性。Worker集群负责实际的数据存储,每个Worker定期向Master发送心跳,汇报健康状态和资源使用情况。
在计算集群侧,Celeborn通过LifecycleManager组件与Spark Driver、Flink JobManager或YARN ApplicationMaster集成。LifecycleManager负责向Celeborn Master申请资源,建立起计算引擎与Celeborn集群之间的桥梁。一旦资源申请完成,计算节点的Executor或Task就可以直接与Celeborn Worker进行数据读写交互。
整个架构的数据流向清晰明确:Driver/JobManager通过LifecycleManager向Master申请资源→Master分配Worker资源→Executor/Task向Worker推送数据→Reducer从Worker拉取数据。这种设计实现了计算与存储的彻底解耦。
Celeborn的核心技术特性
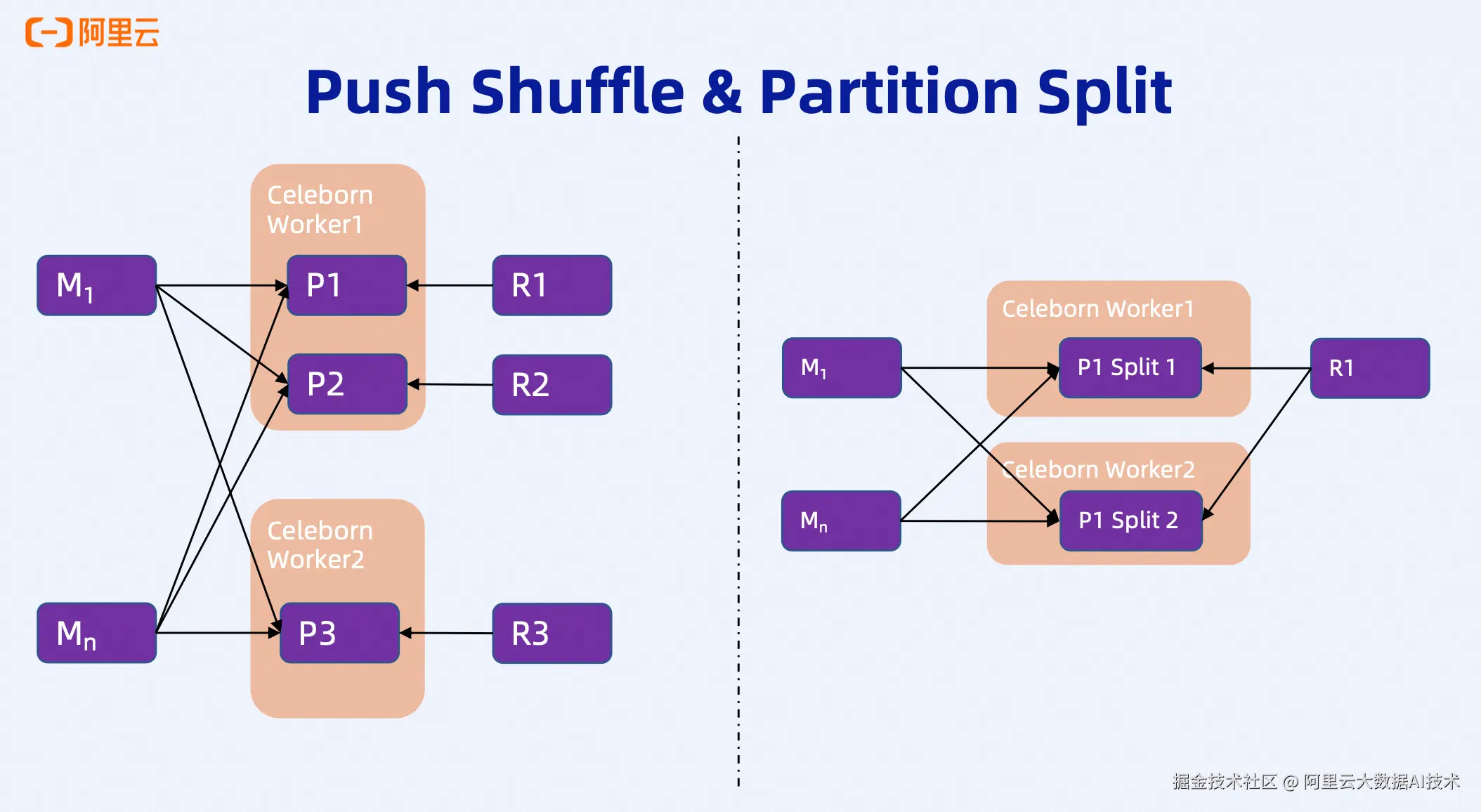
Celeborn的两大核心技术特性是Push Shuffle和Partition Split,几乎所有的性能优化都基于这两个基础机制。
Push Shuffle 机制:
与传统Spark的Pull模式不同,Celeborn采用Push Shuffle模式。每个Map Task会根据不同的partition将数据主动推送到预先申请的Celeborn Worker资源中,数据按partition分别写入不同的文件。这样,Reducer在读取数据时,只需要从对应的partition文件中顺序读取,无需与所有Mapper建立连接。
这带来了两个显著优势:
-
网络连接数从M×N降低到N级别,大幅减少网络开销
-
将随机IO转变为顺序IO,显著提升读取性能
Partition Split 机制:
当单个partition文件的大小超过配置的阈值时,LifecycleManager会自动向Celeborn集群申请新的资源,将同一个partition的后续数据写入新的文件。虽然物理上是不同的文件,但逻辑上它们属于同一个partition。
这个看似简单的机制,为Celeborn的动态扩容、负载均衡和故障自愈提供了坚实的技术基础。当集群新增节点时,正在运行的作业可以通过Partition Split将新数据写入新节点,实现动态资源利用;当某个Worker压力过大时,可以通过Split将数据分流到其他健康节点,避免单点过载。
三、 Serverless Spark 实践:Celeborn 如何让 Shuffle "舒心、放心、安心"?
