重温一场历时90的争论------平均偏差的优点
(Revisiting a 90 yearold
debate: the advantages of
the mean deviation)
York大学:Stephen Gorard
目录
[1. 引言(Introduction)](#1. 引言(Introduction))
[2. 何谓标准偏差?(What is a standard deviation?)](#2. 何谓标准偏差?(What is a standard deviation?))
[3. 何谓均值偏差?(What is a mean deviation?)](#3. 何谓均值偏差?(What is a mean deviation?))
[4. 何故使用标准差?(Why do we use the standard deviation?)](#4. 何故使用标准差?(Why do we use the standard deviation?))
[5. 我们为何要使用平均偏差?(Why might we use the mean deviation?)](#5. 我们为何要使用平均偏差?(Why might we use the mean deviation?))
[5.1 误差传播(Error propagation)](#5.1 误差传播(Error propagation))
[5.2 自由分布(Distribution-free)](#5.2 自由分布(Distribution-free))
[5.3 相关技术(Related techniques)](#5.3 相关技术(Related techniques))
[5.4 简单(Simplicity)](#5.4 简单(Simplicity))
[6. 总结(Conclusion)](#6. 总结(Conclusion))
1. 引言 ( Introduction**)**
本文探讨了数值分析对标准(偏)差 (standard deviation)概念及其近亲------方差 (variance)(差方,各数值与均值之差的平方再取平均值 )------的依赖性。这一探讨揭示了几个潜在的重要观点。首先,它提醒我们:即使像"标准差"这样看似拥有无可挑剔的数学渊源的基础概念,实际上也是一种社会建构,是历史演进的产物( Porter1986) 。其次,正因如此,完全可能存在同样具有合理性的替代方案;本文便概述了其中一种------平均绝对偏差 。第三,基于此,我们或许能够构建出一套更为简化的入门级统计学体系;该体系不仅足以满足许多研究目的的实际需求,而且对于初涉研究领域的学者而言,其学习门槛将大大降低,不再显得令人生畏(Gorard 2003a)。我们可以向这些新手研究人员保证:尽管传统的统计理论往往确有裨益,但在研究分析中运用数字这一行为本身,并不意味着他们必须全盘接受、甚至必须知晓那套特定的理论体系。
2. 何谓标准偏差? ( What is a standard deviation?)
"标准差"是度量"离散程度"或"分散范围"的一种指标。它常用作对一组得分分布范围进行概括性描述的工具,且通常与某种集中趋势指标------即"平均数"------相伴使用。其计算方法为:
**首先,将每个观测值与平均数之差的平方值进行求和;然后,将该总和除以观测值的总数;最后,求取所得结果的正平方根。**例如,给定以下一组独立的测量数据:
13, 6, 12, 10, 11, 9, 10, 8, 12, 9
它们的和为 100,因此其平均值为 10。它们相对于平均值的偏差分别为:
3, 4, 2, 0, 1, 1, 0, 2, 2, 1
为了求得标准差,我们首先将这些偏差平方以消除负值,从而得到:
9, 16, 4, 0, 1, 1, 0, 4, 4, 1
这些平方偏差之和为 40,而它们的平均值(即除以测量次数所得)为 4。这一数值定义为原始数据的"方差";而"标准偏差"则是其正平方根,即 2。通过求平方根,我们得以回归到一个与原始读数处于同一数量级的数值。因此,按照传统的分析方法,这十个数字的平均值为 10,标准偏差为 2。标准偏差这一指标能够揭示原始数据的离散程度,进而反映出平均值的代表性强弱。标准偏差 (SD)之所以采用这种构建方式,其主要原因在于:通过平方运算,所有的负偏差均被消除,从而使所得结果在代数运算中更易于处理。
3. 何谓均值偏差? ( What is a mean deviation?)
