去年开始,我养成了一个习惯:每天早上打开十几个网站,刷 AI 新闻。
机器之心、量子位、新智元要看看吧?Hacker News、Reddit 的 AI 板块也不能错过。还有 Twitter 上那帮 AI 大佬的动态,OpenAI、Anthropic、Google DeepMind 的官方账号......
刷完一圈,一上午就没了。
更崩溃的是,有时候看到一篇好文章,过几天想找,死活想不起来是在哪个平台看到的。
信息焦虑症,实锤了。
我就想:能不能有个工具,把这些信息源全部聚合起来,自动更新,还能智能过滤出真正有价值的 AI 内容?
于是就有了 AI News Aggregator 这个项目。
一、它到底解决了什么问题?
做这个项目之前,我梳理了一下痛点:
| 痛点 | 解决方案 |
|---|---|
| 信息碎片化 | 统一聚合 14+ 平台、70+ RSS、52 公众号 |
| 信息噪音大 | 智能过滤算法精准提取 AI/科技相关内容 |
| 语言障碍 | 自动翻译英文标题为中文,支持双语展示 |
| 实时性差 | GitHub Actions 每 2 小时自动更新 |
| 数据分散 | 结构化 JSON 输出,方便二次开发 |
简单说,就三件事:
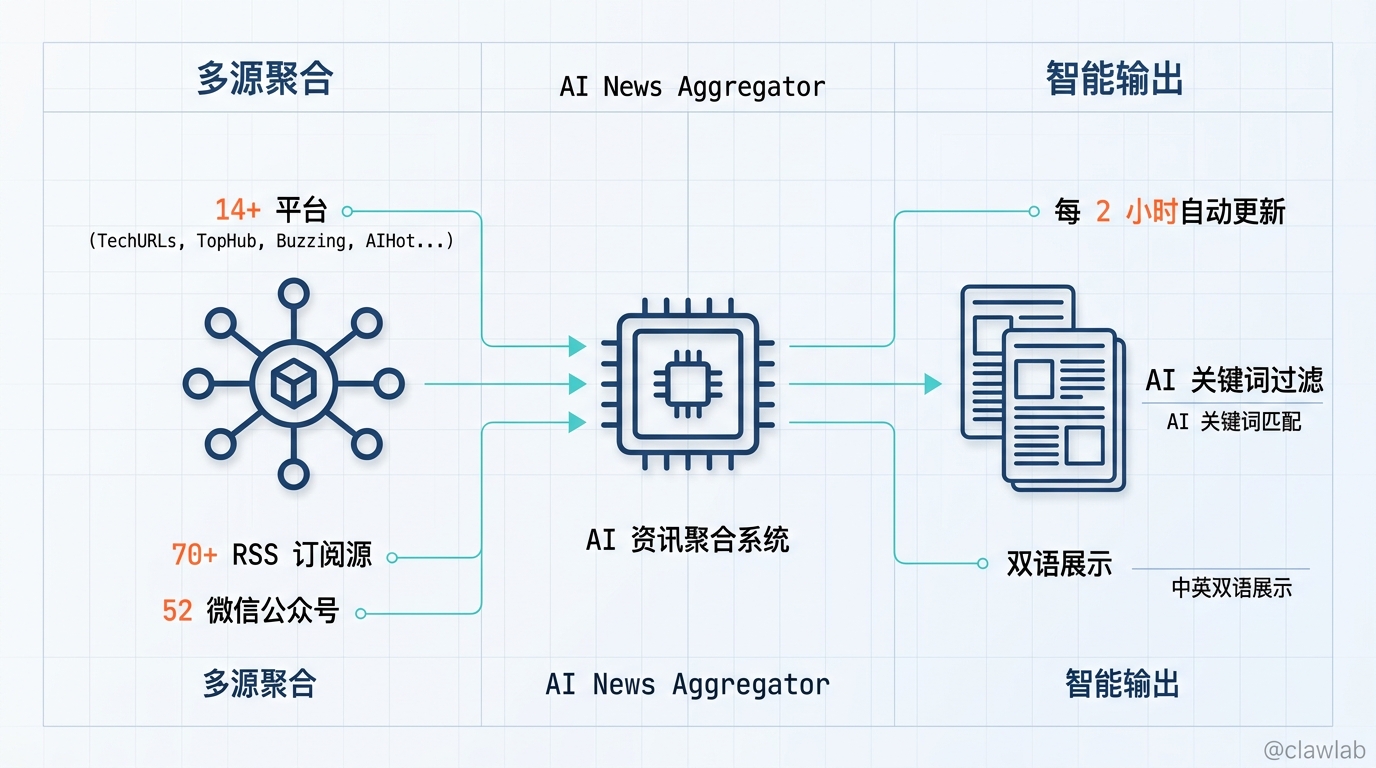
1. 多源聚合
从 14 个专业平台(AI今日热榜、TechURLs、TopHub、Buzzing 等)+ 70+ 精选 RSS 订阅 + 52 个微信公众号,实时抓取 AI 资讯。
2. 智能过滤
不是所有内容都值得看。通过关键词匹配 + 正则校验,从海量信息中精准提取 AI/科技相关内容,过滤掉电商、娱乐等噪音。
3. 自动更新
GitHub Actions 每 2 小时自动抓取一次,数据永远保持最新。还支持英文标题自动翻译为中文,提供双语展示。
二、整体架构:分层设计,职责清晰
先看一张整体架构图:
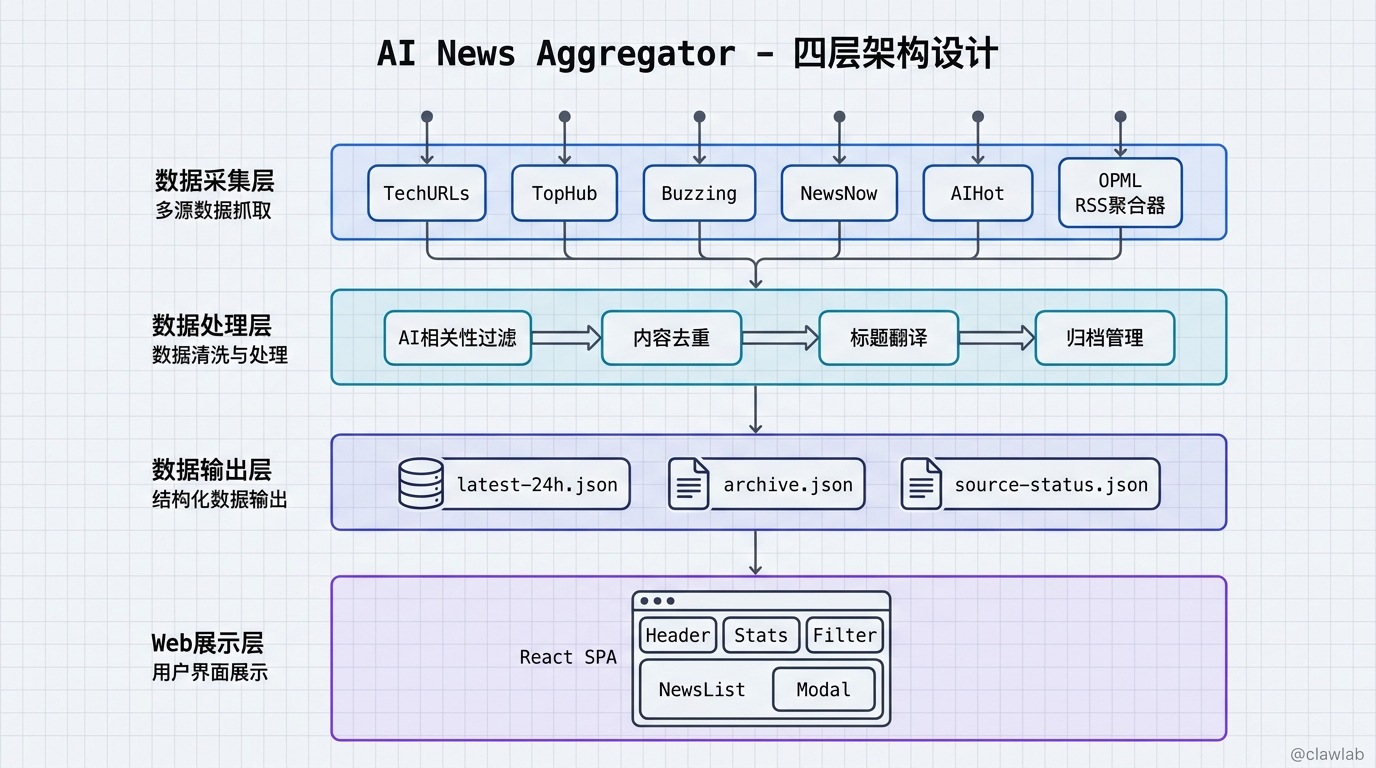
项目整体分为四层:数据采集层 → 数据处理层 → 数据输出层 → Web 展示层,每层职责清晰,高内聚低耦合。
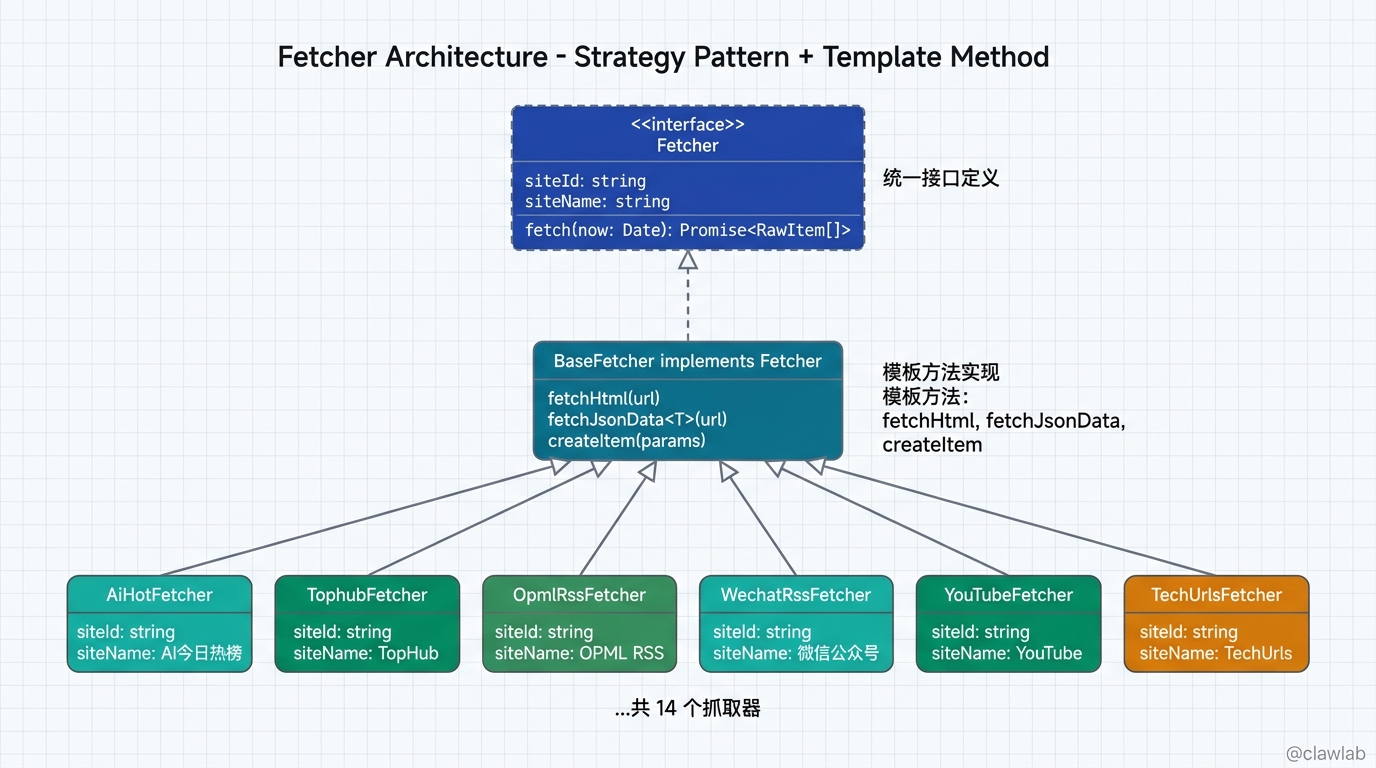
三、抓取器架构:策略模式 + 模板方法
这是整个项目最核心的部分。我设计了 14 个内置抓取器,每个对应一个平台:
| 抓取器 | 平台 | 技术方案 |
|---|---|---|
| AiHotFetcher | AI今日热榜 | Next.js SSR 数据提取 |
| TophubFetcher | TopHub | HTML 解析 + 编码检测 |
| OpmlRssFetcher | OPML RSS | rss-parser 解析 |
| WechatRssFetcher | 微信公众号 | RSSHub 订阅 |
| YouTubeFetcher | YouTube | 视频信息抓取 |
| TechUrlsFetcher | TechURLs | HTML 解析 |
| BuzzingFetcher | Buzzing | HTML 解析 |
| NewsNowFetcher | NewsNow | HTML 解析 |
| AiBaseFetcher | AIbase | HTML 解析 |
| AiHubTodayFetcher | AI HubToday | HTML 解析 |
| BestBlogsFetcher | BestBlogs | HTML 解析 |
| IrisFetcher | Info Flow | RSS 解析 |
| ZeliFetcher | Zeli | HTML 解析 |
| XinzhiyuanFetcher | 新智元 | RSS 解析 |
3.1 基类设计:模板方法模式
为了复用通用逻辑,我设计了一个抽象基类 BaseFetcher:
typescript
export abstract class BaseFetcher implements Fetcher {
abstract siteId: string;
abstract siteName: string;
abstract fetch(now: Date): Promise<RawItem[]>;
// 模板方法:HTML 抓取
protected async fetchHtml(url: string): Promise<CheerioAPI> {
const html = await fetchText(url);
return cheerio.load(html);
}
// 模板方法:JSON 抓取
protected async fetchJsonData<T>(url: string): Promise<T> {
return fetchJson<T>(url);
}
// 工厂方法:创建标准数据项
protected createItem(params: {...}): RawItem {
return {
siteId: this.siteId,
siteName: this.siteName,
...params
};
}
}每个抓取器实现统一的 Fetcher 接口:
typescript
interface Fetcher {
siteId: string;
siteName: string;
fetch(now: Date): Promise<RawItem[]>;
}这种策略模式 的设计,让扩展新数据源变得极其简单------只需新建一个类,实现 fetch 方法,然后注册到工厂函数即可。
3.2 AI今日热榜:Next.js SSR 数据提取
这个比较有意思。AI今日热榜是用 Next.js 构建的,数据不在 HTML 里,而是在 __NEXT_DATA__ 或流式 hydration 的 __next_f.push 中。
怎么提取呢?
