一、问题和需求
传统的OCR技术,比如umi-ocr,可能存在下面的问题。1)对于横的照片,不能自动转正,或转正的效果比较差,导致最后识别效果很差。2)对于一些照片,识别效果不够好,可能出现错误的识别结果,导致后续给大模型解读的时候,造成效果比较差。3)表格类的图片识别效果一般都较差。 4)对应印章信息识别效果很差,比如印章信息的日期信息。 5)公式,手写体基本上识别失败。
现在有个需求,文件吐过是图片信息,我需要让大模型对图片的信息进行一致性审查,看看用户上传的附件信息和用户填写到系统的信息内容是否一致。比如身份证信息,用户可能上传的身份证信息大多数是扫描件,还是横着的,如果走传统的OCR识别文字,再把文字和系统信息对比的话,很有可能就是传统OCR识别的效果差,导致最终审核结果偏差。因此考虑多模态模型来解决上述问题。
因此,我考虑Qwen3.5开源模型的图片理解能力是否已经达到较好的水平,如果水平较好的话,可以考虑直接 图片 + 任务文字 作为模型输入,让模型完成图片信息抽取工作。替代之前的流程,即 图片 通过 OCR 转 图片字符,图片字符 + 任务文字 作为模型的输入。
本章将从下面几个方面测评Qwen3.5开源模型
1.Qwen3.5原生多模型能力是什么?
2.Qwen3.5模型如何通过VLLM企业级部署和python程序调用?
3.Qwen3.5模型能够解决传统OCR困局?包括但不限于 印章信息识别、表格信息识别、旋转图片的识别、公式识别、手写体识别、手写体不同颜色字体识别...
4.Qwen3.5模型调优,图片调优,视频识别,文件识别流程?
二、Qwen3.5原生多模态能力概要

2.1 简介
作为原生视觉-语言模型,Qwen3.5-397B-A17B 在推理、编程、智能体能力与多模态理解等全方位基准评估中表现优异,助力开发者与企业显著提升生产力。该模型采用创新的混合架构,将线性注意力(Gated Delta Networks)与稀疏混合专家(MoE)相结合,实现出色的推理效率:总参数量达 3970 亿,每次前向传播仅激活 170 亿参数,在保持能力的同时优化速度与成本。我们还将语言与方言支持从 119 种扩展至 201 种,为全球用户提供更广泛的可用性与更完善的支持。
在底层架构上,模型采用了与Qwen3-next相似的Linear Attention Gated DeltaNet + Gated Attention机制。更重要的是,Qwen3.5通过引入M-RoPE(Mixture of Rotary Position Embeddings)和3D位置编码技术,将图像、视频等时空信息原生融入到语言模型的位置嵌入中,实现了真正意义上的端到端多模态处理,而非传统视觉编码器与语言模型拼接的方案。
2.2 多模态模型和自然语言模型的基础
这小节,需要搞清楚,qwen3.5系列的原生多模态模型到底是什么意思?和传统的文本模型有什么区别?