除了标准差(SD)之外,还有几种可用于概括数据离散程度的替代指标。其中包括:极差 (range)、四分位数 (quartiles)以及四分位距 (interquartile range)。然而,作为度量离散程度的指标,对标准差而言最直接的替代方案是平均绝对偏差 (MD -- absolute mean deviation)。该指标本质上就是每个数值与总体均值之间绝对差值的平均数。现给出如下一组独立的测量数据:
13, 6, 12, 10, 11, 9, 10, 8, 12, 9
它们的和为 100,因此其平均值为 10。它们相对于平均值的偏差分别为:
3, 4, 2, 0, 1, 1, 0, 2, 2, 1
为了求得平均偏差,我们首先忽略这些偏差中的负号以消除负值,从而得到:
3, 4, 2, 0, 1, 1, 0, 2, 2, 1
这些数值现在代表了每个观测值与平均数之间的距离,且不考虑差异的方向。它们的总和为 16,而这些数值的平均值(即除以测量次数所得)为 1.6。这就是"平均偏差"( Mean Deviation ) ; 对于初涉研究领域的人而言,它比标准差更容易理解,因为它本质上就是偏差值的平均数------即任何数值与总体平均数之间平均相差的量。它具有明确的含义,而数值为 2 的标准差则不具备这种明确性。既然如此,为何标准差如今被广泛采用,而平均偏差却在很大程度上遭到了忽视呢?
4. 何故使用标准差? ( Why do we use the standard deviation?)
早在1914年,Eddington 便指出:"在计算一系列观测数据的平均误差时,最好采用不计正负号的平均留数 (mean residual) 即**绝对平均偏差** ,而非均方留数 即**标准偏差**"(Eddington 1914, 147页)。他在实践中发现,"平均偏差"在处理经验数据时的效果优于标准偏差,尽管"这与大多数教科书的建议相悖,但经证明确是如此"(第147页)。随后,他还声称绝大多数天文学家也都得出了同样的结论。
Fisher (1920) 针对 Eddington 提出的经验证据,运用数学论证进行了反驳,指出在理想条件下,标准差比平均差更为"有效";如今,许多评论家都认可 Fisher 针对标准差的使用提供了全面且有力的辩护(例如 MacKenzie 1981, Aldrich 1997)。Fisher 曾提出,度量任何统计量优劣的标准应基于三个特征。首先,该统计量及其所代表的总体参数应当具有"一致性" (consistent)(即针对样本和总体,其计算方式应保持一致)。其次,该统计量应当具有"充分性" (sufficiency),意指它能够充分归纳并涵盖从样本中提取的、关于总体参数的所有相关信息。此外,该统计量还应当具有"有效性"( efficiency**)** ,意指作为总体参数的估计量,它具有最小的可能误差 。标准差与平均差均能满足前两个标准(且满足程度相同)。据 Fisher 所言,正是在满足最后一个标准------即"有效性"------方面,标准差展现出了其优越性。 当从一个呈正态(常态)分布的总体中反复抽取大样本时,这些样本各自的"平均差"所构成的标准差,要比这些样本各自的"标准差"所构成的标准差高出 14% (Stigler 1973)。因此,对于此类样本而言,其标准差是总体标准差的一个更为"一致"的估计量;在利用样本测量数据来估计总体标准差的方法中,它被公认为优于其他看似合理的替代方案 (Hinton 1995, 第 50 页 )。这正是标准差在随后被广泛推崇的主要原因,也是后世许多统计理论均以此为基础构建的根本所在。
另一个令人关切的问题是,构建"绝对平均偏差"( absolute mean deviation ) 公式所需的绝对值符号,在代数运算中往往难以处理 (http://infinity.sequoias.cc.ca.us/faculty/woodbury/Stats/Tutorial/Disp_Var_Pop.htm)。这使得开发更为复杂的分析方法,相较于使用标准差的情况而言,变得更加繁琐(http://mathworld.wolfram.com/MeanDeviation.html)。因此,如今我们所拥有一套基于标准差(及其平方------即方差)的复杂统计学体系;之所以如此,是因为在理想条件下,标准差的效率高于绝对平均偏差,且其在代数运算上更易于操作 。当然,标准差如今已演变为一种传统,统计分析理论中的诸多其他部分也均以此为基础(例如分布的定义、效应量的计算、方差分析、最小平方回归等等)。例如,标准差不仅构成了广为流传的 Gauss 分布(亦称"正态(常态)分布")定义的一部分,其定义本身也正是基于标准差而确立的。这种特性带来了一项优势:它使得研究者能够相当精确地阐明,在以均值为中心、向两侧延伸的每一个标准差区间内,该分布所涵盖的比例究竟是多少。正因如此,统计学家所掌握的诸多专业技能,其根基均在于对标准差的运用;而正是这些专业技能,构成了他们传授给统计学初学者的核心内容。
5. 我们为何要使用平均偏差? ( Why might we use the mean deviation?)