typescript
export class AiHotFetcher extends BaseFetcher {
siteId = 'aihot';
siteName = 'AI今日热榜';
async fetch(now: Date): Promise<RawItem[]> {
const html = await fetchText('https://aihot.today/');
// 方案1:从 __next_f.push 中提取(流式 hydration)
const decoded = extractNextFMerged(html);
let initialData = extractBalancedJson(decoded, 'initialDataMap');
// 方案2:回退到 __NEXT_DATA__ script(传统 SSR)
if (!initialData) {
const nextData = extractNextDataPayload(html);
initialData = nextData?.props?.pageProps?.initialDataMap;
}
// 数据转换
for (const [sourceId, dataItems] of Object.entries(initialData)) {
for (const item of dataItems) {
items.push(this.createItem({
source: sourceName,
title: item.title_trans || item.title,
url: item.link,
publishedAt: parseDate(item.publish_time, now),
}));
}
}
return items;
}
}关键是双重降级策略,确保数据提取的健壮性。
3.3 OPML RSS 解析器:并发控制 + URL 替换
RSS 订阅是最复杂的数据源,需要处理很多边界情况:
typescript
// OPML 解析:递归处理嵌套 outline
export function parseOpmlSubscriptions(opmlContent: string): OpmlFeed[] {
const parser = new XMLParser({
ignoreAttributes: false,
attributeNamePrefix: '@_',
});
const doc = parser.parse(opmlContent);
// 递归处理嵌套 outline
function processOutline(outline: unknown): void {
const outlines = Array.isArray(outline) ? outline : [outline];
for (const o of outlines) {
const xmlUrl = o['@_xmlUrl'];
if (xmlUrl && !seen.has(xmlUrl)) {
feeds.push({
title: o['@_title'] || o['@_text'],
xmlUrl,
htmlUrl: o['@_htmlUrl'],
});
}
if (o.outline) processOutline(o.outline); // 递归
}
}
return feeds;
}
// URL 替换与跳过逻辑
function resolveOfficialRssUrl(feedUrl: string) {
// 跳过不支持的源(Telegram/B站/知乎等)
for (const prefix of CONFIG.rss.skipPrefixes) {
if (feedUrl.startsWith(prefix)) {
return { url: null, skipReason: 'no_official_rss' };
}
}
// 替换不稳定的 RSSHub 为官方源
const replaced = CONFIG.rss.replacements[feedUrl];
if (replaced) return { url: replaced, skipReason: null };
return { url: feedUrl, skipReason: null };
}
// 并发抓取:p-limit 控制并发数为 20
export async function fetchOpmlRss(now, opmlPath, maxFeeds) {
const feeds = parseOpmlSubscriptions(await readFile(opmlPath));
const limit = pLimit(CONFIG.rss.maxConcurrency);
const results = await Promise.all(
resolvedFeeds.map((feed) =>
limit(() => fetchSingleFeed(feed, now))
)
);
return { items, summaryStatus, feedStatuses };
}四、过滤器模块:四层过滤策略
AI 相关性过滤是最核心的逻辑。不是所有内容都是 AI 相关的,比如 TopHub 上有淘宝热销榜、微博热搜,这些需要过滤掉。
我设计了四层过滤策略:
typescript
export function isAiRelated(record: ArchiveItem): boolean {
const siteId = record.site_id.toLowerCase();