在EMR Serverless Spark的生产环境中,Celeborn展现出了多方面的实用优势。从完善的监控体系、无感知的升级扩容,到智能的故障自愈和对Spark AQE的原生支持,Celeborn为企业级大数据处理提供了坚实保障。
舒心:完整的端到端监控能力
Celeborn自带完整的指标体系,并原生集成Prometheus,提供端到端的监控能力。使用者无需进行复杂的配置,只需按照官方文档一步步操作,就能建立起完善的监控系统。
在实际运维中,Celeborn提供了丰富的监控维度,主要包括:
资源消耗监控(Resource Consumption): 通过监控可以清晰看到某个用户在特定时间段内的Shuffle数据写入量。例如用户在几个小时内写入了多少数据,这个数据量是否异常,异常大数据量会给集群造成较大的压力,一些集群的压力指标可以帮助运维人员了解集群的实际负载情况。同时,监控也会显示Celeborn集群的节点状态------总节点数与正在使用的节点数的差异,反映出集群是否处于扩容、缩容或升级状态。
关键性能指标:
-
Direct Memory(直接内存使用率): 反映Worker的内存压力,是判断是否需要反压的重要指标
-
CPU使用率: 数值显示当前正在使用的Worker CPU核数,可以直观判断计算压力
-
带宽使用率: 监控网络IO是否成为瓶颈
-
可用磁盘空间: 显示整个集群当前可用的磁盘容量,预警存储压力
放心:智能流控 + 动态扩缩 + 故障自愈
反压与流控机制
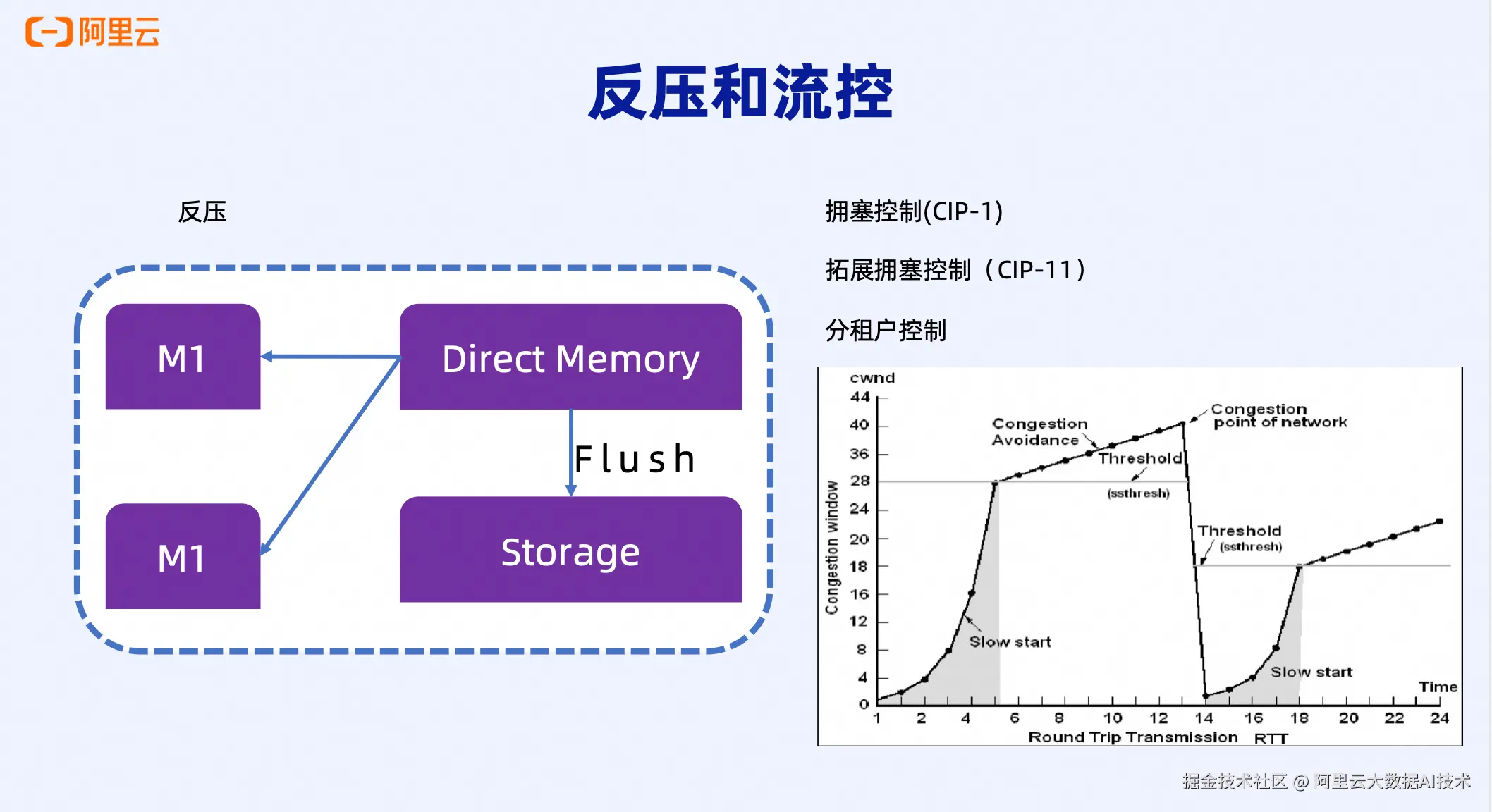
在某个高并发作业场景中,30分钟内写入了约90TB数据。监控显示,这段时间内带宽利用率接近饱和,CPU使用率也达到了较高水平(在16核机器上,部分Worker的CPU已经用满)。由于CPU用满导致数据来不及刷盘,内存占用也随之升高。根据这些指标,系统自动触发了扩容机制,确保集群能够承载突发的高压力负载。面对高压力场景,Celeborn设计了两层保护机制:反压(Backpressure)和流控(Flow Control)。