在另一方面,也有理由主张平均偏差更为可取,并且自 Fisher 以来,我们在分析史的发展道路上可能误入歧途了。事实上,在某些测量值存在误差的现实情境下,平均偏差比标准偏差更为高效;对于非完美正态分布的数据而言,它也更具效率;此外,它与许多其他实用的分析技术紧密相关,且更易于理解。接下来,我将逐一探讨上述各点。
5.1 误差传播( Error propagation**)**
标准差通过对相关数值进行平方运算,导致我们对数据离散程度的认知产生了一定程度的扭曲 。平方这一操作使得每一个与均值的距离单位离都呈指数级(而非加法级数)地放大;而随后对平方和进行开方运算,也无法完全消除这种偏差。正因如此,在上述示例中,标准差(2)会大于平均差(1.6),因为标准差在计算上更加侧重于那些较大的平均偏差。图 1展示了 255 组随机数的平均差与标准差所构成的散点图。其中有两点值得关注:首先,标准差总是大于平均差;其次,对于任意给定的平均差数值,可能对应着不止一个标准差数值,反之亦然。因此,这两个统计量所衡量的并非完全相同的事物。在大量试验(例如图中所示的255组数据)中,两者的 Pearson 相关系数略低于 0.95;按照惯例,这意味着两者约有 90% 的变异性是相互重叠的。如果仅凭这一点便足以断言两者衡量的是同一事物,那么我们理应优先选用平均差,因为它在计算上更为简便。反之,如果两者衡量的并非同一事物,那么最关键的问题就不在于"哪一个统计量更为可靠",而在于"哪一个统计量真正衡量了我们所关注的特定属性"?
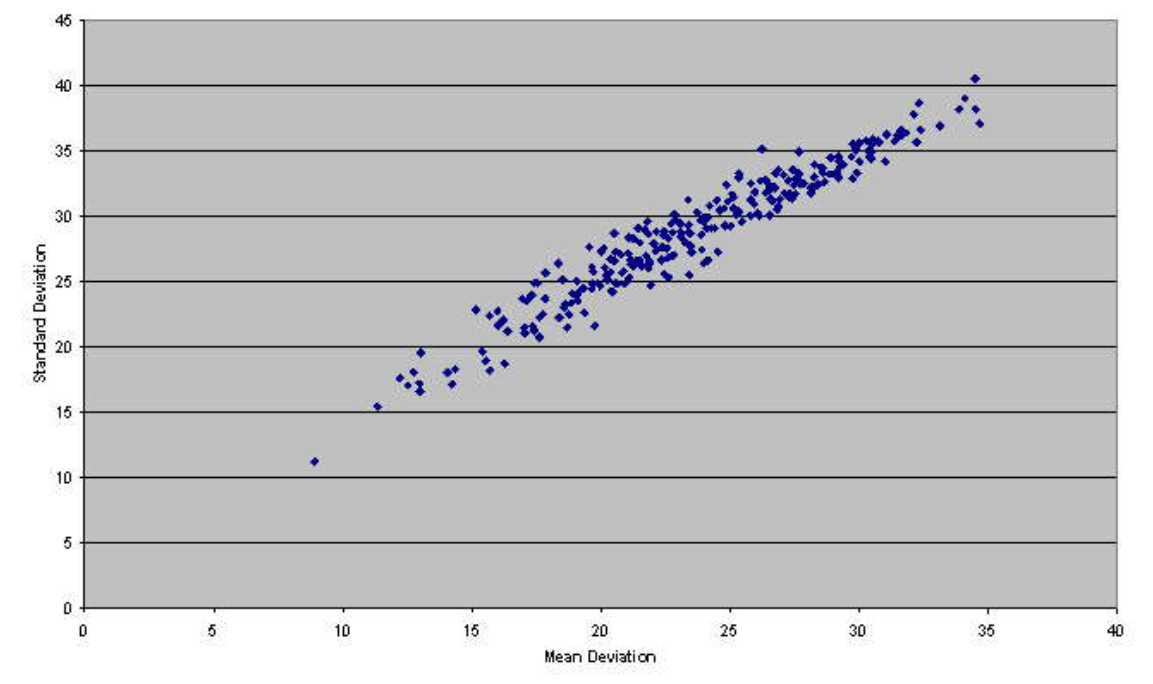
注:本示例基于 255 次试验生成,每次试验均采用一组介于 0 到 100 之间的 10 个随机数。此类示例中普遍存在的散点效应及整体曲线关系,归因于标准差计算过程中涉及的平方和。
-------------------------------------图 1 :随机数集的均值与标准差比较-------------------------------------
标准差那种显而易见的优越性,其实并不像教科书中所通常描绘的那样已成定论(见上文) 。例如,Tukey(1960)及其他学者随后的研究表明,Eddington 当年的观点是正确的,而 Fisher 至少在某一方面显得有些脱离实际。Fisher 关于标准差与平均差相对效率的计算,是基于观测数据中完全不存在任何误差这一前提之上的。 然而,对于那些数据中含有微量"污染"(即误差)的正态分布而言,"样本标准差相对于平均差所拥有的那种在无污染情境下成立的相对优势,将会发生戏剧性的逆转"( Barnett and Lewis 1978, 第159 页 )。哪怕误差成分低至 0.2% (即在 1000 次观测中仅包含 2 个误差点),也足以彻底扭转标准差相对于绝对平均偏差的优势地位(Huber 1981)。因此,在所有那些符合现实情境、且观测与测量过程中难免会产生微小误差的场合下,绝对平均偏差实际上具有更高的效率(例如,当误差成分达到 5% 时,绝对平均偏差的效率甚至超过标准偏差的两倍)。"在实际应用中,我们无疑应当优先选用绝对平均偏差,而非标准偏差"(Huber 1981, 第 3 页)。