在正式进入技术拆解之前,我们先对Qwen3.5的整体架构有一个宏观认知。Qwen3.5采用了混合层架构,每3层线性注意力中插入1层标准全注意力,这种架构设计兼顾了训练的并行性和推理的高效性。同时,无论是全注意力还是线性注意力,都引入了Qwen3-Next中的门控机制,其中线性注意力部分采用了DeltaNet结构,进一步优化了长序列处理能力。更为关键的是,Qwen3.5从预训练阶段就融入了视觉 数据,实现了文本与视觉信息的原生融合,摆脱了传统多模态模型"文本基座+视觉分支"的拼接式设计,这也是其被称为"原生多模态"的核心原因。
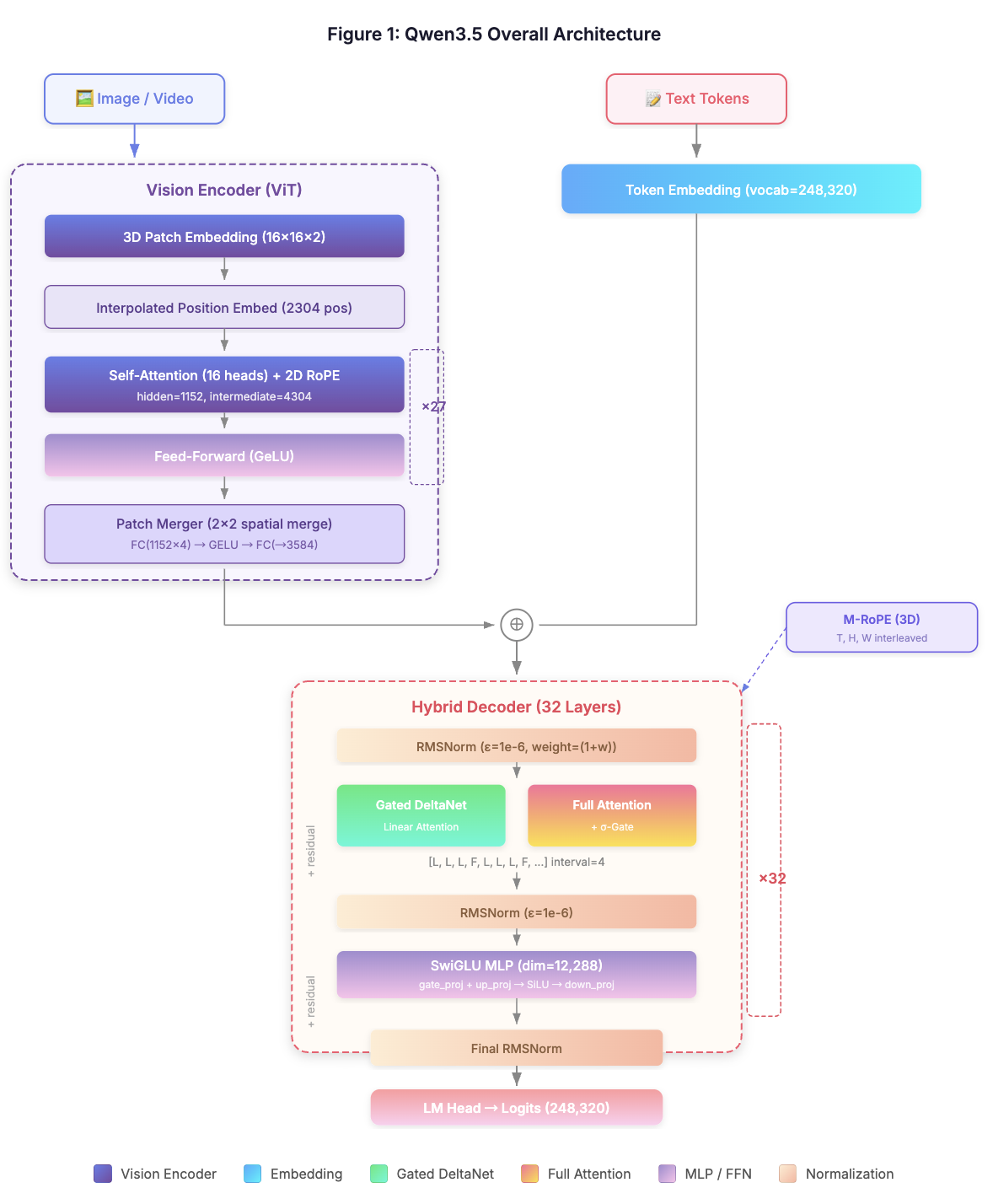
个人总结:
qwen3.5系列模型原生支持 图片 + 文字输入
图片会按照图片像素转换成图片token,文字通过内置字典转换成token,最后变成都需要转换成向量矩阵且合并给给到大模型处理,大模型输出文字。
因此图片中的信息,不会因为图片是旋转的、倒立的、手写体、红色字体、印章信息、表格信息而导致图片信息丢失(实测也是如此)
2.3 图片Token的数量如何计算?