const text = `${title} ${source} ${siteName} ${url}`.toLowerCase();
// 规则1:特定站点全部放行
if (['aibase', 'aihot', 'aihubtoday'].includes(siteId)) {
return true;
}
// 规则2:TopHub 需要额外校验来源白名单
if (siteId === 'tophub') {
if (hasMojibakeNoise(source)) return false;
if (containsAnyKeyword(source, CONFIG.filter.tophubBlockKeywords)) return false;
if (!containsAnyKeyword(source, CONFIG.filter.tophubAllowKeywords)) return false;
}
// 规则3:关键词匹配
const hasAi = containsAnyKeyword(text, CONFIG.filter.aiKeywords) ||
CONFIG.filter.enSignalPattern.test(text);
const hasTech = containsAnyKeyword(text, CONFIG.filter.techKeywords);
// 规则4:噪音过滤
if (containsAnyKeyword(text, CONFIG.filter.commerceNoiseKeywords) && !hasAi) return false;
if (containsAnyKeyword(text, CONFIG.filter.noiseKeywords) && !hasAi) return false;
return hasAi || hasTech;
}过滤策略分层:
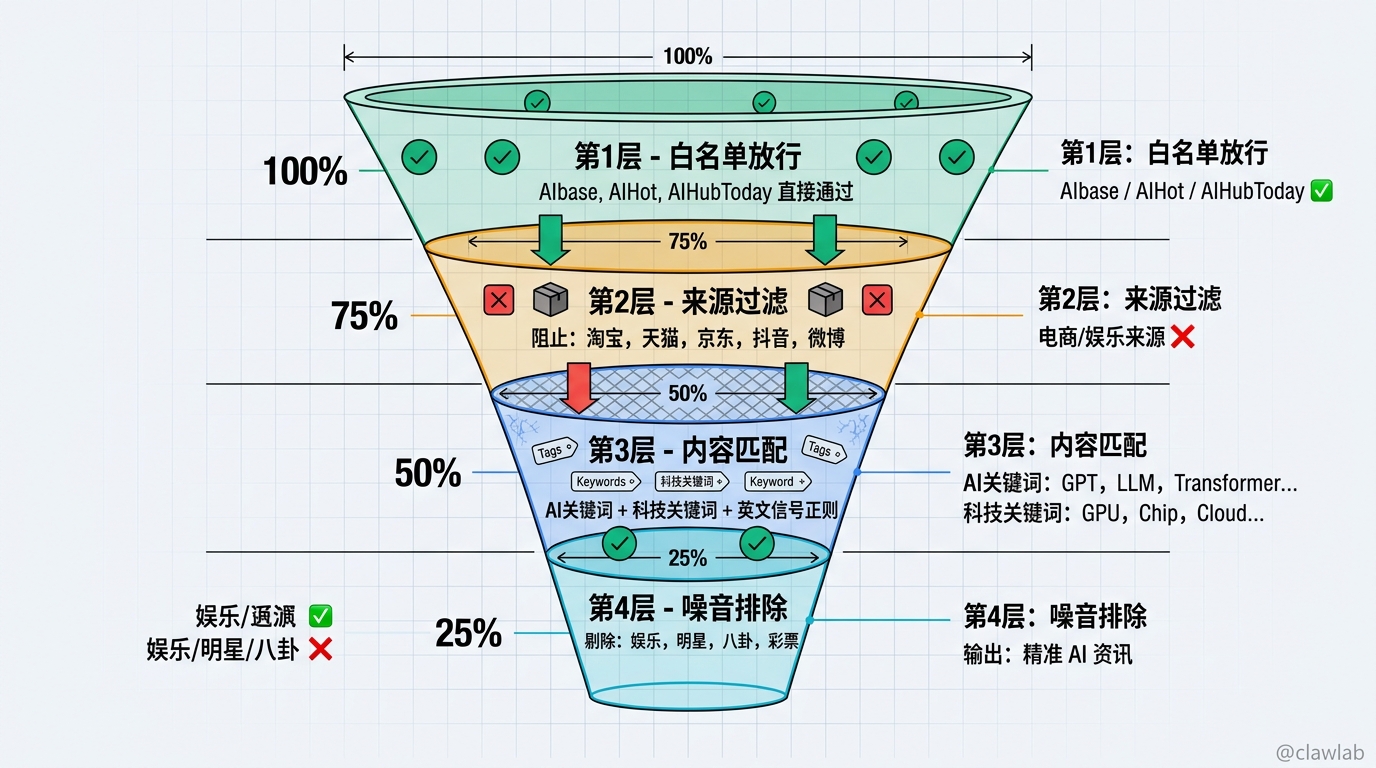
关键词列表是这样定义的:
typescript
filter: {
aiKeywords: ['aigc', 'llm', 'gpt', 'claude', 'gemini', 'deepseek',
'openai', 'anthropic', 'hugging face', 'transformer',
'prompt', 'diffusion', 'agent', '多模态', '大模型', ...],
techKeywords: ['robot', 'chip', 'semiconductor', 'cuda', 'gpu',
'cloud', 'developer', '开源', '技术', '芯片', ...],
noiseKeywords: ['娱乐', '明星', '八卦', '足球', '篮球', '彩票', ...],
commerceNoiseKeywords: ['淘宝', '天猫', '京东', '拼多多', '券后', ...],
}去重逻辑
同一篇文章可能被多个平台转载,需要根据 title + url 去重:
typescript
export function dedupeItemsByTitleUrl(
items: ArchiveItem[],
randomPick: boolean = true
): ArchiveItem[] {
const groups = new Map<string, ArchiveItem[]>();
for (const item of items) {
// 生成去重 Key:title + url
const key = siteId === 'aihubtoday'
? `url::${url}` // 特殊处理
: `${title.toLowerCase()}||${url}`;
if (!groups.has(key)) groups.set(key, []);
groups.get(key)!.push(item);
}
const result: ArchiveItem[] = [];
for (const values of groups.values()) {
if (randomPick) {
// 随机选择(用于 all 模式)
result.push(values[Math.floor(Math.random() * values.length)]);
} else {
// 选择最新的(用于 AI 模式)
result.push(values.reduce(pickNewest));
}
}
return result.sort(byTimeDesc);
}五、翻译模块:缓存复用 + 增量翻译
英文标题需要翻译成中文,但 Google 翻译 API 有调用限制。
我设计了三级翻译策略:
typescript
const TRANSLATE_API = 'https://translate.googleapis.com/translate_a/single';
export async function translateToZhCN(text: string): Promise<string | null> {
const params = new URLSearchParams({
client: 'gtx', // 使用免费端点
sl: 'auto', // 自动检测语言
tl: 'zh-CN', // 目标语言
dt: 't', // 返回翻译
q: text,
});
const response = await fetchJson(`${TRANSLATE_API}?${params}`);
// 解析响应:[[["翻译结果", "原文", ...]]]