统计推断背后的假设仅仅是为了数学上的便利;在实践中,人们通常会援引另一项未经明确论证的假设来为其辩护,即认为微小的初始误差只会导致结论中出现微小的误差。显然,事实并非如此(参见 Gorard 2003b)。"某些最常见的统计程序(尤其是那些针对潜在正态分布进行优化的程序)对于那些看似微小的、偏离假设的偏差,表现出极度的敏感性"(Huber 1981,第1页)。Fisher 与 Eddington 之间的分歧,实际上反映了数学与科学之间的差异。前者所关注的是一个柏拉图式的(Platonic)世界,那里充斥着完美的分布与理想的测量数据。或许,Fisher 曾投身其中的农业领域------一个能够通过无性繁殖来复制研究对象的领域------正是最接近这一理想世界的学科之一。而后者所关注的,则是亚里士多德式的(Aristotelian)、立足于经验研究的现实世界。Eddington 所处的领域------天文学------恰恰突显了追踪测量误差传播过程的重要性;在天文学中,通过计算得出的距离数据往往蕴含着巨大的潜在误差。我们在社会研究中所采用的那些充满瑕疵的测量数据,其性质更接近于天文学(这一主要依赖非实验手段的学科)中的数据,而非农业领域中的数据。
支撑标准差所谓优越性的另一个重要却往往被忽视的假设是:它涉及对从固定总体中随机抽取的样本进行分析(标准差的效率正是基于这一前提计算得出的) 。然而,在许多分析情境中,这一假设并不成立------例如,当分析对象为总体数据、非概率样本,甚至包含大量无应答数据的概率样本时。在上述所有情境下,计算相关数据的变异程度是完全恰当的,但此时不应试图去估算总体的标准差。因此,在从事社会科学研究的学者所面临的绝大多数实际情境中,标准差所标榜的优势实际上根本就不存在。
此外,由于极力推崇某些特定方法,部分统计学家被迫假定其所处理的数据实际上源自一个无限庞大的"超总体"(superpopulation)。例如,Camilli 援引 Goldstein 的观点指出:统计学家真正感兴趣的,并非将样本结果推广至某一特定的有限总体,而是将其推广至一个跨越时空的理想化超总体。Goldstein 声称:"社会统计学家在试图推广分析结果时,几乎不得不采纳'超总体'这一概念"( Camilli 1996, 第 7 页 )。鉴于篇幅所限,本文在此无法对这一奇特立场展开详尽批驳(详见 Gorard 2004);但显而易见的是,若涉及超总体,则其方差必为无穷大( Fama 1963 ),在此情形下,标准差所谓"更高效率"的论断便根本无法成立。分析者绝不能在援引超总体的概念的同时,又试图论证标准差的效率优势。
5.2 自由分布( Distribution-free**)**
除了关于测量"毫无误差"这一不切实际的假设之外, Fisher 的逻辑还依赖于数据呈现理想正态分布这一前提。如果数据并非完全符合正态分布,甚至根本不符合正态分布,结果又将如何呢?