反压机制:
当某个Worker的内存使用率达到高水位阈值时,会暂停客户端向该Worker继续写入数据,转而全力将内存中的数据刷写到磁盘。等待该Worker的状态恢复健康后,再恢复正常的数据写入。这种机制有效防止了内存溢出导致的Worker崩溃。
流控机制:
Celeborn的流控机制类似于TCP的拥塞控制。在短时间内面对超大流量时,Worker可能无法立即承载,流控机制会暂缓作业的数据写入速率,避免整个集群因瞬时流量过大而崩溃。
通过CIP-1(拥塞控制)和CIP-11(扩展拥塞控制)提案,Celeborn还实现了多租户级别的流控能力,可以针对不同租户设置不同的流控策略,保证资源的公平分配。
无感知的升级与缩扩容
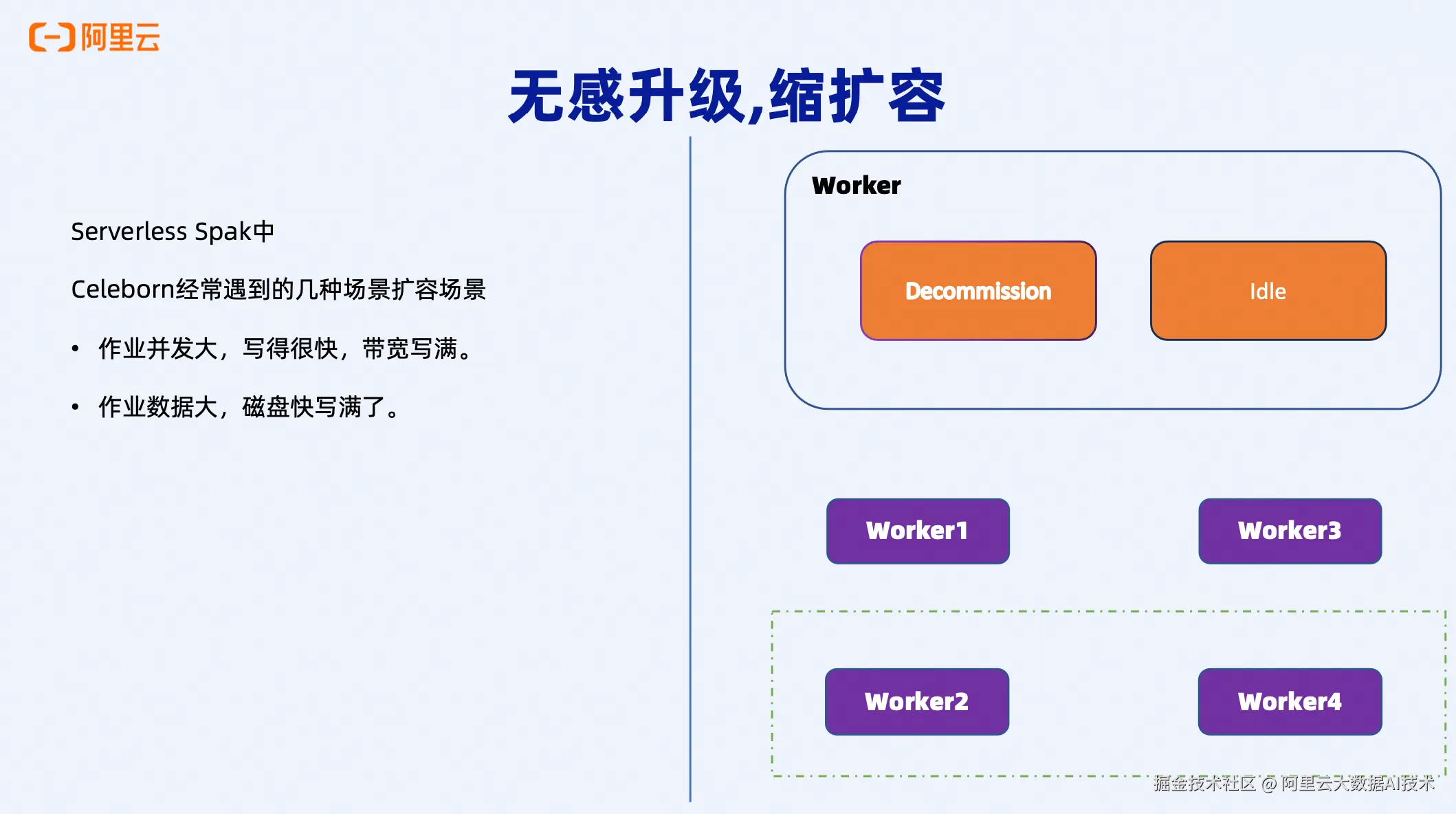
缩容场景: Decommission 机制
当某个Worker进入Decommission状态时,意味着该Worker不再接受新的作业分配,但会继续完成已分配的任务。就像一个员工"上完这个班再下班"------不接新活,但把手头的活干完。完成所有任务后,Worker可以安全地下线进行升级,或者直接进行缩容移除。
扩容场景:Dynamic Resource 动态资源+故障自愈+Stage Rerun
在Serverless Spark环境中,主要有两种扩容场景:
-
带宽压力扩容: 作业并发大、写入速度快,导致带宽打满、CPU和内存压力高
-
磁盘容量扩容: 作业数据量大,磁盘空间即将用尽
假如某作业需要写入500多TB的Shuffle数据,而集群初始磁盘容量不足500TB。在扩容过程中,集群总容量勉强达到600TB。此时面临一个关键问题:新扩容的Worker能否分担正在运行作业的压力?