const translated = response[0]
.filter(seg => seg[0])
.map(seg => String(seg[0]))
.join('');
return translated;
}
export async function addBilingualFields(
itemsAi: ArchiveItem[],
itemsAll: ArchiveItem[],
cache: Map<string, string>,
maxNewTranslations: number
): Promise<{...}> {
let translatedNow = 0;
const enrich = async (item: ArchiveItem, allowTranslate: boolean) => {
const title = item.title.trim();
// 中文标题:直接使用
if (hasCjk(title)) {
return { ...item, title_zh: title };
}
// 英文标题:尝试翻译
if (isMostlyEnglish(title)) {
item.title_en = title;
// 优先使用缓存
let zhTitle = cache.get(title);
// 缓存未命中且允许翻译
if (!zhTitle && allowTranslate && translatedNow < maxNewTranslations) {
zhTitle = await translateToZhCN(title);
if (zhTitle) {
cache.set(title, zhTitle);
translatedNow++;
}
}
if (zhTitle) {
item.title_zh = zhTitle;
item.title_bilingual = `${zhTitle} / ${title}`;
}
}
return item;
};
// AI 条目:允许翻译
const aiOut = await Promise.all(itemsAi.map(it => enrich(it, true)));
// 全部条目:仅使用缓存
const allOut = await Promise.all(itemsAll.map(it => enrich(it, false)));
return { itemsAi: aiOut, itemsAll: allOut, cache };
}翻译策略:
| 策略 | 说明 |
|---|---|
| 缓存复用 | 已翻译标题持久化到 title-zh-cache.json |
| 增量翻译 | 每次最多翻译 80 个新标题 |
| 分级处理 | AI 条目优先翻译,其他条目仅用缓存 |
六、那些踩过的坑
6.1 Next.js SSR 数据提取
AI今日热榜是用 Next.js 构建的,数据不在 HTML 里,而是在 __NEXT_DATA__ 或流式 hydration 的 __next_f.push 中。
关键是双重降级策略,确保数据提取的健壮性。
6.2 编码检测与修复
TopHub 这种国内网站,有时候返回的是 GB18030 编码,而不是 UTF-8。直接解析会乱码。
解决方案:
typescript
let html = new TextDecoder('utf-8').decode(buffer);
// 检测是否有乱码字符
if (hasGarbledCharacters(html)) {
const gb18030Html = new TextDecoder('gb18030').decode(buffer);
// 选择损坏字符更少的版本
if (countGarbledChars(gb18030Html) < countGarbledChars(html)) {
html = gb18030Html;
}
}还有 Mojibake 修复------有些标题在传输过程中被错误编码,需要尝试 Latin1 → UTF-8 转码:
typescript
function maybeFixMojibake(text: string): string {
// 检测常见乱码特征
if (!/[Ãâåèæïð]|[\x80-\x9f]/.test(text)) return text;
// 尝试 Latin1 -> UTF-8 转码
const bytes = Buffer.from(text, 'latin1');
const fixed = bytes.toString('utf-8');
// 如果修复后仍有乱码,返回原文
return hasGarbledCharacters(fixed) ? text : fixed;
}6.3 并发控制
同时抓取 70+ RSS 订阅,不加限制的话会被封 IP。
使用 p-limit 控制并发数:
typescript
const limit = pLimit(20); // 最多 20 个并发
const results = await Promise.all(
feeds.map(feed => limit(() => fetchSingleFeed(feed, now)))
);6.4 HTTP 请求封装:重试 + 超时
typescript
export async function fetchWithRetry(url: string, options = {}) {
const { retries = 3, timeout = 60000 } = options;
let lastError: Error | null = null;
for (let attempt = 0; attempt <= retries; attempt++) {
try {
const controller = new AbortController();