根据我之前的纯文本模型,比如qwen3系列模型,我实测得到的经验是 1 token = 1.4 字符。
那么同样的道理,qwen3.5系列模型的图片token 应该等于多少图片。
如何使用Qwen3.5模型实现视觉理解(图像与视频理解)-大模型服务平台百炼(Model Studio)-阿里云帮助中心
根据阿里云官方文档规则,对于Qwen3.5系列模型,其计算方式有明确的公式:
图片Token数 = (h_bar / 32) × (w_bar / 32) + 2
-
h_bar和w_bar:是图片高度和宽度调整到32的整数倍后的值。 -
32 x 32:这是该模型的关键参数,意味着每 1024 个像素(32x32的方块)被压缩抽象成1个视觉Token。 -
+ 2:系统会自动添加一个开始和结束的特殊标记。
举个例子:一张512x512的图片。
-
先调整尺寸(本身已是32的倍数):h_bar=512, w_bar=512。
-
计算Token数:(512/32) × (512/32) + 2 = 16 × 16 + 2 = 258个图片Token。
所以,图片Token的数量由图片的分辨率(像素数)直接决定,分辨率越高,Token越多,模型看到的细节也越丰富,但同时消耗的显存和算力也越大。
因此所谓的一图片等于多少token,就是像素换算,1视觉token = 1024 像素
根据阿里云官方文档,Qwen3.5系列模型的视觉处理规则是:
-
每个视觉Token对应32×32像素(即1024像素/Token)
-
Token上限为16384个
-
对应的像素上限为:16384 × 32 × 32 = 16,777,216像素 (和文档符合)
这意味着模型理论上支持的最大图像分辨率约为:
-
正方形图像:√16,777,216 ≈ 4096×4096像素
-
16:9宽屏:约5461×3072像素
-
4:3标准:约4730×3548像素
三、VLLM安装
3.1 创建conda虚拟环境
conda环境创建可以看我之前的博文手把手教你使用云服务器和部署相关环境!!!_lanyun-tmp-CSDN博客
conda create -n vllm python=3.12
conda activate vllm
3.2 安装vllm
pip install vllm
pip show vllm
3.3 下载模型
进入到模型存放的目录,先用另一个虚拟环境安装一下modelscope,再使用下面的命令下载模型到当前目录。
modelscope download --model Qwen/Qwen3.5-2B
3.4 启动模型
进入到vllm环境下,输入下面的命令可以看到使用vllm启动的全部参数配置
vllm serve --help=all
或者去官网查看所有的配置参数 vLLM CLI Guide - vLLM
vllm serve /root/model/Qwen3.5-2B
--gpu-memory-utilization 0.6 \
--host 0.0.0.0 \
--port 8004 \
--max_model_len 10000 \
--served-model-name Qwen3.5-2B \
--gpu-memory-utilization 0.4 \
--mm-encoder-tp-mode data \
--mm-processor-cache-type shm \
3.5 启动模型卡主
然后在下面卡住了
(EngineCore_DP0 pid=2340912) <frozen importlib._bootstrap_external>:1301: FutureWarning: The cuda.nvrtc module is deprecated and will be removed in a future release, please switch to use the cuda.bindings.nvrtc module instead.
Loading safetensors checkpoint shards: 0% Completed | 0/1 00:00\
Loading safetensors checkpoint shards: 100% Completed | 1/1 00:02\<00:00, 2.23s/it
Loading safetensors checkpoint shards: 100% Completed | 1/1 00:02\<00:00, 2.23s/it
(EngineCore_DP0 pid=2340912)
(EngineCore_DP0 pid=2340912) INFO 03-20 09:27:48 default_loader.py:293 Loading weights took 2.43 seconds
(EngineCore_DP0 pid=2340912) INFO 03-20 09:27:49 gpu_model_runner.py:4364 Model loading took 4.25 GiB memory and 3.395487 seconds
(EngineCore_DP0 pid=2340912) INFO 03-20 09:27:49 gpu_model_runner.py:5280 Encoder cache will be initialized with a budget of 16384 tokens, and profiled with 1 image items of the maximum feature size.