Dynamic Resource 动态资源能力: 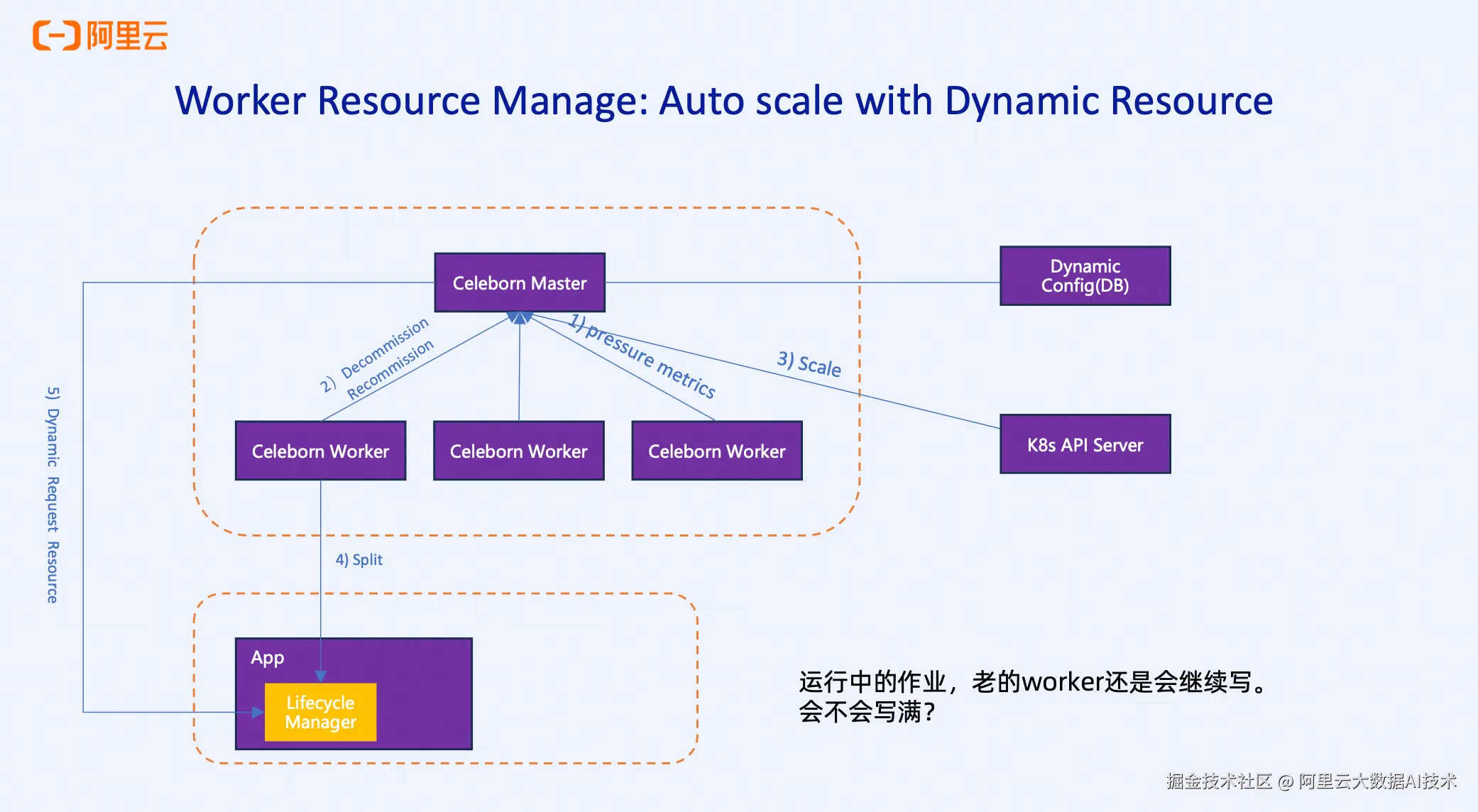 Celeborn通过Partition Split机制优雅地解决了这个问题。正在运行的作业,当数据达到partition的split阈值后,会自动通过LifecycleManager向新加入的Worker申请资源,将后续数据写入新的Worker。这样,新节点可以立即分担正在运行作业的压力,而不是只能服务于新启动的作业。同时,老的Worker也不会立即停止写入,因为它们仍处于可用状态。新老Worker并行工作,共同完成作业的数据写入。
Celeborn通过Partition Split机制优雅地解决了这个问题。正在运行的作业,当数据达到partition的split阈值后,会自动通过LifecycleManager向新加入的Worker申请资源,将后续数据写入新的Worker。这样,新节点可以立即分担正在运行作业的压力,而不是只能服务于新启动的作业。同时,老的Worker也不会立即停止写入,因为它们仍处于可用状态。新老Worker并行工作,共同完成作业的数据写入。
故障自愈 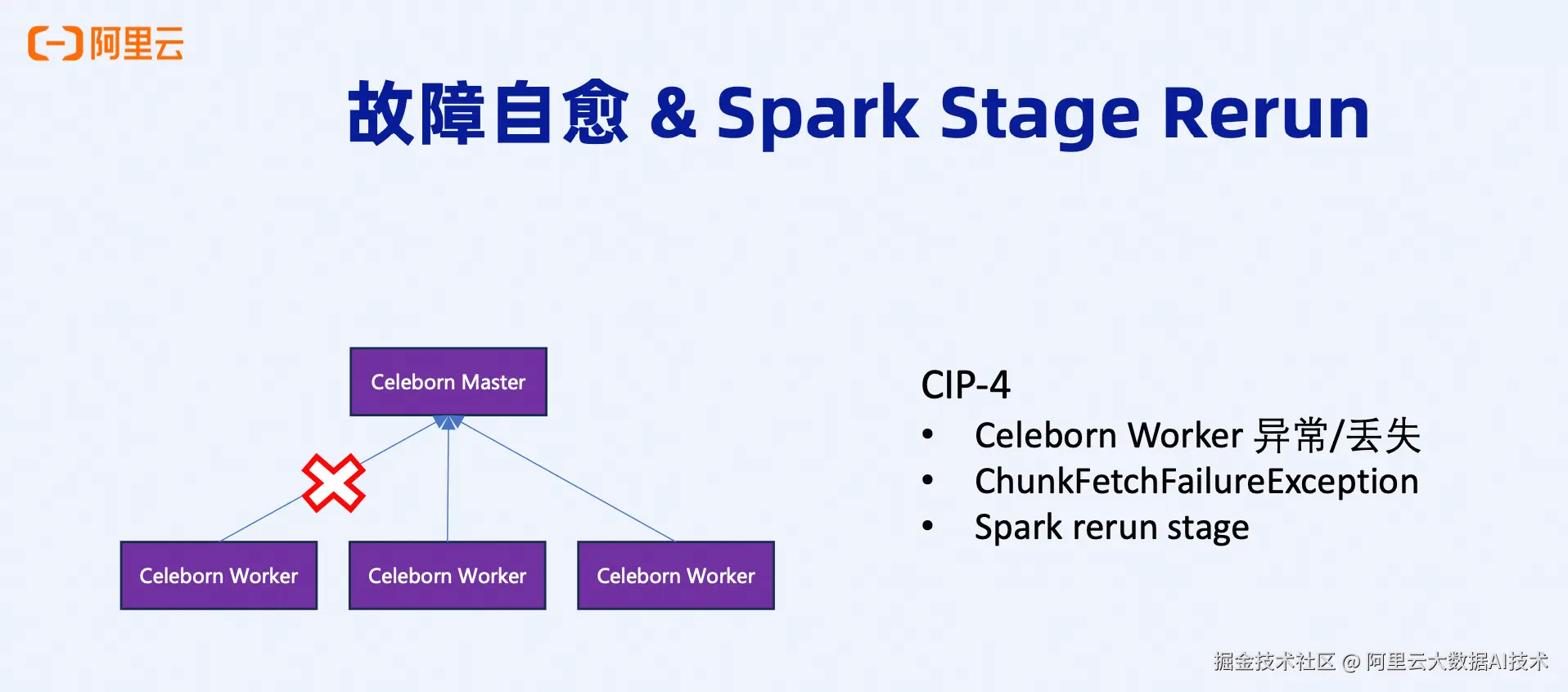
当某个Worker的磁盘使用率达到64%等较高水位时(可配置),该Worker仍然可用。但如果继续写入导致磁盘使用率接近98%,Celeborn会自动停止向该Worker写入数据,主动触发Split,将数据分流到其他健康的Worker。
这个配置项叫做disk reserve size,通过预留一定的磁盘空间,可以防止Worker被"写爆",同时将压力均匀分摊到新上线的Worker上。这也是Celeborn故障自愈能力的一个重要体现------当某个Worker压力过大、健康状态不佳时,会自动临时下线,等待恢复正常后再重新加入。
Stage Rerun