Fisher 本人曾指出,对于非正态(或 Gauss )分布而言,平均偏差是一种更为适用的度量指标(Stigler 1973)。例如,通过重复模拟实验,便可针对均匀分布来直观地展示这一点。然而,我们首先必须审视这样一种论断中看似存在的"同义反复"现象:即认为样本标准差相较于样本平均偏差,能更稳健地估计总体标准差(例如 Hinton 1995)。我们不应将"样本标准差与总体标准差的关系"拿来与"样本平均偏差与总体标准差的关系"进行直接对比。正确的做法应当是将样本平均偏差与总体平均偏差进行比较;图 1 阐明了为何必须这样做------因为每一个平均偏差值都可能对应着不止一个标准偏差值(反之亦然),这种多对一或一对多的对应关系,若将平均偏差值与标准偏差值直接对比,便会造成平均偏差值显得不够稳健可靠的错觉。
重复进行的模拟结果表明,对于非正态分布而言,平均偏差的效率至少与标准偏差相当。例如,我从包含 0 到 19 之间 20 个整数的总体中,抽取了1000个样本(采用有放回抽样),每个样本包含 10 个介于 0 和 19 之间的随机数。已知该总体的均值为 9.5,平均偏差为 5,标准偏差为 5.77。这1000个样本的标准偏差分布在 2.72 至 7.07 之间,而样本的平均偏差则分布在 2.30 至 6.48 之间。这 1000 个估计标准偏差值围绕其真实均值 5.77 的标准偏差略高于1.0257;而这 1000 个估计平均偏差值围绕其真实均值 5 的标准偏差则略低于 1.020 。在对另外多组各包含 1000 个样本的数据集进行重复模拟时,上述数值及其差异方向均表现得相对稳定。这充分说明,对于涉及随机数的此类均匀分布而言,平均偏差的效率至少与标准偏差的效率相当。
正态分布,就像"无误差测量"这一概念一样,本质上只是一种数学构想。在实际应用中,科学家们所处理的观测数据往往仅是与这种理想模型相似或近似。然而,严格的正态性却是 Fisher 证明标准差具有统计效率时的基本假设之一。Eddington 所意识到的关键在于:实际应用中总是难免会出现偏离正态分布的微小偏差,而这些微小偏差却会对理想化的统计程序产生相当重大的影响(Hampel 1997)。通常而言,我们所观测到的数据分布往往呈现出"长尾"特征------即相比于理想假设下的预期情况,实际分布中包含更多的极端数值。由于我们在计算标准差时需要对数据偏离均值的差值进行平方运算(而在计算平均差时则无需此步),因此,这种具有长尾特征的分布往往会导致标准差所反映的变异程度发生"膨胀"(Huber 1981)。平方运算这一步骤,使得数据点偏离均值的每一单位距离在数值上呈指数级(而非简单的加和级数)放大;而随后对平方和进行开方运算,也并不能完全消除由此产生的偏差。当然,在实际工作中,这一事实往往会被一种普遍做法所掩盖------即对所谓的"异常值"(outliers)进行剔除(Barnett and Lewis 1978)。事实上,我们习惯于采用标准差而非平均差作为统计指标,恰恰构成了施加在数据分析人员身上的一种隐性压力,促使他们去忽略数据中的任何极端数值。
因对偏差进行平方处理而产生的扭曲,已导致形成这样一种文化:人们惯常建议学生剔除或忽略那些偏差较大的有效测量数据,理由是这些数据会对最终结果产生不当影响 。这种做法完全无视这些数据本身作为证据的重要性;这意味着,我们不再允许仅仅因为实证证据与我们关于数据分布的先验假设不符,就让这些假设受到挑战。优秀的科学研究理应珍视那些揭示了理论分析与实际观测之间存在有趣鸿沟的结果;然而,我们却有着一段漫长且不光彩的历史------即简单地无视任何威胁到我们基本信条的研究结果 (Moss 2001)。**极值数据在多种自然及社会现象中均属重要事件,其中包括城市扩张、收入分配、地震、交通拥堵、太阳耀斑以及雪崩等。我们不能仅仅因为它们似乎游离于模型之外,就将其简单地予以摒弃。**如果我们像少数评论家那样认真对待这些极值数据,便会发现:许多看似近似正态分布的数据集,实际上都呈现出某种持续偏离正态分布的特征。在这种情况下,基于标准差的统计技术往往会得出误导性的结论;因此,"诸如......平均绝对偏差......之类的变异性概念,对于描述此类数据分布的变异程度而言,是更为恰当的衡量指标"(Fama 1963, 第 491 页 )。