const timeoutId = setTimeout(() => controller.abort(), timeout);
const response = await fetch(url, {
headers: {
'User-Agent': CONFIG.http.userAgent,
'Accept-Language': 'zh-CN,zh;q=0.9,en;q=0.8',
},
signal: controller.signal,
});
clearTimeout(timeoutId);
// 可重试的状态码:429, 500, 502, 503, 504
if (!response.ok && CONFIG.http.retryStatusCodes.includes(response.status)) {
throw new Error(`HTTP ${response.status}`);
}
return response;
} catch (error) {
lastError = error;
if (attempt < retries) {
// 指数退避:800ms, 1600ms, 2400ms
await sleep(CONFIG.http.retryDelay * (attempt + 1));
}
}
}
throw lastError;
}七、自动化部署:GitHub Actions 全搞定
项目配置了 GitHub Actions,每 2 小时自动执行:
yaml
on:
schedule:
- cron: "0 */2 * * *" # 每 2 小时工作流程:
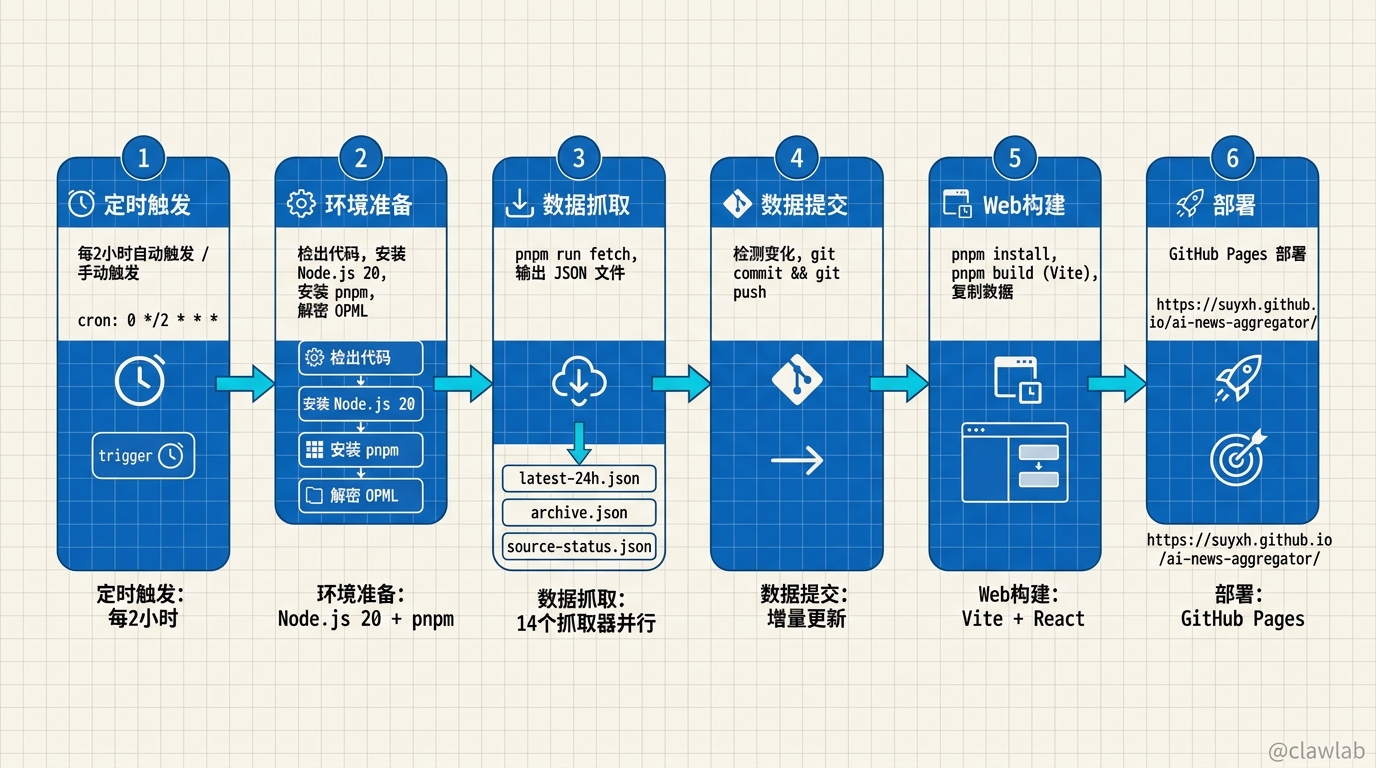
全程自动化,完全不用人工干预。
八、前端架构:React Hooks + 智能预加载
React 18 + TypeScript + Vite + Tailwind CSS,一个标准的现代前端技术栈。
核心 Hook: useNewsData
typescript
export function useNewsData(): UseNewsDataReturn {
const [data, setData] = useState<NewsData | null>(null);
const [selectedSite, setSelectedSite] = useState('opmlrss');
const [selectedSource, setSelectedSource] = useState('all');
const [searchQuery, setSearchQuery] = useState('');
const [displayCount, setDisplayCount] = useState(PAGE_SIZE);
const [timeRange, setTimeRange] = useState<TimeRange>('24h');
// 智能预加载:加载 24h 数据后自动预加载 7d 数据
const preloadedDataRef = useRef<{ [key in TimeRange]?: NewsData }>({});
// 数据获取
const fetchData = async (range: TimeRange, isPreload = false) => {
if (preloadedDataRef.current[range] && !isPreload) {
setData(preloadedDataRef.current[range]!);
return;
}
const fileName = range === '24h' ? 'latest-24h.json' : 'latest-7d.json';
const response = await fetch(`${basePath}data/${fileName}`);
const json = await response.json();
preloadedDataRef.current[range] = json;
if (!isPreload) setData(json);
};
// 筛选逻辑
const filteredItems = useMemo(() => {
let items = data?.items || [];
// 按站点筛选
if (selectedSite !== 'all') {
items = items.filter(item => item.site_id === selectedSite);
}
// 按来源筛选
if (selectedSource !== 'all') {
items = items.filter(item => item.source === selectedSource);
}
// 搜索
if (searchQuery.trim()) {
const query = searchQuery.toLowerCase();
items = items.filter(item =>
item.title.toLowerCase().includes(query) ||
item.source.toLowerCase().includes(query) ||
item.title_zh?.toLowerCase().includes(query)
);
}
// 分页
return items.slice(0, displayCount);
}, [data, selectedSite, selectedSource, searchQuery, displayCount]);
return { data, filteredItems, sourceStats, ... };
}还有一个智能预加载机制:加载 24h 数据后,自动在后台预加载 7d 数据。这样用户切换时间范围时,可以实现"秒开"。
九、扩展指南:想加新数据源怎么办?