在早期版本中,如果某个Celeborn Worker的磁盘损坏导致数据丢失,唯一的解决方案是增加Worker节点,并使用双副本机制------同一份数据写两次到不同的Worker。虽然这能保证可靠性,但成本翻倍,对于企业来说并不经济。
Stage Rerun机制(CIP-4):
Celeborn在近期版本中引入了Stage Rerun能力,大幅降低了容错成本。当Reducer读取数据时发现某部分数据丢失,Celeborn会向Spark返回ChunkFetchFailureException错误,告知Spark需要重跑数据丢失对应的Stage。
整个作业不会失败,只需要重新执行丢失数据涉及的Stage,然后重新写入和读取这部分数据即可。这种局部重跑机制,恢复速度比整个作业失败后重跑要快得多,而且不需要双副本,节省了存储成本和写入开销。
通过Master-Worker之间的心跳监控和故障检测,Celeborn能够快速发现Worker异常或丢失,触发Stage Rerun流程,实现真正的故障自愈。
安心:原生支持 Spark AQE 优化,应对真实业务复杂性
Spark的自适应查询执行(AQE, Adaptive Query Execution)是重要的性能优化特性,主要包括Partition合并、Join策略切换和Skew Join优化。要支持AQE,Shuffle服务必须具备两个核心能力:
- Partition Range Read: 一个Reducer读取多个Partition
- Mapper Range Read: 一个Reducer读取多个Mapper的数据
Partition Range Read:
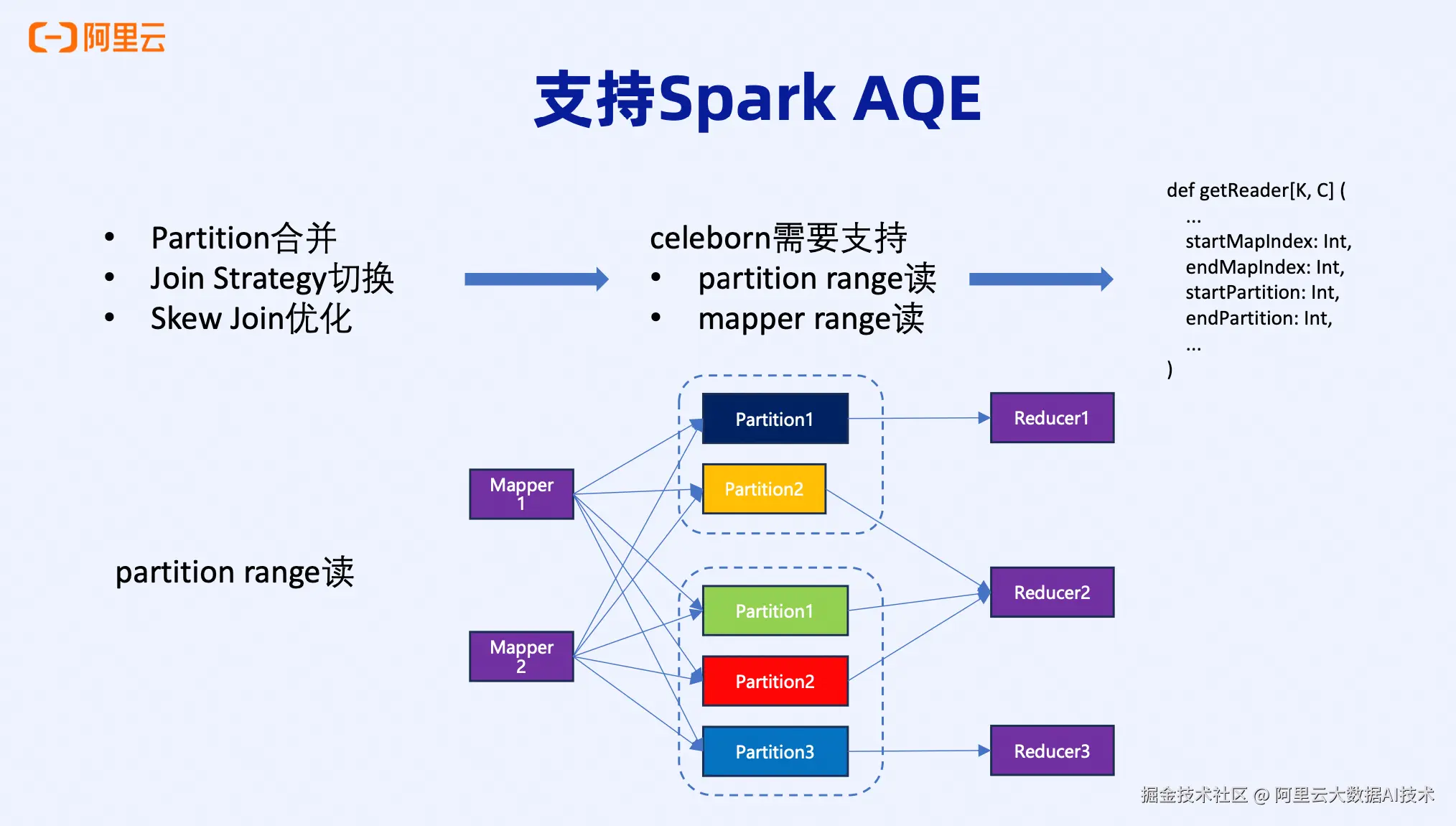
这对Celeborn来说是天然支持的。无论一个partition被split成几个文件,逻辑上仍然是一个partition。Reducer读取一个partition和读取多个partition,在实现上没有本质区别。
Mapper Range Read:
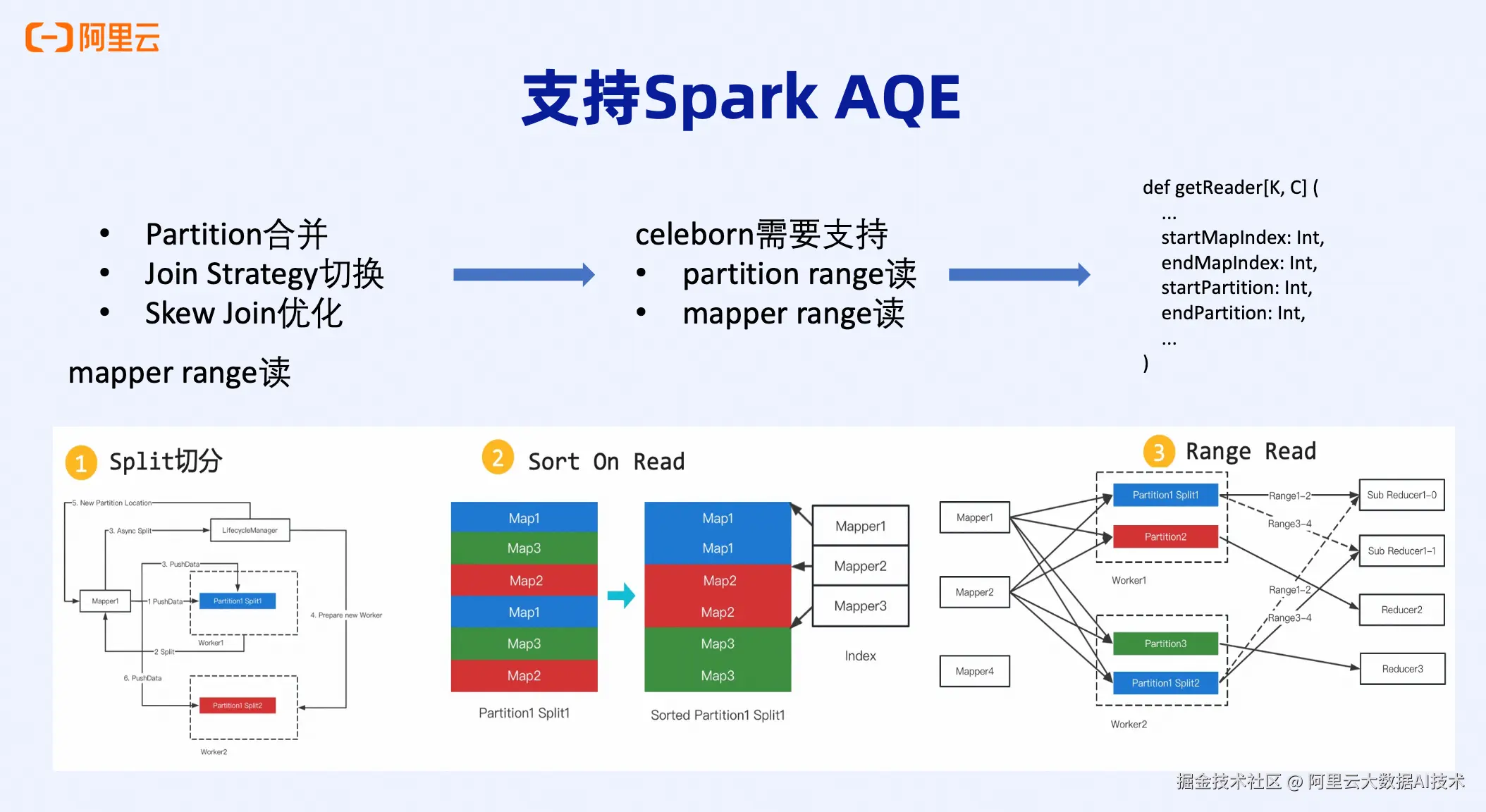
Mapper Range Read则更具挑战性。原本一个Mapper的数据在本地是有序的,但Celeborn的Push Shuffle将不同Mapper的数据分散到了不同的Worker。现在要重新合并这些数据,就像"复合"一样,需要做额外的工作------对partition中的数据按Mapper维度重新排序。
这个排序操作IO开销大,存在超时风险。在Serverless Spark生产环境中,Mapper Range Read场景很常见:
场景一:Spark Skew Join 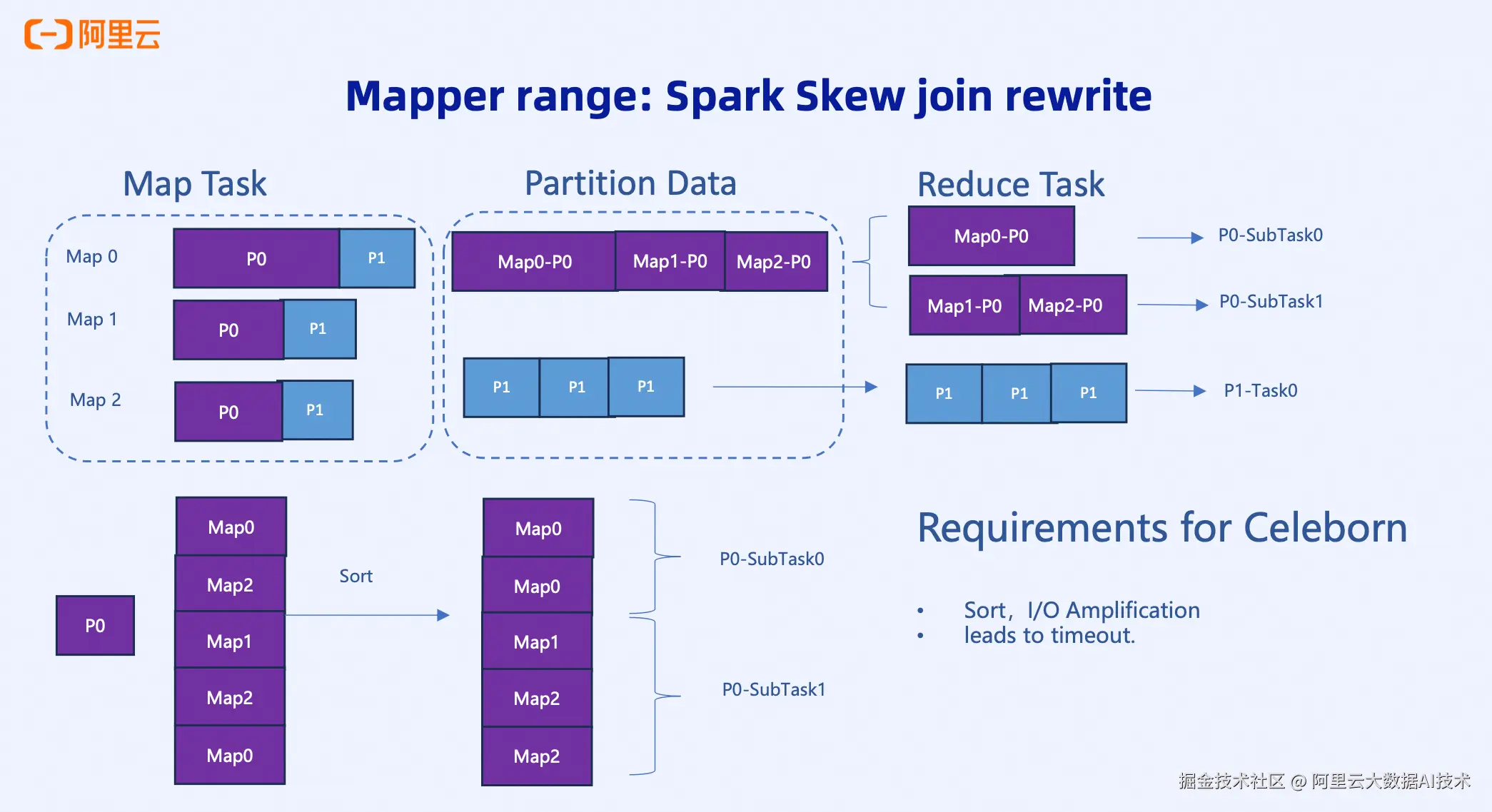
当某个partition数据特别大时,让单个Reducer读取会非常慢,导致整个作业都要等待这个慢Task。Spark AQE会将这个大partition拆分成多个Sub Reduce Task并行读取,这就需要按Mapper维度进行数据划分。
场景二:LocalShuffleReader(Sort Merge Join转Broadcast Hash Join) 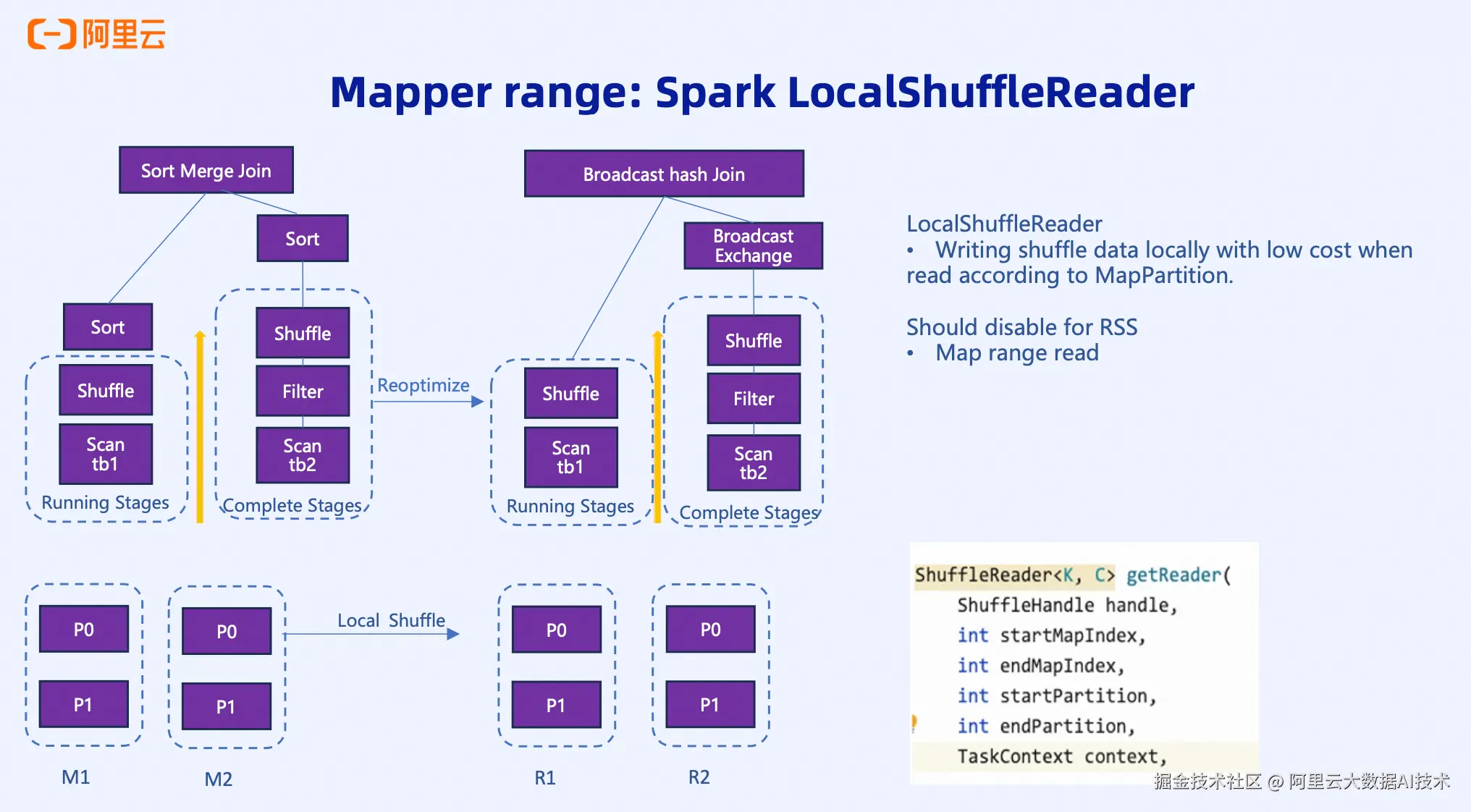
当Sort Merge Join的某个表经过Filter后变得很小,小到可以进行Broadcast时,Spark AQE会动态将执行计划从Sort Merge Join切换为Broadcast Hash Join。这个过程中会产生一个Broadcast Exchange阶段,需要进行Mapper Range Read。
在实际生产案例中,这两种场景不仅常见,而且往往伴随着数据倾斜------不仅partition之间有倾斜,即使按Task划分后,各个Task的数据量仍然不均匀。
Celeborn的创新解决方案
Trunk Read
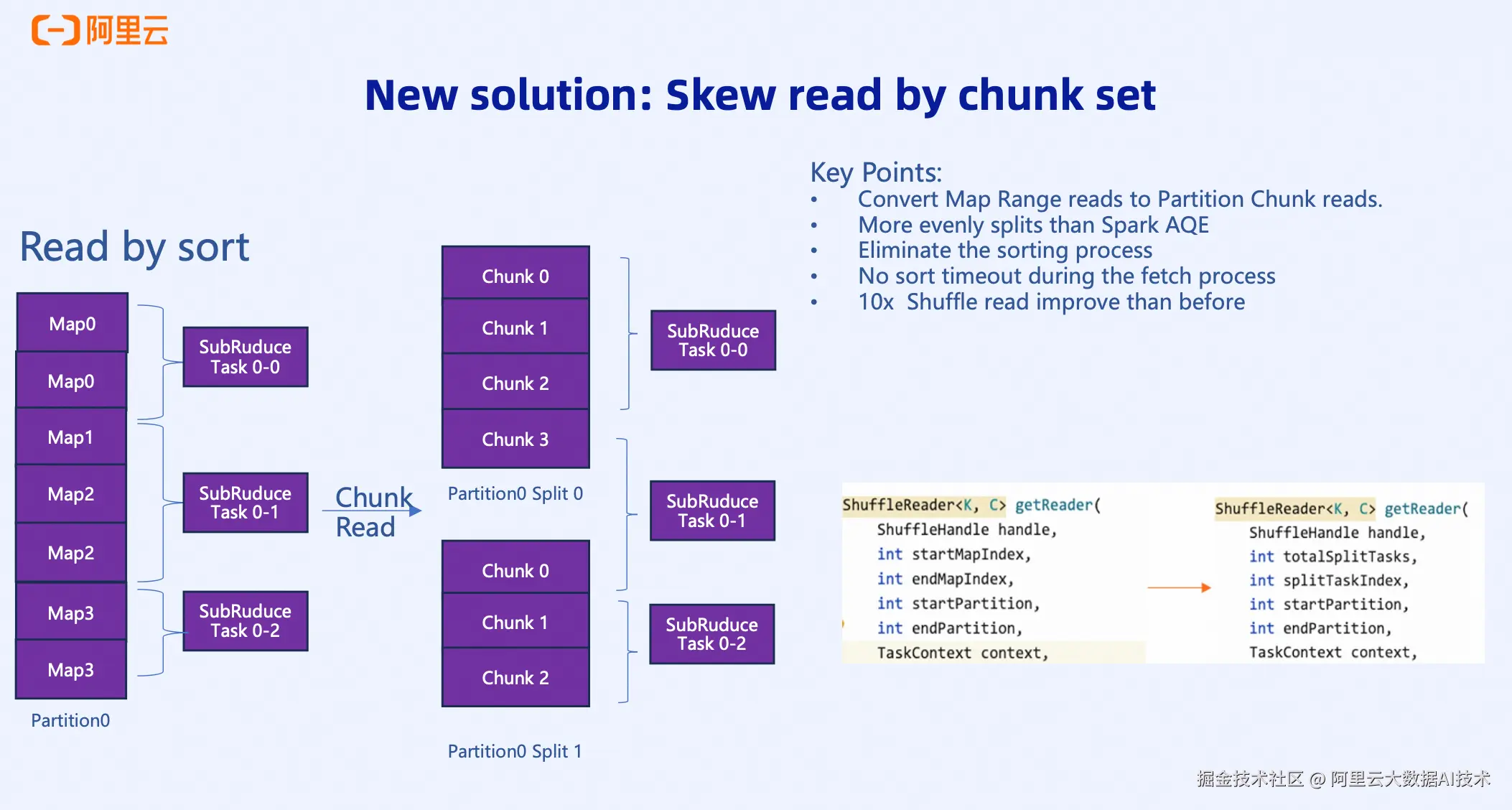