然后我查找了多模态的说明部分,发现 budget of 16384 tokens,
如果需要部署的模型更好调用工具可以加上下面两个
--enable-auto-tool-choice \
--tool-call-parser qwen3_coder \
vllm serve /root/model/Qwen3.5-2B --host 0.0.0.0 --port 8005 --max_model_len 6000 --served-model-name Qwen3.5-2B --gpu-memory-utilization 0.6 --mm-encoder-tp-mode data --mm-processor-cache-type lru
vllm serve /root/model/Qwen3.5-2B --host 0.0.0.0 --port 8004 --max_model_len 6000 --served-model-name Qwen3.5-2B --gpu-memory-utilization 0.7 --mm-encoder-tp-mode weights --mm-processor-cache-type lru --trust-remote-code --max_num_seqs 8 --mm-processor-kwargs '{"max_pixels": 524288}'
四、模型调用代码
五、模型效果
3.1 公式
输入:

输出:

考虑到图片本身比较模糊,没有办法识别的效果比较好
3.2 手写体公式
模型输入:
你能知道我给你的图片是横的还是竖的吗,我给你的是手写体,有红笔写的就是内容比较重要的,需要你输出的时候使用md格式加粗输出,表示是红色的字体,把图片的所有文本信息返回给我,回答只需要是 横的 或 竖的 然后加上图片完整的可以复制的MD格式内容

模型输出:
{'type': 'text', 'text': '横的\\n\\n# 离散数学\\n## §1 命题逻辑的基本概念\\n\\n### \*\*\[命题与联结词**\n**命题**\n非真即假的陈述句称为命题\n\neg: "因为 3\>2,所以 3 \\\\neq 2" 是一个
非真即假的陈述句\n"3\>2"、"3 \\\\neq 2"也都是命题,都为真,所以整体命题也是真\n\n**简单命题或原子
命题**\n"3\>2"和"3 \\\\neq 2"都是无法再拆分的命题,称为简单命题\n简单命题 + 联结词 = 复合命题\n\n**判断是否为命题**\n① 判断是否为陈述句\n② 判断它是否有唯一真值\n\neg: 判断\n④ 我正在说假话。\n**不
是命题**。因为若它为真 \\\\Rightarrow 表明我正在说真话;\n若为假 \\\\Rightarrow 我正在说真话。\n由
真推出假,表明是悖论。**悖论不是命题**'}]

可以看到,把内容还原到md编辑器中,可以说识别的效果很好了,1)红色字体 2)布局格式 3)手写字体
3.3 旋转图片测试
本地部署的模型测试通过,因为在2.2中,我们可以知道,图片信息是转换成图片token进入大模型中的,这意味着模型本身就可以像人一样理解图片信息。
六、参考文章
https://qwen.ai/blog?id=qwen3.5
Qwen3.5 Usage Guide - vLLM Recipes
vllm/vllm/model_executor/models/colqwen3_5.py at main · vllm-project/vllm
深度解剖Qwen3.5,字节跳动新一代原生多模态大模型的技术突破与底层逻辑_qwen3.5-vl-CSDN博客
使用VLLM生产部署阿里开源 Qwen3.5-35B ,跑满长上下文 + 28 路并发
OpenAI Chat API 参考-大模型服务平台百炼(Model Studio)-阿里云帮助中心
如何使用Qwen3.5模型实现视觉理解(图像与视频理解)-大模型服务平台百炼(Model Studio)-阿里云帮助中心