只需三步:
1. 创建新的 Fetcher 类
typescript
class NewSourceFetcher extends BaseFetcher {
siteId = 'newsource';
siteName = 'New Source';
async fetch(now: Date): Promise<RawItem[]> {
const html = await this.fetchHtml('https://newsource.com');
// ...解析数据
return items.map(item => this.createItem({...}));
}
}2. 导出
typescript
export { NewSourceFetcher } from './newsource.js';3. 注册到工厂函数
typescript
export function createAllFetchers(): Fetcher[] {
return [
...existing,
new NewSourceFetcher(),
];
}就这么简单。
十、技术亮点总结
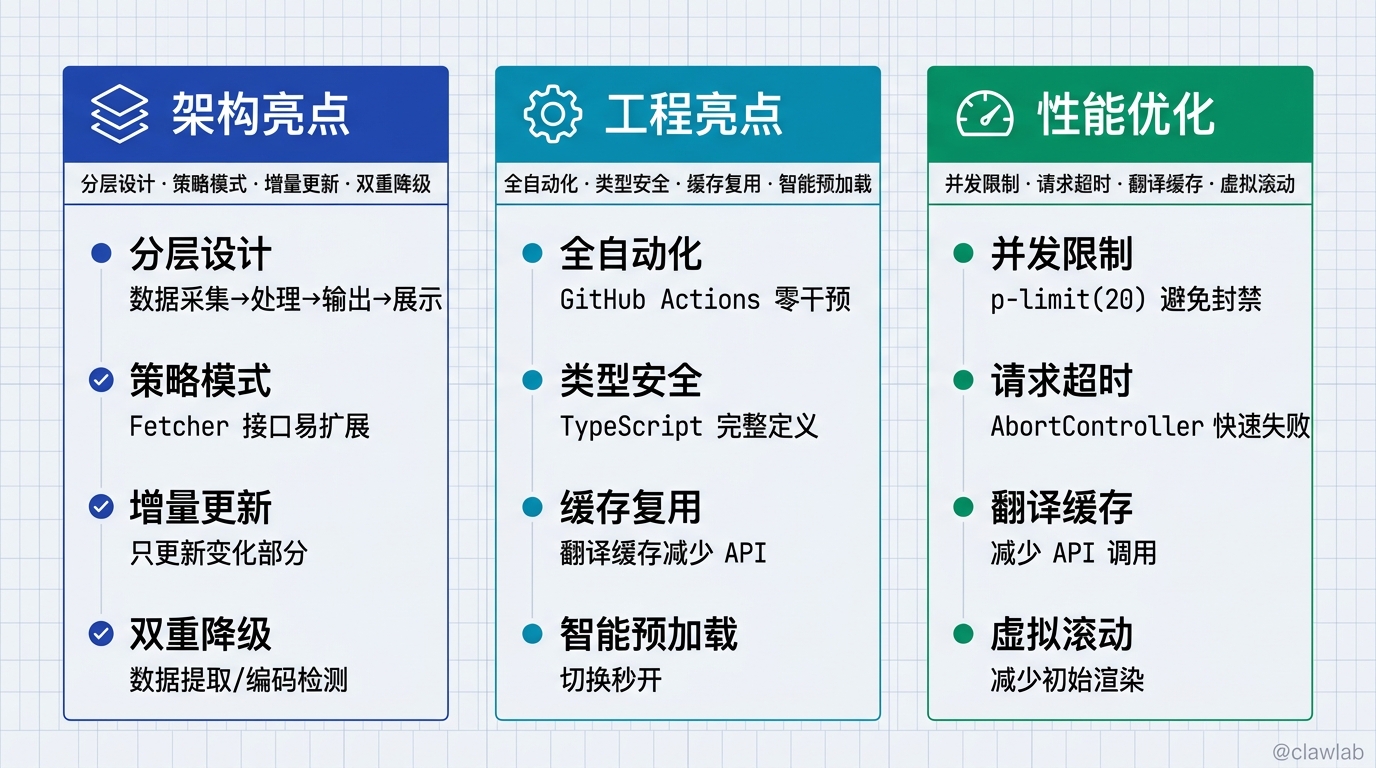
架构亮点
| 亮点 | 说明 |
|---|---|
| 分层设计 | 数据采集层 → 处理层 → 输出层 → 展示层,职责清晰 |
| 策略模式 | Fetcher 接口使扩展新数据源极为简单 |
| 增量更新 | 归档数据只更新变化部分,高效可靠 |
| 双重降级 | 数据提取、编码检测等多重降级策略 |
工程亮点
| 亮点 | 说明 |
|---|---|
| 全自动化 | GitHub Actions 实现全自动更新部署 |
| 类型安全 | TypeScript 完整类型定义 |
| 缓存复用 | 翻译缓存减少 API 调用 |
| 智能预加载 | 前端预加载实现切换秒开 |
性能优化
| 层级 | 策略 | 实现 | 效果 |
|---|---|---|---|
| 抓取层 | 并发限制 | p-limit(5) / p-limit(20) | 避免被封禁 |
| 抓取层 | 请求超时 | AbortController | 快速失败 |
| 抓取层 | 指数退避 | retryDelay * (attempt + 1) | 平滑重试 |
| 处理层 | 增量合并 | Map<id, ArchiveItem> | O(1) 查找 |
| 处理层 | 翻译缓存 | title-zh-cache.json | 减少 API 调用 |
| 处理层 | 翻译限流 | maxNewTranslations: 80 | 控制耗时 |
| 前端 | 虚拟滚动 | displayCount + loadMore | 减少初始渲染 |
| 前端 | useMemo | 筛选结果缓存 | 避免重复计算 |
| 前端 | 智能预加载 | 加载 24h 后预加载 7d | 切换秒开 |
用户体验亮点
| 亮点 | 说明 |
|---|---|
| 响应式设计 | 支持移动端 |
| 暗色模式 | 支持浅色/深色主题切换 |
| 多维度筛选 | 按平台、来源、关键词筛选 |
| 收藏/历史 | 本地持久化收藏和阅读历史 |
| 双语展示 | 英文标题自动翻译为中文 |
写在最后
这个项目解决了我自己的痛点,也希望能帮到同样有信息焦虑的朋友。
技术栈:
- 后端:TypeScript + Cheerio + rss-parser + p-limit
- 前端:React 18 + Vite + Tailwind CSS
- 部署:GitHub Actions + GitHub Pages
核心价值:
- 多源聚合,一网打尽
- 智能过滤,精准推送
- 自动更新,省心省力
- 双语支持,无障碍阅读
如果你也想搭建自己的资讯聚合系统,欢迎参考这个项目。代码开源,MIT 协议,随便折腾。 https://github.com/SuYxh/ai-news-aggregator
如果这篇文章对你有帮助,点个赞再走呗 👍
关注「WEB大前端」,每周分享技术实践和行业洞察。