Celeborn在0.5版本中将Sort Read优化为Chunk Read,实现了性能的飞跃。
用一个生动的比喻来说明:
Sort Read: 像是让6个人排队自己切蛋糕,每个人想吃多少切多少。切的多的人吃得久,切的少的人吃得快,快的人还要等慢的人,整体时间很长。
Chunk Read: 直接按固定方式切成6块均匀的蛋糕,每个人拿一块直接吃。大家吃的时间一样长,而且不用排队,显著提高了效率。
具体来说,Chunk Read将Mapper Range读取转换为Partition Chunk读取。数据被分成均匀的Chunk,每个Sub Reduce Task读取相应的Chunk Set,避免了排序过程,消除了排序超时风险,实现了更均匀的负载分配。
在测试中,Chunk Read在特定场景下可以达到10倍的性能提升,特别是在Task级别也存在数据倾斜的情况下,效果更加显著。
应对数据倾斜的并发Shuffle Writer
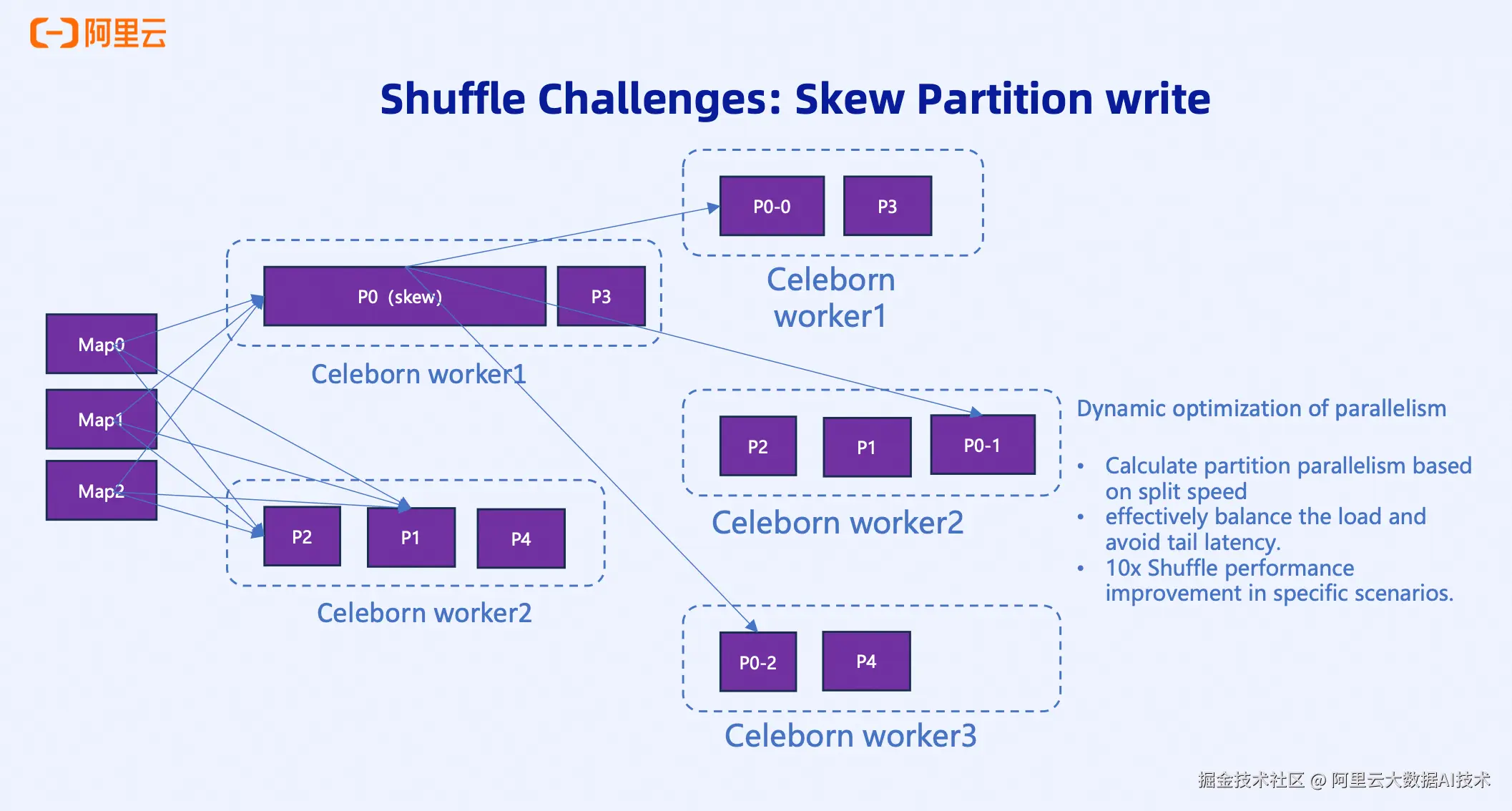 Partition Split机制虽然强大,但也会面临数据倾斜带来的挑战。当某个partition特别大,需要不断Split时,会产生长尾效应------写入快的partition需要等待写入慢的partition。
Partition Split机制虽然强大,但也会面临数据倾斜带来的挑战。当某个partition特别大,需要不断Split时,会产生长尾效应------写入快的partition需要等待写入慢的partition。
原因在于Celeborn一直以来的Partition Split是串行阻塞的,只有在需要时才进行Split,无法一次性拆分多个。
社区的多种优化方案:
Celeborn社区对这个问题展现出很高的活跃度,提出了多种解法:
方案一:指数级Split 第一次Split分1个,第二次分2个,第三次分4个,随着Split次数增加,每次分配的资源数量呈指数增长。