5.3 相关技术( Related techniques**)**
使用均值偏差的另一个优势在于它与一系列其他简单分析技术之间存在联系和相似之处,本文在此将简要介绍其中的几种。1997 年,Gorard 提出使用"隔离指数(segregation index)"(S)来概括个体在不同组织单元之间分布的不均衡程度,例如贫困家庭子女在特定学校中呈现出的聚集现象。该指数与几种较为成熟的指数(如相异指数(dissimilarity index))存在关联。然而,相较于这些指数,S 具有两大显著优势。其一,它具有极强的"组成不变性(composition invariant)"------这意味着该指数仅受分布不均衡程度的影响,而完全不受相关数值整体规模按比例变化的影响(Gorard 和 Taylor,2002)。也许更为重要的是,S 具有一种通俗易懂的含义:它代表了弱势群体(即贫困家庭子女)中必须更换其所属组织单元(即学校)的那部分人群所占的比例,唯有如此,弱势个体的分布才能达到完全均衡的状态。而其他指数------尤其是像基尼系数那样涉及对偏差值进行平方运算的指数------则无法得出这种易于解读的数值。S 与平均偏差之间的相似性令人惊叹:平均偏差实际上正是将 S 这一指数进行调整后所得到的结果,旨在使其适用于处理实数数据,而非仅仅局限于各类别的频数数据。此外,与 S 一样,平均偏差对数据中可能存在的问题具有较强的容忍度,且其含义也比其他潜在的竞争性指数更易于理解。
在社会研究中,当我们考察跨越时间、地域或其他类别存在的差异时,必须确保所使用的数值具有可比性(即"成比例")(Gorard 1999)。否则,可能会得出具有误导性的结论。实现这一目标的一个简便方法是:考察各项数值之间的差异,并将其与数值本身的量级(即数值本身的大小)进行相对比较。例如,在比较获得特定考试成绩的男生与女生人数时,我们可以用女生的人数减去男生的人数,然后将所得差值除以总人数(Gorard et al. 2001)。若将男生的人数记作 b,女生的人数记作 g,那么所谓的"成绩差距"便可定义为 (g - b)/( g + b)。这一指标与一系列其他的评分及指数密切相关,其中包括"隔离指数"(参见上文及 Taylor et al. 2000)。然而,此类方法所得出的结果往往难以解读,除非所处理的数值属于具有"绝对零点"的比例尺度数据(ratio values)------例如考试分数。若处理的是像《金融时报》(FT)股价指数这类不具备明确零点的数值,那么在考察跨越时间、地域或其他类别的差异时,最好参照其"常规波动范围"来进行考量。具体而言,如果我们用两个数值之间的差异除以该数值过往的波动幅度,便能自动解决数值尺度(即数值量级)的可比性问题。
这种通过计算"效应量"来评估分数差异之实质重要性的方法,正日益受到推崇;相比之下,那种仅评估差异之"显著性"(其效用相对较低)的做法则显得逊色(Gorard 2004)。其标准做法是:将两个平均数之差除以它们的标准差。换言之,在进行相减运算之前,先将这两个分数各自除以其对应的标准差,从而实现标准化。当然,我们也可以转而选用平均偏差作为除数(即分母)。举例而言,假设待比较的平均数之一是基于两个观测值 (x, y) 计算得出的。那么,它们的总和为 ( x + y ),平均数为 ( x + y )/2,而平均偏差则为 (|x - (x + y)/2| + | y - (x + y)/2|)/2。此时,经过标准化的平均数------即该平均数除以其平均偏差所得的值------将表示为:
由于分子和分母均被 2 除,因此可以将其约去,从而得到:
如果 x 和 y 相等,则不存在变异,平均偏差将为零。如果 x 大于平均值,那么在分子中,平均值 (x + y)/2 会从 x 中减去;而在分母中,y 则会从平均值 (x + y)/2 中减去。由此得出的结果为:
如果 x 小于平均值,则在分子中用 (x + y)/2 减去 x,而在分母中用 y 减去 (x + y)/2。由此得出的结果为:
例如,如果所涉及的两个数值实际上是 13 和 27,那么它们的标准化得分即为 20/710。因此,对于这一双数值的示例而言,基于平均偏差的效应量,实际上就是两个"成就差距"(见上文)之倒数间的差值。
诸如此类的相似之处表明,将基于概率论的传统统计学与"政治算术"等更为简化的方法加以统一,是具有可能性的。反过来,这将使新入行的研究人员能够掌握更为简便的数值处理技术,用于日常研究工作;同时,这些技术或许还能实现与各类其他形式数据的简易整合(Gorard 与 Taylor,2004)。
5.4 简单( Simplicity**)**
在计算技术的早期,计算单个数值的平方根似乎比求取一系列数值的绝对值要容易得多。如今情况已不再如此,因为所有的计算工作均由计算机代劳。相较于其他合理的替代指标,标准差目前显露出若干潜在的弊端;对于初涉研究领域的新手而言,其核心难题在于它缺乏显而易见的直观含义。那种先进行平方运算再求和、继而除以项数并开平方根的计算流程,使得最终得出的数值显得颇为怪异。事实上,它确实显得有些怪异;其对于后续数值分析的重要性,往往只能依靠研究者去"信赖"和接受。学生们被告知应当使用这一指标,但在社会科学领域,大多数学生最终往往索性放弃使用任何形式的数值分析方法( Murtonen 和 Lehtinen,2003 )。鉴于标准差与平均差在功能上殊途同归,平均差在含义上的相对简明性,或许正是我们今后在教学与实践中应优先选用平均差、而非那更为繁琐且缺乏直观意义的标准差的最重要理由。对于大多数希望通过统计指标来概括其研究数据离散程度的研究者而言,他们并不希望进行任何形式的数值"加工"------无论这种加工是代数运算还是其他形式。对于这类研究者,以及绝大多数作为研究成果受众的读者而言,选用平均差无疑是一种更为"民主"的选择。
6. 总结 ( Conclusion**)**
标准差作为任何统计学课程中最早讲授的概念之一,其复杂程度实属不必要的过高;在此,我们将其作为一个例证,用以说明在研究方法中,为了便于进行数学运算,往往牺牲了实用主义原则 。在极少数的理想情境下------即我们从随机样本中获得了完整且毫无测量误差的响应数据,并希望利用样本的分散程度来估算完美的"Gauss 总体"的分散程度------此时已有研究表明,相比于"平均偏差",标准差确实能更稳定地反映总体中与之对应的指标。值得注意的是,这种比较只能通过模拟实验来实现;因为在现实的研究工作中,我们根本无从知晓总体的真实数值------若已知晓,也就无需费力通过样本去进行估算了。归根结底,关于标准差的核心论点在于:我们可以依据样本观测数据计算出一个数值(即标准差),而该数值与依据总体数据以同样方式计算出的数值之间,存在着一种相对稳定的对应关系。然而,这一论点本身其实并无多大价值。仅仅具备"可靠性"这一特质,并不足以赋予该统计量任何实质性的应用价值。例如,如果某种计算方法无论代入何种数据都能得出一个恒定不变的数值,那么样本参数与总体参数之间无疑将呈现出一种"完美无缺"的对应关系。但这又有何意义呢?显然,问题的关键并不在于该统计量本身的稳定性如何,而在于它是否真正捕捉并反映了我们所关注的核心信息。同理,我们不应仅仅为了简化复杂的代数运算,就去选用那些并不恰当的统计量。当然,当今传统统计学体系中的诸多分支理论,确实大多是以标准差为基石构建而成的;但我们必须清醒地认识到:这种依赖关系并非是不可替代、非此不可的 。事实上,正如 Hampel(1997,第 9 页)所指出的那样,我们在实践中似乎过于"依赖那些基于未经充分论证的假设所推导出的孤立的数学理论片段,而非立足于实证事实与具体观测数据"。由此产生的一个后果是:自 1920 年以来,人们所构建的各类描述性统计方法,其复杂程度往往超出了实际所需,且在某种程度上显得不够"民主"(即不够通俗易懂、易于普及)。在社会科学领域,研究人员在定量研究工作及相关技能方面所呈现出的短板,通常被归结为一种"能力缺失"(deficit model)的模式;随之而来的呼声便是,号召更多的研究人员积极提升自身开展此类定量研究工作的能力。然而,其中一个关键障碍可能在于方法本身因不必要的复杂性而产生的缺陷,而非潜在用户方面的问题。