方案二:动态并行度优化 根据Split速度动态计算需要分配的资源数量。如果Split很快,说明数据写入速度快,就多分配一些;如果Split总数不多且比较慢,就少分配,同时预留一些冗余空间继续写入。
这种方案将单线Split变成了多线Split,实现了并发的Shuffle Writer。虽然这个方案还在社区讨论中尚未合入主分支,但在生产环境中已经得到验证,在特定场景下同样可以带来10倍的性能提升。
四、未来规划:更强大的Celeborn生态
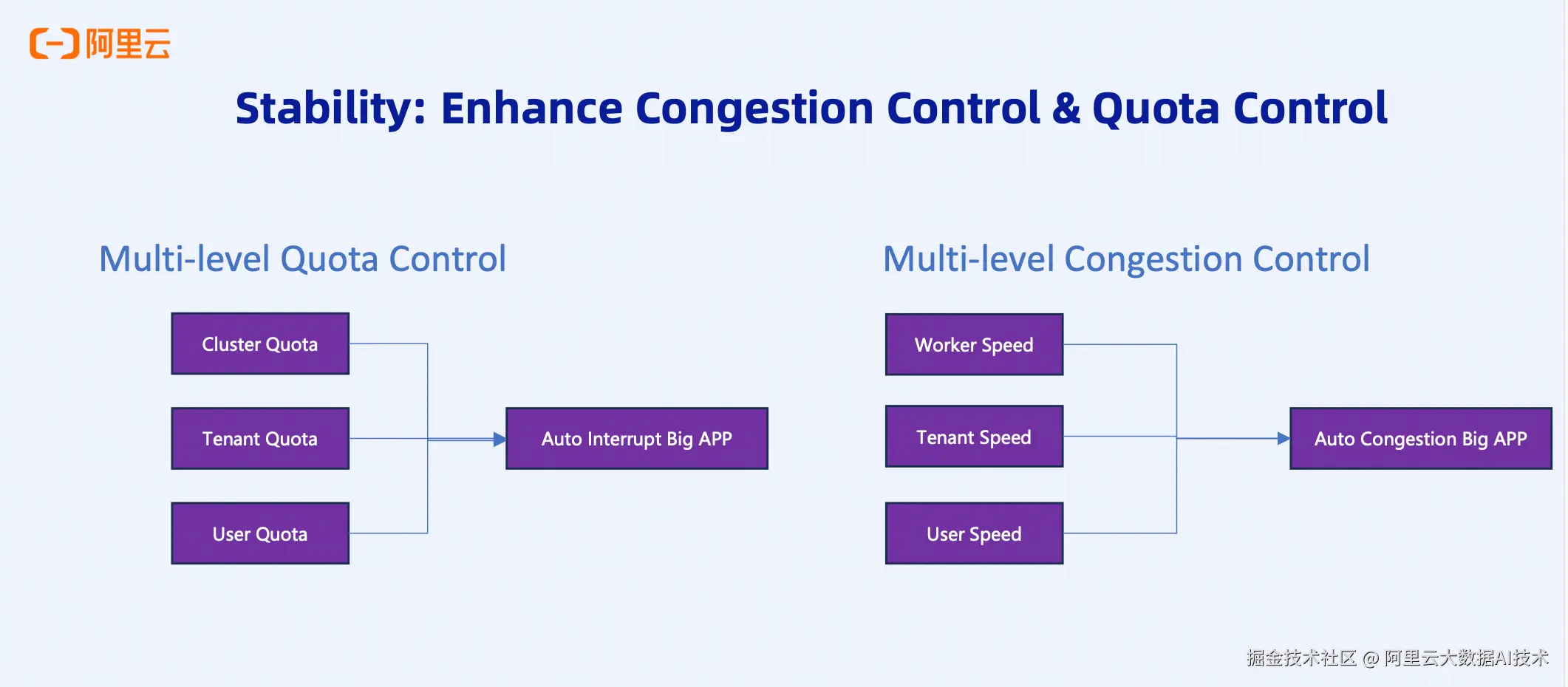
增强拥塞控制与配额管理
Celeborn未来将实现多层次的拥塞控制和配额管理机制:
多层次拥塞控制:
-
集群层面: 控制整个集群的流量上限
-
租户层面: 控制单个租户的写入速度
-
用户层面: 控制单个用户的Shuffle速度
-
Worker层面: 控制单个Worker的负载压力
多维度配额控制:
除了速度控制,还将支持多维度的配额限制,可以针对不同的用户、租户设置不同的资源配额。当超过配额时,可以自动中断大作业或对大作业进行拥塞控制,确保集群资源的公平分配。
版本演进与新功能开发
EMR Serverless Spark目前使用的是Celeborn 0.5版本,而社区已经迭代到0.6版本。我们正快速推进 Serverless Spark 的 Celeborn 与社区版本保持同步,获得社区最新的稳定性和性能优化。
此外,我们将持续进行0.7版本新特性开发:
-
Auto Scale(自动扩缩容): 根据负载自动调整集群规模
-
App Priority(应用优先级): 支持不同优先级的作业调度
-
Parallel Shuffle Writer(并发Shuffle Writer): 正式将并发Split能力合入主线
这些新特性将进一步提升Celeborn的自动化运维能力和资源利用效率,为企业级大数据处理提供更加智能和高效的Shuffle服务。